As AI inference workloads grow more complex, designing flexible and scalable hardware infrastructure is more critical than ever. In this session, we’ll explore how Cloudflare builds hardware for its global network, balancing cost, performance, and adaptability. From selecting the right inference accelerators to designing for flexibility in evolving workloads, we’ll discuss real-world trade-offs, system design constraints, and operational challenges. Join us for an inside look at how real deployment metrics shape our hardware roadmap and the lessons learned from scaling inference at the edge amidst shifting performance bottlenecks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
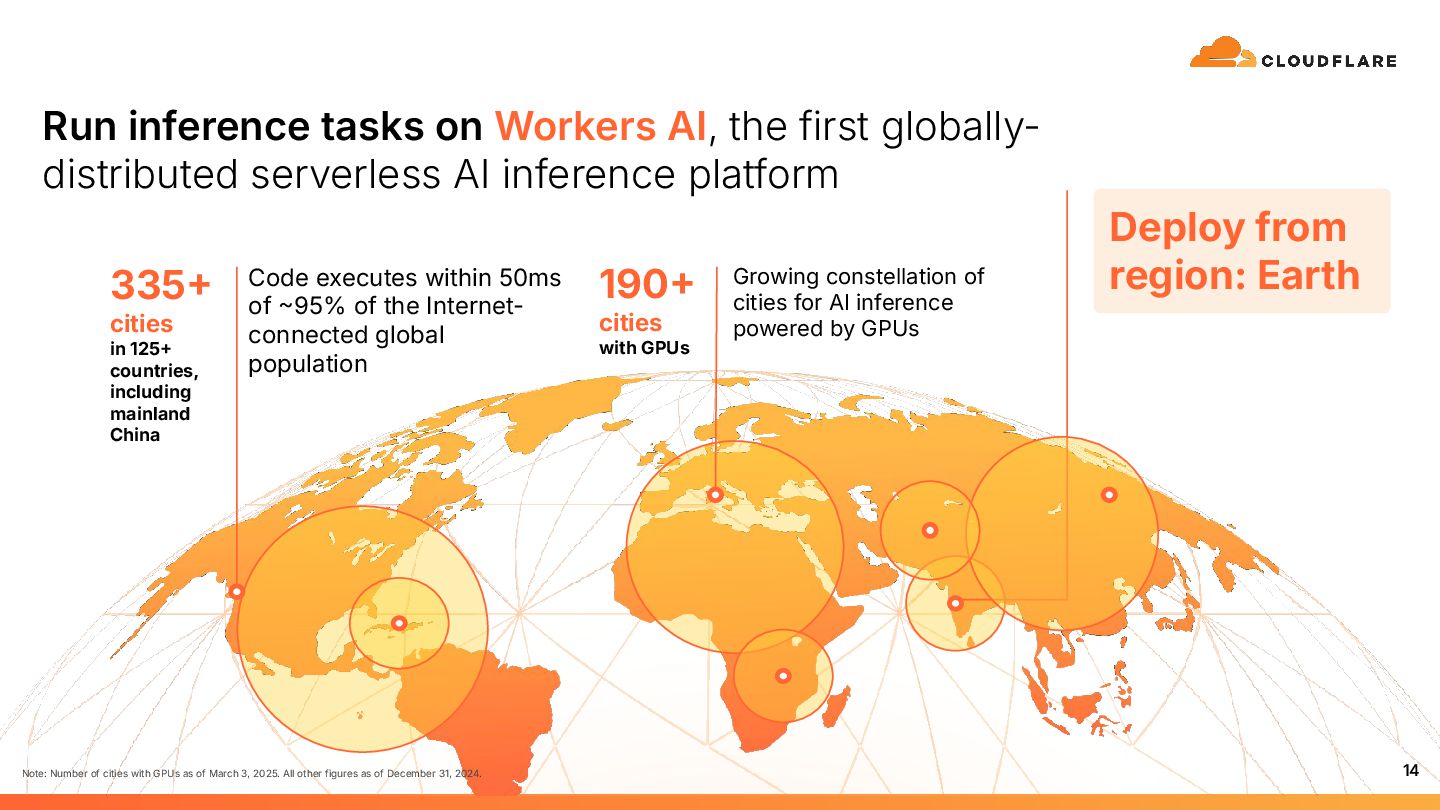{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
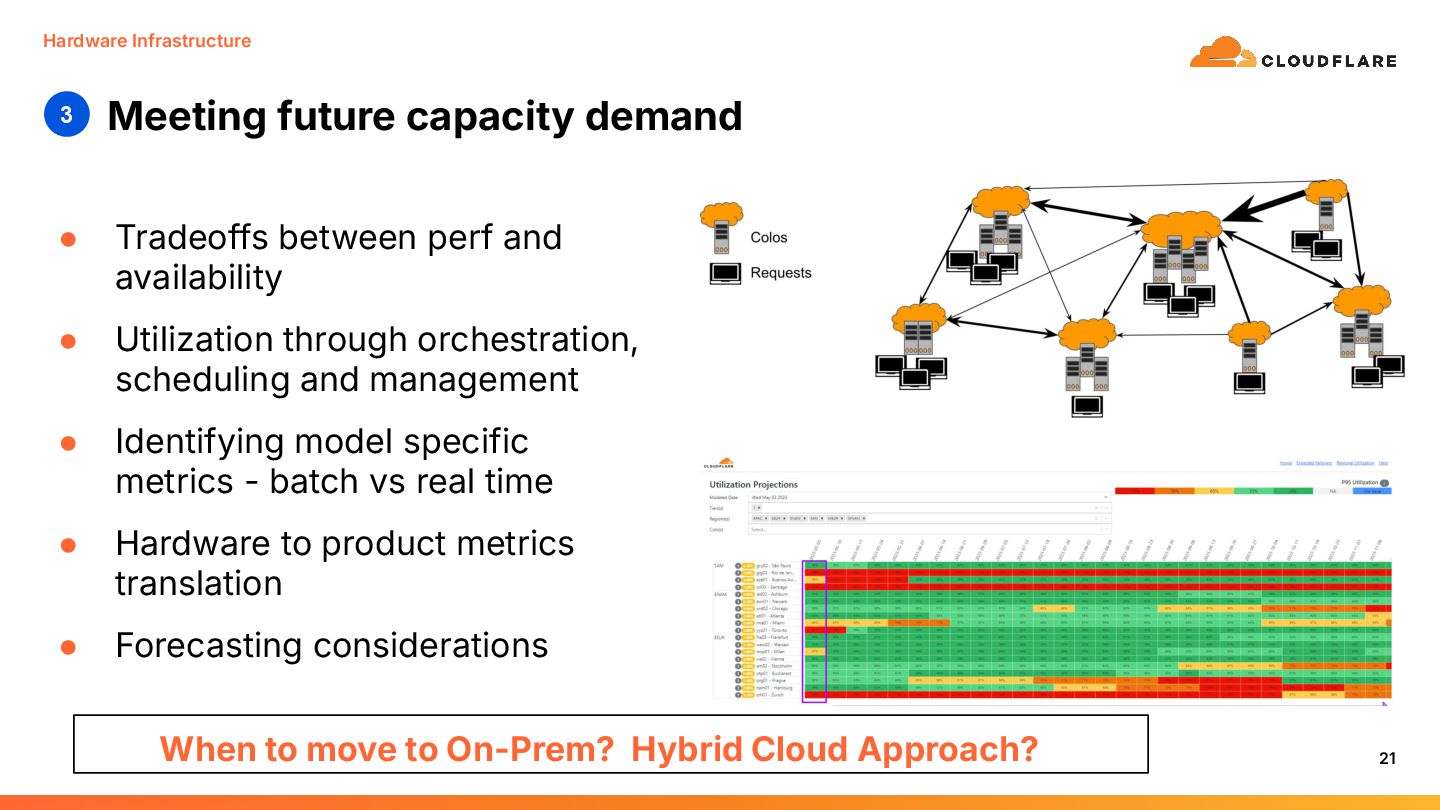{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
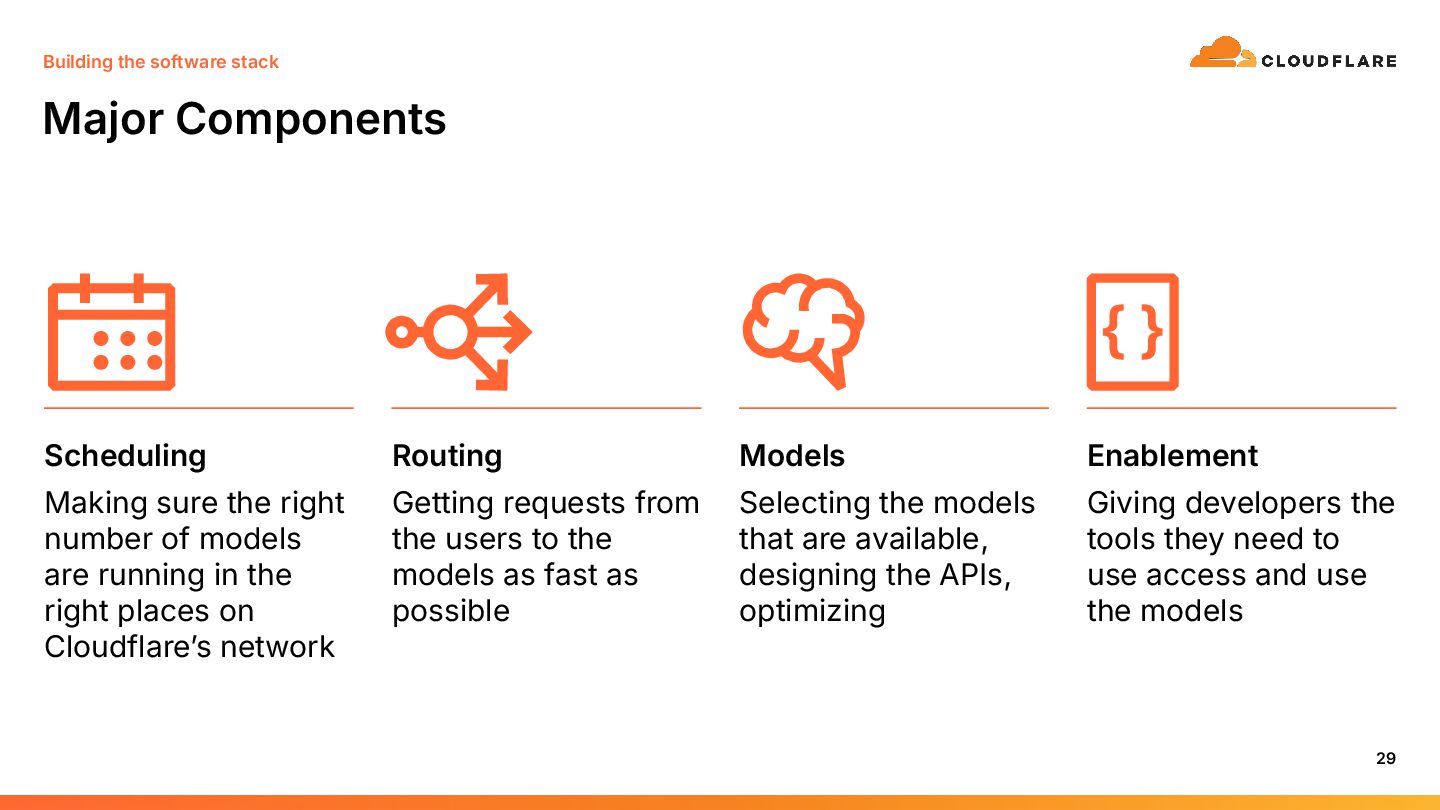{kind=link}
{kind=link}
{kind=link}