application developer • Co-founder of Lost Property (service company) • Python developer fiddling with Erlang and Haskell • Love using Postgres • Running the Pyramid London Meetup Twitter: @rachbelaid
• Stopword (eg: ‘and’, ‘a’, ‘the’, ‘but’) • Stemming (Finding the root of a word) • Relevance (Algo used to rank the results of the query) • Boost (enhancing the relevance of certains document based on condition) • Position (Position of a token inside the document)
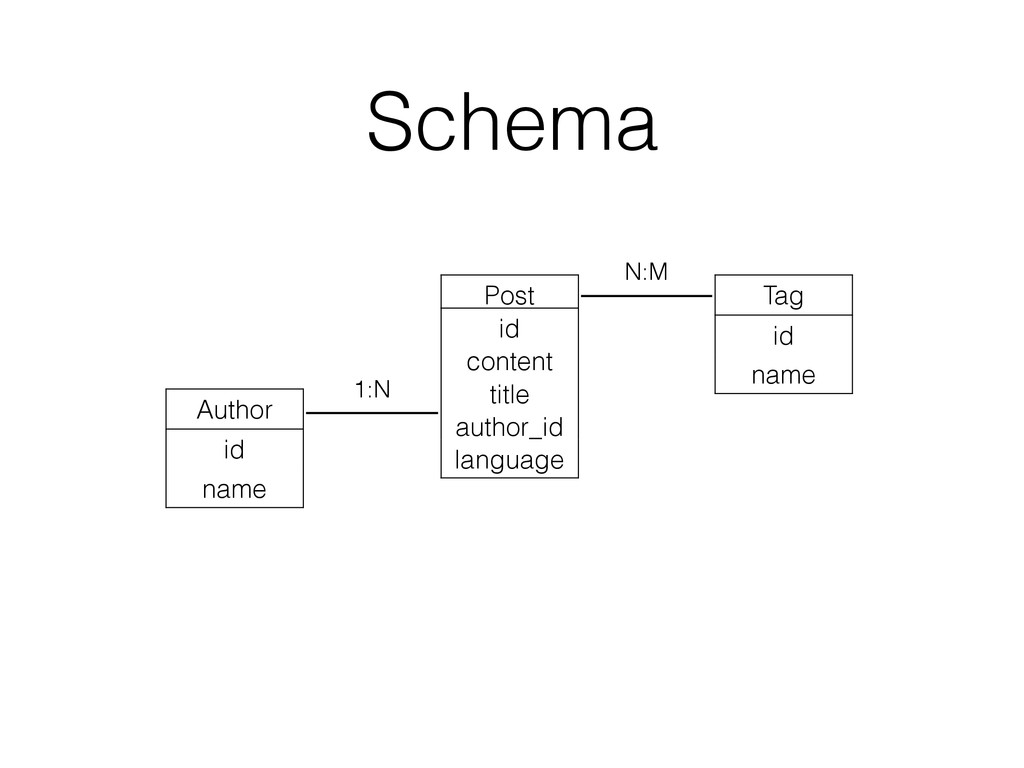
|| ' ' || author.name || ' ' || coalesce((string_agg(tag.name, ' ')), '') as document FROM post JOIN author ON author.id = post.author_id JOIN posts_tags ON posts_tags.post_id = posts_tags.tag_id JOIN tag ON tag.id = posts_tags.tag_id GROUP BY post.id;
a tsvector. ! SELECT to_tsvector('Try not to become a man of success, but rather try to become a man of value'); ! Result: ! to_tsvector ---------------------------------------------------------- 'becom':4,13 'man':6,15 'rather':10 'success':8 'tri':1,11 'valu':17 ! ! • less words than in the original sentence, • some of the words are different (try became tri) • they are all followed by numbers. (position)
distinct lexemes which are words that have been normalized to make variants of the same word look alike. ! For example: ! - folding upper-case letters to lower-case - removal of suffixes (such as 's', 'es' or 'ing' in English). ! This allows searches to find variant forms of the same word without tediously entering all the possible variants. ! The numbers represent the position of the lexeme in the original string.
post_id, to_tsvector(post.title) || to_tsvector(post.content) || to_tsvector(author.name) || to_tsvector(coalesce((string_agg(tag.name, ' ‘)), ‘')) as content FROM post JOIN author ON author.id = post.author_id JOIN posts_tags ON posts_tags.post_id = posts_tags.tag_id JOIN tag ON tag.id = posts_tags.tag_id GROUP BY post.id );
it') @@ ‘dream' as result; ! result ---------- t ! SELECT to_tsvector('It''s kind of fun to do the impossible') @@ ‘impossible' as result; ! result ---------- f
build a tsquery which creates the same lexemes and, using the operator @@, casts the string into a tsquery. SELECT ‘impossible’::tsquery, to_tsquery('impossible'); tsquery | to_tsquery -------------+------------ 'impossible' | 'imposs'
the facts') @@ to_tsquery('! fact’); -> FALSE ! SELECT to_tsvector('If the facts don''t fit the theory, change the facts') @@ to_tsquery('theory & !fact’); -> FALSE ! SELECT to_tsvector('If the facts don''t fit the theory, change the facts.') @@ to_tsquery('fiction | theory’); -> TRUE
|| to_tsvector(post.language::regconfig, post.content) || to_tsvector(‘simple’, author.name) || to_tsvector( ‘simple’, coalesce((string_agg(tag.name, ‘’)), ‘') ) as content FROM post JOIN author ON author.id = post.author_id JOIN posts_tags ON posts_tags.post_id = posts_tags.tag_id JOIN tag ON tag.id = posts_tags.tag_id GROUP BY post.id ); Language support: Build new documents
to normalise accents. Eg: difficult to search for french accent with an english keyboard. ! CREATE EXTENSION unaccent; SELECT unaccent('èéêë'); unaccent ---------- eeee (1 row)
new dictionary: CREATE TEXT SEARCH CONFIGURATION fr ( COPY = french ); ALTER TEXT SEARCH CONFIGURATION fr ALTER MAPPING FOR hword, hword_part, word WITH unaccent, french_stem; When we are using this new text search config, we can see the lexemes: SELECT to_tsvector('french', 'il était une fois'); to_tsvector ------------- 'fois':4 SELECT to_tsvector('fr', 'il était une fois'); to_tsvector —————————— 'etait':2 'fois':4
you want to be able to get search results ordered by relevance. • To order our results by revelance PostgreSQL provides a few functions but we will be using only 2 of them : ts_rank() and setweight(). • The function setweight() allows us to assign a weight value to a tsvector(); the value can be 'A', 'B', 'C' or 'D'
document'), to_tsquery('example | document')) as relevancy; -> 0.0607927 SELECT ts_rank(to_tsvector('This is an example of document'), to_tsquery('example | unkown')) as relevancy; -> 0.0303964 SELECT ts_rank(to_tsvector('This is an example of document'), to_tsquery('example & document')) as relevancy; -> 0.0985009 SELECT ts_rank(to_tsvector('This is an example of document'), to_tsquery('example & unknown')) as relevancy; -> 1e-20
as post_id, post.title as title, setweight(to_tsvector(post.language::regconfig, post.title), 'A') || setweight(to_tsvector(post.language::regconfig, post.content), 'B') || setweight(to_tsvector('simple', author.name), 'C') || setweight(to_tsvector(‘simple', coalesce(string_agg(tag.name, ' '))), 'B') as document FROM post JOIN author ON author.id = post.author_id JOIN posts_tags ON posts_tags.post_id = posts_tags.tag_id JOIN tag ON tag.id = posts_tags.tag_id GROUP BY post.id );
you can simply create a GIN index around the tsvector() function. (one table only) CREATE INDEX idx_fts_post ON post USING gin( setweight( to_tsvector(language, title),’A’)|| setweight( to_tsvector(language, content),'B') );
document is spread accross multiple tables with different weights. For a better performance it's necessary to denormalize the data : • MATERIALIZED VIEW (if can have indexing delay) • TRIGGERS • Application logic • ?? suggestions ??
feature of Postgres but ElasticSearch and SOLR are tool dedicated to do FTS: • PG required to have the tsquery build properly where ES make it easier to do query with custom analyser on part of document • PG make it easier to not think about data sync or canonical datastore problem • ES offers great languages (and better out of the box) than PG. Lucene • PG is rock solid and easy to run • ES better unicode case folding
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}