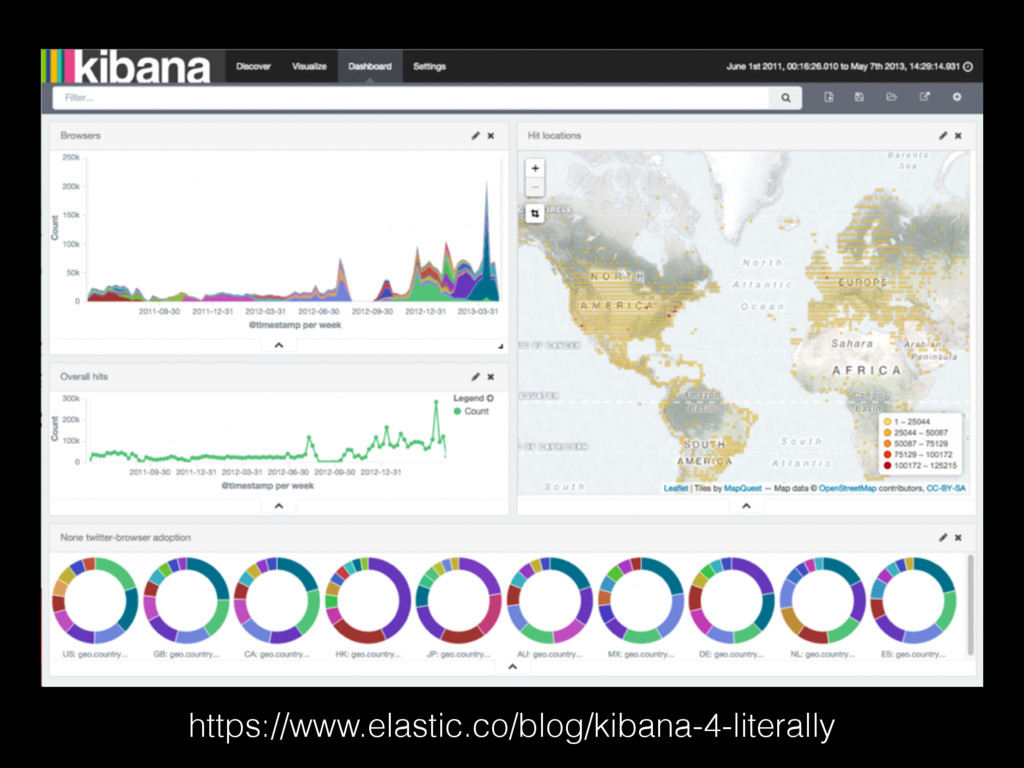
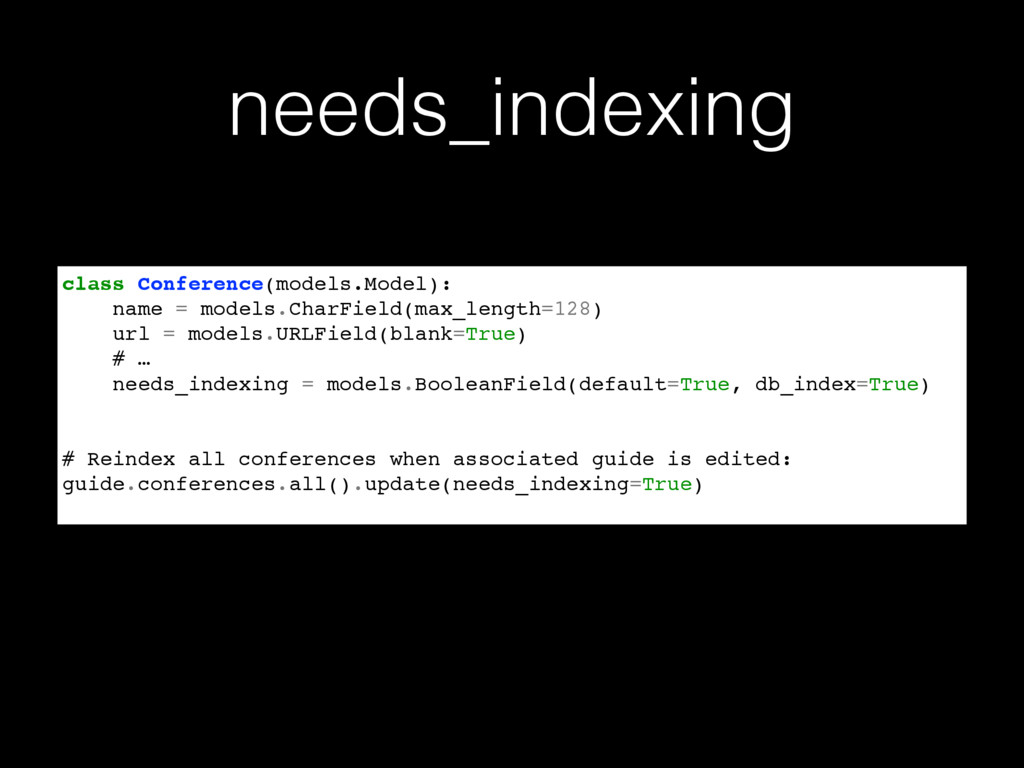
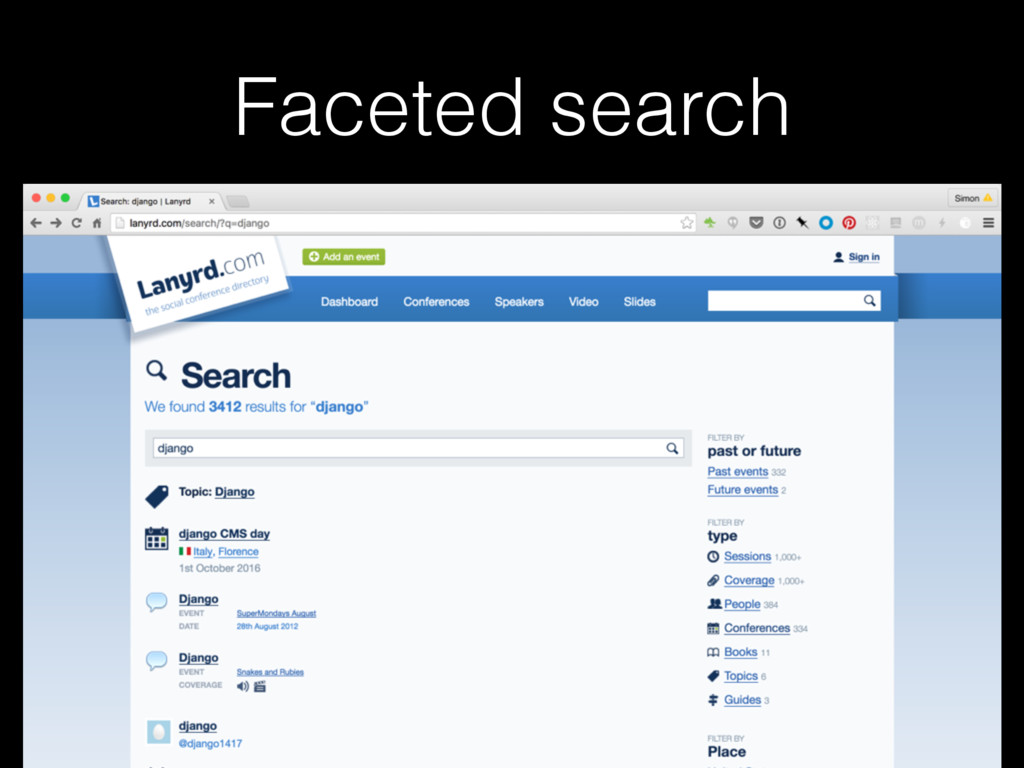
Description
Elasticsearch is a powerful open-source search and analytics engine with applications that stretch far beyond adding text-based search to a website. Learn how Elasticsearch can be used with Python and Django to crunch through complex datasets and quickly build powerful interfaces for exploring information.
Bio
Simon Willison is an engineering director at Eventbrite, a Bay Area ticketing company working to bring the world together through live experiences. Simon works as part of a small product research and prototyping lab helping develop new concepts for Eventbrite products and features. Simon joined Eventbrite through their acquisition of Lanyrd, a Y Combinator funded company he co-founded in 2010. He is a co-creator of the Django Web Framework.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
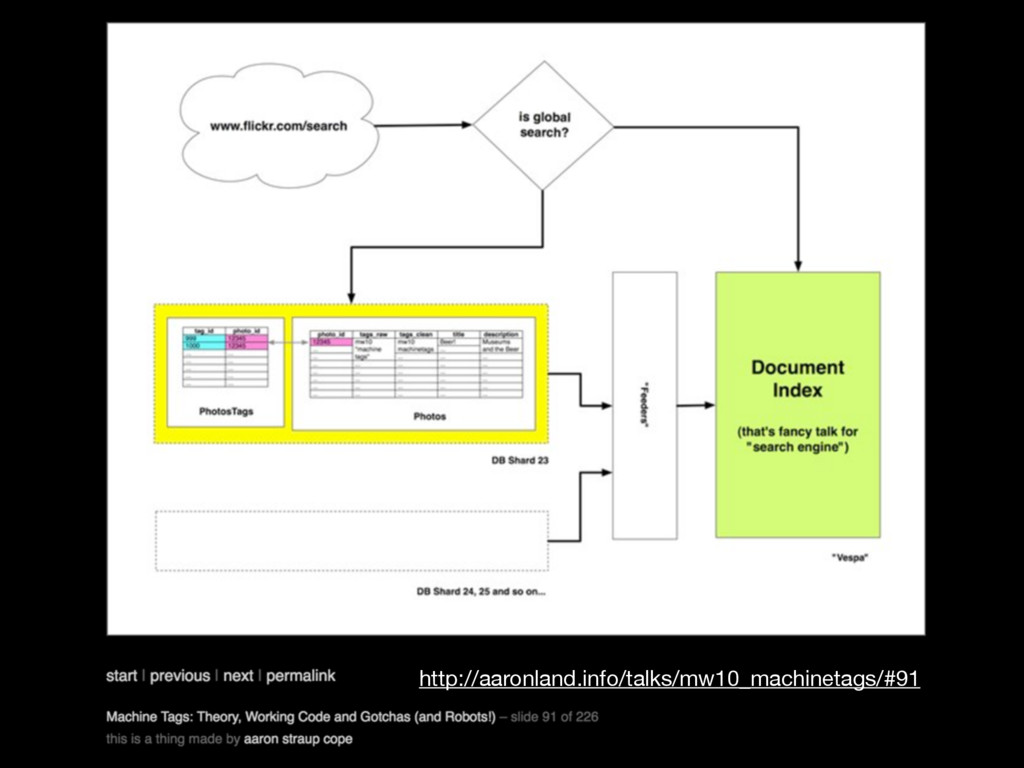{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}