Often the data you want is available somewhere on the internet. It might all be on one page (if you're lucky!) or distributed across many pages (possibly hundreds or thousands of pages!).
But you want those data consolidated locally. Not on a server in some distant land, but right here on your hardware. And in a convenient format. CSV or JSON, perhaps? Certainly not HTML!
What would Ragnar do? He'd go out, grab those data and bring them home.
The contemporary Internet Viking uses Web Scraping techniques to systematically extract information from web pages. This tutorial will demonstrate the process of web scraping. This is the battle plan:
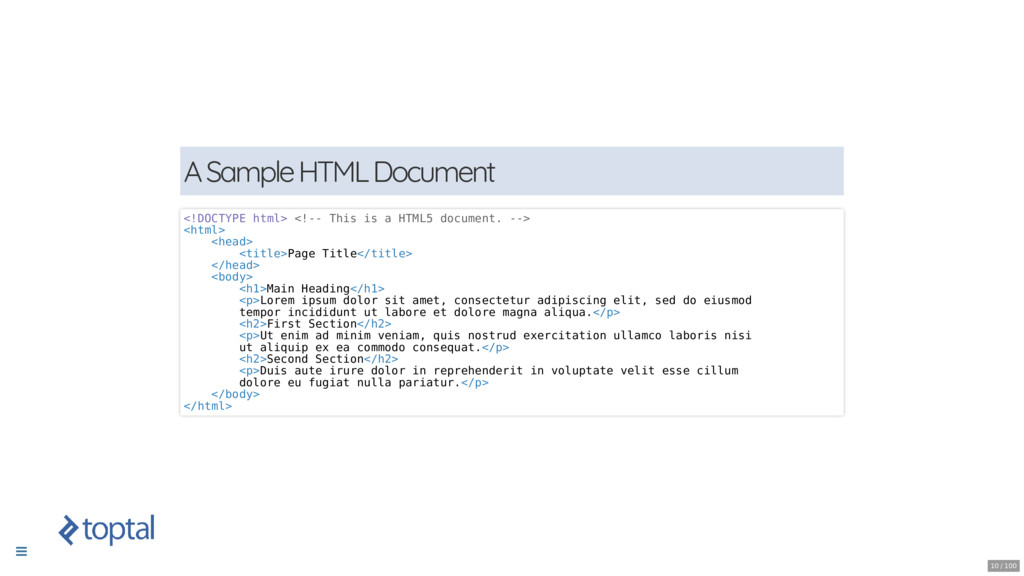
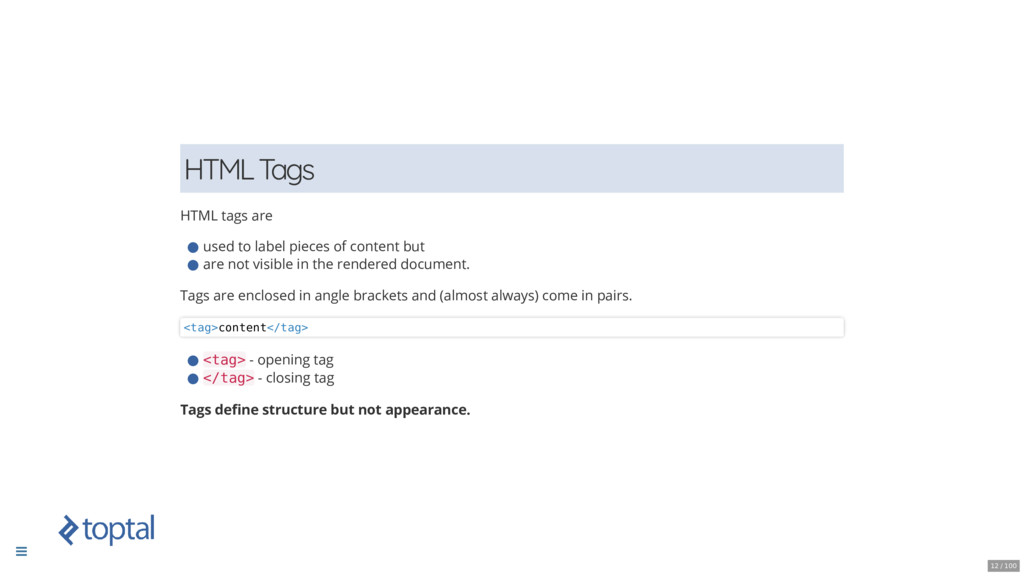
* Sharpening the Axe: Understanding of the structure of a HTML document.
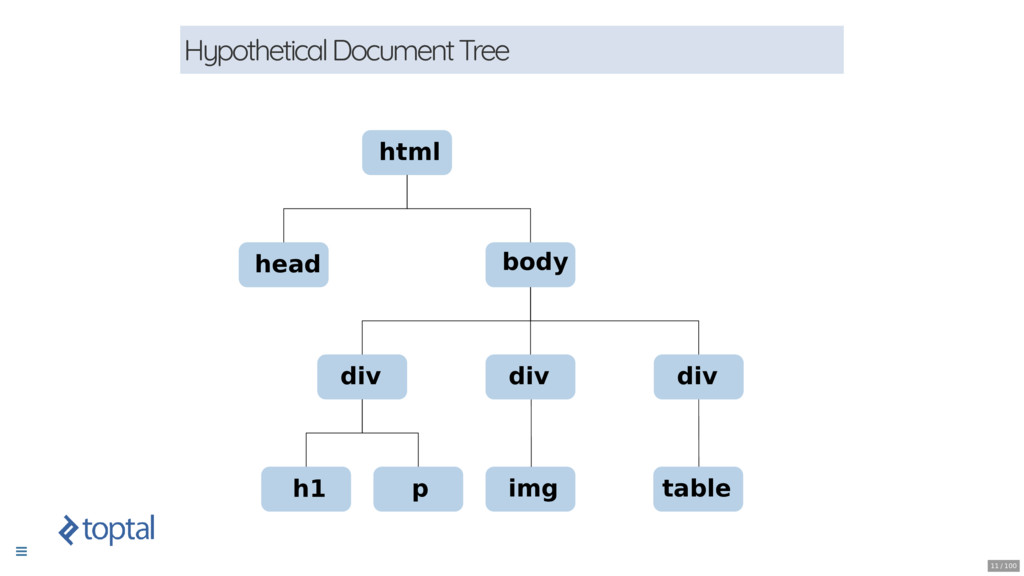
* Preparing the Longships: Using the DOM to select HTML elements.
* Doing Battle: Manual extraction of data from a HTML document.
* Stashing the Treasure: Storing data as CSV or JSON.
* The Journey Home: Automated scraping with Scrapy.
* Triumphant Return: Driving a browser using Selenium.
The first two components will be fairly brief, covering this material at a high level. We'll dig much deeper into the latter topics.
By the end of the tutorial you should be able to easily (and confidently) pillage and plunder large swathes of the internet.
Come along and make Ragnar proud. Tyr! Odin owns you all!
This tutorial will be suitable for Vikings with low to moderate levels of Python experience.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Attributes /* Matches <a> with a class attribute. */ a[class]](https://files.speakerdeck.com/presentations/d31adbedf8fb4da8a15ea3dd7fe85639/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}