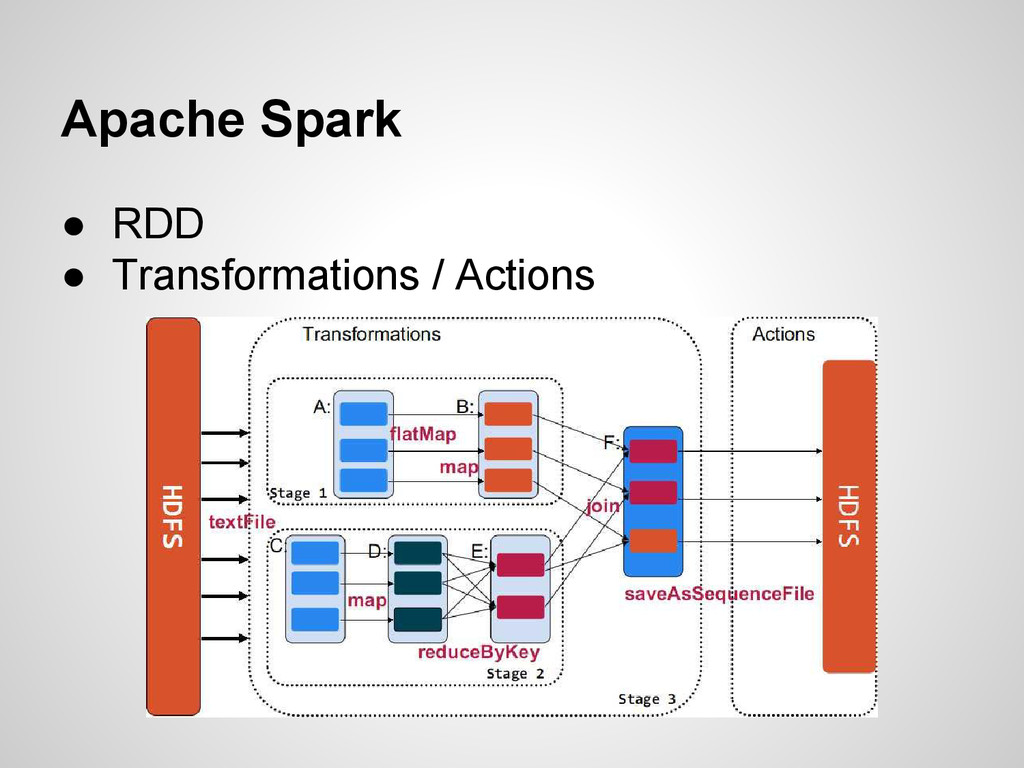
and large- scale processing of datasets on clusters. • Storage ◦ Hadoop Distributed File System (HDFS) • Parallel processing of large datasets ◦ Hadoop MapResuce
large-scale data processing • Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk. • Write applications quickly in Java/Scala/Python
Status ◦ 192.168.28.9:8080 • Add “/usr/local/spark/bin” into your $PATH Edit your ~/.bashrc $ export PATH=$PATH:/usr/local/spark/bin • Run ◦ $ spark-submit --master spark://NLG-WKS-9:7077 YourPyhonSparkScript.py
env-name ◦ $ vittualenv --no-site-packages env-name ▪ No site packages • Work in your env ◦ $ source env-name/bin/active ◦ Do anything in your env ^_< • Leave env ◦ (env-name) $ deactivate
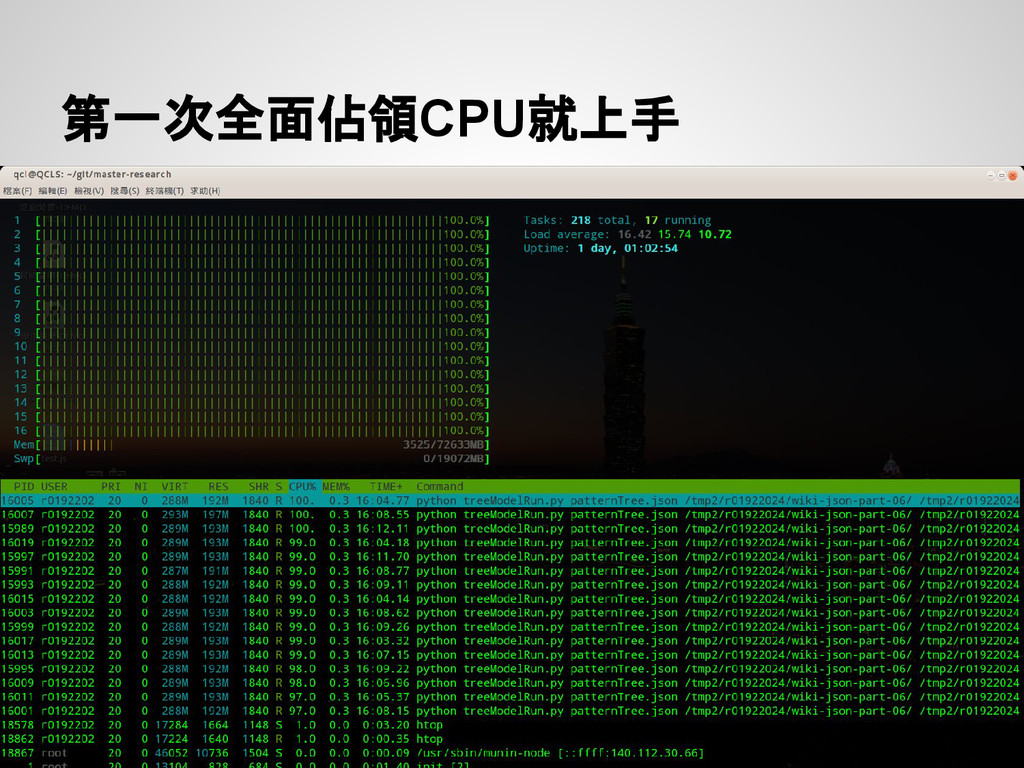
[...] results = [] pool = multiprocessing.Pool(processes=multiprocessing.cpu_count()) for job in jobs: result.append( pool.apply_async(doSth, (job) ) ) pool.close() pool.join() for r in results: result = r.get()
{kind=link}
{kind=link}
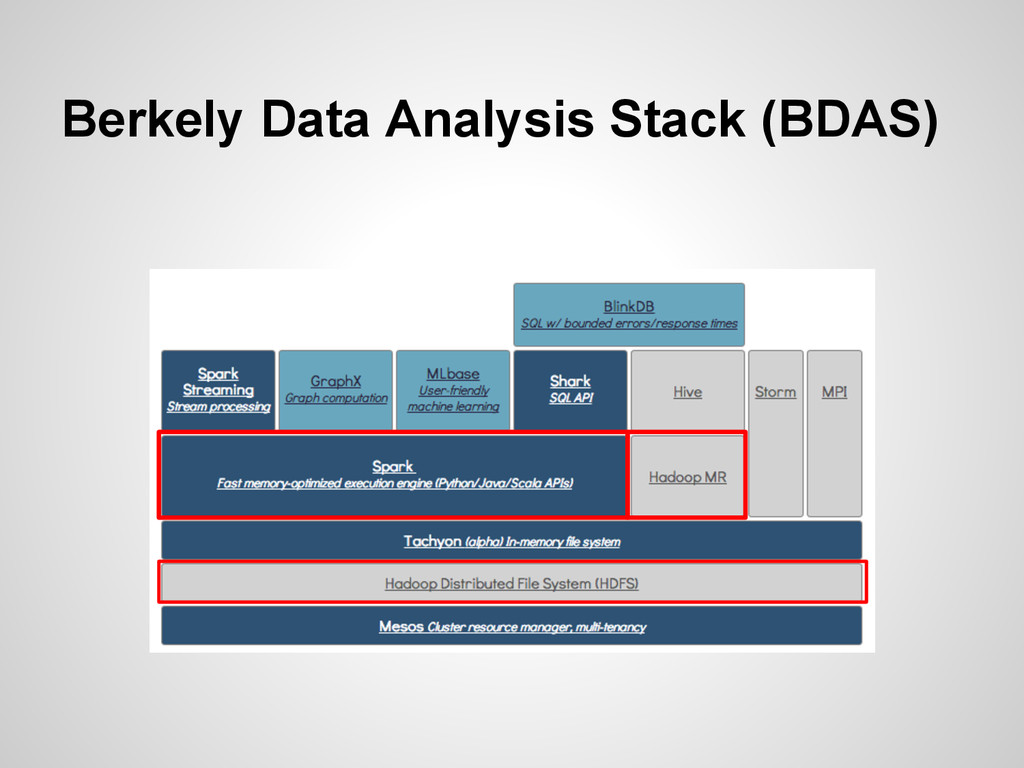{kind=link}
{kind=link}
{kind=link}
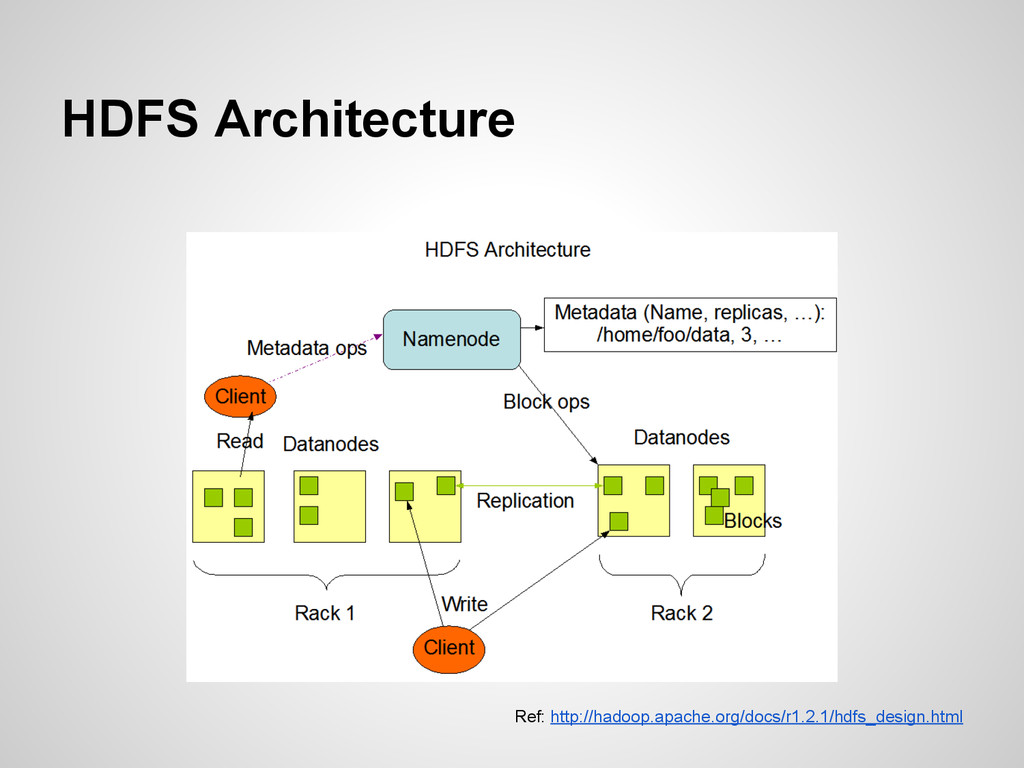{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
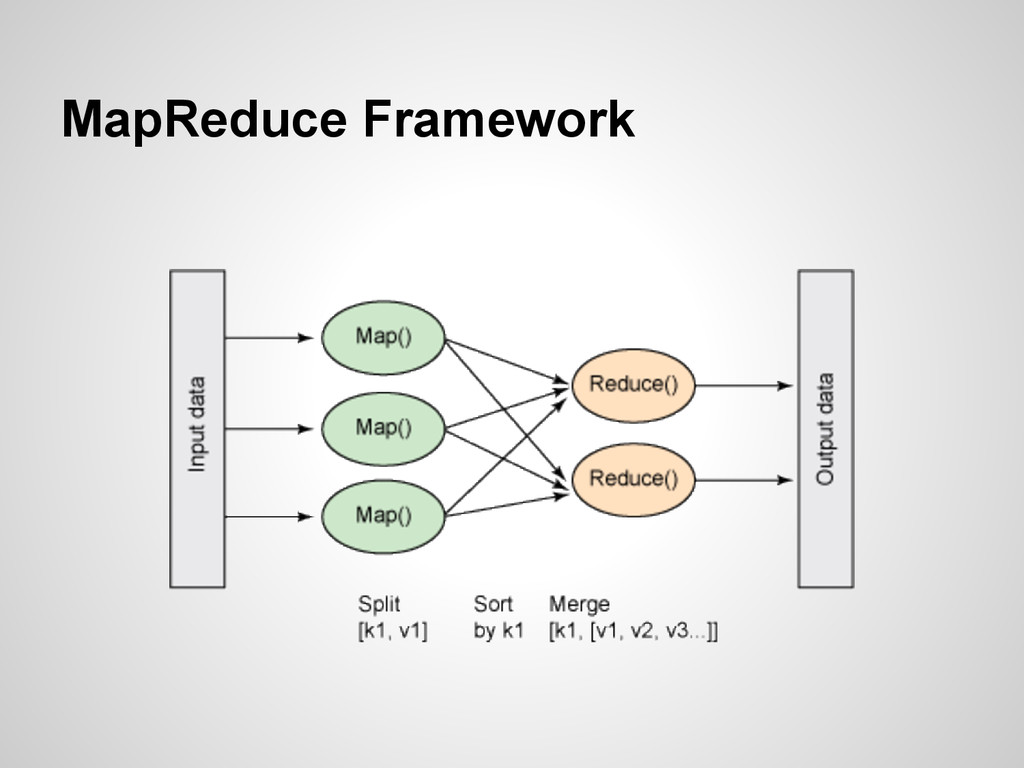{kind=link}
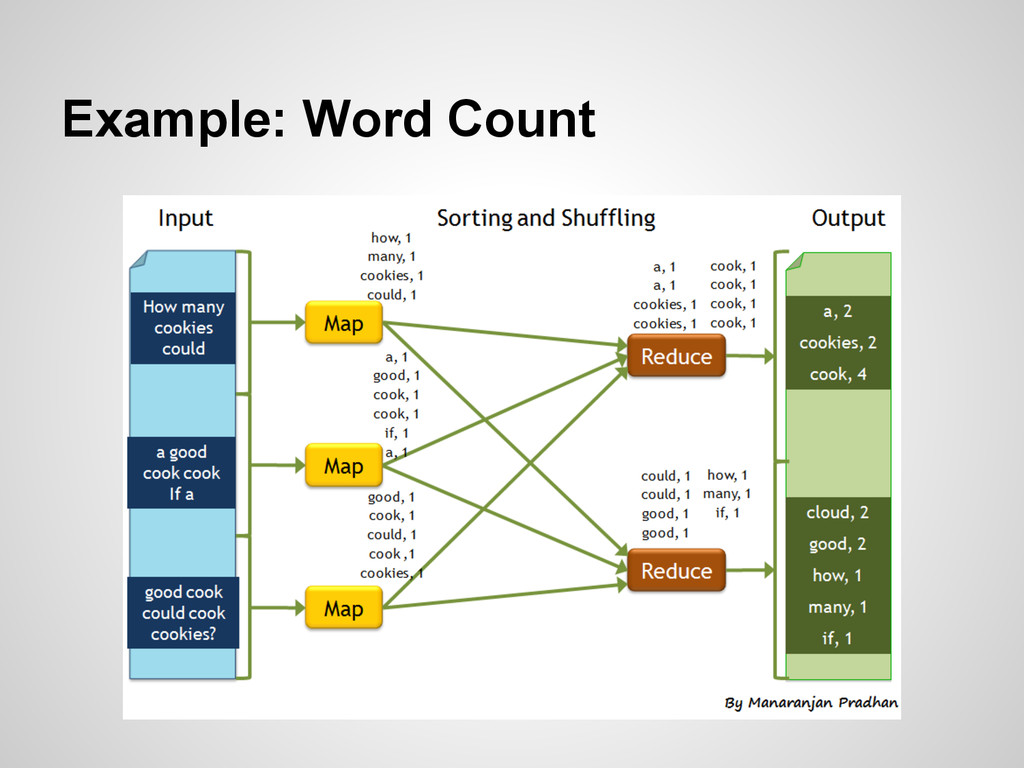{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}