that enables marketers and media owners to drive better commerce outcomes. Its industry leading Commerce Media Platform connects thousands of marketers and media owners to deliver richer consumer experiences from product discovery to purchase. By powering trusted and impactful advertising, Criteo supports an open internet that encourages discovery, innovation, and choice. For more information, please visit www.criteo.com.
new server • Do hours long, manual tests • Realize you picked wrong BIOS option • Start over • Now you need to test another part • Start over • BMC power report inconsistent with PDU • Start over
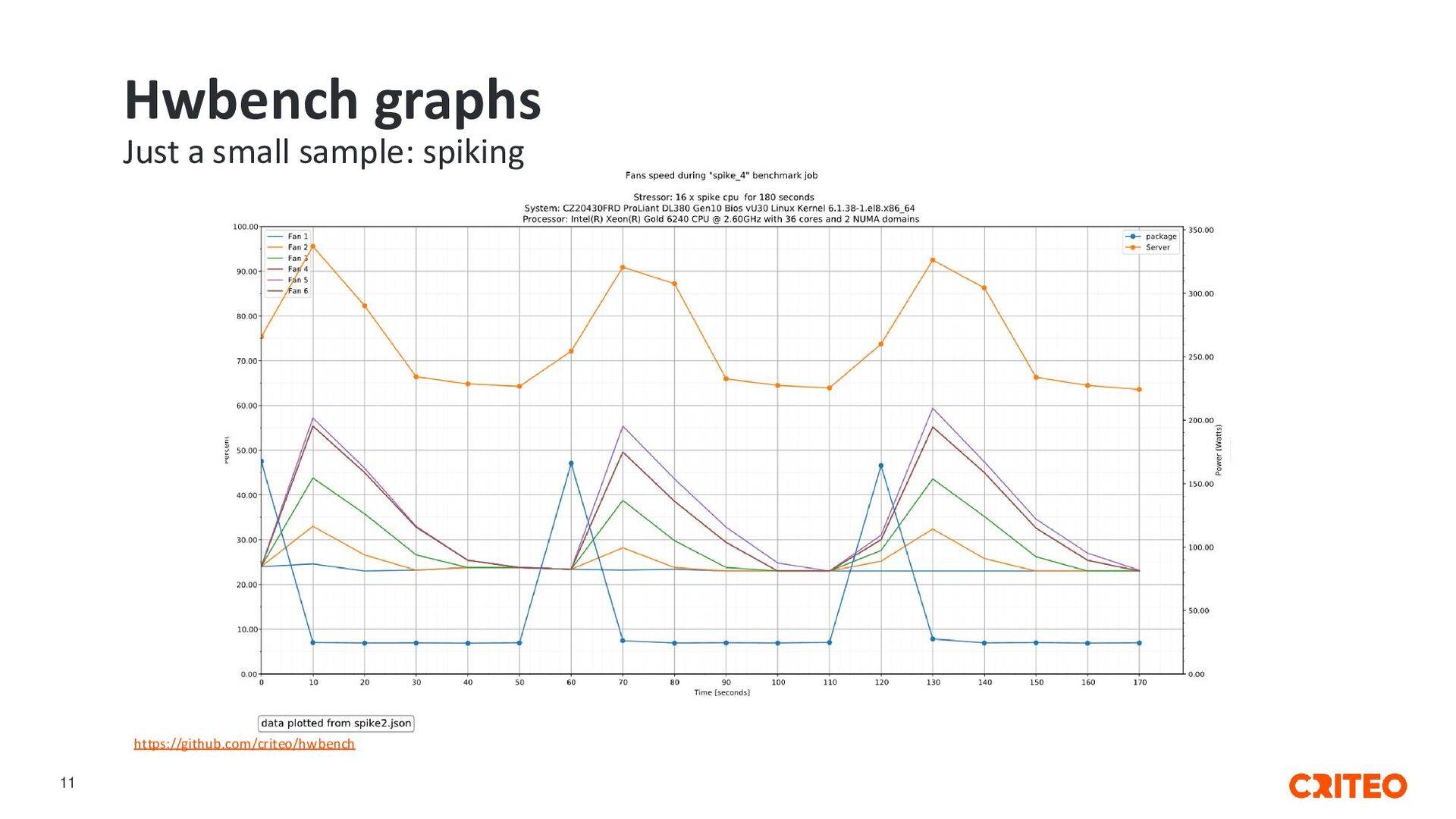
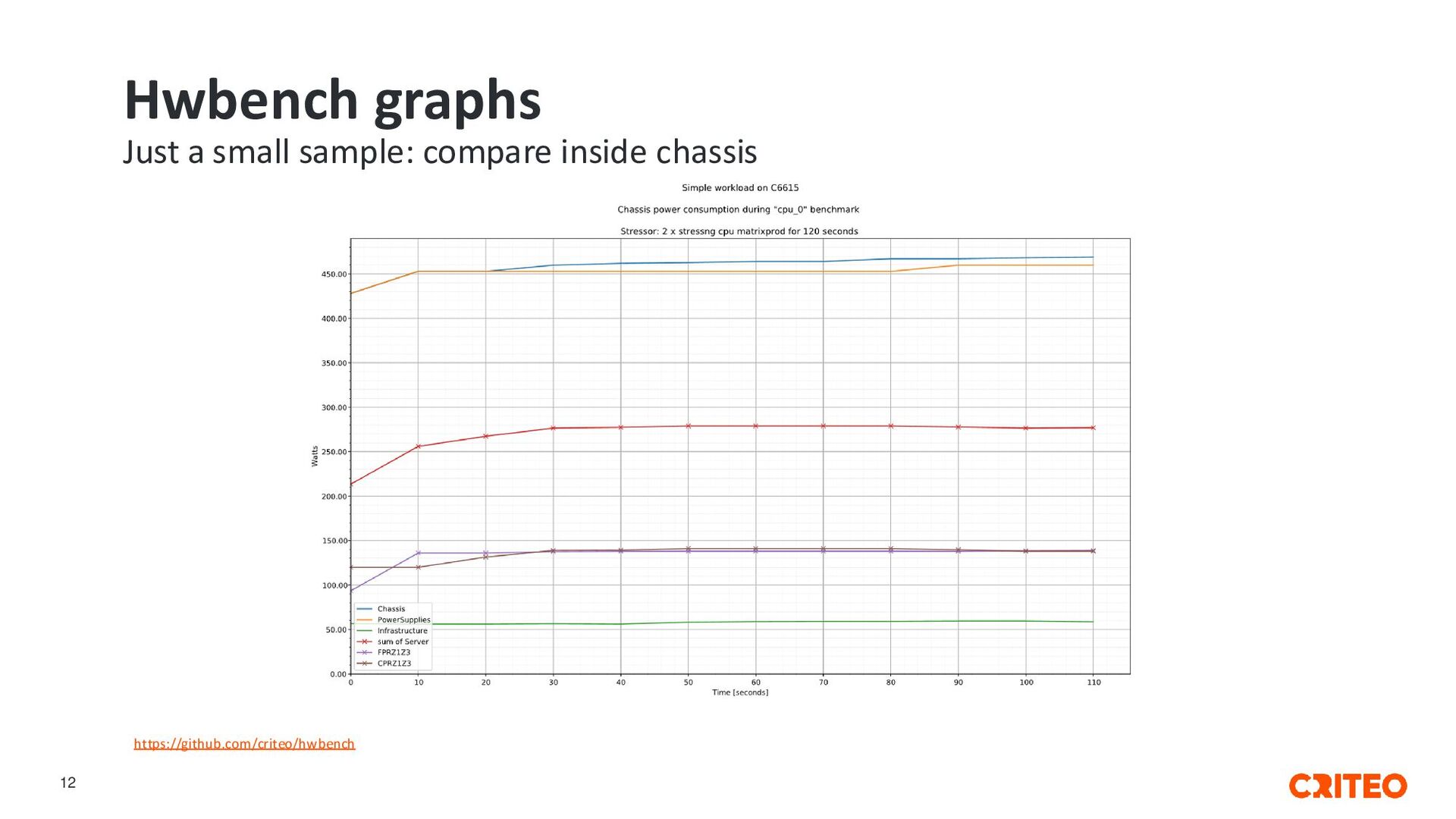
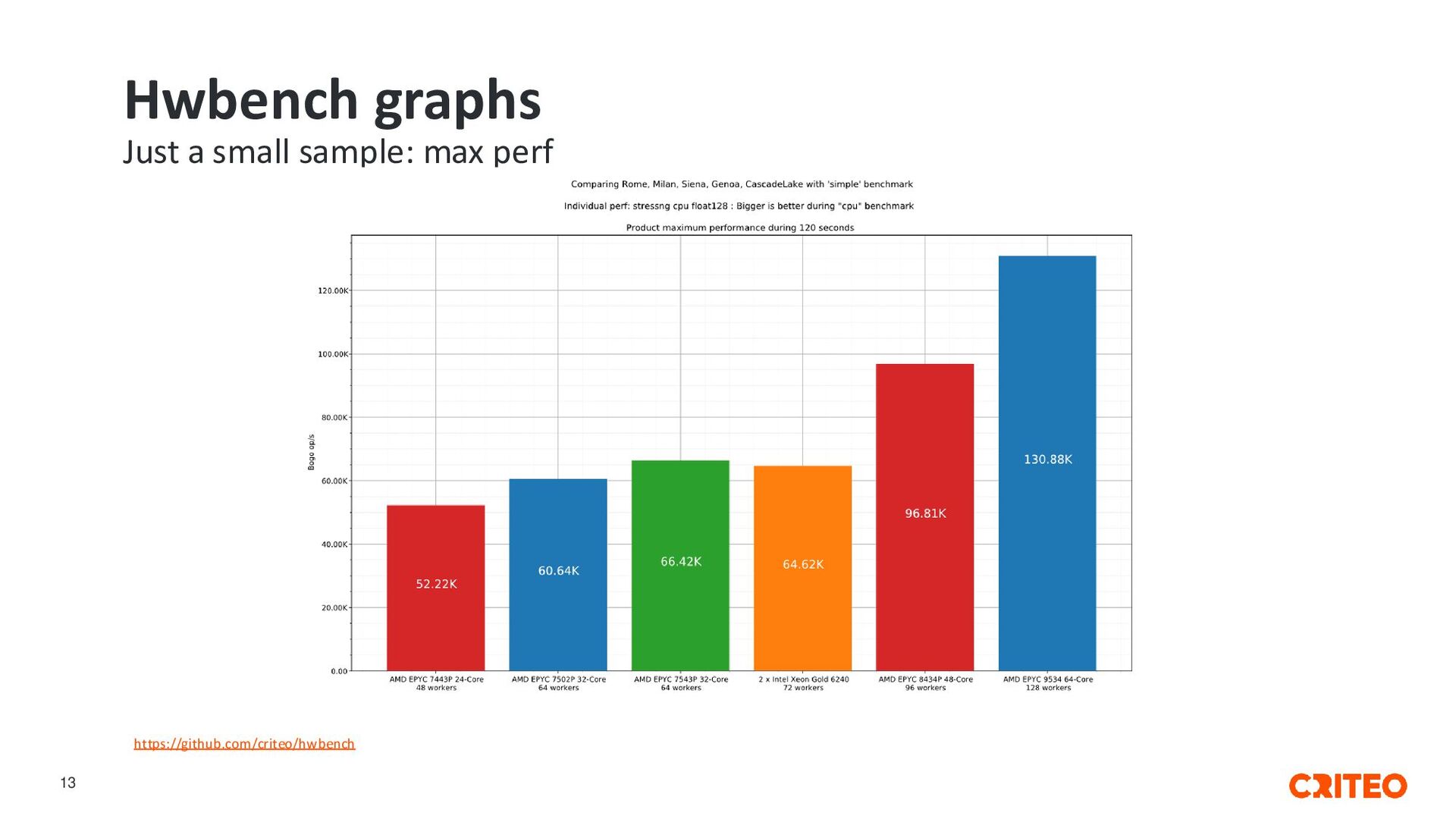
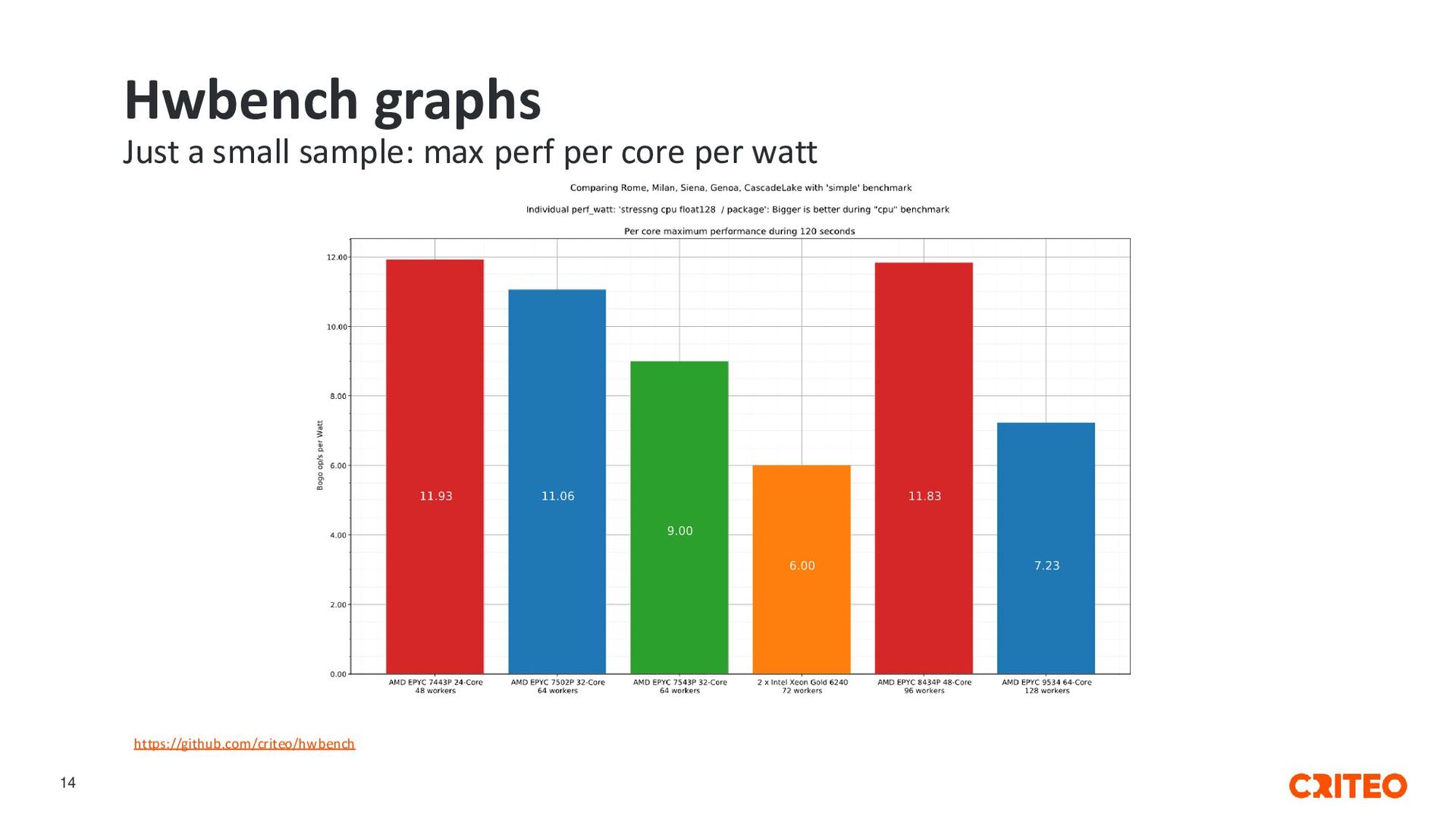
it, give us feedback • Vendors: try it, criticize and give advice • Exchange traceable results and reproducible tests • Contributions welcome! https://github.com/criteo/hwbench
infra: o Regular updates of firmware o Auto-detection of hardware problems o Auto-release of servers and ticket fixing • Small number of customers: o Windows o Servers as pets, not cattle
the box: o Listing all firmware, versions and available updates on a given server o Getting an accurate changelog o Common tooling to do updates o Precise control of firmware versions for canary testing • See @Erwan’s OSFC talk: https://www.osfc.io/2022/talks/open-firmware-on-your-infrastructure-not-only-for- hyperscalers/
targeting SREs (automation) o Toolbox (API) vs packaged tool • Participate in open-source tooling: o LVFS/fwupd o dmidecode (HPE), smartmontools, nvme-cli • Open-source is major differentiator
are slow to arrive on servers (e.g PLDM) • No certification, only test suites and profiles • Often metrics need vendor-specific handling and reverse engineering (undocumented) • Easy to find inconsistencies in implementations
impact customer workloads • Untestable and undocumented error cases (ex: undecoded MCEs or BMC errors) o Hard to automate detection o No indication of gravity or action to take • In-band still necessary (disks, CPU perf throttling...)
has access a limited set of servers • We monitor and see issues on thousands of a single type of server o « in rare conditions » o A few percents is a lot of impacted servers • Let’s (transparently) share the monitoring metrics! o Vendors can anticipate support
than customers o No more bugfixes (see gen+1) o No more new features (see gen+2) • Clear communication in advance • Pay to have software maintenance throughout server lifetime?
• Sometimes changing parts at scale is impractical • (Good) Written reports have the most impact on the long term, as they get passed around o But you might not see this (around 18 months)
• JEDEC Post Package Repair (PPR) for DIMMs • Firmware remediations o Bad diagnostic in monitoring o Software bug already fixed after bump o Software bug to report
have in-house tools o We lack tools to identify « working hardware » • How identical do we want it to be? o Functional equivalents are not always equivalent o No automatable checks
We care about root-of-trust transfer of ownership for BMCs (see talk by @Vincent on OpenBMC) • Processor fusing isn’t properly thought o Security could be kept without value destruction
We aim at working only with companies that offer and support open-source software We want to improve things for everyone If ideas and processes can help similar actors, we are happy to share mostly everything. We want privileged access to engineering Support starts at L3+ We want everything to be automation-ready Infra-as-code approach, usually via API We question spec sheets and put promises to the test NDA level data sheets >> marketing presentations We want to see what the future holds Knowledge is key when planning months/years ahead. Best would be to contribute to designs & roadmaps. We want to use our assets for as long as possible 5-year strict minimum. 7 to 9-year is our target We consider all costs TCO is key (power consumption, performance, cost, long-term support,…). We truly care about our environmental footprint Given similar products, environmental impact would be a strong tie-breaker. Openness Expertise Efficiency orientation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}