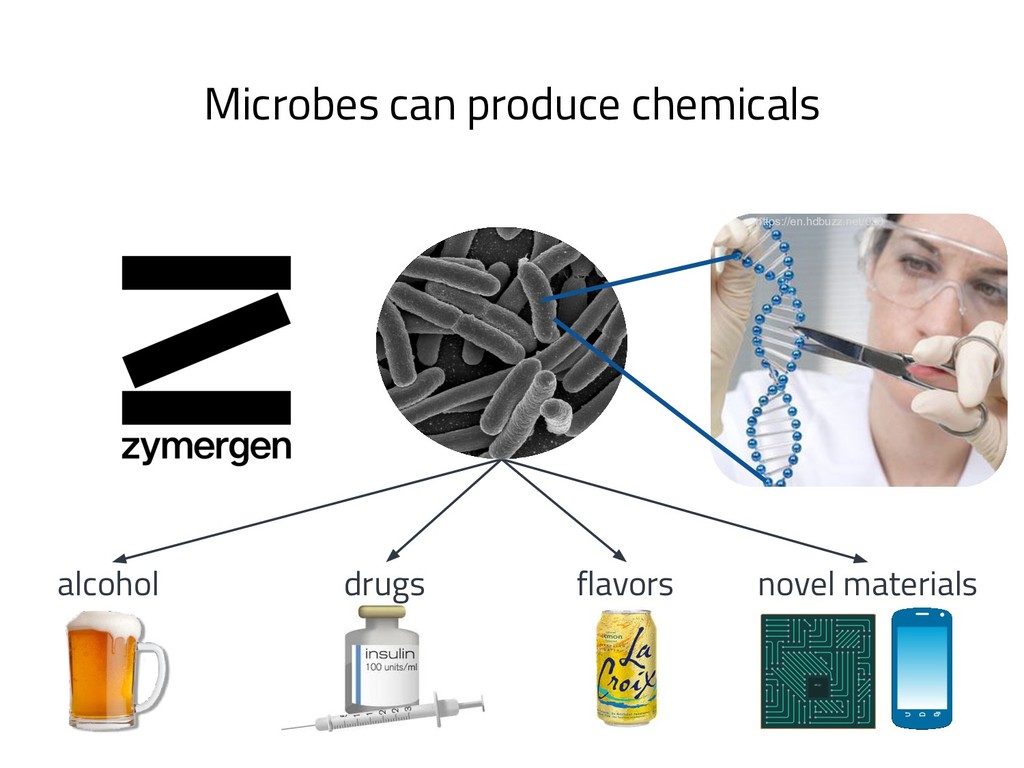
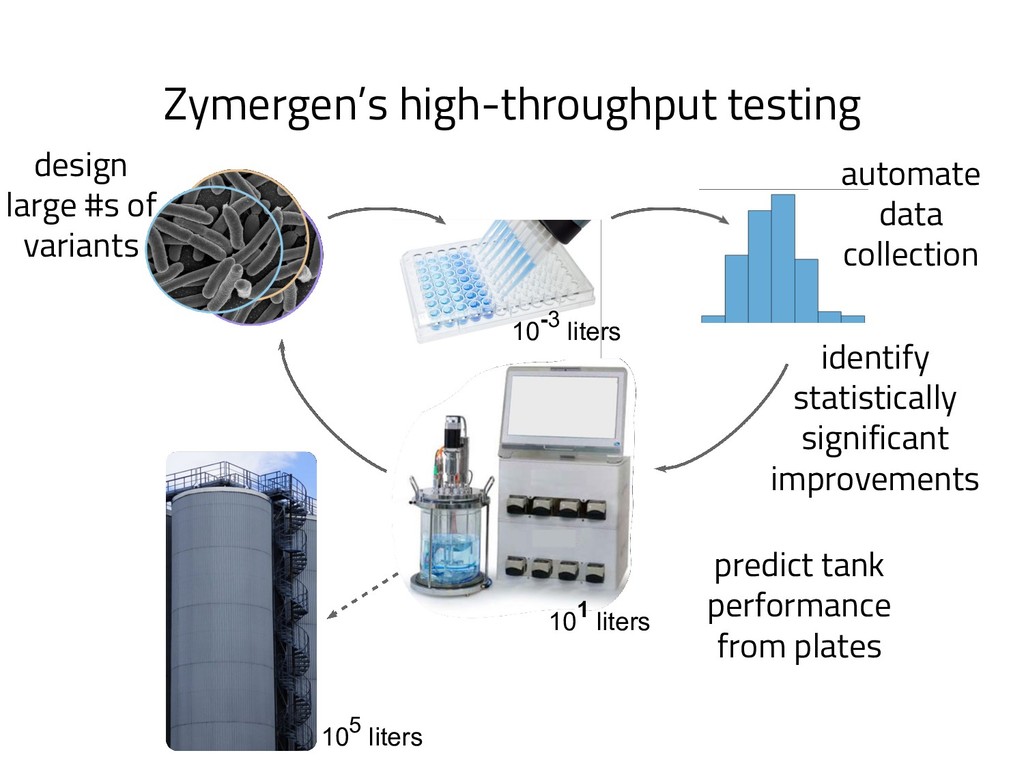
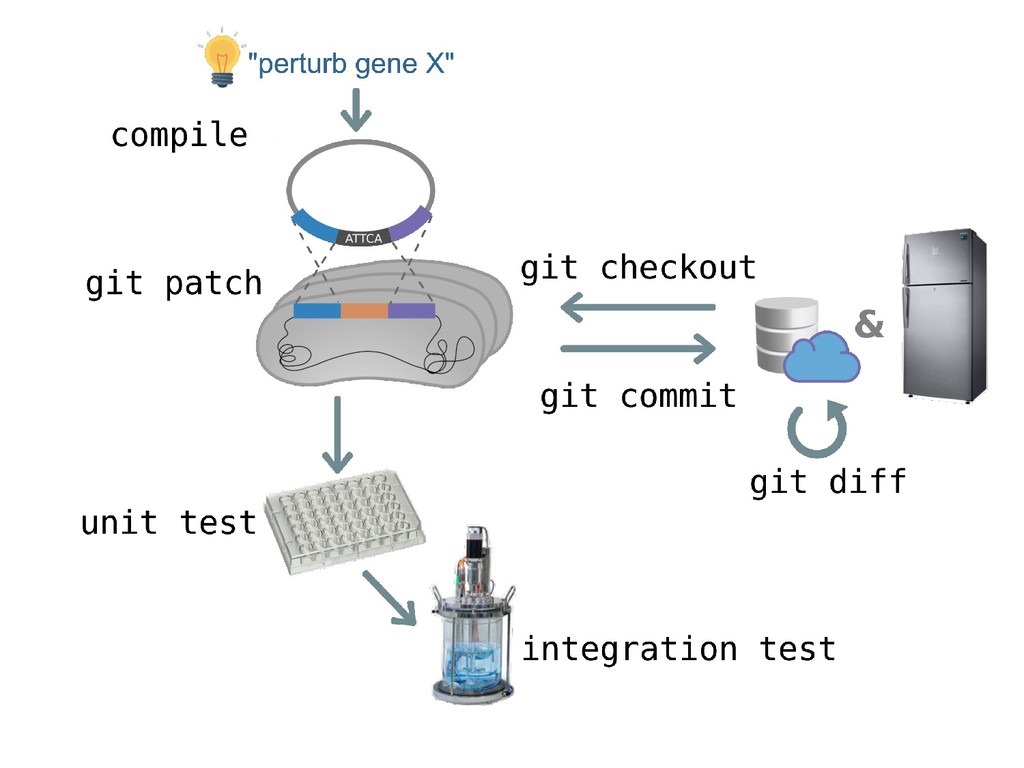
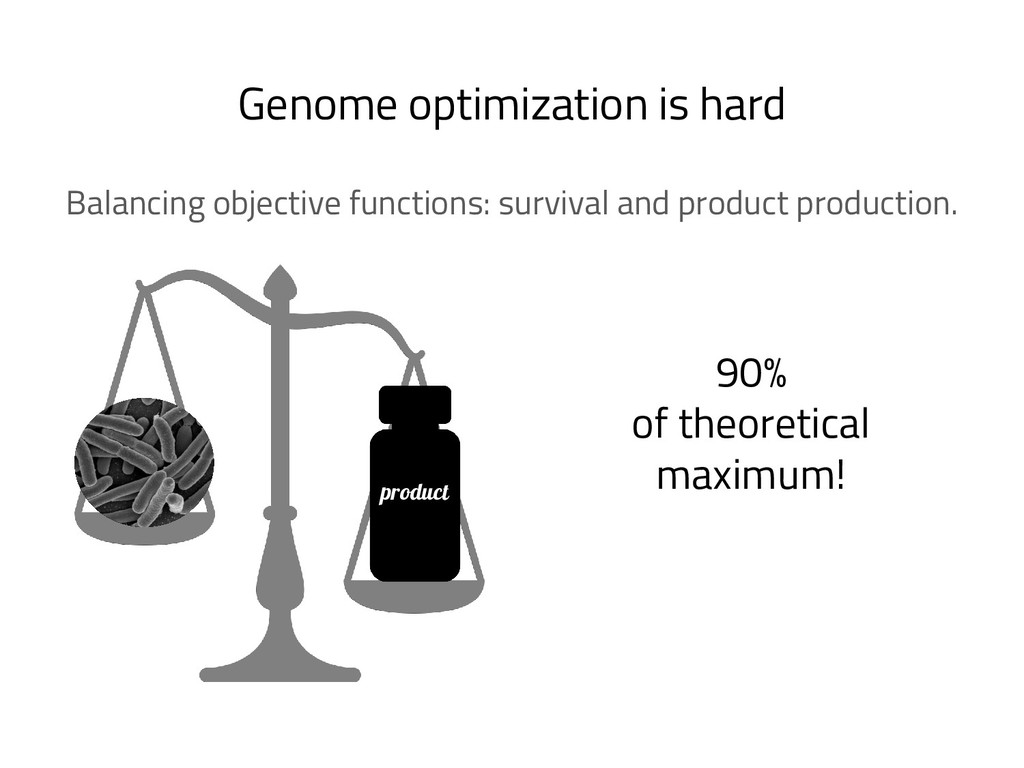
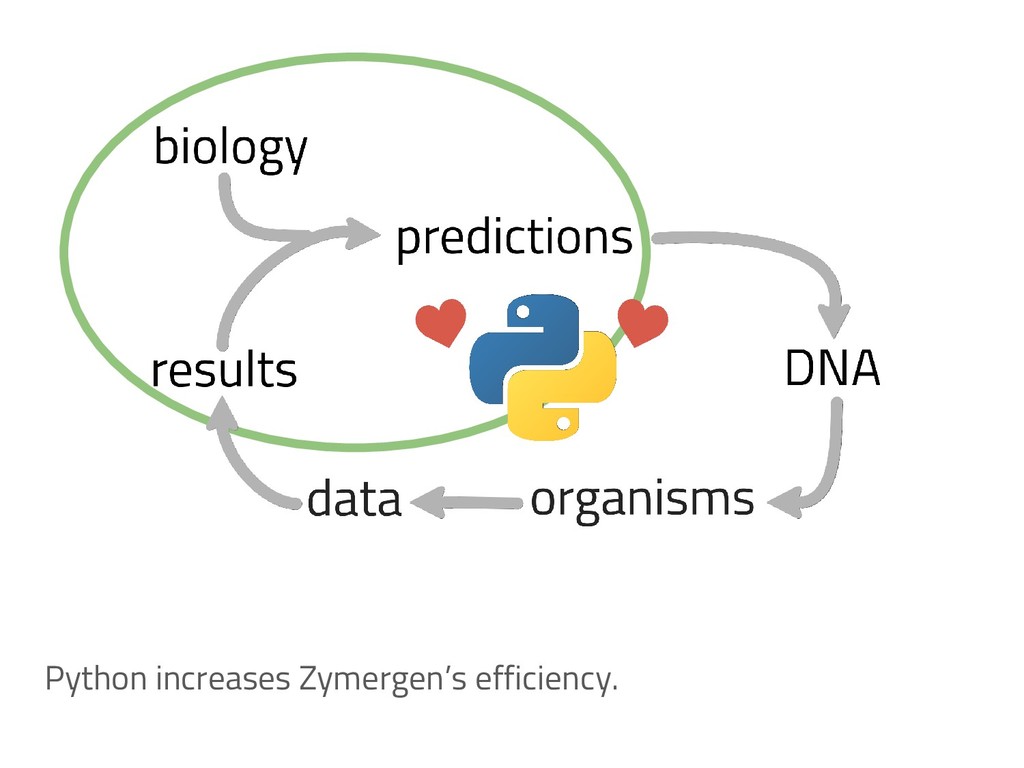
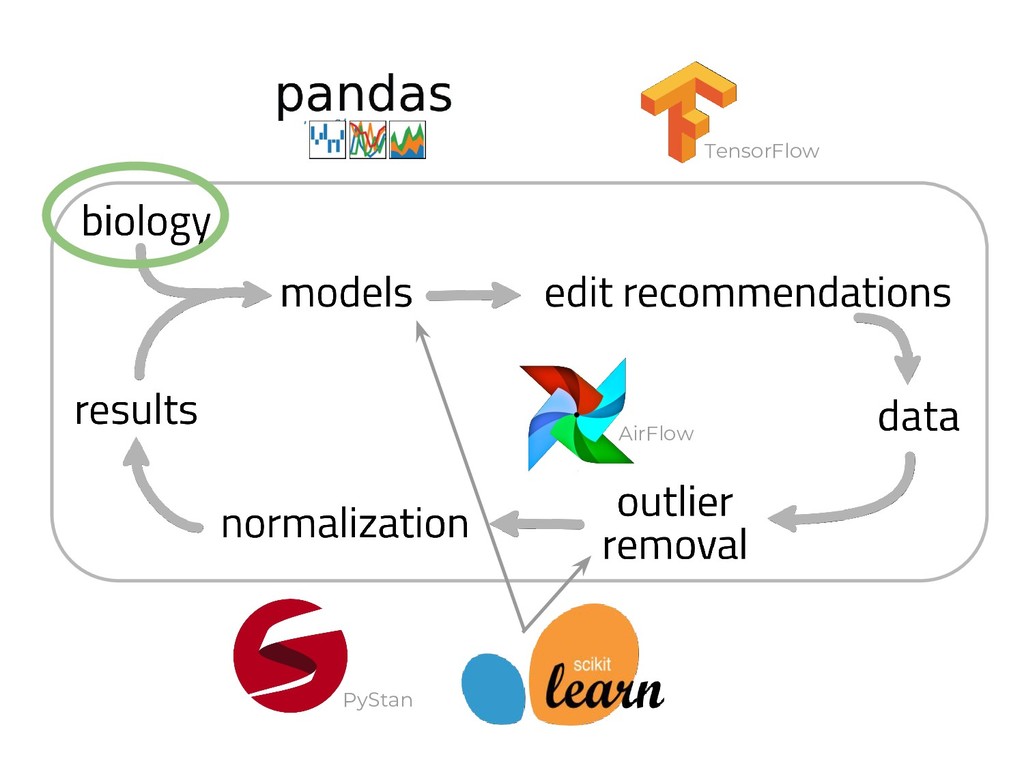
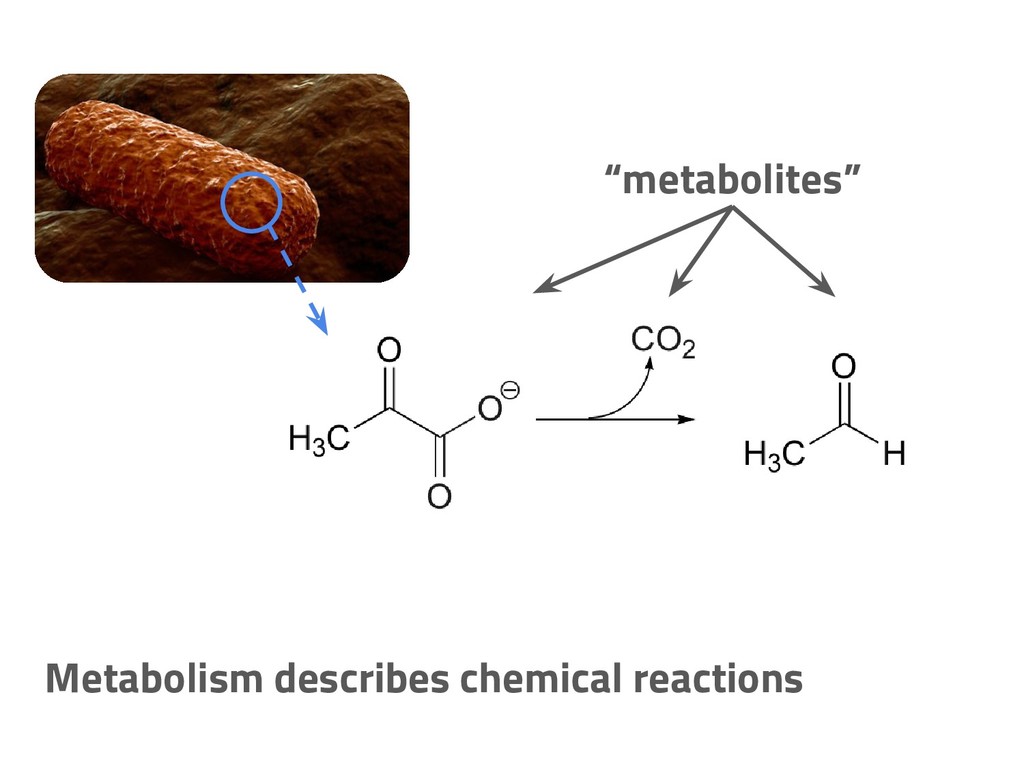
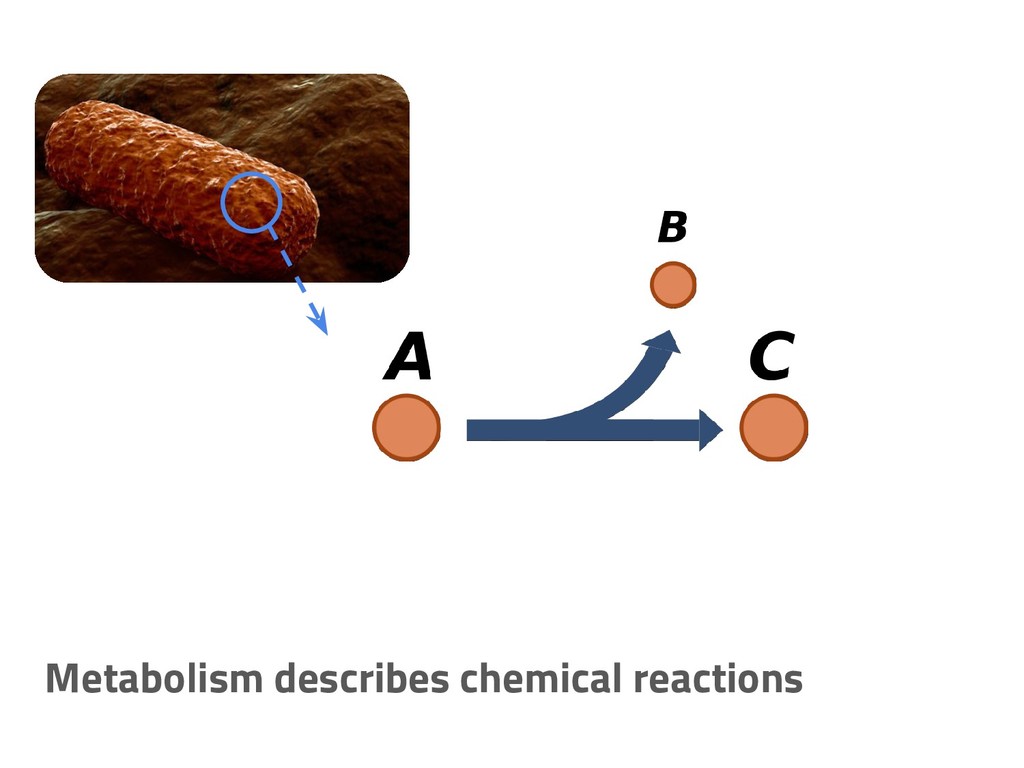
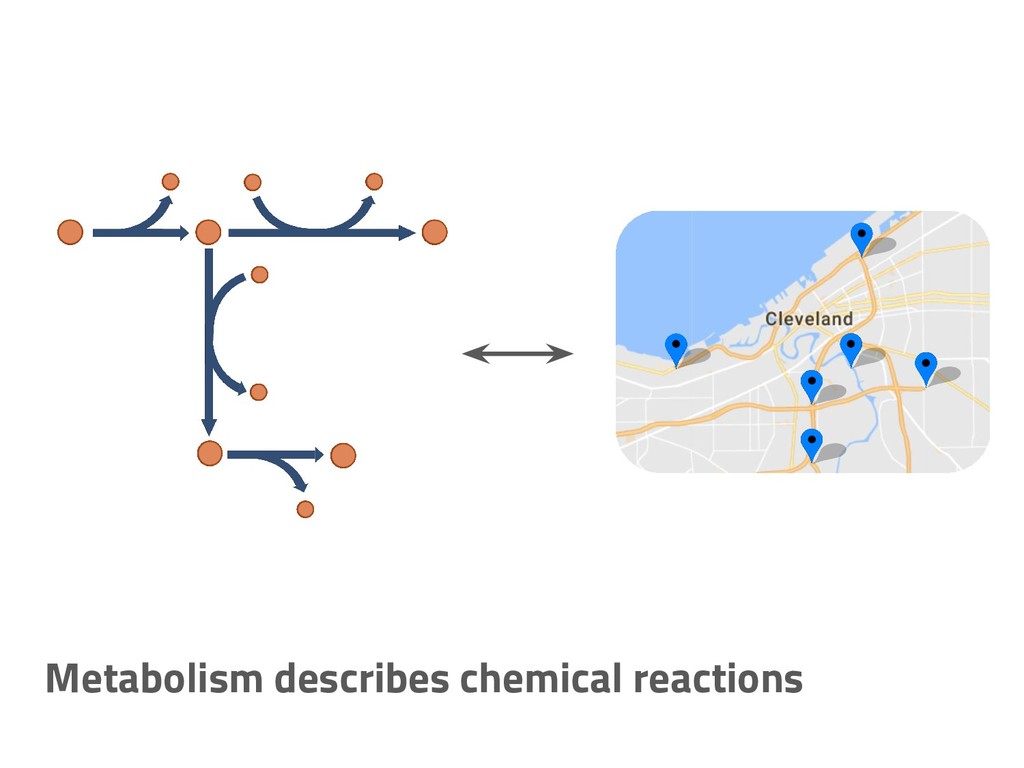
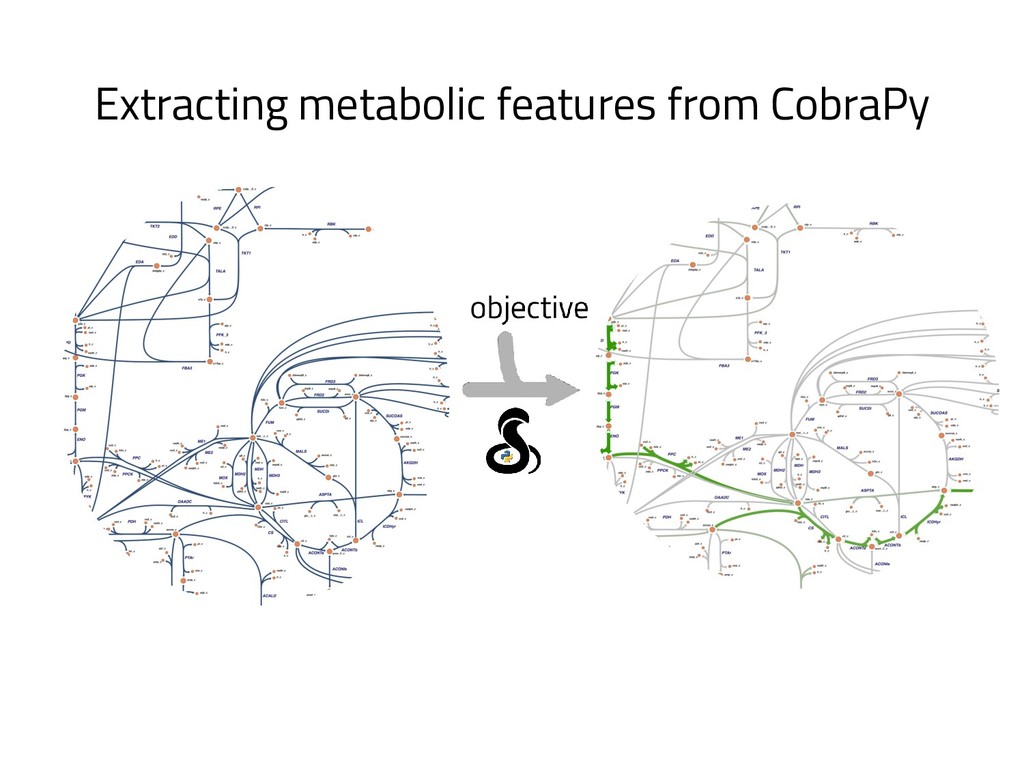
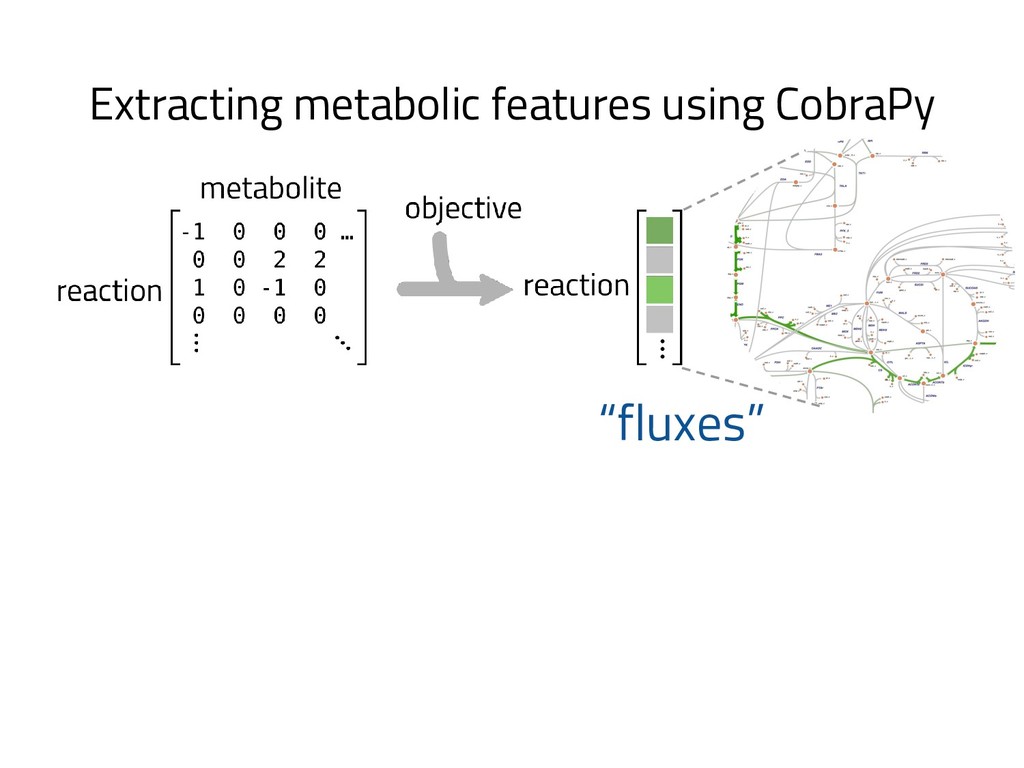
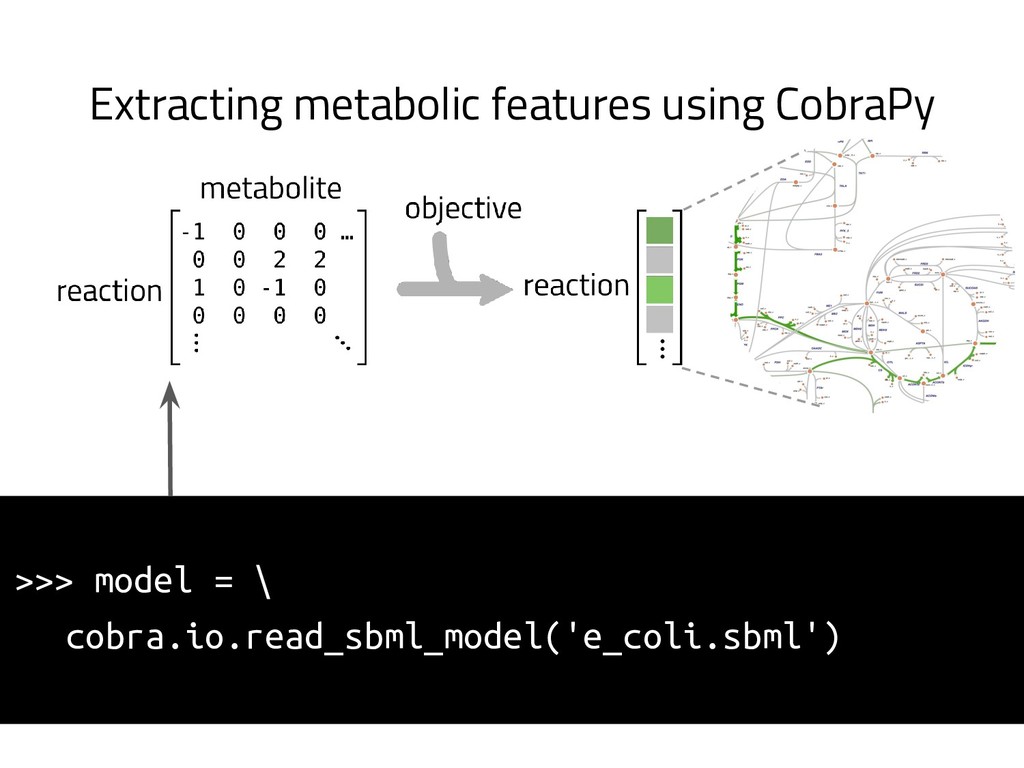
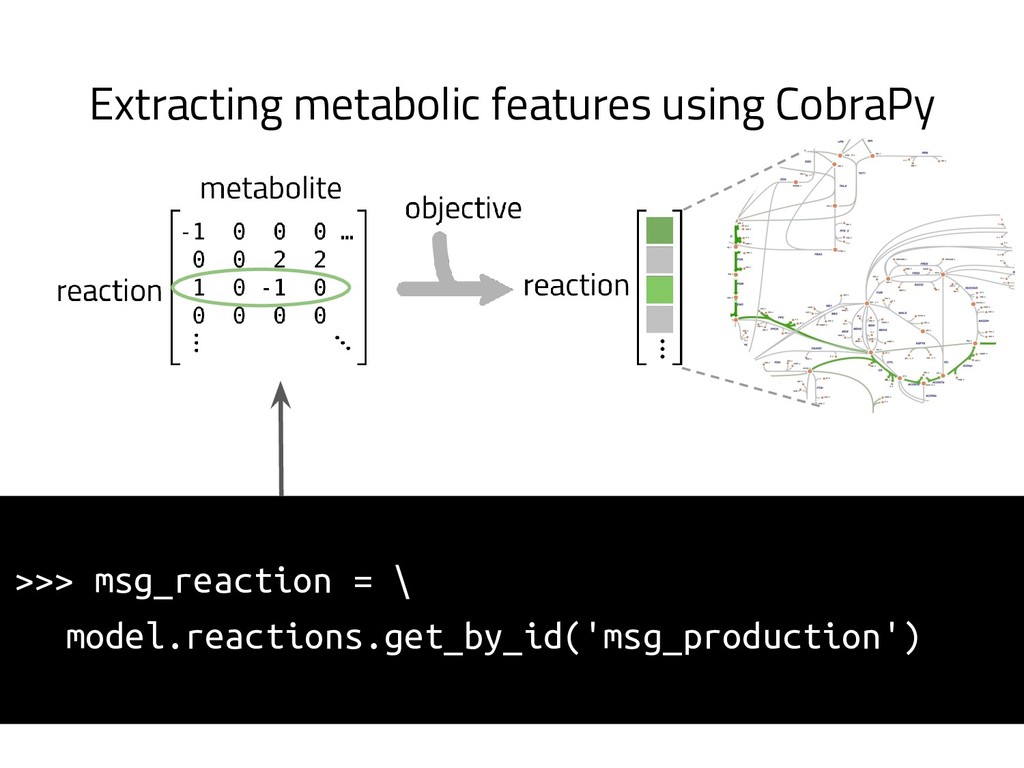
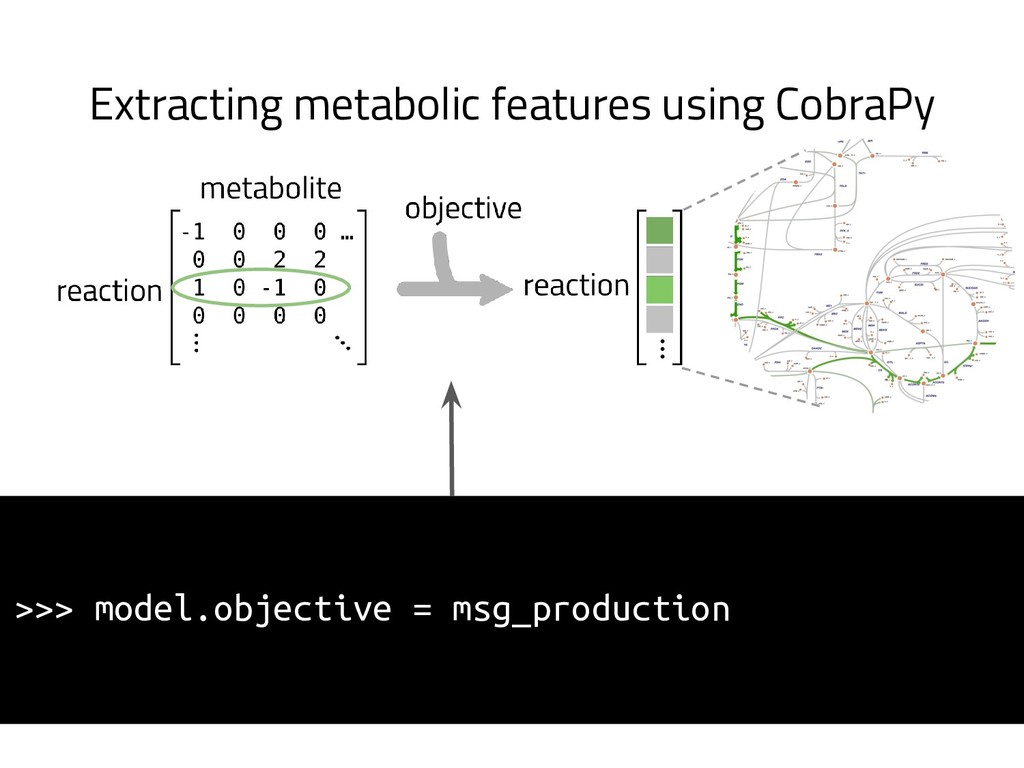
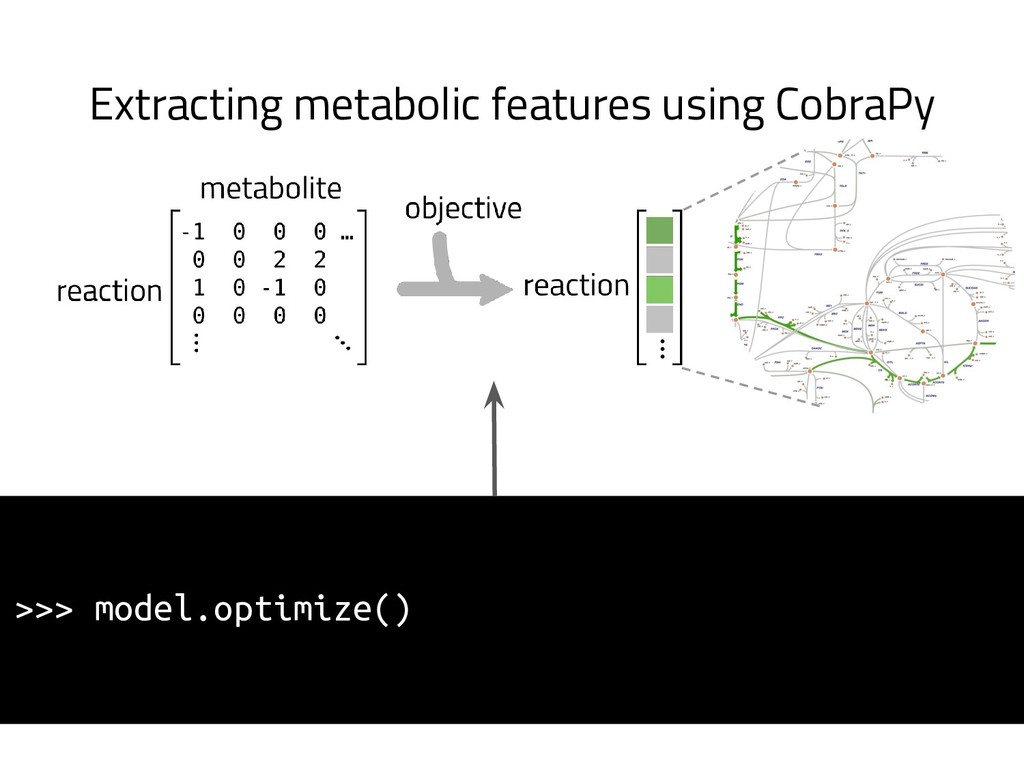
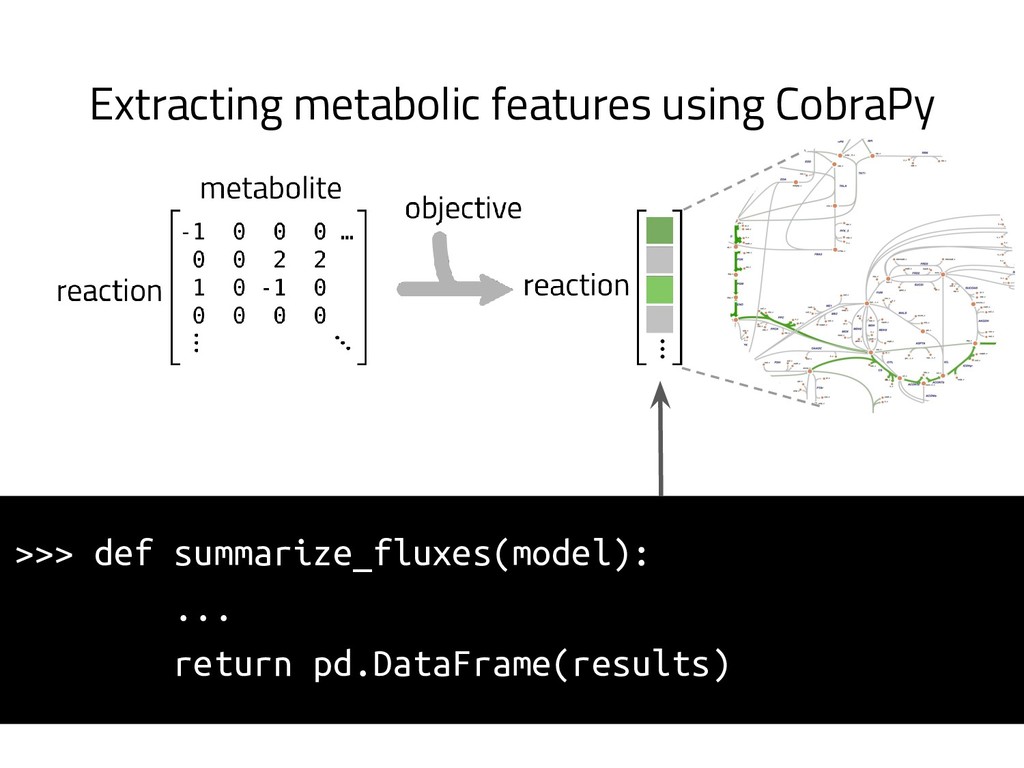
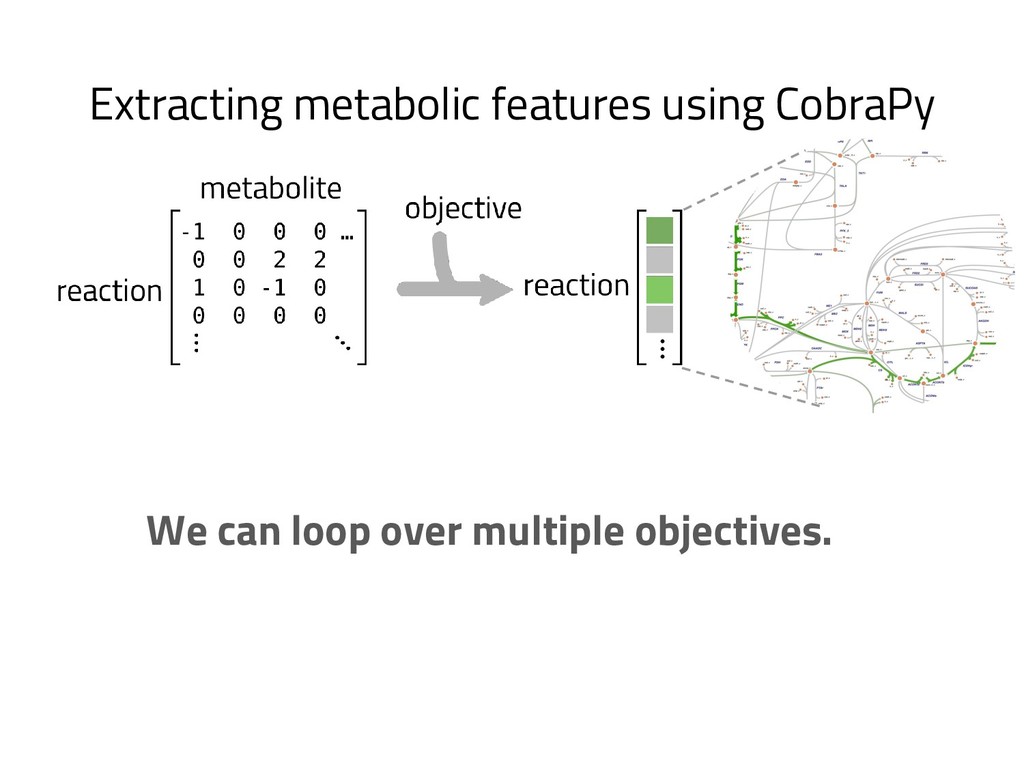
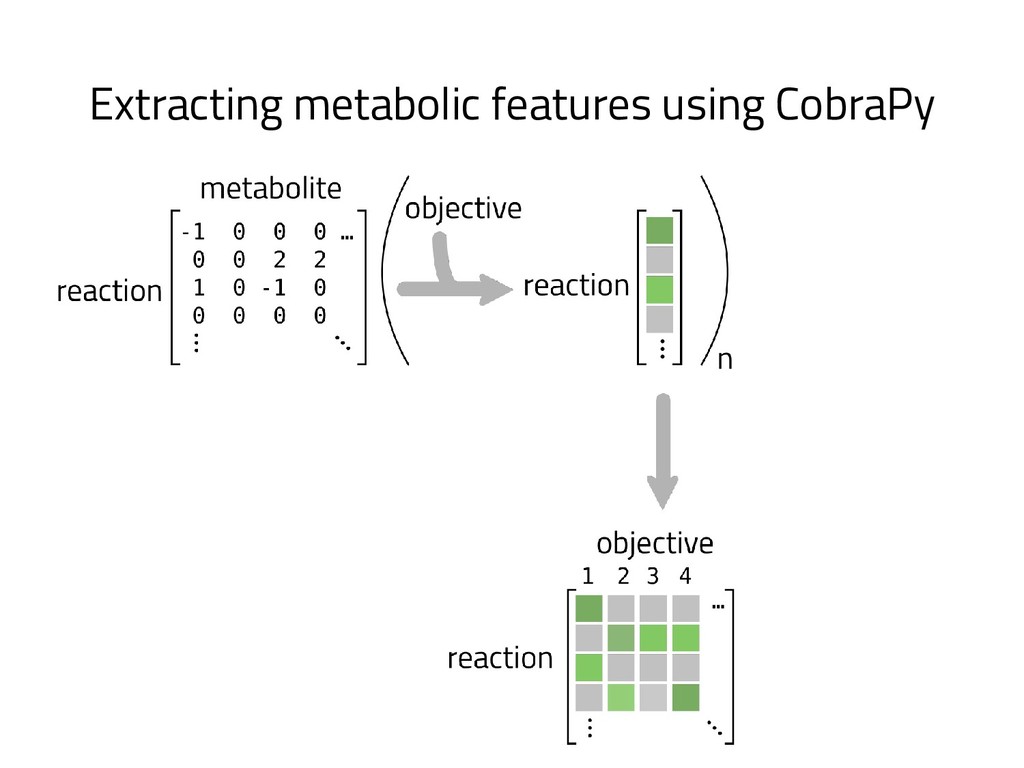
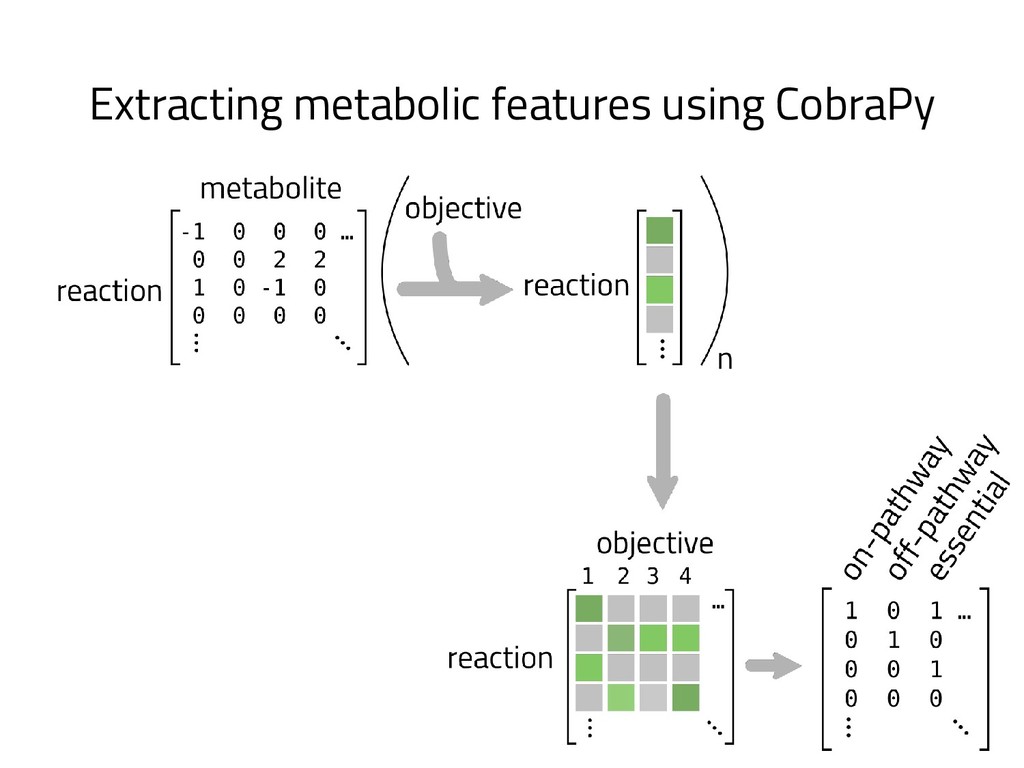
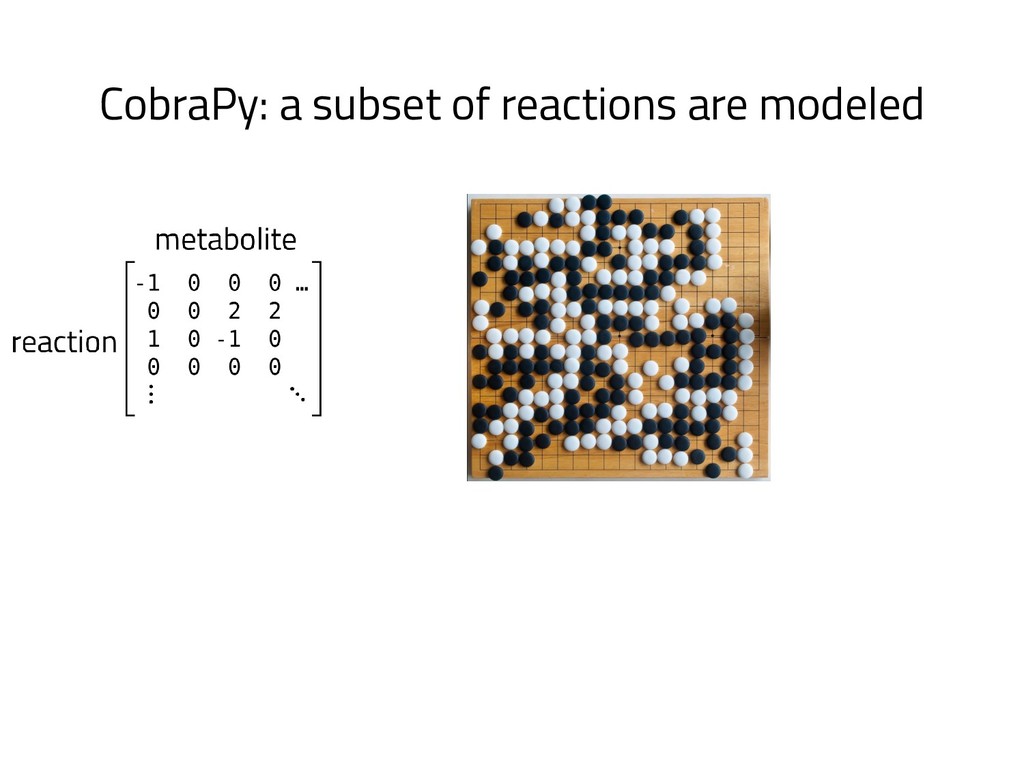
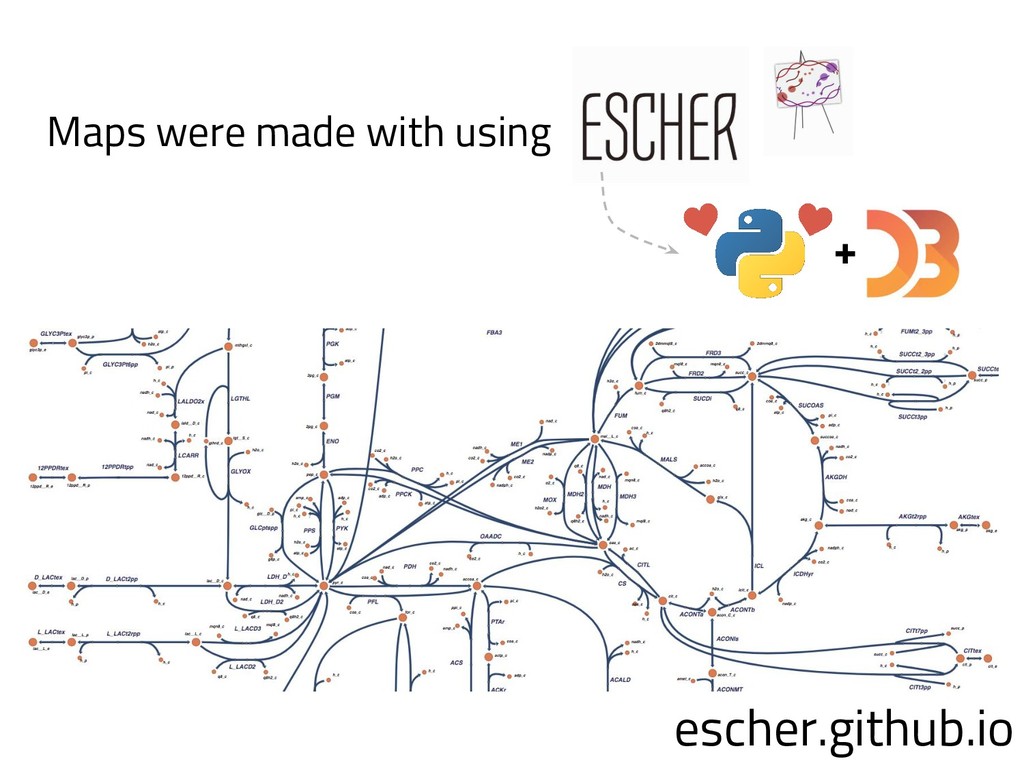
The genome of a typical microbe contains roughly 5 million base pairs of DNA including > 4000 genes, which provide the instructions for cellular replication, energy metabolism, and other biological processes. At Zymergen, we edit DNA to design microbes with improved ability to produce valuable materials and molecules. Microbes with these edits are built and tested in high throughput by our fleet of robots. Genomes are far too large for exhaustive search, so identifying which edits to make requires machine learning on non-standard features. Our task to extract information from trees, networks, and graphs of independently representable knowledge bases (metabolism, genomics, regulation), in ways that respect the strongly causal relationships between systems. In this talk, I will describe how we use Python’s biological packages (e.g. BioPython, CobraPy, Escher, goatools) and other packages (NetworkX, TensorFlow, PyStan, AirFlow) to extract machine learning features and predict which genetic edits will produce high-performance microbes.
https://us.pycon.org/2018/schedule/presentation/242/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}