Every day, in scientific research and business applications, we rely on statistics and machine learning as our support tools for predictive modeling. To satisfy our desire of modeling uncertainty, to predict trends and to predict patterns that may occur in future, we developed a vast library of tools for decision making. In other words, we learned to take advantage of computers to replicate the real world, making intuitive decisions more quantitative, labeling unlabeled data, predicting trends, and ultimately trying to predict the future. Now, whether we are applying predictive modeling techniques to our research or business problems, we want to make "good" predictions!
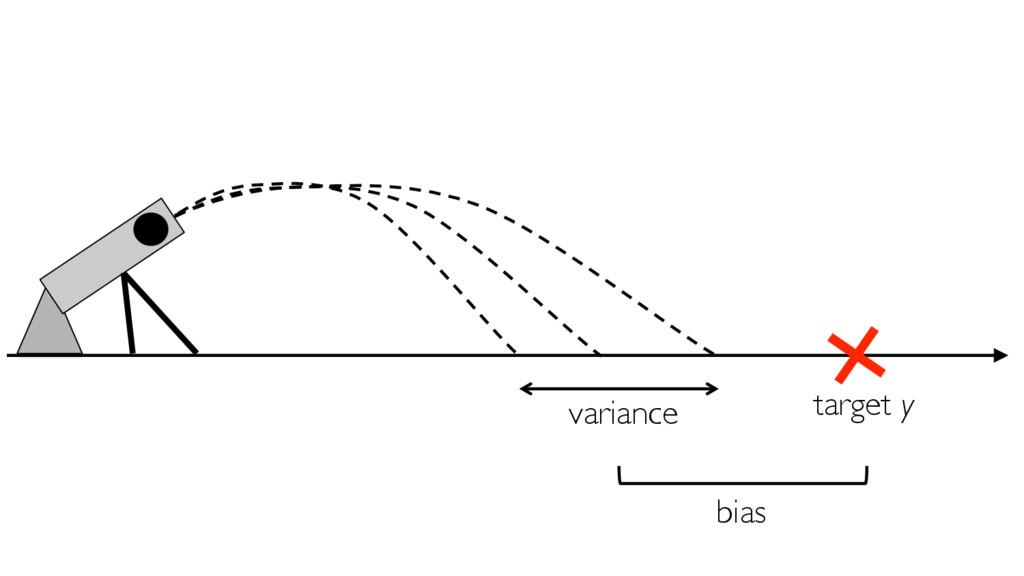
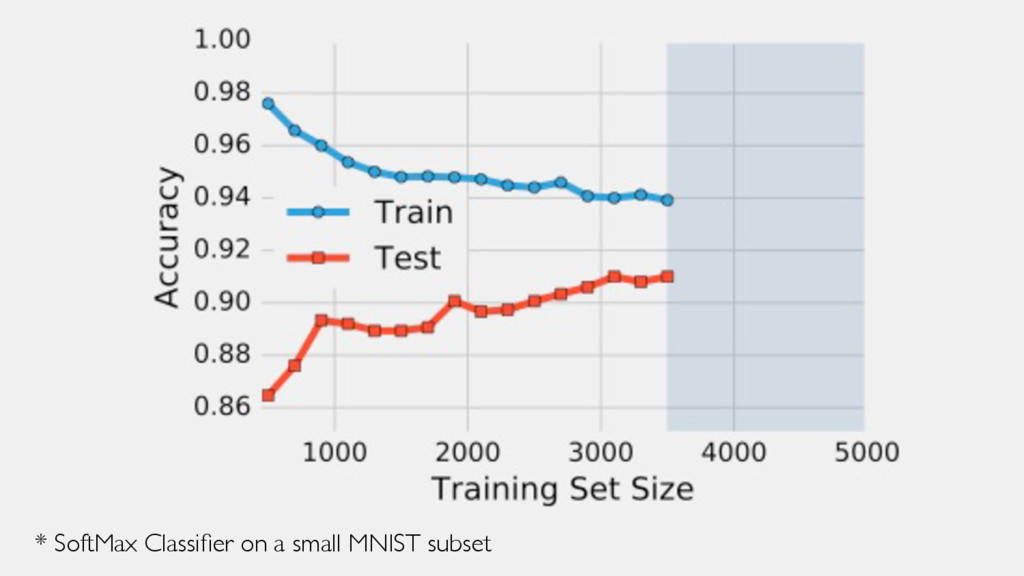
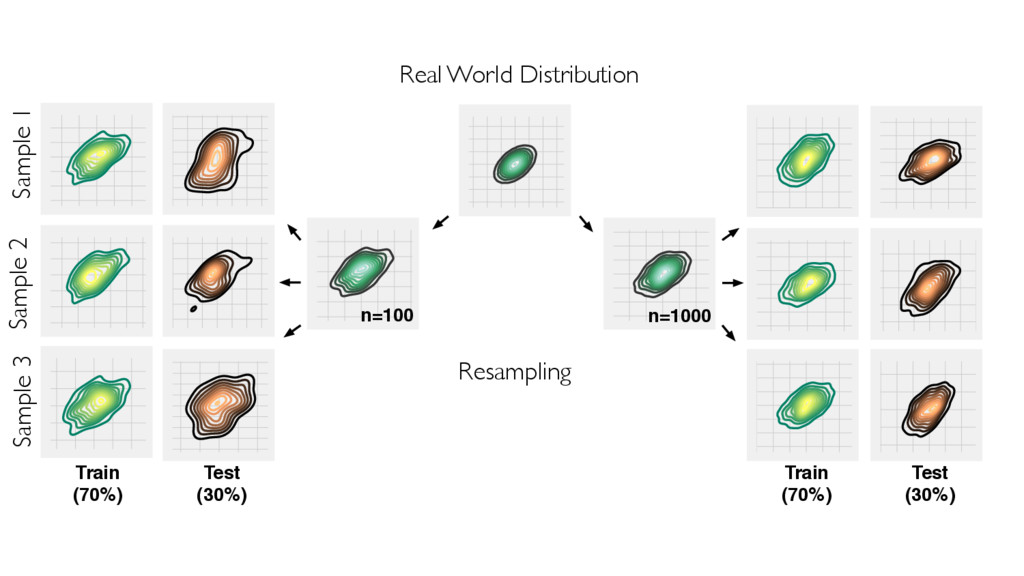
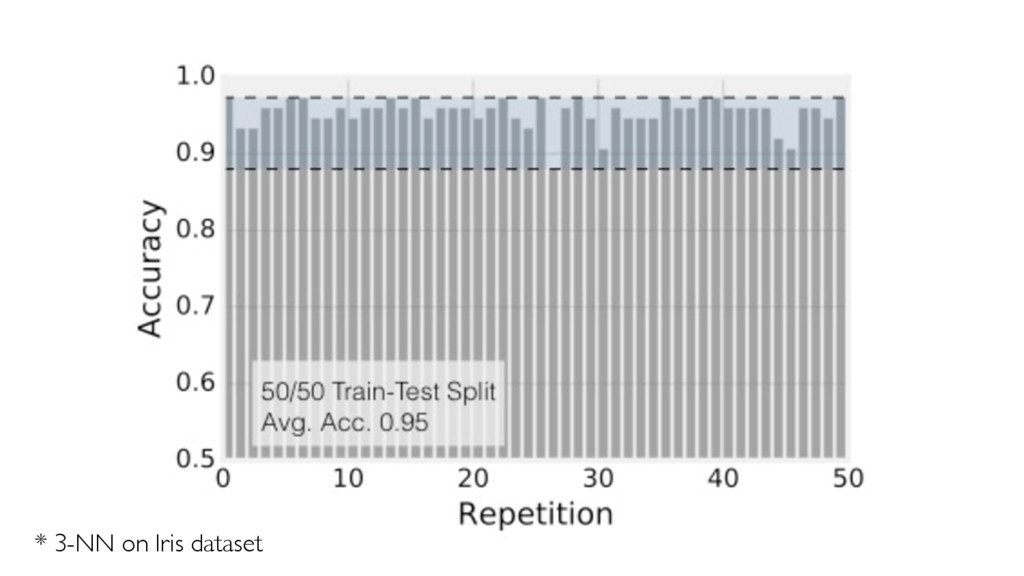
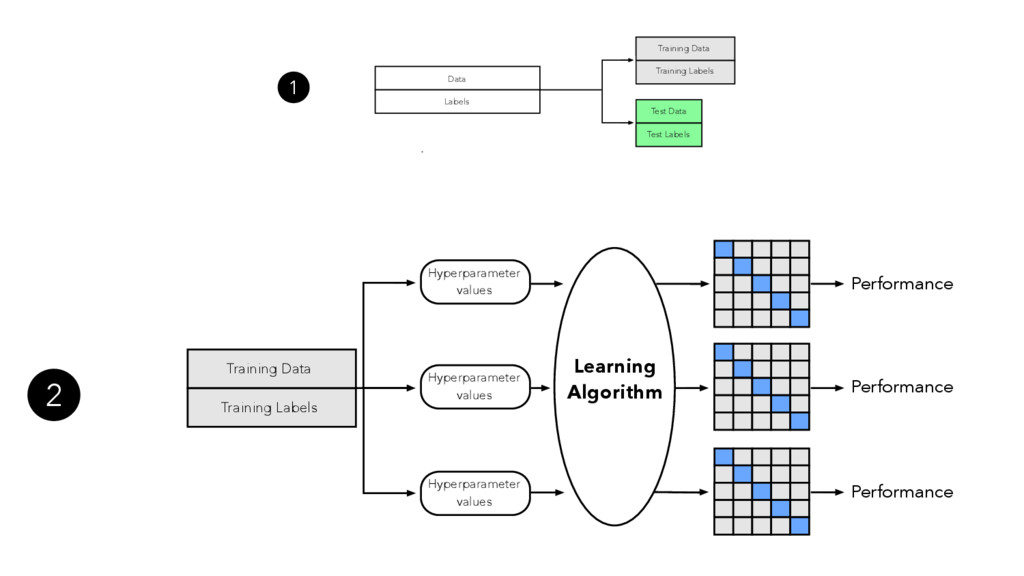
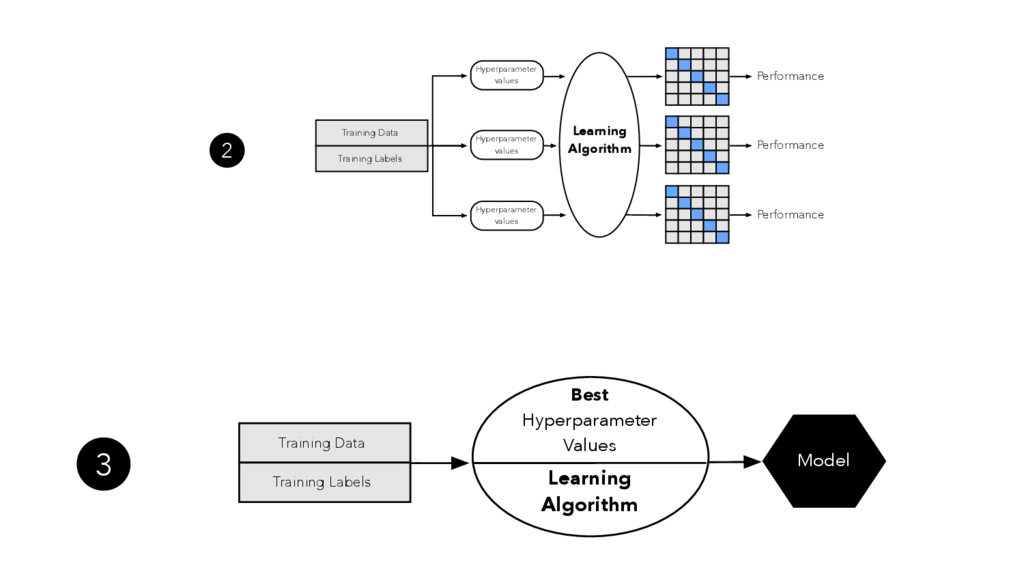
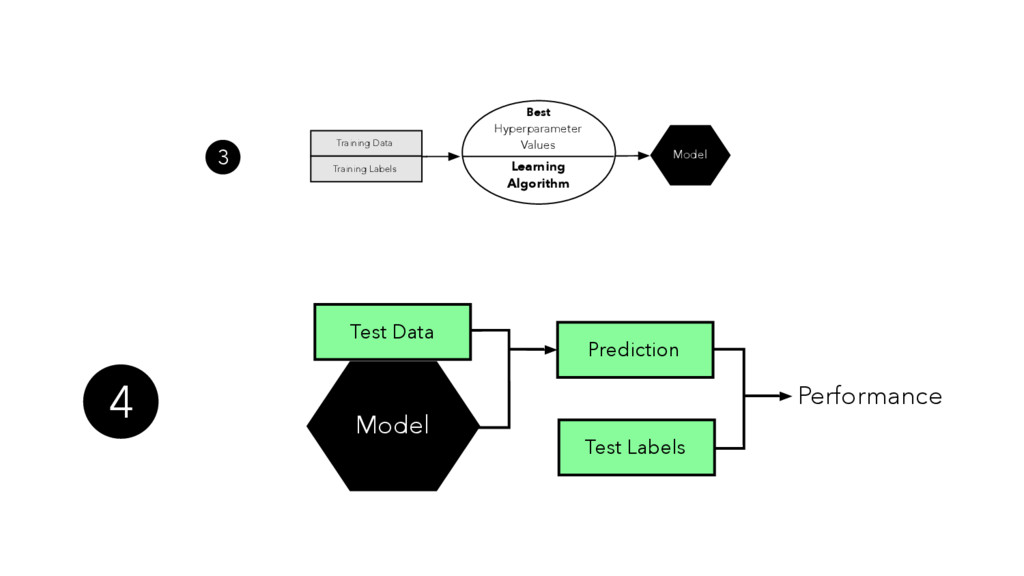
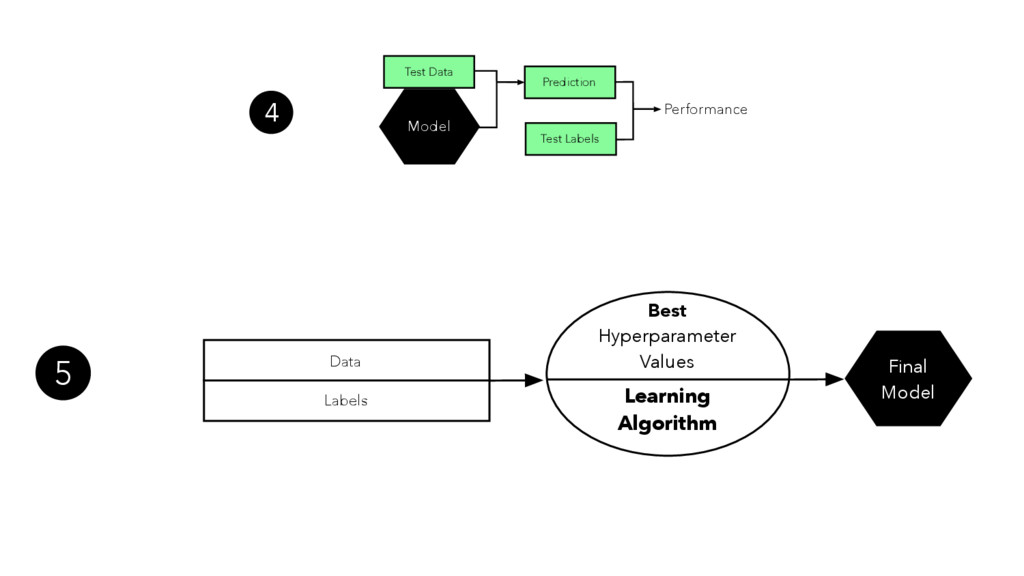
In the presence of modern machine learning libraries, choosing a machine learning algorithm to fit a model to our training data has never been that simple. However, making sure that our model generalizes well to unseen data is still up to us — the machine learning practitioners and researchers. In this talk, we will discuss the two most important components of various estimators of generalization performance: bias and variance. We will discuss how we can make the best use of our data at hand — proper (re)sampling -- and how to pick appropriate performance metrics. Then, we will compare various techniques for algorithm selection and model selection to find the right tool and approach for our task at hand. In the context of the "bias-variance trade-off," we will go over potential weaknesses in common modeling techniques, and we will learn how to take uncertainty into account to build predictive model performs well on unseen data.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![https://github.com/rasbt [email protected] http://sebastianraschka.com @rasbt](https://files.speakerdeck.com/presentations/7dfe2b945afc4fbcbe0ca8e469407acd/slide_33.jpg){kind=link}