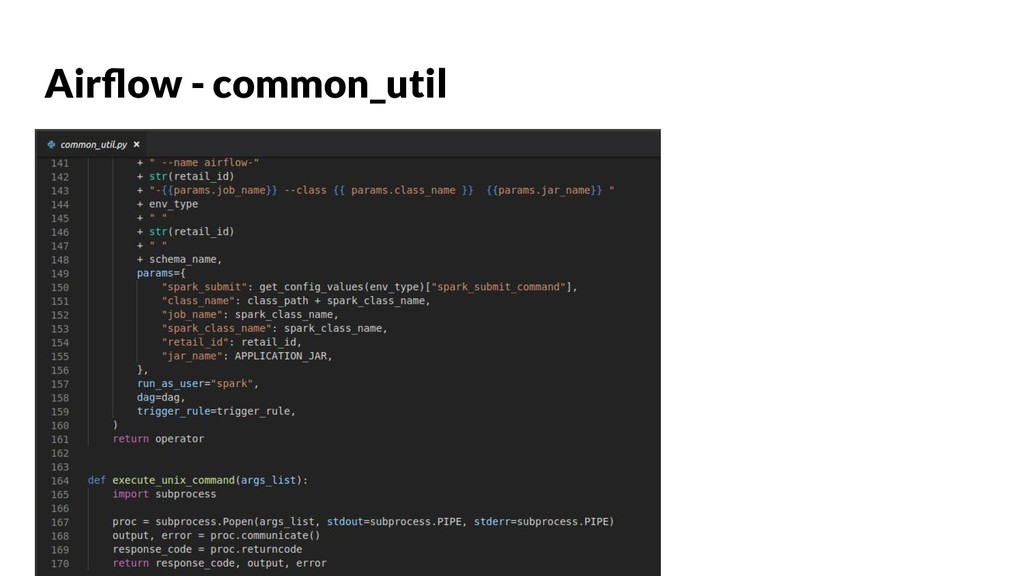
Spark is a good tool for processing large amounts of data, but there are many pitfalls to avoid in order to build large scale systems in production, This talk will take you through fundamental concepts of Apache Spark for Python Developers. We'll examine some of the data serialization and interoperability issues specifically with Python libraries like Numpy, Pandas which are highly impacting PySpark performance. We will address this issue with Apache arrow (PyArrow API) which is a cross-language development platform for in-memory data. This talk will show what the challenges you may face while productionizing Spark for TB’s of data and their possible solutions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
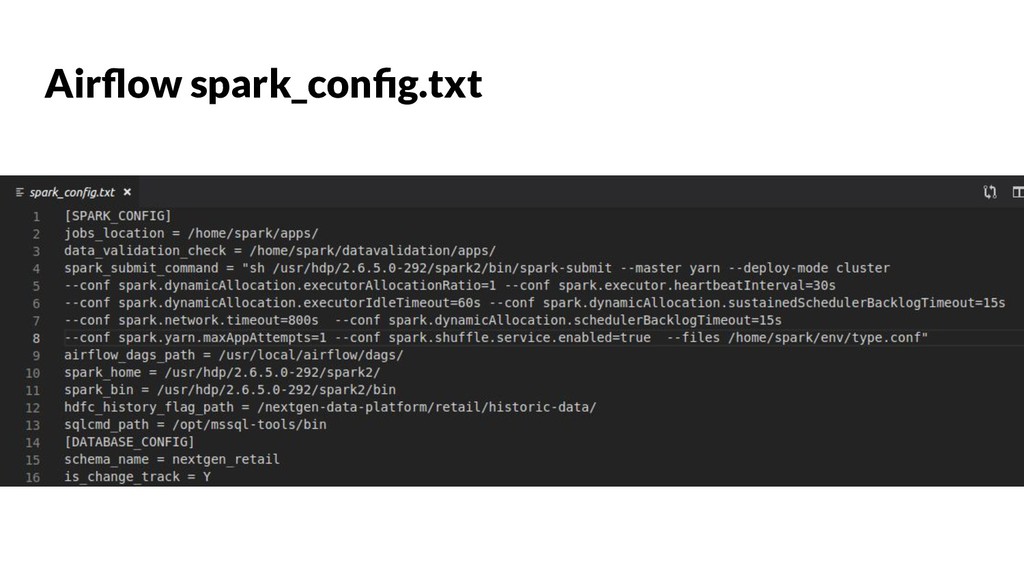{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
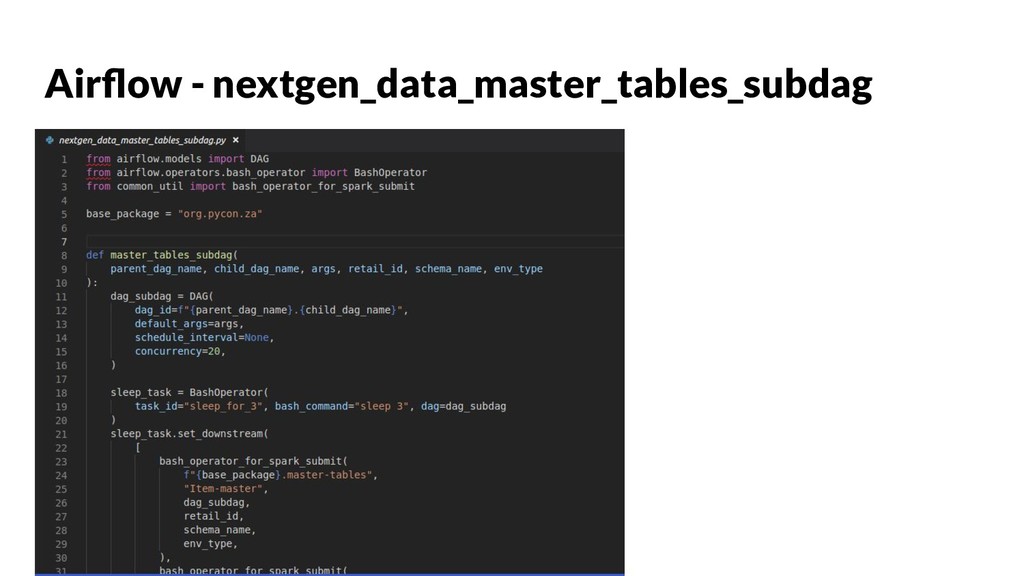{kind=link}
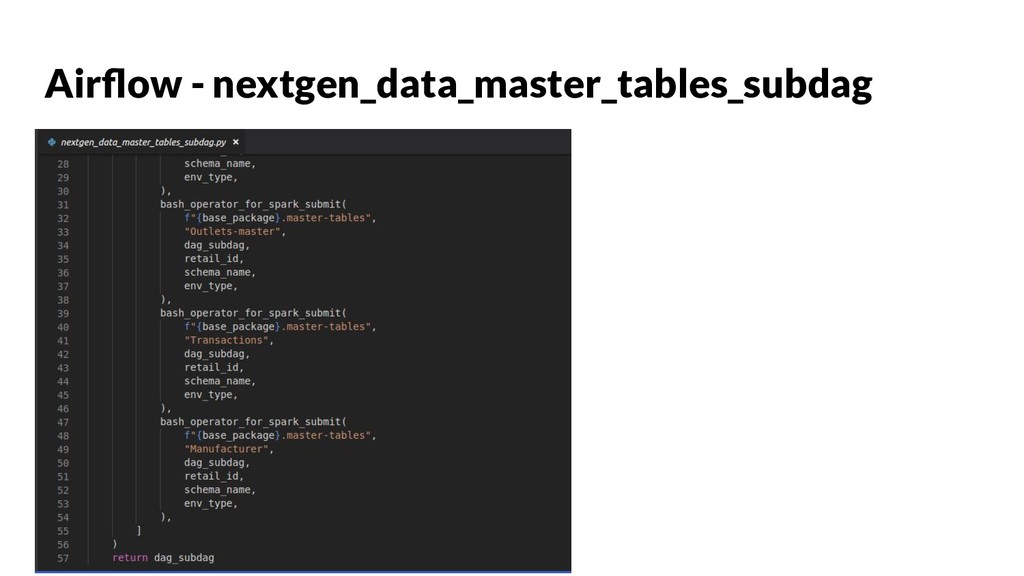{kind=link}
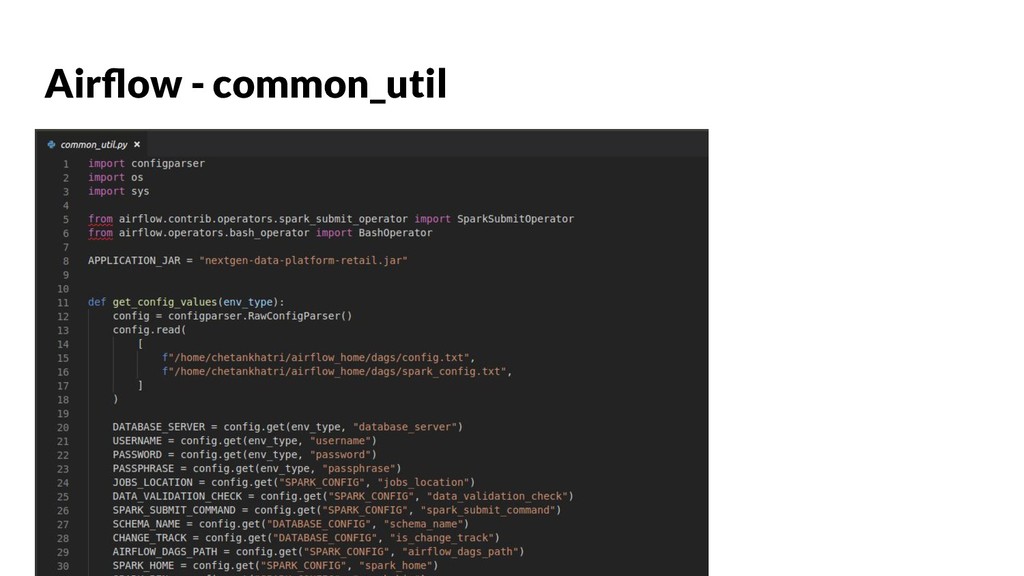{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References [1] How to Setup Airflow Multi-Node Cluster with Celery](https://files.speakerdeck.com/presentations/e35e82518e0e411494a7978fbdc1bb61/slide_80.jpg){kind=link}
{kind=link}
{kind=link}