So I’ve heard that there are only two hard things in Computer Science: cache invalidation, naming things, and off-by-one errors. Perhaps they are right.
In this talk, I’m going to tell a story of how we got caught out by a somewhat naive approach to caching ... or, to be more honest, a series of naive approaches to caching. It is my hope that by listening to my sorry tale, you will be introduced to some of the key concepts that will allow you to avoid our fate.
More specifically, I’m going to talk about our experience at St James Software working with in-process caches, and then with inter-process caching using Python and memcached. Along the way, I will introduce a couple of different caching strategies, including time-based and least-recently-used, and, of course, will devote some time to the perils of cache invalidation.
Finally, I will take a small diversion to discuss some pitfalls that you should watch out for, if and when you choose to add a new application to your solution.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![del self.cache[username]](https://files.speakerdeck.com/presentations/587d66a01eb20131141752618285faa3/slide_11.jpg){kind=link}
{kind=link}
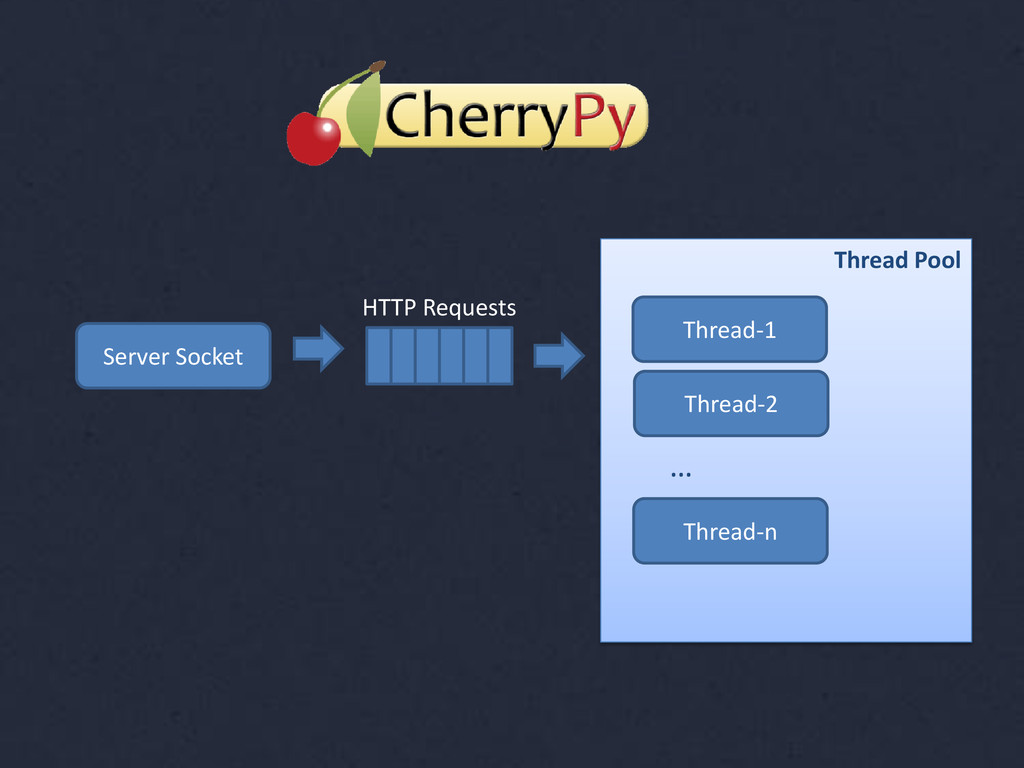{kind=link}
{kind=link}
{kind=link}
{kind=link}
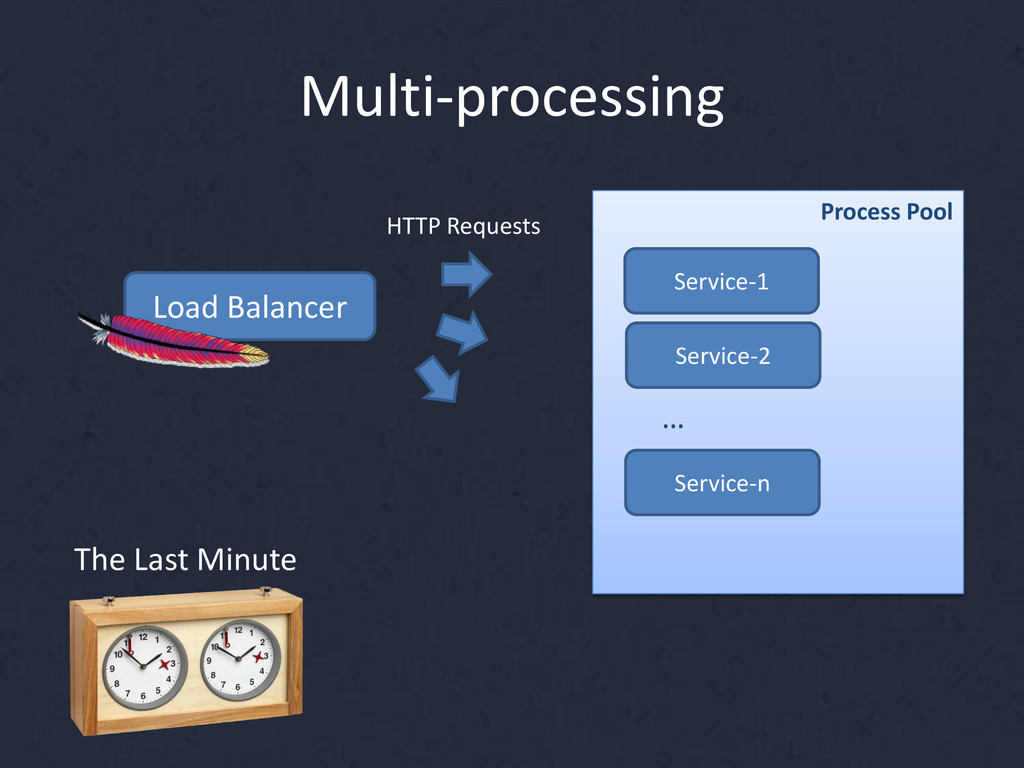{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
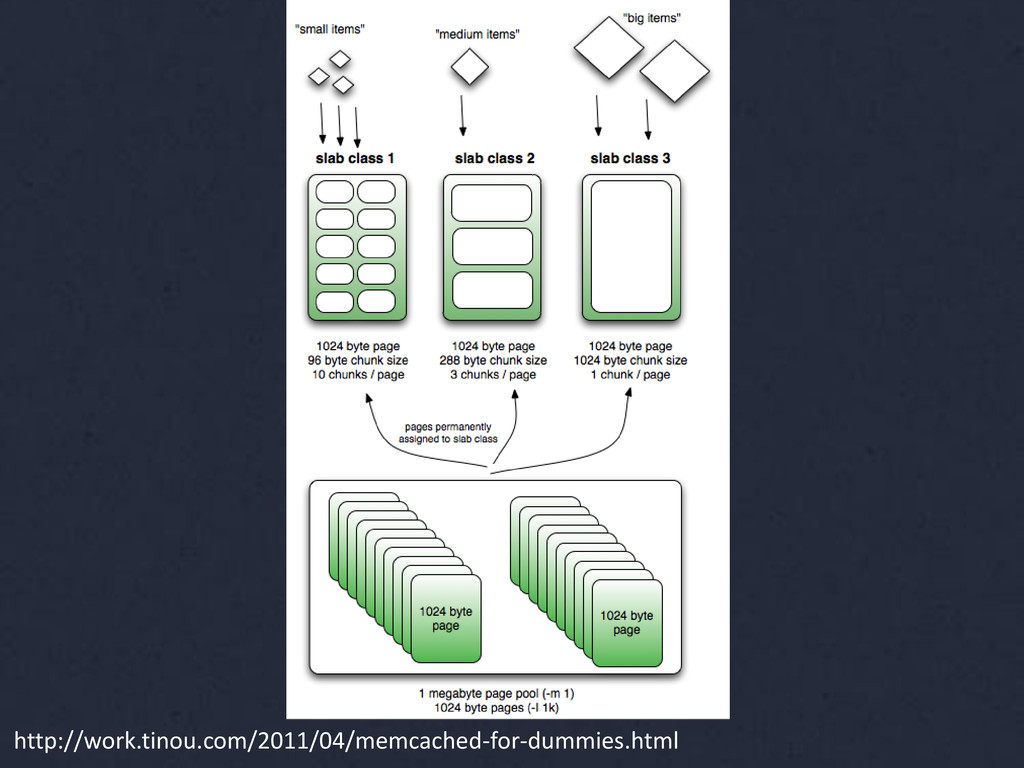{kind=link}
{kind=link}
{kind=link}
{kind=link}
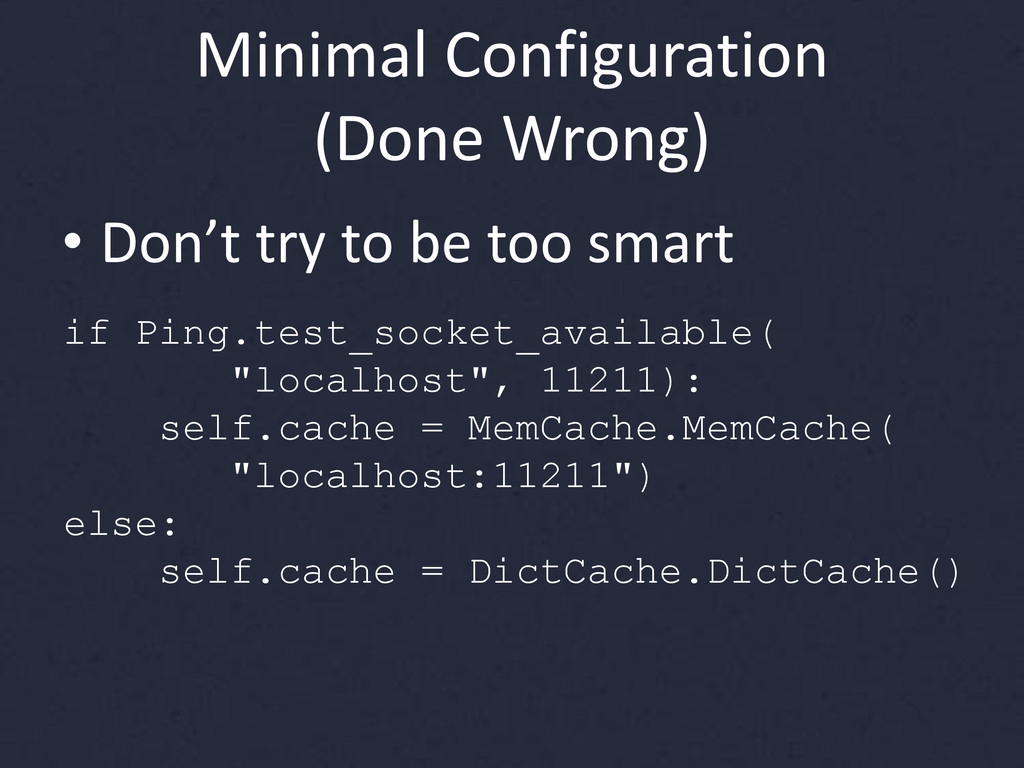{kind=link}
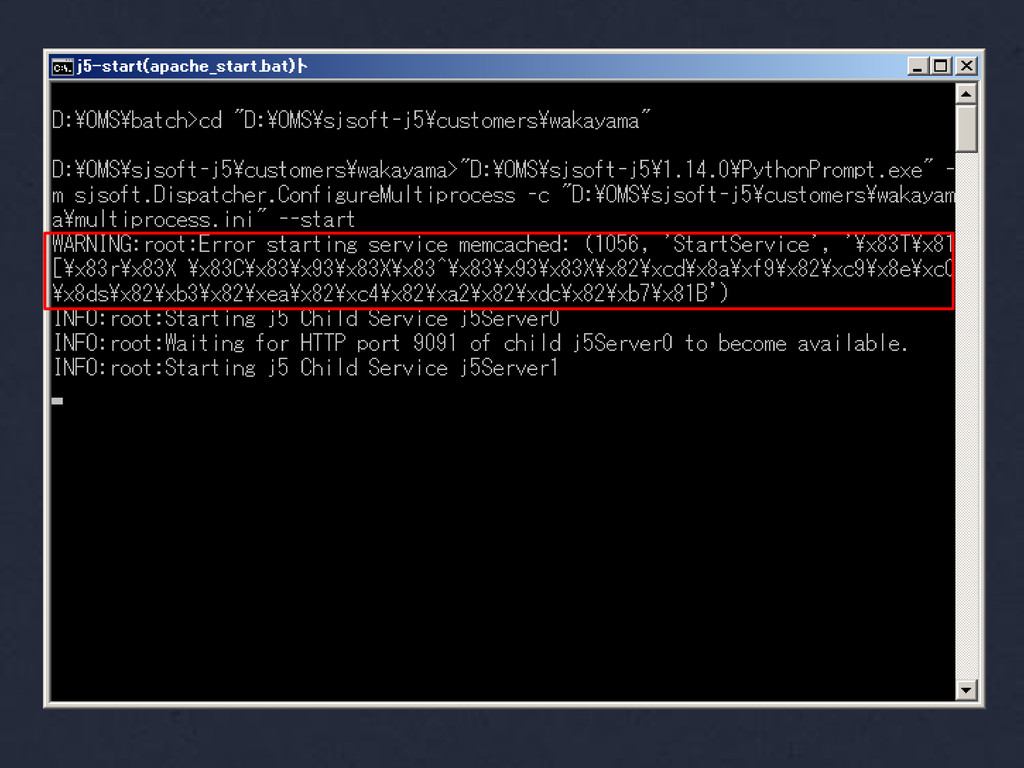{kind=link}
{kind=link}
{kind=link}
{kind=link}
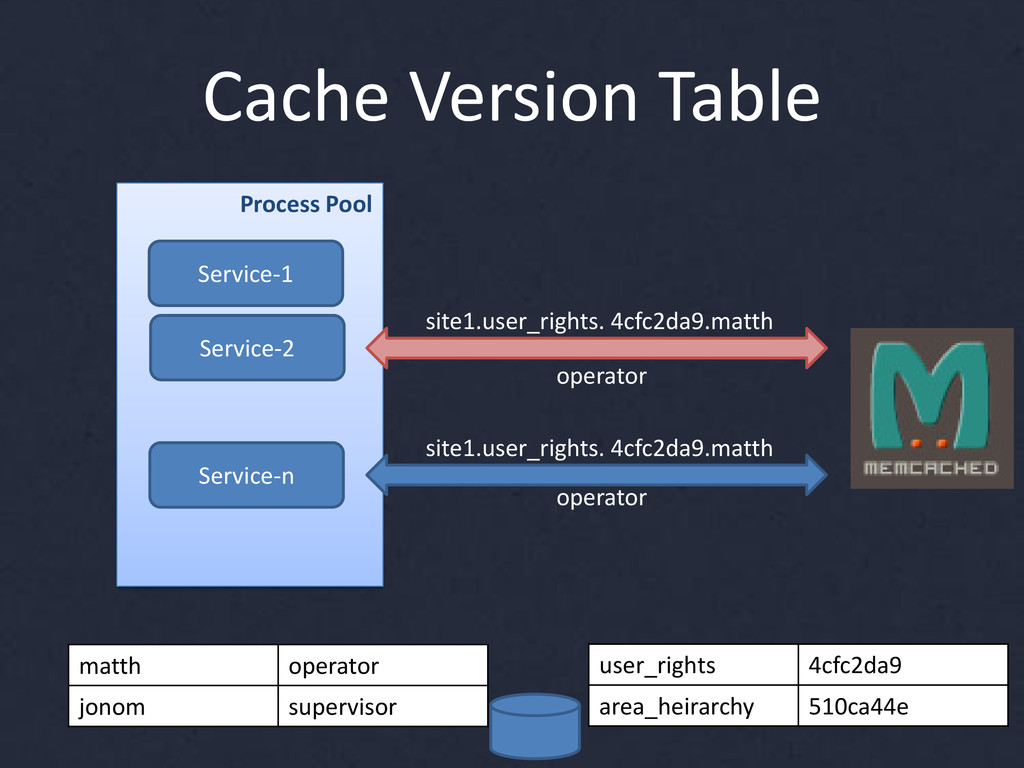{kind=link}
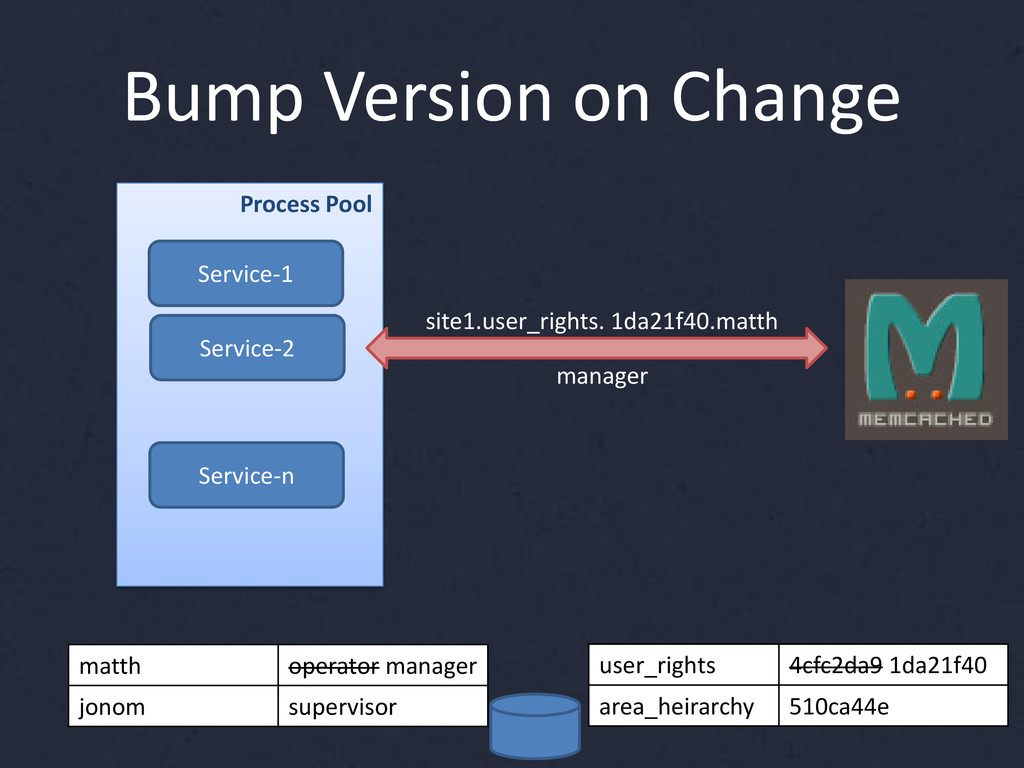{kind=link}
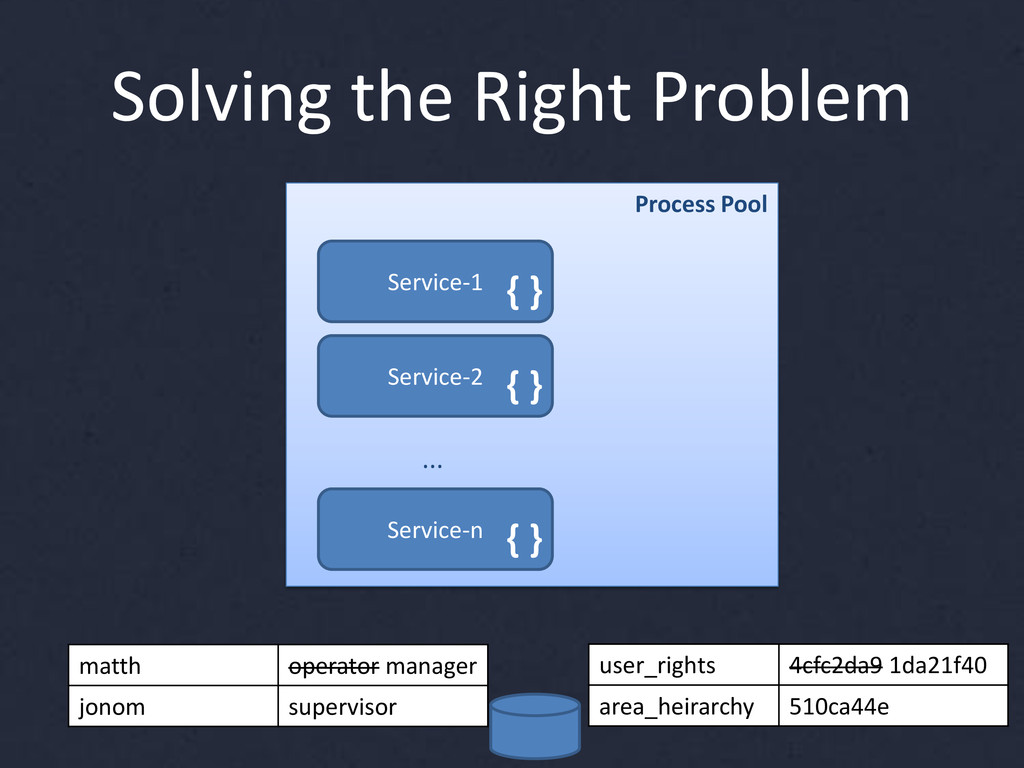{kind=link}
{kind=link}
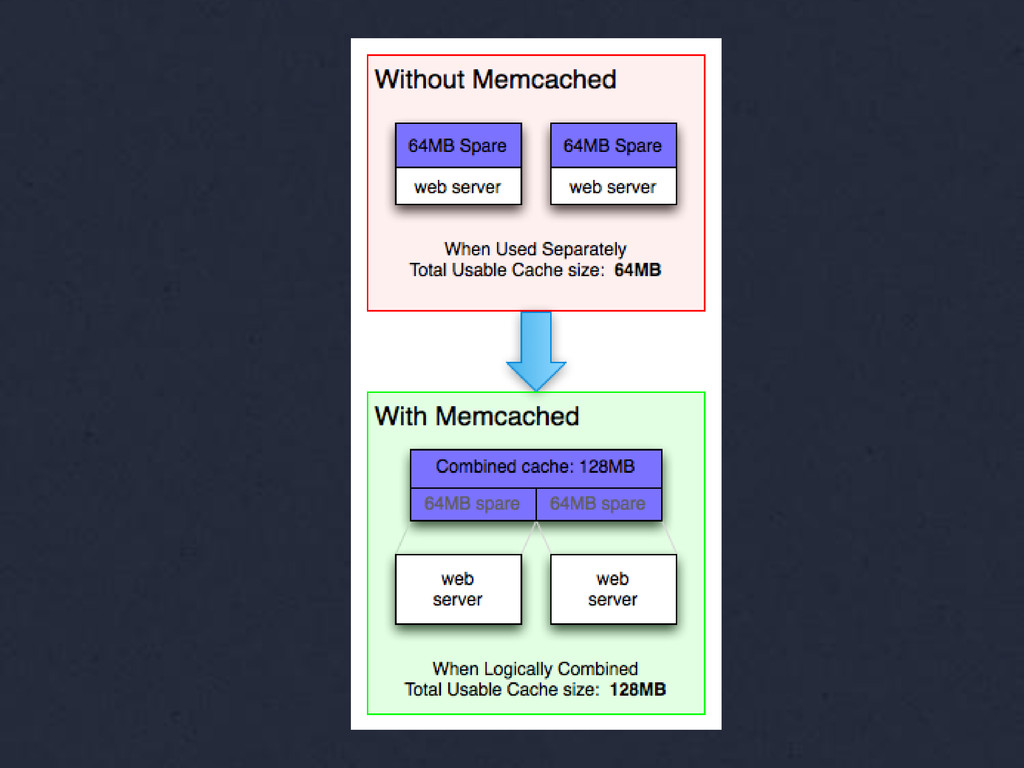{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}