scoutbee, Berlin Building Large Language Models, Knowledge Graphs and MLOps. Twitter : @nischalhp linkedin.com/in/nischalhp https:/ /github.com/deep-learning-for-humans Raghotham Sripadraj AI Architect at PayPal, Bangalore Building Document AI, Large Language and Computer Vision Models at PayPal. Twitter : @raghothams linkedin.com/in/raghothams/
cool music producers. How can we find them based on what we like? Le us circa 2023 - Here is shazam.nearest_neighbors, music discovery using language models and graphs. https:/ /github.com/deep-learning-for-humans
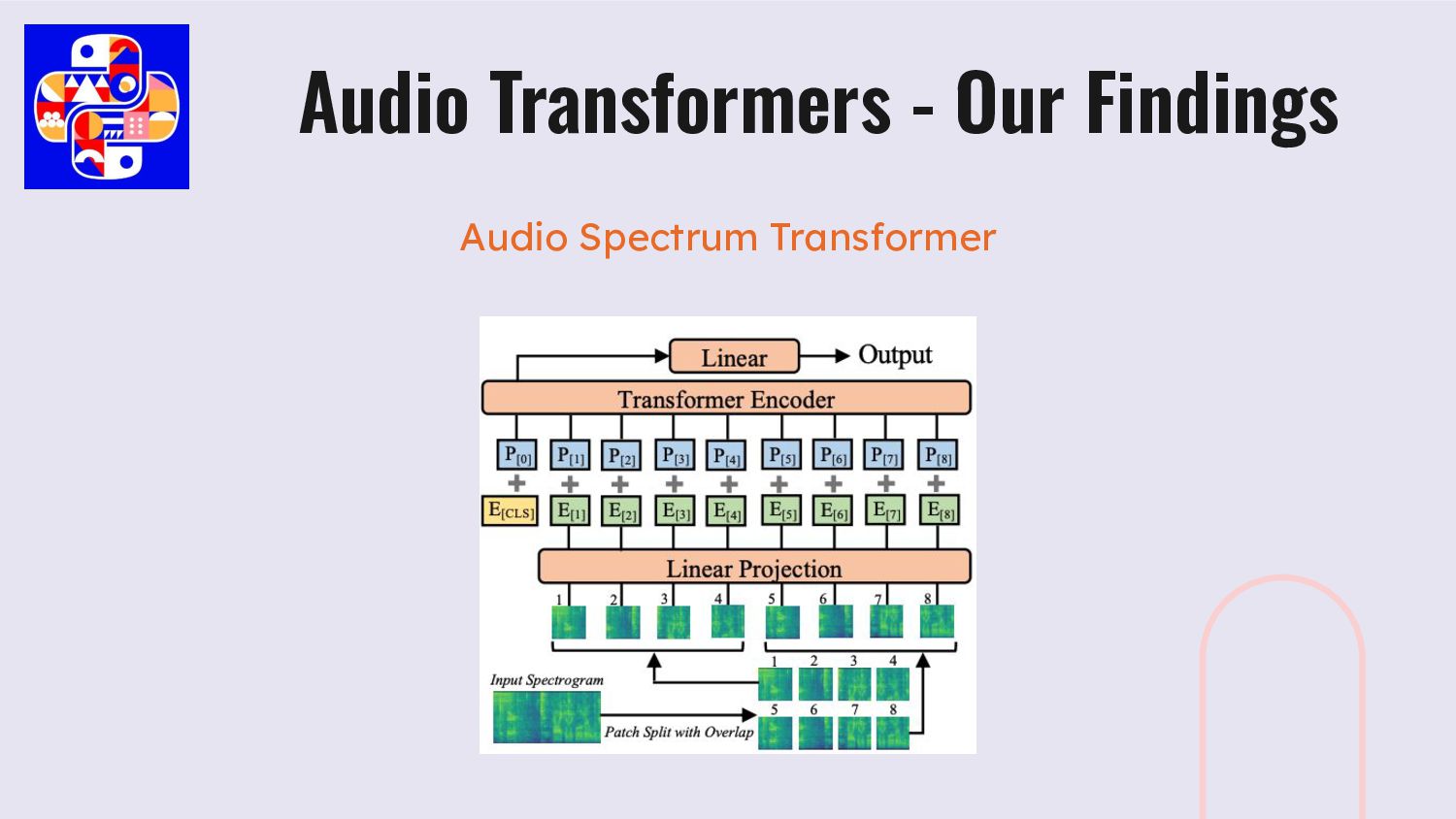
transformers model and tried a quick similarity using a vector store, to find the most similar samples. Wav2Vec2 Audio Spectrum Transformer CLAP Our Experiments with Transformers
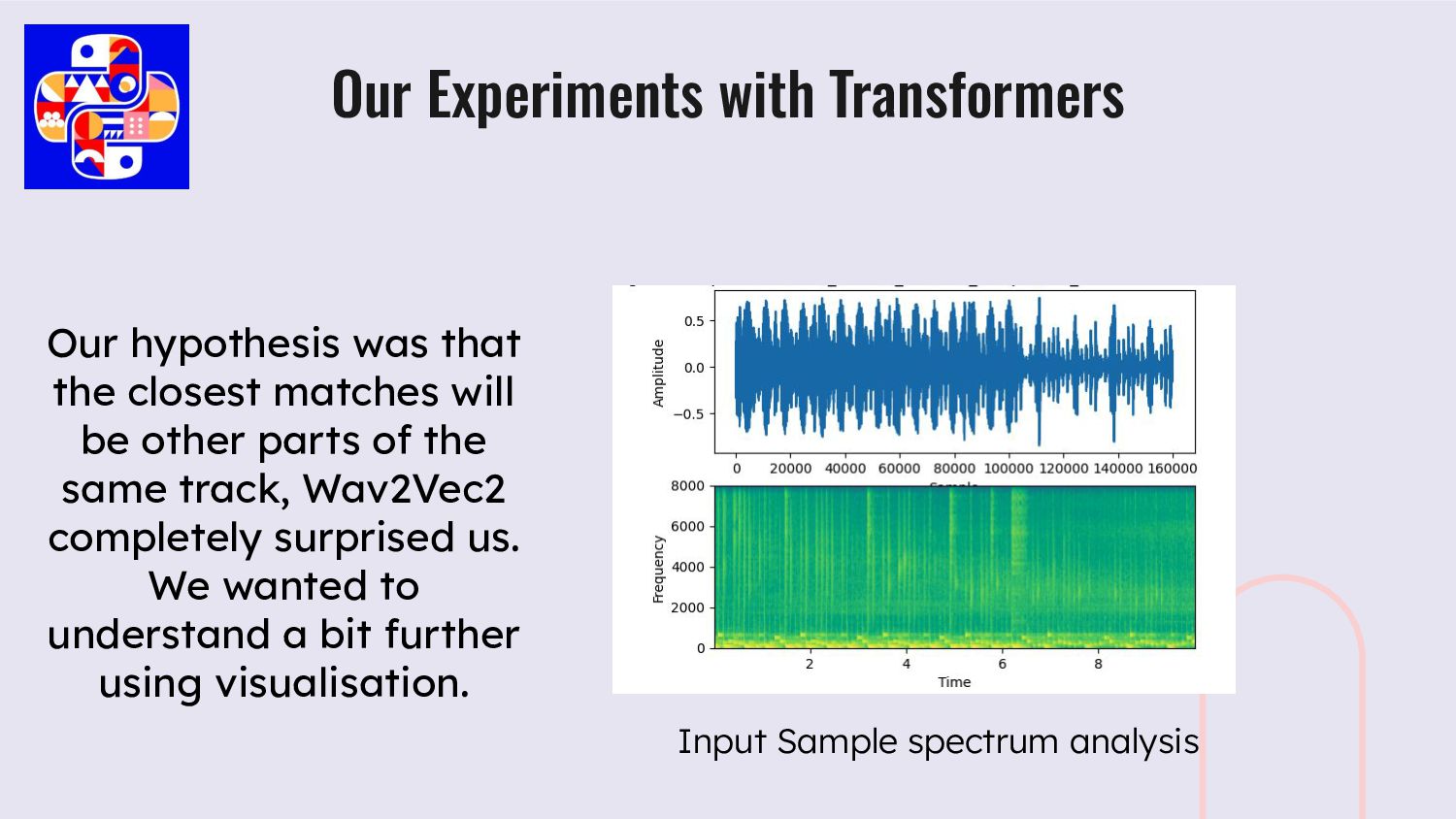
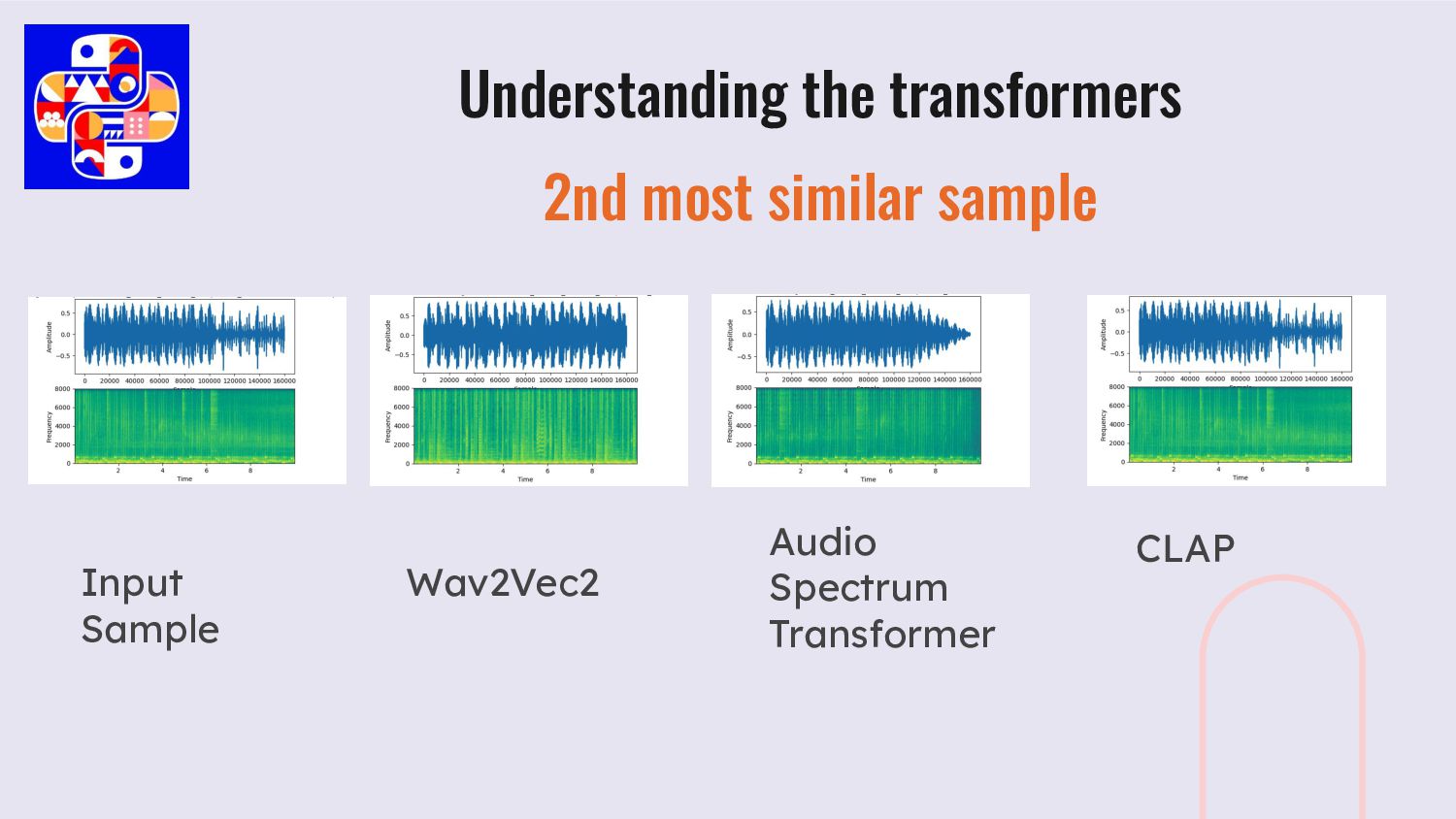
parts of the same track, Wav2Vec2 completely surprised us. We wanted to understand a bit further using visualisation. Input Sample spectrum analysis Our Experiments with Transformers
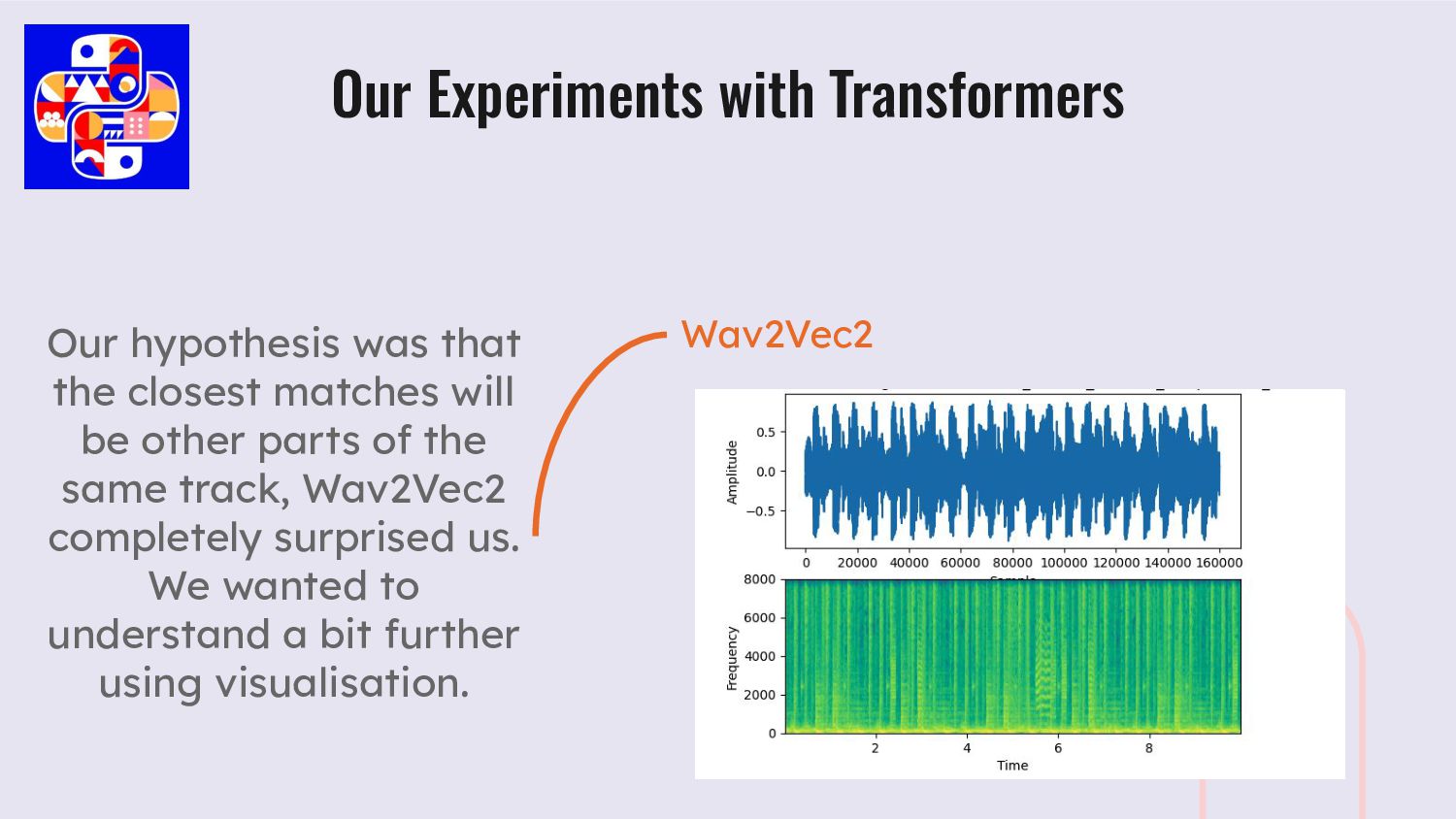
parts of the same track, Wav2Vec2 completely surprised us. We wanted to understand a bit further using visualisation. Our Experiments with Transformers Wav2Vec2
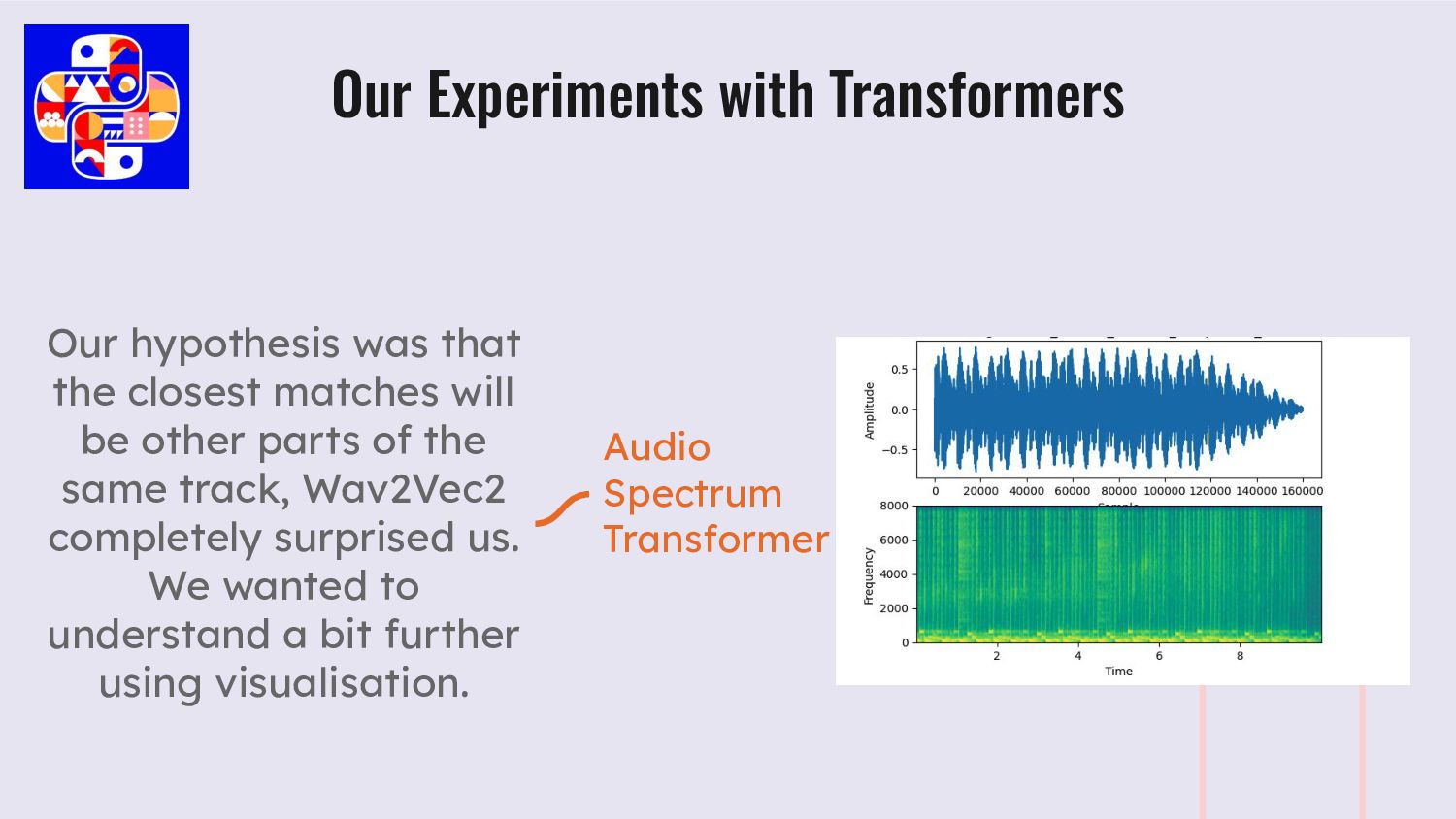
parts of the same track, Wav2Vec2 completely surprised us. We wanted to understand a bit further using visualisation. Our Experiments with Transformers Audio Spectrum Transformer
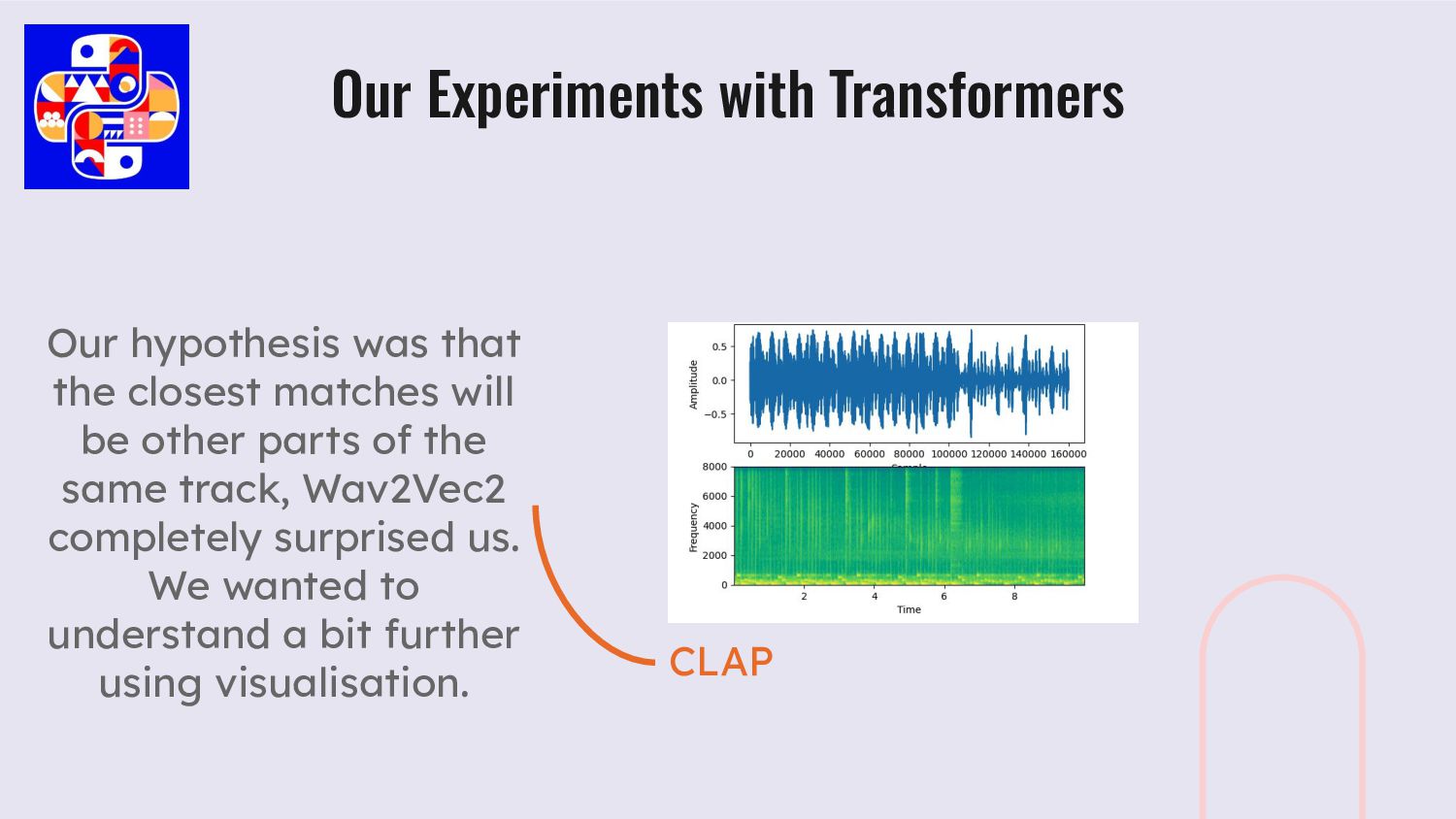
parts of the same track, Wav2Vec2 completely surprised us. We wanted to understand a bit further using visualisation. Our Experiments with Transformers CLAP
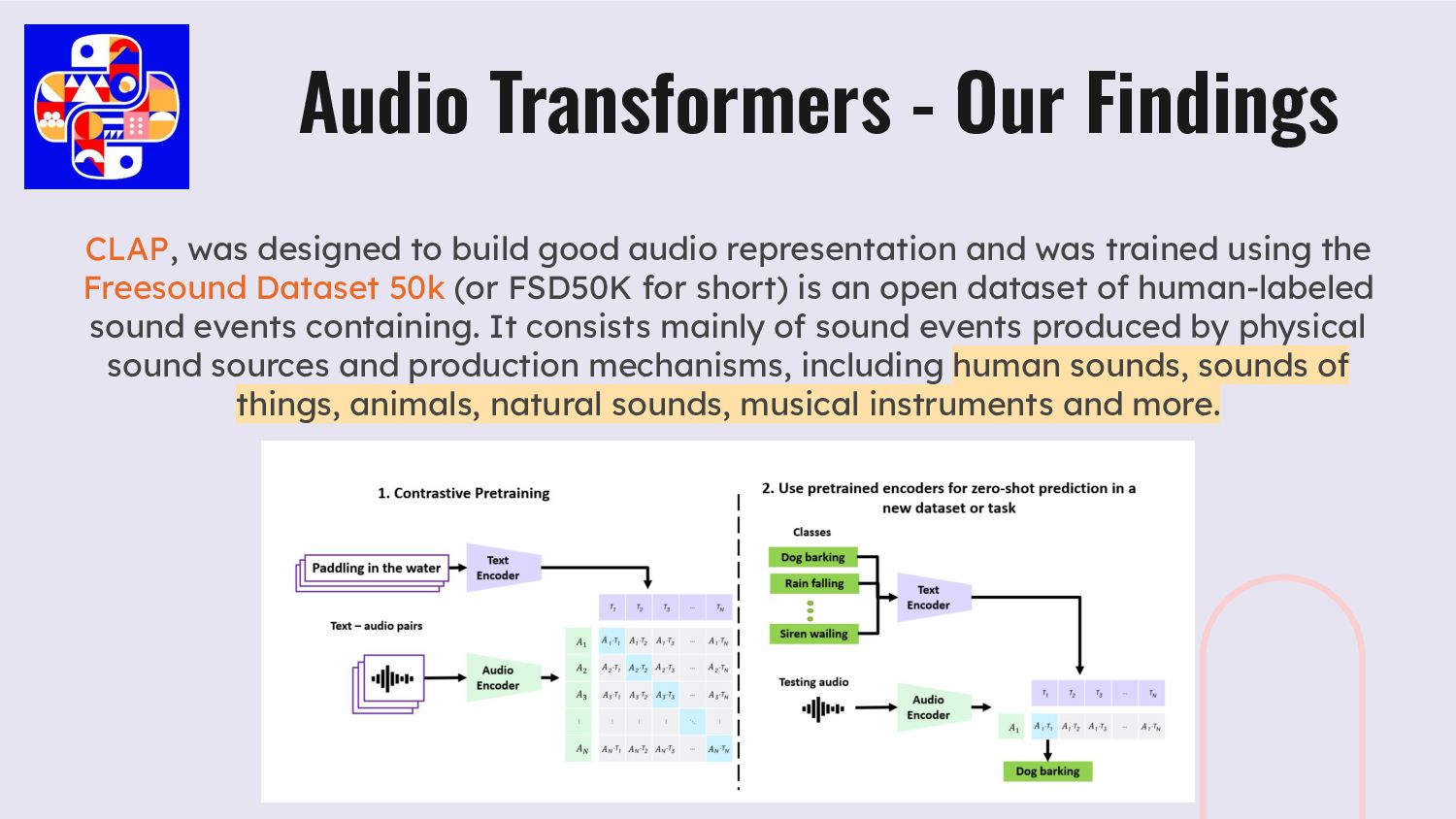
is a collection of over 2 million 10-second audio clips excised from YouTube videos and labeled with the sounds that the clip contains from a set of 527 labels. Audio Transformers - Our Findings
trained using the Freesound Dataset 50k (or FSD50K for short) is an open dataset of human-labeled sound events containing. It consists mainly of sound events produced by physical sound sources and production mechanisms, including human sounds, sounds of things, animals, natural sounds, musical instruments and more. Audio Transformers - Our Findings
sampling rates used. Embeddings generated for all the samples using Wav2Vec, Clap, AST transformers model Indexed the embeddings into a vector store (FAISS) to generate similarity Spectrum analysis of the samples and similar samples to better understand the transformers Audio Transformers - Summary
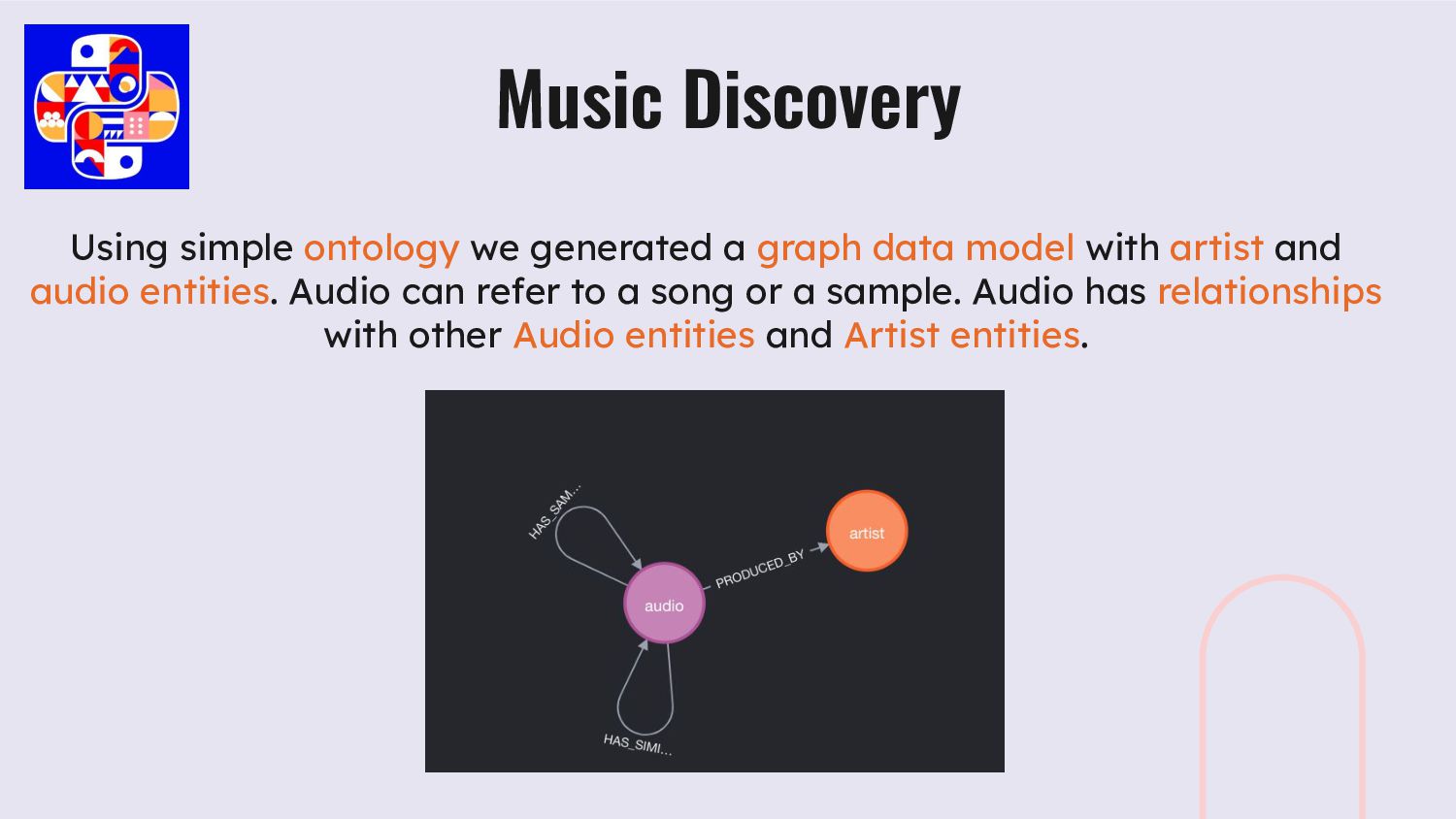
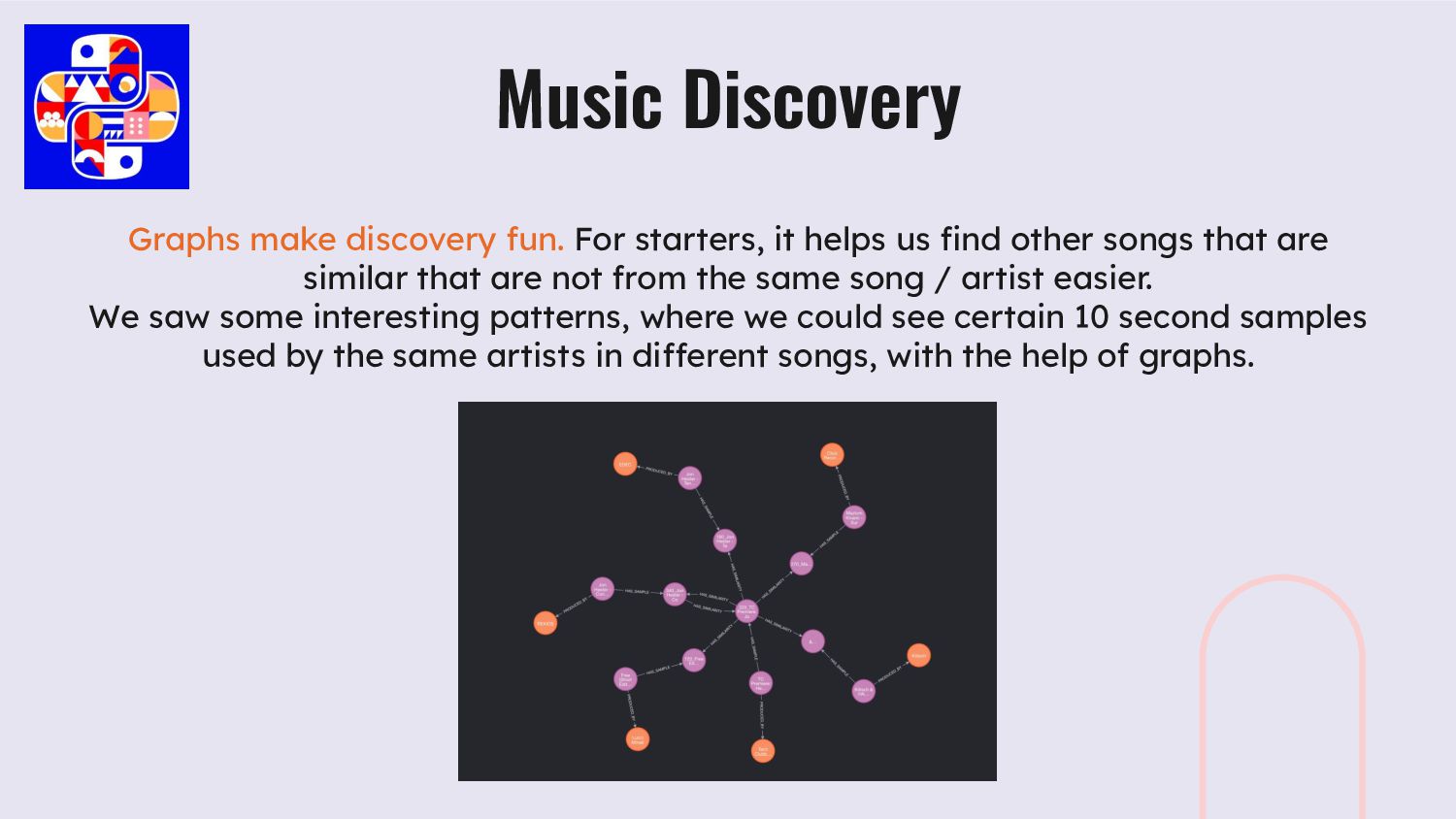
artist and audio entities. Audio can refer to a song or a sample. Audio has relationships with other Audio entities and Artist entities. Music Discovery
other songs that are similar that are not from the same song / artist easier. We saw some interesting patterns, where we could see certain 10 second samples used by the same artists in different songs, with the help of graphs. Music Discovery
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}