Information Retrieval Modern Information Retrieval Information Retrieval: Implementing and Evaluating Search Engines IR=情報検索 https://a.co/d/38BDNKx https://a.co/d/aSseRE9 https://a.co/d/37WAL89
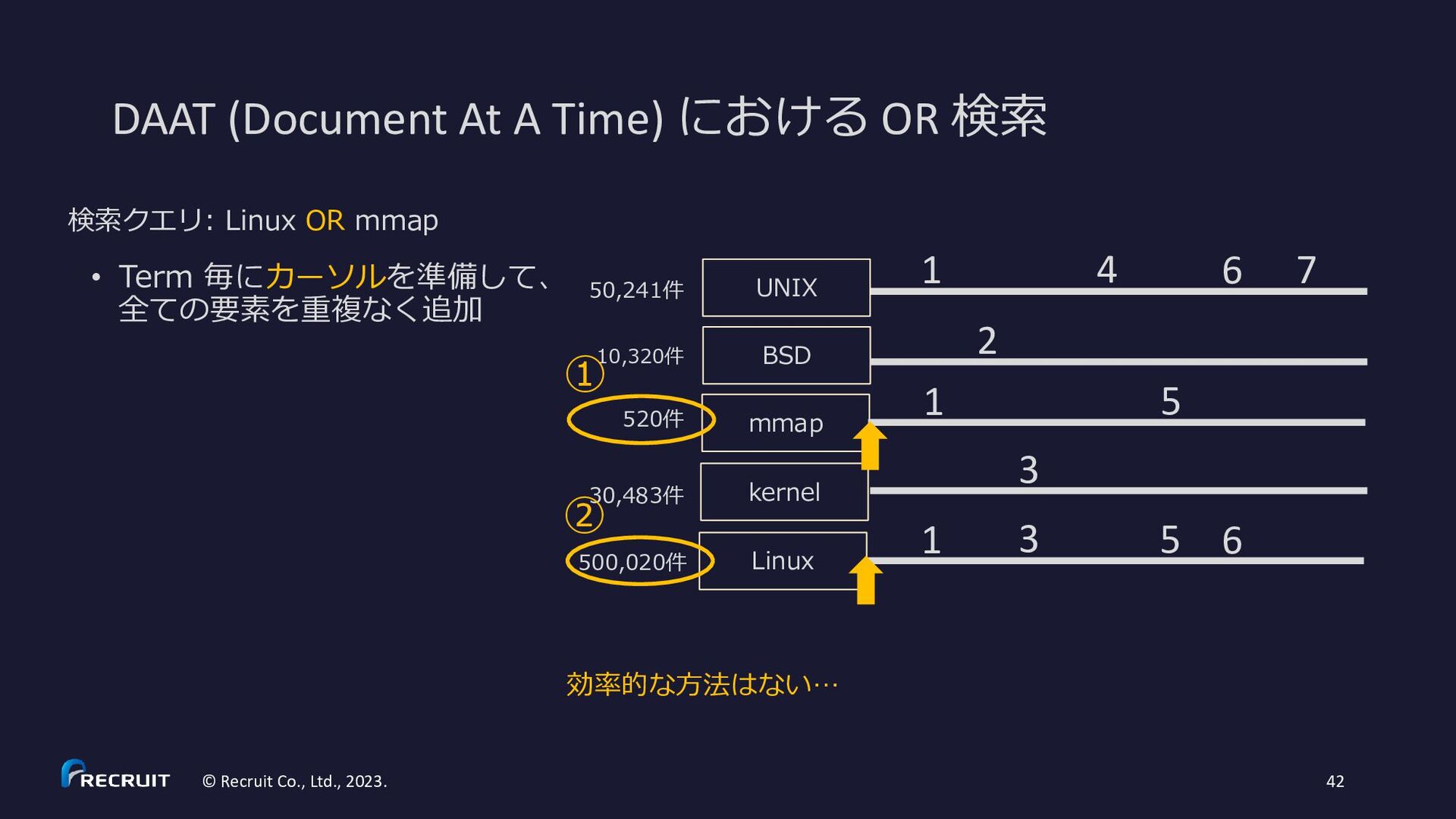
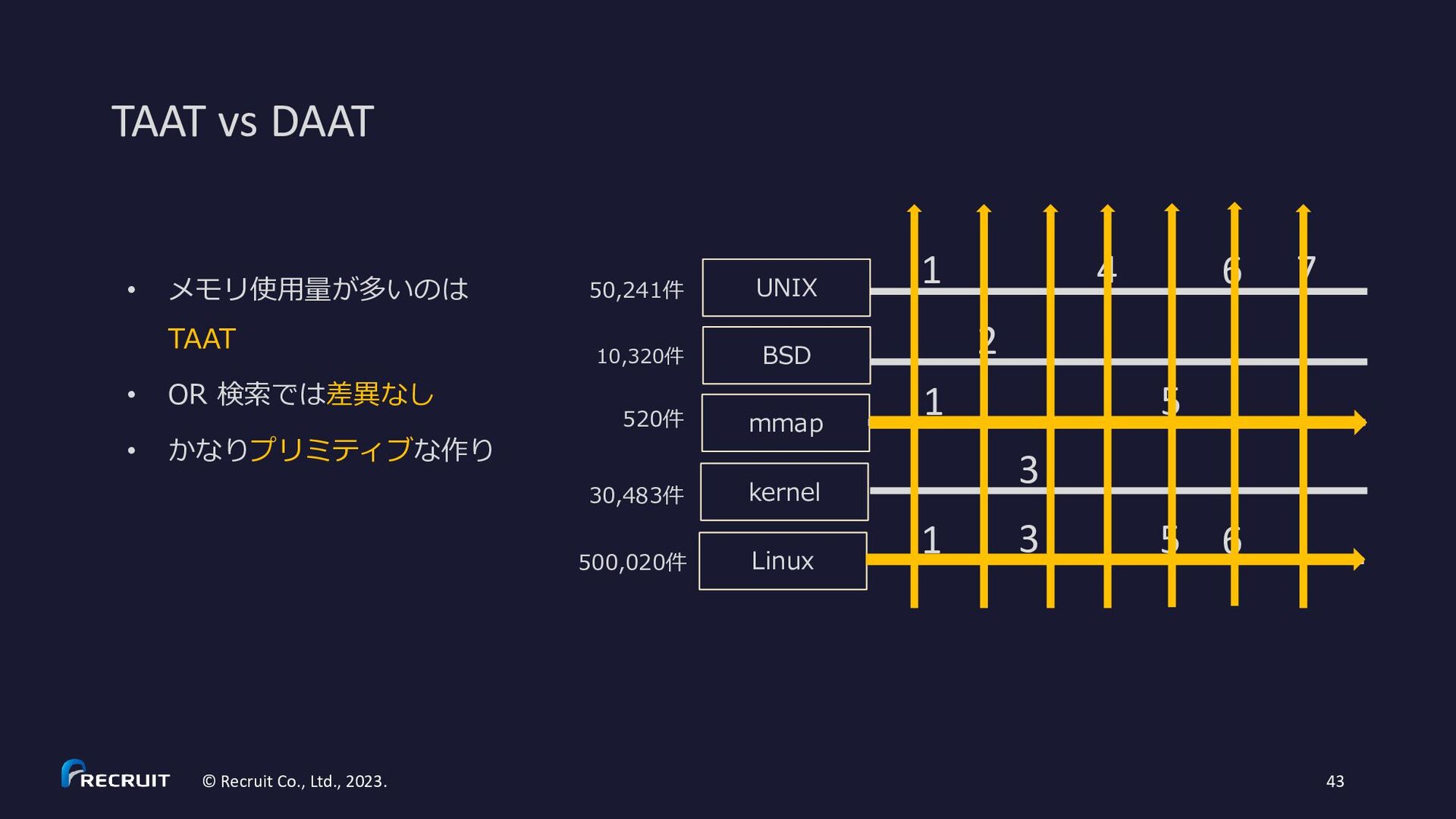
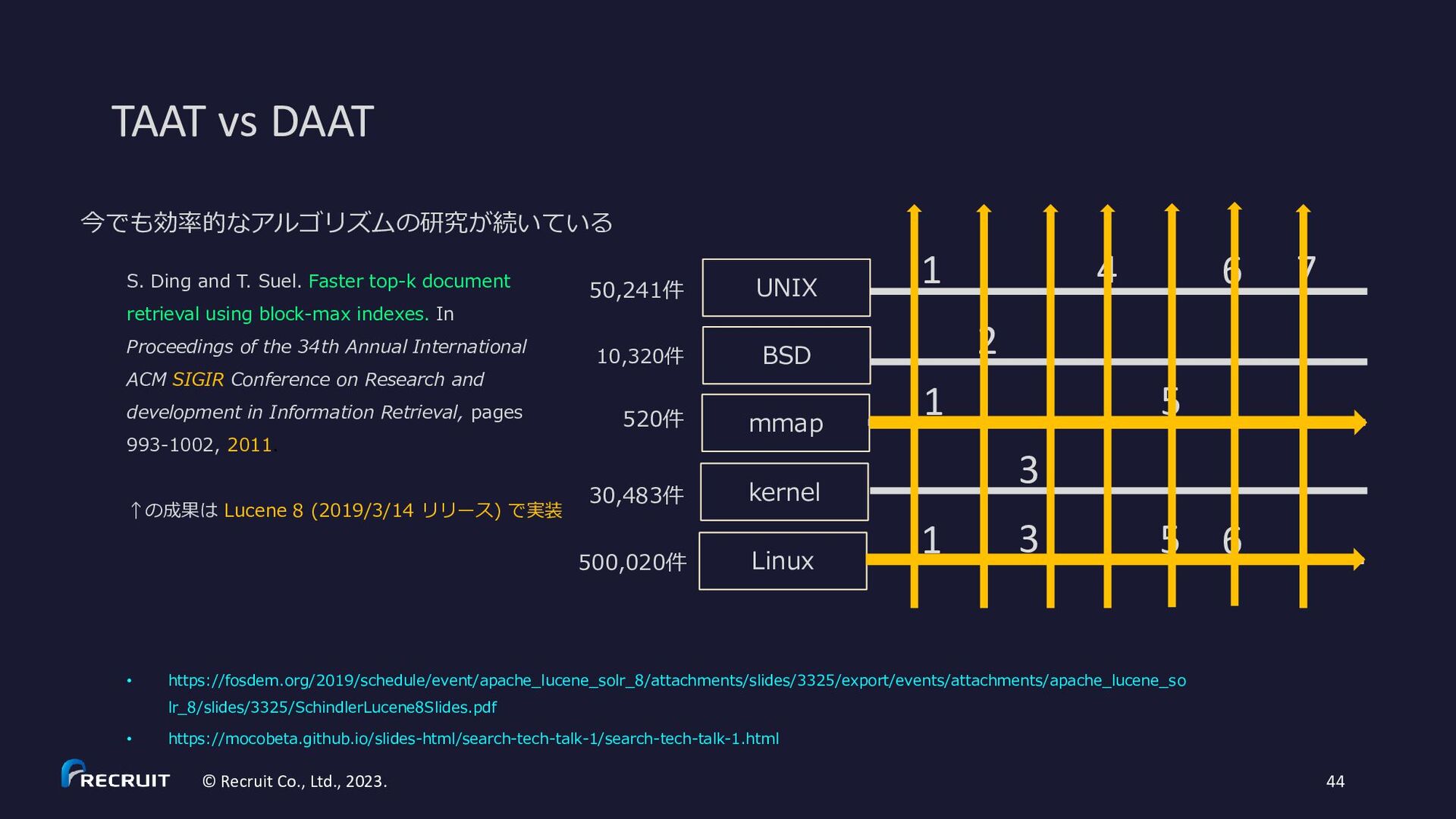
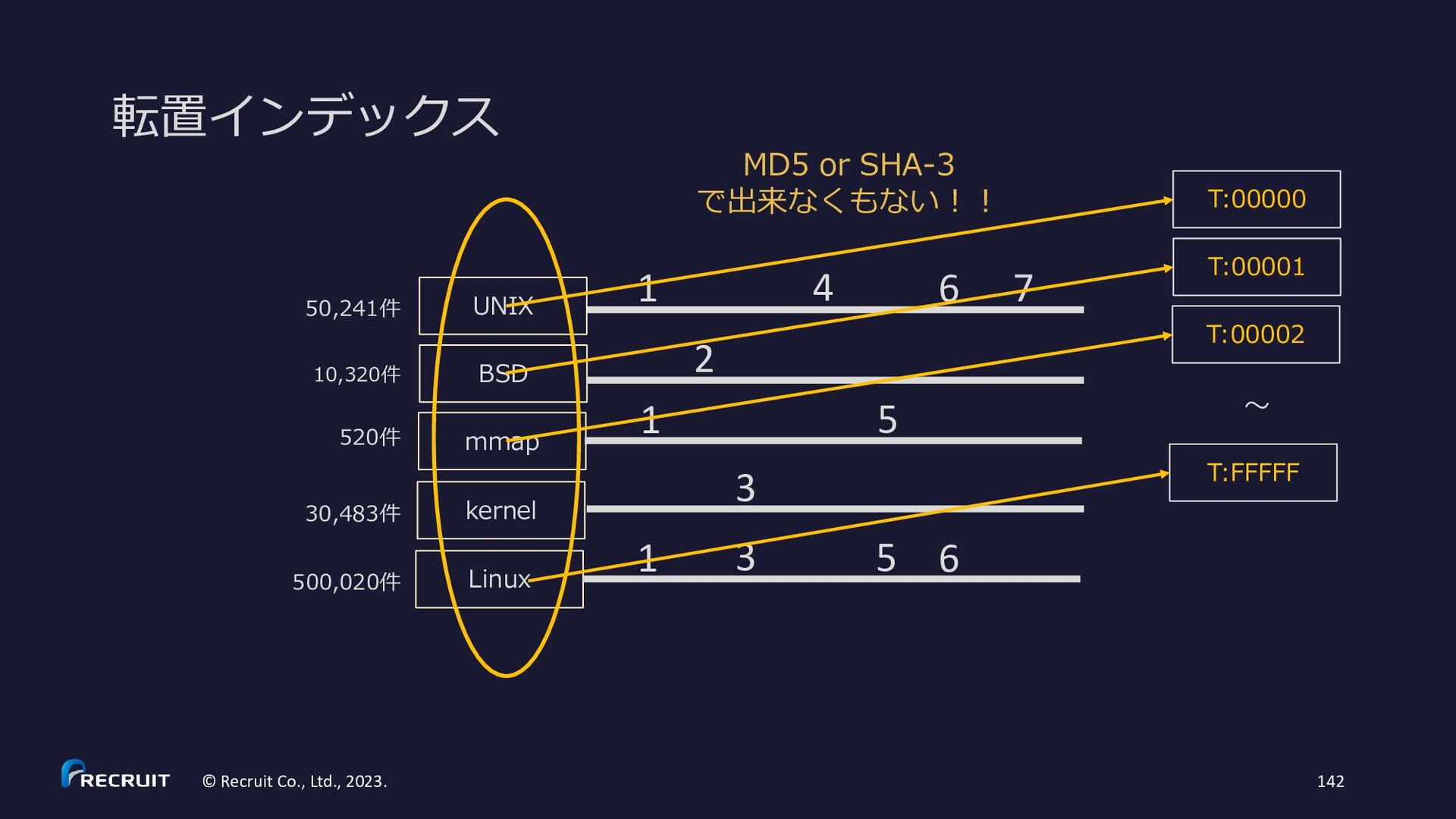
10,320件 30,483件 500,020件 UNIX BSD mmap kernel Linux 520件 1 1 1 2 3 3 4 5 5 6 6 7 S. Ding and T. Suel. Faster top-k document retrieval using block-max indexes. In Proceedings of the 34th Annual International ACM SIGIR Conference on Research and development in Information Retrieval, pages 993-1002, 2011. ↑の成果は Lucene 8 (2019/3/14 リリース) で実装 • https://fosdem.org/2019/schedule/event/apache_lucene_solr_8/attachments/slides/3325/export/events/attachments/apache_lucene_so lr_8/slides/3325/SchindlerLucene8Slides.pdf • https://mocobeta.github.io/slides-html/search-tech-talk-1/search-tech-talk-1.html 今でも効率的なアルゴリズムの研究が続いている
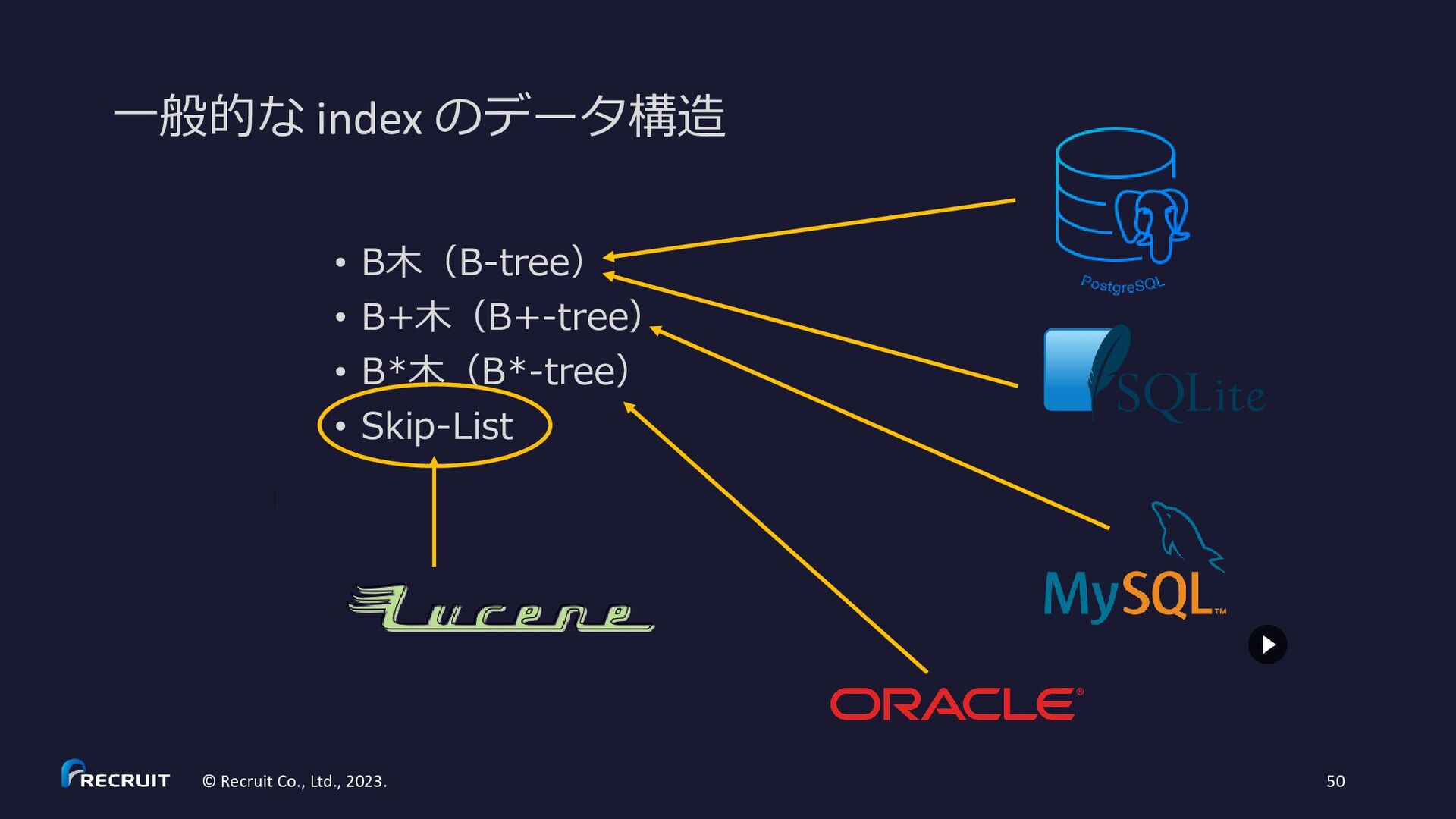
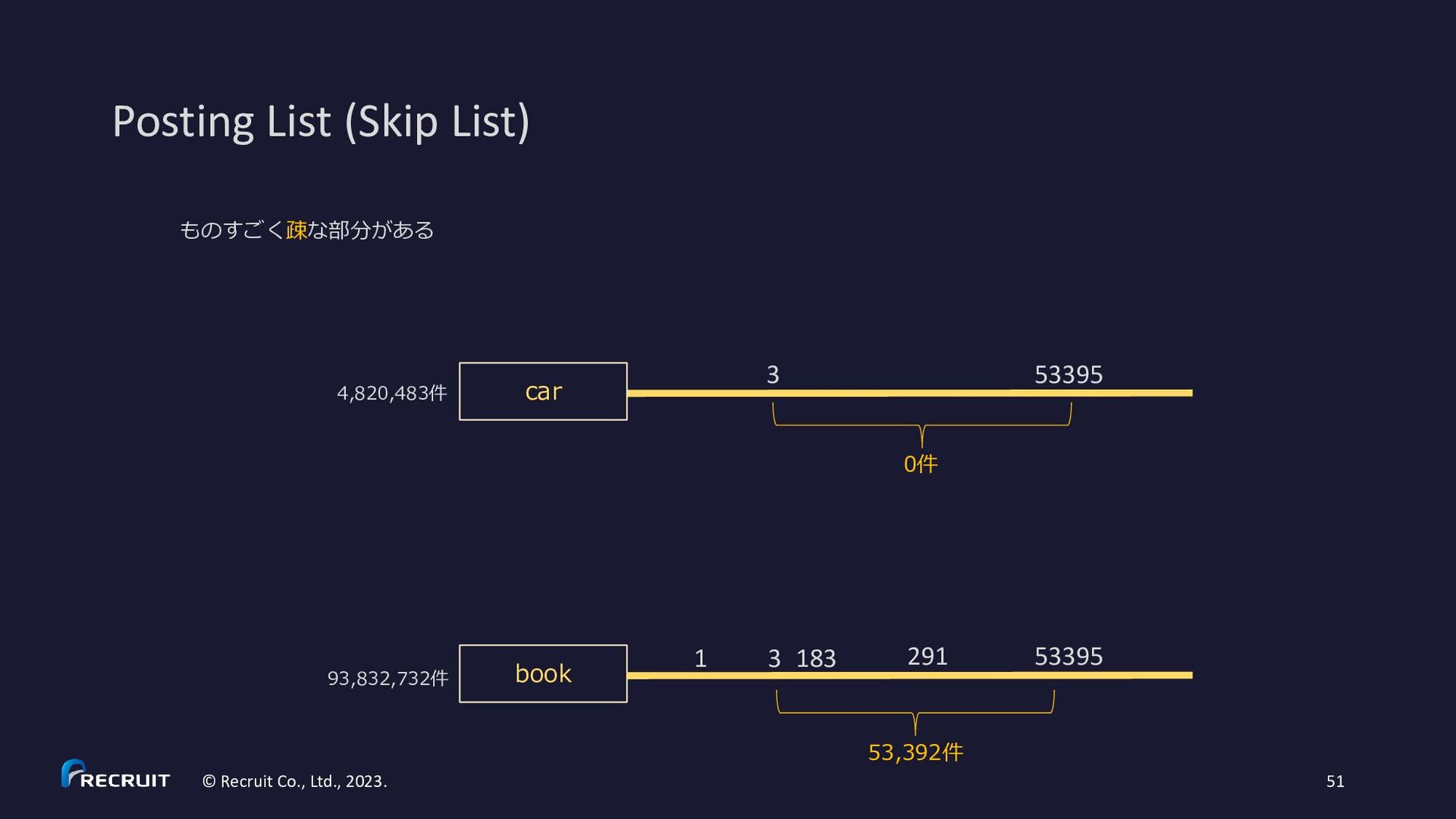
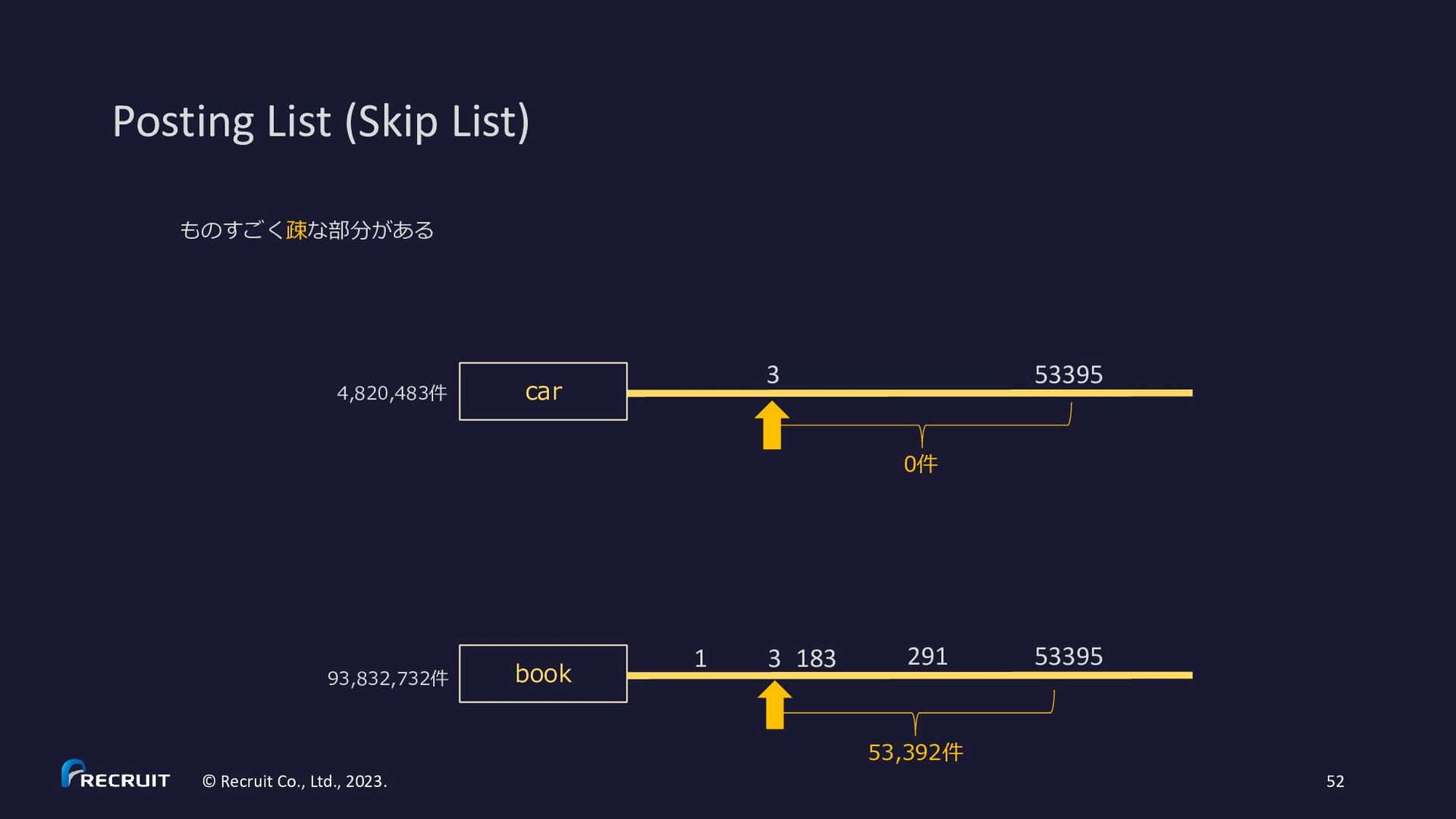
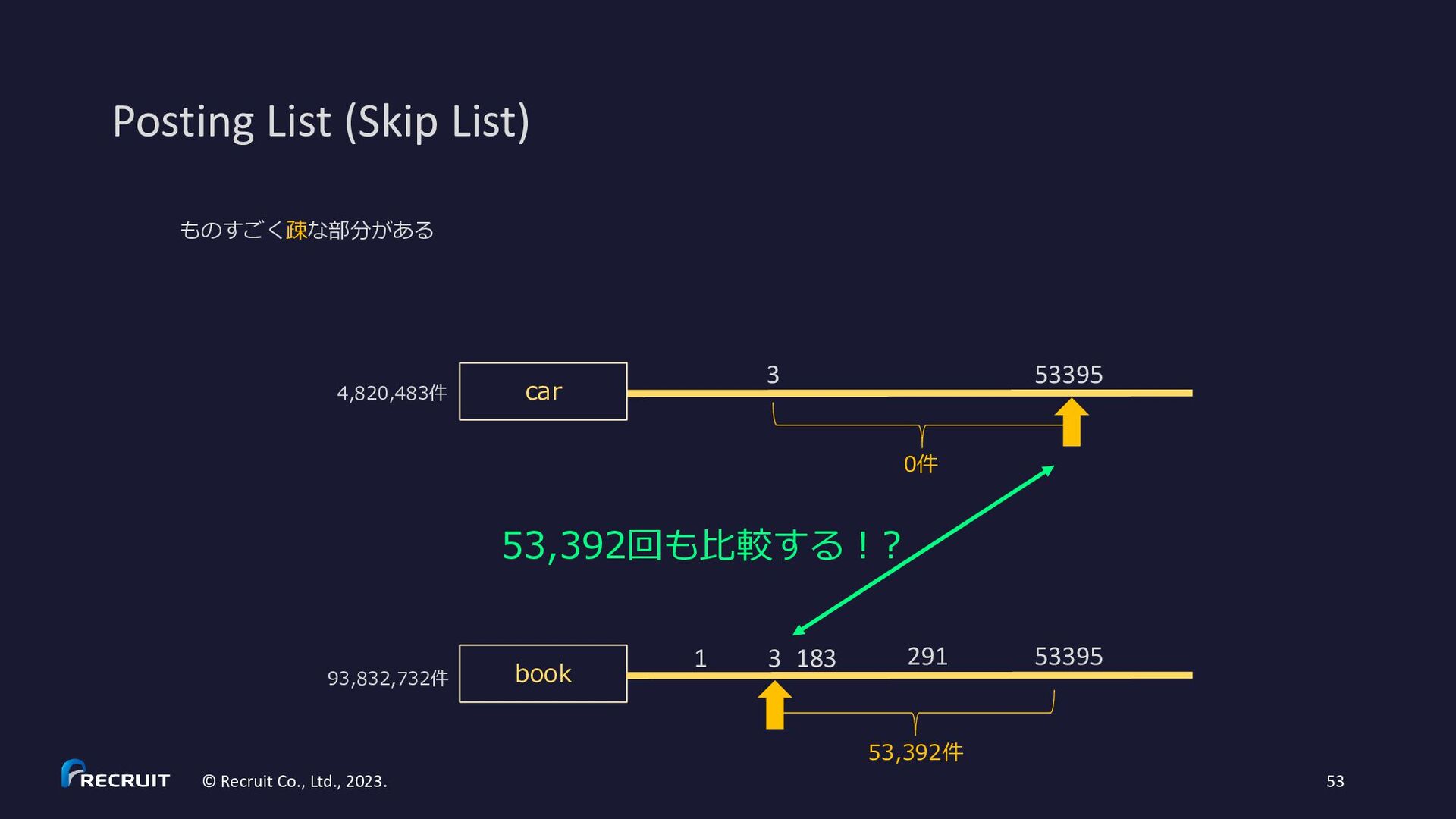
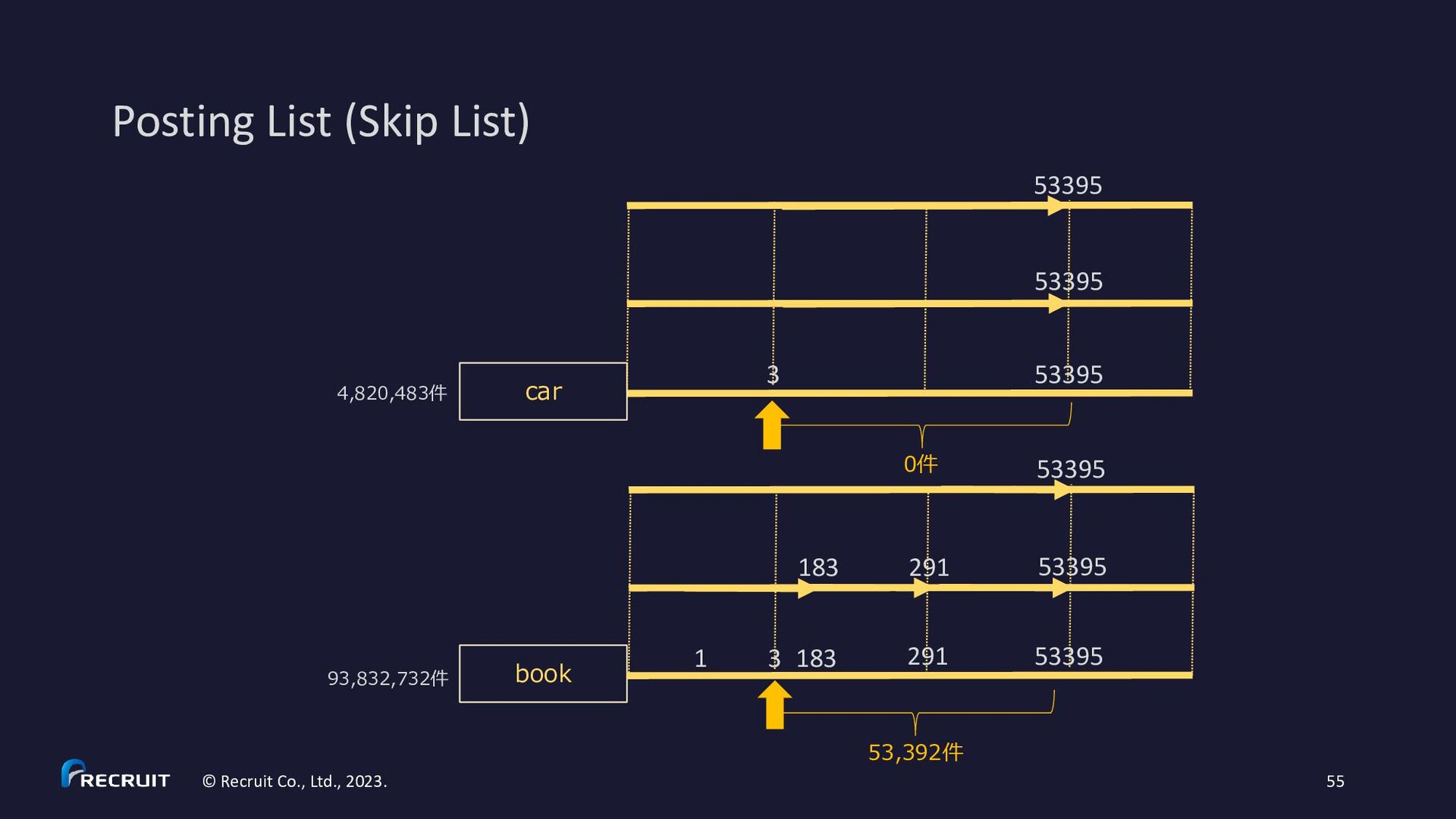
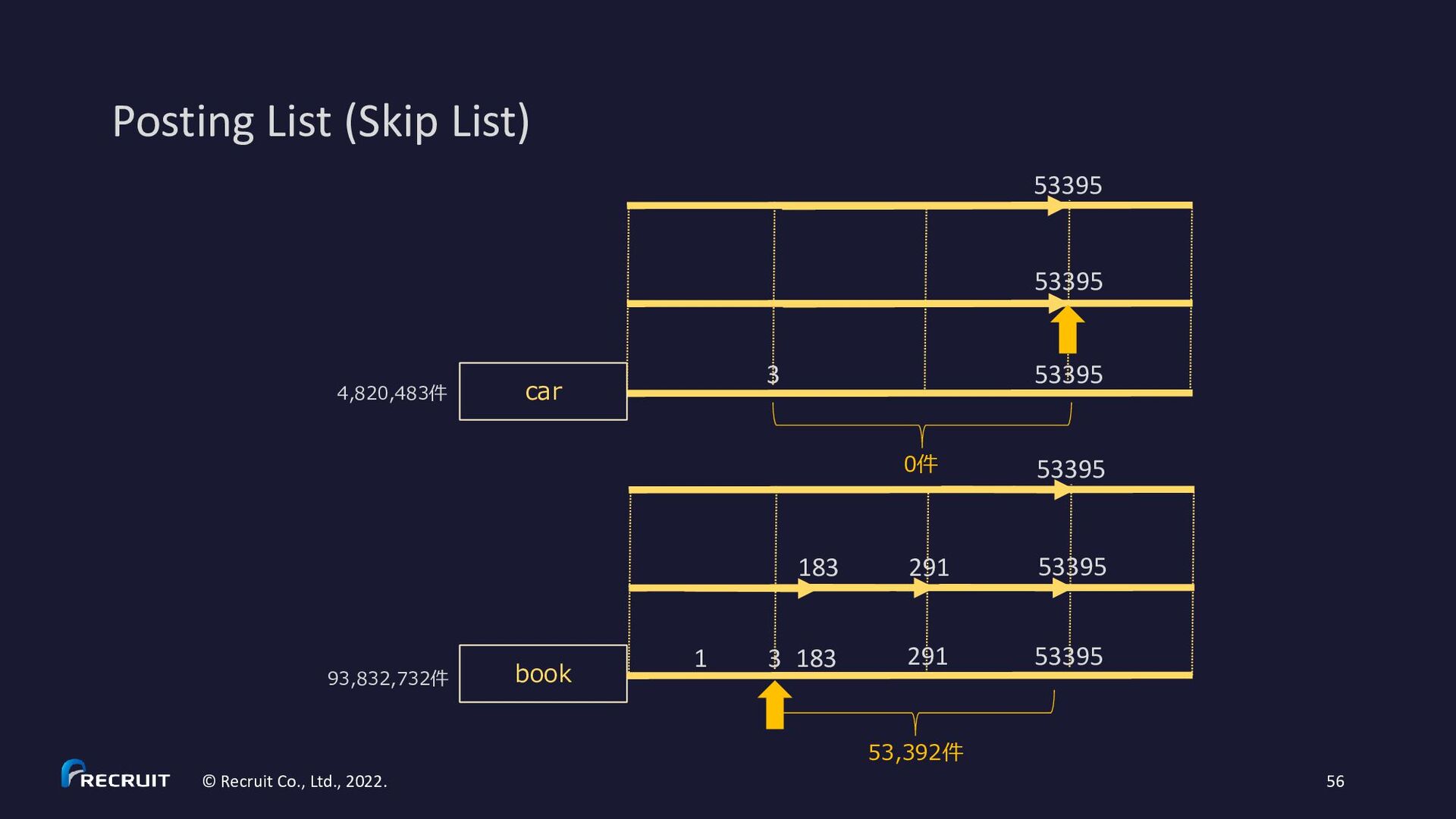
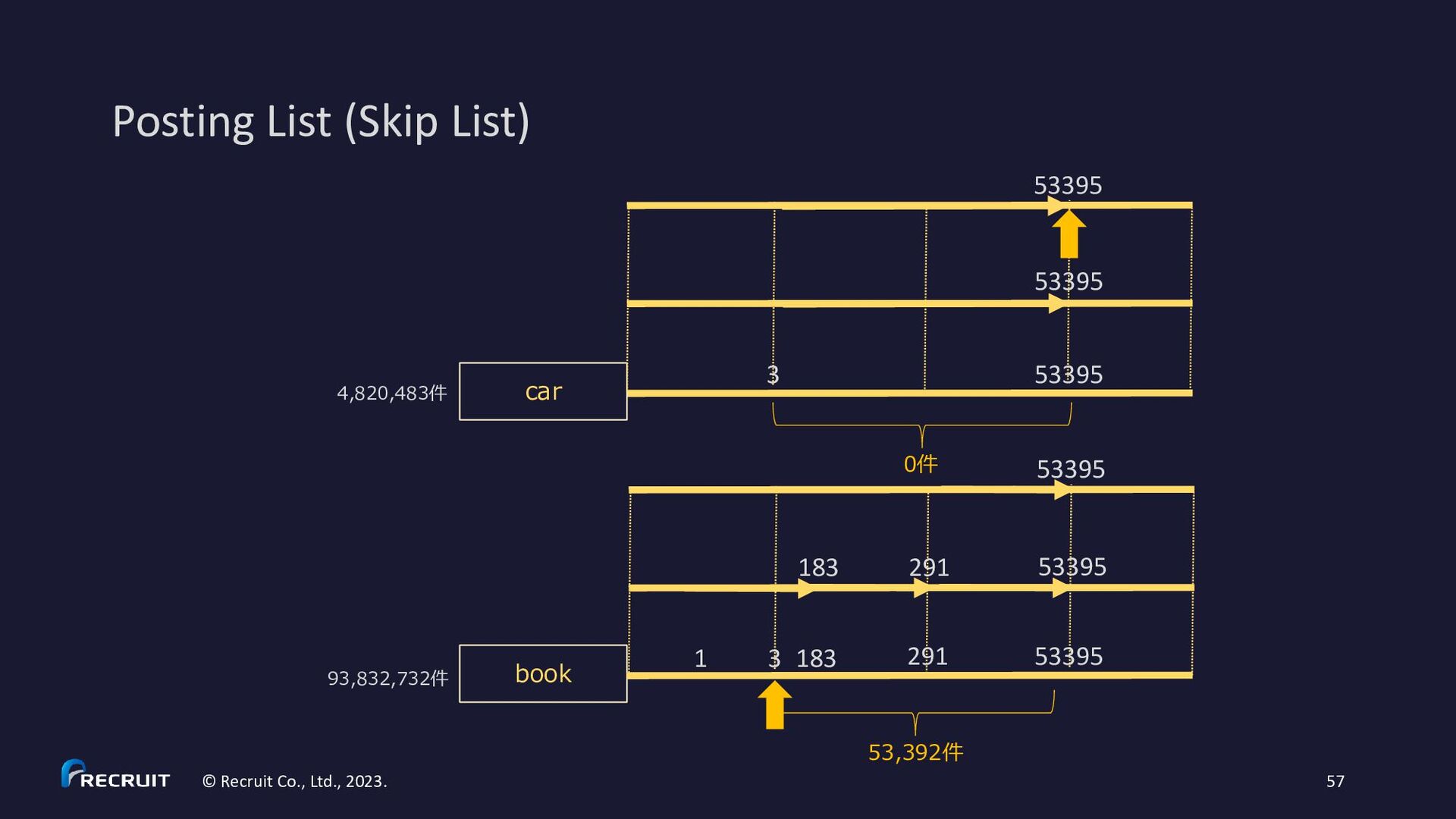
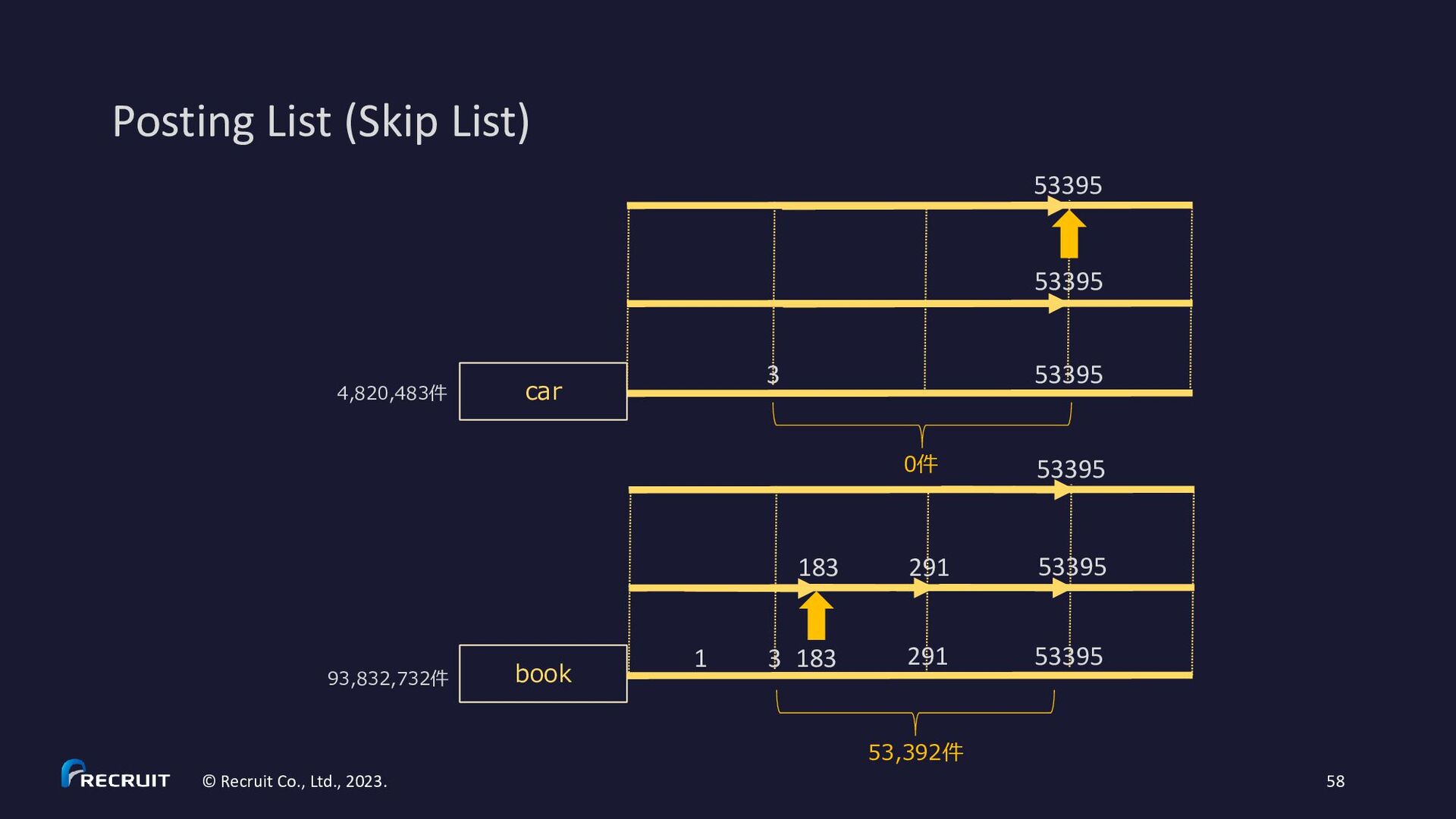
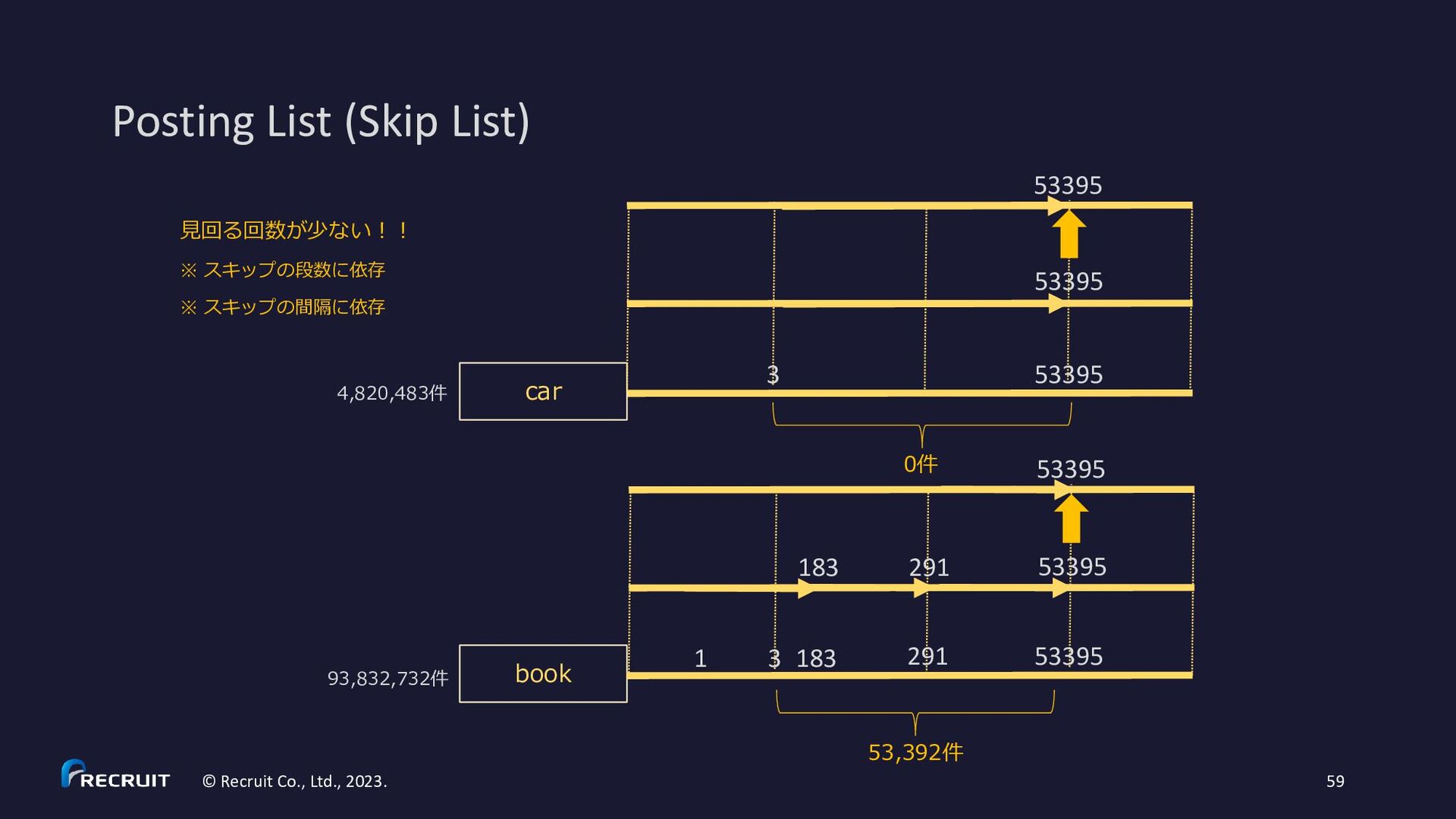
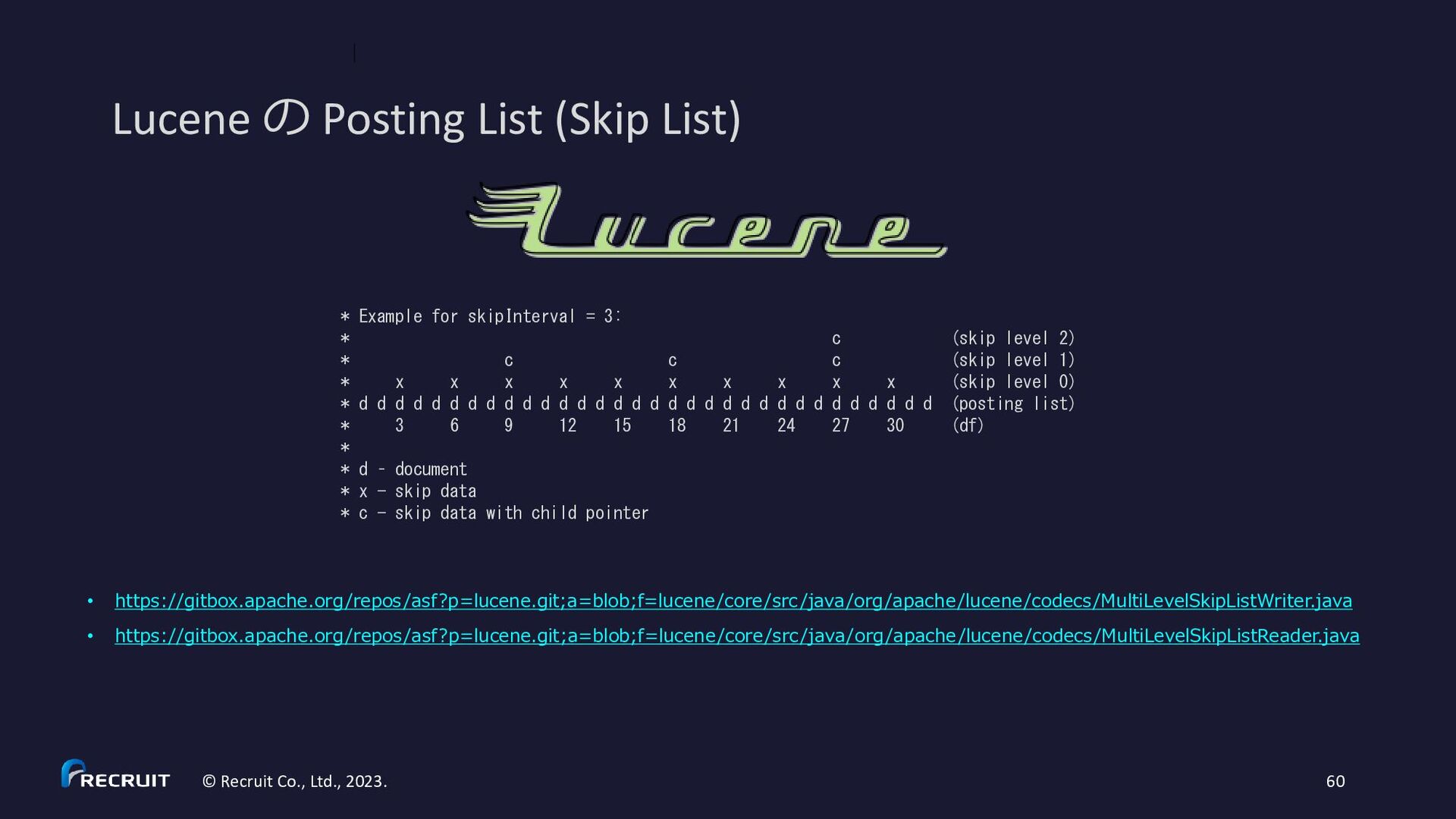
2023. 60 • https://gitbox.apache.org/repos/asf?p=lucene.git;a=blob;f=lucene/core/src/java/org/apache/lucene/codecs/MultiLevelSkipListWriter.java • https://gitbox.apache.org/repos/asf?p=lucene.git;a=blob;f=lucene/core/src/java/org/apache/lucene/codecs/MultiLevelSkipListReader.java * Example for skipInterval = 3: * c (skip level 2) * c c c (skip level 1) * x x x x x x x x x x (skip level 0) * d d d d d d d d d d d d d d d d d d d d d d d d d d d d d d d d (posting list) * 3 6 9 12 15 18 21 24 27 30 (df) * * d – document * x - skip data * c - skip data with child pointer
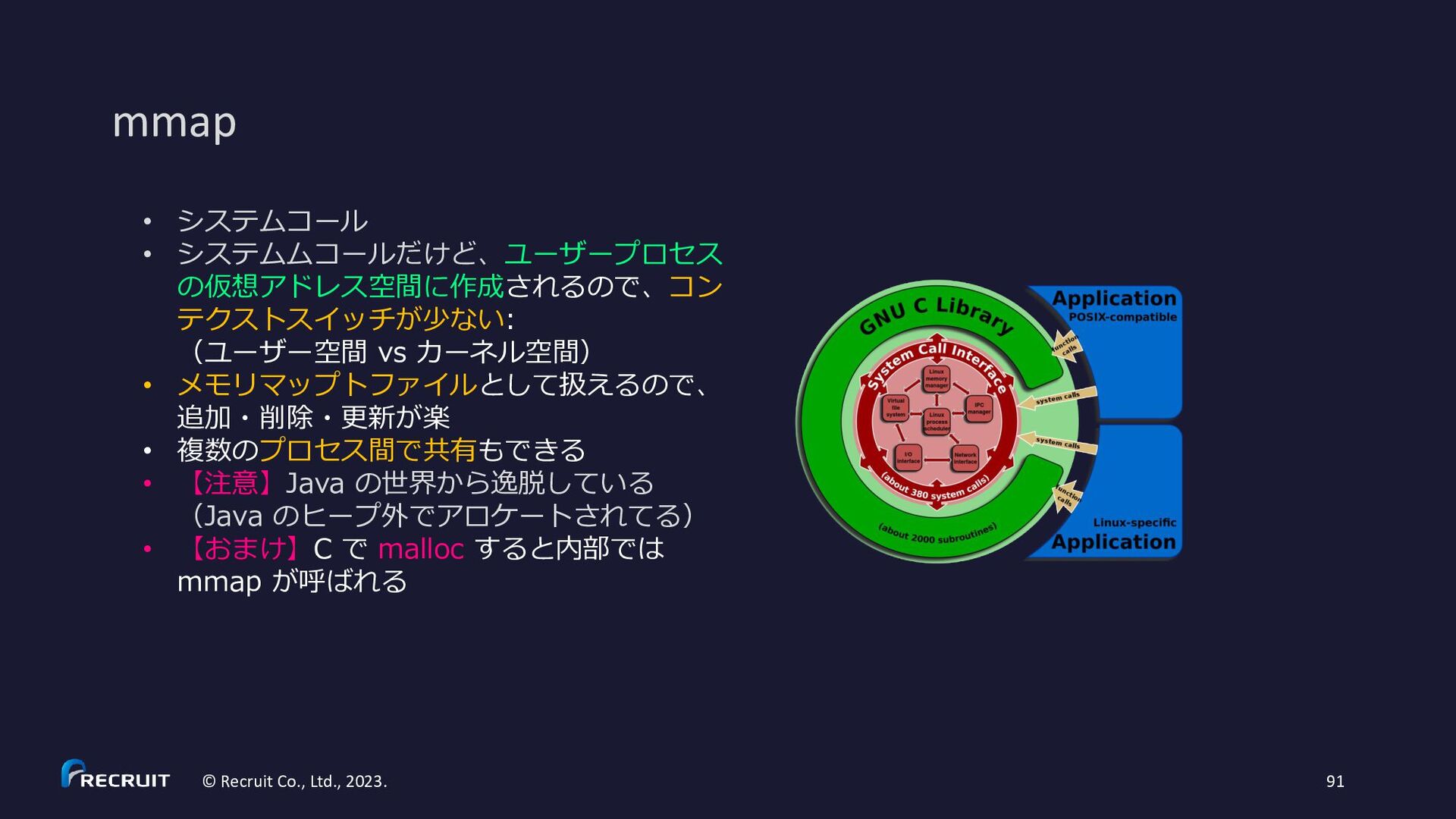
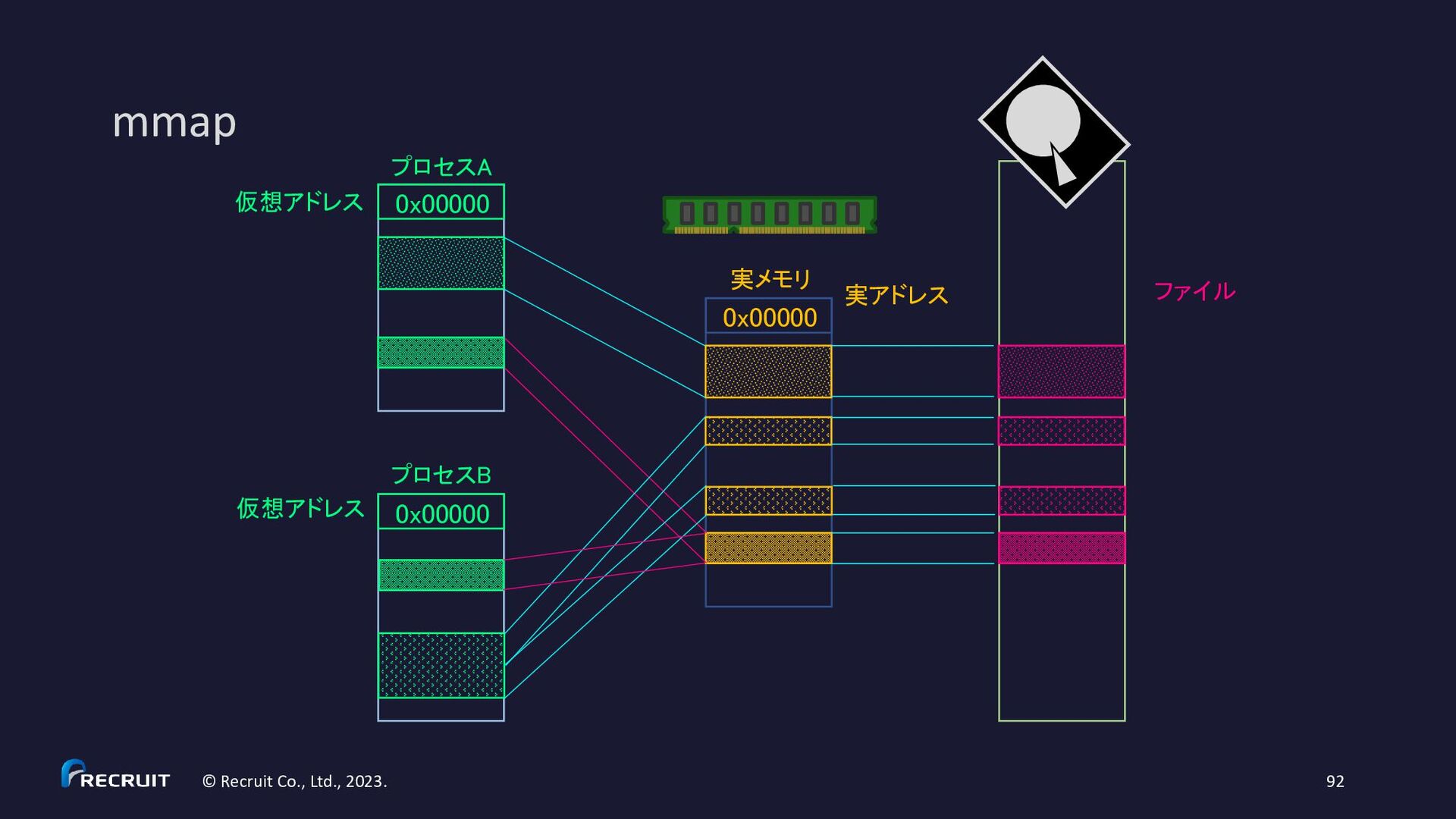
recommendation is to give 50% of the available memory to Elasticsearch heap, while leaving the other 50% free. It won’t go unused; Lucene will happily gobble up whatever is left over.” 【注意】Java の世界から逸脱している(Java のヒープ外でアロケートされてる)
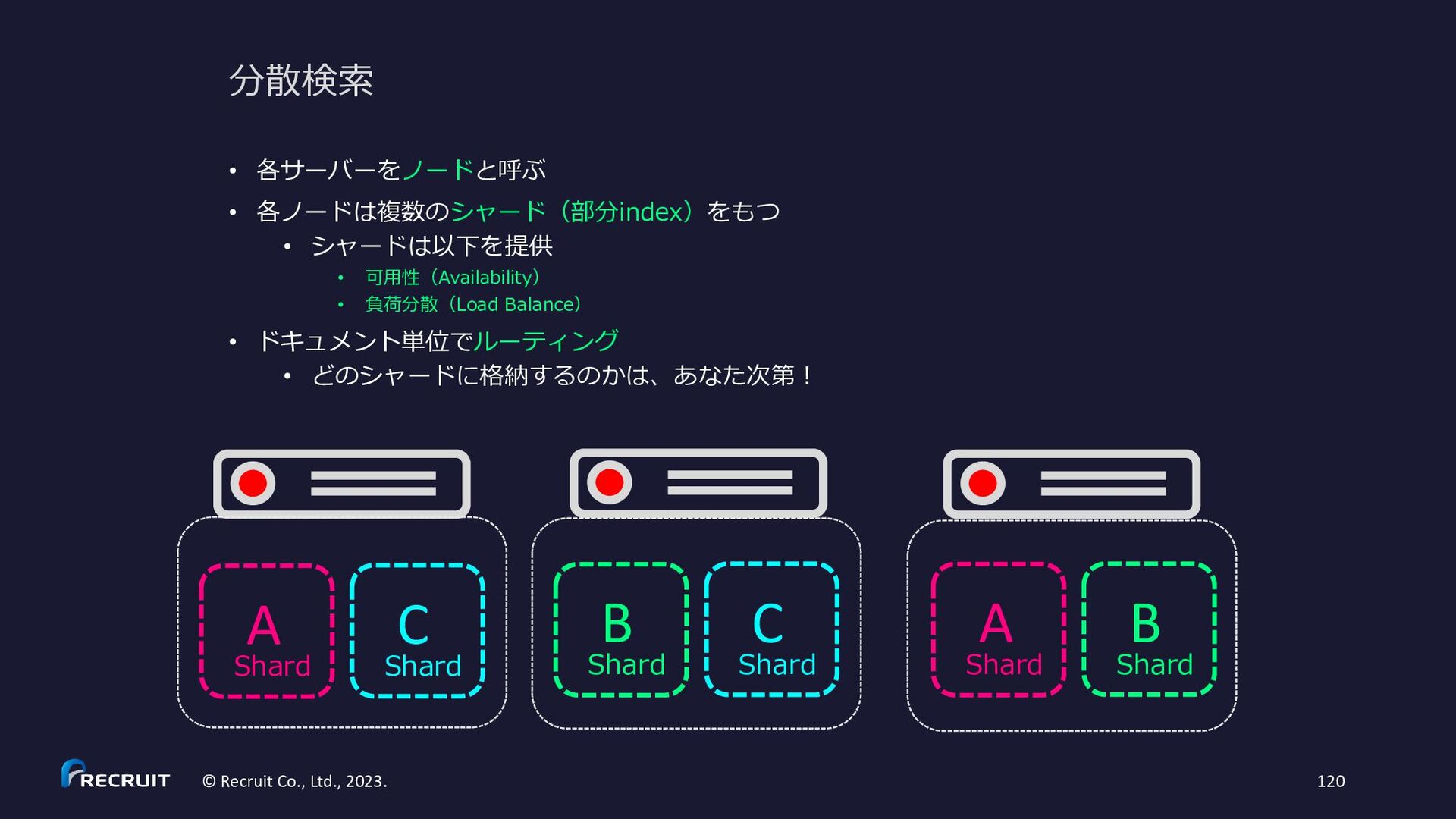
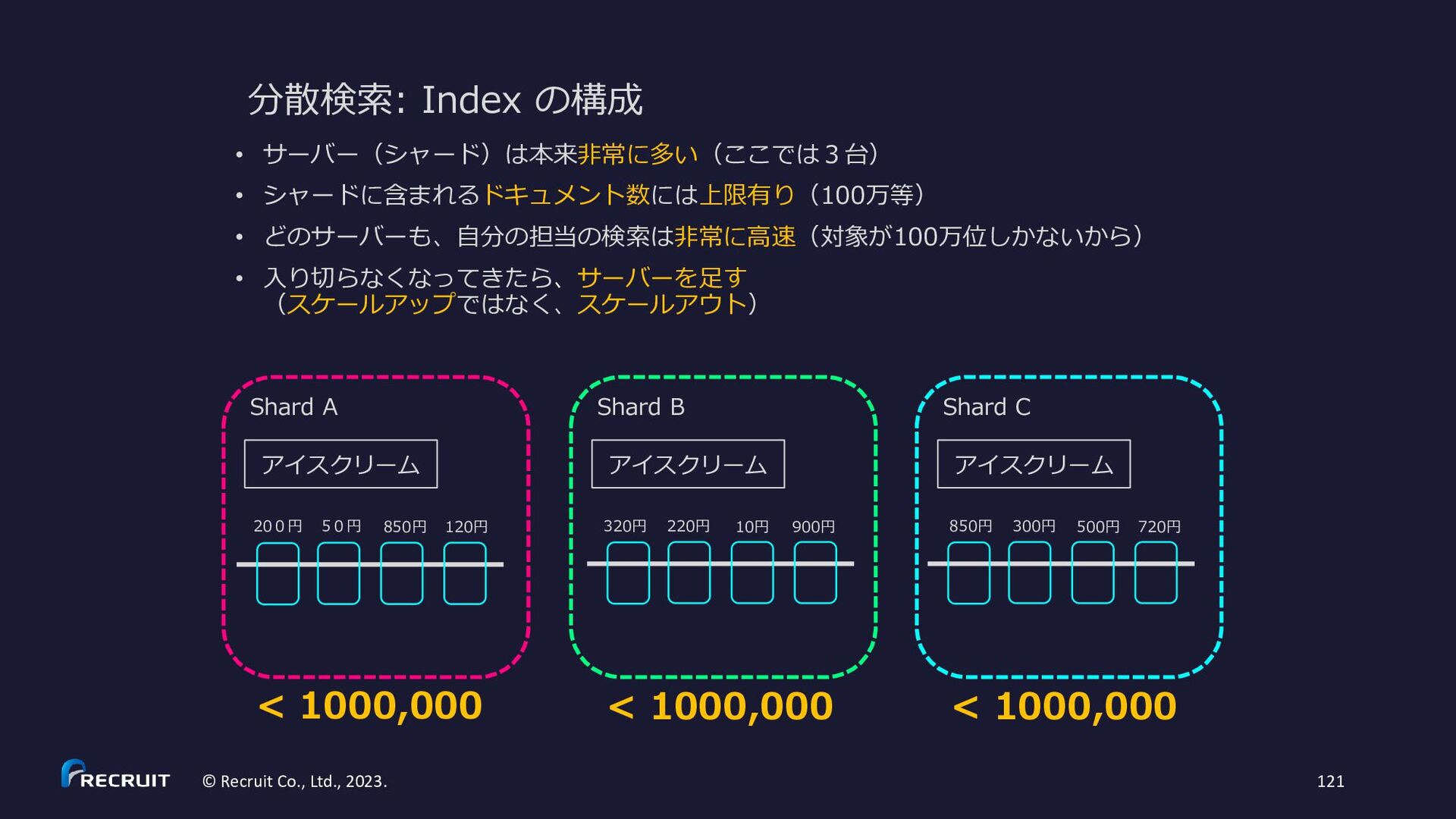
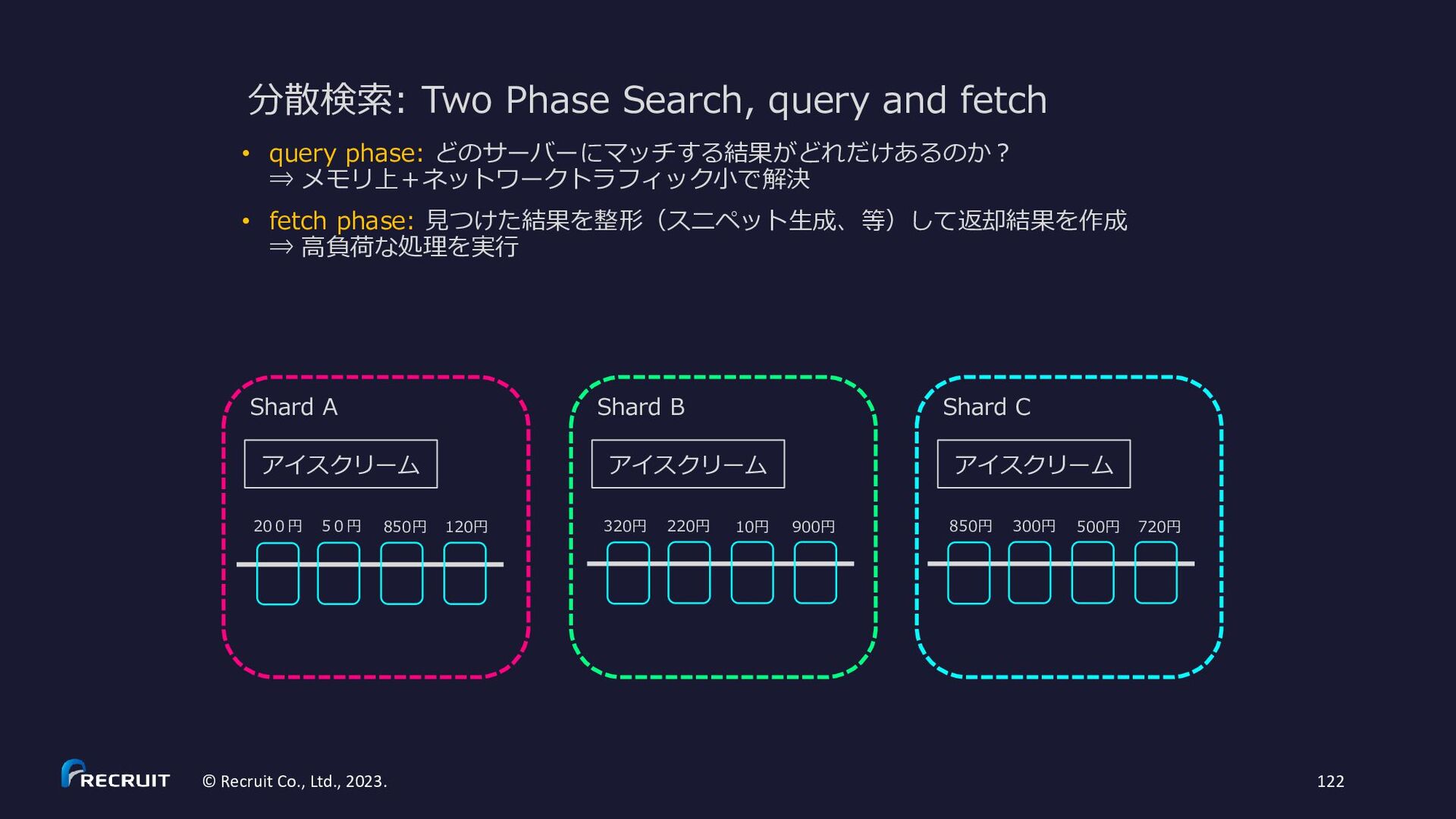
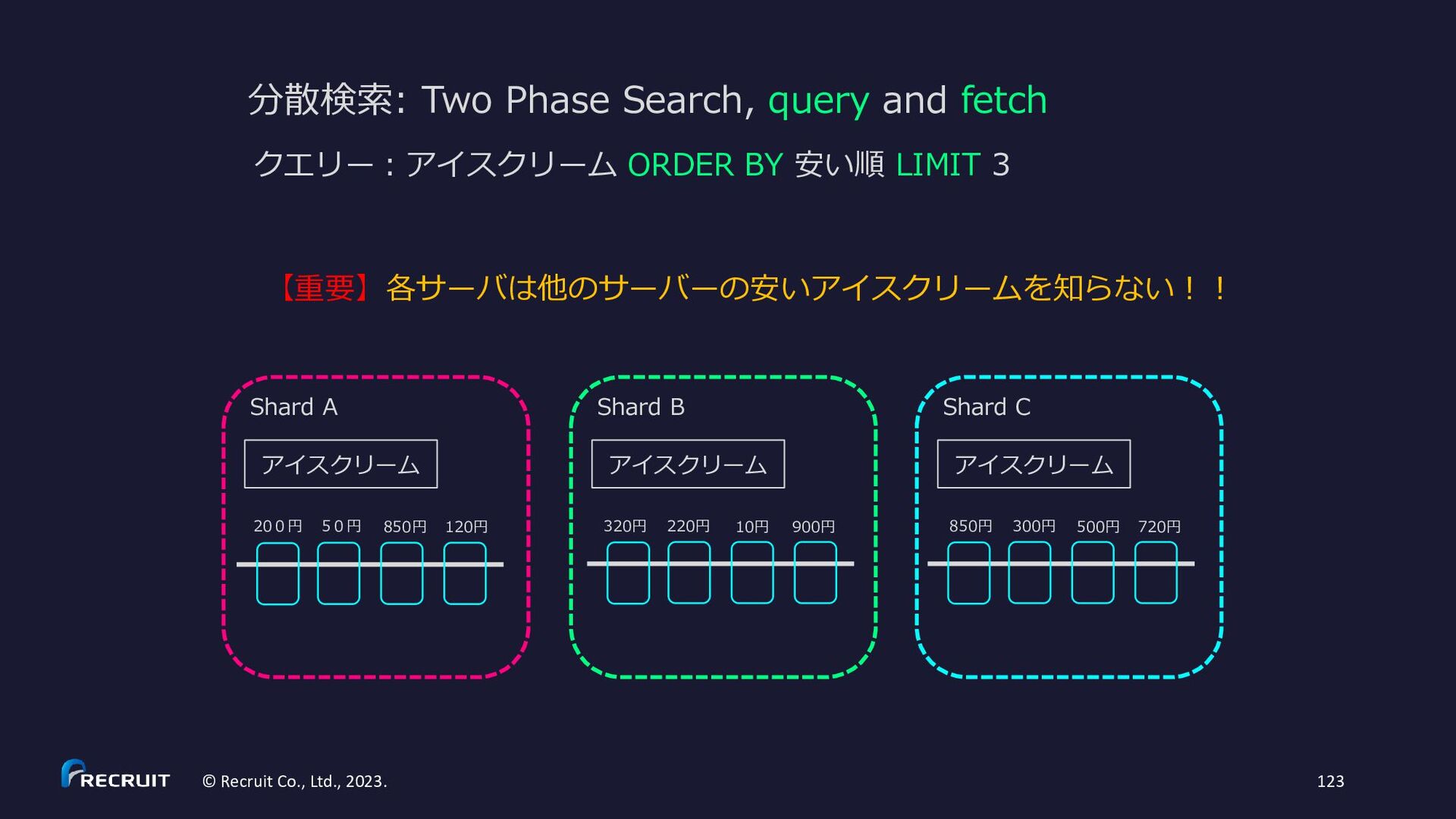
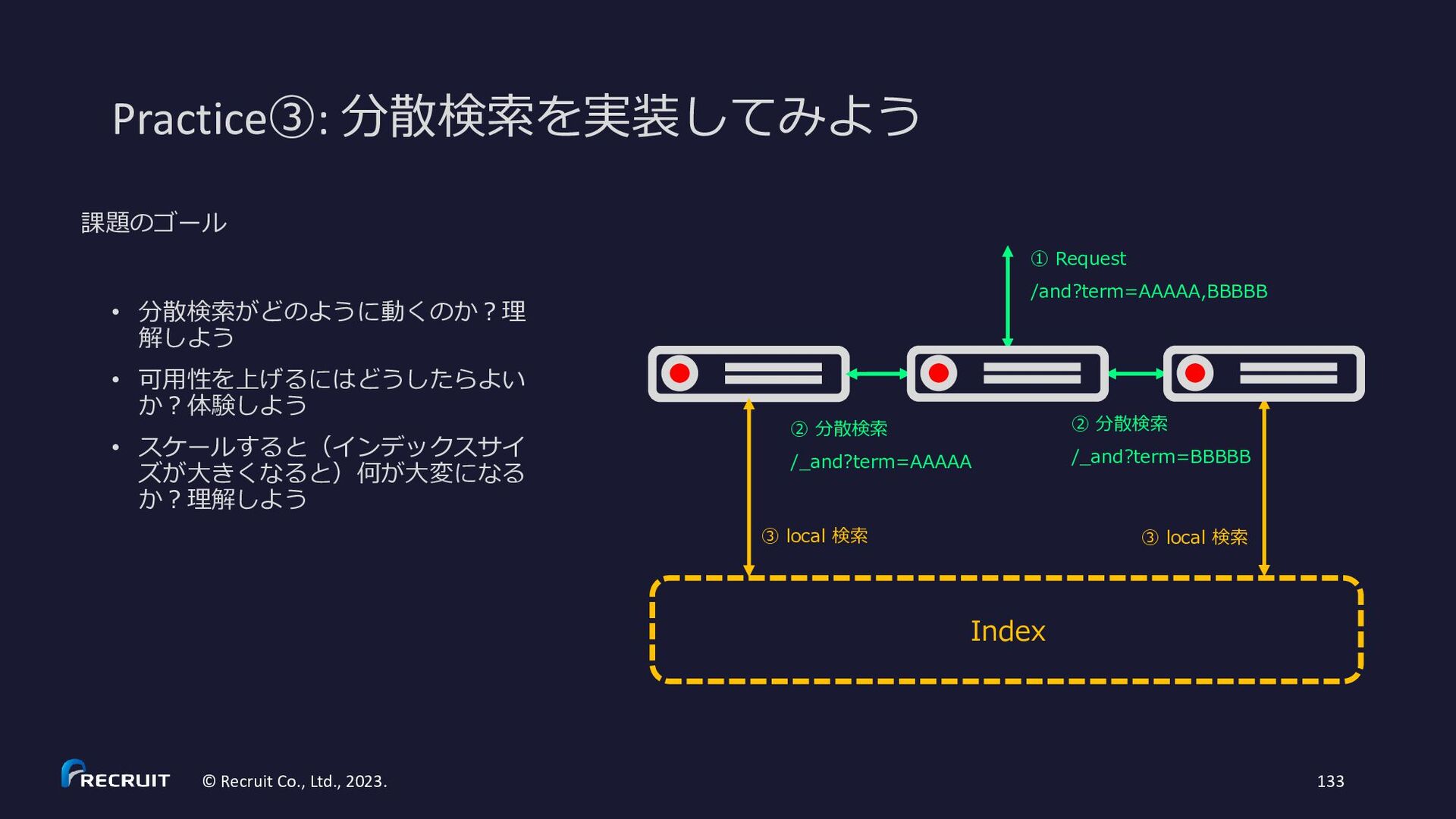
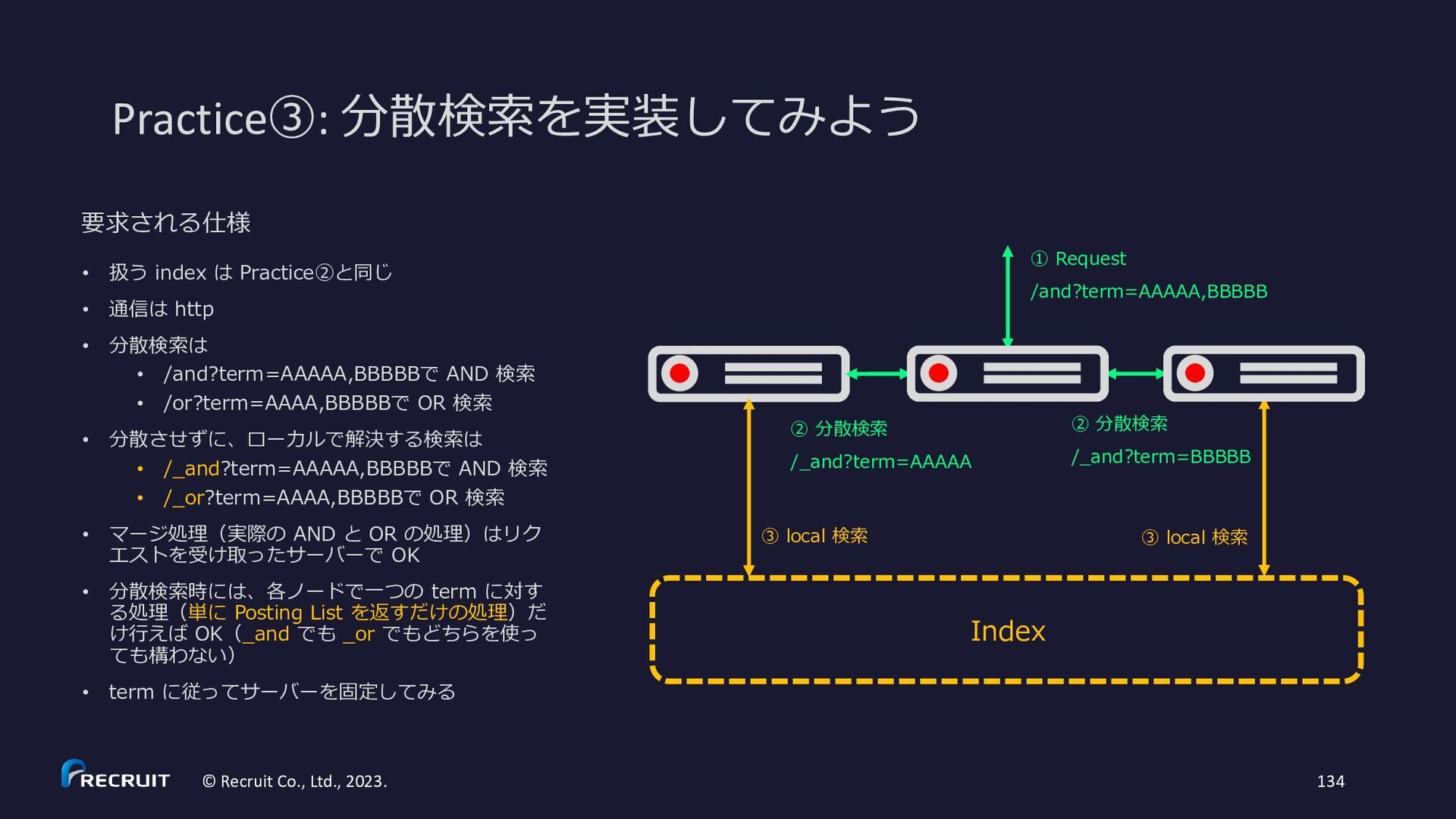
解しよう • 可用性を上げるにはどうしたらよい か?体験しよう • スケールすると(インデックスサイ ズが大きくなると)何が大変になる か?理解しよう 課題のゴール Index ① Request /and?term=AAAAA,BBBBB ② 分散検索 /_and?term=AAAAA ③ local 検索 ③ local 検索 ② 分散検索 /_and?term=BBBBB
扱う index は Practice②と同じ • 通信は http • 分散検索は • /and?term=AAAAA,BBBBBで AND 検索 • /or?term=AAAA,BBBBBで OR 検索 • 分散させずに、ローカルで解決する検索は • /_and?term=AAAAA,BBBBBで AND 検索 • /_or?term=AAAA,BBBBBで OR 検索 • マージ処理(実際の AND と OR の処理)はリク エストを受け取ったサーバーで OK • 分散検索時には、各ノードで一つの term に対す る処理(単に Posting List を返すだけの処理)だ け行えば OK(_and でも _or でもどちらを使っ ても構わない) • term に従ってサーバーを固定してみる Index ① Request /and?term=AAAAA,BBBBB ② 分散検索 /_and?term=AAAAA ③ local 検索 ③ local 検索 ② 分散検索 /_and?term=BBBBB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
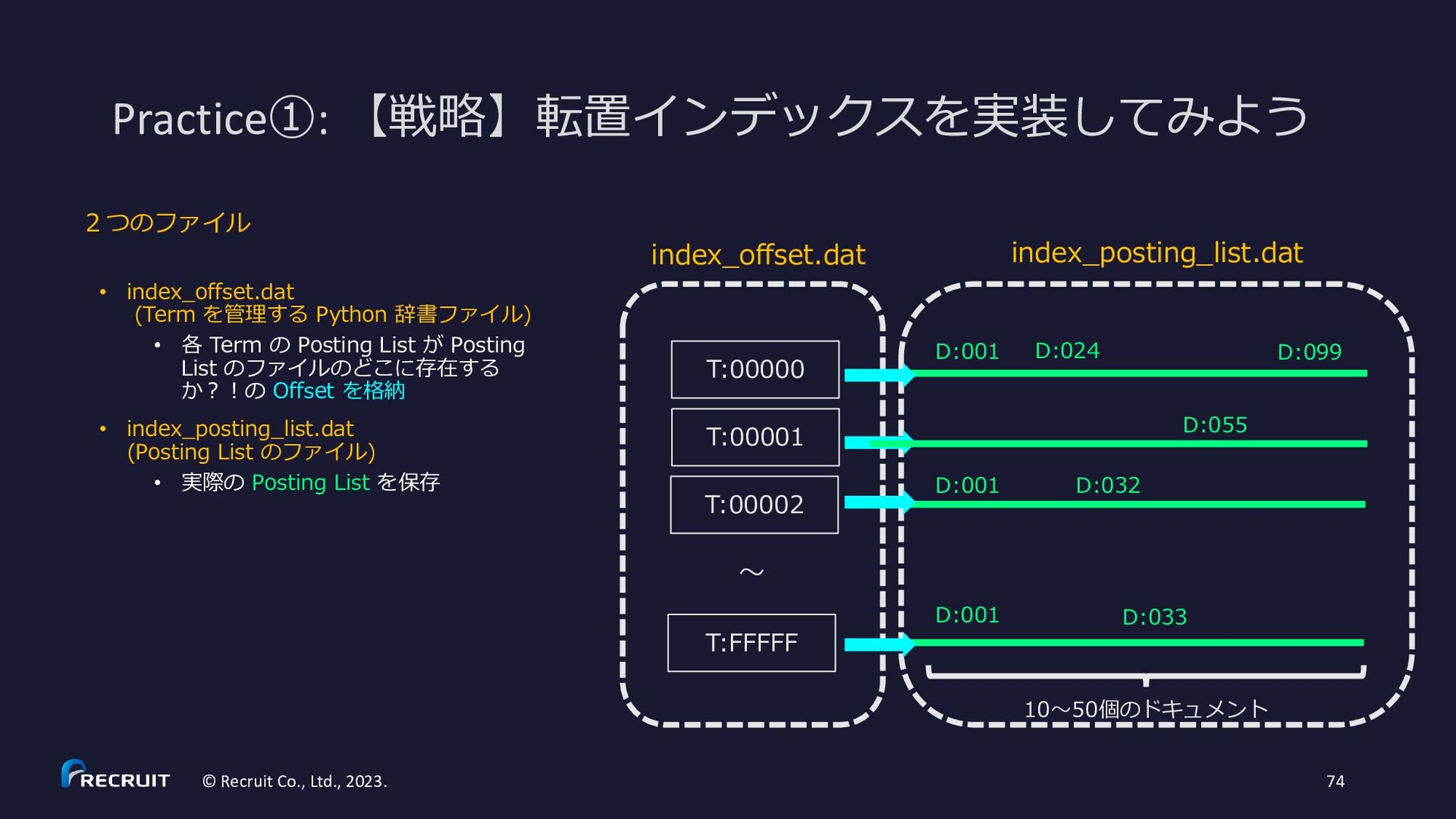{kind=link}
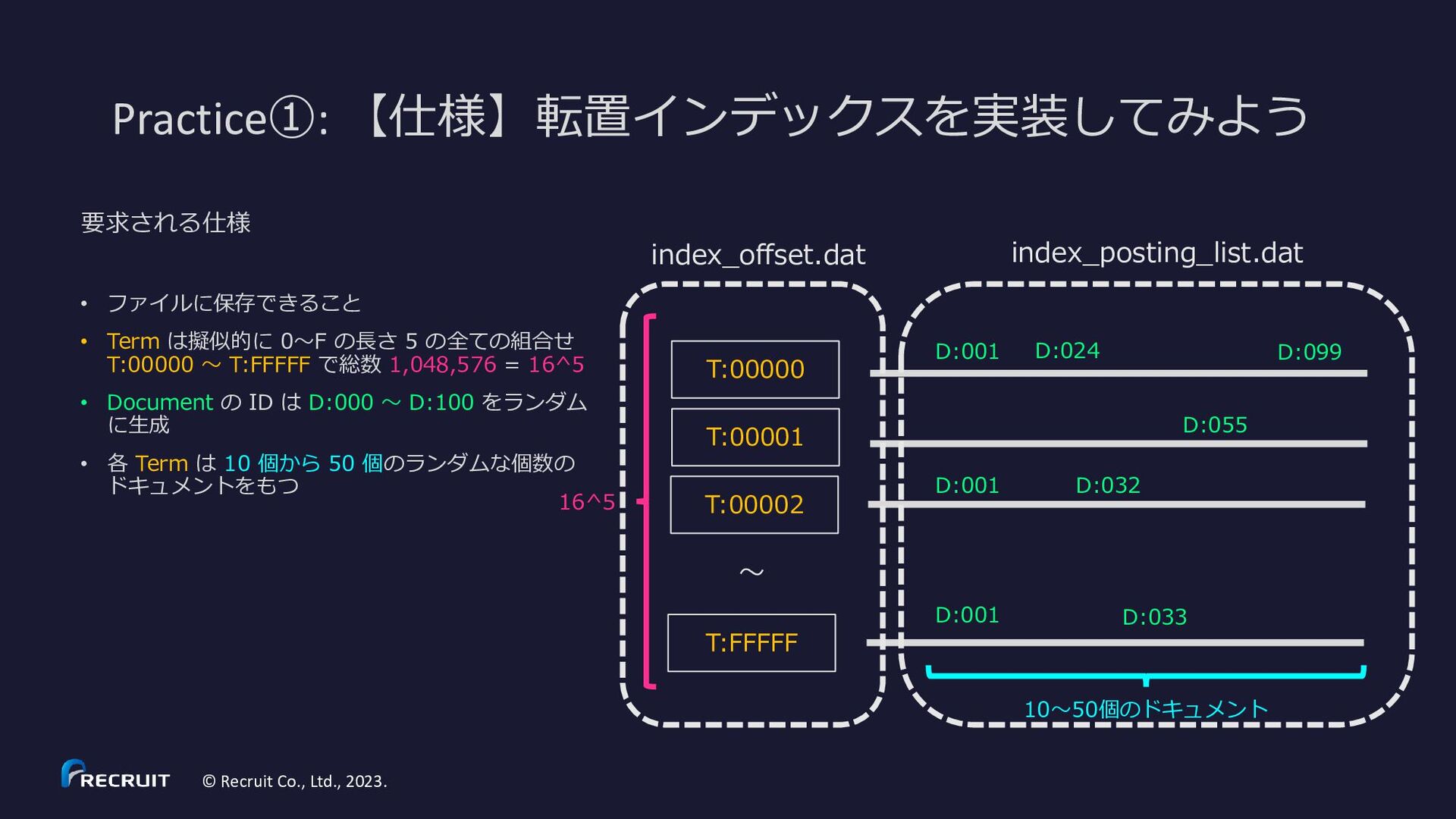{kind=link}
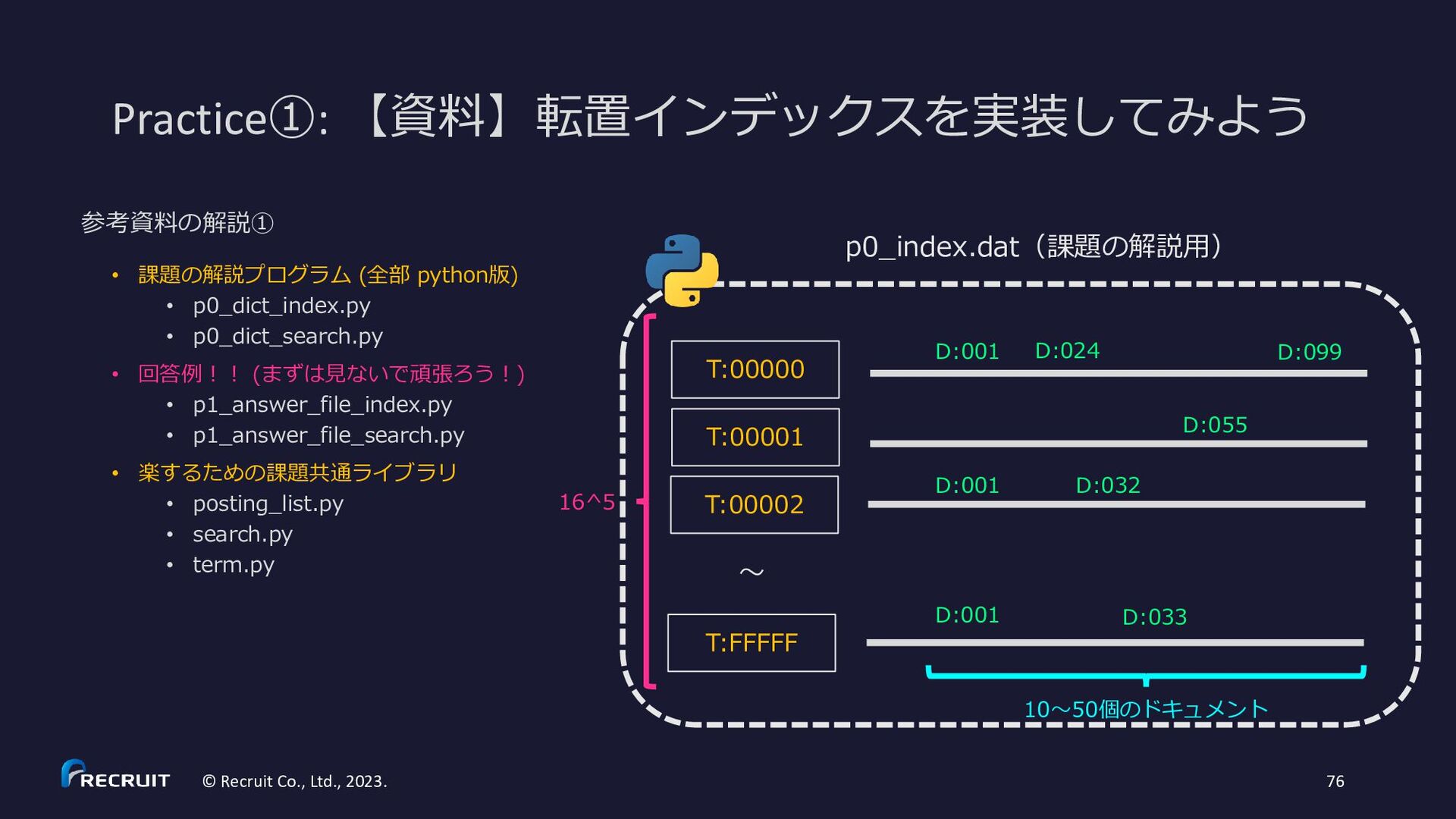{kind=link}
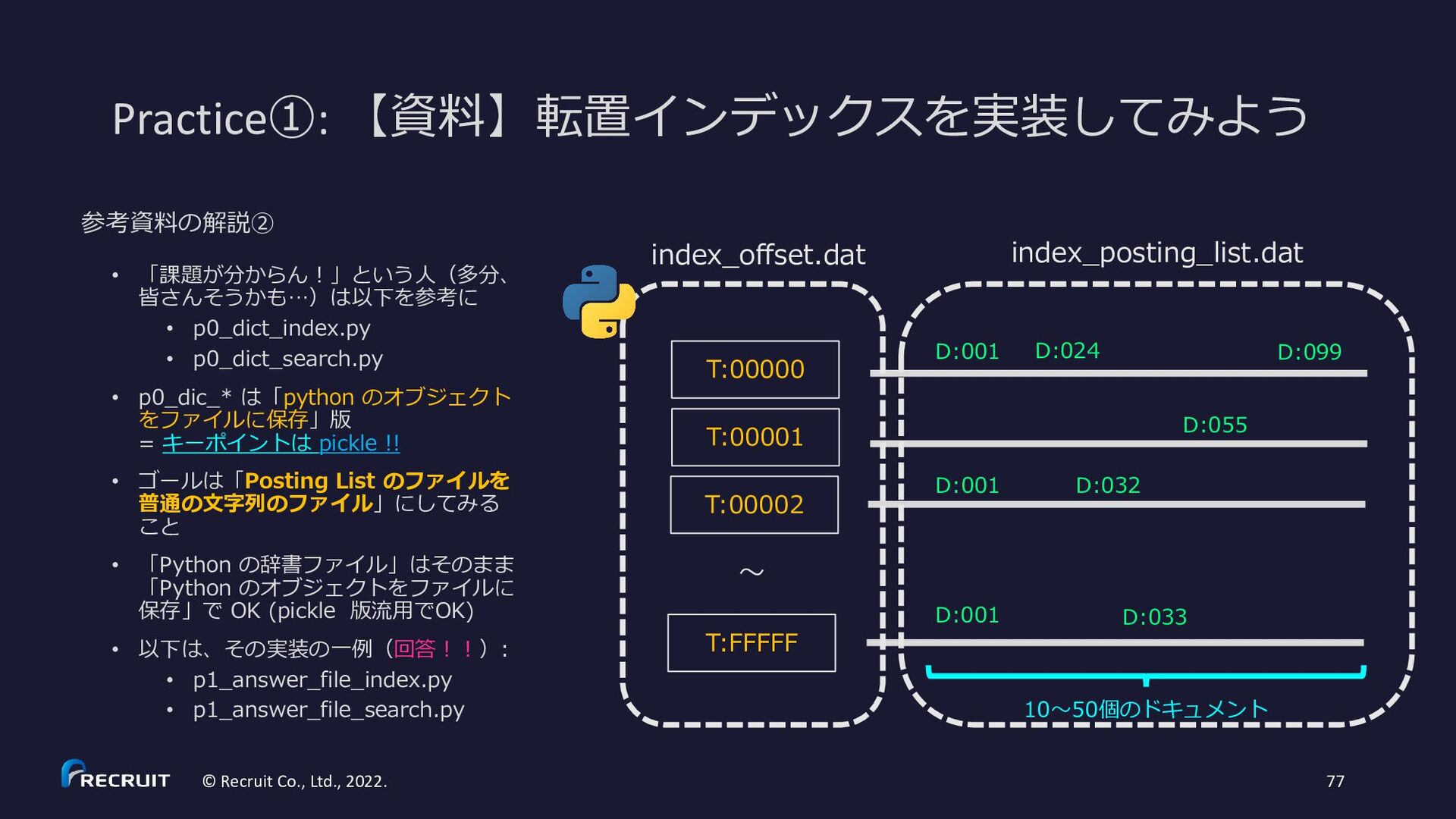{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
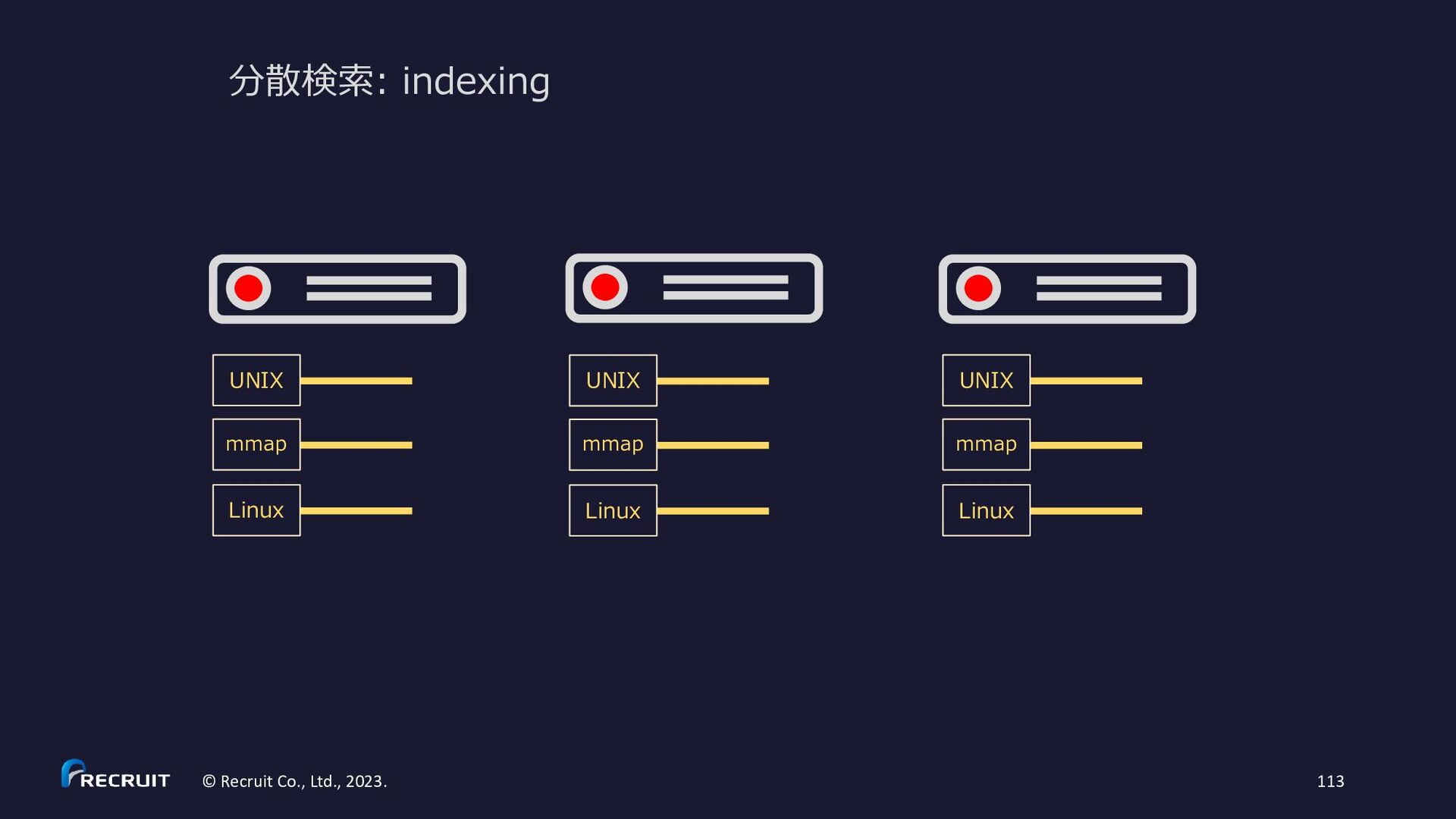{kind=link}
{kind=link}
{kind=link}
{kind=link}
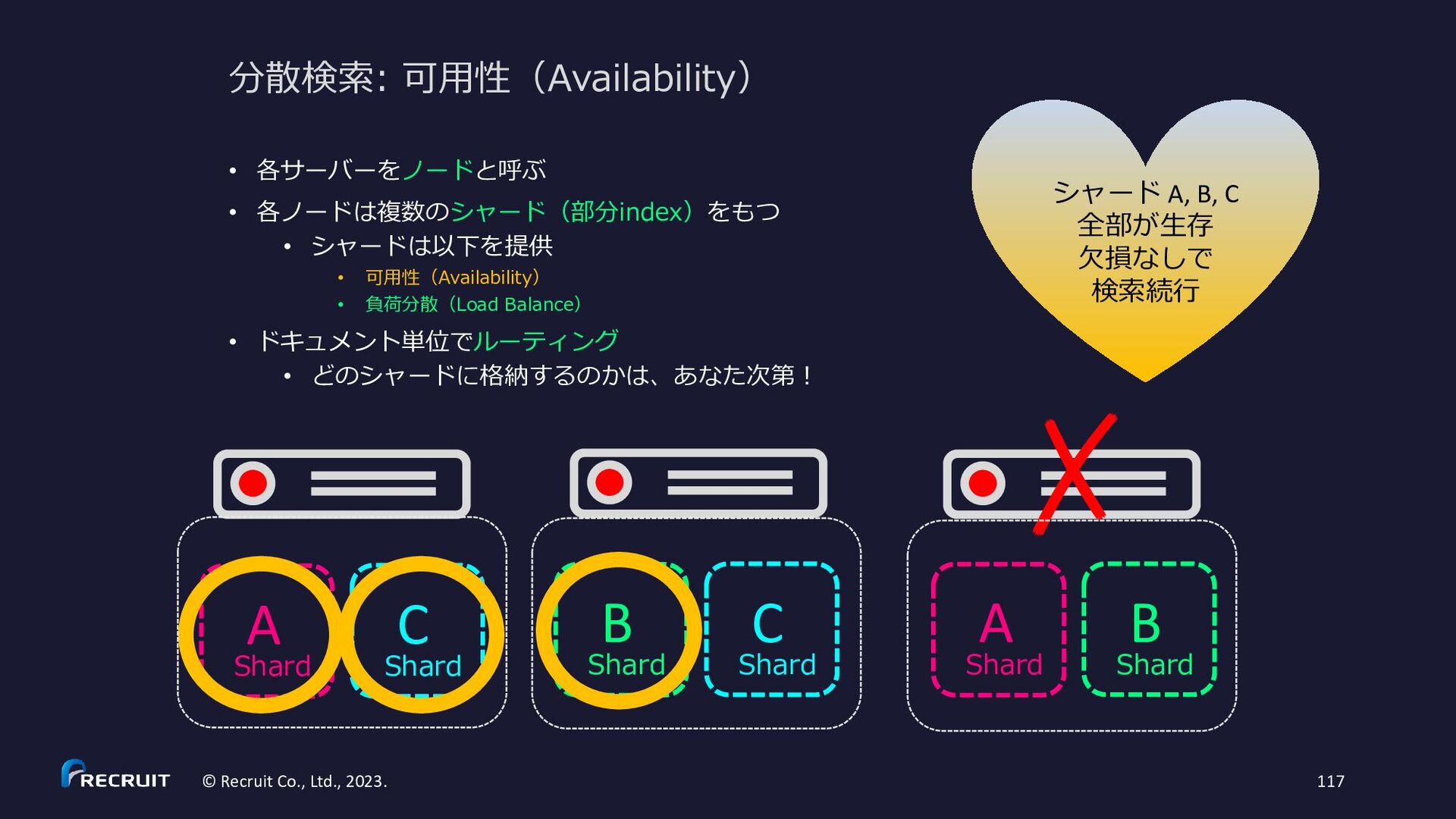{kind=link}
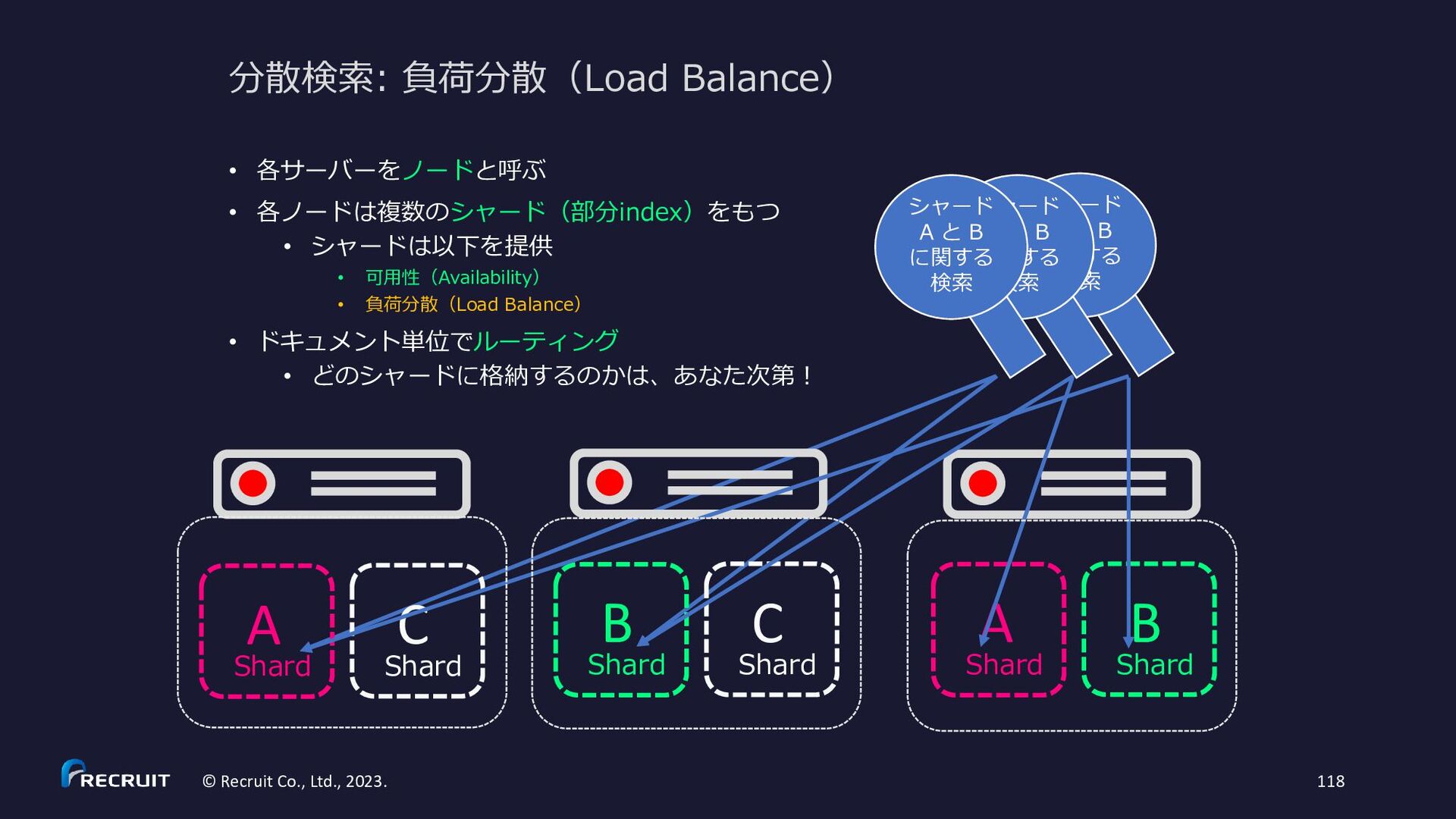{kind=link}
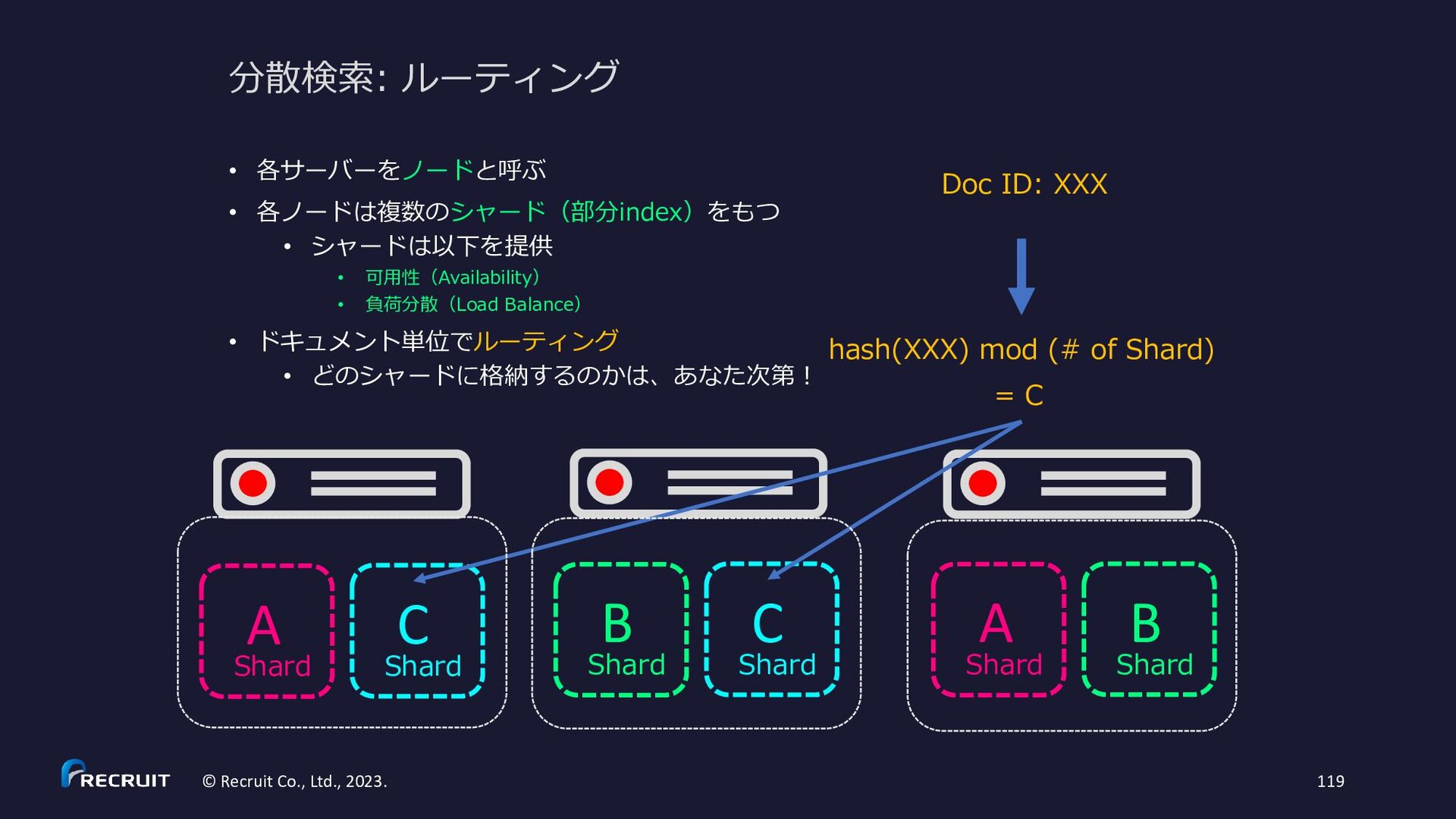{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
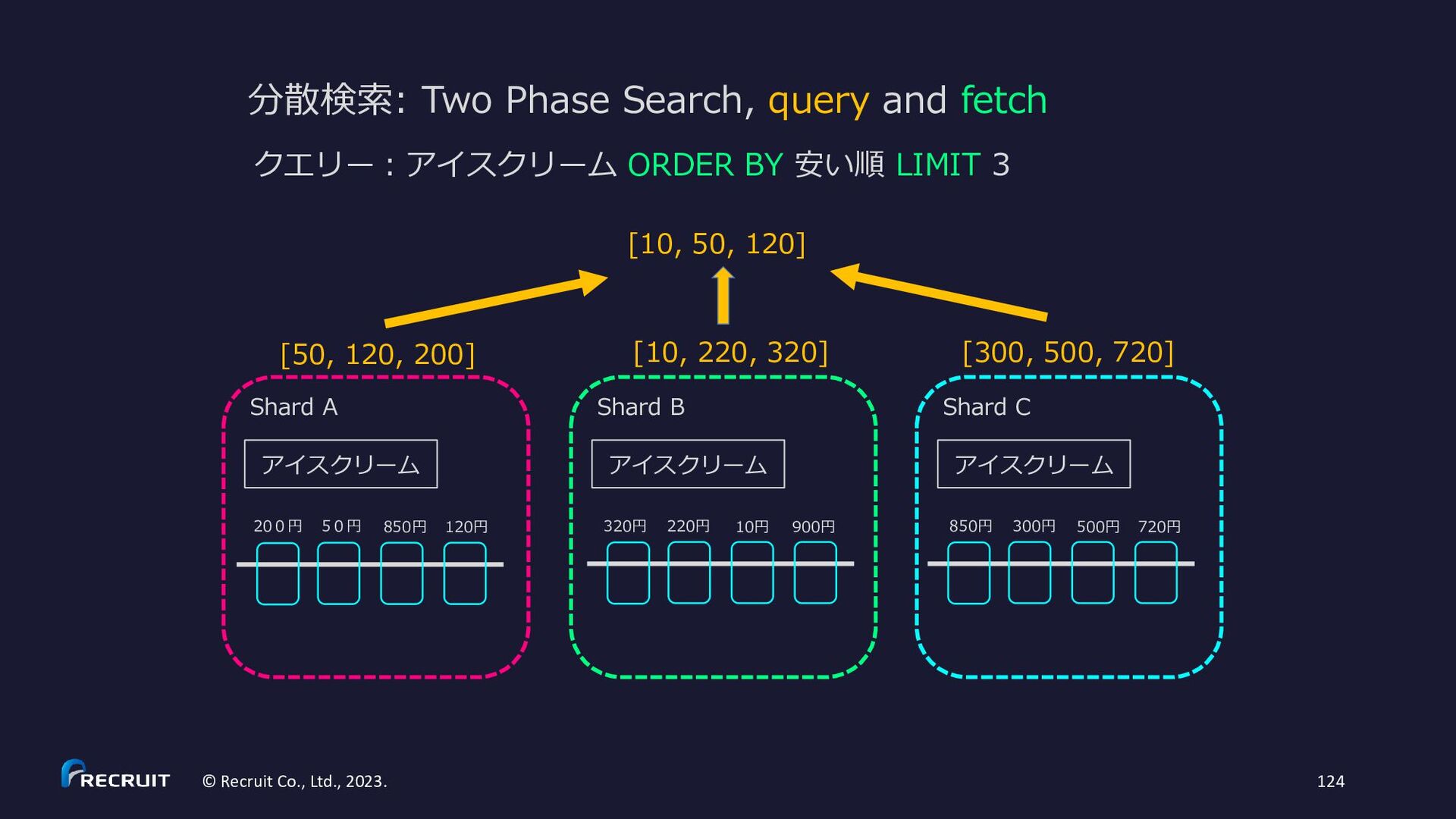{kind=link}
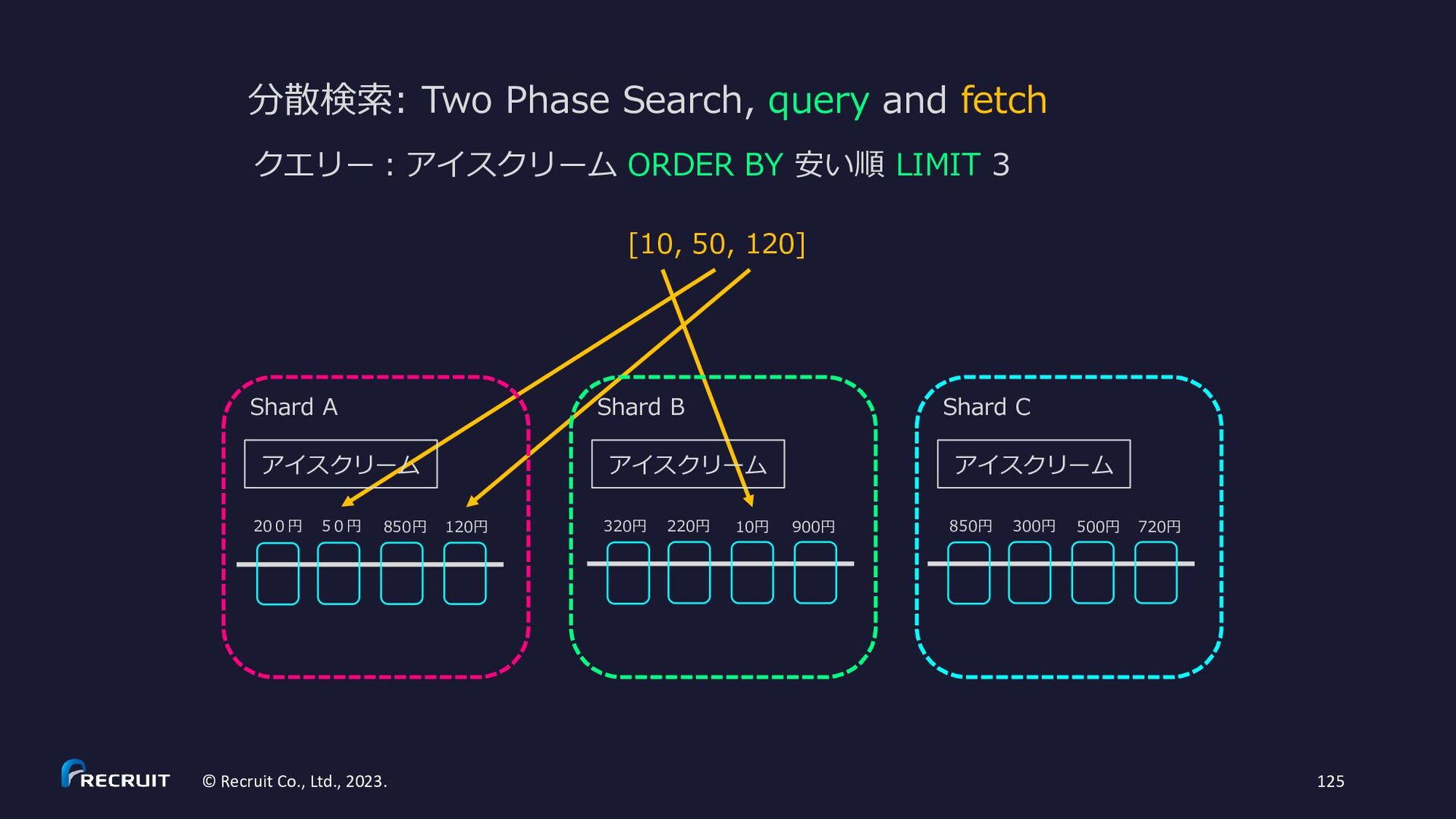{kind=link}
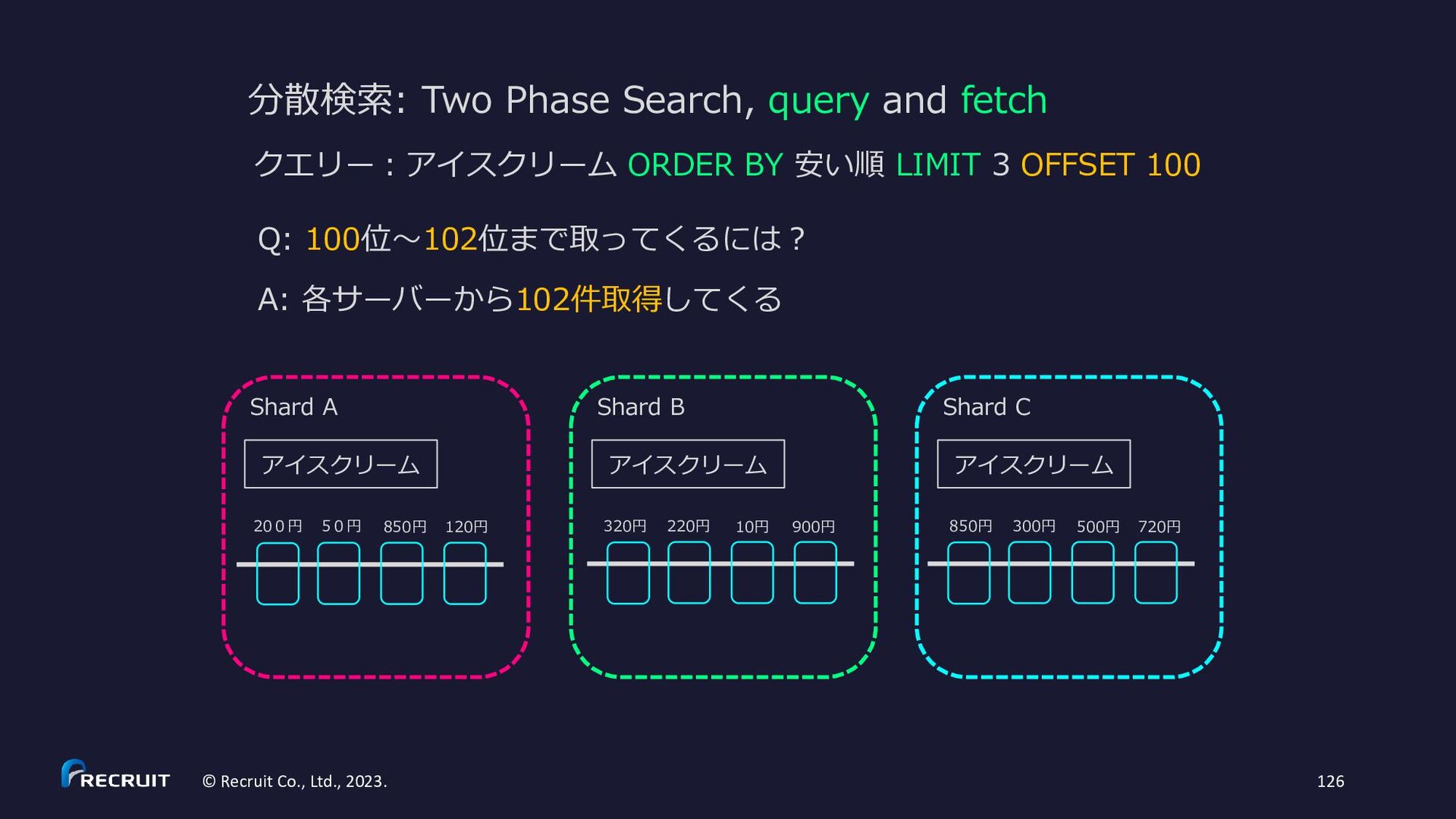{kind=link}
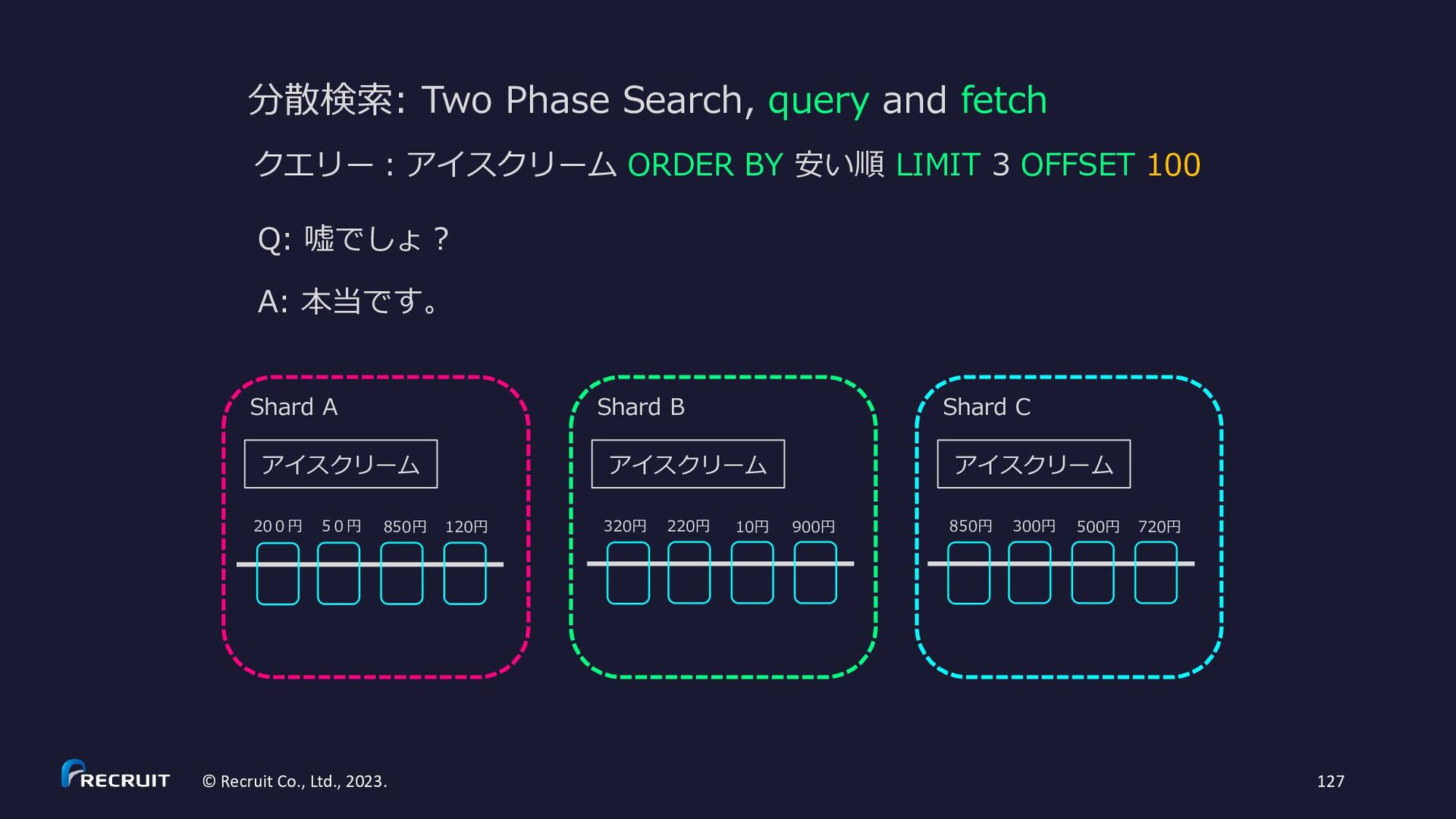{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
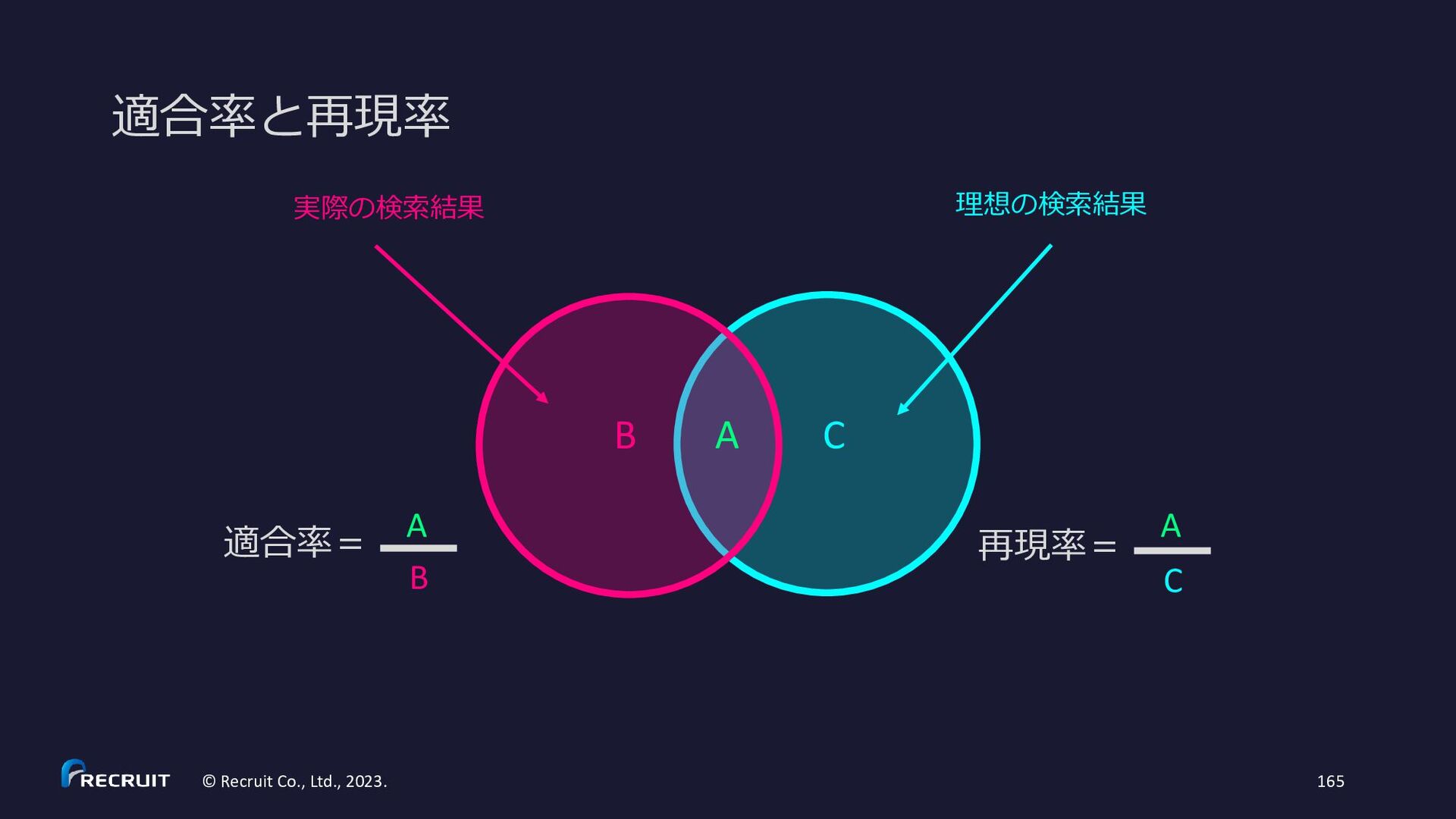{kind=link}
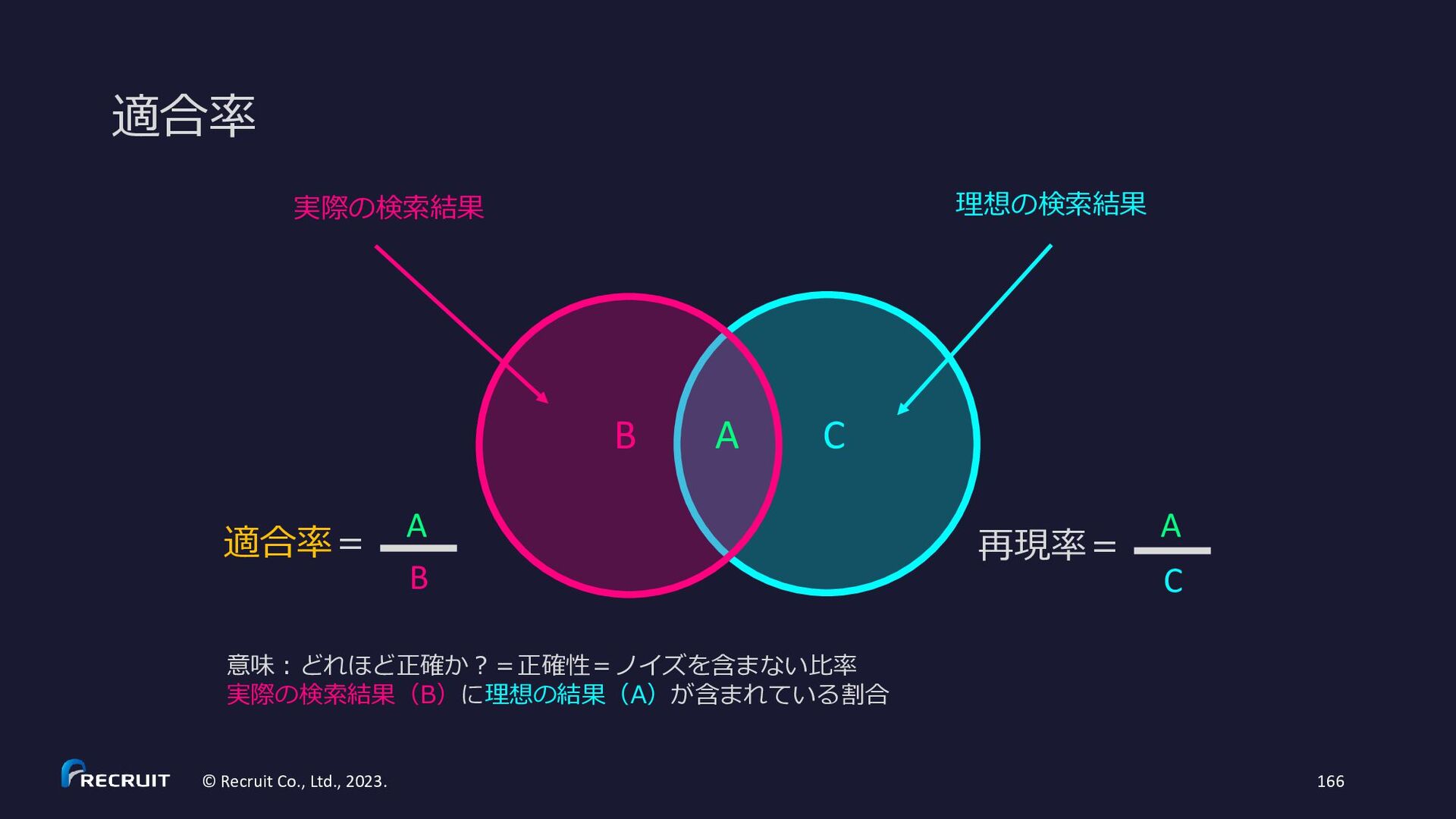{kind=link}
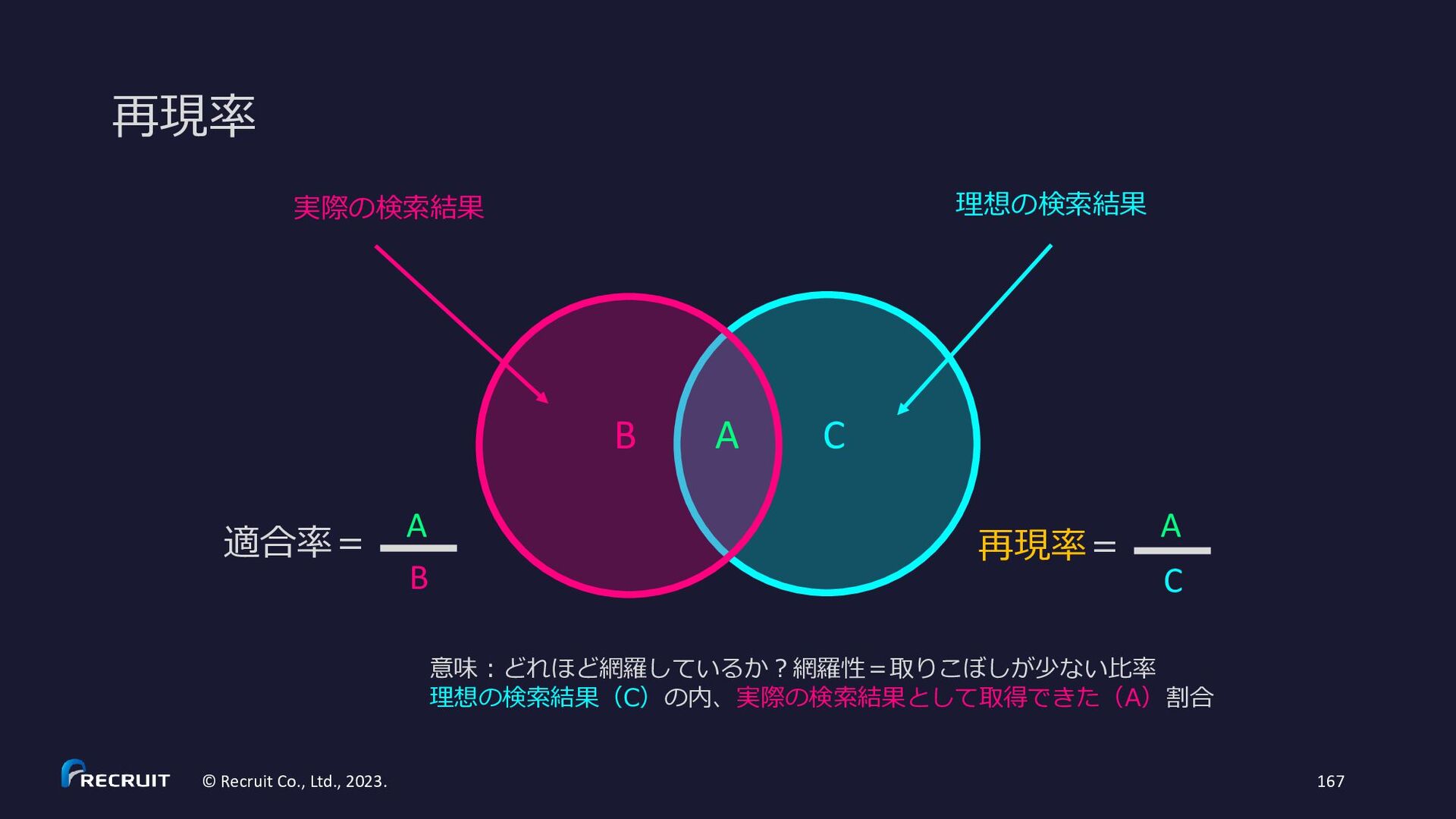{kind=link}
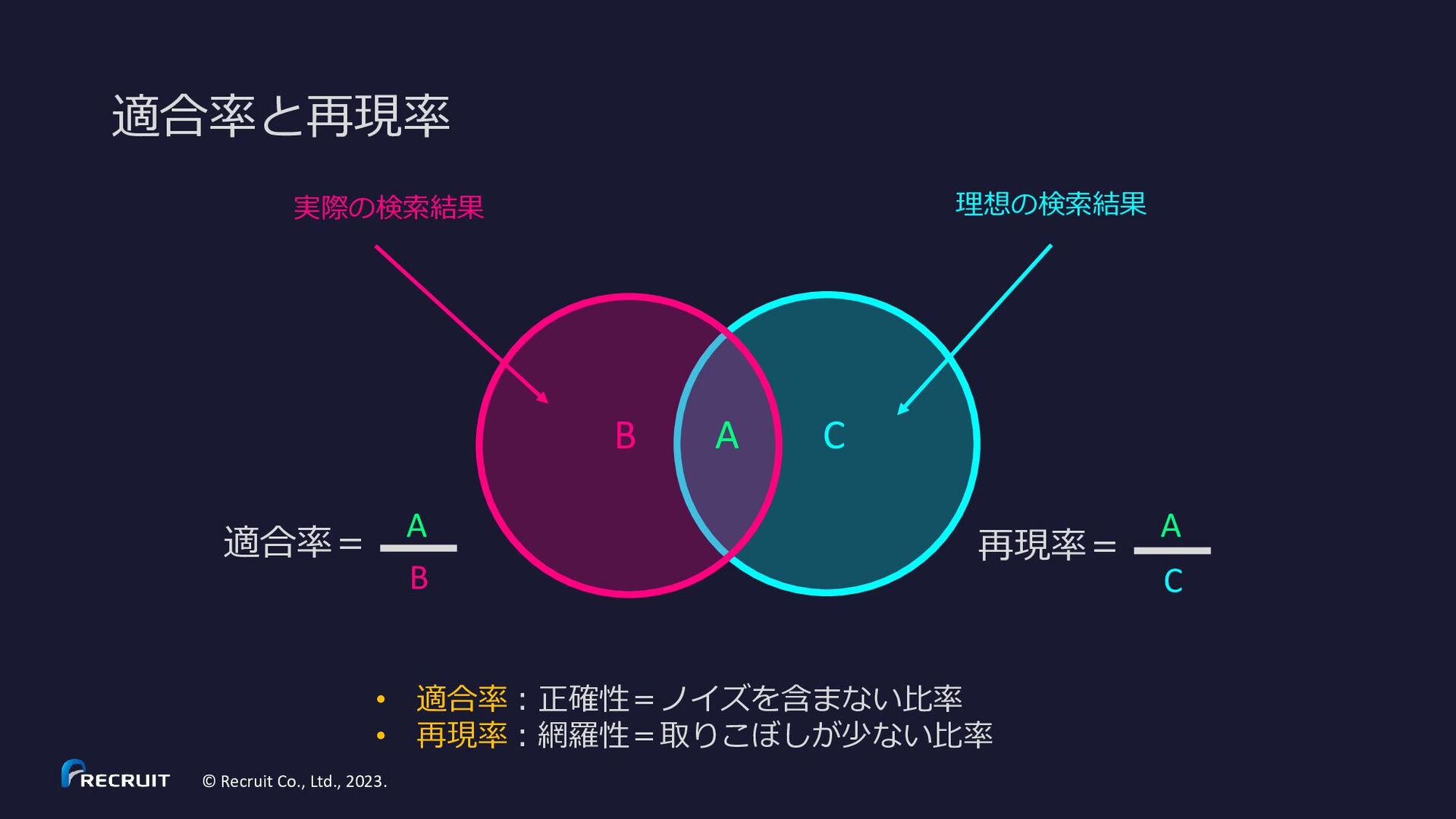{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
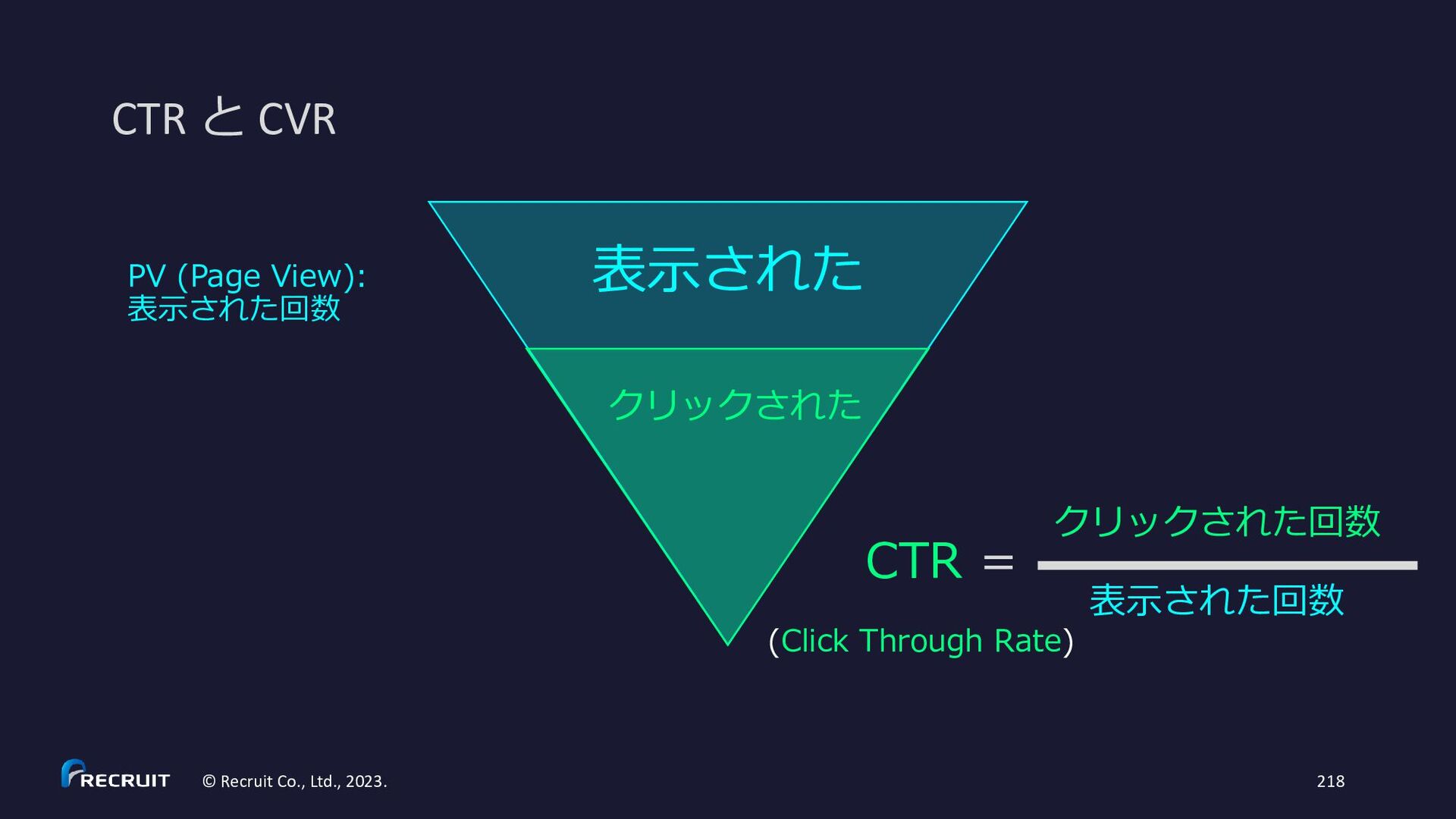{kind=link}
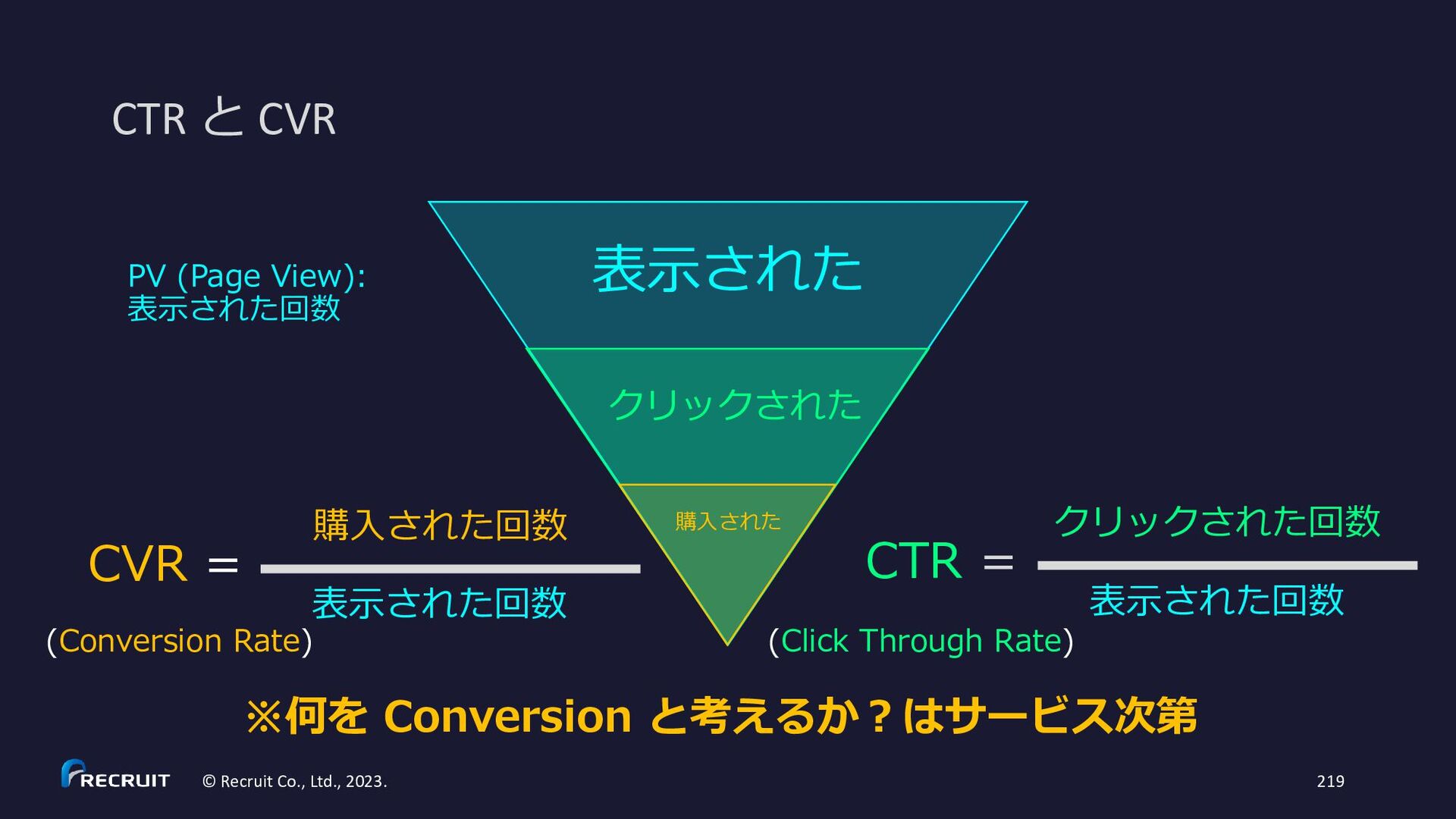{kind=link}
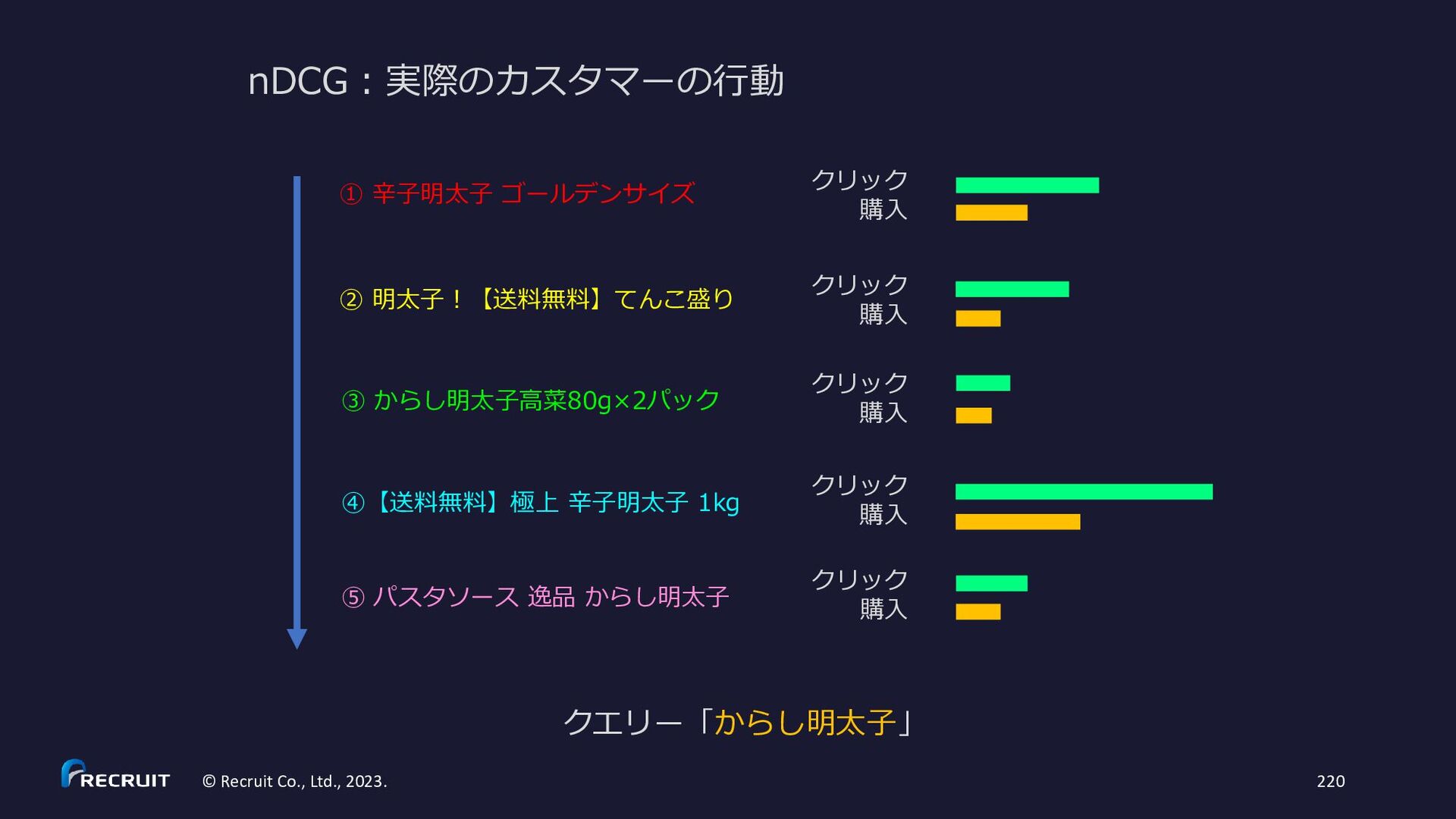{kind=link}
{kind=link}
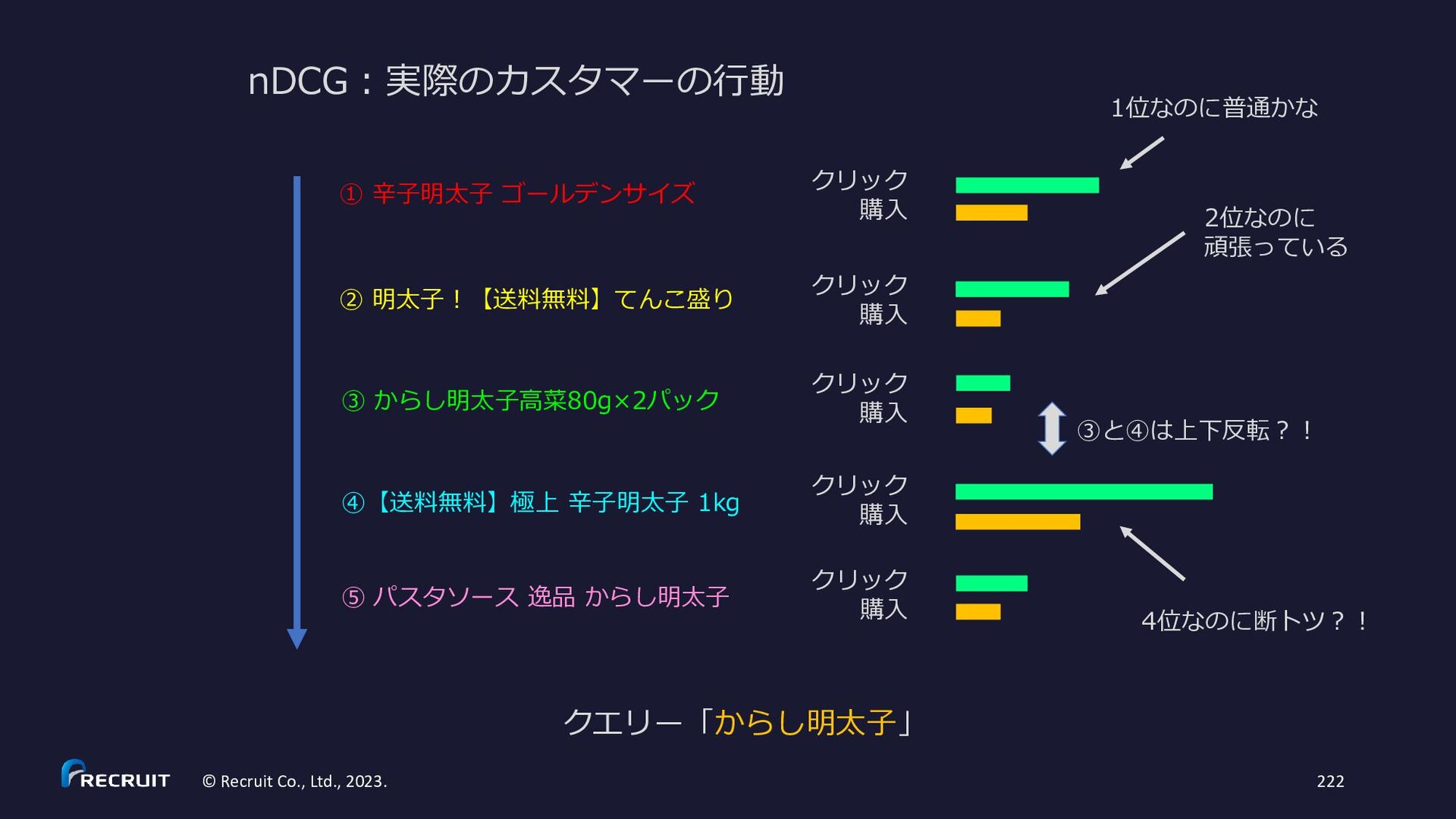{kind=link}
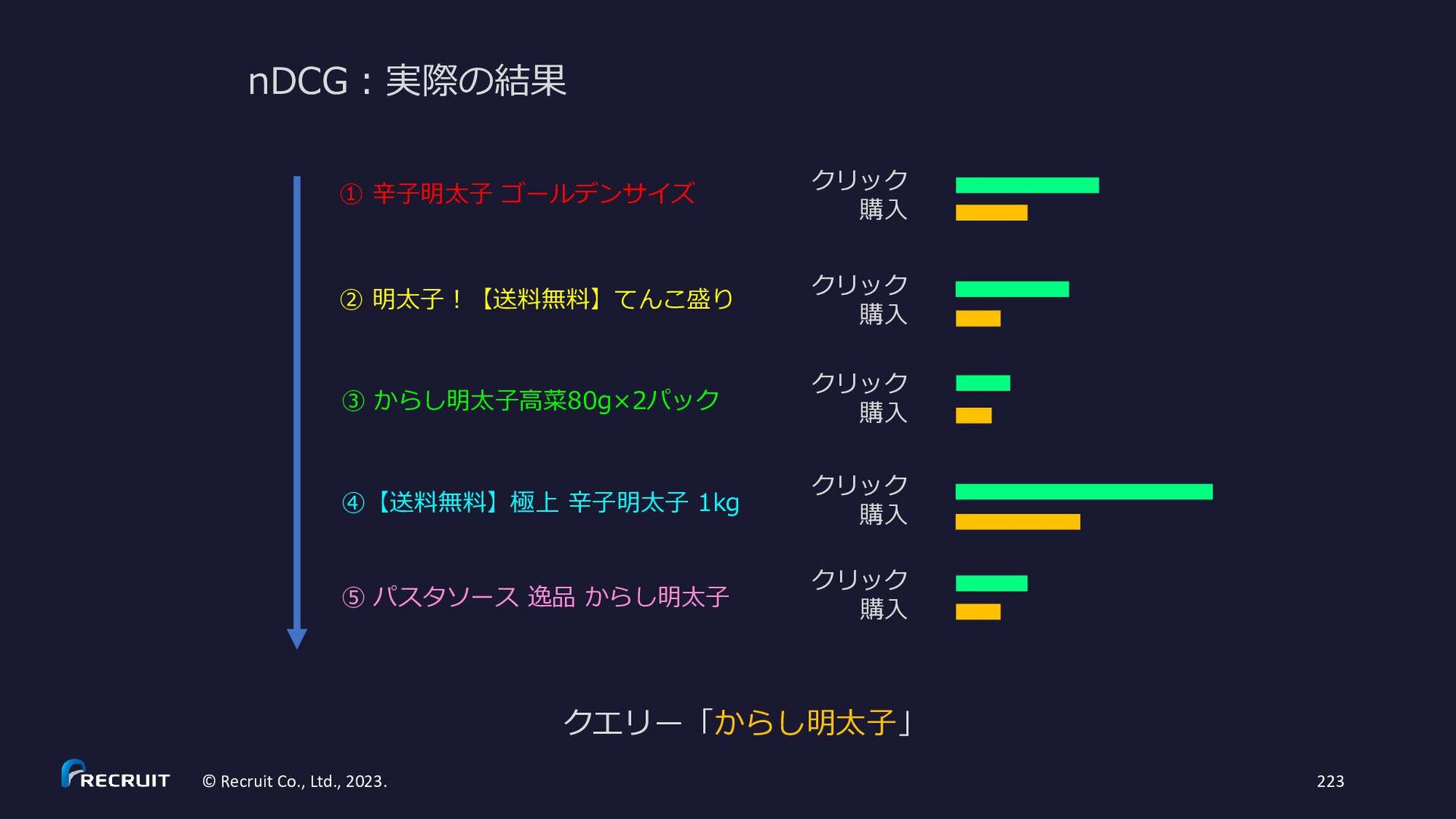{kind=link}
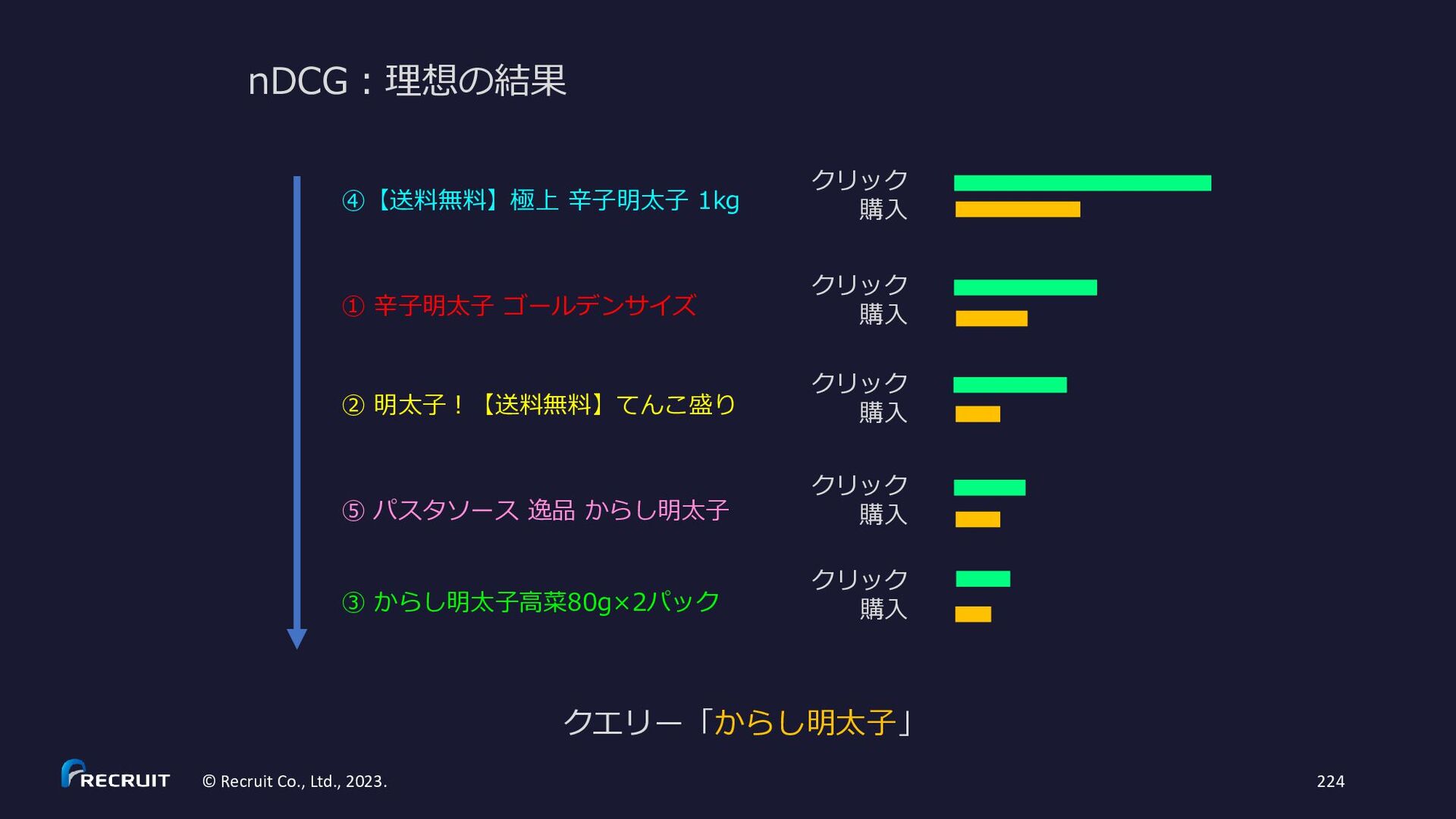{kind=link}
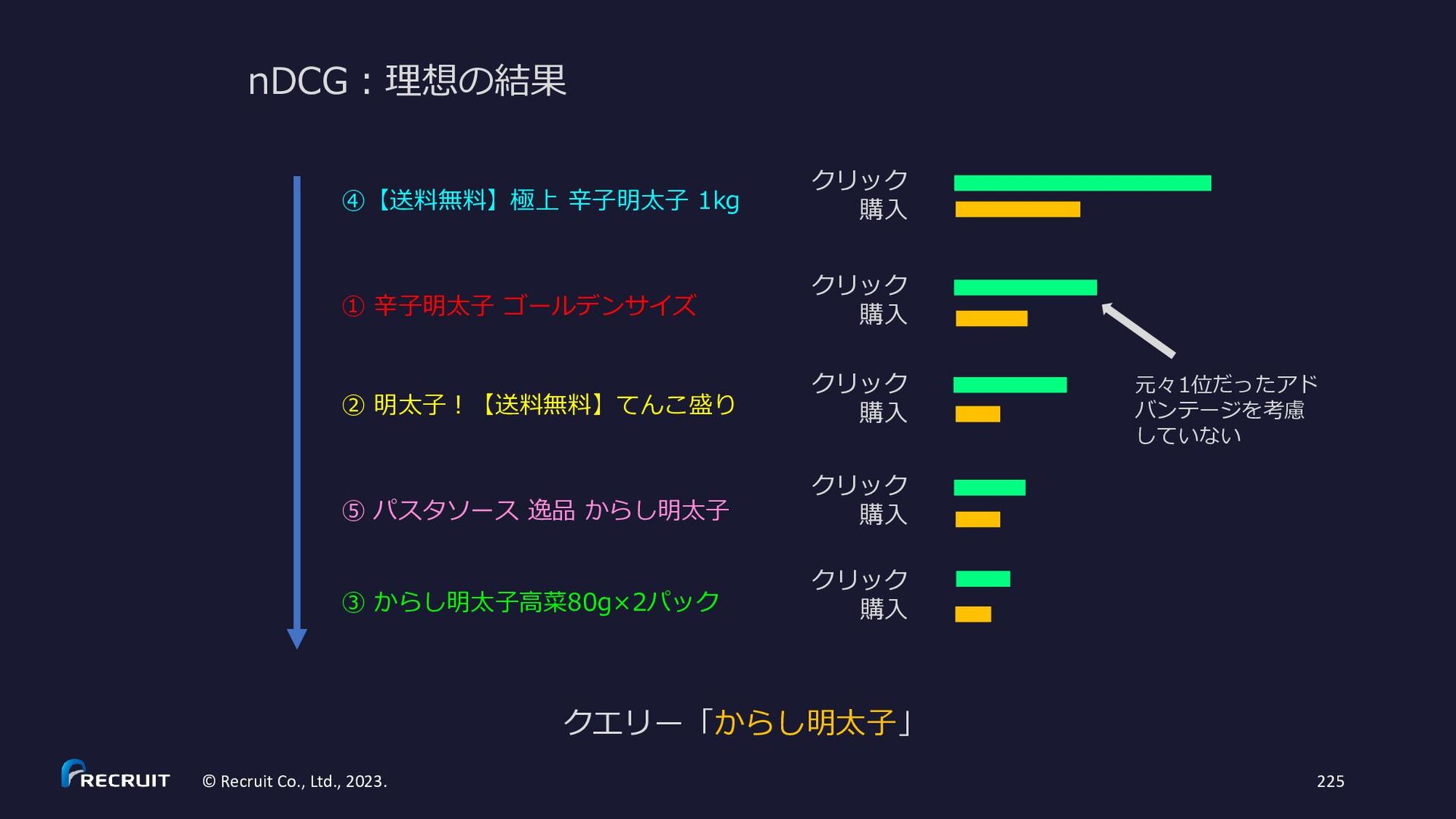{kind=link}
{kind=link}
{kind=link}
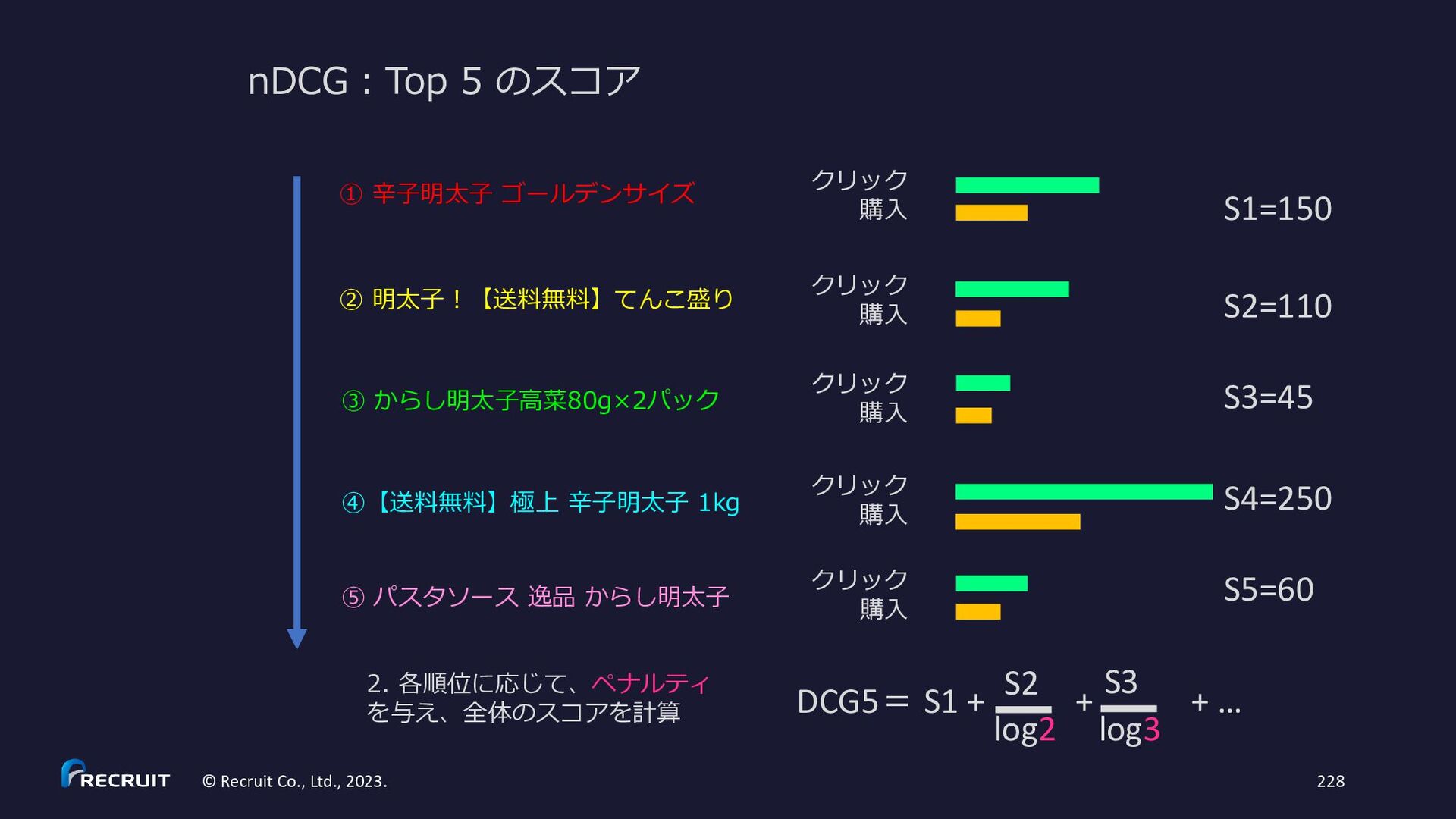{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}