A primer on Information Theory and its fundamental theorem which I gave in the spring of 2012 as part of MAT 490 at Berry College. There are a few significant typos in this presentation, so be warned.
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Introduction How do you... • Talk to space shuttles? • Avoid cross-talk over telephone lines? • Make a CD that still plays if you scratch it?
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 History Claude Shannon “The Father of Information Theory” • 1916 - 2001 • MIT • Differential Analyzer • Bell Labs • ENIGMA Papers • A Symbolic Analysis of Relay and Switching Circuits “Possibly the most important, and also the most famous, master’s thesis of the century.” -Howard Gardner • A Mathematical Theory of Communication http://www.bell-labs.com/news/2001/february/26/1.html Copyright Bell Labs
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Definitions and Notation • Shannon bit – “The amount of information gained (or entropy removed) upon learning the answer to a question whose two possible answers were equally likely, a priori.”
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Definitions and Notation • Shannon bit – “The amount of information gained (or entropy removed) upon learning the answer to a question whose two possible answers were equally likely, a priori.” • Target Space – {x1, x2, ..., xn}
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Definitions and Notation • Shannon bit – “The amount of information gained (or entropy removed) upon learning the answer to a question whose two possible answers were equally likely, a priori.” • Target Space – {x1, x2, ..., xn} • P(X = x1) or simply P(x1)
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Definitions and Notation • Shannon bit – “The amount of information gained (or entropy removed) upon learning the answer to a question whose two possible answers were equally likely, a priori.” • Target Space – {x1, x2, ..., xn} • P(X = x1) or simply P(x1) • Expected Value – E(X) = n i=1 xiP(xi)
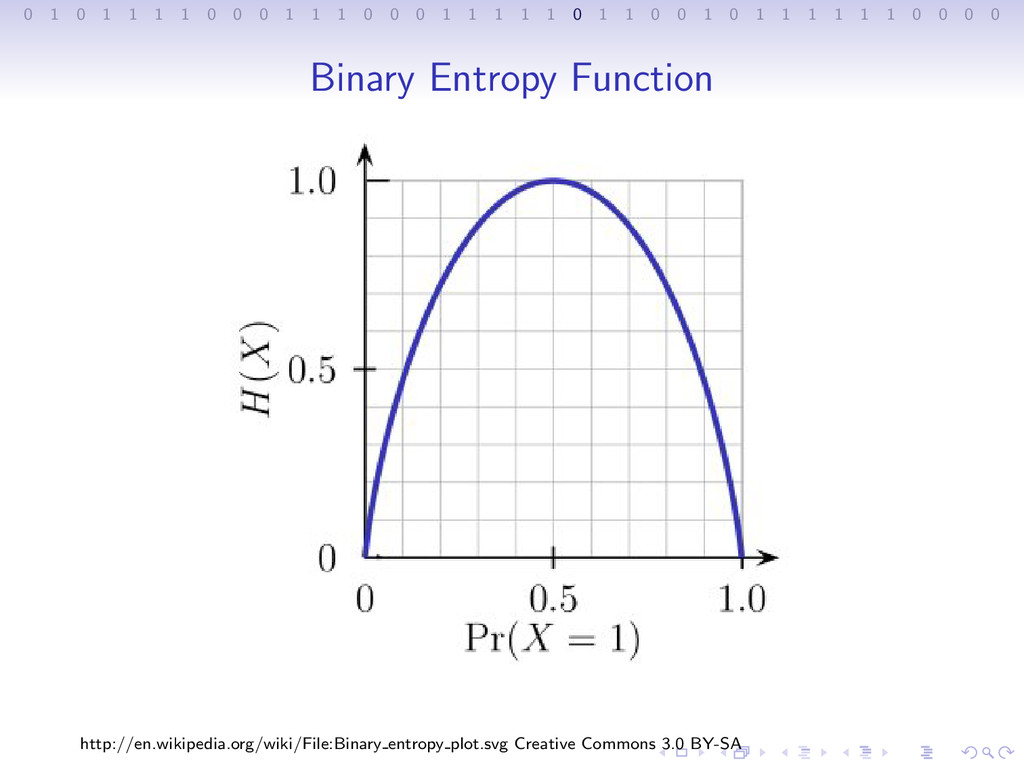
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Shannon Entropy A measure of the amount of uncertainty in the value of a random variable, measured in Shannon bits. Example: Coin Toss
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Shannon Entropy A measure of the amount of uncertainty in the value of a random variable, measured in Shannon bits. Example: Coin Toss Two notes: • Entropy in Thermodynamics
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Shannon Entropy A measure of the amount of uncertainty in the value of a random variable, measured in Shannon bits. Example: Coin Toss Two notes: • Entropy in Thermodynamics • Shannon bits vs. digital bits
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Entropy Function For random variable X with target space x1, x2, ..., xn H(X) = n i=0 P(xi) log2 1 P(xi) or, if we pop a sign out of the log, = − n i=0 P(xi) log2 (P(xi))
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Entropy Function For random variable X with target space x1, x2, ..., xn H(X) = n i=0 P(xi) log2 1 P(xi) or, if we pop a sign out of the log, = − n i=0 P(xi) log2 (P(xi)) compare this to statistical mechanics: S = −k i pi log(pi)
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Binomial Experiments A fixed number n trials of a system with two outcomes, with a probability of success p. Then the probability of k successes is P(k) = n k pk(1 − p)n−k
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Binomial Experiments A fixed number n trials of a system with two outcomes, with a probability of success p. Then the probability of k successes is P(k) = n k pk(1 − p)n−k Binomial coefficient: n! k!(n − k)!
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Noisy Channels • Channel – A medium (physical or logical) over which information is sent. • Noisy channel – Channel which has some probability (noise parameter f) that a bit will swap values (be “flipped”).
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Repetition Codes Let’s send a message! Noise frequency f = 25% s t r s’ 11010 11010 11010 11010 10010 11011 10000 10010 Hamming distance from s to s’ = 1. Error of 20%. How much, in general, do we reduce the error by?
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Repetition Codes Error Correction in General case: P(errorRN ) = N n=N+1 2 N n fn(1 − f)N−n This is the sum of Binomial probabilities of getting more than half the bits flipped.
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Repetition Codes Error Correction in General case: P(errorRN ) = N n=N+1 2 N n fn(1 − f)N−n This is the sum of Binomial probabilities of getting more than half the bits flipped. Error probabilities for f = .25: • P(errorR3) ≈ .156 • P(errorR7) ≈ .071
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Repetition Codes Error Correction in General case: P(errorRN ) = N n=N+1 2 N n fn(1 − f)N−n This is the sum of Binomial probabilities of getting more than half the bits flipped. Error probabilities for f = .25: • P(errorR3) ≈ .156 • P(errorR7) ≈ .071 Rate reduction. Is there a better way?
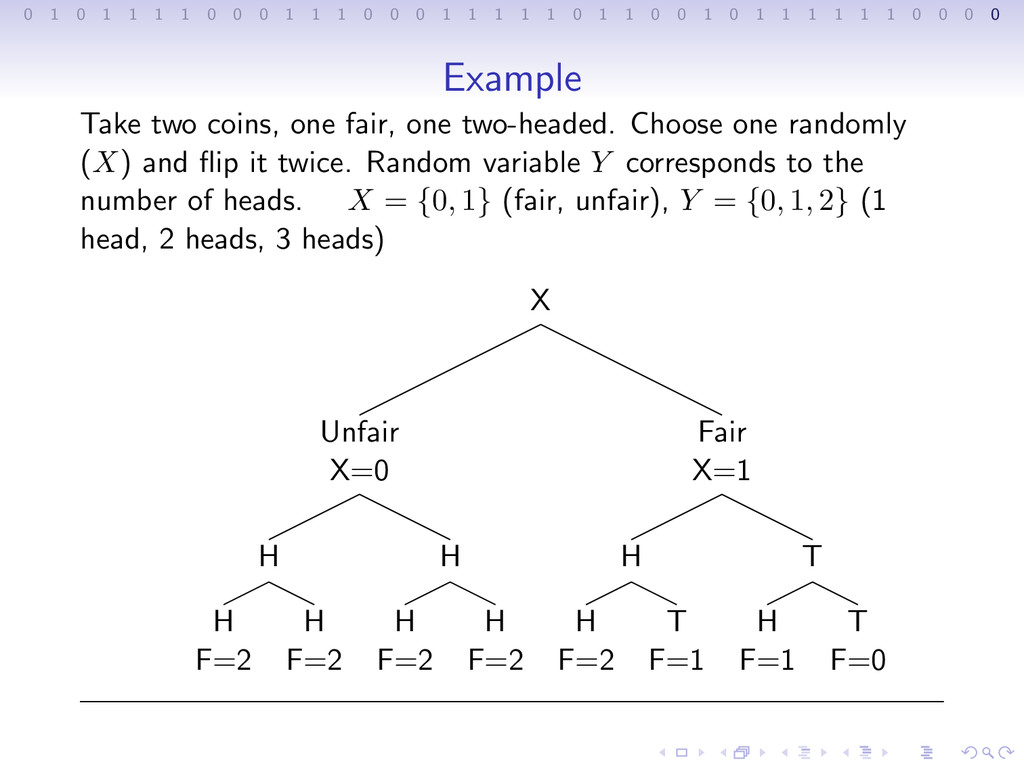
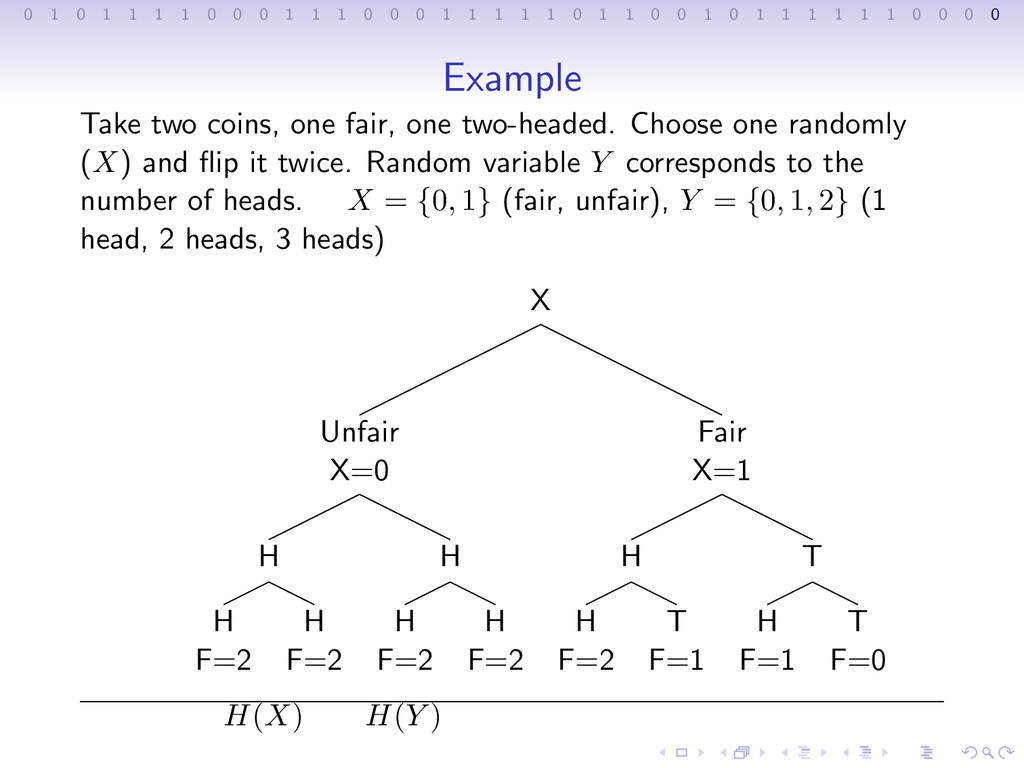
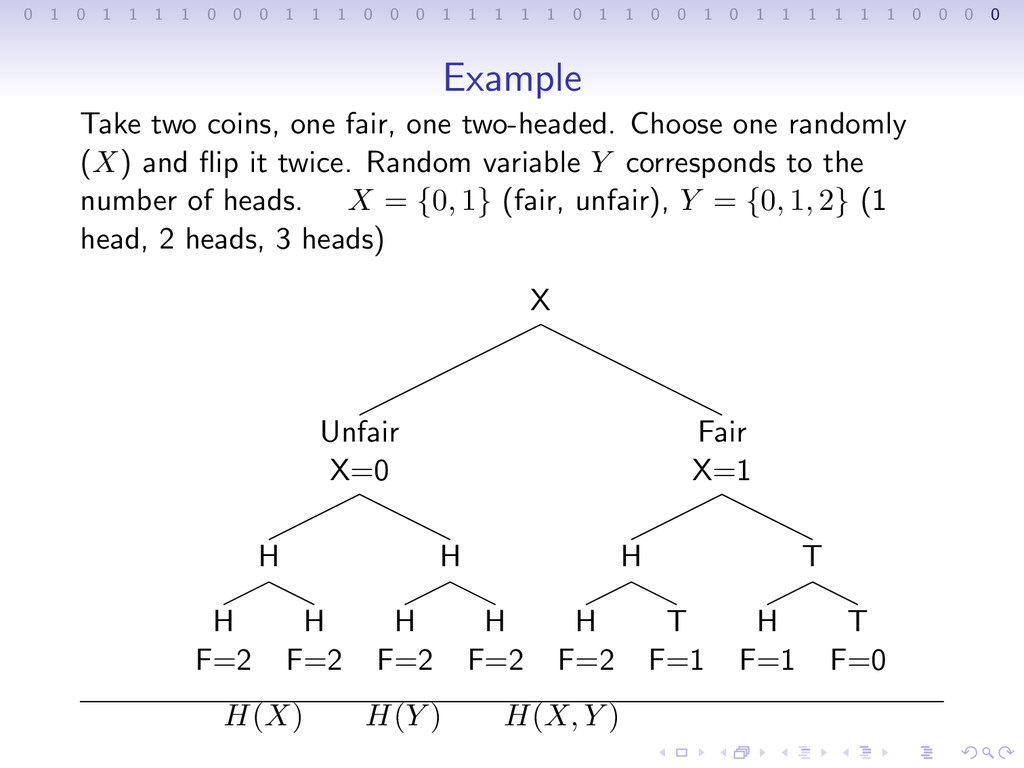
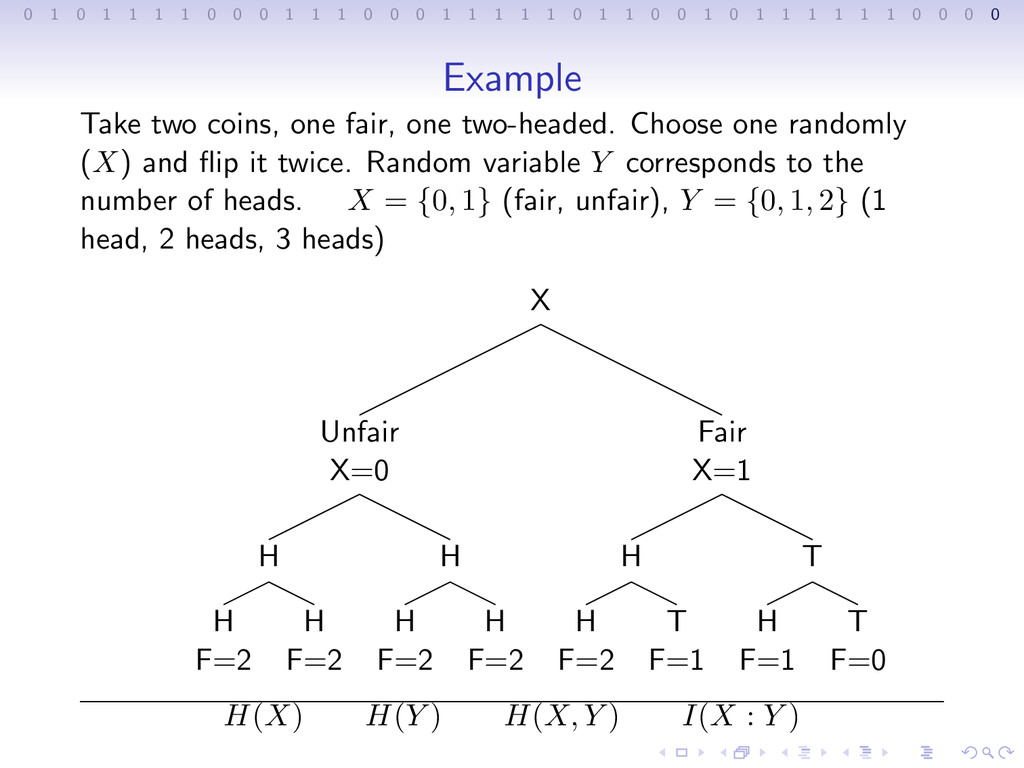
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Example Take two coins, one fair, one two-headed. Choose one randomly (X) and flip it twice. Random variable Y corresponds to the number of heads. X = {0, 1} (fair, unfair), Y = {0, 1, 2} (1 head, 2 heads, 3 heads)
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Example Take two coins, one fair, one two-headed. Choose one randomly (X) and flip it twice. Random variable Y corresponds to the number of heads. X = {0, 1} (fair, unfair), Y = {0, 1, 2} (1 head, 2 heads, 3 heads) X Unfair X=0 H H F=2 H F=2 H H F=2 H F=2 Fair X=1 H H F=2 T F=1 T H F=1 T F=0
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Example Take two coins, one fair, one two-headed. Choose one randomly (X) and flip it twice. Random variable Y corresponds to the number of heads. X = {0, 1} (fair, unfair), Y = {0, 1, 2} (1 head, 2 heads, 3 heads) X Unfair X=0 H H F=2 H F=2 H H F=2 H F=2 Fair X=1 H H F=2 T F=1 T H F=1 T F=0 H(X) H(Y )
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Example Take two coins, one fair, one two-headed. Choose one randomly (X) and flip it twice. Random variable Y corresponds to the number of heads. X = {0, 1} (fair, unfair), Y = {0, 1, 2} (1 head, 2 heads, 3 heads) X Unfair X=0 H H F=2 H F=2 H H F=2 H F=2 Fair X=1 H H F=2 T F=1 T H F=1 T F=0 H(X) H(Y ) H(X, Y )
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Example Take two coins, one fair, one two-headed. Choose one randomly (X) and flip it twice. Random variable Y corresponds to the number of heads. X = {0, 1} (fair, unfair), Y = {0, 1, 2} (1 head, 2 heads, 3 heads) X Unfair X=0 H H F=2 H F=2 H H F=2 H F=2 Fair X=1 H H F=2 T F=1 T H F=1 T F=0 H(X) H(Y ) H(X, Y ) I(X : Y )
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 More Definitions Assuming channel Λ is a discrete, memoryless, binary symmetric channel (BSC) with error parameter f • Discrete – Messages can be divided into separate symbols. Furthermore, X and Y have finite target spaces.
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 More Definitions Assuming channel Λ is a discrete, memoryless, binary symmetric channel (BSC) with error parameter f • Discrete – Messages can be divided into separate symbols. Furthermore, X and Y have finite target spaces. • Memoryless – Probabilities are independent and don’t change.
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 More Definitions Assuming channel Λ is a discrete, memoryless, binary symmetric channel (BSC) with error parameter f • Discrete – Messages can be divided into separate symbols. Furthermore, X and Y have finite target spaces. • Memoryless – Probabilities are independent and don’t change. • Binary Symmetric Channel – Channel with binary input and binary output and error parameter f < .5
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 More Definitions Assuming channel Λ is a discrete, memoryless, binary symmetric channel (BSC) with error parameter f • Discrete – Messages can be divided into separate symbols. Furthermore, X and Y have finite target spaces. • Memoryless – Probabilities are independent and don’t change. • Binary Symmetric Channel – Channel with binary input and binary output and error parameter f < .5 • Redundancy – Extra information added to a message to reduce error.
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 More Definitions Assuming channel Λ is a discrete, memoryless, binary symmetric channel (BSC) with error parameter f • Discrete – Messages can be divided into separate symbols. Furthermore, X and Y have finite target spaces. • Memoryless – Probabilities are independent and don’t change. • Binary Symmetric Channel – Channel with binary input and binary output and error parameter f < .5 • Redundancy – Extra information added to a message to reduce error. • Capacity – Maximum concentration of information for a given channel. Γ = maxP(X) I(X : Y )
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 More Definitions Assuming channel Λ is a discrete, memoryless, binary symmetric channel (BSC) with error parameter f • Discrete – Messages can be divided into separate symbols. Furthermore, X and Y have finite target spaces. • Memoryless – Probabilities are independent and don’t change. • Binary Symmetric Channel – Channel with binary input and binary output and error parameter f < .5 • Redundancy – Extra information added to a message to reduce error. • Capacity – Maximum concentration of information for a given channel. Γ = maxP(X) I(X : Y ) Simplifies to Γ = 1 − H(f)
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Fundamental Theorem Goal: to minimize error probability, while also minimizing redundancy (and thereby maximize rate). Let Λ be a BSC with parameter f < 1/2 and resulting capacity Γ = 1 − H(f). Let R be any information rate with R < Γ. Let > 0 be an arbitrarily small positive quantity. Then, there exists a code C of length N and a rate ≥ R and a decoding algorithm such that the maximum probability of error is ≤ .
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Fundamental Theorem Goal: to minimize error probability, while also minimizing redundancy (and thereby maximize rate). Let Λ be a BSC with parameter f < 1/2 and resulting capacity Γ = 1 − H(f). Let R be any information rate with R < Γ. Let > 0 be an arbitrarily small positive quantity. Then, there exists a code C of length N and a rate ≥ R and a decoding algorithm such that the maximum probability of error is ≤ . • Baby analogy
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Fundamental Theorem Goal: to minimize error probability, while also minimizing redundancy (and thereby maximize rate). Let Λ be a BSC with parameter f < 1/2 and resulting capacity Γ = 1 − H(f). Let R be any information rate with R < Γ. Let > 0 be an arbitrarily small positive quantity. Then, there exists a code C of length N and a rate ≥ R and a decoding algorithm such that the maximum probability of error is ≤ . • Baby analogy • R > Γ
1 1 1 0 0 0 1 1 1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 Sources Primary Sources 1. Aiden A. Bruen and Mario A. Forcintino. Cryptography, Information Theory, and Error-Correction John Wiley Sons, 2005. 2. David J. C. MacKay. Information Theory, Inference, and Learning Algorithms Cambridge University Press, 2003. Papers 1. Claude E. Shannon, Warren Weaver. The Mathematical Theory of Communication Univ of Illinois Press, 1949. 2. Thomas A. Kunkel. DNA Replication Fidelity JBC Papers 2004.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}