Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
アーキテクトが考えるシステム改善を継続するための心得 / tech-meetup2_nishi...
Search
Recruit
PRO
January 21, 2022
Technology
630
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
アーキテクトが考えるシステム改善を継続するための心得 / tech-meetup2_nishimura
2022/01/20_RECRUIT TECH MEETUP #2での、西村の講演資料になります
Recruit
PRO
January 21, 2022
More Decks by Recruit
See All by Recruit
AIネイティブ時代における 開発組織の役割と拡張の可能性
recruitengineers
PRO
2
230
開発が速く安くなった後の話 AI時代のソフトウェアエンジニアリング組織論 #devsumi
recruitengineers
PRO
45
31k
双方向推薦システムにおける長期的マッチング最大化に向けた代理目的関数の設計と実証
recruitengineers
PRO
1
160
就職⽀援サービスにおけるキャリアアドバイザーのシフトスケジューリング
recruitengineers
PRO
1
210
Model Routerを使った逐次LLM選択による毀損低減効果の検証
recruitengineers
PRO
2
83
ストリーム処理基盤のFlink移行検証と適材適所の実践
recruitengineers
PRO
2
120
AI 時代の Platform Engineering
recruitengineers
PRO
3
520
巨大プラットフォームを進化させる「第3のROI」
recruitengineers
PRO
2
3.7k
データ戦略を加速させる プラットフォーム エンジニアリングと進化的アーキテクチャ
recruitengineers
PRO
3
130
Other Decks in Technology
See All in Technology
CTOキーノート:AI時代の「つなぐ」を再定義 ― 真のIoTとリアルワールドAI【SORACOM Discovery 2026】
soracom
PRO
0
290
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
560
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
データ活用研修 問いの発見と仮説構築【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
530
AI工学特論: MLOps・継続的評価
asei
11
2.9k
現場で使える AWS DevOps Agent 活用ノウハウ - Release Management 機能の検証結果を添えて / AWS DevOps Agent Release Management and Know-How
kinunori
3
420
reFACToring
moznion
1
790
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
2
160
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
15
6k
「休む」重要さ
smt7174
7
1.8k
AI研修(Day1)【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
2.2k
QA・ソフトウェアテスト研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
3
1.5k
Featured
See All Featured
Art, The Web, and Tiny UX
lynnandtonic
304
22k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
280
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
420
Java REST API Framework Comparison - PWX 2021
mraible
34
9.6k
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
180
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
430
Facilitating Awesome Meetings
lara
57
7k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.6k
First, design no harm
axbom
PRO
2
1.2k
The Pragmatic Product Professional
lauravandoore
37
7.4k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.7k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
640
Transcript
アーキテクトが考える システム改善を継続するための心得 2022年1月20日 西村祐樹
2 ミッション「まだ、ここにない、出会い。」を「より早く、シンプルに、もっと近くに。」実現 人材領域と販促領域で、事業者と個人のマッチング支援、事業者の業務・経営支援などを行っている 販促領域 (主に国内) リクルートグループの事業領域は「人材」と「販促」 人材領域 (国内外) 3
自己紹介 西村祐樹 2019年6月 株式会社リクルートテクノロジーズ(当時)入社 所属 プロダクト統括本部 HRアーキテクトグループ 最近やってること ・技術難度の高い案件の支援(設計、コーディングなど) ・注力サービスへの技術、運用支援
など
本日話す内容 1.アーキテクトグループの紹介 2.事例をもとに改善の考え方紹介 ※ Kubernetesやコンテナの話も途中入りますが、細かな内容には触れません
アーキテクトグループの紹介
・システムの安定稼働、開発を維持するために構造的な問題を解決して 価値を発揮するグループ ・技術の精通だけでなく、現場の課題認識と解決能力も求められる (いわゆるシステム設計だけにとどまらない) ・主に古くからある大規模システムを担当している (古くからある大規模システム ≒ ビジネス規模の大きいシステム) アーキテクトグループとは 私の主な担当システム
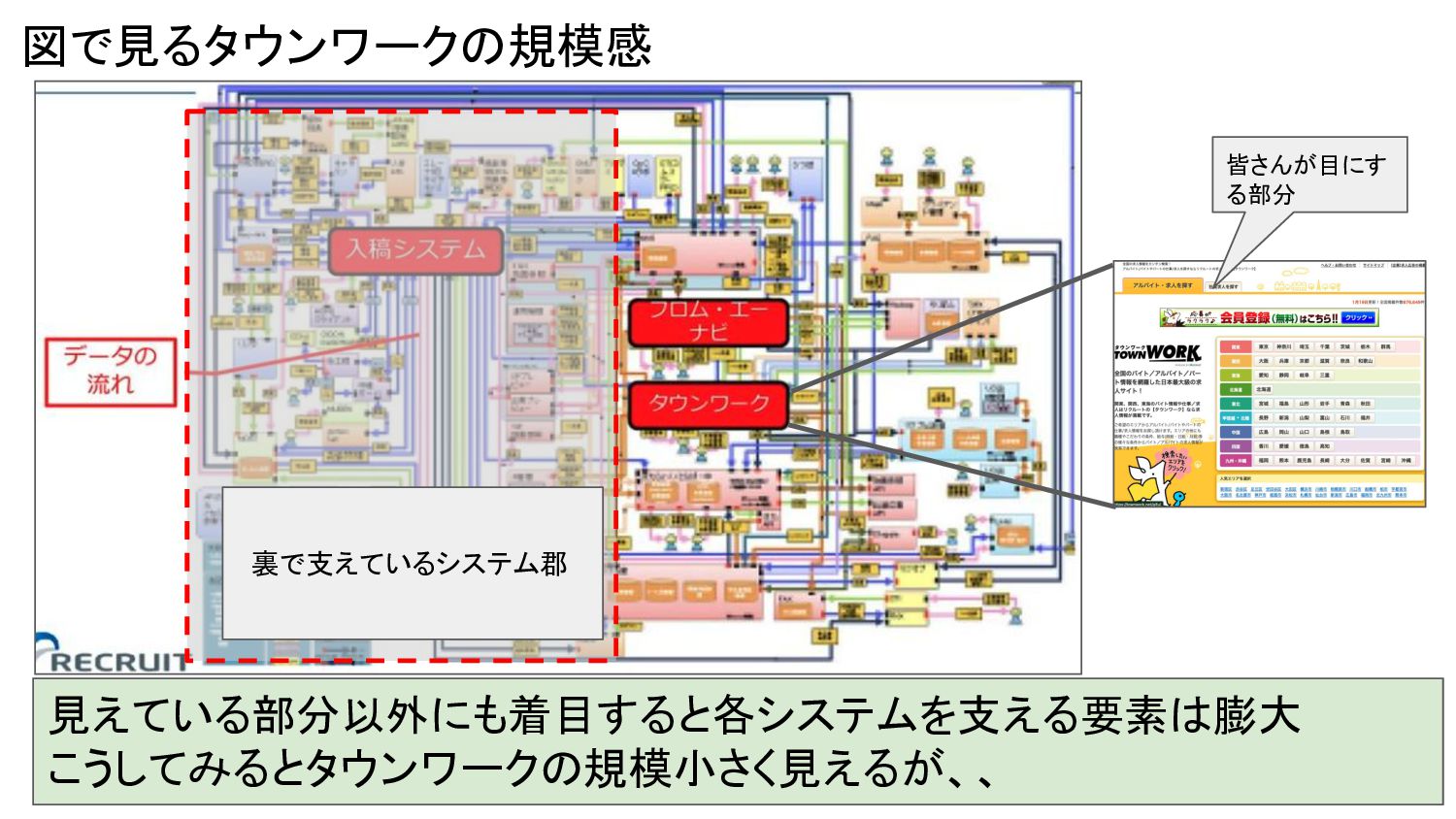
図で見るタウンワークの規模感 見えている部分以外にも着目すると各システムを支える要素は膨大 こうしてみるとタウンワークの規模小さく見えるが、、 皆さんが目にす る部分 裏で支えているシステム郡
数値で見るタウンワークの規模感 ・掲載求人数 数十万求人 ・月間トラフィック数 数億アクセス(秒間約数百アクセス) ・開発者数 Web、アプリ合計約35人 数値で見るとそんなことはない 少しのサービス障害や開発の手戻りなどでもインパクトが大きい
先輩、上司の活動事例 ・肥大化、複雑化コードのリファクタリング https://codezine.jp/article/detail/11570 https://codezine.jp/article/detail/11445 ・プロセス改善 https://speakerdeck.com/poohsunny/devsumi2018 https://www.slideshare.net/i2key/devsumi-152929762#36 ・技術負債除去 https://speakerdeck.com/rtechkouhou/taunwaku90mo-yuan-gao-fals ejie-zai-wozhi-eruregasibatutipahuomansutiyuningu-number-devsum
i-number-devisumid https://youtu.be/qgVG8AVrM7M ・自動テスト強化 https://www.slideshare.net/i2key/devsumi-152929762#56 https://speakerdeck.com/rtechkouhou/kokoshu-nian-jian-falsetaunwa kuiosapurifalseenziniafalsetiyarenzi?slide=32 本日はタウンワークでの開発環境改善事例をもとに我々の仕事の考え方 を紹介していきます
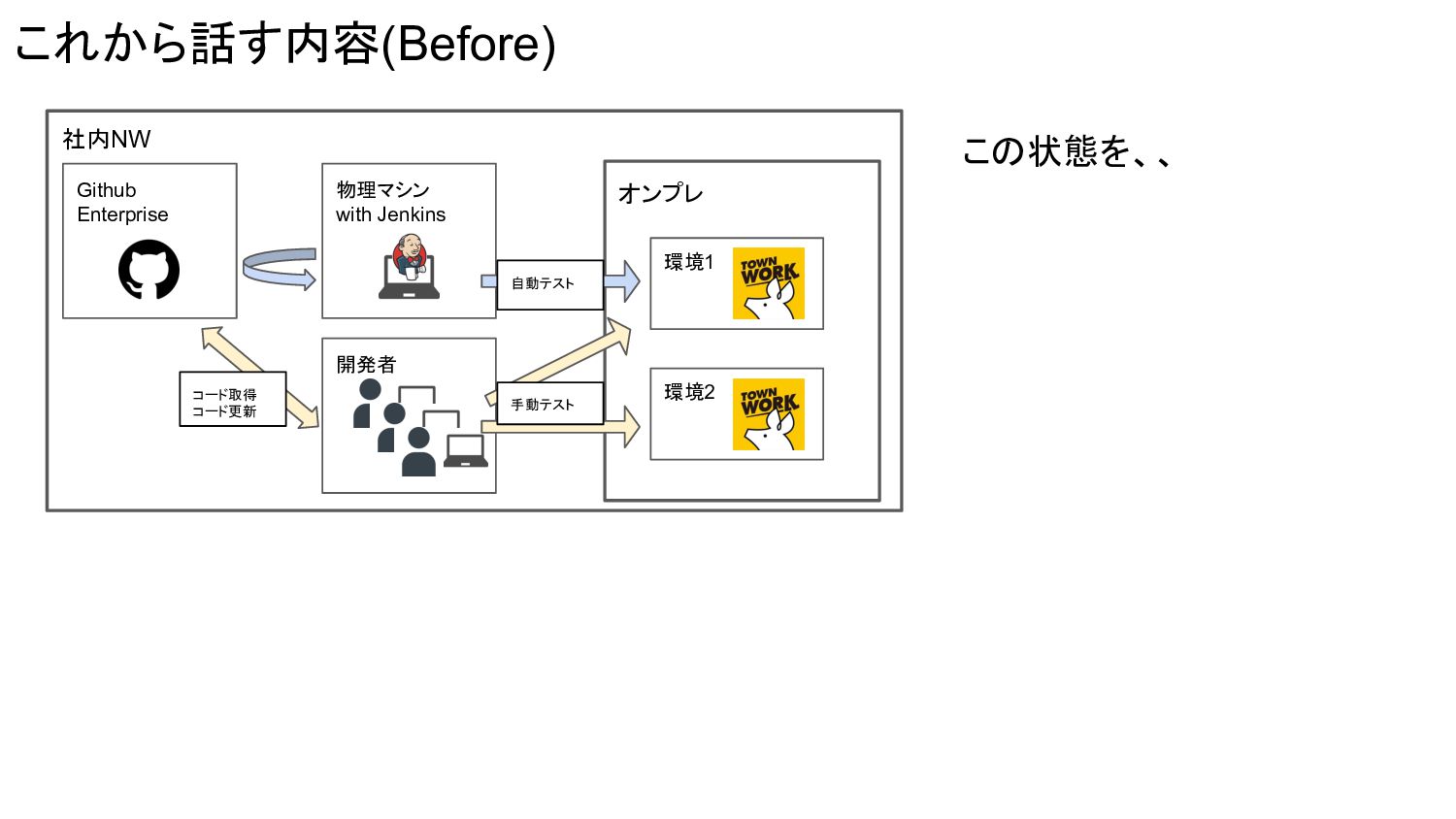
これから話す内容(Before) 社内NW オンプレ 環境1 環境2 開発者 Github Enterprise 物理マシン with
Jenkins 自動テスト 手動テスト コード取得 コード更新 この状態を、、
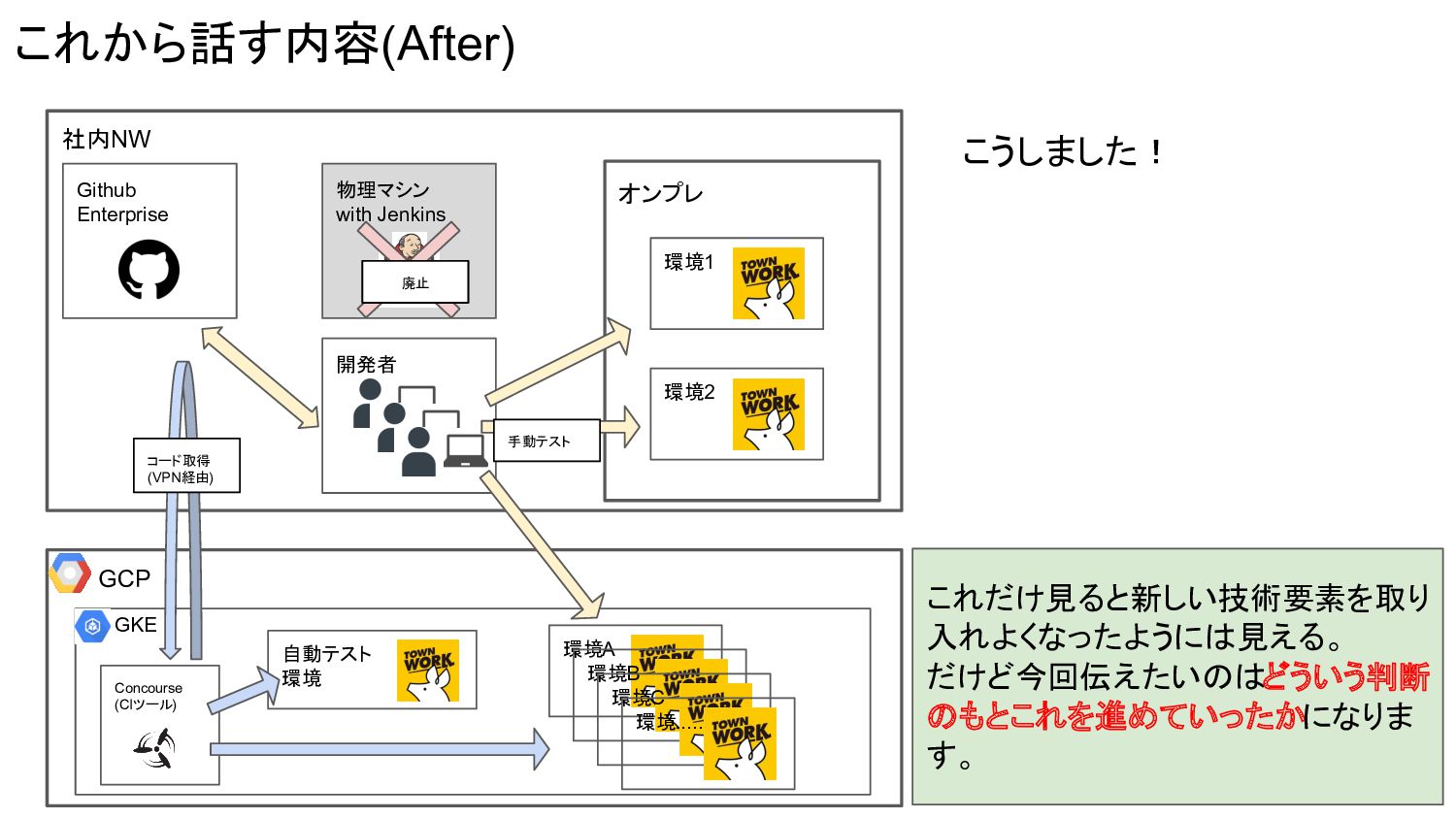
Concourse (CIツール) これから話す内容(After) 社内NW オンプレ 環境1 環境2 開発者 Github Enterprise
物理マシン with Jenkins 手動テスト GCP GKE 自動テスト 環境 環境A 環境B 環境C 環境..... コード取得 (VPN経由) 廃止 これだけ見ると新しい技術要素を取り 入れよくなったようには見える。 だけど今回伝えたいのはどういう判断 のもとこれを進めていったかになりま す。 こうしました!
事例をもとに改善の考え方紹介
話す内容の流れ ステップ1: 問題、課題認識と目標設定 ステップ2: 目標に向けた実現性検証 ステップ3: 構築、運用開始 ステップ4: 導入後の結果確認
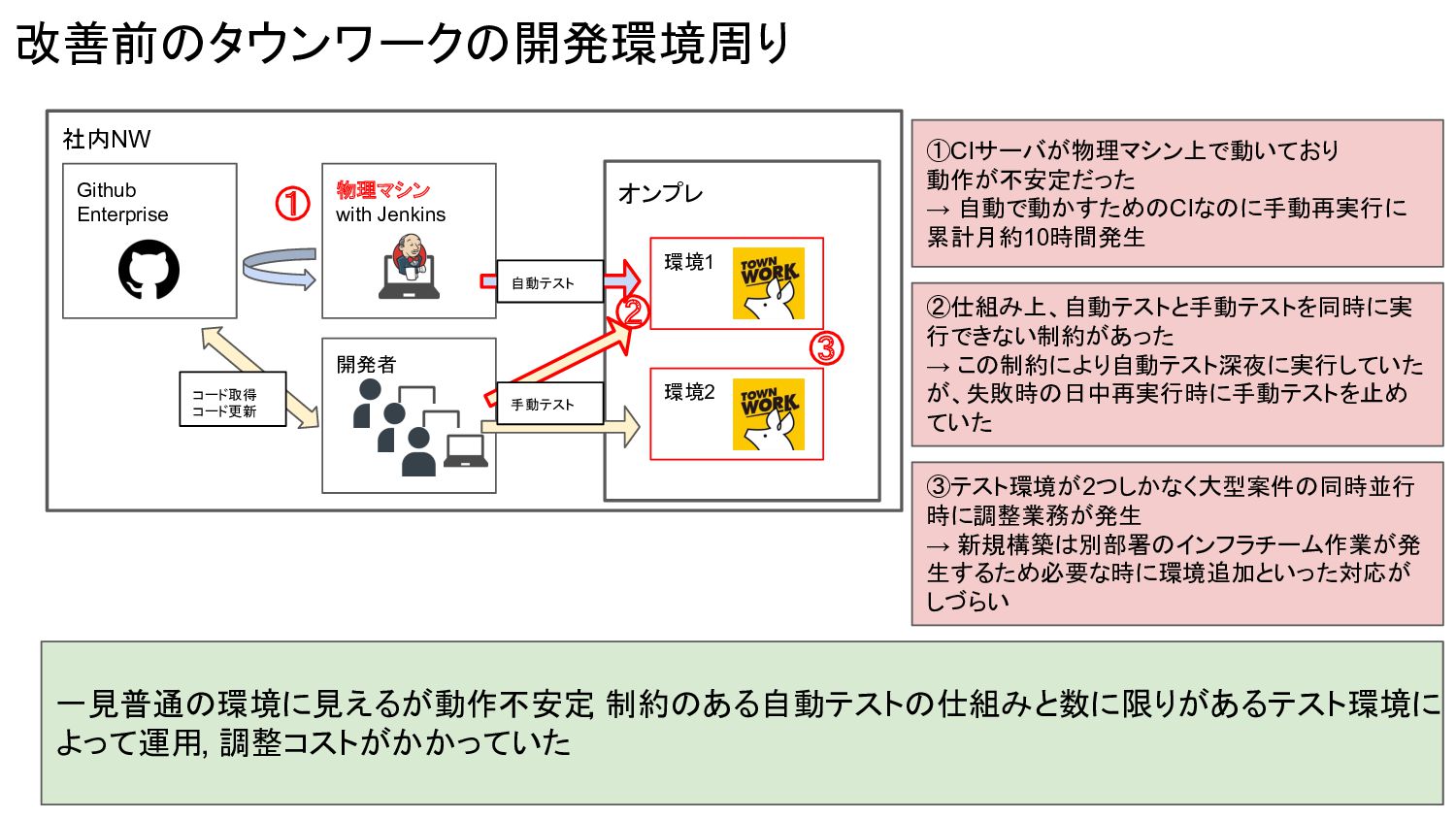
改善前のタウンワークの開発環境周り 社内NW オンプレ 環境1 環境2 開発者 Github Enterprise 物理マシン with
Jenkins 自動テスト 手動テスト コード取得 コード更新 ①CIサーバが物理マシン上で動いており 動作が不安定だった → 自動で動かすためのCIなのに手動再実行に 累計月約10時間発生 ②仕組み上、自動テストと手動テストを同時に実 行できない制約があった → この制約により自動テスト深夜に実行していた が、失敗時の日中再実行時に手動テストを止め ていた ③テスト環境が2つしかなく大型案件の同時並行 時に調整業務が発生 → 新規構築は別部署のインフラチーム作業が発 生するため必要な時に環境追加といった対応が しづらい ① ② ③ 一見普通の環境に見えるが動作不安定 , 制約のある自動テストの仕組みと数に限りがあるテスト環境に よって運用, 調整コストがかかっていた
物理マシン問題と自動テスト制約のみを解決する場合 社内NW オンプレ 環境1 環境2 開発者 Github Enterprise 物理マシン with
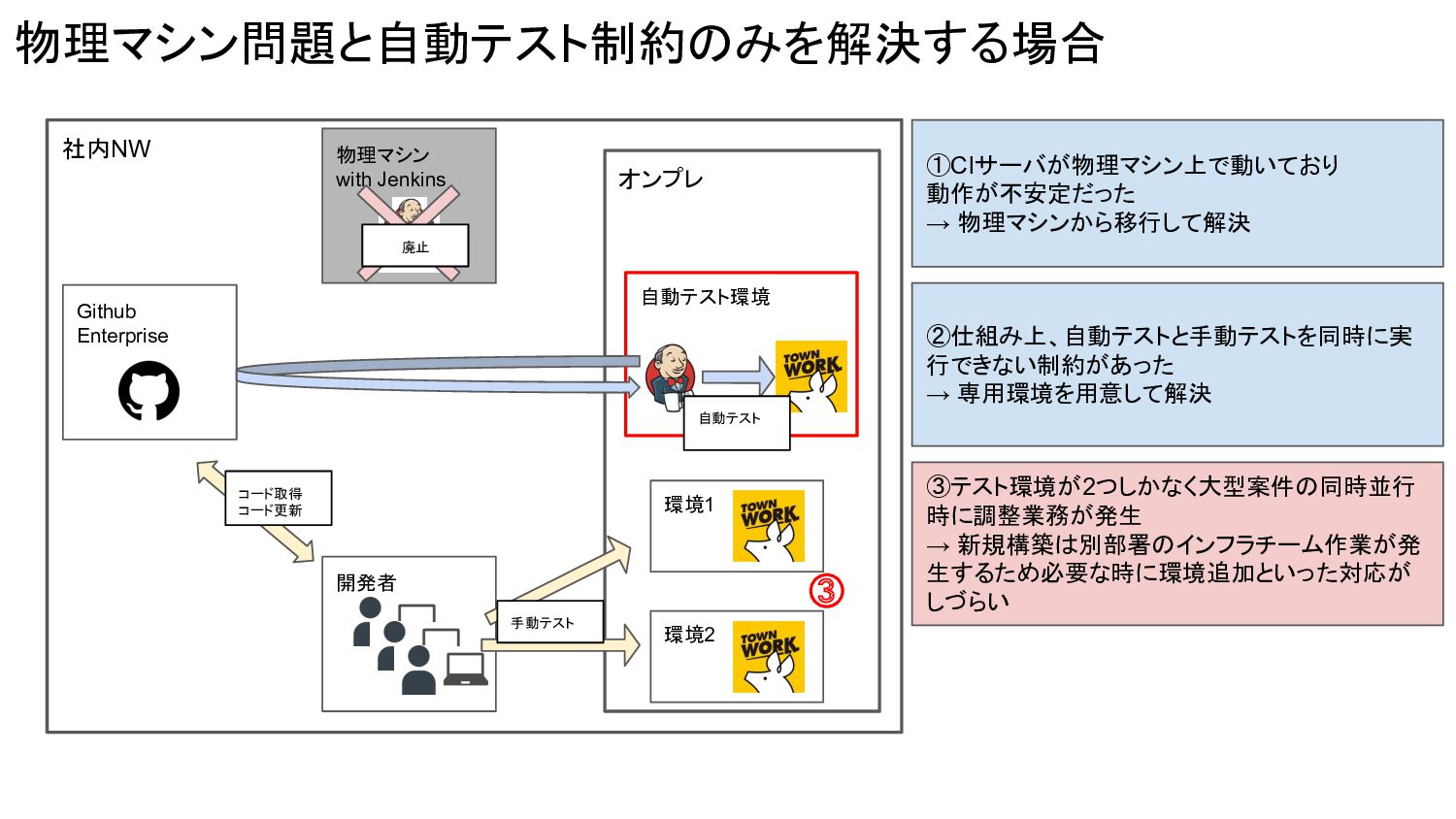
Jenkins 手動テスト コード取得 コード更新 ①CIサーバが物理マシン上で動いており 動作が不安定だった → 物理マシンから移行して解決 ②仕組み上、自動テストと手動テストを同時に実 行できない制約があった → 専用環境を用意して解決 ③テスト環境が2つしかなく大型案件の同時並行 時に調整業務が発生 → 新規構築は別部署のインフラチーム作業が発 生するため必要な時に環境追加といった対応が しづらい ③ 自動テスト環境 自動テスト 廃止
物理マシン問題と自動テスト制約のみを解決する場合 社内NW オンプレ 環境1 環境2 開発者 Github Enterprise 物理マシン with
Jenkins 手動テスト コード取得 コード更新 ①CIサーバが物理マシン上で動いており 動作が不安定だった → 物理マシンから移行して解決 ②仕組み上、自動テストと手動テストを同時に実 行できない制約があった → 専用環境を用意して解決 ③テスト環境が2つしかなく大型案件の同時並行 時に調整業務が発生 → 新規構築は別部署のインフラチーム作業が発 生するため必要な時に環境追加といった対応が しづらい ③ 自動テスト環境 デプロイ 自動テスト 廃止 1. 普通に考えたらそもそもこの構成にしてるはずでは? なぜ物理マシンでJenkins動かすという選択肢を取ったのか?
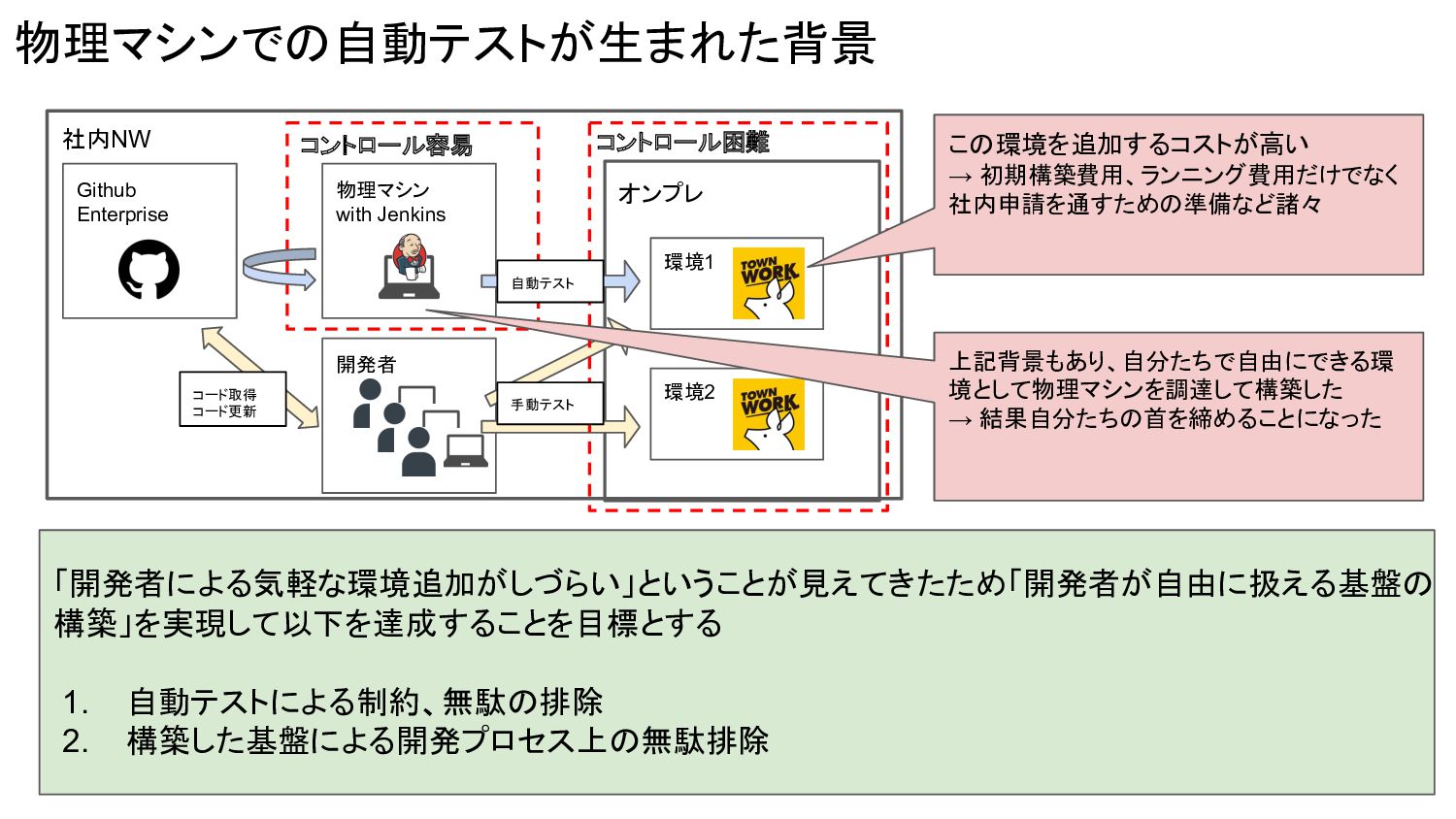
物理マシンでの自動テストが生まれた背景 社内NW オンプレ 環境1 環境2 開発者 Github Enterprise 物理マシン with
Jenkins コード取得 コード更新 「開発者による気軽な環境追加がしづらい」ということが見えてきたため「開発者が自由に扱える基盤の 構築」を実現して以下を達成することを目標とする 1. 自動テストによる制約、無駄の排除 2. 構築した基盤による開発プロセス上の無駄排除 コントロール容易 上記背景もあり、自分たちで自由にできる環 境として物理マシンを調達して構築した → 結果自分たちの首を締めることになった この環境を追加するコストが高い → 初期構築費用、ランニング費用だけでなく 社内申請を通すための準備など諸々 コントロール困難 自動テスト 手動テスト
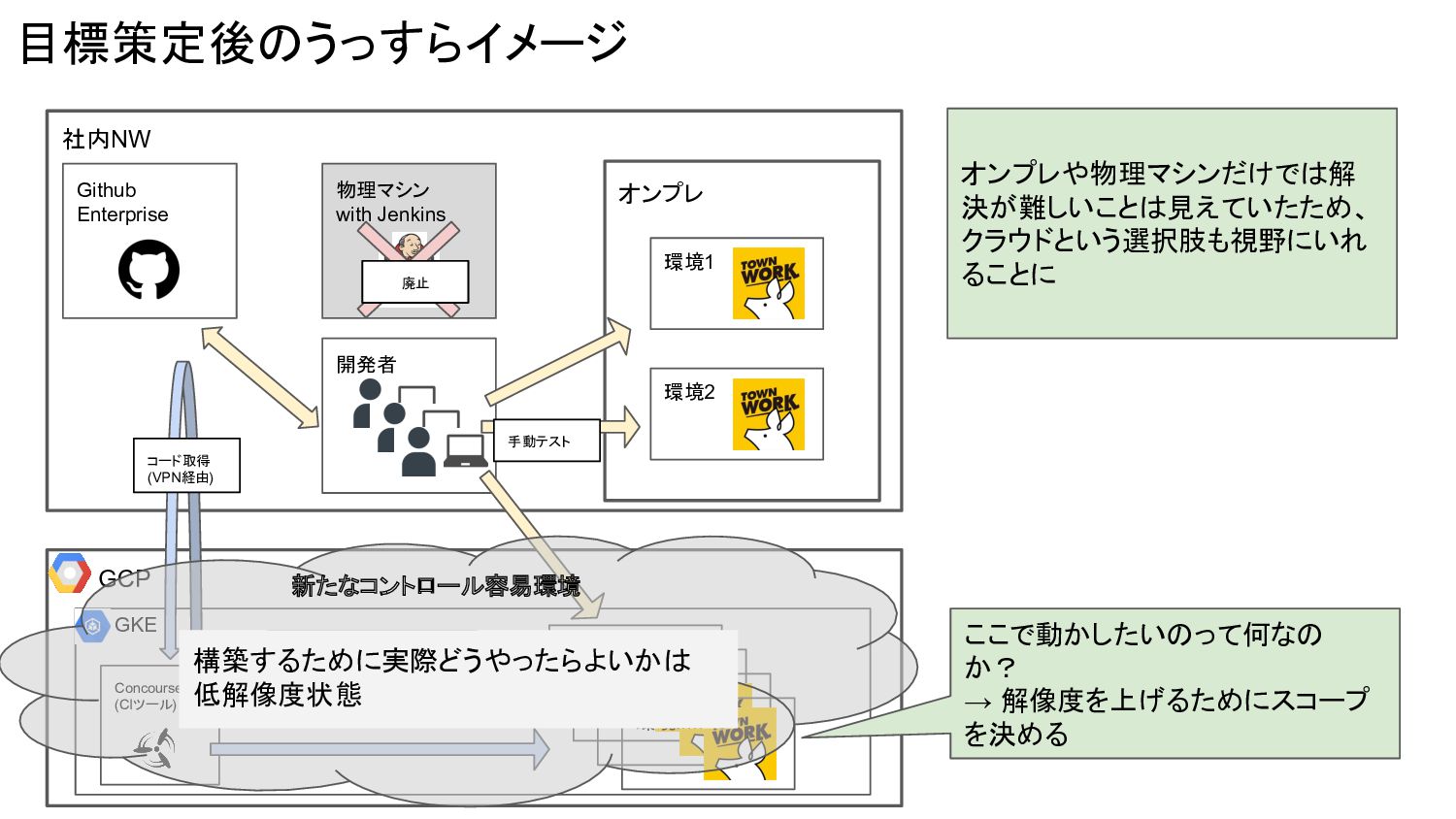
Concourse (CIツール) 目標策定後のうっすらイメージ 社内NW オンプレ 環境1 環境2 開発者 Github Enterprise
物理マシン with Jenkins 手動テスト GCP GKE 自動テスト 環境 環境A 環境B 環境C 環境..... コード取得 (VPN経由) 廃止 構築するために実際どうやったらよいかは 低解像度状態 ここで動かしたいのって何なの か? → 解像度を上げるためにスコープ を決める オンプレや物理マシンだけでは解 決が難しいことは見えていたため、 クラウドという選択肢も視野にいれ ることに 新たなコントロール容易環境
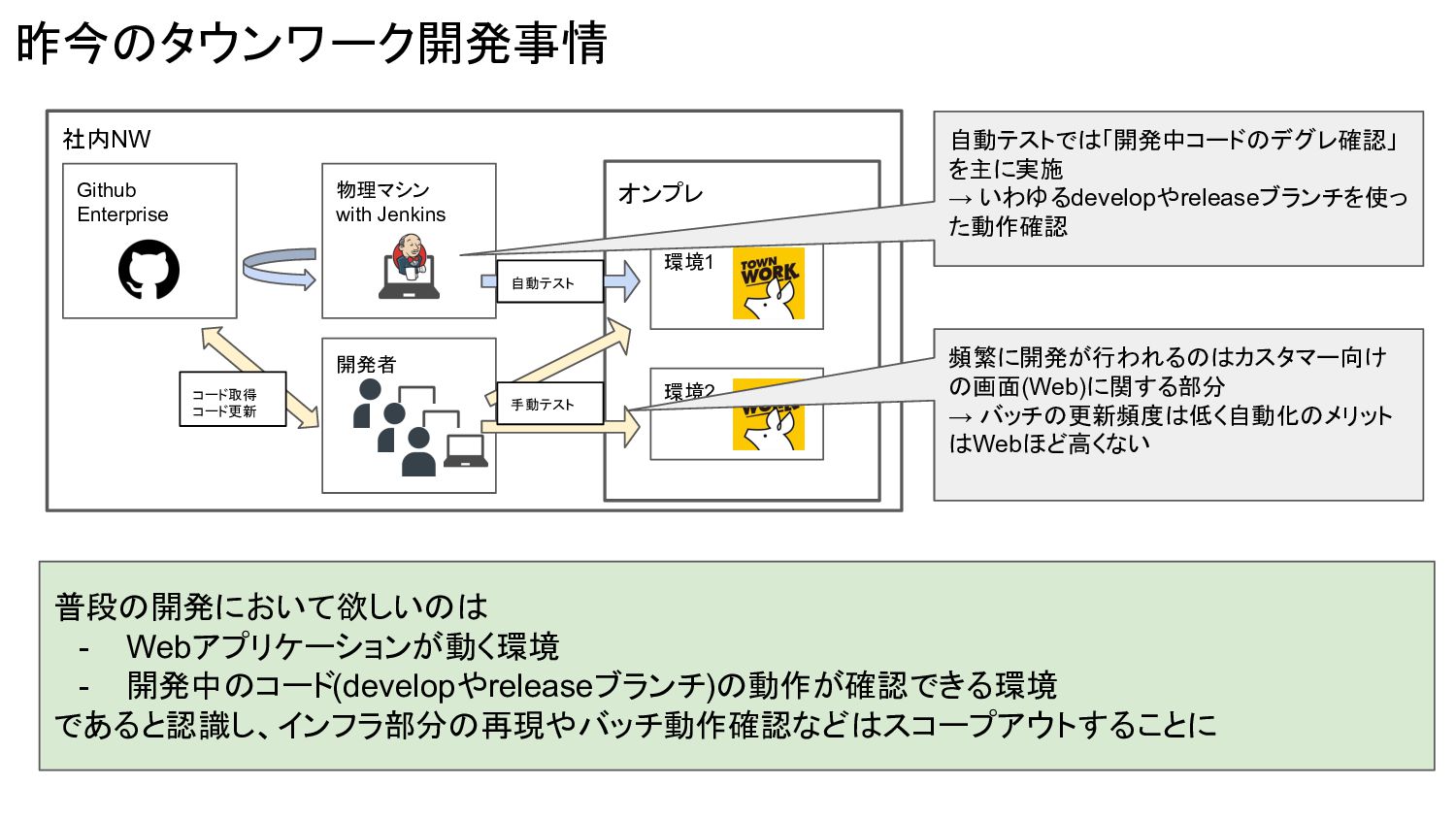
昨今のタウンワーク開発事情 社内NW オンプレ 環境1 環境2 開発者 Github Enterprise 物理マシン with
Jenkins 自動テスト 手動テスト コード取得 コード更新 頻繁に開発が行われるのはカスタマー向け の画面(Web)に関する部分 → バッチの更新頻度は低く自動化のメリット はWebほど高くない 自動テストでは「開発中コードのデグレ確認」 を主に実施 → いわゆるdevelopやreleaseブランチを使っ た動作確認 普段の開発において欲しいのは - Webアプリケーションが動く環境 - 開発中のコード(developやreleaseブランチ)の動作が確認できる環境 であると認識し、インフラ部分の再現やバッチ動作確認などはスコープアウトすることに
ステップ1: 問題、課題認識と目標設定 「環境追加しづらい」起因により各種問題が出ているという認識のもと 「開発者が自由に扱える基盤の構築」を実施し、 「自動テストによる制約、無駄の排除」「構築した基盤による開発プロセス上の無駄排除」を実現する ステップ2: 目標に向けた実現性検証 ステップ3: 構築、運用開始 ステップ4:
導入後の結果確認 ここまでのまとめ
目標に向けた実現性検証 検証1: オンプレ以外での動作、実現性検証 目的: 今の制約(オンプレにしか環境は構築できない )が突破できるのかを試す 検証2: 環境の複製検証 目的: 用途ごとに環境を簡単に複製することができるかを試す
検証3: クラウド上での動作検証 目的: 1,2での検証内容がクラウドで適用できるかを試す ステップ1によりやりたいことは定まってきたので実現に必要な検証を洗い出す
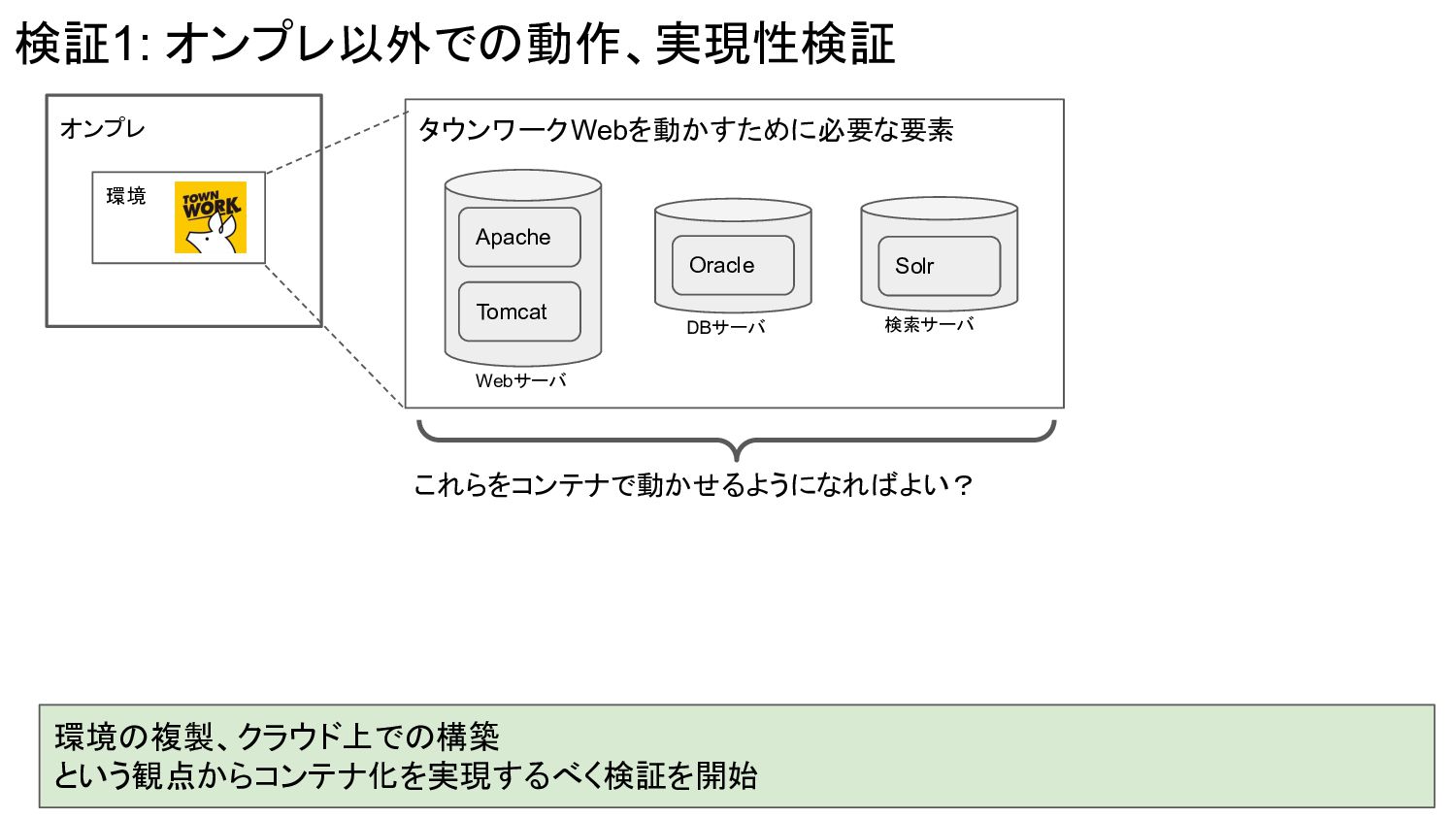
オンプレ 環境 検証1: オンプレ以外での動作、実現性検証 環境の複製、クラウド上での構築 という観点からコンテナ化を実現するべく検証を開始 これらをコンテナで動かせるようになればよい? Apache Tomcat Webサーバ
Oracle DBサーバ Solr 検索サーバ タウンワークWebを動かすために必要な要素
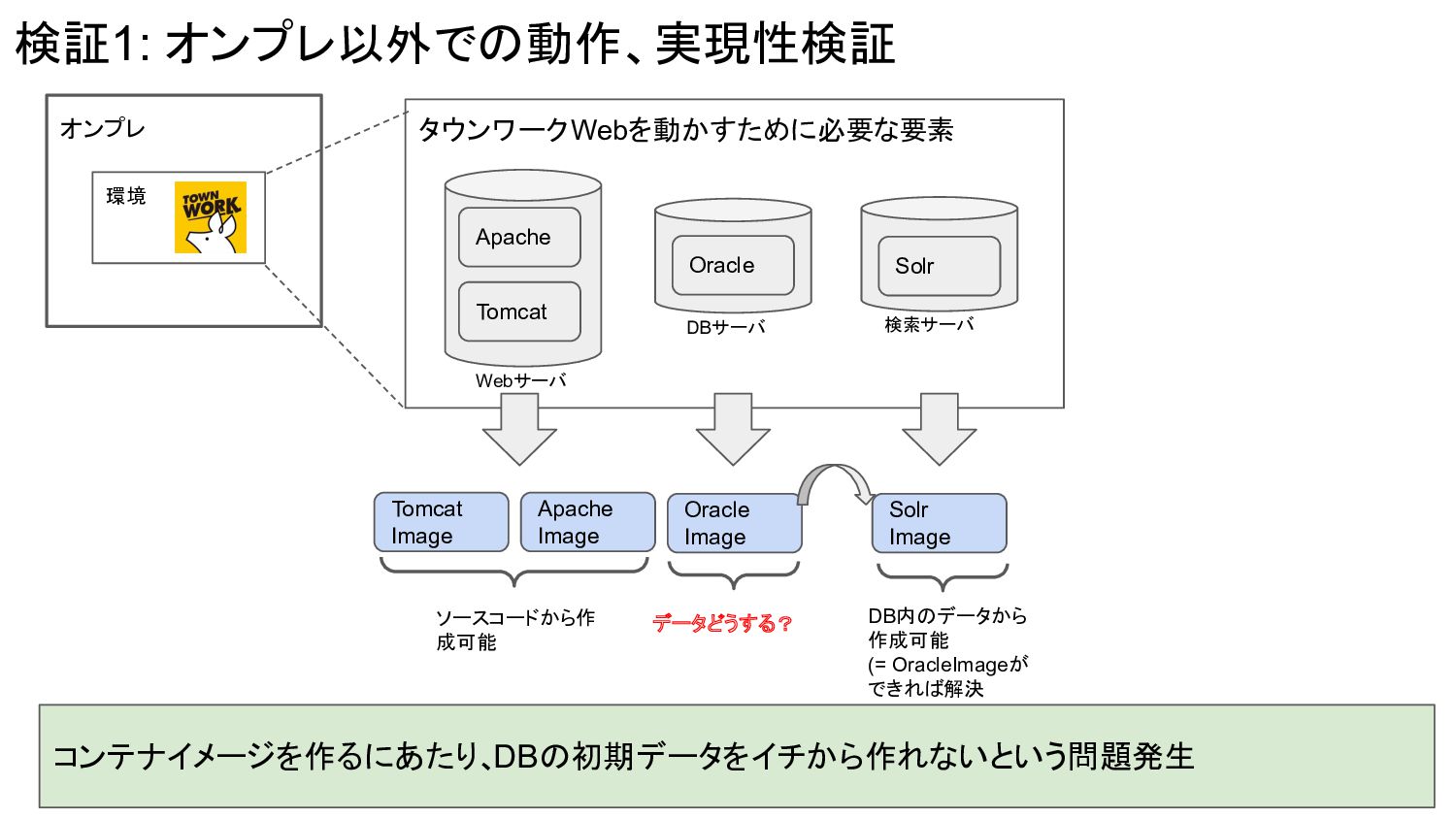
オンプレ 環境 検証1: オンプレ以外での動作、実現性検証 Apache Tomcat Webサーバ Oracle DBサーバ Solr
検索サーバ タウンワークWebを動かすために必要な要素 Tomcat Image Apache Image Oracle Image Solr Image ソースコードから作 成可能 データどうする? DB内のデータから 作成可能 (= OracleImageが できれば解決 コンテナイメージを作るにあたり、 DBの初期データをイチから作れないという問題発生
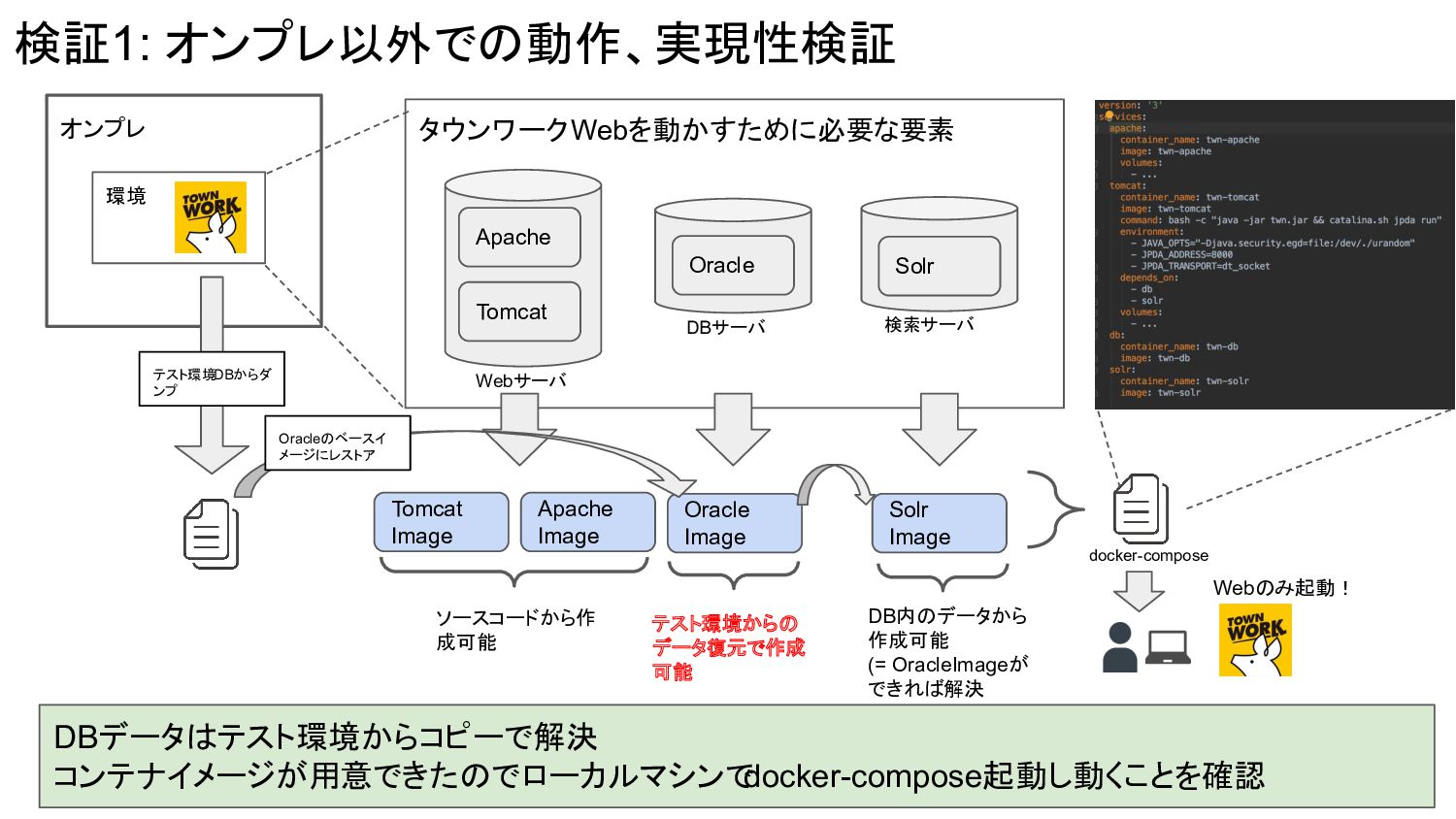
オンプレ 環境 Apache Tomcat Webサーバ Oracle DBサーバ Solr 検索サーバ 検証1:
オンプレ以外での動作、実現性検証 タウンワークWebを動かすために必要な要素 Tomcat Image Apache Image Oracle Image Solr Image ソースコードから作 成可能 テスト環境からの データ復元で作成 可能 DB内のデータから 作成可能 (= OracleImageが できれば解決 テスト環境DBからダ ンプ Oracleのベースイ メージにレストア Webのみ起動! docker-compose DBデータはテスト環境からコピーで解決 コンテナイメージが用意できたのでローカルマシンで docker-compose起動し動くことを確認
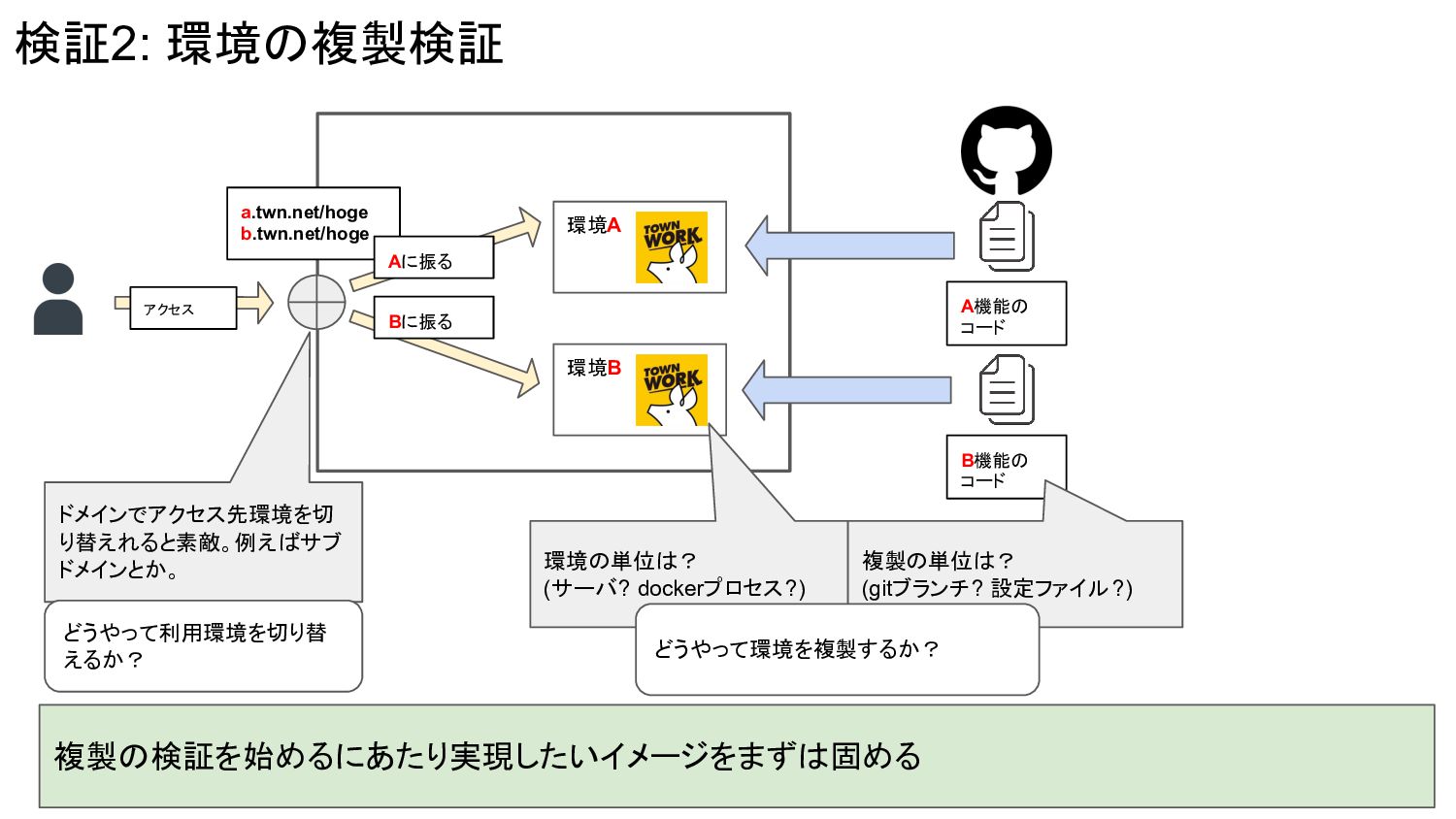
検証2: 環境の複製検証 環境A 環境B アクセス a.twn.net/hoge b.twn.net/hoge Aに振る Bに振る B機能の
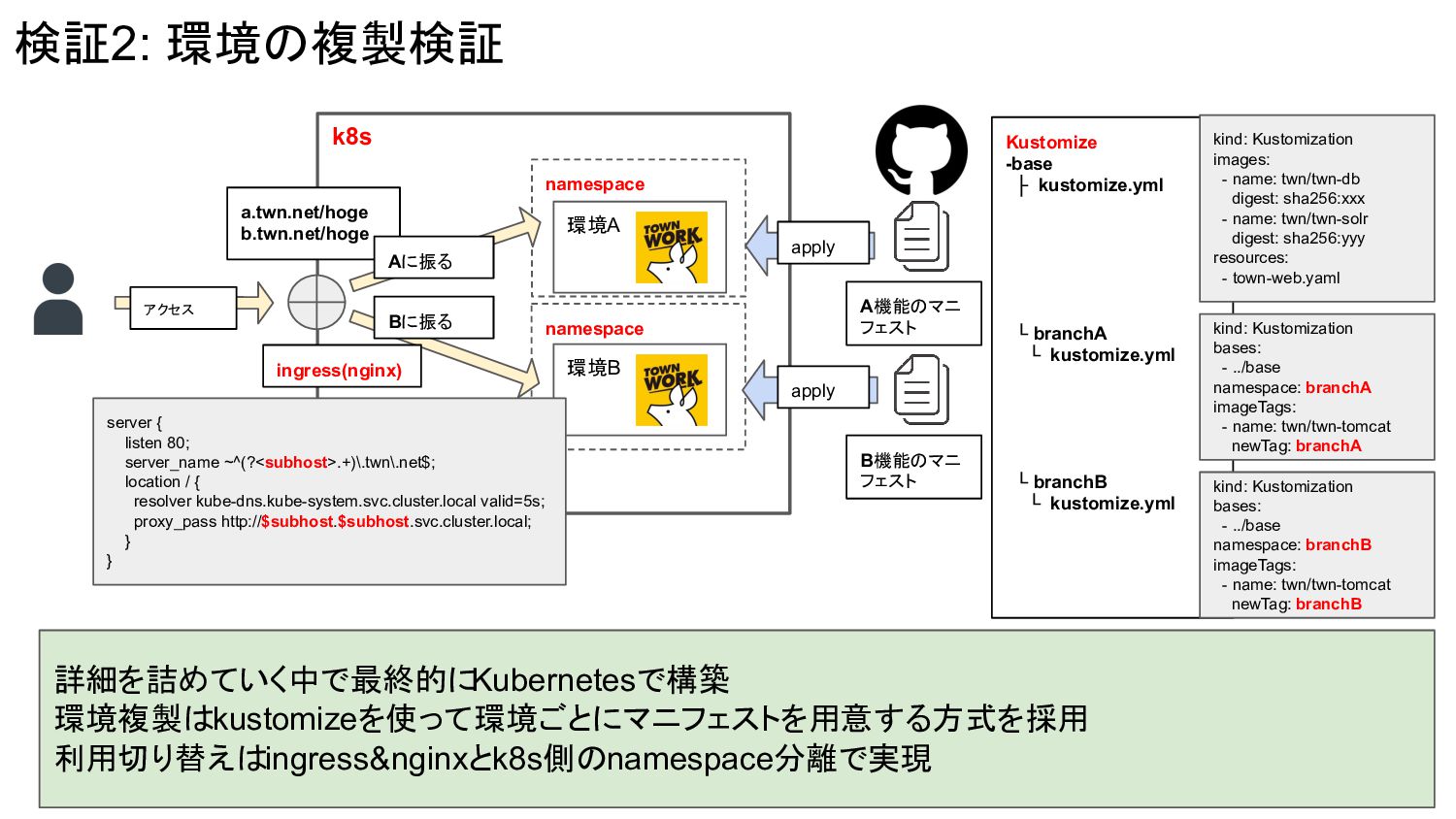
コード A機能の コード 複製の検証を始めるにあたり実現したいイメージをまずは固める 環境の単位は? (サーバ? dockerプロセス?) 複製の単位は? (gitブランチ? 設定ファイル?) ドメインでアクセス先環境を切 り替えれると素敵。例えばサブ ドメインとか。 どうやって利用環境を切り替 えるか? どうやって環境を複製するか?
namespace namespace 検証2: 環境の複製検証 環境A 環境B アクセス Bに振る B機能のマニ フェスト
A機能のマニ フェスト 詳細を詰めていく中で最終的に Kubernetesで構築 環境複製はkustomizeを使って環境ごとにマニフェストを用意する方式を採用 利用切り替えはingress&nginxとk8s側のnamespace分離で実現 k8s ingress(nginx) a.twn.net/hoge b.twn.net/hoge Aに振る Kustomize -base ├ kustomize.yml └ branchA └ kustomize.yml └ branchB └ kustomize.yml apply apply kind: Kustomization images: - name: twn/twn-db digest: sha256:xxx - name: twn/twn-solr digest: sha256:yyy resources: - town-web.yaml kind: Kustomization bases: - ../base namespace: branchA imageTags: - name: twn/twn-tomcat newTag: branchA kind: Kustomization bases: - ../base namespace: branchB imageTags: - name: twn/twn-tomcat newTag: branchB server { listen 80; server_name ~^(?<subhost>.+)\.twn\.net$; location / { resolver kube-dns.kube-system.svc.cluster.local valid=5s; proxy_pass http://$subhost.$subhost.svc.cluster.local; } }
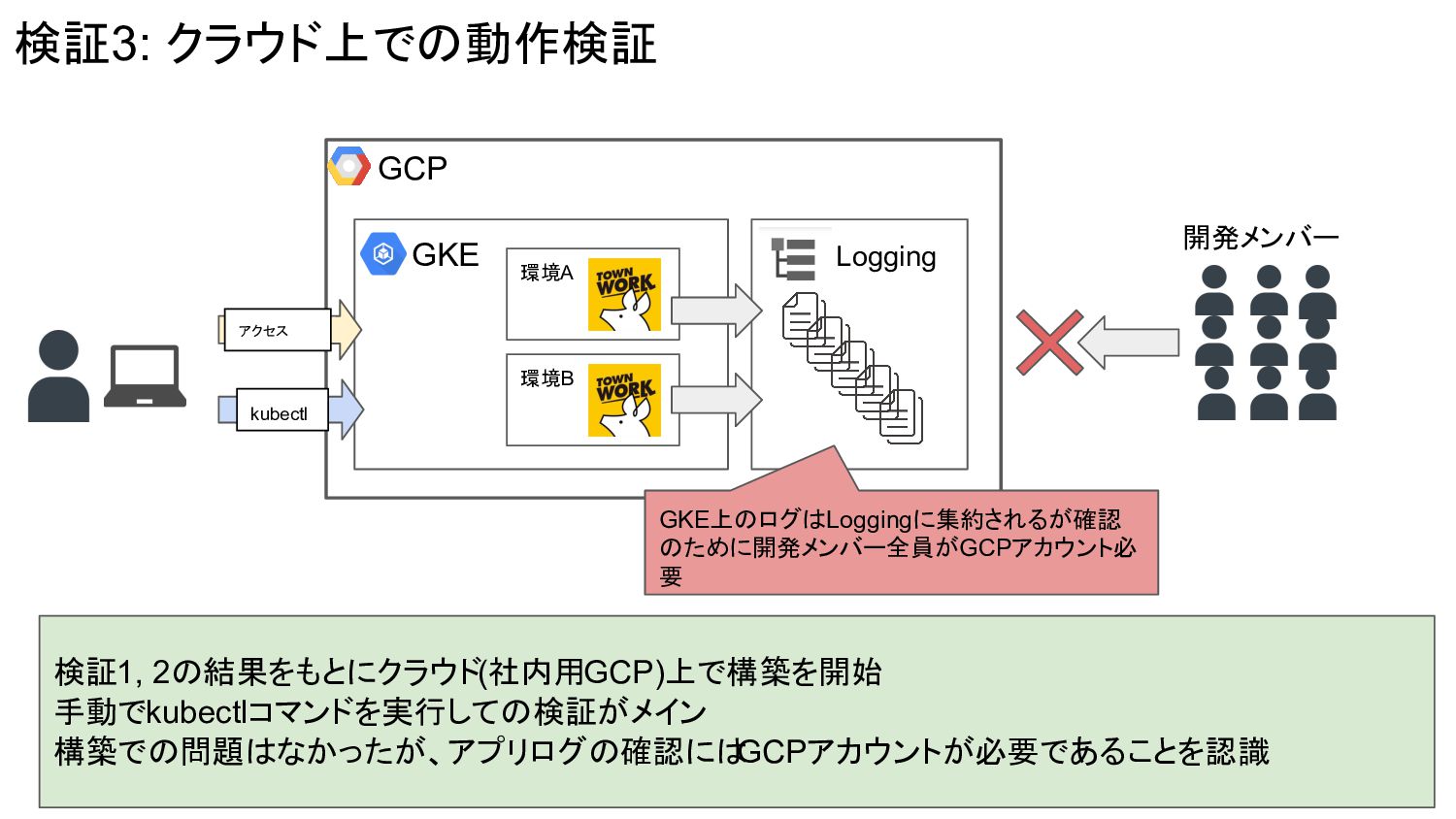
GCP GKE 環境A 検証3: クラウド上での動作検証 検証1, 2の結果をもとにクラウド(社内用GCP)上で構築を開始 手動でkubectlコマンドを実行しての検証がメイン 構築での問題はなかったが、アプリログの確認には GCPアカウントが必要であることを認識
環境B kubectl アクセス Logging GKE上のログはLoggingに集約されるが確認 のために開発メンバー全員がGCPアカウント必 要 開発メンバー
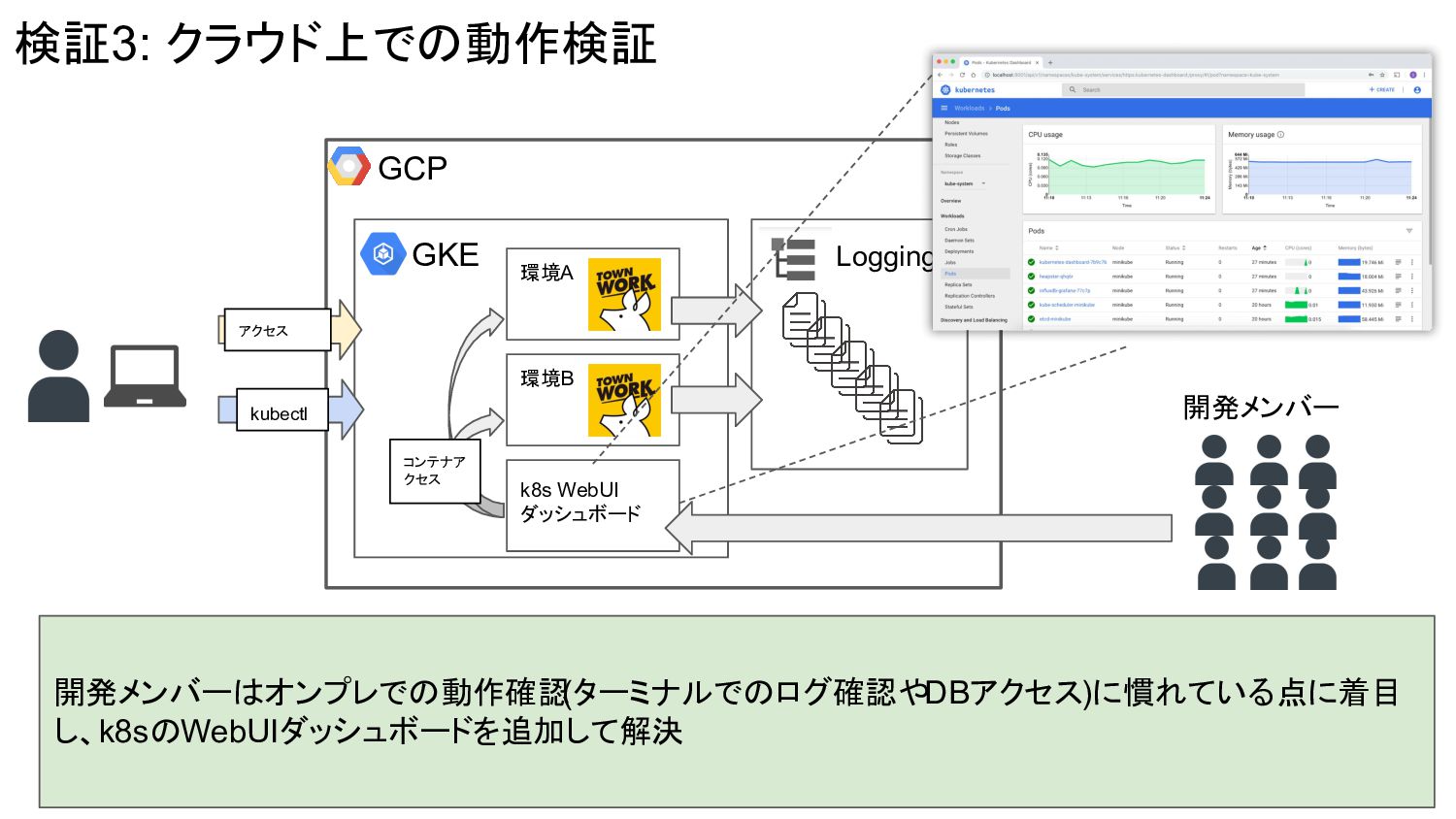
GCP GKE 環境A 検証3: クラウド上での動作検証 開発メンバーはオンプレでの動作確認 (ターミナルでのログ確認やDBアクセス)に慣れている点に着目 し、k8sのWebUIダッシュボードを追加して解決 環境B kubectl
アクセス Logging 開発メンバー k8s WebUI ダッシュボード コンテナア クセス
ステップ2: 目標に向けた実現性検証 コンテナ化による動作検証、 k8sによる複数環境検証、クラウド化の検証によって実現性を確認 ステップ3: 構築、運用開始 ステップ4: 導入後の結果確認 ここまでのまとめ ステップ1:
問題、課題認識と目標設定 「環境追加しづらい」起因により各種問題が出ているという認識のもと 「開発者が自由に扱える基盤の構築」を実施し、 「自動テストによる制約、無駄の排除」「構築した基盤による開発プロセス上の無駄排除」を実現する
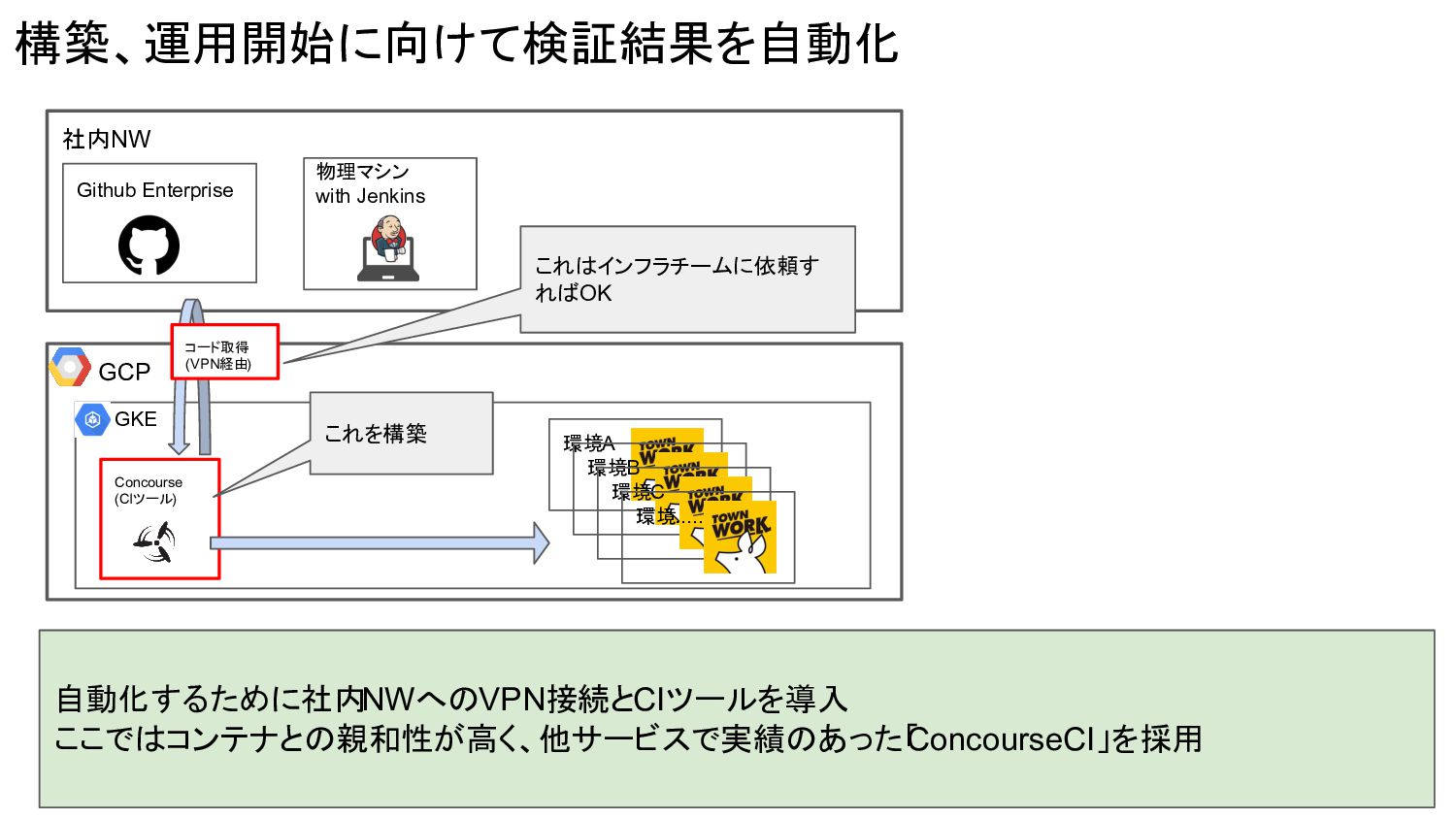
Concourse (CIツール) 構築、運用開始に向けて検証結果を自動化 社内NW Github Enterprise GCP GKE 環境A 環境B
環境C 環境..... コード取得 (VPN経由) 自動化するために社内NWへのVPN接続とCIツールを導入 ここではコンテナとの親和性が高く、他サービスで実績のあった「 ConcourseCI」を採用 物理マシン with Jenkins これはインフラチームに依頼す ればOK これを構築
Concourse (CIツール) 構築、運用開始に向けて検証結果を自動化 社内NW Github Enterprise GCP GKE 環境A 環境B
環境C 環境..... コード取得 (VPN経由) 自動化するために社内NWへのVPN接続とCIツールを導入 ここではコンテナとの親和性が高く、他サービスで実績のあった「 ConcourseCI」を採用 物理マシン with Jenkins これはインフラチームに依頼す ればOK これを構築 1. ここの自動化が一番重要と考えてます 皆さんも経験ありませんか、、? - 過去誰かが作った自動化が動かなくなり業務が止まった - プロダクトコードよりもCIのコードのほうがいじるのが怖い環境 - なぜやっているのかよくわからない自動化の呪い - いきなり運用を切り替えて混乱する現場 こういったことを避けるために自動化ステップにおいては以下を実施 1.現場開発メンバーからの早期FBをもらって充分状態を目指す(やりすぎ防止) 2.最悪捨ててもよい状態及び思考をもって取り組む(可逆的に進める) 3.誰かがすべてを把握する状態を避ける(属人化の軽減) 4.目的, 背景を文書化して残す(運用陳腐化防止)
Concourse (CIツール) 構築、運用開始に向けて検証結果を自動化 社内NW Github Enterprise GCP GKE 環境A 環境B
環境C 環境..... コード取得 (VPN経由) 4つを意識して自動化を作り込むだけでなく運用も見据えた動きを進める 物理マシン with Jenkins GCP上での構築が完了して運 用できるまで残す → 可逆的に進める 各自動化タスクをアーキチーム内で分担 新人育成用タスクとしてやってもらう → 属人化の軽減 開発メンバー ある程度できたら軽微な画面 開発の動作確認に使って FBも らう → やりすぎ防止 今回の取り組みを文書化して残 す → 運用陳腐化防止
構築完了、運用開始 既存との変更点をドキュメント化してメンバーに説明 しばらくは新運用を見守りながら進める 自動テスト運用の変更点まとめ
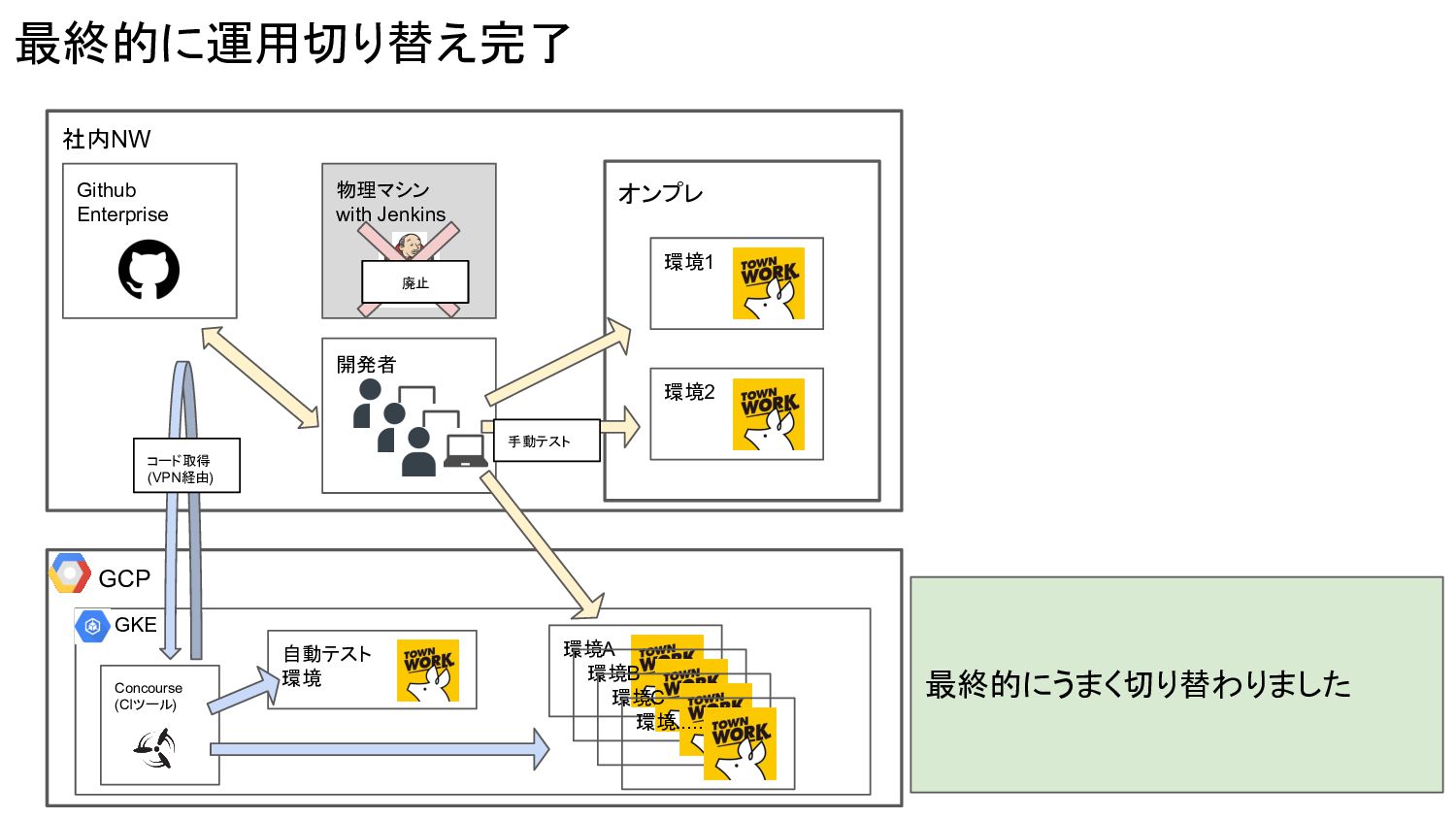
Concourse (CIツール) 最終的に運用切り替え完了 社内NW オンプレ 環境1 環境2 開発者 Github Enterprise
物理マシン with Jenkins 手動テスト GCP GKE 自動テスト 環境 環境A 環境B 環境C 環境..... コード取得 (VPN経由) 最終的にうまく切り替わりました 廃止
ステップ2: 目標に向けた実現性検証 コンテナ化による動作検証、 k8sによる複数環境検証、クラウド化の検証によって実現性を確認 ステップ3: 構築、運用開始 検証と異なりここから先の構築は今後の運用に大きく関わってくる 「やりすぎ防止」「可逆的に進める」「属人化の軽減」「運用陳腐化防止」の 4つを気にして進めて 最終的に運用定着まで実施
ステップ4: 導入後の結果確認 ここまでのまとめ ステップ1: 問題、課題認識と目標設定 「環境追加しづらい」起因により各種問題が出ているという認識のもと 「開発者が自由に扱える基盤の構築」を実施し、 「自動テストによる制約、無駄の排除」「構築した基盤による開発プロセス上の無駄排除」を実現する
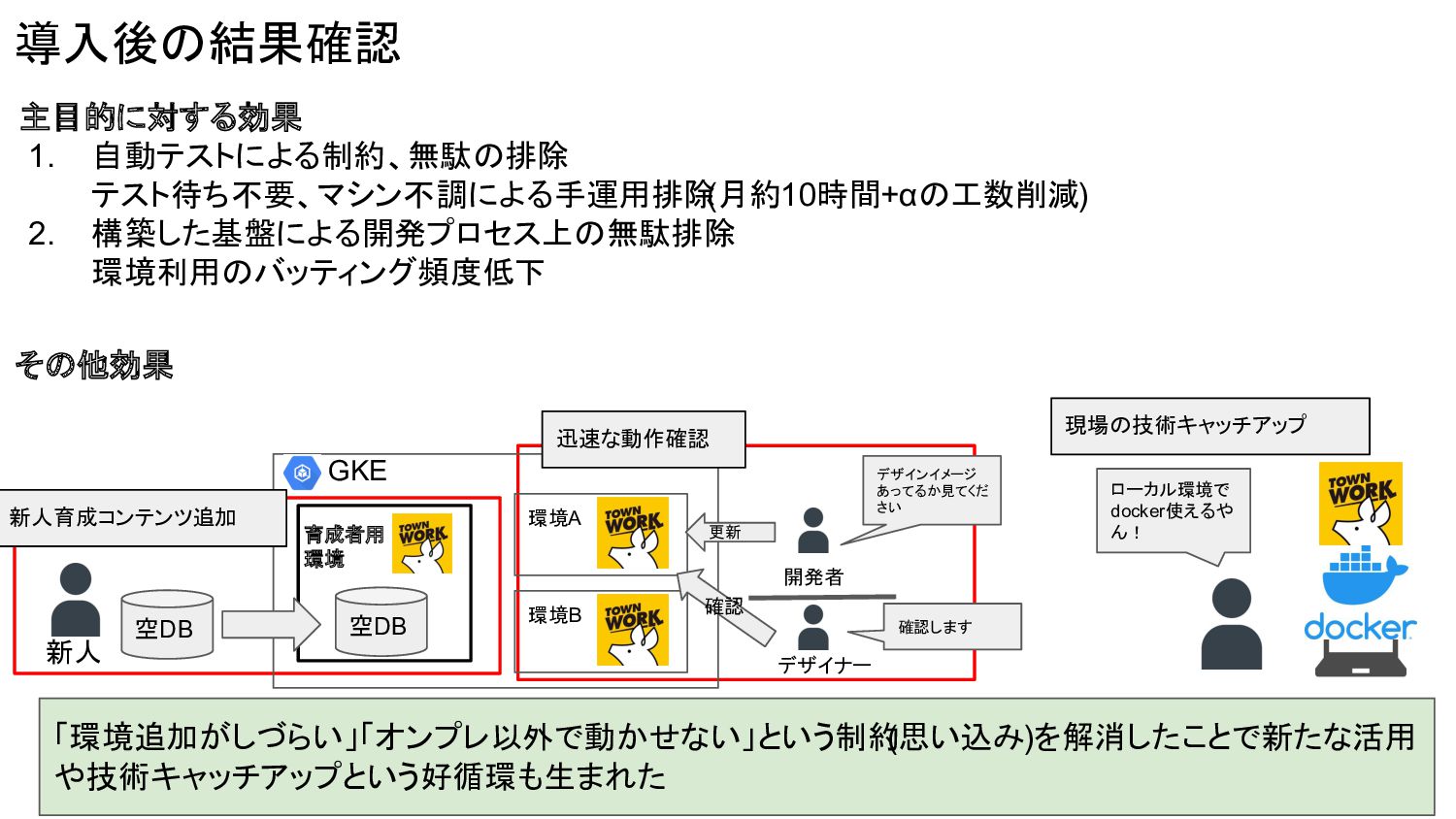
導入後の結果確認 主目的に対する効果 1. 自動テストによる制約、無駄の排除 テスト待ち不要、マシン不調による手運用排除 (月約10時間+αの工数削減) 2. 構築した基盤による開発プロセス上の無駄排除 環境利用のバッティング頻度低下 GKE
環境A 育成者用 環境 空DB 新人 空DB 新人育成コンテンツ追加 ローカル環境で docker使えるや ん! 「環境追加がしづらい」「オンプレ以外で動かせない」という制約 (思い込み)を解消したことで新たな活用 や技術キャッチアップという好循環も生まれた その他効果 環境B 迅速な動作確認 デザイナー 開発者 更新 デザインイメージ あってるか見てくだ さい 確認します 現場の技術キャッチアップ 確認
ステップ2: 目標に向けた実現性検証 コンテナ化による動作検証、 k8sによる複数環境検証、クラウド化の検証によって実現性を確認 ステップ3: 構築、運用開始 検証と異なりここから先の構築は今後の運用に大きく関わってくる 「やりすぎ防止」「可逆的に進める」「属人化の軽減」「運用陳腐化防止」の 4つを気にして進めて 最終的に運用定着まで実施
ステップ4: 導入後の結果確認 当初目的も達成しつつ、制約突破による副次的な効果も発生した (※今回は導入後の効果が分かりやすかった ) ここまでのまとめ ステップ1: 問題、課題認識と目標設定 「環境追加しづらい」起因により各種問題が出ているという認識のもと 「開発者が自由に扱える基盤の構築」を実施し、 「自動テストによる制約、無駄の排除」「構築した基盤による開発プロセス上の無駄排除」を実現する
ステップ1: 問題、課題認識と目標設定 「環境追加しづらい」起因により各種問題が出ているという認識のもと 「開発者が自由に扱える環境の構築」「自動テストによる制約、無駄の排除」「構築した仕組みによる改善効果の 発揮 」の3つを目標設定 ステップ2: 目標に向けた実現性検証 コンテナ化による動作検証、 k8sによる複数環境検証、クラウド化の検証によって実現性を確認
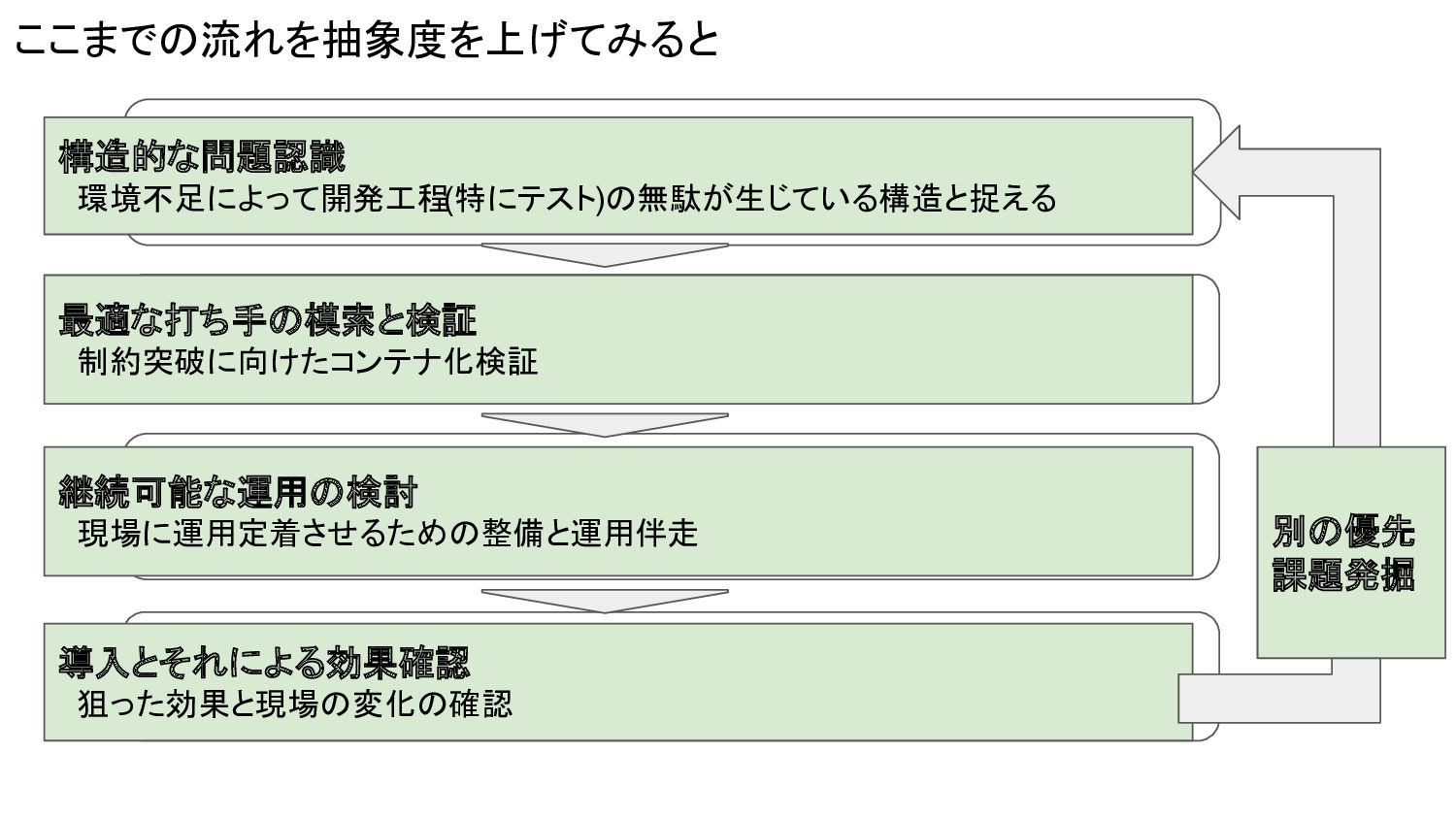
ステップ3: 構築、運用開始 検証と異なりここから先の構築は今後の運用に大きく関わってくる 「やりすぎ防止」「可逆的に進める」「属人化の軽減」「運用陳腐化防止」の 4つを気にして進めて 最終的に運用定着まで実施 ステップ4: 導入後の結果確認 当初目的も達成しつつ、制約突破による副次的な効果も発生した (※今回は導入後の効果が分かりやすかった ) ここまでの流れを抽象度を上げてみると 構造的な問題認識 環境不足によって開発工程(特にテスト)の無駄が生じている構造と捉える 継続可能な運用の検討 現場に運用定着させるための整備と運用伴走 導入とそれによる効果確認 狙った効果と現場の変化の確認 最適な打ち手の模索と検証 制約突破に向けたコンテナ化検証 別の優先 課題発掘
ステップ1: 問題、課題認識と目標設定 「環境追加しづらい」起因により各種問題が出ているという認識のもと 「開発者が自由に扱える環境の構築」「自動テストによる制約、無駄の排除」「構築した仕組みによる改善効果の 発揮 」の3つを目標設定 ステップ2: 目標に向けた実現性検証 コンテナ化による動作検証、 k8sによる複数環境検証、クラウド化の検証によって実現性を確認
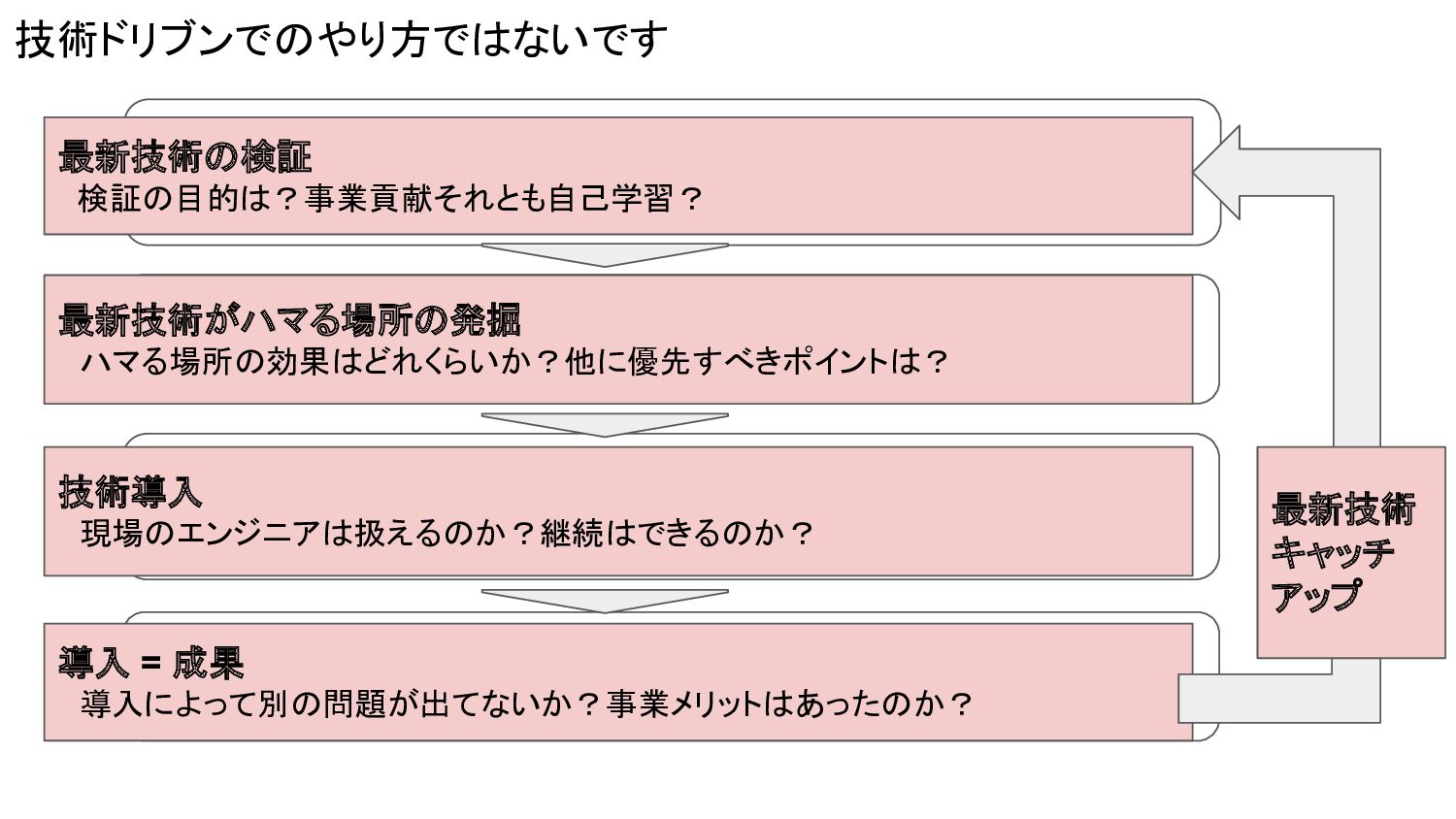
ステップ3: 構築、運用開始 検証と異なりここから先の構築は今後の運用に大きく関わってくる 「やりすぎ防止」「可逆的に進める」「属人化の軽減」「運用陳腐化防止」の 4つを気にして進めて 最終的に運用定着まで実施 ステップ4: 導入後の結果確認 当初目的も達成しつつ、制約突破による副次的な効果も発生した (※今回は導入後の効果が分かりやすかった ) 技術ドリブンでのやり方ではないです 最新技術の検証 検証の目的は?事業貢献それとも自己学習? 技術導入 現場のエンジニアは扱えるのか?継続はできるのか? 導入 = 成果 導入によって別の問題が出てないか?事業メリットはあったのか? 最新技術がハマる場所の発掘 ハマる場所の効果はどれくらいか?他に優先すべきポイントは? 最新技術 キャッチ アップ
最後にまとめ 大規模システムにおける改善のポイント ・課題認識と効果も合わせた導入をする → 技術導入が目的ではなく課題解決がメイン ・運用も含めて推進する → 構築しても現場にハマらなければ意味がない → 大規模システムでの運用変更による工数増加は馬鹿にできない
・技術でゴリ押しするだけが正しいわけではない → 今回の事例ではクラウド化がハマったがオンプレの方がやりやすいのであればそれでも よかった → 労力に見合う効果を発揮することと、それを見極めるために現場を知ることが重要
興味のある方お待ちしておりますmm ご清聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}