Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
新規検索基盤でマッチング精度向上に挑む! ~『ホットペッパーグルメ』の開発事例 技術編
Search
Recruit
PRO
March 06, 2025
Technology
830
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
新規検索基盤でマッチング精度向上に挑む! ~『ホットペッパーグルメ』の開発事例 技術編
2025/2/20に開催したRecruit Tech Conference 2025の須藤の資料です
Recruit
PRO
March 06, 2025
More Decks by Recruit
See All by Recruit
開発が速く安くなった後の話 AI時代のソフトウェアエンジニアリング組織論 #devsumi
recruitengineers
PRO
4
1k
双方向推薦システムにおける長期的マッチング最大化に向けた代理目的関数の設計と実証
recruitengineers
PRO
0
100
就職⽀援サービスにおけるキャリアアドバイザーのシフトスケジューリング
recruitengineers
PRO
1
180
Model Routerを使った逐次LLM選択による毀損低減効果の検証
recruitengineers
PRO
1
63
ストリーム処理基盤のFlink移行検証と適材適所の実践
recruitengineers
PRO
2
110
AI 時代の Platform Engineering
recruitengineers
PRO
2
460
巨大プラットフォームを進化させる「第3のROI」
recruitengineers
PRO
2
3.6k
データ戦略を加速させる プラットフォーム エンジニアリングと進化的アーキテクチャ
recruitengineers
PRO
2
110
まなび領域における生成AI活用事例
recruitengineers
PRO
2
320
Other Decks in Technology
See All in Technology
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
130
知らん間に、回ってる
ming_ayami
0
530
貴方はどのエンジニアリングを磨くのか
hatyibei
0
130
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
580
アカウントが増えてからでは遅い? ~ マルチアカウント統制の勘所 ~
kenichinakamura
0
220
kintone の AI コワーカーを、 Anthropic にエージェントを"ホストさせて"作った話 #devkinmeetup
sugimomoto
0
100
GuardrailからGovernanceへ~AIエージェント運用の次の課題~
sbspsy
2
270
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.3k
ゼロをイチにする仕事が終わったあと
smasato
0
340
クラウド上のデータ復旧で見落としがちな制約: 医療系 SaaS の BCP 設計から得た教訓
kakehashi
PRO
0
3.4k
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
180
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
120
Featured
See All Featured
BBQ
matthewcrist
89
10k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
370
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
760
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
260
Why Our Code Smells
bkeepers
PRO
340
58k
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
610
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.2k
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
Designing for Performance
lara
611
70k
Transcript
新規検索基盤でマッチング精度向上に挑む! ~『ホットペッパーグルメ』の開発事例 RECRUIT TECH CONFERENCE 2025 技術編 須藤 遼介 株式会社リクルート
プロダクトディベロップメント室
須藤 遼介 ゲーム・NBA観戦・ラーメン 経歴 / Career 2019年にリクルートにキャリア採用入社。 機械学習エンジニアとして各種領域を担当 2024年より飲食領域の検索基盤開発・ロジック開発を担当 趣味
/ Hobbies データ推進室 販促領域データソリューション3ユニット (飲食・ビューティー) 飲食・ビューティーデータソリューション部 飲食・ビューティーデータエンジニアリングG
新規検索基盤の構築
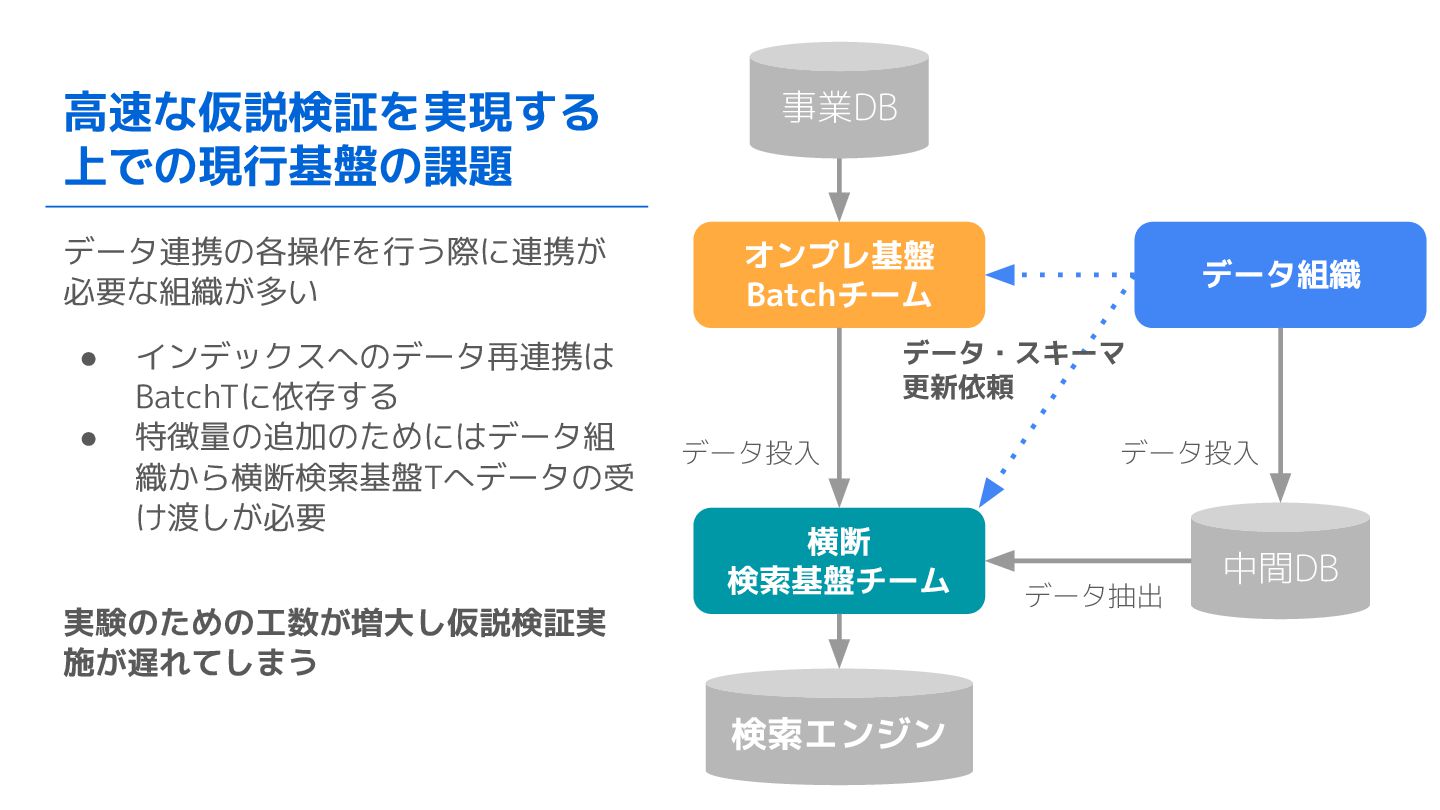
高速な仮説検証を実現する 上での現行基盤の課題 データ連携の各操作を行う際に連携が 必要な組織が多い • インデックスへのデータ再連携は BatchTに依存する • 特徴量の追加のためにはデータ組 織から横断検索基盤Tへデータの受
け渡しが必要 実験のための工数が増大し仮説検証実 施が遅れてしまう オンプレ基盤 Batchチーム 横断 検索基盤チーム データ組織 データ投入 事業DB 中間DB データ抽出 データ・スキーマ 更新依頼 データ投入 検索エンジン
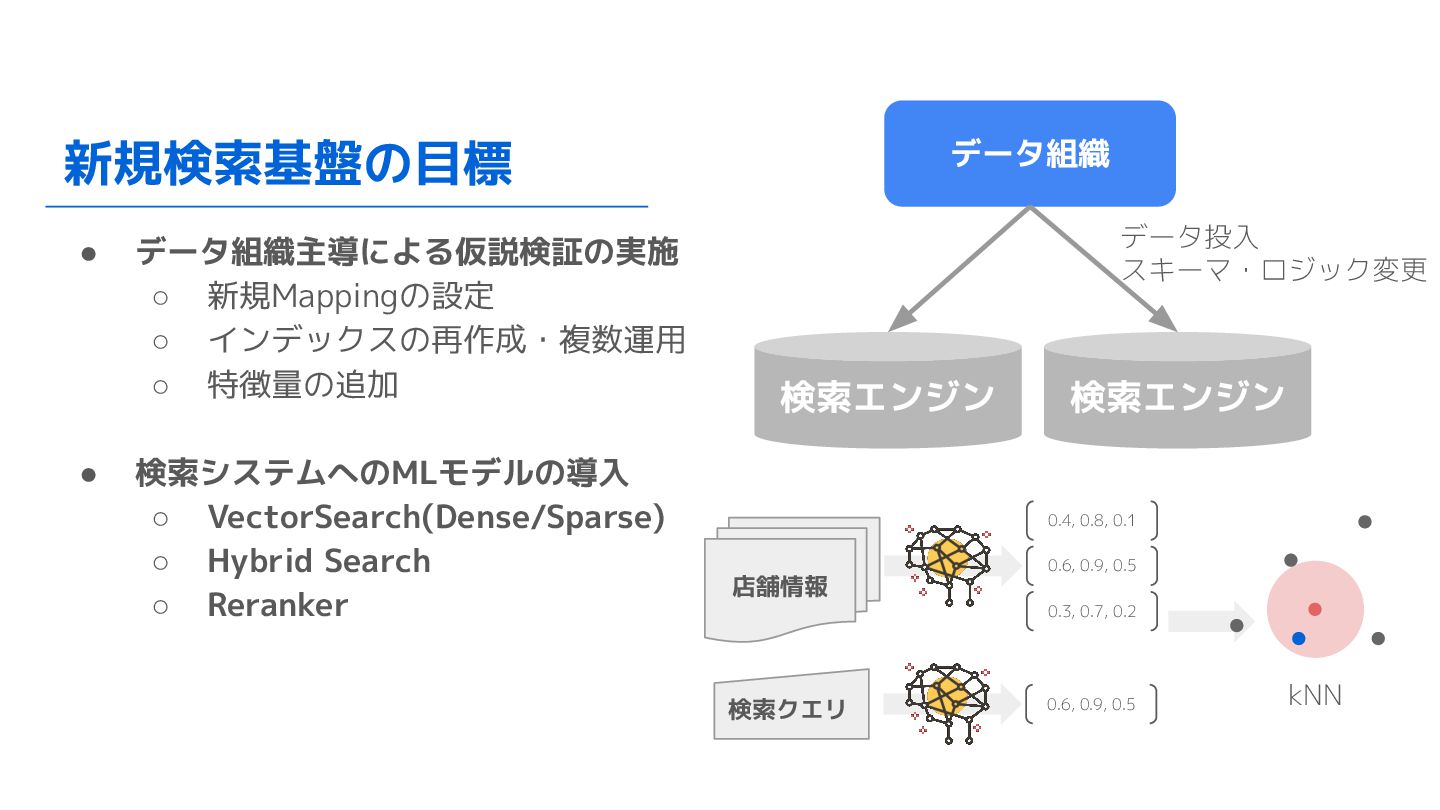
新規検索基盤の目標 • データ組織主導による仮説検証の実施 ◦ 新規Mappingの設定 ◦ インデックスの再作成・複数運用 ◦ 特徴量の追加 •
検索システムへのMLモデルの導入 ◦ VectorSearch(Dense/Sparse) ◦ Hybrid Search ◦ Reranker データ組織 データ投入 スキーマ・ロジック変更 検索エンジン 店舗情報 0.4, 0.8, 0.1 0.6, 0.9, 0.5 0.3, 0.7, 0.2 検索クエリ 0.6, 0.9, 0.5 kNN 検索エンジン
Amazon OpenSearch Serviceの導入 検索エンジンとしてOpenSearchを導入 • 現行のElastic Searchからの資産が活かせる ◦ SearchTemplate /
Index Mapping • 無停止アップグレードに対応 ◦ Blue/Green Deploy • マネージドのETLツールも用意 • 基本的なベクトル検索やHybrid Searchに対応 • AWSで構築された社内ML基盤との連携が容易 社内のAWSで構築された API/Job基盤 Amazon OpenSearch Service Amazon OpenSearch Ingestion
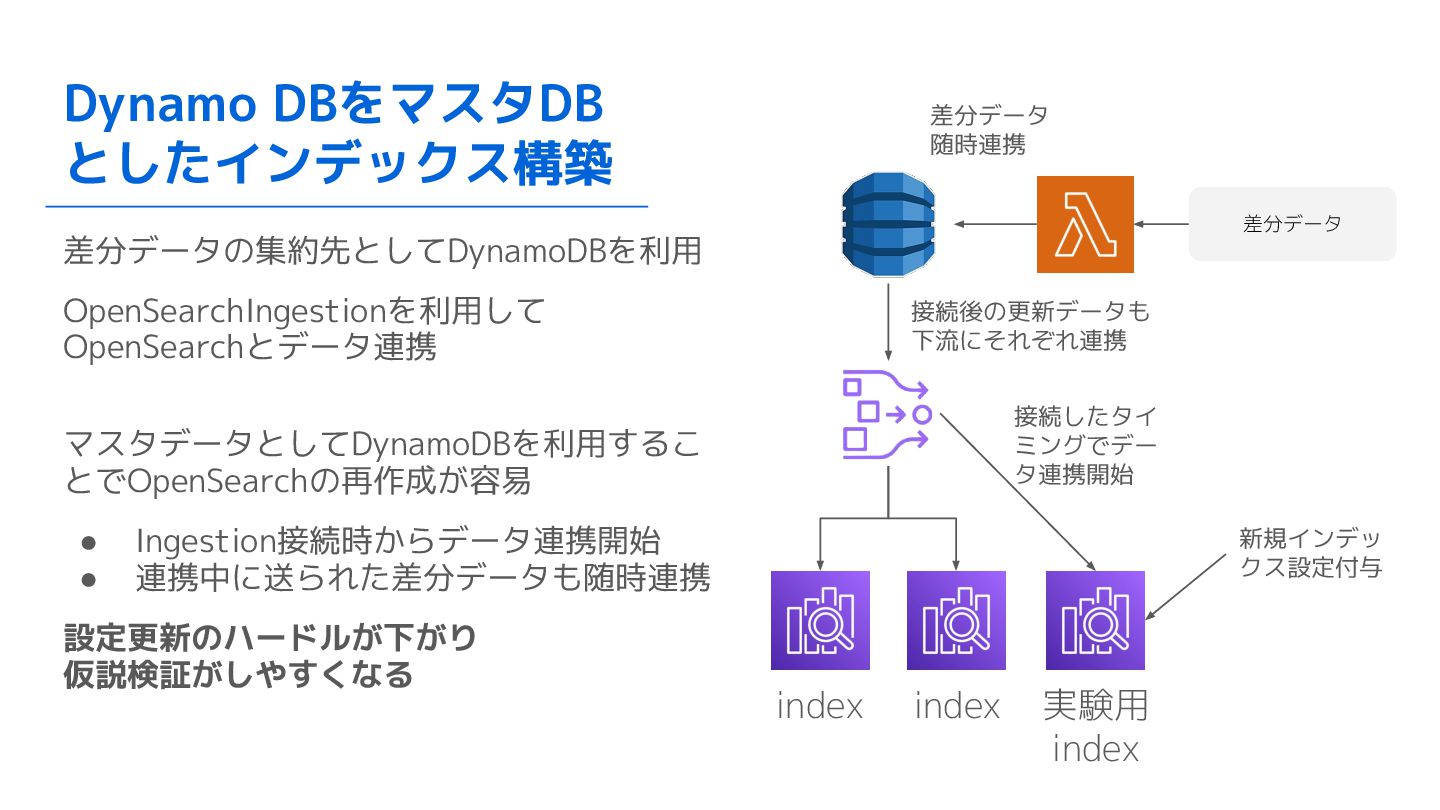
Dynamo DBをマスタDB としたインデックス構築 差分データの集約先としてDynamoDBを利用 OpenSearchIngestionを利用して OpenSearchとデータ連携 マスタデータとしてDynamoDBを利用するこ とでOpenSearchの再作成が容易 • Ingestion接続時からデータ連携開始
• 連携中に送られた差分データも随時連携 設定更新のハードルが下がり 仮説検証がしやすくなる 差分データ 新規インデッ クス設定付与 接続したタイ ミングでデー タ連携開始 index index 実験用 index 差分データ 随時連携 接続後の更新データも 下流にそれぞれ連携
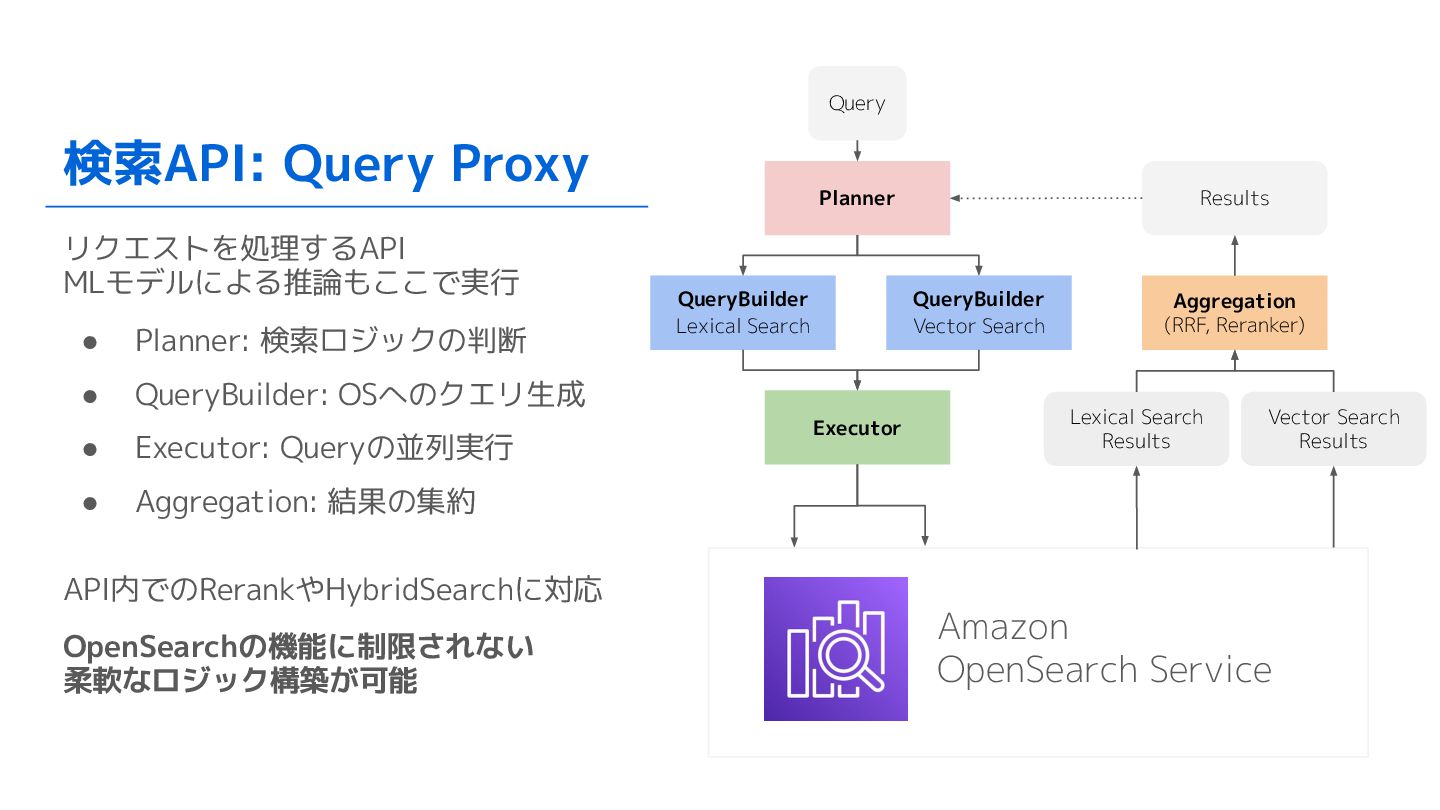
検索API: Query Proxy リクエストを処理するAPI MLモデルによる推論もここで実行 • Planner: 検索ロジックの判断 • QueryBuilder:
OSへのクエリ生成 • Executor: Queryの並列実行 • Aggregation: 結果の集約 API内でのRerankやHybridSearchに対応 OpenSearchの機能に制限されない 柔軟なロジック構築が可能 Planner QueryBuilder Lexical Search QueryBuilder Vector Search Executor Lexical Search Results Vector Search Results Aggregation (RRF, Reranker) Results Query Amazon OpenSearch Service
実際に運用してみて • インデックスの再作成のハードルは非常に下がった ◦ Mappingの変更などは非常に簡単に行える • OpenSearchIngestionはかなりハマりポイントが多かった ◦ 更なるドキュメントの拡充を期待! •
OpenSearchのベクトル検索機能は限定的 ◦ ベクトル検索の機能を外出しするのは必須の判断だったかも
検索ロジックの改善
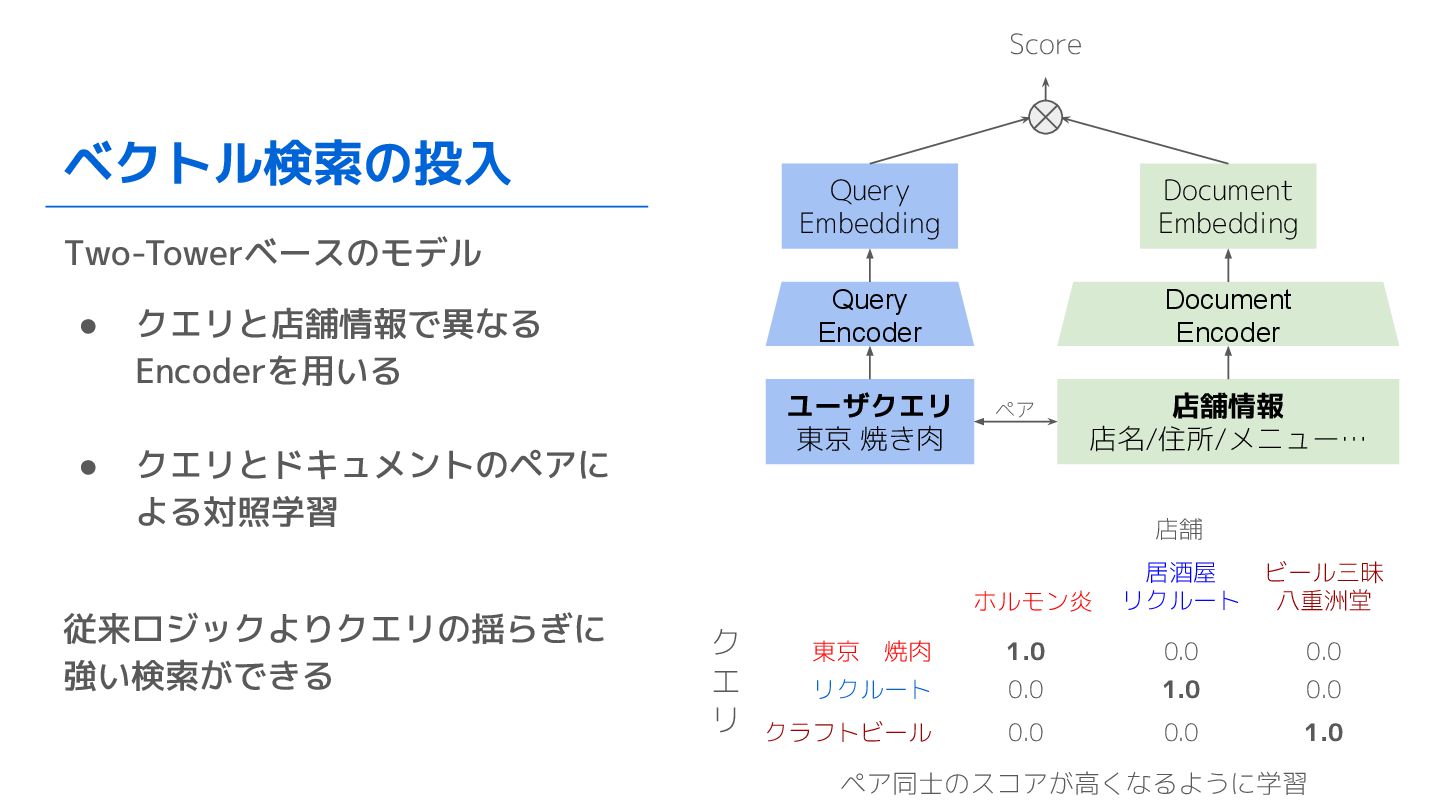
ベクトル検索の投入 Two-Towerベースのモデル • クエリと店舗情報で異なる Encoderを用いる • クエリとドキュメントのペアに よる対照学習 従来ロジックよりクエリの揺らぎに 強い検索ができる
東京 焼肉 リクルート クラフトビール ホルモン炎 居酒屋 リクルート ビール三昧 八重洲堂 1.0 1.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 ユーザクエリ 東京 焼き肉 店舗情報 店名/住所/メニュー… Query Encoder Document Encoder Query Embedding Document Embedding ペア Score ク エ リ 店舗 ペア同士のスコアが高くなるように学習
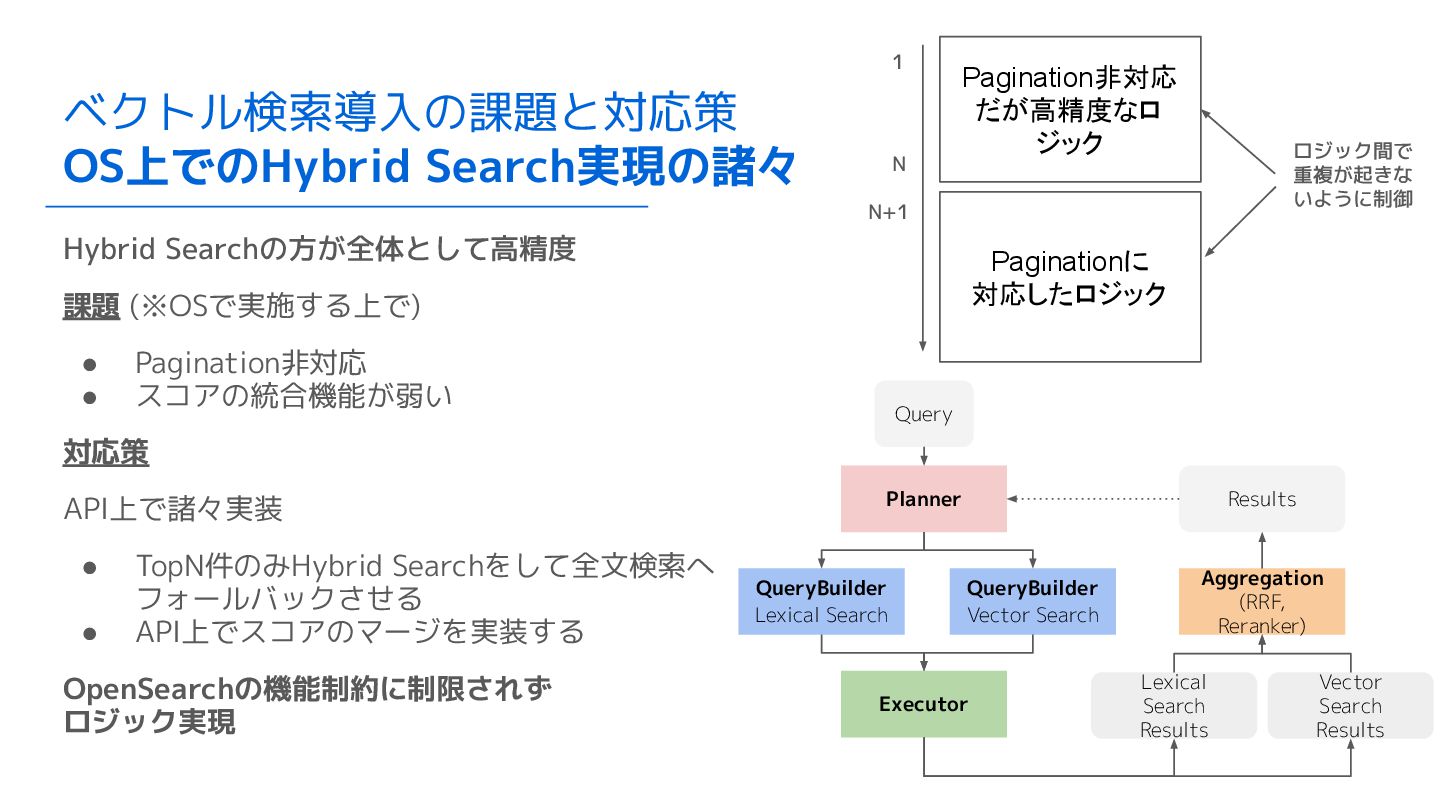
ベクトル検索導入の課題と対応策 OS上でのHybrid Search実現の諸々 Hybrid Searchの方が全体として高精度 課題 (※OSで実施する上で) • Pagination非対応 •
スコアの統合機能が弱い 対応策 API上で諸々実装 • TopN件のみHybrid Searchをして全文検索へ フォールバックさせる • API上でスコアのマージを実装する OpenSearchの機能制約に制限されず ロジック実現 Pagination非対応 だが高精度なロ ジック Paginationに 対応したロジック Planner QueryBuilder Lexical Search QueryBuilder Vector Search Executor Lexical Search Results Vector Search Results Aggregation (RRF, Reranker) Results Query ロジック間で 重複が起きな いように制御 1 N N+1
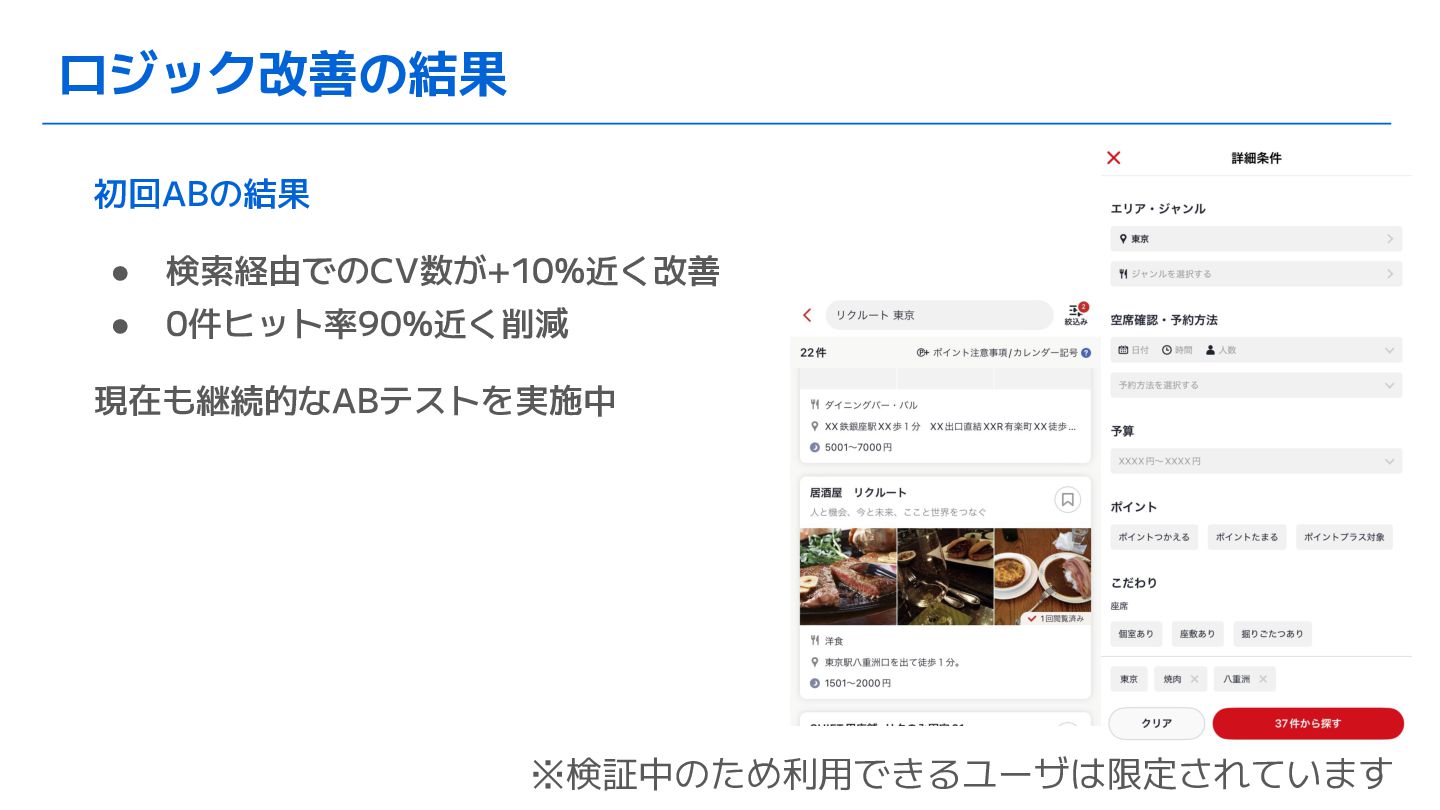
ロジック改善の結果 初回ABの結果 • 検索経由でのCV数が+10%近く改善 • 0件ヒット率90%近く削減 現在も継続的なABテストを実施中 ※検証中のため利用できるユーザは限定されています
まとめ 基盤 • 設定変更・再構築のしやすい検索システムを構築 Open Search/Ingestion/DynamoDB • API上でHybridSearch/Rerankingを行うことでOSの制約にとらわれない ロジックの実装に対応 ロジック
• Two-Towerモデルを中心にしたベクトル検索ロジックを作成 • 各種精度向上の工夫により本番ABテストで10%近くのCV向上を実現
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}