This keynote talk was given at JupyterCon in NYC.
https://www.oreilly.com/ideas/the-future-of-data-driven-discovery-in-the-cloud
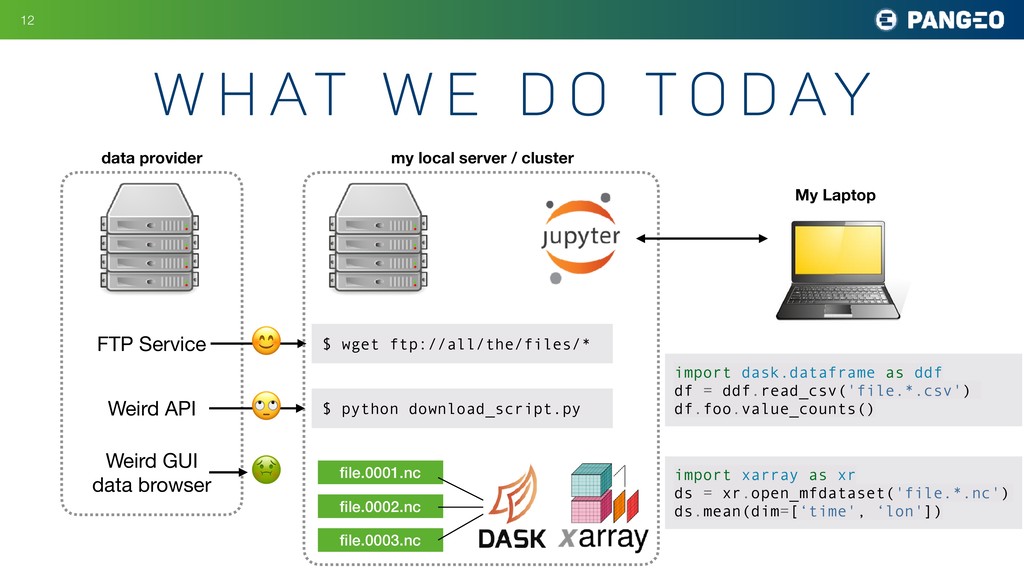
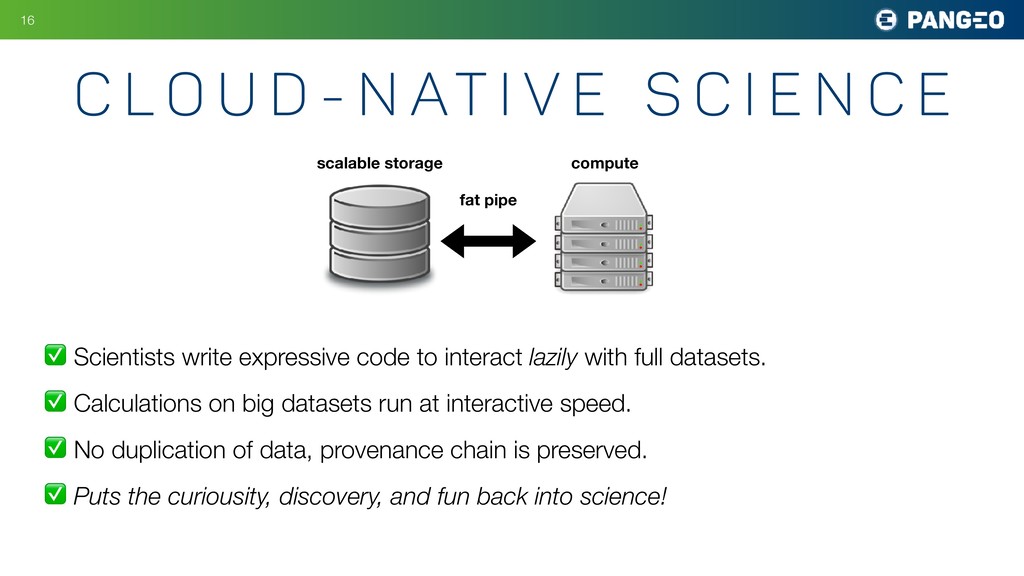
What are the limiting factors to scientific progress? Of course, we always want more experiments, better measurements, and bigger simulations. But many fields, from microbiology to climate science and astronomy, are struggling to make sense of the data they already have, due to the size and complexity of modern scientific datasets. Academic science still mostly operates on a download model: datasets are downloaded and stored on-premises, where they are accessible to local computers. As datasets reach the petabyte scale, this model is breaking hard. Its inefficiency presents severe barriers to reproducibility and interdisciplinary research. Without a different approach to infrastructure, it will be difficult for basic science to reap the benefits of machine learning and artificial intelligence.
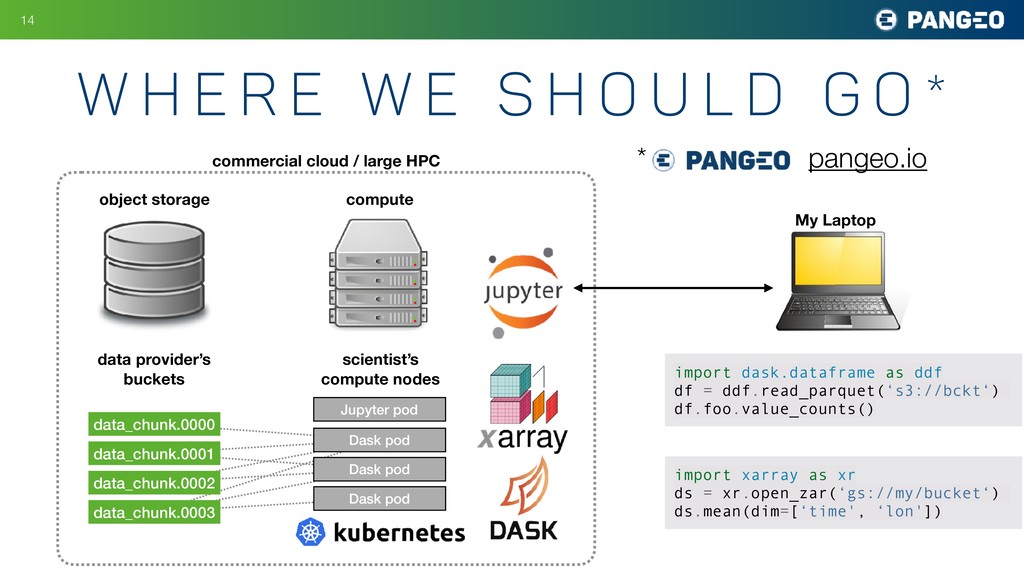
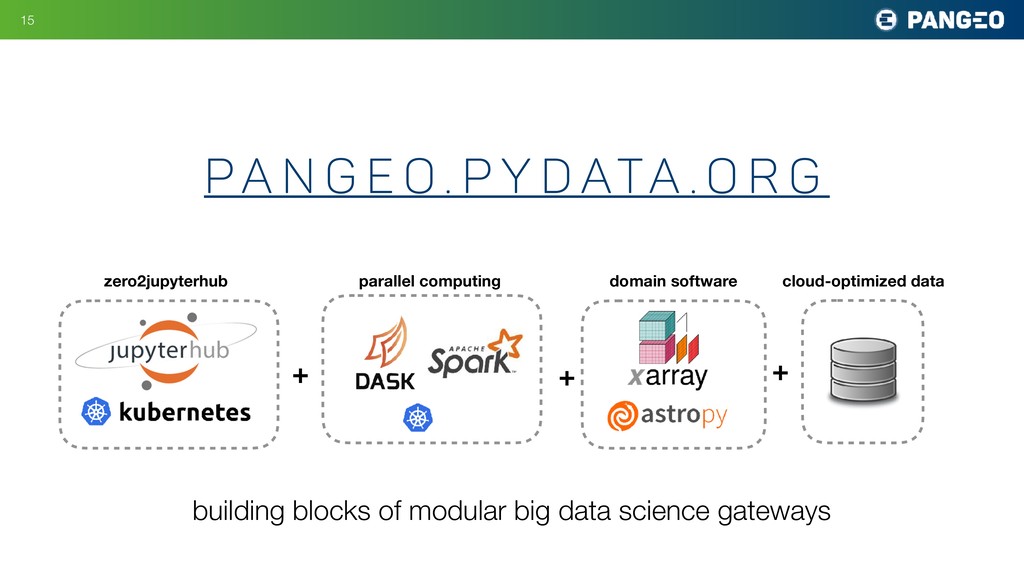
Ryan Abernathey makes the case for the large-scale migration of scientific data and research to the cloud. The cloud offers a way to make the largest datasets instantly accessible to the most sophisticated computational techniques. A global scientific data commons could usher in a golden age of data-driven discovery. Drawing on his experience with the Pangeo project, Ryan demonstrates that the technology to build it mostly already exists. Jupyter, which enables scientists to interact naturally with remote systems, is a key element of the proposed infrastructure. Other important elements are flexible frameworks for interactive distributed computing (such as Dask) and cloud-optimized storage formats. The biggest challenge is social—convincing the stakeholders and funders that the benefits of migrating to the cloud outweigh the considerable costs. A partnership between academia, government, and industry could catalyze a phase transition to a vastly more productive and exciting cloud-native scientific process.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}