Modern deep learning model performance is very dependent on the choice of model hyperparameters, and the tuning process is a major bottleneck in the machine learning pipeline. In this talk, we will overview modern methods for hyperparameter tuning and show how Ray Tune, a scalable open source hyperparameter tuning library with cutting edge tuning methods, can be easily incorporated into everyday workflows. Find Ray Tune on Github at https://github.com/ray-project/ray.
This talk was originally given at PyData LA2019.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
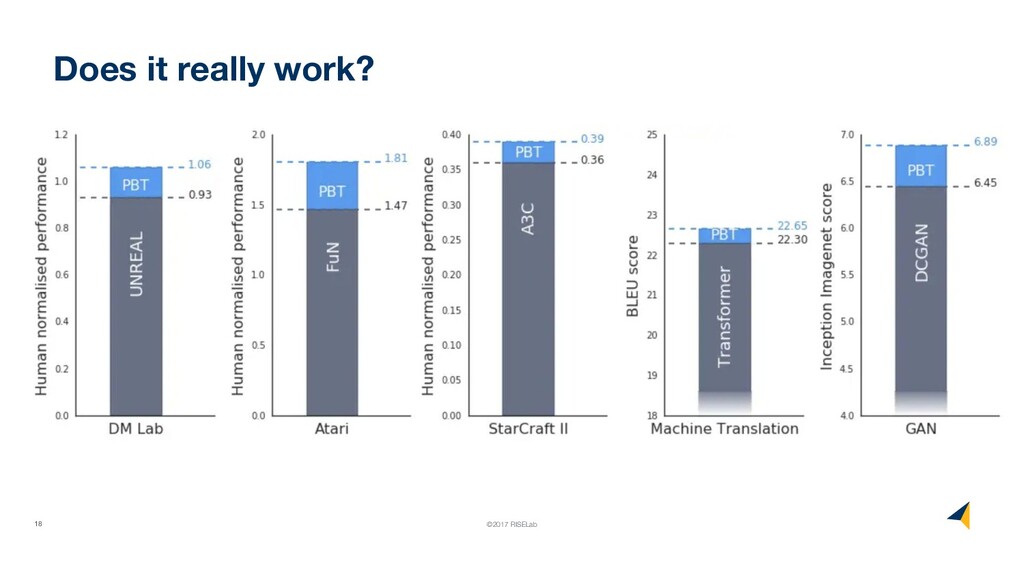{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
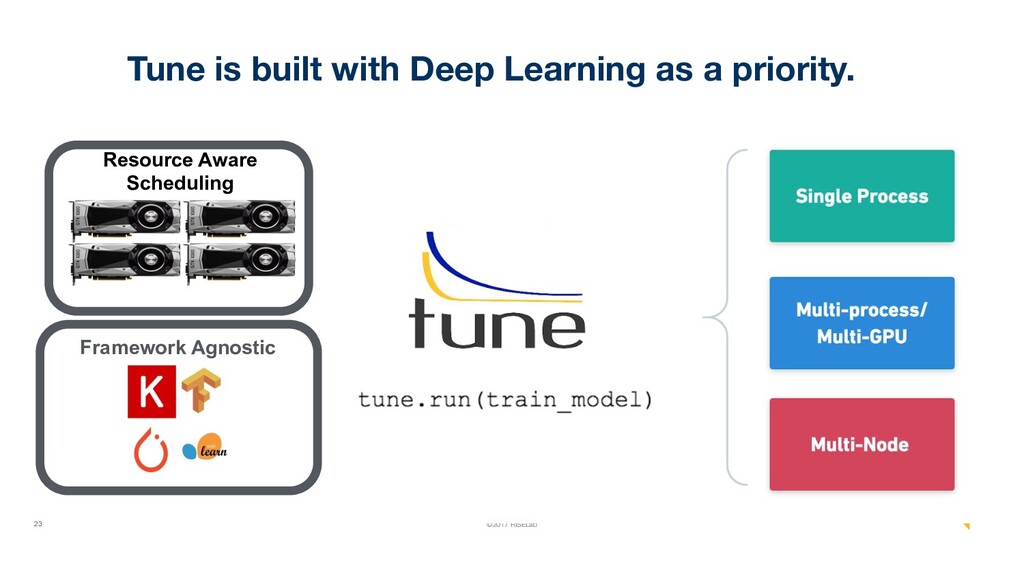{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}