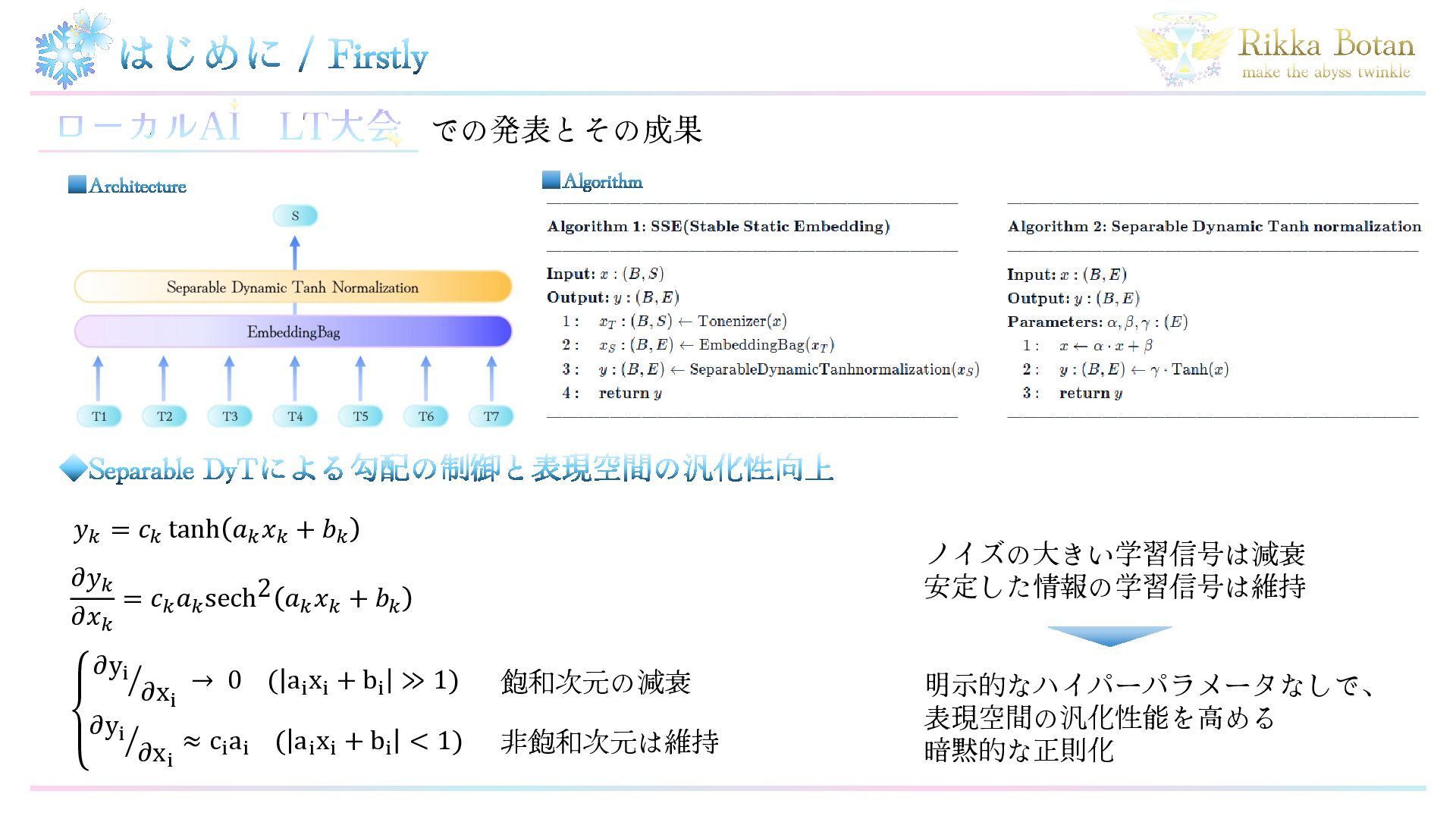
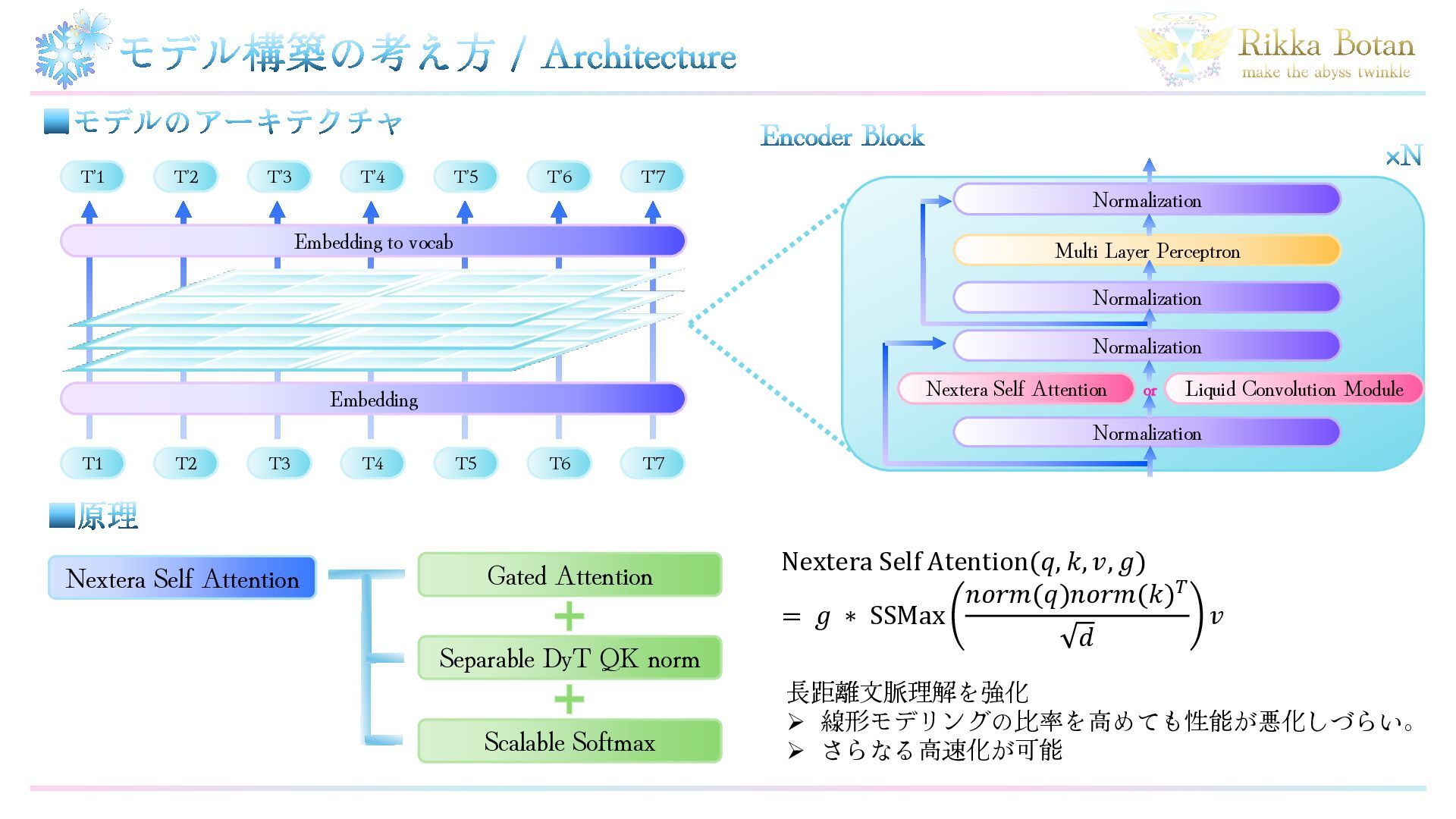
Qiu et al., “Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free”, arXiv:2505.06708, 10 May 2025 【2】Scalable Softmax QK matrixに系列長に応じたスケーリングを 行うことで長距離文脈での性能を改善 Ken M. Nakanishi, “Scalable-Softmax Is Superior for Attention”, arXiv:2501.19399, 31 Jan 2025 【3】LFMs: Liquid Foundation Models 液体時間定数型微分方程式からの着想で 世界最高クラスの効率となるモデルを構築 LiquidAI team, “LFM2 Technical Report”, arXiv:2511.23404, 28 Nov 2025 Perspective 最新の研究成果を用いることで、 高速化と高精度化が可能ではないか? Challenge モダンなSelf Attention機構を ライブラリ側の最適化を 阻害しない形で統合を行い、 線形モデリングと組み合わせる。 Idea 数学的に等価な式に変形し統合 + 線形モデリングにおける 係数の非線形性改善 ・畳み込み演算の効率改善 ◆先行研究
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}