Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向...
Search
Rikka Botan
June 30, 2026
Research
120
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
ローカルAIに向き合う展示会 vol.2における発表スライドです。
双方向エンコーダーモデルの研究進捗に関する発表です。
Rikka Botan
June 30, 2026
More Decks by Rikka Botan
See All by Rikka Botan
【生成AIなんでも展示会vol.5 LT登壇】NexteraBERT発表資料
rikkabotan7
0
130
SSE: Stable Static Embedding
rikkabotan7
0
25
【ローカルAI LT大会】SSE: Stable Static Embedding ー速度低下を伴わず 静的埋め込みモデルの潜在能力を引き出す Dynamic Tanh手法の提案
rikkabotan7
0
98
SEA Model series Op.1: Saint Lupinus pre-release
rikkabotan7
0
140
Other Decks in Research
See All in Research
LINEヤフー データサイエンス Meetup「三井物産コモディティ予測チャレンジ」の舞台裏-AlpacaTechパート
gamella
1
610
nlp2026 In-Context Learningに基づく経路案内のための地理的知識の活用方法に関する検討
takashiinui
0
100
AIで最適化を解けるか?
mickey_kubo
0
140
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
130
[CV勉強会@関東 CVPR2026] PSDesigner: Automated Graphic Design with a Human-Like Creative Workflow / kantocv 67th CVPR 2026
shunk031
0
140
COMETAを用いたデータ民主化運動の歴史
sazimai
0
110
Spatial Active Noise Control Based on Sound Field Interpolation Incorporating Physical Constraints
skoyamalab
0
120
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
160
Φ-Sat-2のAutoEncoderによる情報圧縮系論文
satai
4
850
「行ける・行けない表」による地域公共交通の性能評価
bansousha
0
170
Visual SLAM未来予測 / Future Prediction in Visual SLAM
koide3
1
640
Sleuthcon Keynote - How Cybercriminals (ab)use AI
fr0gger
0
250
Featured
See All Featured
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
880
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
350
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Designing for Performance
lara
611
70k
Context Engineering - Making Every Token Count
addyosmani
9
1k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
KATA
mclloyd
PRO
35
15k
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
Transcript
液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価 NexteraBERT: Rethinking Bidirectional Encoder Models with Liquid
Time-Constant Modules, Modern Self-Attention, and Separable Dynamic Tanh normalization
Vol.2 ローカルAIに向き合う 展示会
◆趣味 お菓子作り・紅茶・クラシック鑑賞・お洋服 ◆最近の活動 Silver Award: Liquid AI Hackathon Series |
Tokyo 記事執筆(Mamba, LFM2 (LTCs) 関連) SSE Modelシリーズの公開 自己紹介 / About us 独立研究者(機械学習 / 代数学 / 数理論理学) Independent researcher (machine learning / algebra / mathematical logic) り っ か ぼ た ん 六花 牡丹 Rikka Botan X(Twitter) Portfolio
目録 / Contents 1 NexteraBERTについて / Introduction 2 3 4
評価・考察 / Evaluations 手法/ Method モジュール構築の考え方 / Principle
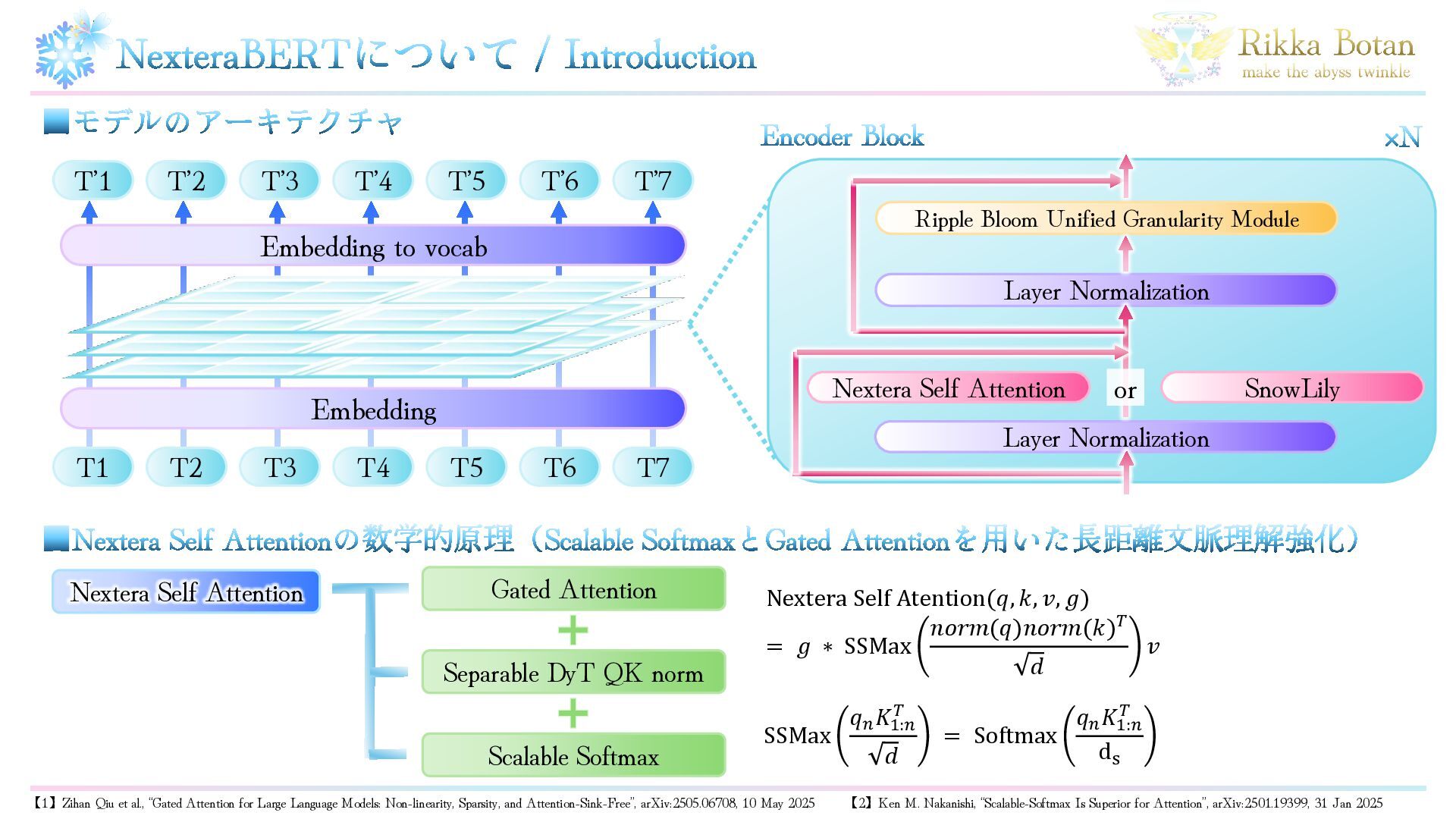
NexteraBERTについて / Introduction ▪モデルのアーキテクチャ T’1 T’2 T’3 T’4 T’5 T’6
T’7 T1 T2 T3 T4 T5 T6 T7 Embedding to vocab Embedding Encoder Block Ripple Bloom Unified Granularity Module Nextera Self Attention Layer Normalization Layer Normalization ×N SnowLily or Nextera Self Attention Scalable Softmax Gated Attention Separable DyT QK norm Nextera Self Atention(𝑞, 𝑘, 𝑣, 𝑔) = 𝑔 ∗ SSMax 𝑛𝑜𝑟𝑚(𝑞)𝑛𝑜𝑟𝑚(𝑘)𝑇 𝑑 𝑣 ▪Nextera Self Attentionの数学的原理(Scalable SoftmaxとGated Attentionを用いた長距離文脈理解強化) SSMax 𝑞𝑛 𝐾1:𝑛 𝑇 𝑑 = Softmax 𝑞𝑛 𝐾1:𝑛 𝑇 ds 【1】Zihan Qiu et al., “Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free”, arXiv:2505.06708, 10 May 2025 【2】Ken M. Nakanishi, “Scalable-Softmax Is Superior for Attention”, arXiv:2501.19399, 31 Jan 2025
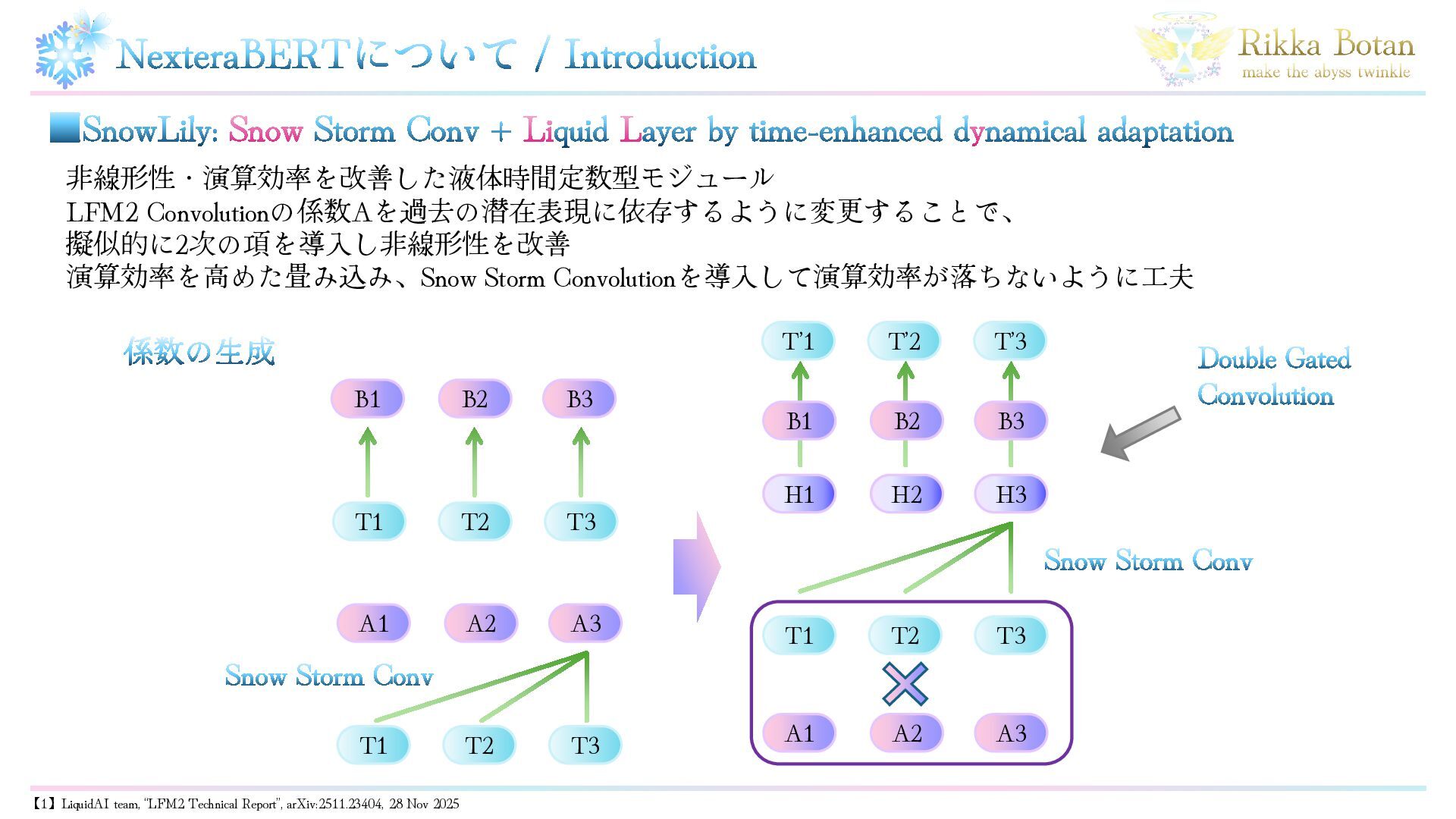
NexteraBERTについて / Introduction 非線形性・演算効率を改善した液体時間定数型モジュール LFM2 Convolutionの係数Aを過去の潜在表現に依存するように変更することで、 擬似的に2次の項を導入し非線形性を改善 演算効率を高めた畳み込み、Snow Storm Convolutionを導入して演算効率が落ちないように工夫
▪SnowLily: Snow Storm Conv + Liquid Layer by time-enhanced dynamical adaptation T1 T2 T3 A3 A2 A1 T’1 T’2 T’3 T1 T2 T3 H3 H2 H1 A3 A2 A1 B3 B2 B1 B3 B2 B1 T1 T2 T3 Snow Storm Conv Snow Storm Conv 係数の生成 Double Gated Convolution 【1】LiquidAI team, “LFM2 Technical Report”, arXiv:2511.23404, 28 Nov 2025
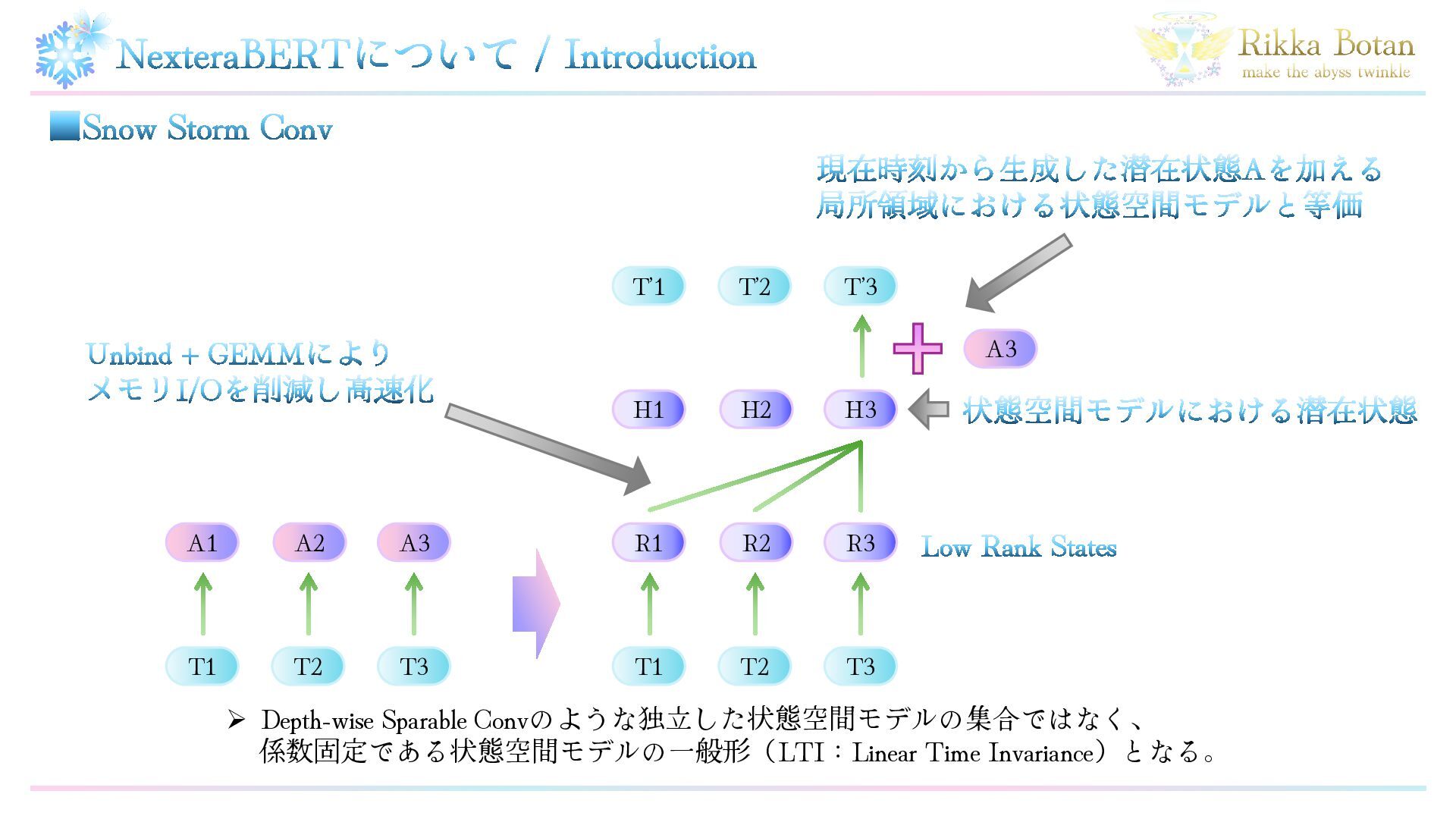
NexteraBERTについて / Introduction ▪Snow Storm Conv T’1 T’2 T’3 T1
T2 T3 R3 R2 R1 Low Rank States A3 A2 A1 T1 T2 T3 H3 H2 H1 A3 ➢ Depth-wise Sparable Convのような独立した状態空間モデルの集合ではなく、 係数固定である状態空間モデルの一般形(LTI:Linear Time Invariance)となる。 Unbind + GEMMにより メモリI/Oを削減し高速化 現在時刻から生成した潜在状態Aを加える 局所領域における状態空間モデルと等価 状態空間モデルにおける潜在状態
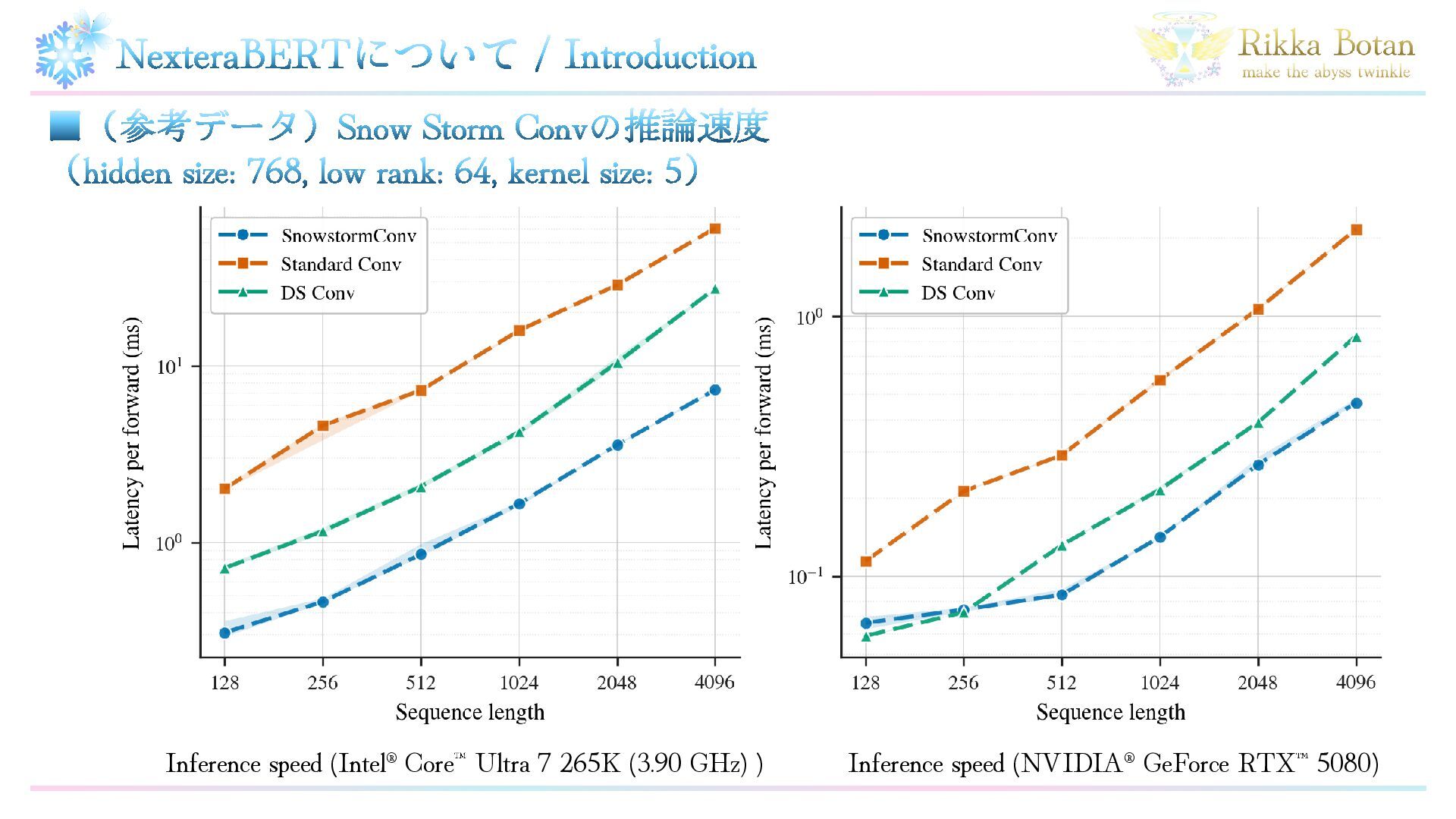
NexteraBERTについて / Introduction ▪(参考データ)Snow Storm Convの推論速度 (hidden size: 768, low
rank: 64, kernel size: 5) Inference speed (Intel® Core Ultra 7 265K (3.90 GHz) ) Inference speed (NVIDIA® GeForce RTX 5080)
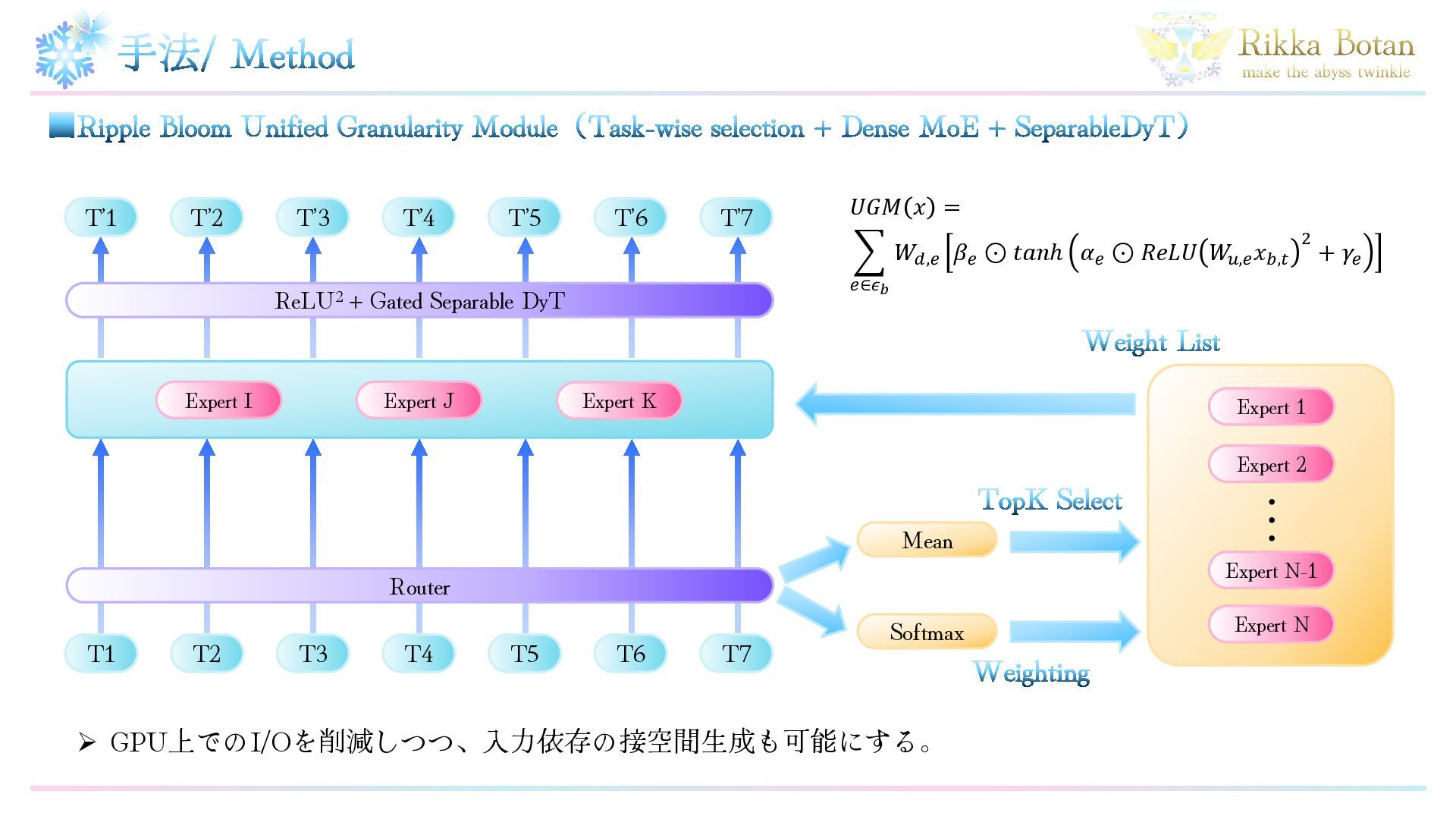
モジュール構築の考え方 / Principle Perspective MoEはExpertsを基底とする表現空間を生成するだけであり、 MLPとは異なり入力依存の接空間生成はできない。 Challenge Task-wiseなスパース性と入力依存の接空間生成の両方を 可能にする構造を構築する。 Idea
粗いスパース+接空間生成という2段階とすることで高速化する。 MoEの非効率性の原因となっていたメモリのI/Oを削減するために Expertsを1段階目で粗く選択。 2段階目で入力依存の接空間生成を行う。
手法/ Method T’1 T’2 T’3 T’4 T’5 T’6 T’7 Expert
I Expert J Expert K T1 T2 T3 T4 T5 T6 T7 Router Weight List Expert 1 Expert 2 Expert N Expert N-1 ・ ・ ・ TopK Select Mean Softmax Weighting ReLU2 + Gated Separable DyT ▪Ripple Bloom Unified Granularity Module(Task-wise selection + Dense MoE + SeparableDyT) ➢ GPU上でのI/Oを削減しつつ、入力依存の接空間生成も可能にする。 𝑈𝐺𝑀 𝑥 = 𝑒∈𝜖𝑏 𝑊𝑑,𝑒 𝛽𝑒 ⊙ 𝑡𝑎𝑛ℎ 𝛼𝑒 ⊙ 𝑅𝑒𝐿𝑈 𝑊 𝑢,𝑒 𝑥𝑏,𝑡 2 + 𝛾𝑒
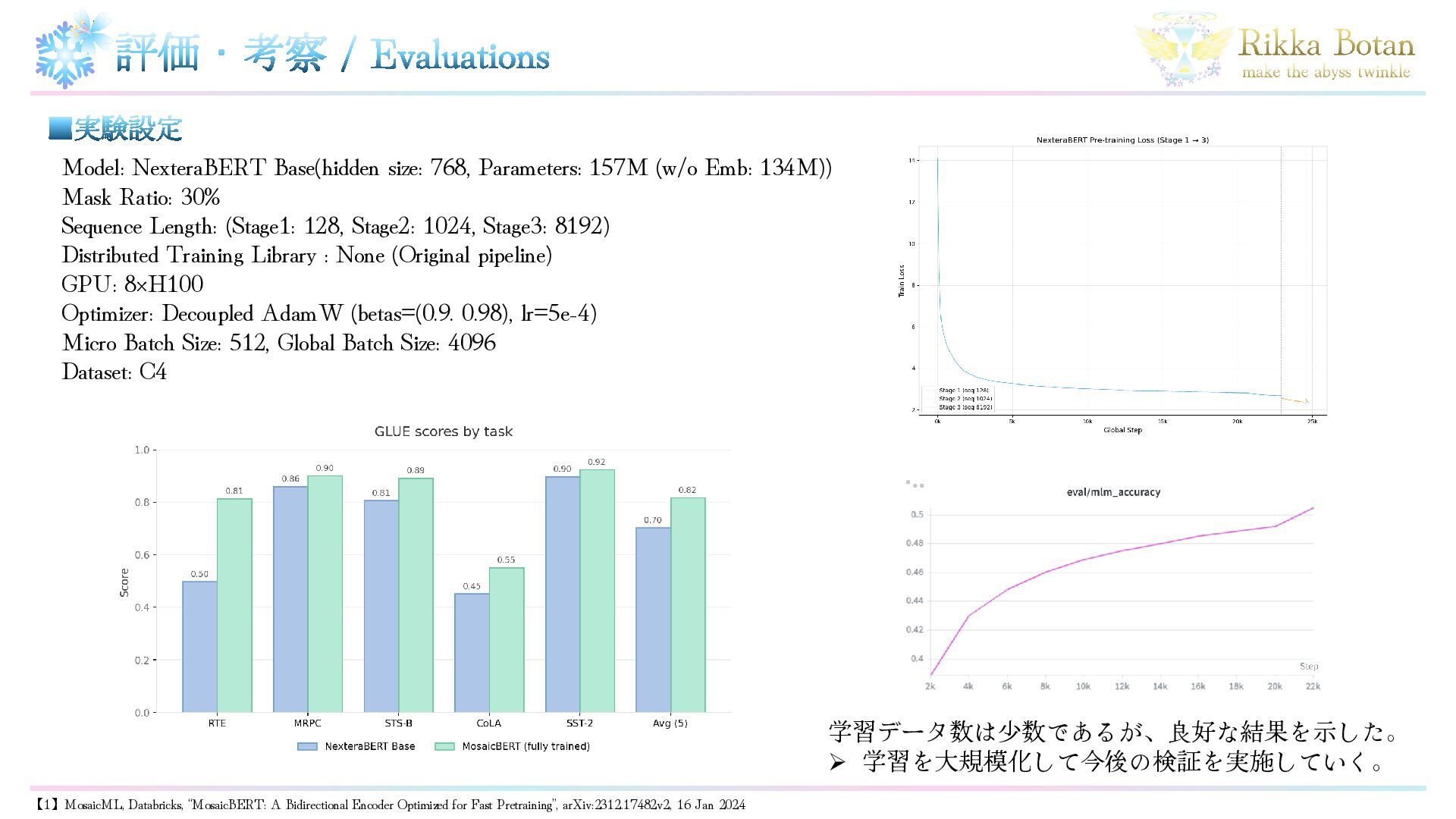
▪実験設定 評価・考察 / Evaluations Model: NexteraBERT Base(hidden size: 768, Parameters:
157M (w/o Emb: 134M)) Mask Ratio: 30% Sequence Length: (Stage1: 128, Stage2: 1024, Stage3: 8192) Distributed Training Library : None (Original pipeline) GPU: 8×H100 Optimizer: Decoupled AdamW (betas=(0.9. 0.98), lr=5e-4) Micro Batch Size: 512, Global Batch Size: 4096 Dataset: C4 学習データ数は少数であるが、良好な結果を示した。 ➢ 学習を大規模化して今後の検証を実施していく。 【1】MosaicML, Databricks, “MosaicBERT: A Bidirectional Encoder Optimized for Fast Pretraining”, arXiv:2312.17482v2, 16 Jan 2024
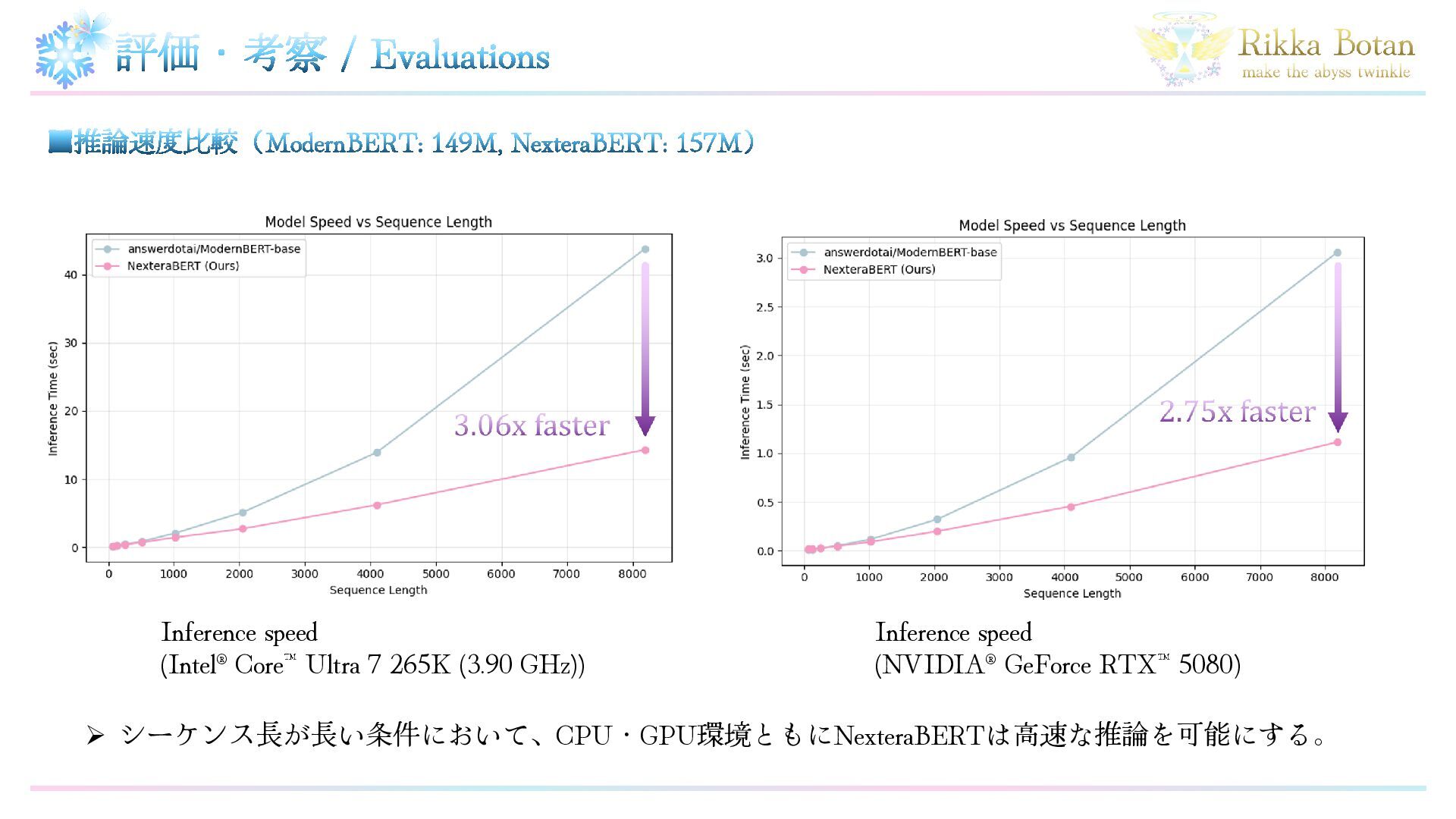
▪推論速度比較(ModernBERT: 149M, NexteraBERT: 157M) 評価・考察 / Evaluations ➢ シーケンス長が長い条件において、CPU・GPU環境ともにNexteraBERTは高速な推論を可能にする。 Inference
speed (Intel® Core Ultra 7 265K (3.90 GHz)) Inference speed (NVIDIA® GeForce RTX 5080)
13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}