Propaganda Detection in Fake News using Natural Language Processing
What is the real world basis for this problem?
Modern times have modern problems. And in India for the past few years we have seen a spike in mob incited violence and killings as a result of fake news spread through social media, messengers and even at times through legit news channels. Apart from educating the masses to identify fake and real news and not get carried away by propaganda, this problem also has a technology based solution. Fake news has already existed in the world, but social media, the fact that the world is so connected that it takes mere seconds for these to spread has exacerbated this issue. All the checks on a piece of news that can be done by a human, can be automated too. This paper aims at doing exactly that by checking with mainstream news agencies to verify the claims by extracting keywords and detecting propaganda using natural language processing libraries.
.
Why attend this talk?
This is a technical talk, but the underlying idea is one that almost anyone could identify with. The implementations and the technical know-how’s would be suitable for those even in the Beginner stages in their understanding of machine learning and natural language processing. This talk is to be taken as an example of how some societal/civic problems can be considered technology problems and solved. It also serves as an example in translating almost any such problem into a tech one, dividing it into steps and solving every mini problem to solve the whole.
The big idea!!!
What exactly is fake news? For the uninitiated, fake news is news that looks real, at times, and deludes people into believing it but is actually fake or modified to suit vested interests. Fake news has always existed in the world. Till the end of the cold war, fake news has existed, as either pro-Soviet or pro-America propaganda. Some fake news has political implications, affects trade deals and does result in affecting the life of the people living in the countries involved. This is an indirect effect though. In the 21st century with the widespread use of social media, instant messengers the effects are more dangerously direct. Fake news in the last few years have been used to slander communities, inciting violence, riots and even on occasion lynching and killing people. Fake news has also been used on social media to topple governments, swivel elections and build up mass perspective for and against individuals and organizations. This also means that for the modern world and democratic ideals to survive in today’s world the menace of fake news must be addressed.
There are a few characteristics that help a human differentiate fake news from the rest. A lot of the “fake news” containing messages shared on social media handles, have bad spellings and wrong grammar. A properly researched news article that has been taken from a credible news channel, paper or any other media is less likely to have any of these. Secondly, there would be no legitimate sources mentioned. And the keywords from the article, if searched for would result in either the news not existing, or skillfully modified to the interest of the maker. Images and videos are also not spared from these modifications with the usage of photo editing and video editing software in today’s world. Propaganda based fake news also generally either praises or criticizes individuals, communities or organizations. These characteristics can translate into a technical module, to predict whether a particular article is fake news or not.
Based on these very steps this proposal now describes how two major steps are implemented and integrated to accomplish this.
The first is to find out reliable sources for the piece of news. Here we can use the Rapid Automatic Keyword Extraction algorithm. It is based on the frequency of a particular word and the co-occurrence of these words, basically a n- gram based approach. The nltk rake algorithm takes care of all the stop words in the English language which consists of prepositions, articles and such. The RAKE algorithm also gives us ranked phrases which makes it easier to use the first “n” ranked phrases to search in a neutral, well established and reputed news aggregator API to find if there are any articles corresponding to these phrases. The second step is to find the similarity of the articles retrieved if any, and the fake news. This is done by comparing the fake news passage to the extract of sentences from the article containing the said keywords and using the SpaCy similarity feature to determine this.
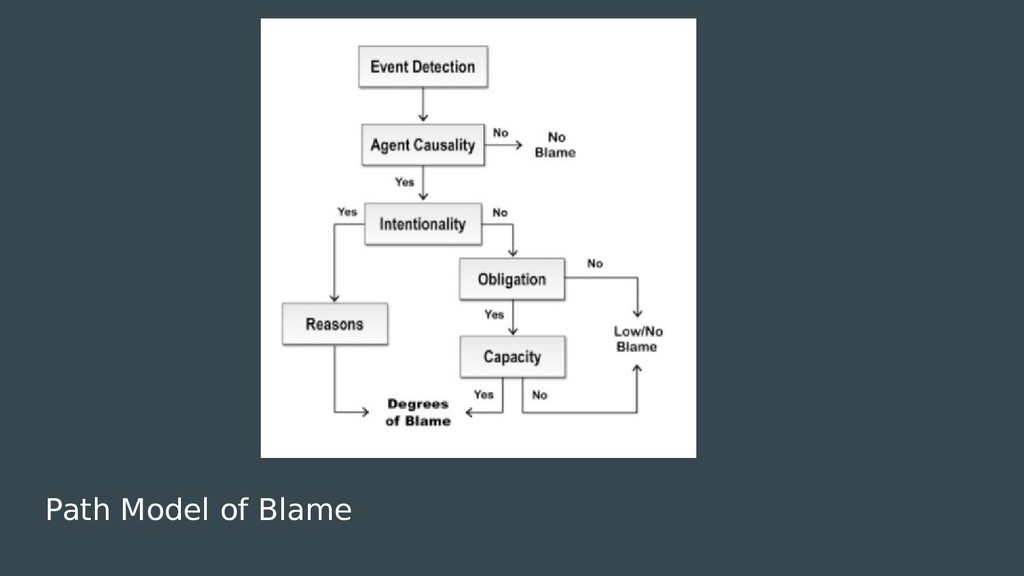
The second part is identifying propaganda and this is where I use the Path Model of Blame to determine if the news contains any propaganda both blame and praise. Apart from these propaganda can also be identified from the contents of the article.
Figure : Path Model of Blame
In order to quantify propaganda we can also quantify the data using parameters like
location (a town, a country),
labeling
argumentation
emotions (fear, outrage, sympathy, hatred, other, missing),
fabrication
politician (the name of a mentioned politician)
For the scope of this proposal we consider only two stages of the whole model. That is event detection and the agent implied by the text. This is done by extracting events from the article and then parsing them based on a pattern that can be fed in the parser as a mixture of regular expression and the Parts of Speech tagging by nltk.
Based on the thresholds defined for both the source finding with similarity and propaganda detection the article would qualify as a fake news article or not.
Progress so far...
Having run these models on a few of the popular fake news article, the systems have worked very well at times for some articles with a 100% accuracy, but this is not the case for all articles. This means that for cases that have failed miserable, a fine tuning of this module is necessary. Though the fake news detector is not an accurate system and should not be considered as such, fake news detection is definitely a technology problem and can be solved thus.
A lot of the problems in the modern world are technology problems and can be solved by using the tools we have built and have at hand.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}