Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第八章-決定木モデル【数学嫌いと学ぶデータサイエンス・統計的学習入門】
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Ringa_hyj
July 22, 2020
Technology
110
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
第八章-決定木モデル【数学嫌いと学ぶデータサイエンス・統計的学習入門】
第八章【数学嫌いと学ぶデータサイエンス・統計的学習入門】
Ringa_hyj
July 22, 2020
More Decks by Ringa_hyj
See All by Ringa_hyj
DVCによるデータバージョン管理
ringa_hyj
0
410
deeplakeによる大規模データのバージョン管理と深層学習フレームワークとの接続
ringa_hyj
0
120
Hydraを使った設定ファイル管理とoptunaプラグインでのパラメータ探索
ringa_hyj
0
240
ClearMLで行うAIプロジェクトの管理(レポート,最適化,再現,デプロイ,オーケストレーション)
ringa_hyj
0
270
Catching up with the tidymodels.[Japan.R 2021 LT]
ringa_hyj
3
880
多次元尺度法MDS
ringa_hyj
0
420
因子分析(仮)
ringa_hyj
0
210
階層、非階層クラスタリング
ringa_hyj
0
160
tidymodels紹介「モデリング過程料理で表現できる説」
ringa_hyj
0
690
Other Decks in Technology
See All in Technology
OPENLOGI Company Profile for engineer
hr01
1
75k
モバイル研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
240
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
BigQuery を検索ソースとした AI Agent の作り方って 〇〇 通りあんねん
satohjohn
0
110
セキュリティ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
14
13k
Azure Durable Functions で作った NL2SQL Agent の精度向上に取り組んだ話/aidevday2026
thara0402
0
100
ソフトウェアアーキテクチャ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
650
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
6
530
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
440
データ活用研修 データマネジメント【MIXI 26新卒技術研修】
mixi_engineers
PRO
4
570
数値で見る Microsoft MVP 〜Spec Kit と GitHub Copilot Agent で作るデータ可視化ダッシュボード〜
yutakaosada
0
150
『モデル + ハーネス』で読み解く AIエージェント入門
oracle4engineer
PRO
2
210
Featured
See All Featured
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
3
370
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
510
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.5k
The Cost Of JavaScript in 2023
addyosmani
55
10k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
330
Building Adaptive Systems
keathley
44
3.1k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
410
Navigating Team Friction
lara
192
16k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
910
Transcript
日本一の数学嫌いと学ぶ データサイエンス ~入門~ @Ringa_hyj
@Ringa_hyj 日本一の数学嫌いと学ぶ データサイエンス ~第八章:決定木モデル~
対象視聴者: 数式や記号を見ただけで 教科書を閉じたくなるレベル , , C , ,
決定木モデル ・回帰木 ・分類木 ・バギング ・ランダムフォレスト ・ブースティング
回帰木
予測したい変数を周辺の説明変数から予測する。 周辺の説明変数を単純な層に分ける(セグメント化)、 予測変数空間もセグメント化され、 そのセグメントの平均や最頻(多数決)を使って予測とsる セグメント分けの過程が分岐していく木のようなので 決定木 と呼ばれる 単純な決定木はロジスティックやスプラインには敵わない そこでバギングやランダムフォレストにより複数の単純な決定木を作ることで 複雑・非線形に予測ができる
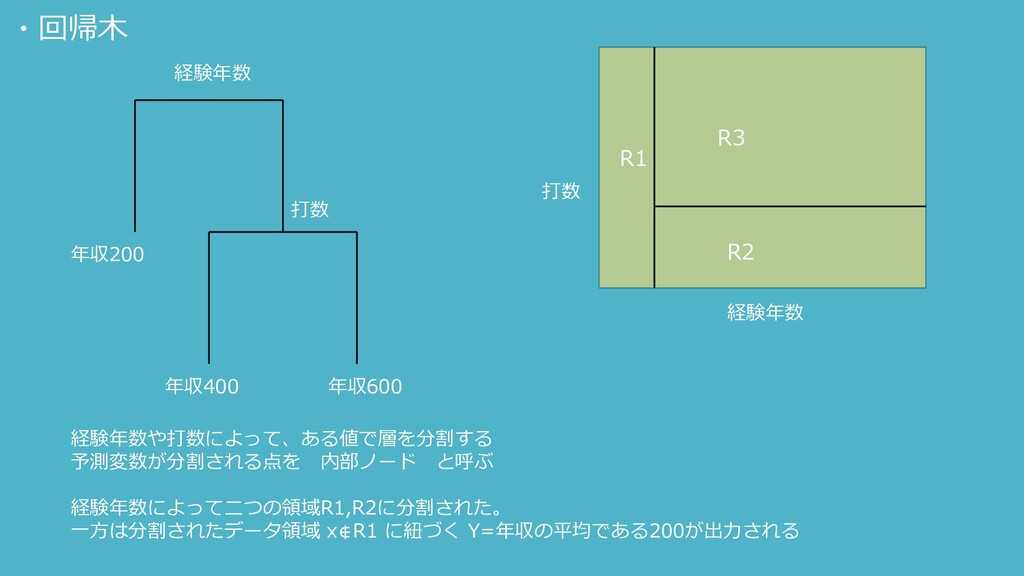
R1 年収200 年収400 年収600 経験年数 打数 打数 経験年数 経験年数や打数によって、ある値で層を分割する 予測変数が分割される点を
内部ノード と呼ぶ 経験年数によって二つの領域R1,R2に分割された。 一方は分割されたデータ領域 x∉R1 に紐づく Y=年収の平均である200が出力される R2 R3 ・回帰木
R1 打数 経験年数 R2 R3 領域、内部ノード の閾値を決めるかという話 ා =1
∈ − ො 2 上式(RSS)を最小化するように学習する y^Rjは j番目の箱の予測対象の値の平均である 最大J領域まで分けていることを考える しかし、とりうるJの上限を毎回計算していては計算コス トが持たない ・回帰木
再帰的な2分割法 ある状態のデータを最も綺麗に分割する変数を探し、2つに分割する というシンプルな方法(全体のJがいくつになるか関係ない) 分割した後のデータが綺麗に分割できるかは気にしていない 予測につかう変数と、分割点をRSSが最も小さくなるようにもとめる 各変数で分割点を動かしていけばわかるが、数式では 各変数に対して以下を最小とするようなsを求め、その中で最小の変数Xjとsの組を採用する ∈1 ,
− ො 1 2 ∈2 , − ො 2 2 + ・回帰木
刈り込み 訓練データには当てはまりやすいものの、汎化性が得られにくい より分岐を少なくするにはどうするか RSSの減少に閾値をもうけて、減少量が小さければ分岐をつくらない という方法 しかしこの方法では欠点があり、役に立たないような変数が早いうちに分岐に使われた場合 あとに残った重要な変数の分岐が生じなくなってしまう そこで考えられたのが、一度細かい分岐の大きな木をつくり いらない分岐を消していく方法 ・回帰木
木の複雑さをコストとして考えた刈り込み法は 最弱リンク刈り込み法とよばれる 2分割を行う 領域内の観測値(変数?)がある値よりも下回るまで分割を続ける 以下を木のコストとして考える |T|は終端のノード数 Rmはm番目のノードで分けられた領域 YRmはその領域の平均値 αはチューニングパラメタ 0の時はなにも制約なく木を作った場合に同じとなる
αを増加させると、終端ノード数に罰を加えていくことになる 訓練データと交差検証データを使いながらバランスのいいαを決める つまりαを変化させながら、テスト誤差、交差検証誤差の一番小さくなるように分岐をさせていく。 ා =1 ∈ − ො 2 + ・回帰木
分類木
・分類木 質的変数を予測したいときは平均値を出力というわけにもいかない 分割点を考えるために 不純度 を考える RSSも使えないので 誤分類率(分類誤差) を採用する 分類木の出力は終端の領域内の予測対象の変数(クラス)のうち最も頻度の多いものである 対して誤分類率は、それ以外の割合を考えると、
mという分類後の領域で一番多いクラスがkだとする p^mkは領域内の合計数でクラスkの合計数を割った kの面積 である k以外の面積を誤分類率として考える あまり感度が良くないため、 不純度として ジニ指数 や エントロピー が有名である = 1 − max
・分類木 ジニ指数(ジニ不純度) 全Kクラスの総分散を表す すべてのpmkが0 or 1であると、ジニ係数が小さくなる 0 or 1ということは、特定のクラスのみである 、不純なクラスが混ざっていない
ということになる = =1 1 − Ƹ
・分類木 エントロピー pmkは0から1の間であるので、-pmk log pmk に変形すると必ず0以上になる pmkが0か1に近ければ、エントロピーは0に近くなる ジニ不純度と似た挙動をする = −
=1 log
・分類木 分類木の作成にはジニ係数やエントロピーを使って分類するといい ジニ係数やエントロピーでも刈り込みはできるが、 精度良く木を刈り込むには誤分類率をつかうのが好ましい
・分類木 今までの線形回帰は = 0 + =1 = =1
∗ 1 ∈ 回帰木は 問題によってどちらを採用するかを決めるのがいい。 二次元plotで線形の場合は線形回帰 階段状や、より複雑な関係性、場合分けで予測が複雑に変化するような関係 になっている場合は回帰木で予測することが望ましい 分析の中には説明の簡単、解釈性や視覚的インパクトを得るために 決定木を採用することもすくなくない
・決定木のメリット デメリット メリット ・木は説明しやすい ・人間らしい意思決定と似ている ・ダミー変数を使わずに質的データを扱える デメリット ・単純な決定木では線形・非線形回帰の精度を超えることは難しい ・データの変化によって木の構造が変化するため作ったモデルが崩れやすい
バギング
・バギング 単純な決定木ではバリアンスが大きくなる難点がある (汎化がない) たとえば訓練データを二つに区切って決定木を作ると全く別のものができることもある バリアンスが小さいモデル(決定木)と言われれば、 どんなデータでも似たようなモデルができること と考えることができる 線形回帰は変数の数に対してデータ数nが増えることでバリアンスの小さいモデルが得られる バギングとはbootstrap aggregation
のことで、ブートストラップ法(交差検証の項参照) と関係を持つ 同じシステムから得られた独立な訓練データが nセットあるとする 同じシステムなので、出てくるデータの分散はσ^2である 訓練データの平均も同じくμであるはず。 すると標本平均の分散から、分散はσ^2/n つまり、観測値の平均を取るということは、分散を小さくするということである
・バギング この標本平均の分散の考え方を、モデルに関して考えてみる 複数の訓練データを得る それぞれの訓練データに各々のモデルを当てはめる モデルの出力の平均値を求める すると、全データを使って1つのモデルを作り、出力は平均値をとる よりも 別々のモデルに別々の訓練データを入れて、その出力平均を取った方がいい という考えになる こうすることで分散の小さいモデルが得られる
መ = 1 =1 መ
・バギング ただし、複数の訓練データが得られない場合もある そのため1つの訓練データをブートストラップ法によって重複を許す再標本化を行う こうしてB組の訓練データを作り出す こうして得られたfの平均化モデルが、バギングのモデルである B個のモデルは刈り込みのされてない過学習モデルである このモデルを別データで数千つくり平均化することで、精度が向上する (集合知みたいな) モデル数Bは100から良い性能を示す傾向がある 分類の場合は平均よりも
1モデルは終端ノードの領域で多数決を取る B個のモデルの予測の多数決を取る
・バギング out of bag OOB バギングで得たモデルは交差検証せずとも評価できる方法がある (交差検証のために数百のモデルに当てはめなくともいい) ブートストラップ標本で各木が作られているということは、重複が許されているということである 平均的に1つの木には訓練(観測)データのだいたい2/3が使われている。 残りの訓練(観測)データをOOB観測値という
つまり、 i番目のデータが学習に使われていない木のグループA(i番目のデータがOOB)があるとする グループAの木の個数は1/3*B個ということになる 回帰ならこのグループの出力平均を取る、分類なら多数決をとる こうして得られたOOBによる予測値を実データと比較する 回帰ならOOB平均2乗誤差 分類ならOOB誤分類率 で評価する こうすることで交差検証の計算付加が軽減する (別のデータセットを数百モデルに適応せずとも、一部のOOBを1/3*B個のモデルに当てはめるだけで済む)
・バギング 変数の重要度 複数の木を使うことで解釈性は複雑になる RSSやジニ指数を使うことで重要度を得ることができる ある変数がOOBによって平均的にどれだけRSSが減少するかを確認できる
ランダムフォレスト
・ランダムフォレスト バギングと同じくブートストラップ標本を使って複数の木を作るところまでは同じ 少し改良を加える 決定木を作るときp個の変数からm個の変数をランダムサンプリングする そのうち1つが分割に使われる また次の分割でm個の変数がサンプリングされ といった方法を使う ここで採用するmは多くの場合pの平方根が採用される この方法によって複数の木を作るときに、類似していない木を作ることができる 予測変数のうち有用なものが1つあり、その他はほどほどに有用なとき
すべての変数をつかった場合は有用なものが最初の分割に使われることになる。 こうして複数の木が類似してしまう
・ランダムフォレスト 分割は一部のm個の変数で予測される 平均的に分割点の p-m/p 個は一番有用な変数を含まないことになる 多くの変数に相関がある場合mを小さくとる 木の本数Bを調節する 等の調節を行う
ブースティング
・ブースティング 決定木に対するブースティングを説明する バギングは複数の木をブートストラップ標本から作る ブースティングはブートストラップ標本を用いないで、一つの木を成長させていく 大きく成長させることで過学習が起こる ブースティングは過学習を抑えながら木を成長させる 出力に対してモデルを当てはめ、出力でなく残差に対してさらに決定木をあてはめる 分類のブースティングは多少複雑である
・ブースティング 木の数Bは ブースティングはBが大きすぎると過学習になるので注意。交差検証で Bを決める 縮小パラメタλ は小さな正の値(0.01~0.001) ブースティングの学習速度を調節する λを小さくするならBは大きくする と性能が良くなる 分割数
d は複雑さを調節する たいていd=1を使う 1の時は1つの変数のみを1分割する dはブースティングモデルの交互作用の次数を調整するものである
・ブースティング 訓練データの予測対象yi を ri に格納する 予測のための変数と応答変数を(X,ri)とする f(X)=0として空のモデルを置く b=1 1本目のモデルを立てる d個の分割(終端ノードは
d+1 個)として制限した木 f1をつくる f(X) = f(X) + λ f1 出力の残差を計算し、riに更新する 残差ri = ri – λ f1(Xi) これをb=Bまでくり返す 最終的なモデルはb個の決定木の合計となる = =1
None
None
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}