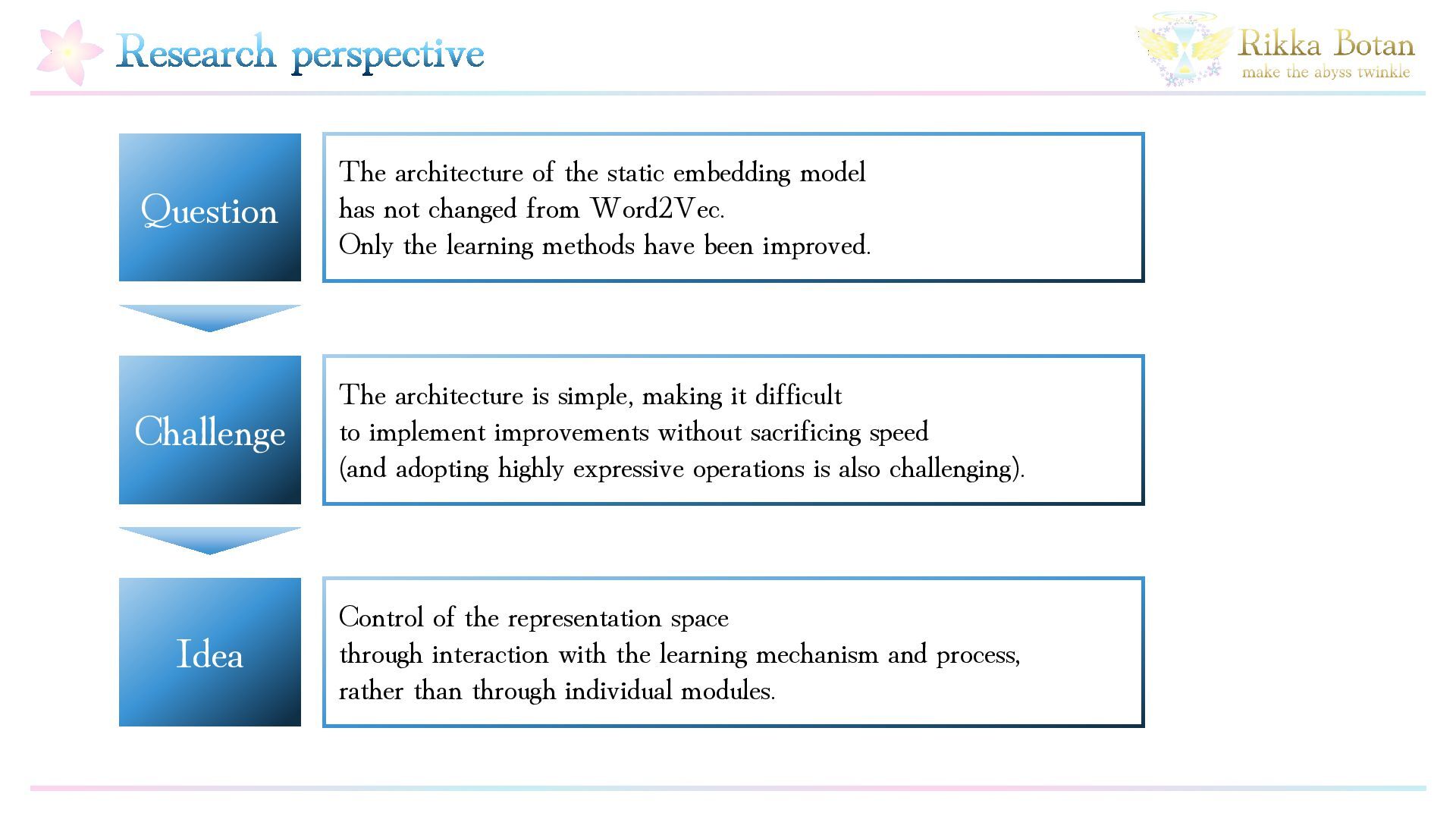
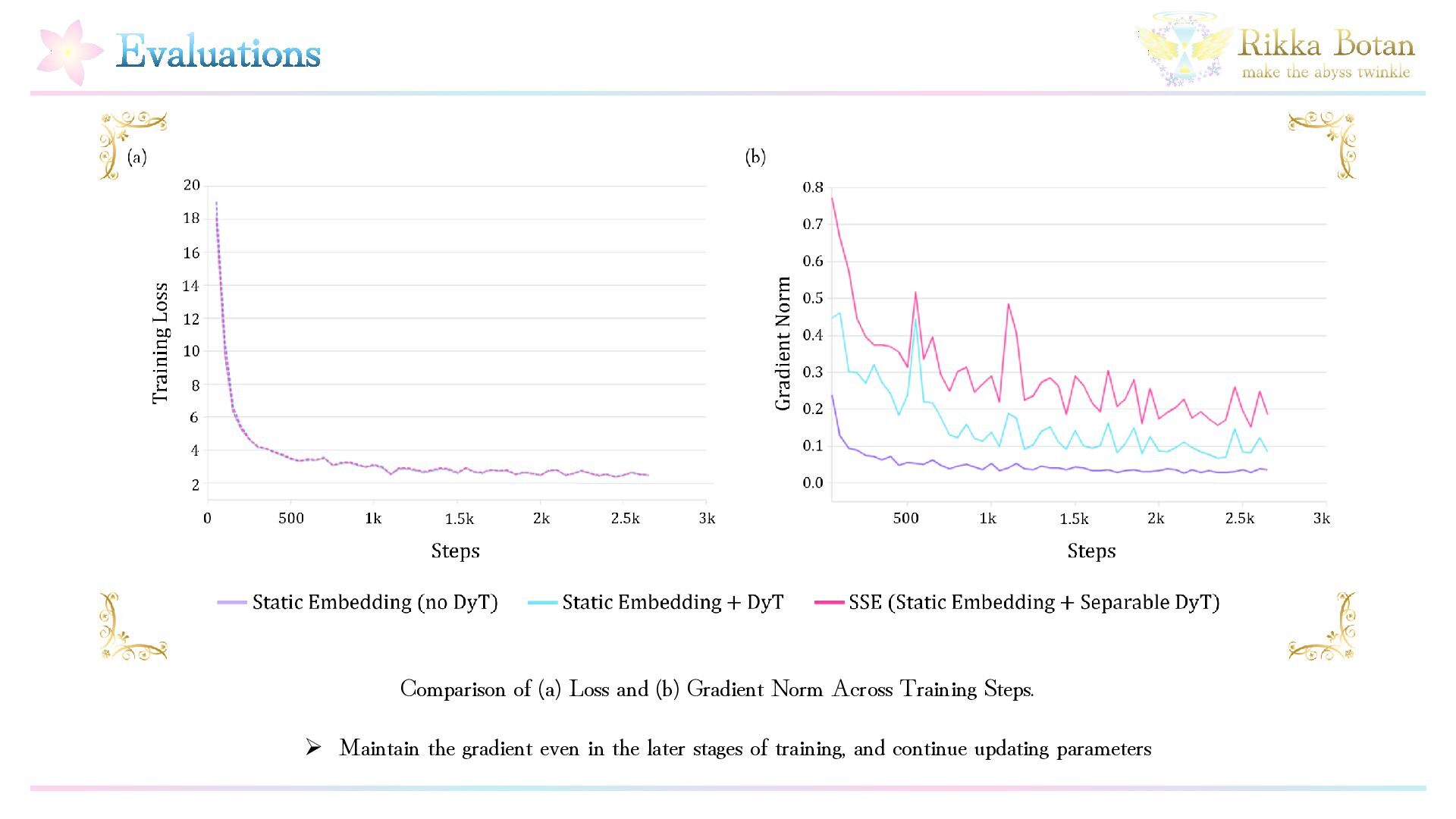
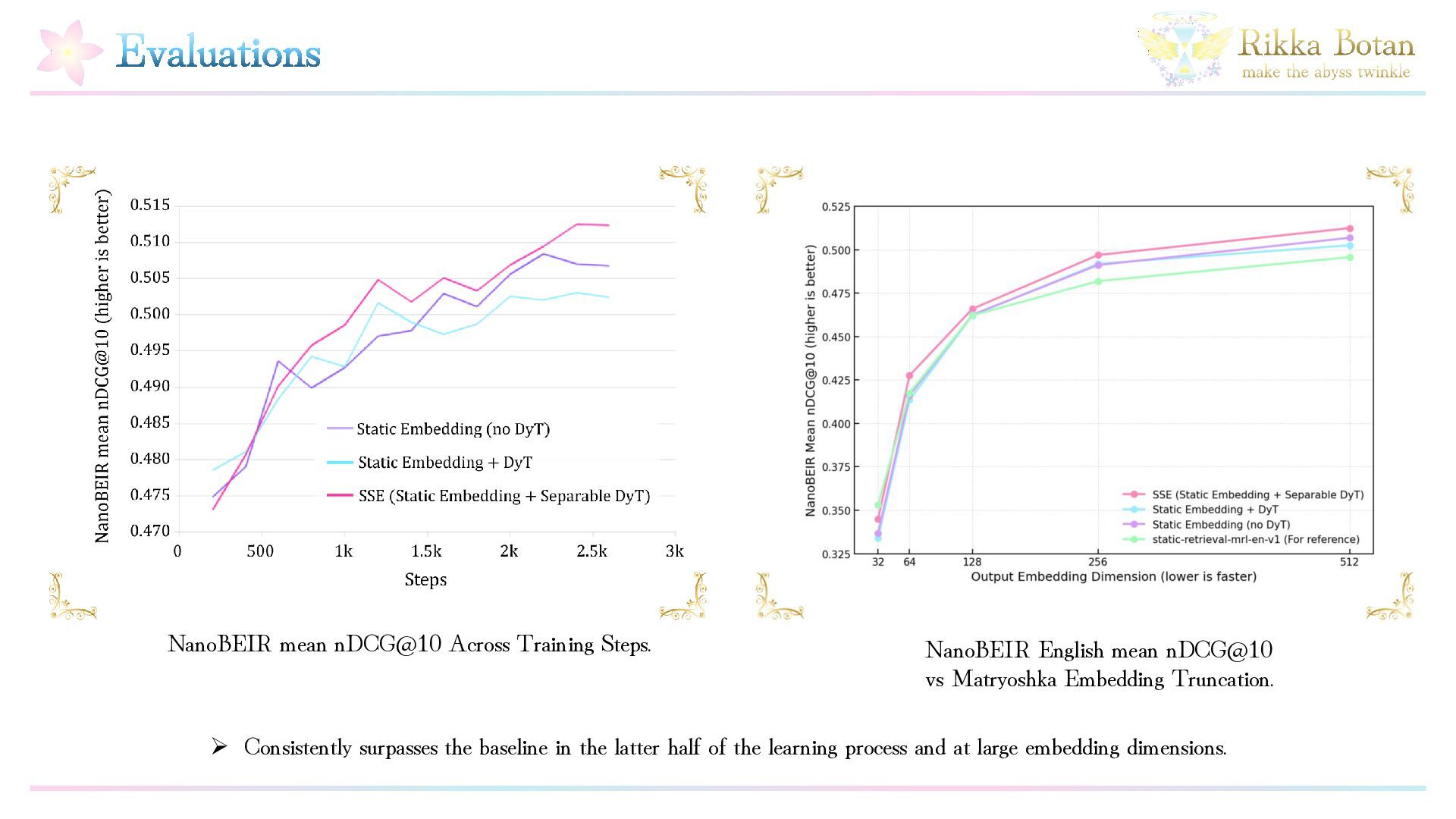
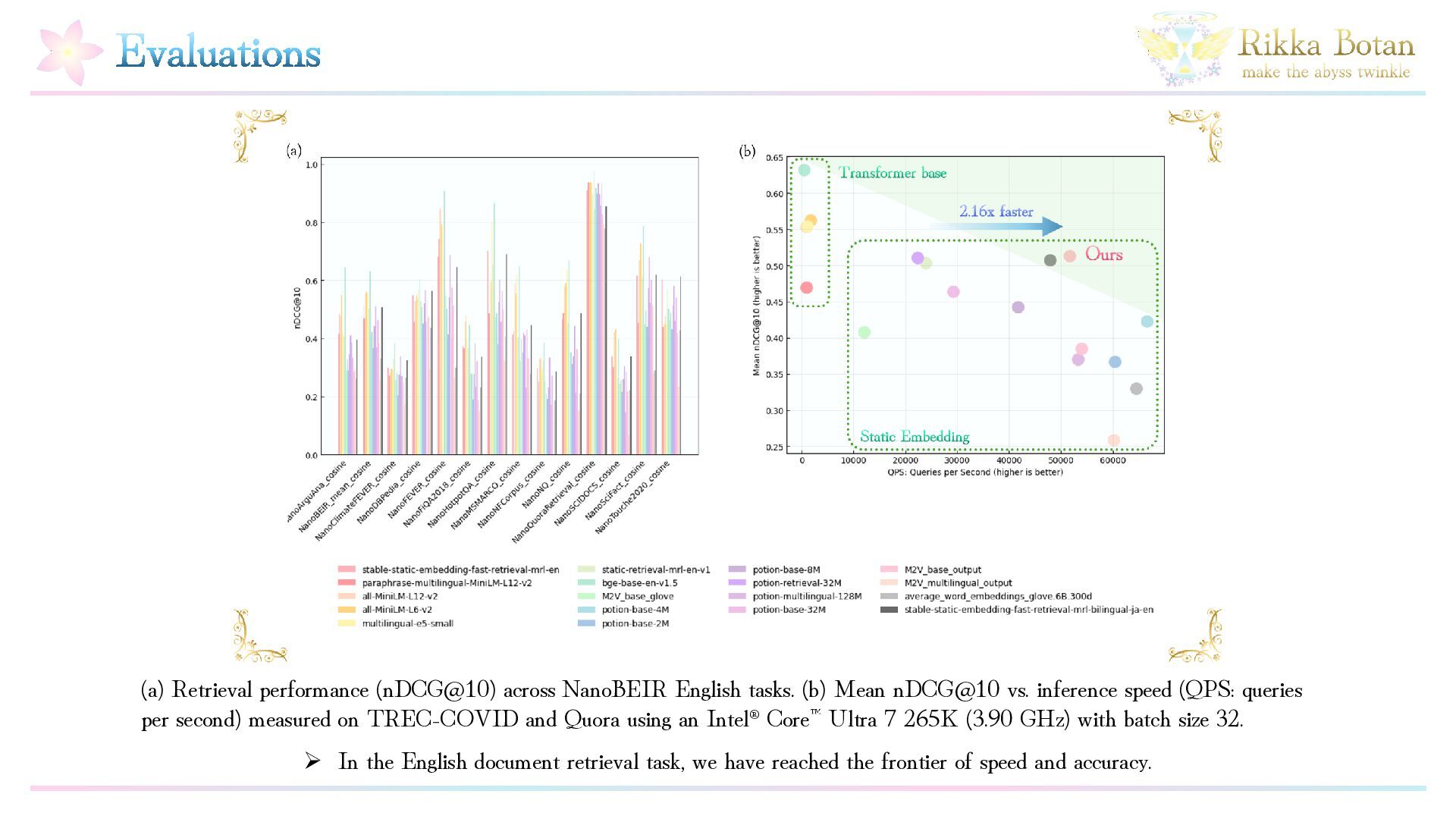
Static embedding models enable fast inference due to their simple architecture, but, it is well known that improving their structural expressiveness is challenging. At the same time, as corpora continue to grow in scale, the demand for both higher efficiency and higher accuracy in embedding models has increased significantly. In this work, we propose a simple yet effective method called SSE (Stable Static Embedding), which incorporates Separable DyT (Dynamic Tanh normalization). We demonstrate that SSE achieves higher retrieval performance than prior approaches while using only half the number of parameters. Despite having only 16 million parameters, SSE attains a mean NanoBEIR (English) nDCG@10 score of 0.512. By leveraging Separable DyT, SSE effectively regulates gradient flow and suppresses inter-dimensional imbalance and overfitting, thereby improving generalization performance. Our method provides a new perspective on static embedding models and offers a pathway toward faster and more accurate retrieval systems.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}