Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ストリーム処理基盤のFlink移行検証と適材適所の実践
Search
Recruit
PRO
June 09, 2026
Technology
110
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ストリーム処理基盤のFlink移行検証と適材適所の実践
2026/6/2に、Data Streaming World Tour 2026で発表した田村の資料になります。
Recruit
PRO
June 09, 2026
More Decks by Recruit
See All by Recruit
開発が速く安くなった後の話 AI時代のソフトウェアエンジニアリング組織論 #devsumi
recruitengineers
PRO
24
11k
双方向推薦システムにおける長期的マッチング最大化に向けた代理目的関数の設計と実証
recruitengineers
PRO
1
110
就職⽀援サービスにおけるキャリアアドバイザーのシフトスケジューリング
recruitengineers
PRO
1
190
Model Routerを使った逐次LLM選択による毀損低減効果の検証
recruitengineers
PRO
2
71
AI 時代の Platform Engineering
recruitengineers
PRO
3
470
巨大プラットフォームを進化させる「第3のROI」
recruitengineers
PRO
2
3.6k
データ戦略を加速させる プラットフォーム エンジニアリングと進化的アーキテクチャ
recruitengineers
PRO
3
120
まなび領域における生成AI活用事例
recruitengineers
PRO
2
330
AI時代にエンジニアはどう成長すれば良いのか?
recruitengineers
PRO
2
590
Other Decks in Technology
See All in Technology
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
220
ボーイスカウトルールでメモリやスキルを改善しよう
azukiazusa1
4
1.3k
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
140
シンガポールで登壇してきます
yama3133
0
210
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
160
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
2
390
美しいコードを書くためにF#を学んでみた話
yud0uhu
1
440
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
4.4k
ポストモーテム! DDoSからサイトは守れた。 でもビジネスは守れなかった。
bengo4com
1
3.1k
ガバナンスの「ちょうどいい落とし所」を探れ!開発スピードを妨げない運用判断の勘所 / SRE NEXT 2026
genda
1
180
AIレビューはどこまで任せられるのか?自動化と人が背負うレビューの境界
sansantech
PRO
3
940
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
280
Featured
See All Featured
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
190
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
How STYLIGHT went responsive
nonsquared
100
6.2k
Docker and Python
trallard
47
4k
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Product Roadmaps are Hard
iamctodd
55
12k
Six Lessons from altMBA
skipperchong
29
4.3k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.5k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Building Adaptive Systems
keathley
44
3.1k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Transcript
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved ストリーム処理基盤の
Flink移行検証と適材適所の実践 株式会社インディードリクルートテクノロジーズ プロダクト統括本部 データ データソリューションユニット データエンジニアリング部 田村 優友 2026/06/02 Data Streaming World Tour 2026: Tokyo
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 株式会社インディードリクルートテクノロジーズ
プロダクト統括本部 データ データソリューションユニット データエンジニアリング部 2015-2021 大手メーカーでWebアプリケーションの開発に従事 2021-2024 株式会社リクルートにキャリア入社 HRプロダクトのデータエンジニアとして データ基盤やAPI、ETLパイプラインの開発を担当 2025-現在 組織再編に伴い株式会社インディードリクルート テクノロジーズへ出向 引き続きHRプロダクトのデータエンジニアとして従事 田村 優友 Tamura Yusuke 写真 Profile 経歴 所属 2
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 3
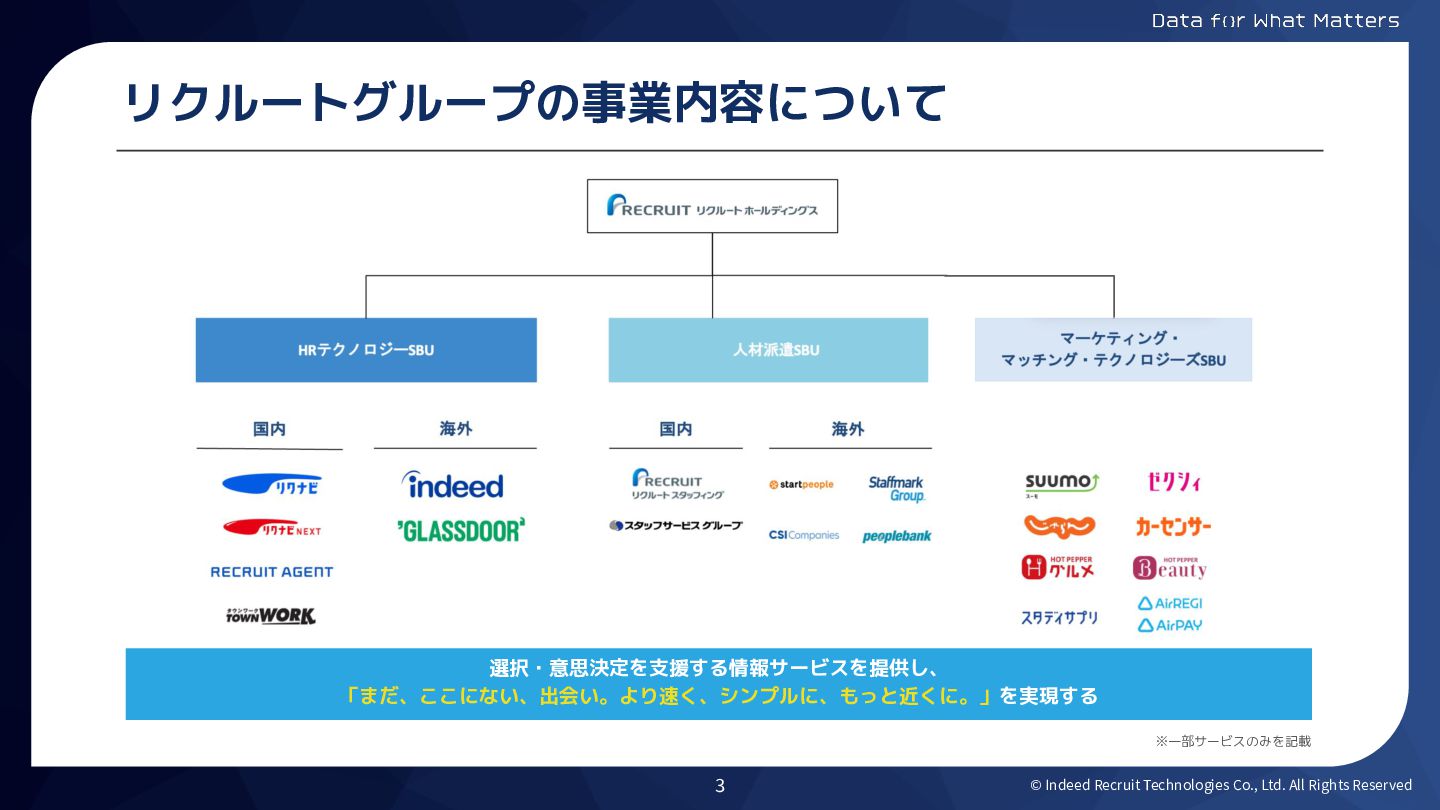
リクルートグループの事業内容について 選択・意思決定を支援する情報サービスを提供し、 「まだ、ここにない、出会い。より速く、シンプルに、もっと近くに。」を実現する ※一部サービスのみを記載
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved HRテクノロジーSBUのビジネスモデルについて
テクノロジーの力でマッチングを速く、シンプルに、もっと近くに • 求職者の皆様とクライアントの皆様の間に立ち、Indeed PLUSといった求人プラットフォームを 通じて、双方にとって最適なマッチングを提供 • 当社グループのマッチングエンジンを活用し、採用活動の効率化を推進 4
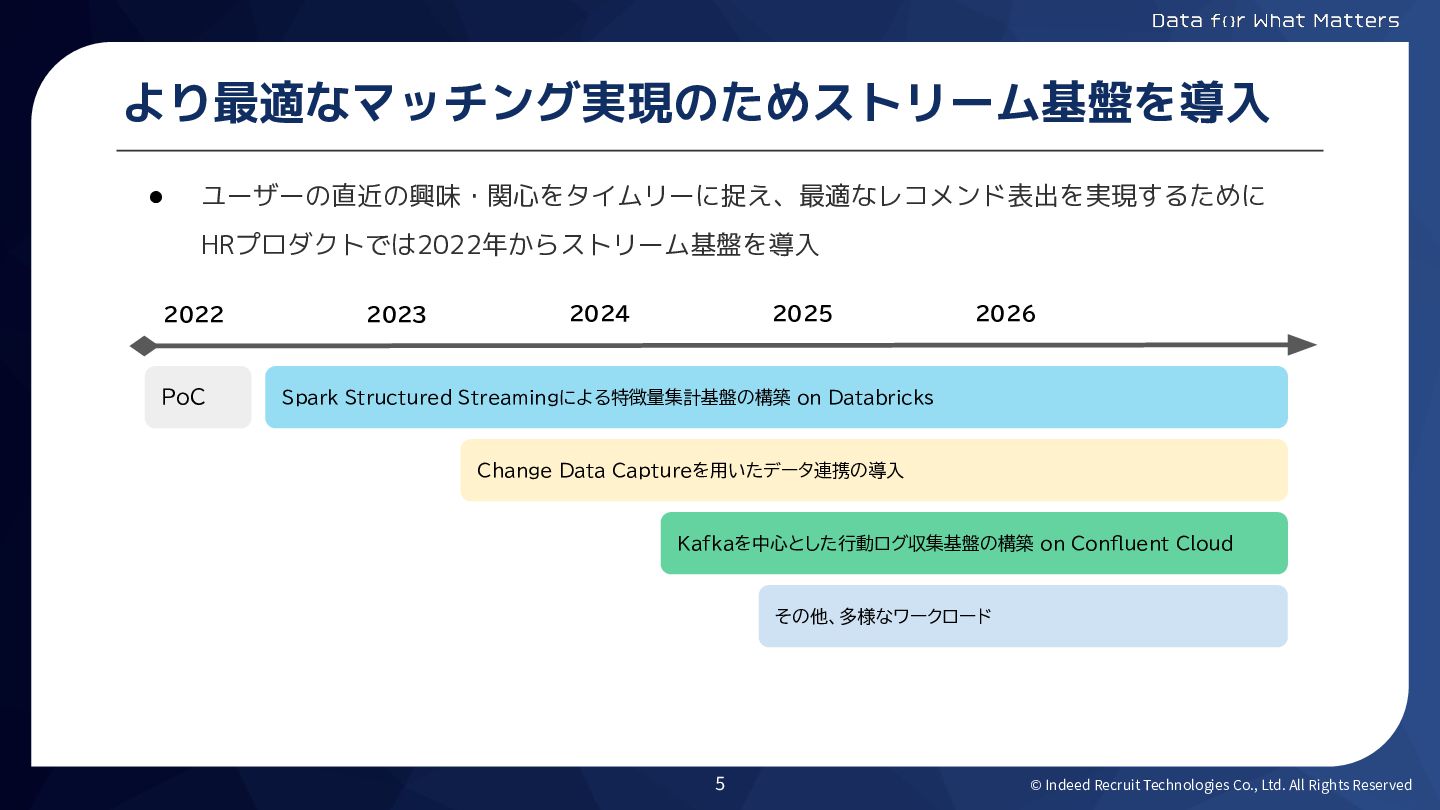
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved より最適なマッチング実現のためストリーム基盤を導入
• ユーザーの直近の興味・関心をタイムリーに捉え、最適なレコメンド表出を実現するために HRプロダクトでは2022年からストリーム基盤を導入 2022 PoC Spark Structured Streamingによる特徴量集計基盤の構築 on Databricks Change Data Captureを用いたデータ連携の導入 Kafkaを中心とした行動ログ収集基盤の構築 on Confluent Cloud 2023 2024 2025 2026 その他、多様なワークロード 5
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 本日の内容
6 • Spark Structured Streaming を用いた現行の機械学習モデル向けの特徴量集計基盤が抱える レイテンシとコストの課題 • 上記の Confluent Cloud for Apache Flink への移行検証プロセス • ワークロードの特性に応じた Flink と Spark の使い分けと判断基準
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 移行検証
概要
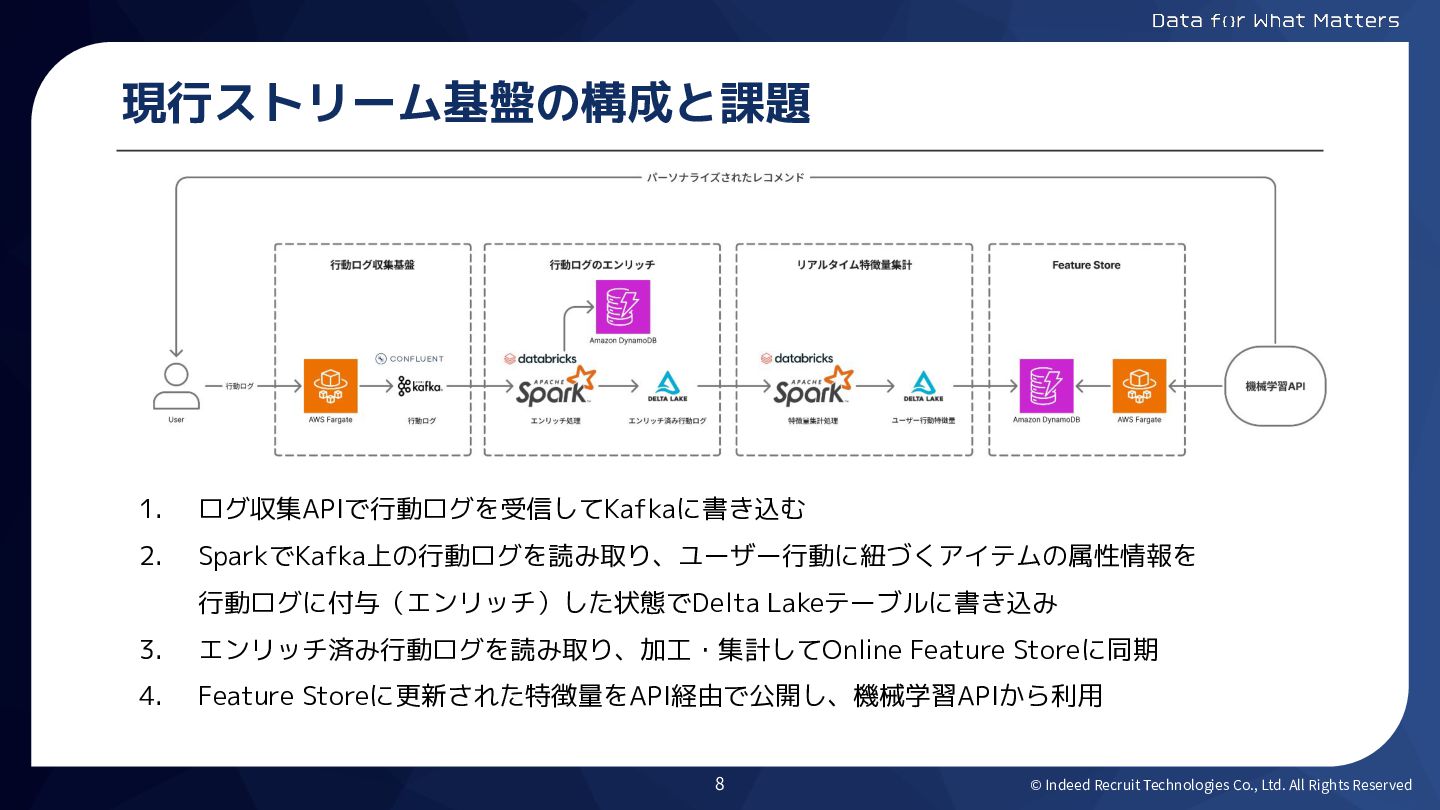
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 現行ストリーム基盤の構成と課題
1. ログ収集APIで行動ログを受信してKafkaに書き込む 2. SparkでKafka上の行動ログを読み取り、ユーザー行動に紐づくアイテムの属性情報を 行動ログに付与(エンリッチ)した状態でDelta Lakeテーブルに書き込み 3. エンリッチ済み行動ログを読み取り、加工・集計してOnline Feature Storeに同期 4. Feature Storeに更新された特徴量をAPI経由で公開し、機械学習APIから利用 8
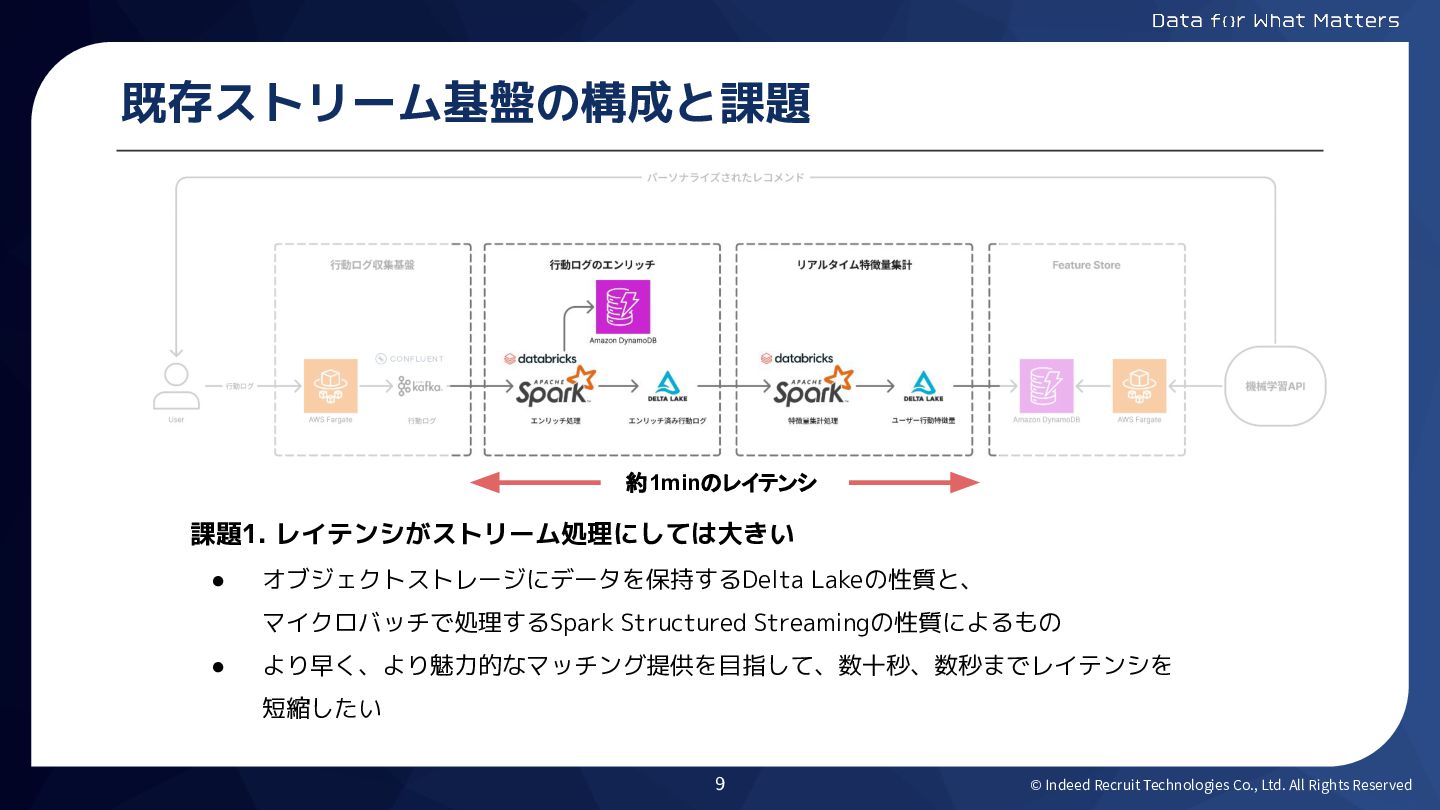
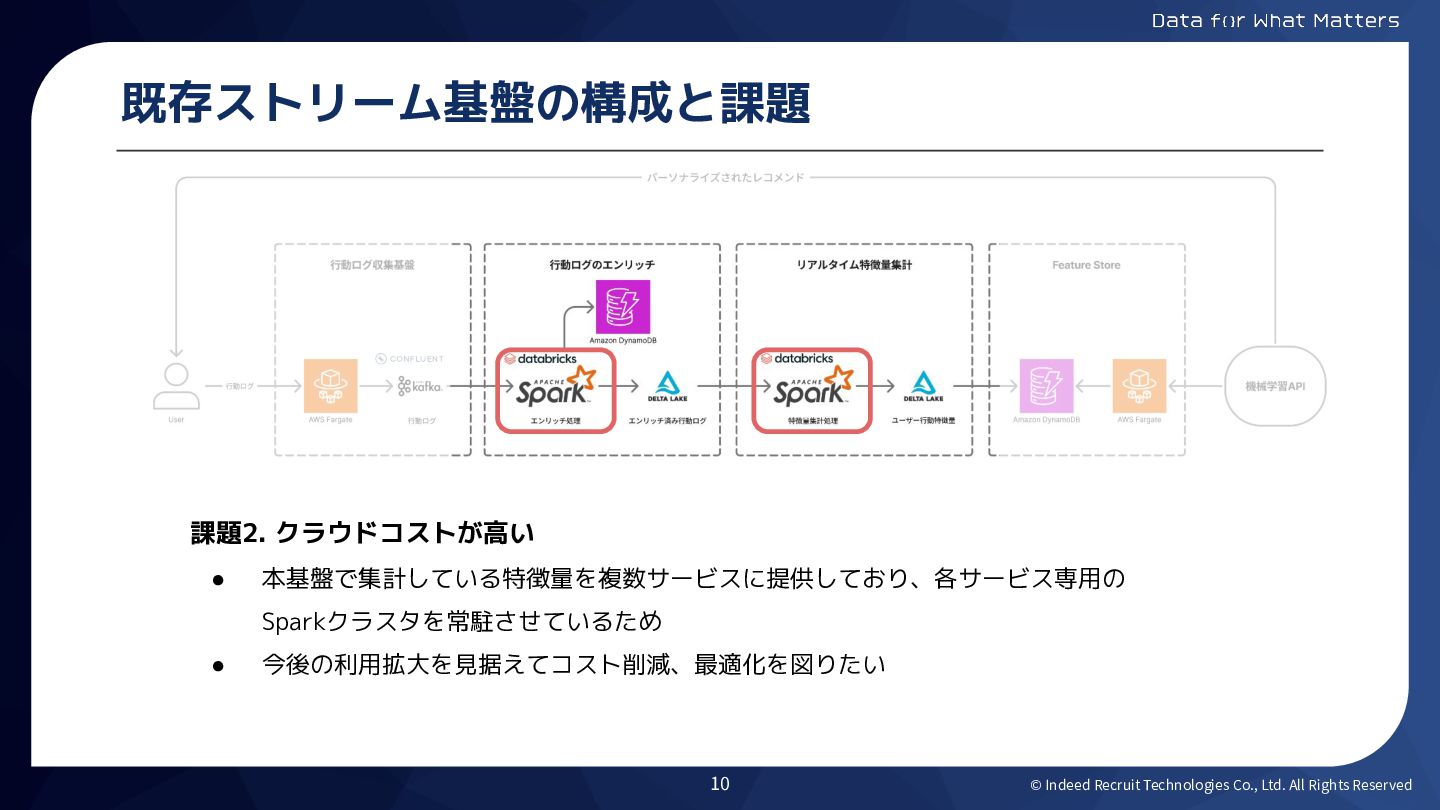
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 既存ストリーム基盤の構成と課題
約1minのレイテンシ 課題1. レイテンシがストリーム処理にしては大きい • オブジェクトストレージにデータを保持するDelta Lakeの性質と、 マイクロバッチで処理するSpark Structured Streamingの性質によるもの • より早く、より魅力的なマッチング提供を目指して、数十秒、数秒までレイテンシを 短縮したい 9
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 既存ストリーム基盤の構成と課題
課題2. クラウドコストが高い • 本基盤で集計している特徴量を複数サービスに提供しており、各サービス専用の Sparkクラスタを常駐させているため • 今後の利用拡大を見据えてコスト削減、最適化を図りたい 10
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved Flink移行検証の目的とスコープ
スコープ • 行動ログのエンリッチ処理 • リアルタイム特徴量集計処理 目的 • Confluent Cloud for Apache Flink の採用により、前述したレイテンシとコストの課題が 解決できるかを見定める ◦ Confluent Cloud for Apache Flink がフルマネージドかつサーバーレスであるため、 副次的効果として運用コストの削減も狙う • 現行基盤(Spark Structured Streaming + DeltaTable)との比較を通して、 HRプロダクトにおけるストリーム処理の実装方針を定める 11
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 行動ログのエンリッチ処理の移行
検証 1
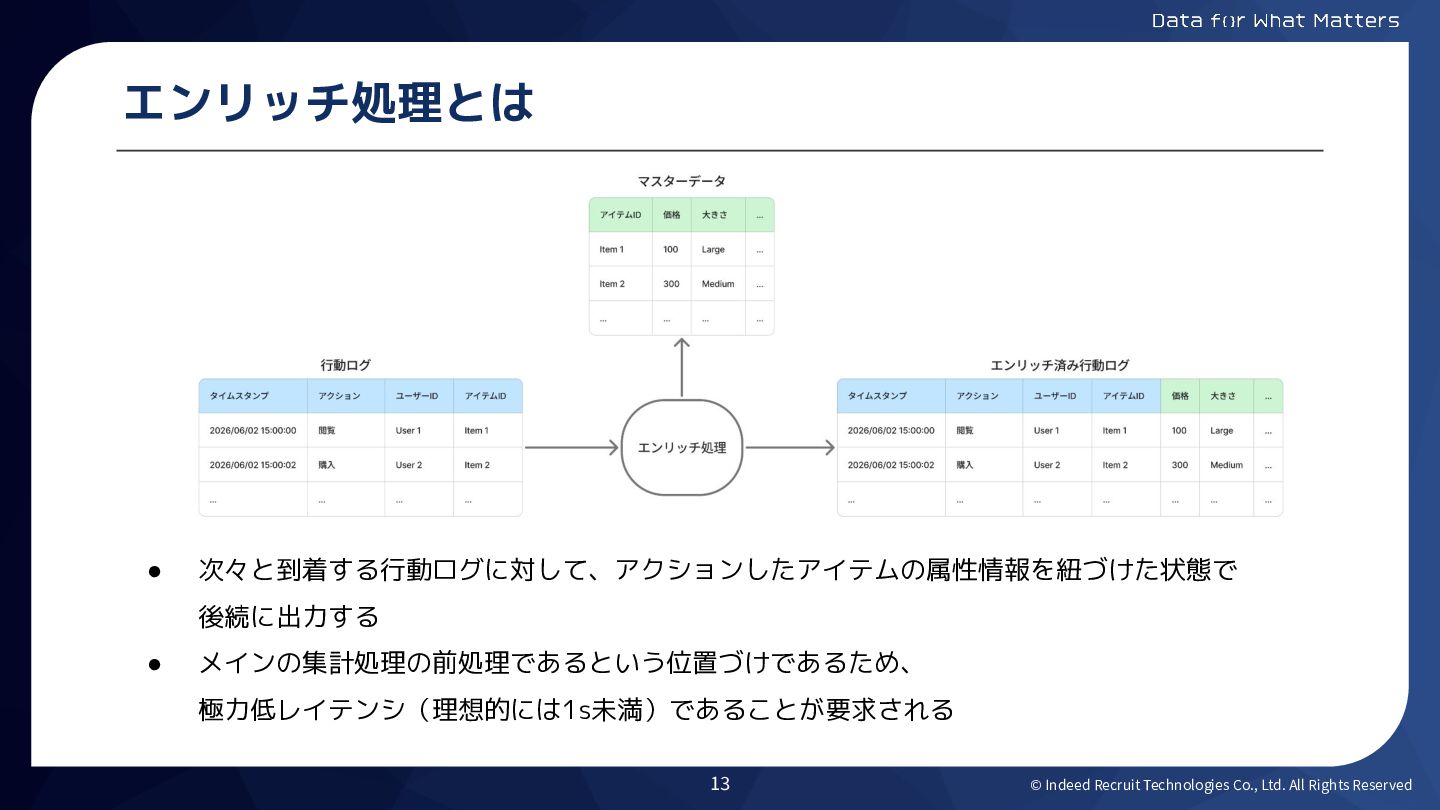
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved エンリッチ処理とは
• 次々と到着する行動ログに対して、アクションしたアイテムの属性情報を紐づけた状態で 後続に出力する • メインの集計処理の前処理であるという位置づけであるため、 極力低レイテンシ(理想的には1s未満)であることが要求される 13
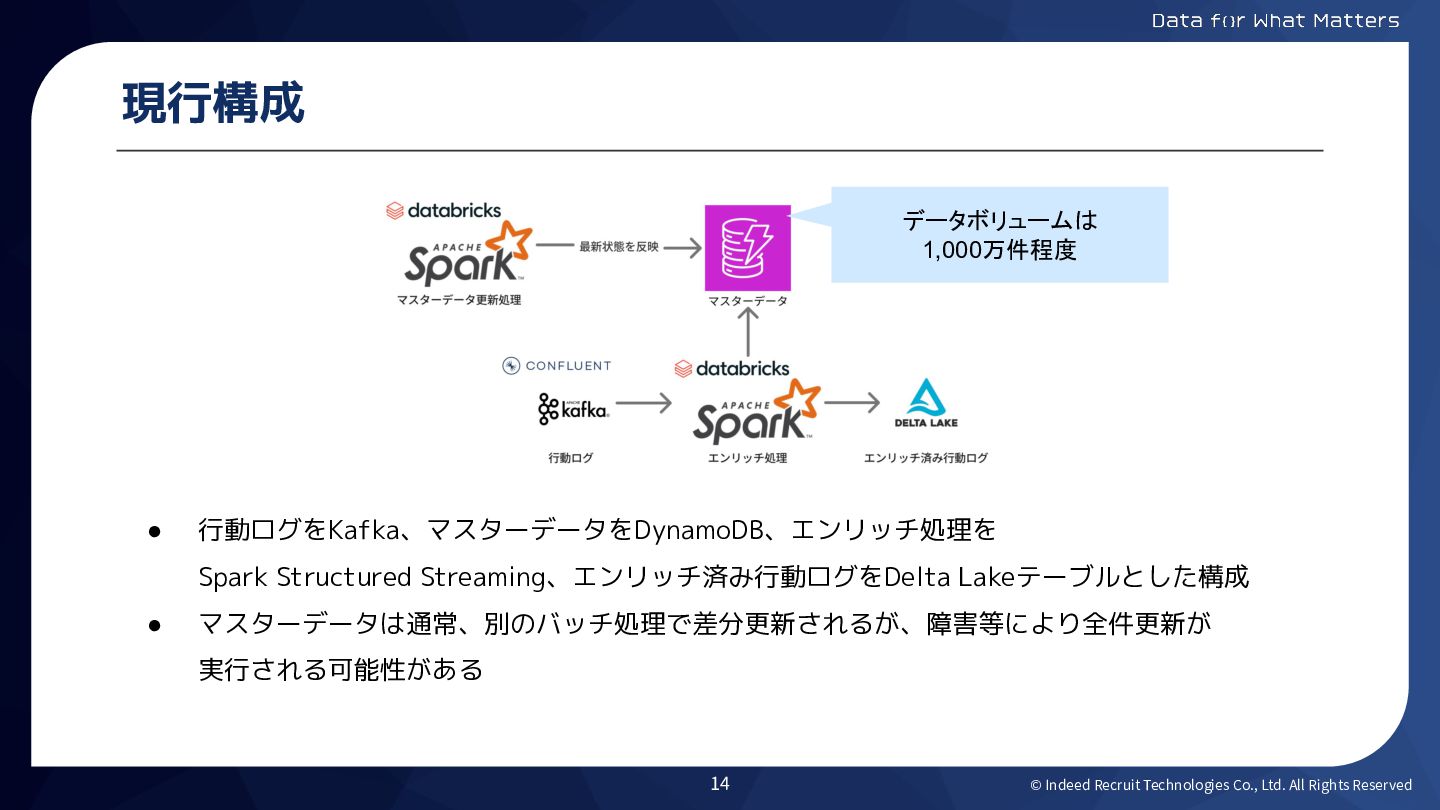
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 現行構成
• 行動ログをKafka、マスターデータをDynamoDB、エンリッチ処理を Spark Structured Streaming、エンリッチ済み行動ログをDelta Lakeテーブルとした構成 • マスターデータは通常、別のバッチ処理で差分更新されるが、障害等により全件更新が 実行される可能性がある データボリュームは 1,000万件程度 14
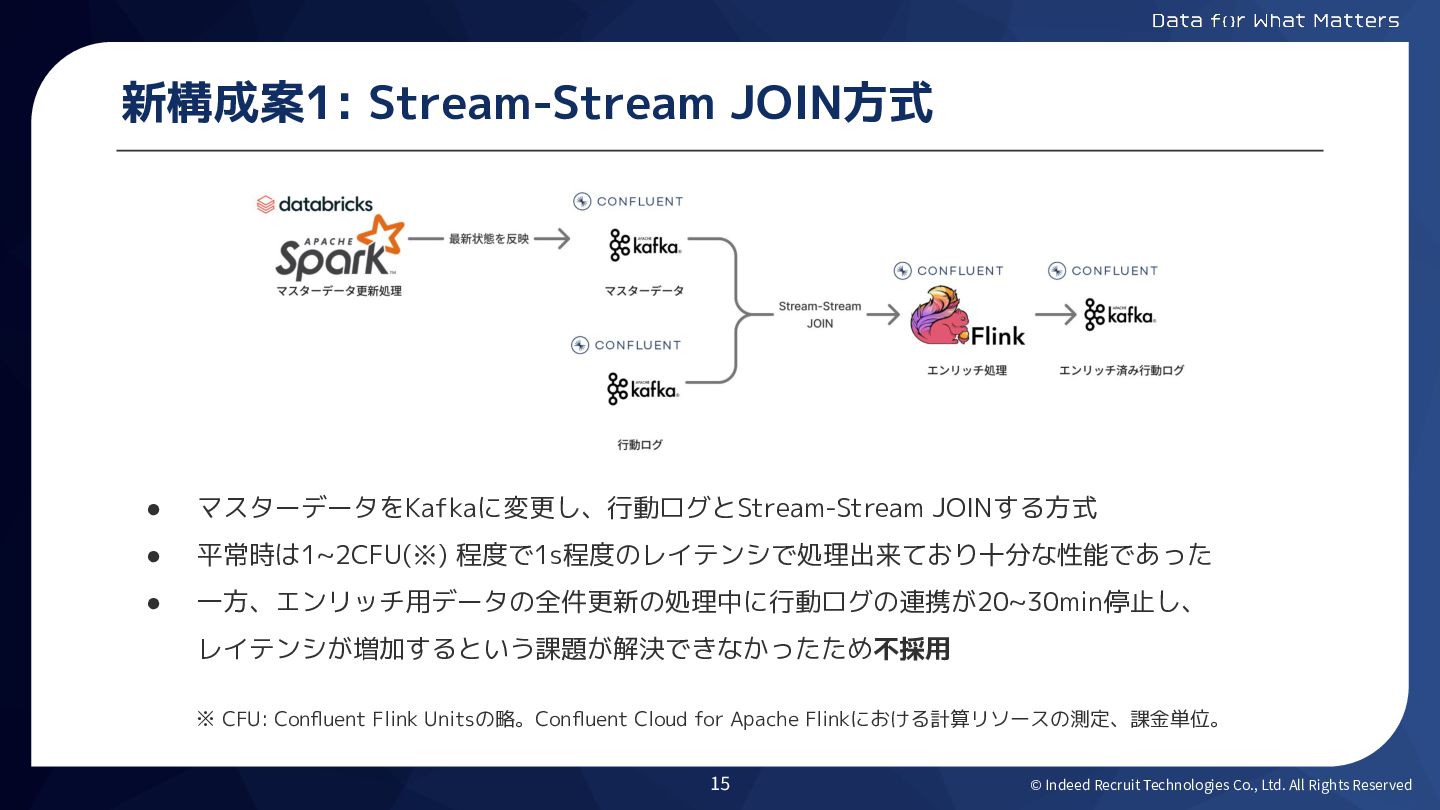
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 新構成案1:
Stream-Stream JOIN方式 • マスターデータをKafkaに変更し、行動ログとStream-Stream JOINする方式 • 平常時は1~2CFU(※) 程度で1s程度のレイテンシで処理出来ており十分な性能であった • 一方、エンリッチ用データの全件更新の処理中に行動ログの連携が20~30min停止し、 レイテンシが増加するという課題が解決できなかったため不採用 15 ※ CFU: Confluent Flink Unitsの略。Confluent Cloud for Apache Flinkにおける計算リソースの測定、課金単位。
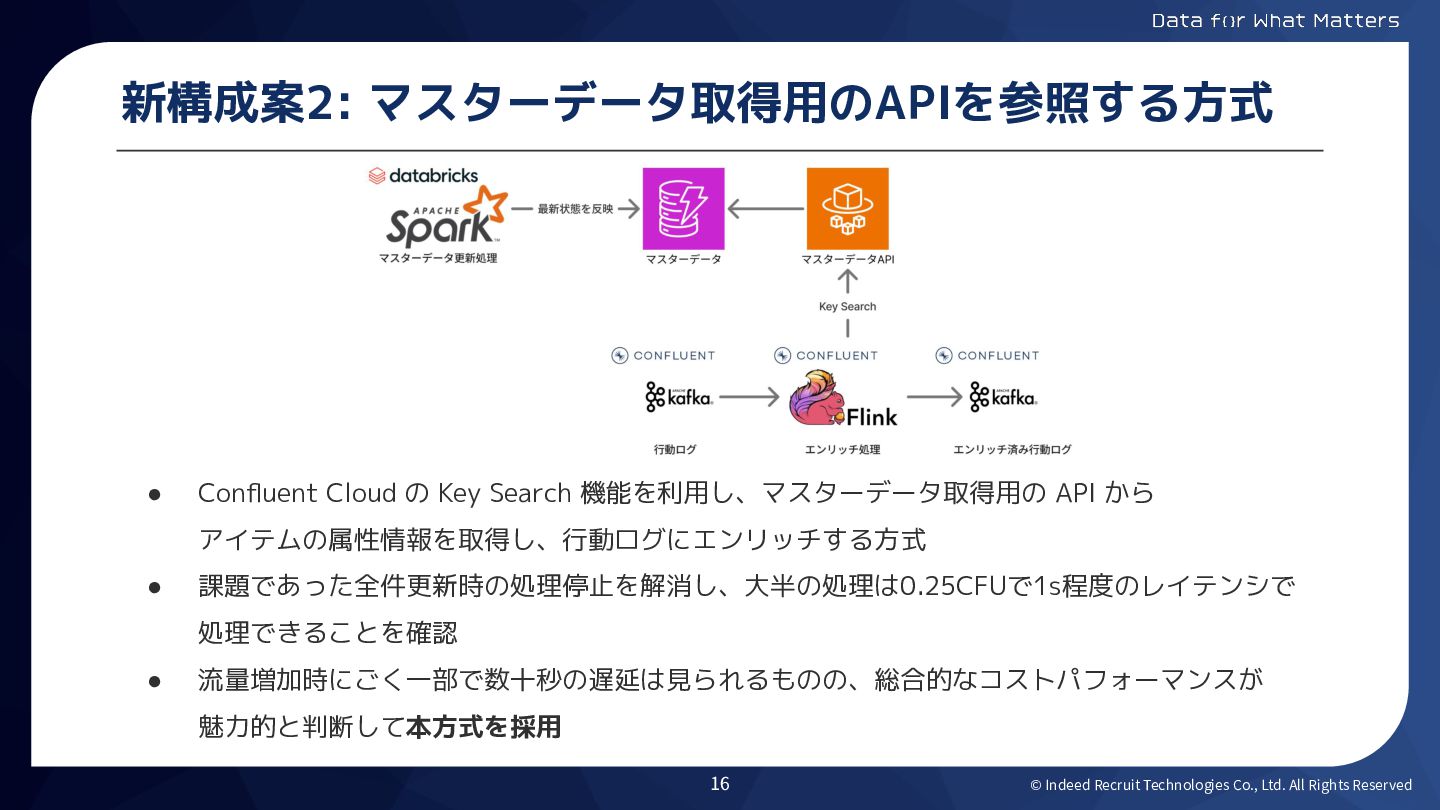
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 新構成案2:
マスターデータ取得用のAPIを参照する方式 • Confluent Cloud の Key Search 機能を利用し、マスターデータ取得用の API から アイテムの属性情報を取得し、行動ログにエンリッチする方式 • 課題であった全件更新時の処理停止を解消し、大半の処理は0.25CFUで1s程度のレイテンシで 処理できることを確認 • 流量増加時にごく一部で数十秒の遅延は見られるものの、総合的なコストパフォーマンスが 魅力的と判断して本方式を採用 16
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 特徴量集計処理の移行
検証 2
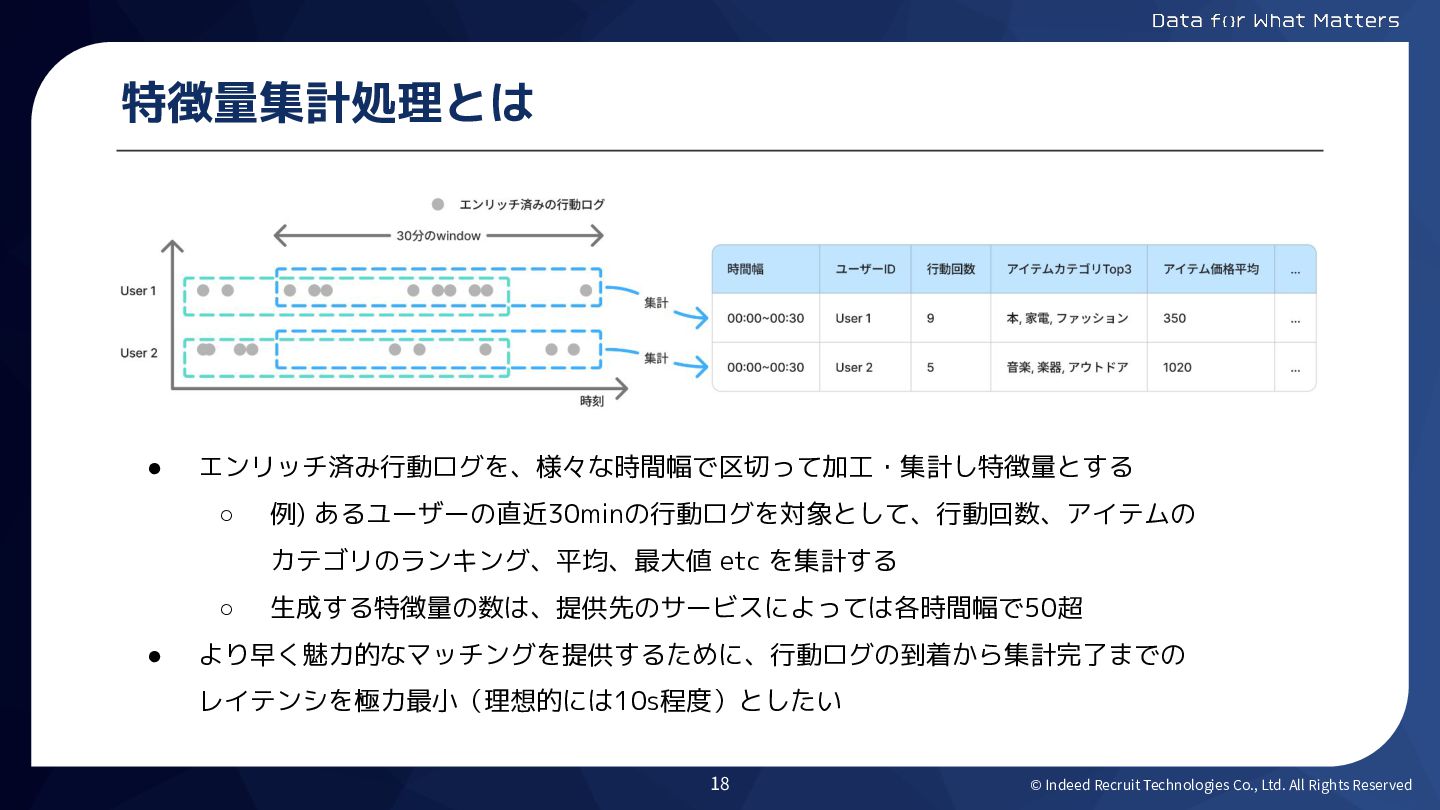
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 特徴量集計処理とは
• エンリッチ済み行動ログを、様々な時間幅で区切って加工・集計し特徴量とする ◦ 例) あるユーザーの直近30minの行動ログを対象として、行動回数、アイテムの カテゴリのランキング、平均、最大値 etc を集計する ◦ 生成する特徴量の数は、提供先のサービスによっては各時間幅で50超 • より早く魅力的なマッチングを提供するために、行動ログの到着から集計完了までの レイテンシを極力最小(理想的には10s程度)としたい 18
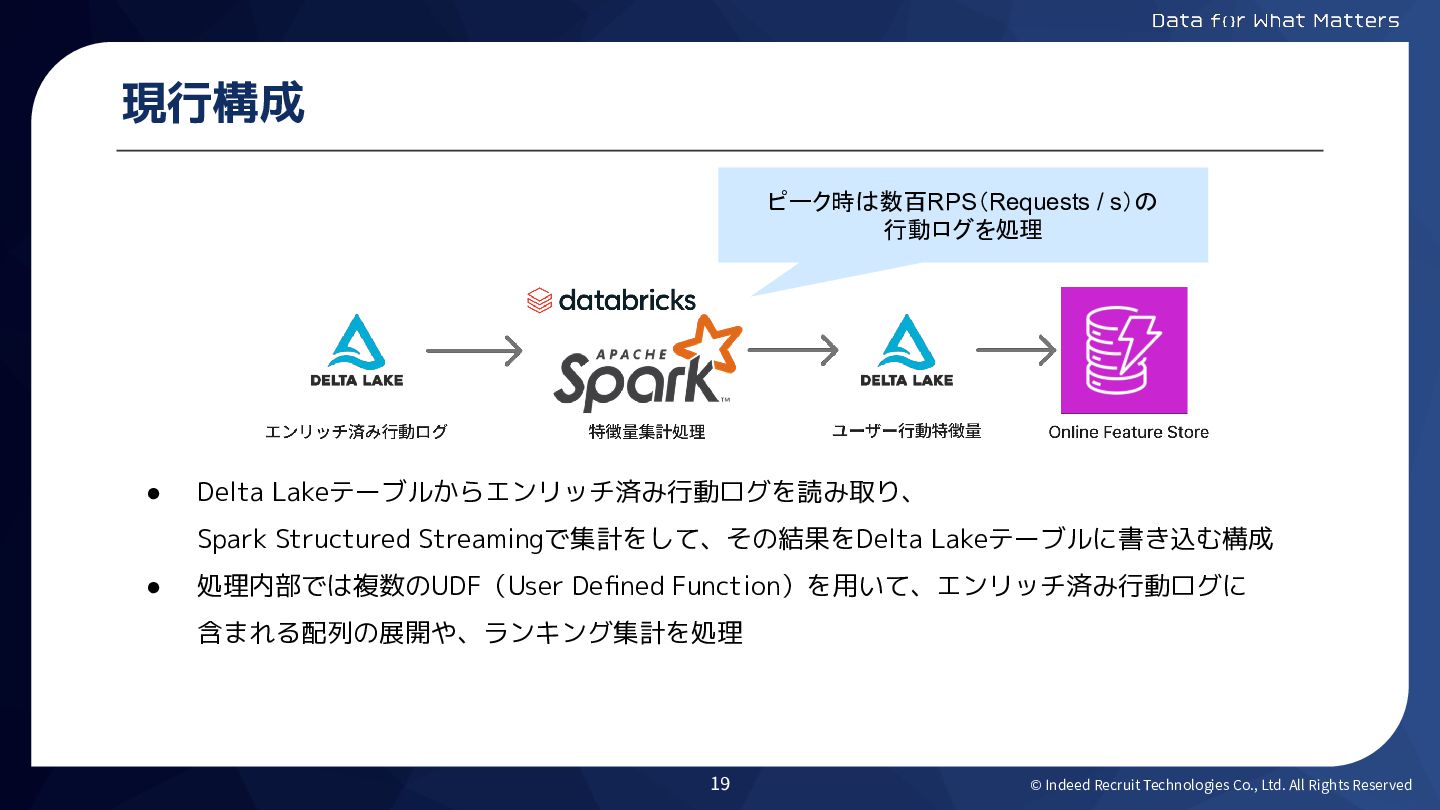
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 現行構成
• Delta Lakeテーブルからエンリッチ済み行動ログを読み取り、 Spark Structured Streamingで集計をして、その結果をDelta Lakeテーブルに書き込む構成 • 処理内部では複数のUDF(User Defined Function)を用いて、エンリッチ済み行動ログに 含まれる配列の展開や、ランキング集計を処理 ピーク時は数百RPS(Requests / s)の 行動ログを処理 19
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 現行の特徴量集計処理の内訳
20
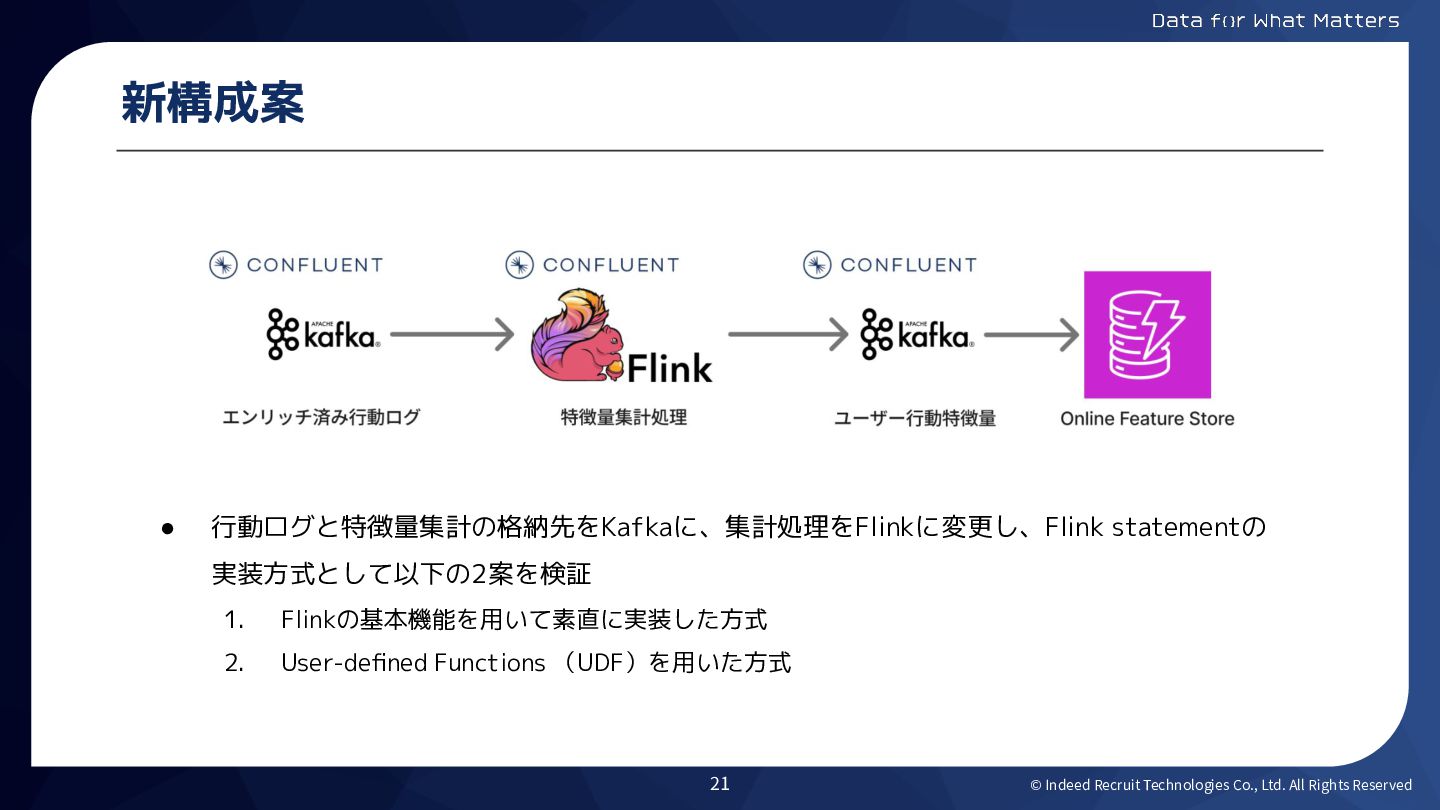
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 新構成案
• 行動ログと特徴量集計の格納先をKafkaに、集計処理をFlinkに変更し、Flink statementの 実装方式として以下の2案を検証 1. Flinkの基本機能を用いて素直に実装した方式 2. User-defined Functions (UDF)を用いた方式 21
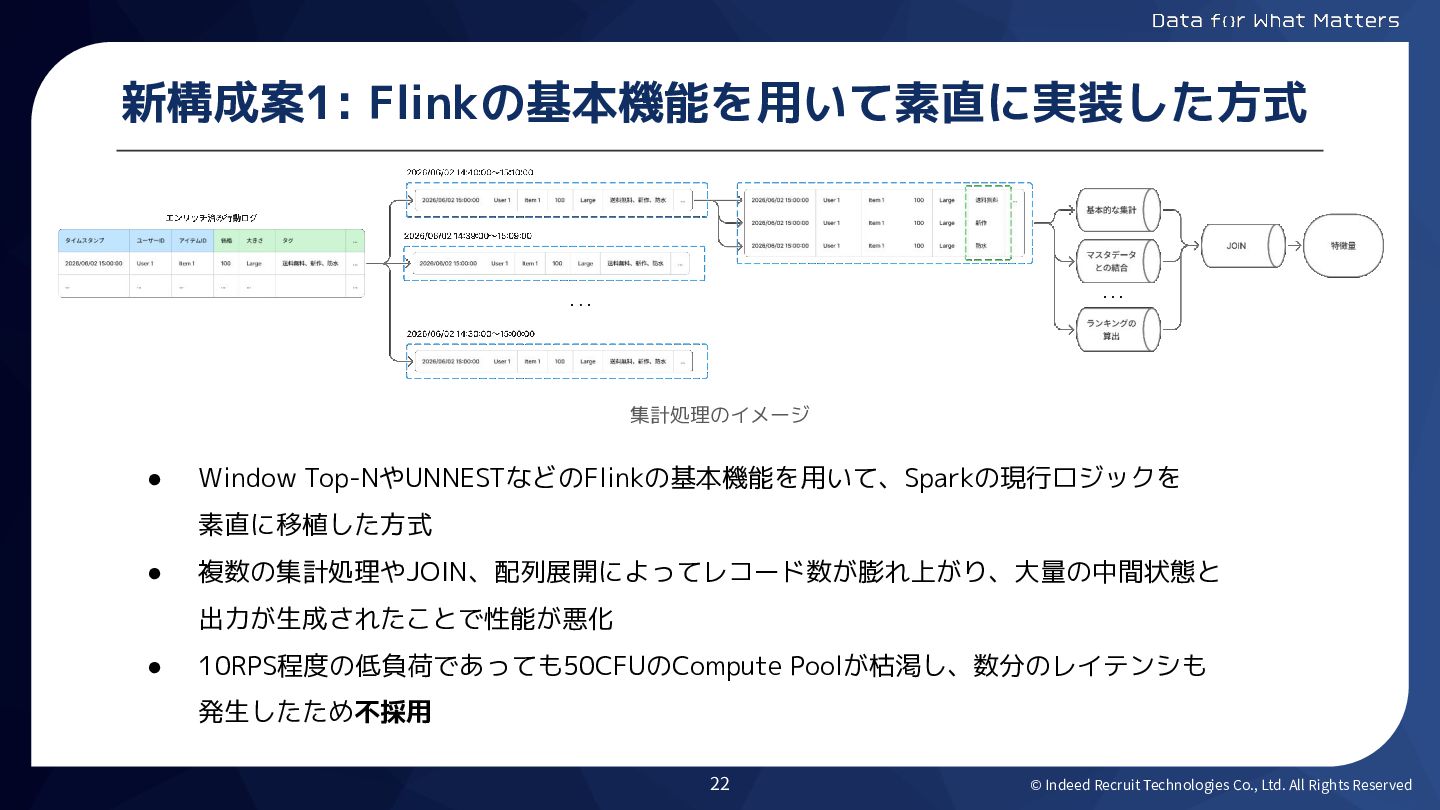
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 新構成案1:
Flinkの基本機能を用いて素直に実装した方式 • Window Top-NやUNNESTなどのFlinkの基本機能を用いて、Sparkの現行ロジックを 素直に移植した方式 • 複数の集計処理やJOIN、配列展開によってレコード数が膨れ上がり、大量の中間状態と 出力が生成されたことで性能が悪化 • 10RPS程度の低負荷であっても50CFUのCompute Poolが枯渇し、数分のレイテンシも 発生したため不採用 集計処理のイメージ 22
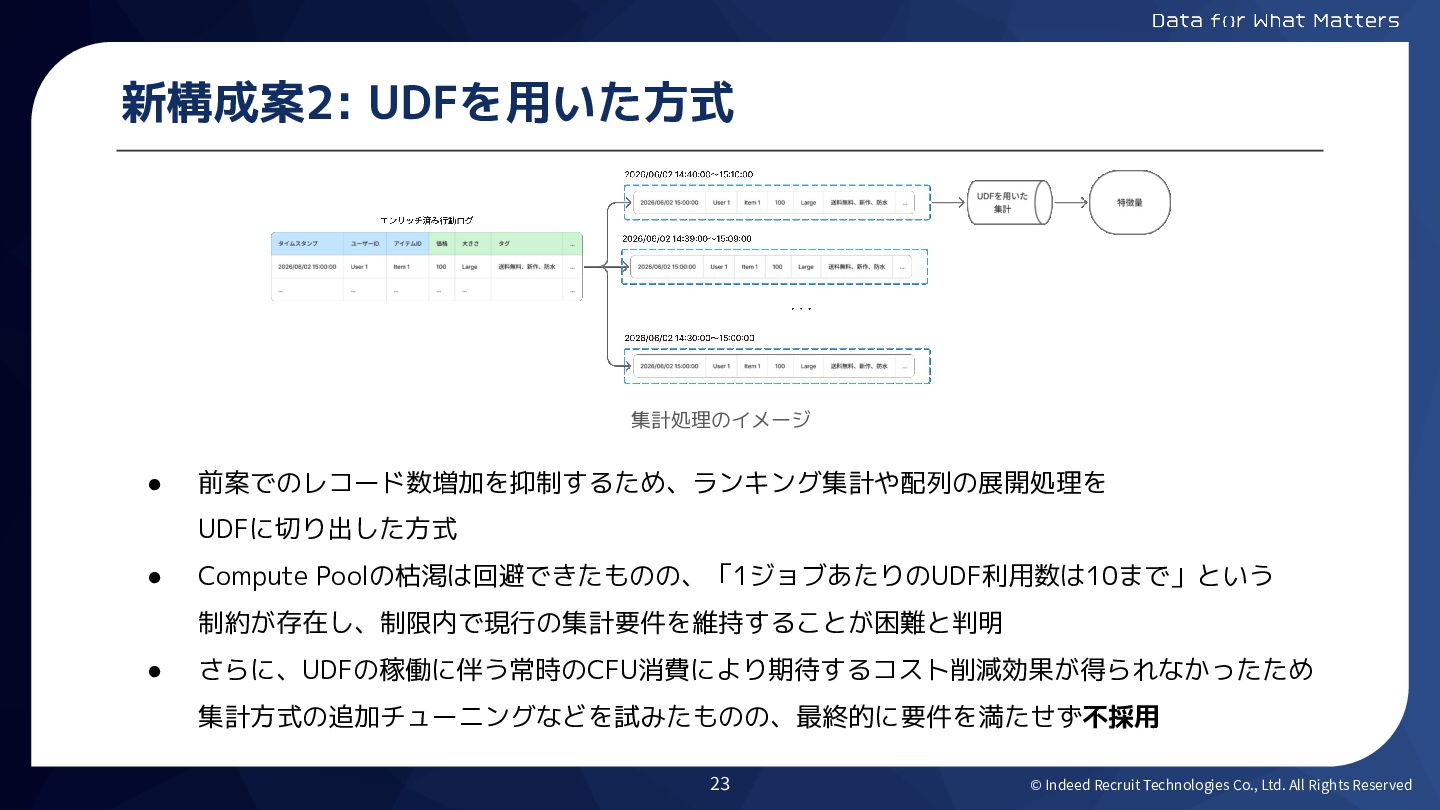
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 新構成案2:
UDFを用いた方式 • 前案でのレコード数増加を抑制するため、ランキング集計や配列の展開処理を UDFに切り出した方式 • Compute Poolの枯渇は回避できたものの、「1ジョブあたりのUDF利用数は10まで」という 制約が存在し、制限内で現行の集計要件を維持することが困難と判明 • さらに、UDFの稼働に伴う常時のCFU消費により期待するコスト削減効果が得られなかったため 集計方式の追加チューニングなどを試みたものの、最終的に要件を満たせず不採用 集計処理のイメージ 23
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved まとめ
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 結論
行動ログのエンリッチ処理 • Flinkを採用する ◦ 処理レイテンシを約20sから約1sへ短縮でき、月額コストについても約70%の削減が 見込まれるため 特徴量集計処理 • 引き続きSpark Structured Streamingを採用する ◦ UDFの利用数上限の中で、現行の集計要件を維持するためには大幅な設計変更が必要となる ◦ 上記に加えてUDFの利用自体に追加でコストがかかることも踏まえると 現行と比較してコストパフォーマンスの良い方法とならなかった 25
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved FlinkとSparkの使い分け
Flinkに寄せる領域 • 役割: 秒未満の低レイテンシと低コストが求められるデータ連携・変換 • 具体例: 劇的な改善を実現した行動ログのエンリッチ処理など • 方針: シンプルで高速な処理はFlinkに任せ、きれいに加工されたデータを後続に提供する Spark Structured Streamingを継続利用する領域 • 役割: 柔軟なクエリ実装や複雑な状態管理を伴う集計、バッチ処理 • 具体例: 移行を見送った複雑な行動特徴量集計など • 方針: Flinkなどから連携されたデータを、Sparkの豊富な関数と既存資産を活用して処理する 26
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 今後の展望
• Flinkの採用を決定したエンリッチ処理、シンプルな集計処理の移行の実施 • Flinkの採用を見送った複雑な集計処理の改善に向けた検証の継続 ◦ UDFの集約やCompute Poolの設定変更により要件を満たせる可能性があることが新たに判明 ◦ Confluentのカスタマーサクセステクニカルアーキテクトの皆様、検証にご協力いただき ありがとうございます • ストリーム基盤全体での責務の見直しやコストとパフォーマンスの最適化 ◦ 本検証は、あくまで現行基盤のSpark Structured Streamingを Flinkに置き換える内容にとどまっていたため 27
© Indeed Recruit Technologies Co., Ltd. All Rights Reserved 28
We are hiring! カジュアル面談はこちらより お申し込みください データサイエンティスト 機械学習エンジニア データエンジニア アナリティクスエンジニア R&Dエンジニア データアプリケーションエンジニア クラウドエンジニア
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}