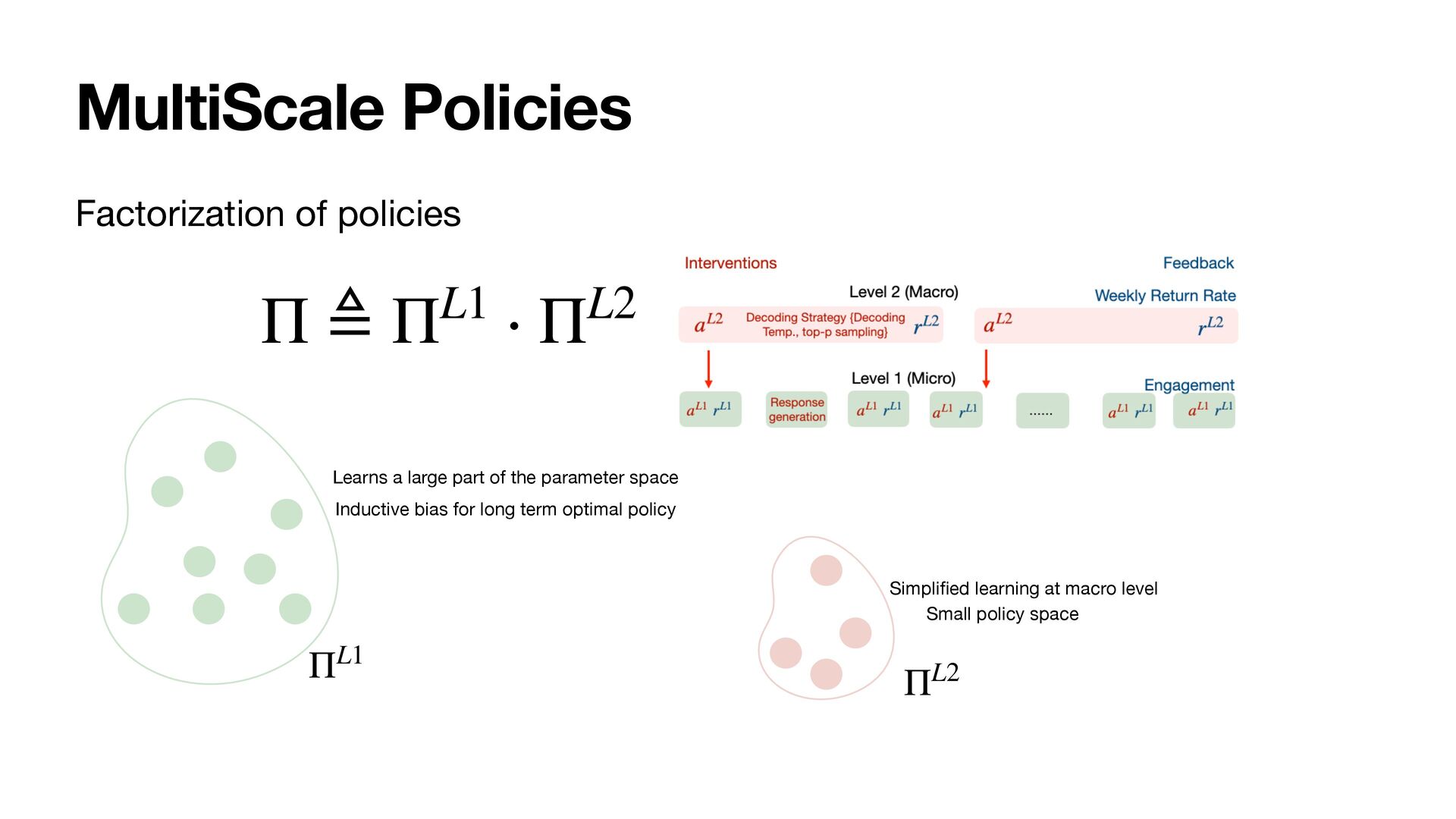
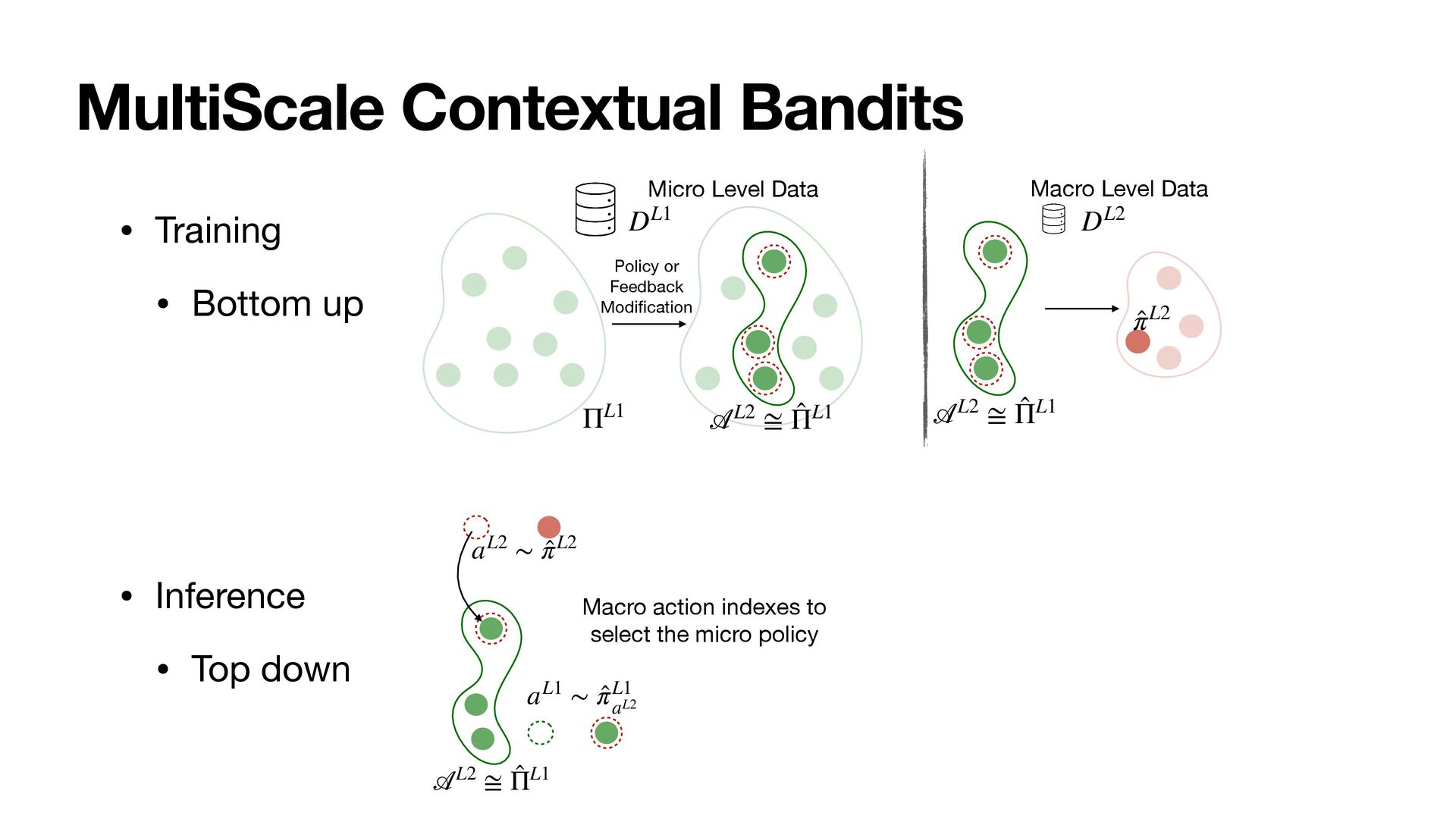
The feedback that AI systems (e.g., recommender systems, chatbots) collect from user interactions is a crucial source of training data. While short-term feedback (e.g., clicks, engagement) is widely used for training, there is ample evidence that optimizing short-term feedback does not necessarily achieve the desired long-term objectives. Unfortunately, directly optimizing for long-term objectives is challenging, and we identify the disconnect in the timescales of short-term interventions (e.g., rankings) and the long-term feedback (e.g., user retention) as one of the key obstacles. To overcome this disconnect, we introduce the framework of MultiScale Policy Learning to contextually reconcile that AI systems need to act and optimize feedback at multiple interdependent timescales.
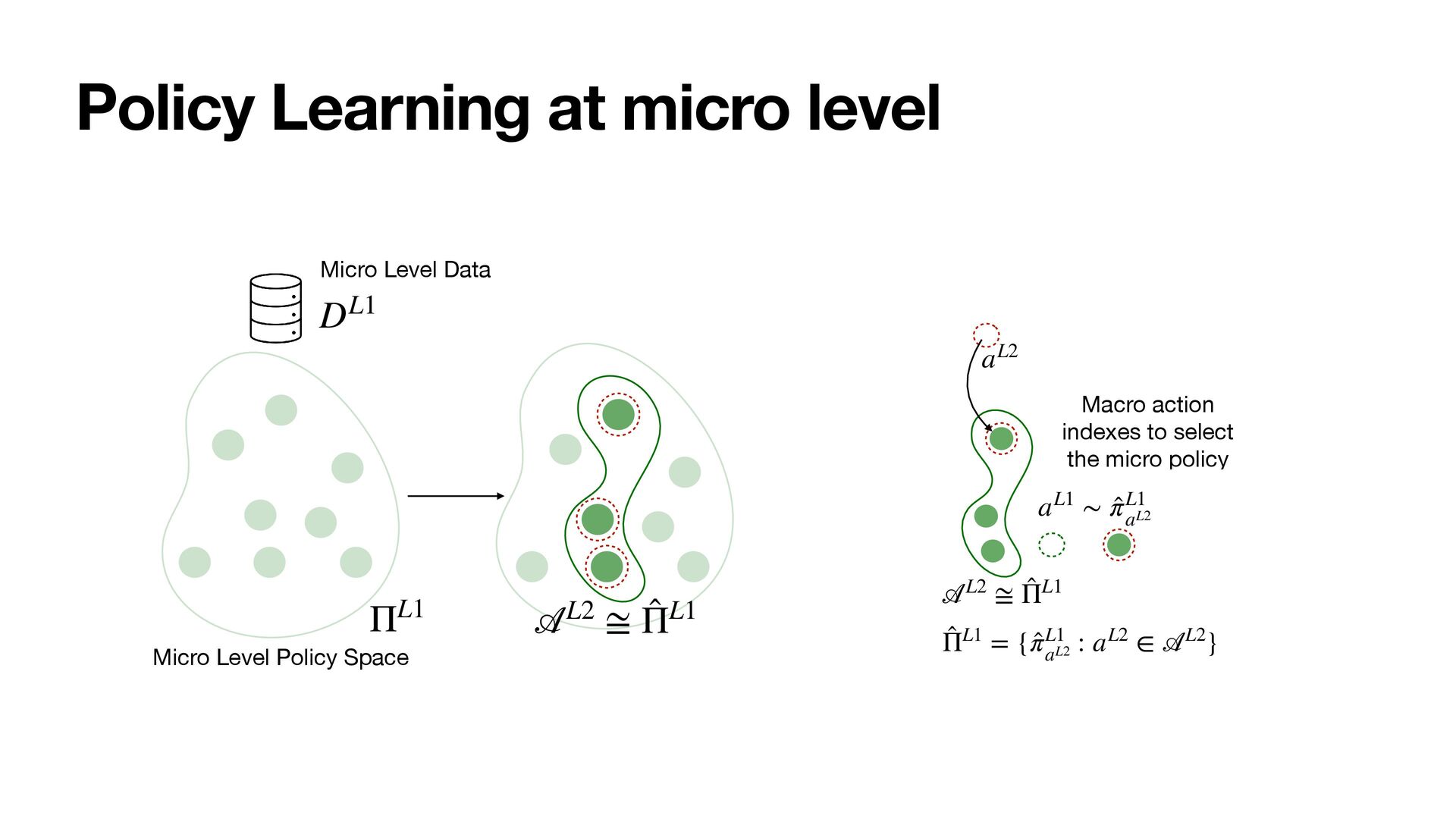
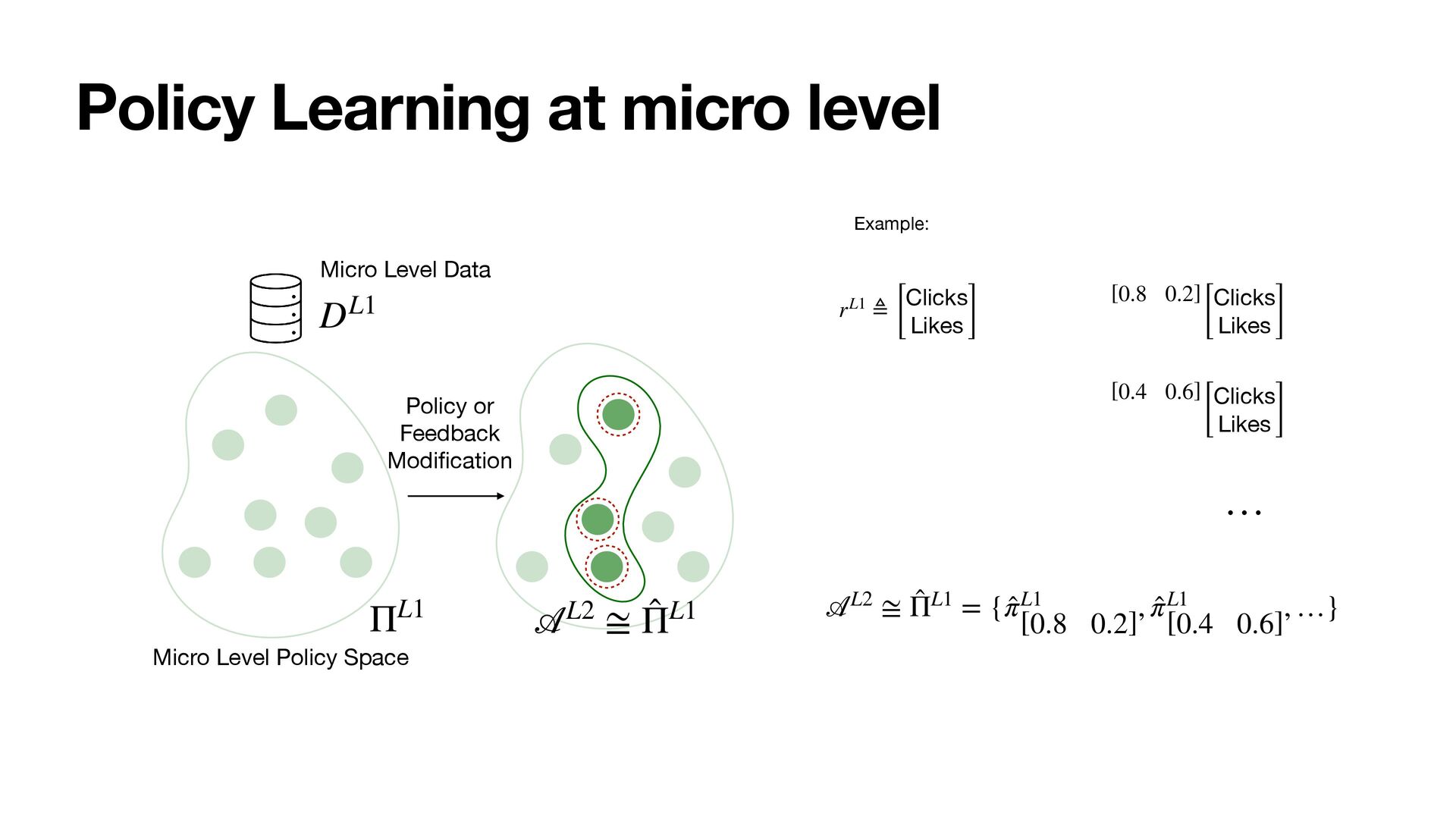
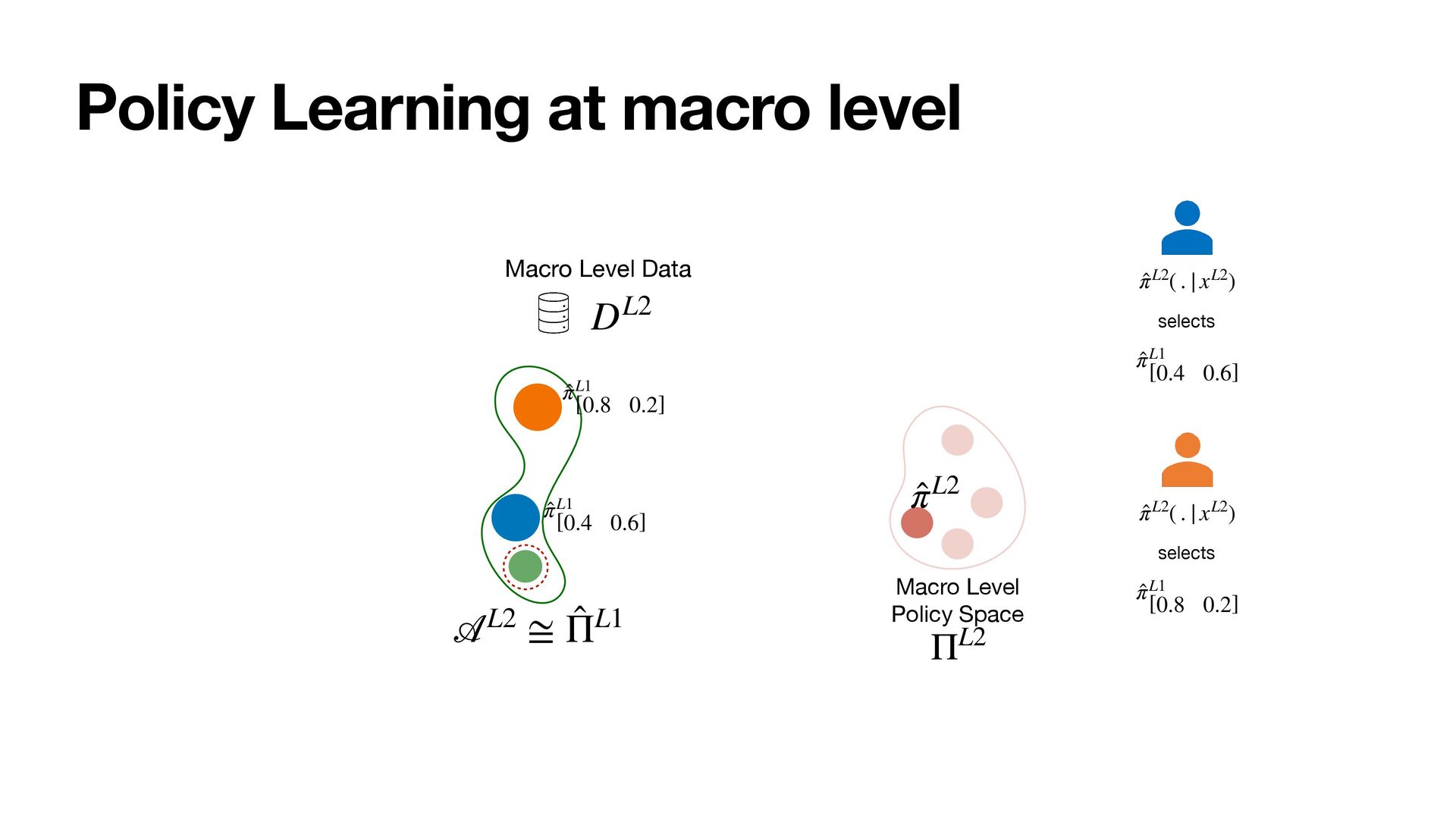
Following a PAC-Bayes motivation, we show how the lower timescales with more plentiful data can provide a data-dependent hierarchical prior for faster learning at higher scales, where data is more scarce.
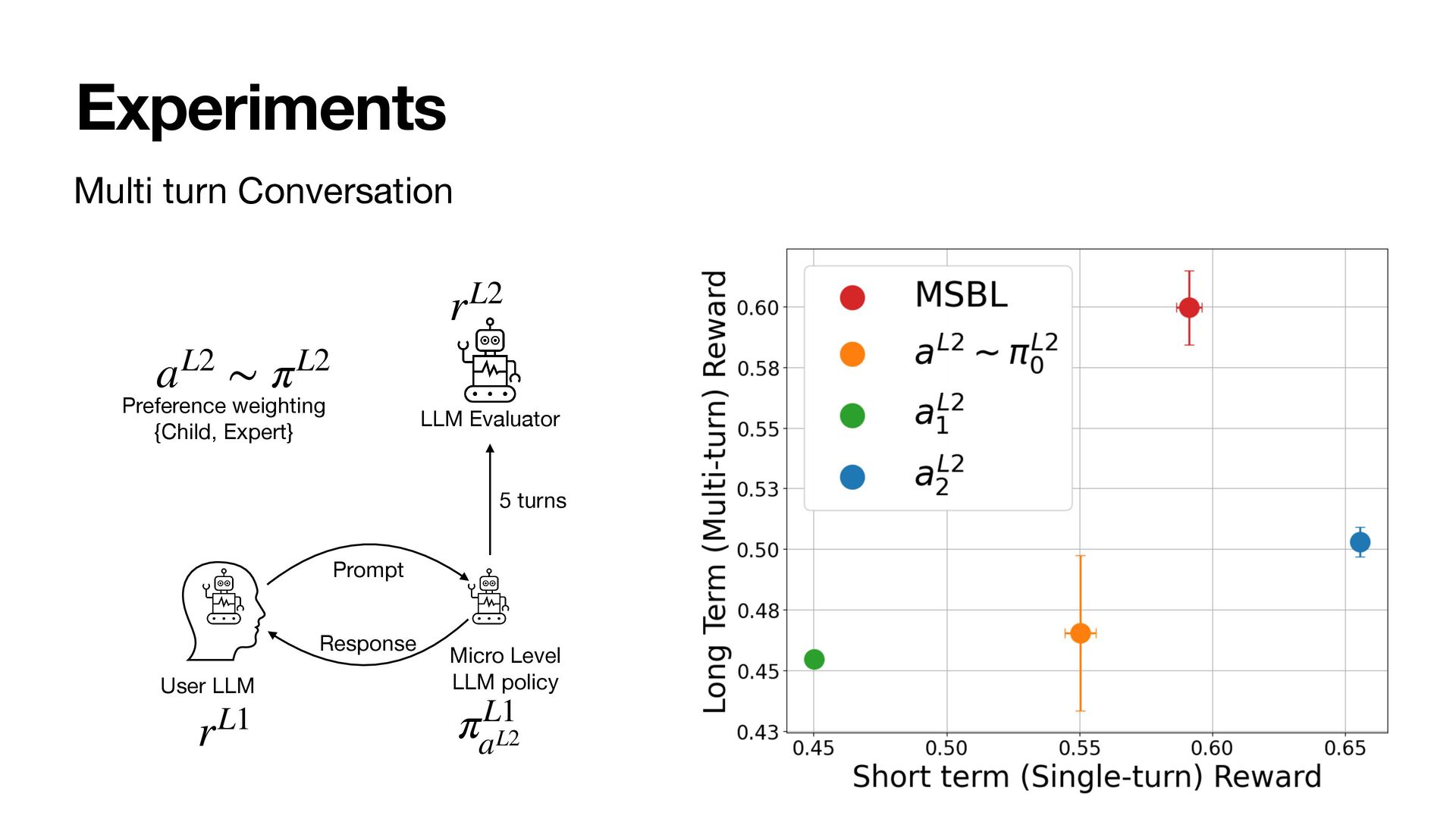
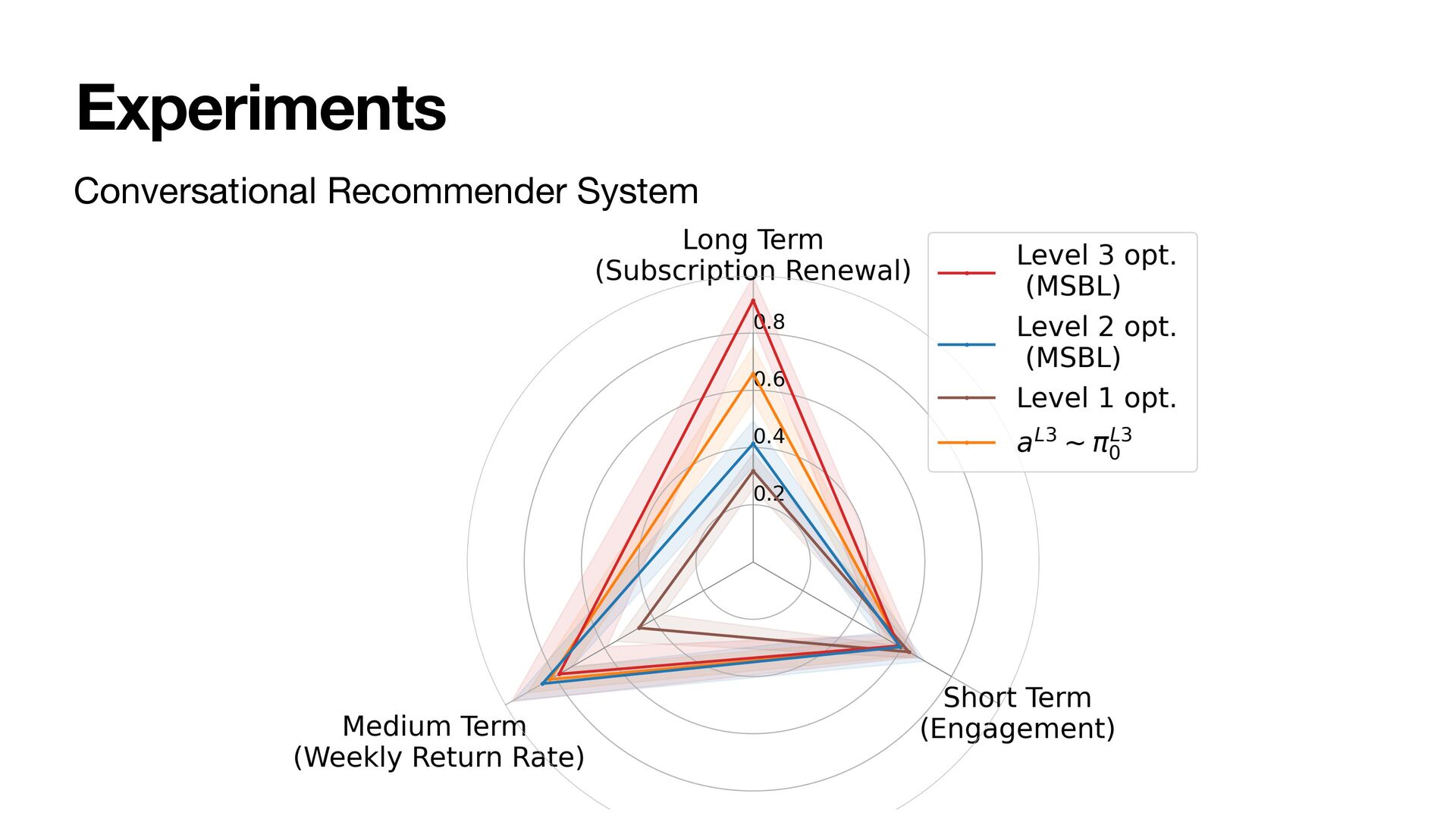
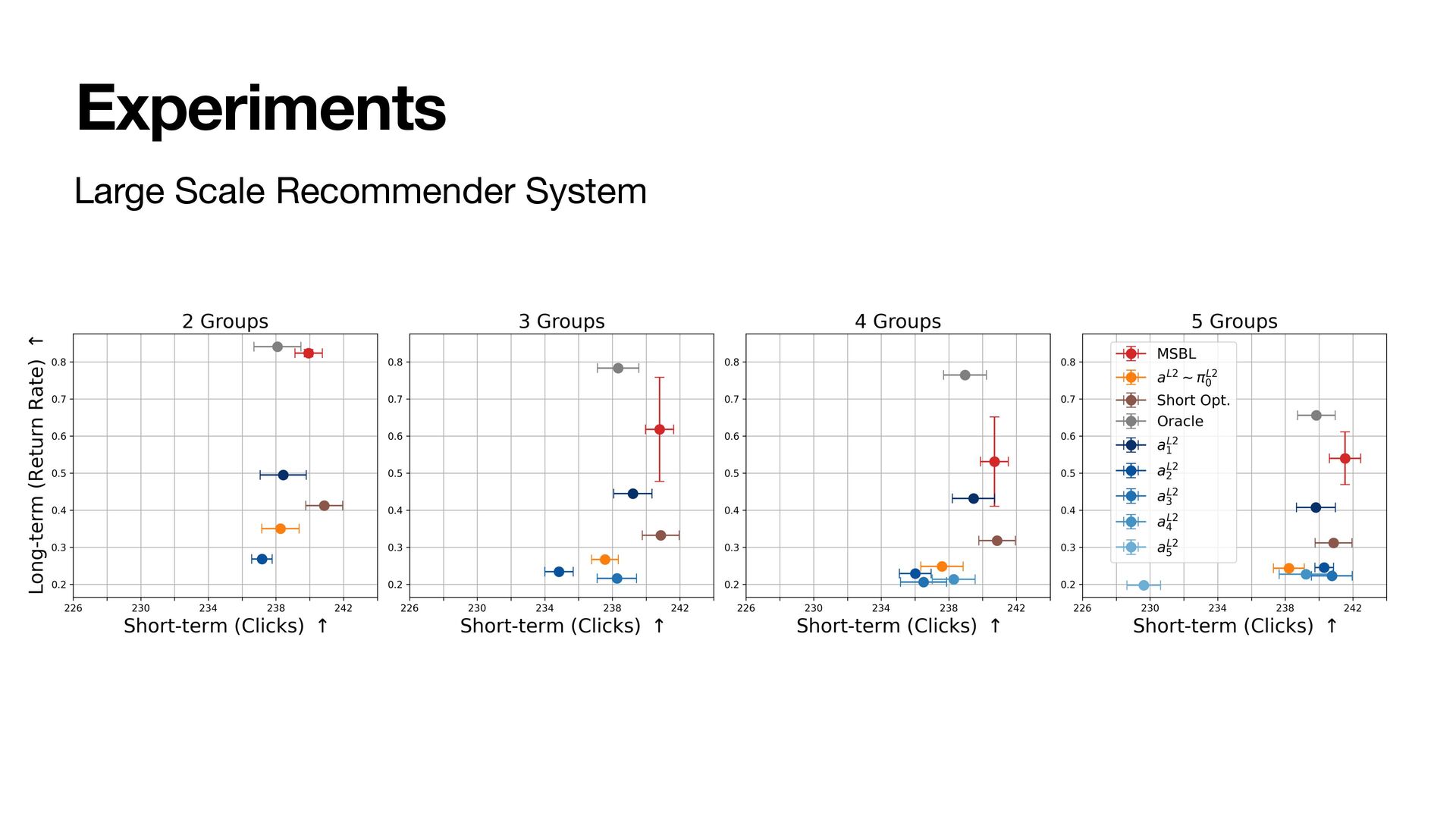
As a result, the policies at all levels effectively optimize for the long-term. We instantiate the framework with MultiScale Off-Policy Bandit Learning (MSBL) and demonstrate its effectiveness on three tasks relating to recommender and conversational systems.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}