Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Making Deployments Easy with TF Serving | TF Ev...
Search
Rishit Dagli
May 11, 2021
Programming
200
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Making Deployments Easy with TF Serving | TF Everywhere India
My talk at TensorFlow Everywhere India
Rishit Dagli
May 11, 2021
More Decks by Rishit Dagli
See All by Rishit Dagli
Fantastic Models and Where to Find Them
rishitdagli
0
99
Plant AI: Project Showcase
rishitdagli
0
170
Deploying an ML Model as an API | Postman Student Summit
rishitdagli
0
120
APIs 101 with Postman
rishitdagli
0
140
Deploying Models to production with Azure ML | Scottish Summit
rishitdagli
1
110
Computer Vision with TensorFlow, Getting Started
rishitdagli
0
340
Teaching Your Models to Play Fair | Global AI Student Conf
rishitdagli
1
210
Deploying Models to Production with TF Serving
rishitdagli
1
240
Superpower Your Android apps with ML: Android 11 | Devfest 2020
rishitdagli
1
100
Other Decks in Programming
See All in Programming
初めてのKubernetes 本番運用でハマった話
oku053
0
130
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
990
『コードを書く以外の』エンジニアリング〜課金基盤移行プロジェクト推進のためのTips4選
yuriko1211
0
530
「正の参照」と 「負の導出」で組む ハーネスエンジニアリング
cottpan
1
150
PHPだって関数型したい 〜できること、できないこと〜 / fp-in-php
jsoizo
1
240
AWS CDK を「作」ってみた 〜フルスクラッチで見えた CDK の裏側〜 / aws-cdk-from-scratch
gotok365
3
480
PHP に部分適用が来るぞ!……ところで何それ?おいしいの? #phpcon / phpcon-2026
shogogg
0
320
ローカルLLMでどこまでコードが書けるか -縮小版 / How much code can be written on a local LLM Shortened
kishida
2
200
AIが無かった頃の素敵な出会いの話
codmoninc
1
160
Go言語とトイモデルで学ぶTransformerの気持ち / fukuokago23-transformer
monochromegane
0
140
PHP初心者セッション2026 〜生成AIでは見えない裏側を知る:今だからLAMPを通して仕組みを学ぶ〜
kashioka
0
620
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
360k
Featured
See All Featured
How STYLIGHT went responsive
nonsquared
100
6.2k
HDC tutorial
michielstock
2
750
sira's awesome portfolio website redesign presentation
elsirapls
0
300
Music & Morning Musume
bryan
47
7.3k
30 Presentation Tips
portentint
PRO
1
350
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
300
Typedesign – Prime Four
hannesfritz
42
3.1k
First, design no harm
axbom
PRO
2
1.2k
Git: the NoSQL Database
bkeepers
PRO
432
67k
Deep Space Network (abreviated)
tonyrice
0
230
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
Transcript
Making Deployments Easy with TF Serving Rishit Dagli High School
TEDx, TED-Ed Speaker rishit_dagli Rishit-dagli
“Most models don’t get deployed.”
of models don’t get deployed. 90%
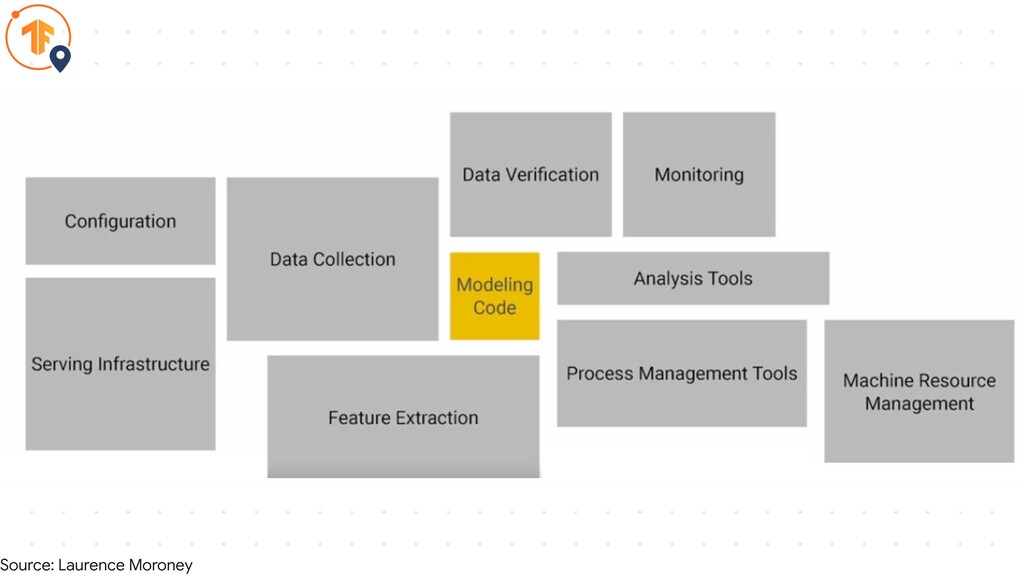
Source: Laurence Moroney
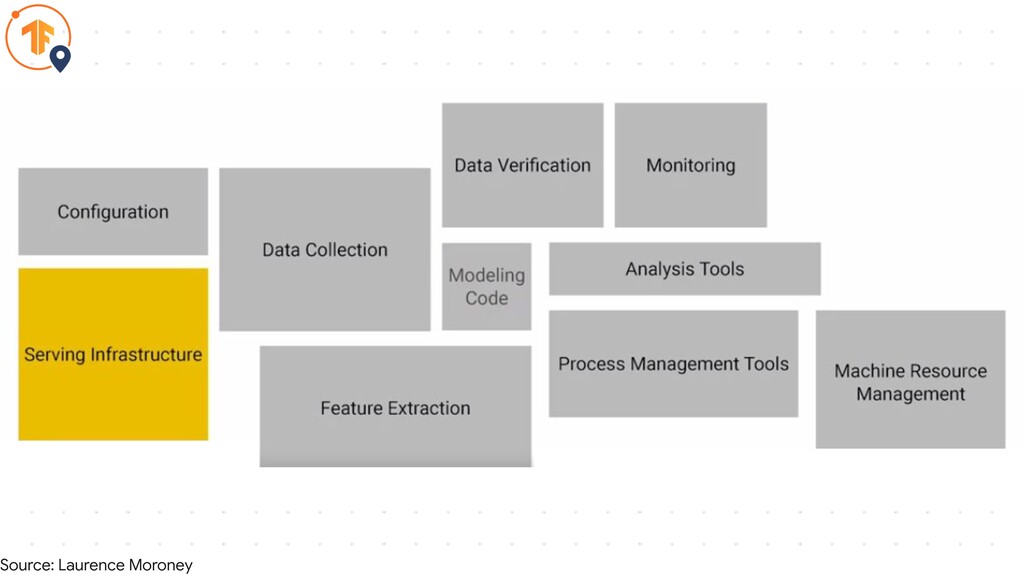
Source: Laurence Moroney
• High School Student • TEDx and Ted-Ed Speaker •
♡ Hackathons and competitions • ♡ Research • My coordinates - www.rishit.tech $whoami rishit_dagli Rishit-dagli
• Devs who have worked on Deep Learning Models (Keras)
• Devs looking for ways to put their model into production ready manner Ideal Audience
Why care about ML deployments? Source: memegenerator.net
None
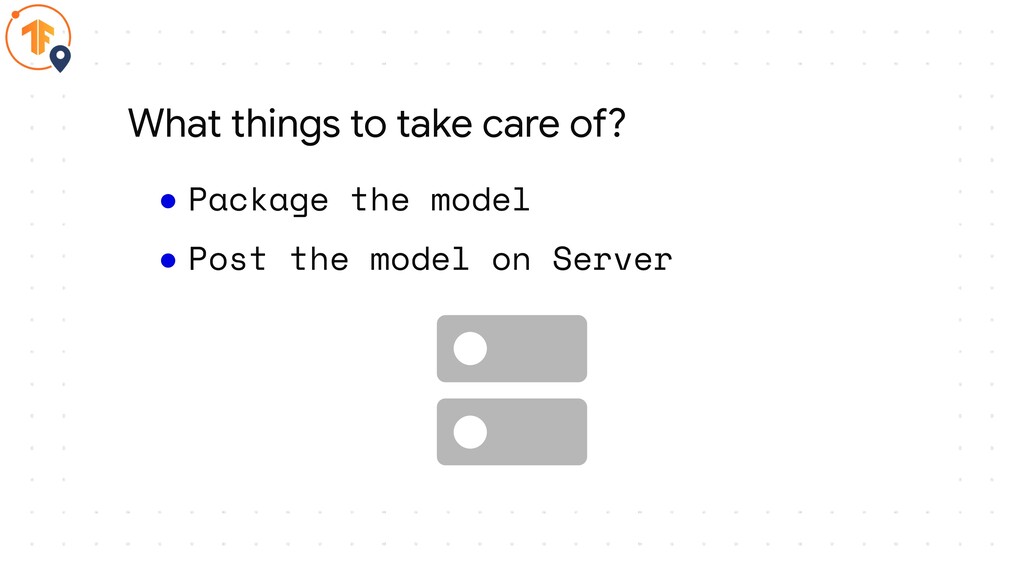
• Package the model What things to take care of?
• Package the model • Post the model on Server
What things to take care of?
• Package the model • Post the model on Server
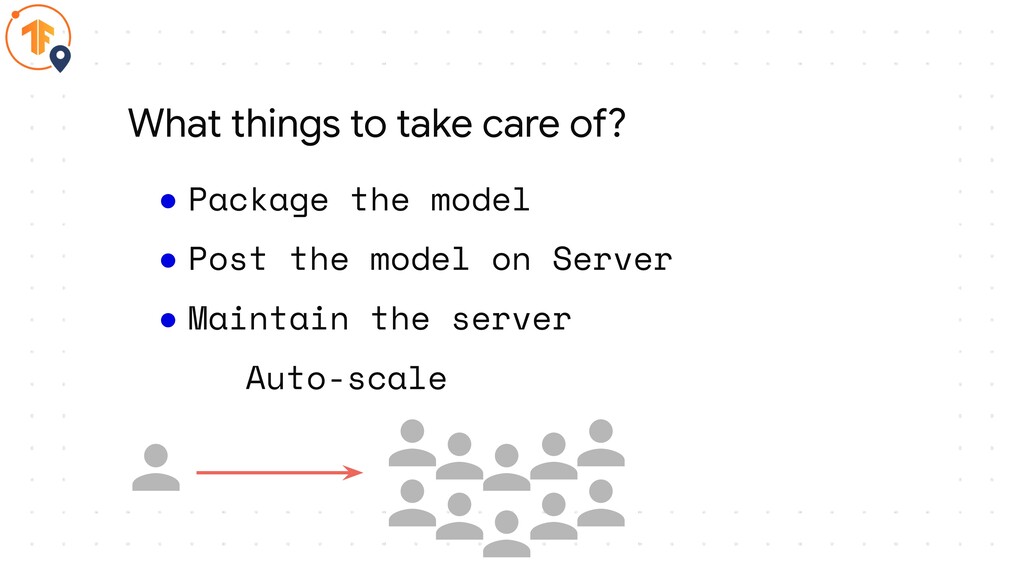
• Maintain the server What things to take care of?
• Package the model • Post the model on Server
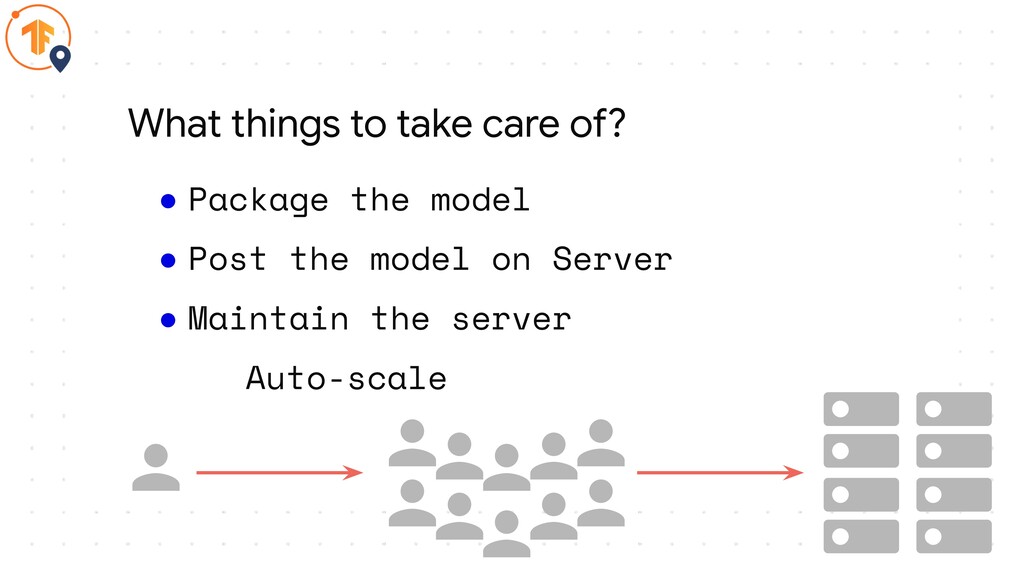
• Maintain the server Auto-scale What things to take care of?
• Package the model • Post the model on Server
• Maintain the server Auto-scale What things to take care of?
• Package the model • Post the model on Server
• Maintain the server Auto-scale Global availability What things to take care of?
• Package the model • Post the model on Server
• Maintain the server Auto-scale Global availability Latency What things to take care of?
• Package the model • Post the model on Server
• Maintain the server • API What things to take care of?
• Package the model • Post the model on Server
• Maintain the server • API • Model Versioning What things to take care of?
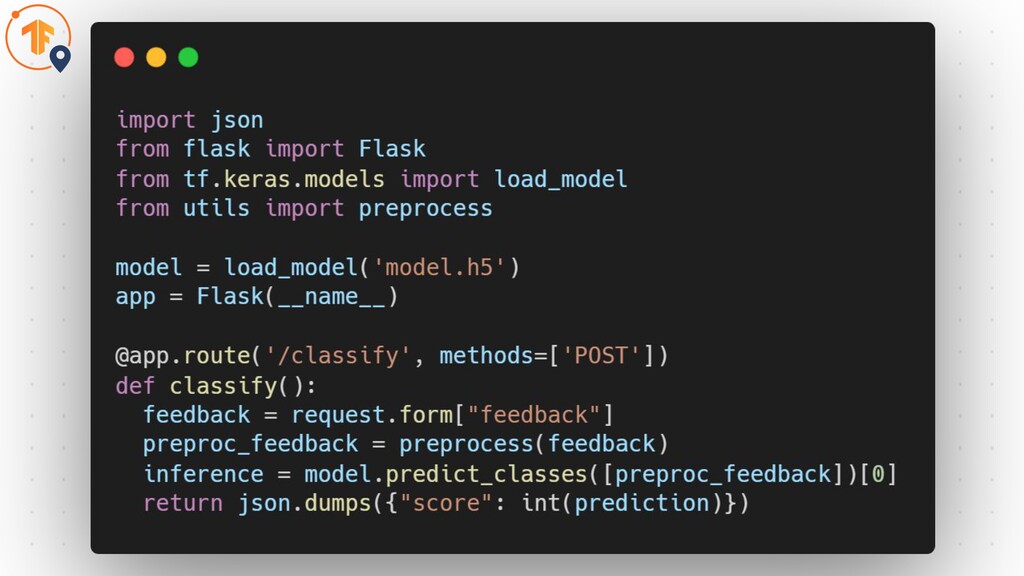
Simple Deployments Why are they inefficient?
None
Simple Deployments Why are they inefficient? • No consistent API
• No model versioning • No mini-batching • Inefficient for large models Source: Hannes Hapke
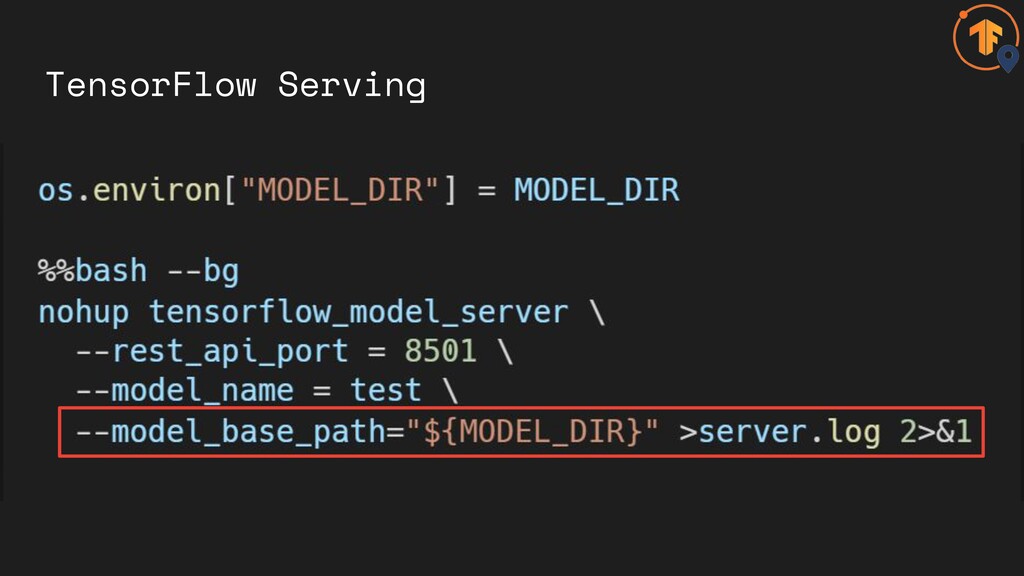
TensorFlow Serving
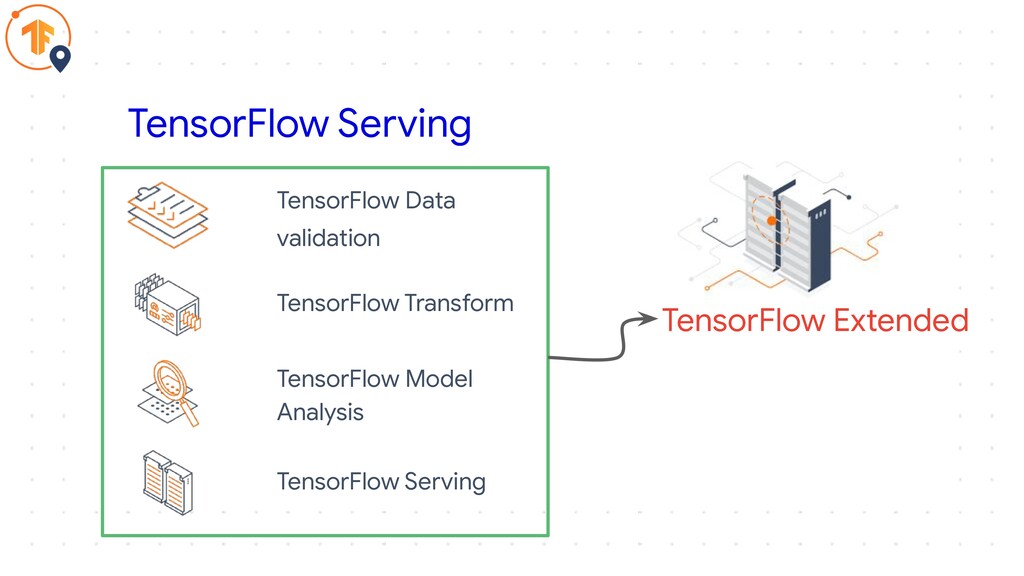
TensorFlow Serving TensorFlow Data validation TensorFlow Transform TensorFlow Model Analysis
TensorFlow Serving TensorFlow Extended
• Part of TensorFlow Extended TensorFlow Serving
• Part of TensorFlow Extended • Used Internally at Google
TensorFlow Serving
• Part of TensorFlow Extended • Used Internally at Google
• Makes deployment a lot easier TensorFlow Serving
The Process
• The SavedModel format • Graph definitions as protocol buffer
Export Model
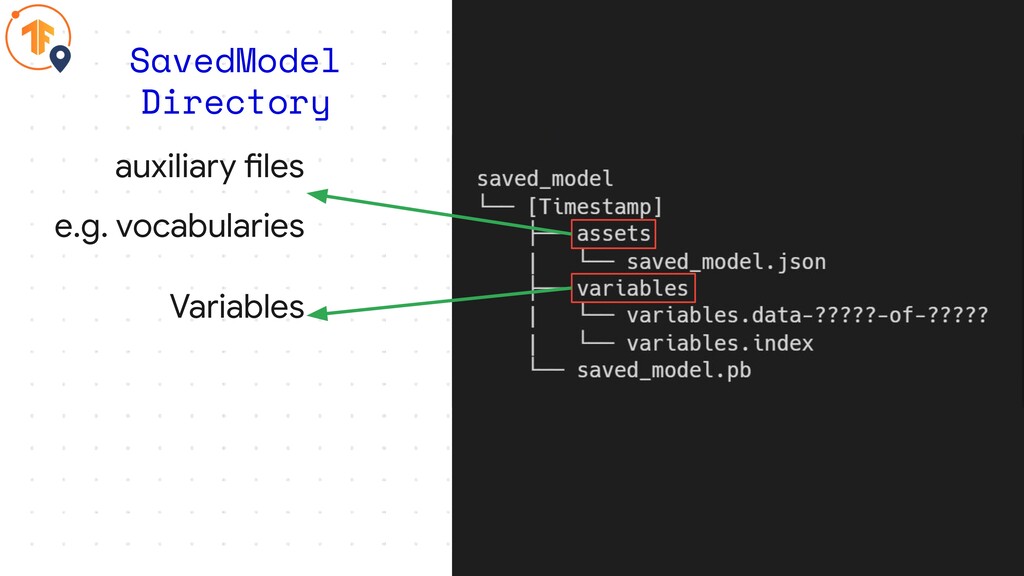
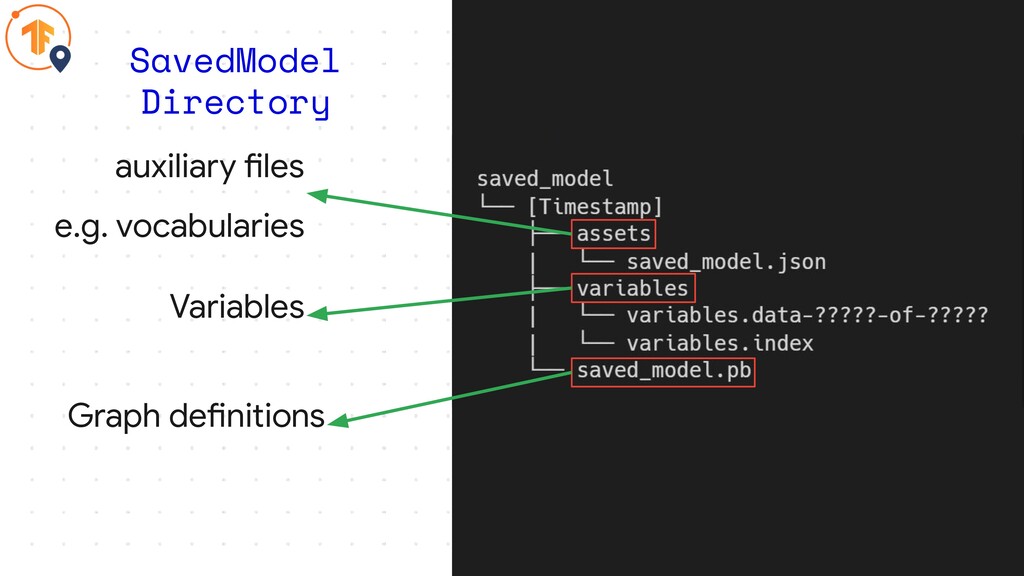
SavedModel Directory
auxiliary files e.g. vocabularies SavedModel Directory
auxiliary files e.g. vocabularies SavedModel Directory Variables
auxiliary files e.g. vocabularies SavedModel Directory Variables Graph definitions
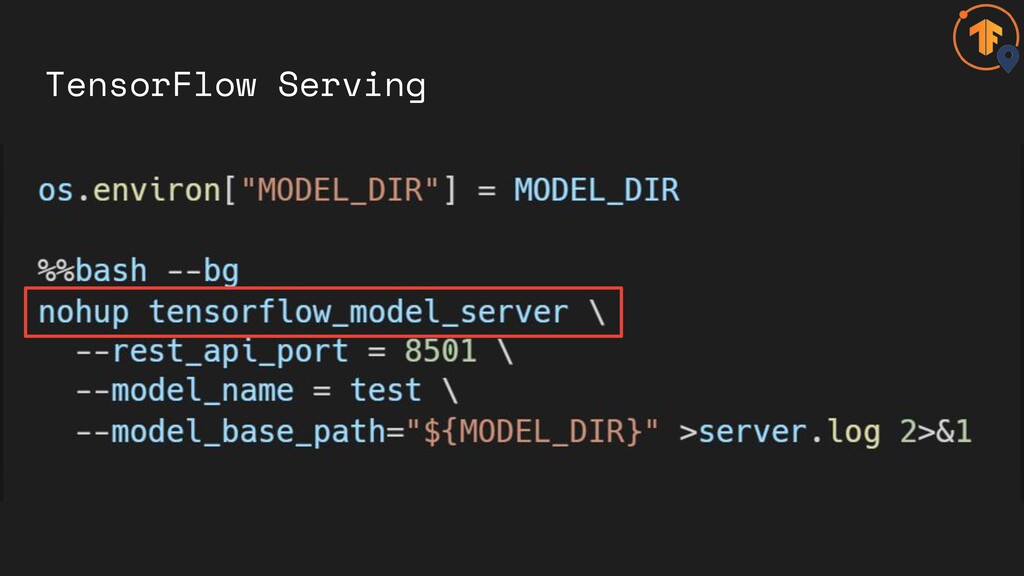
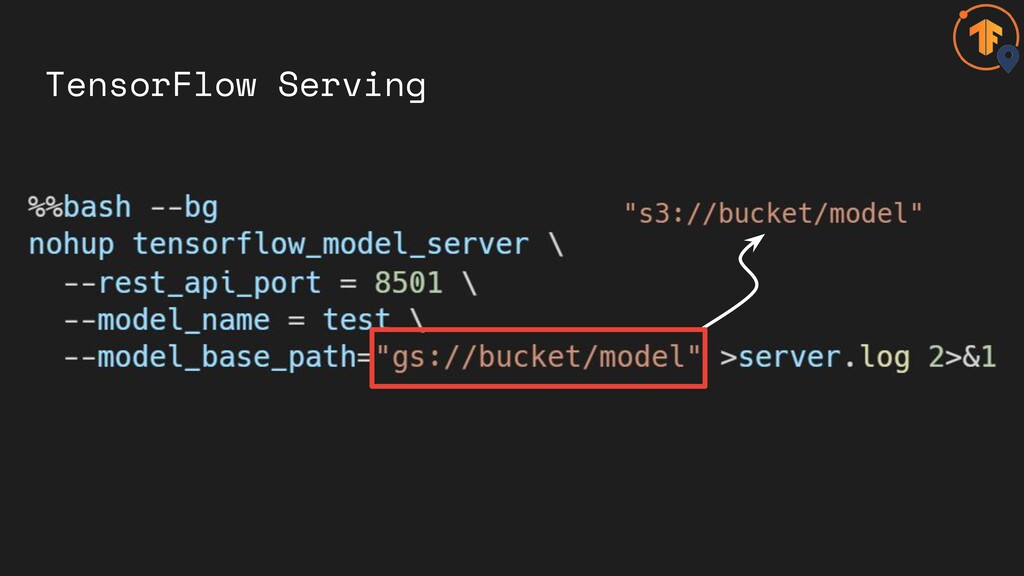
TensorFlow Serving
TensorFlow Serving
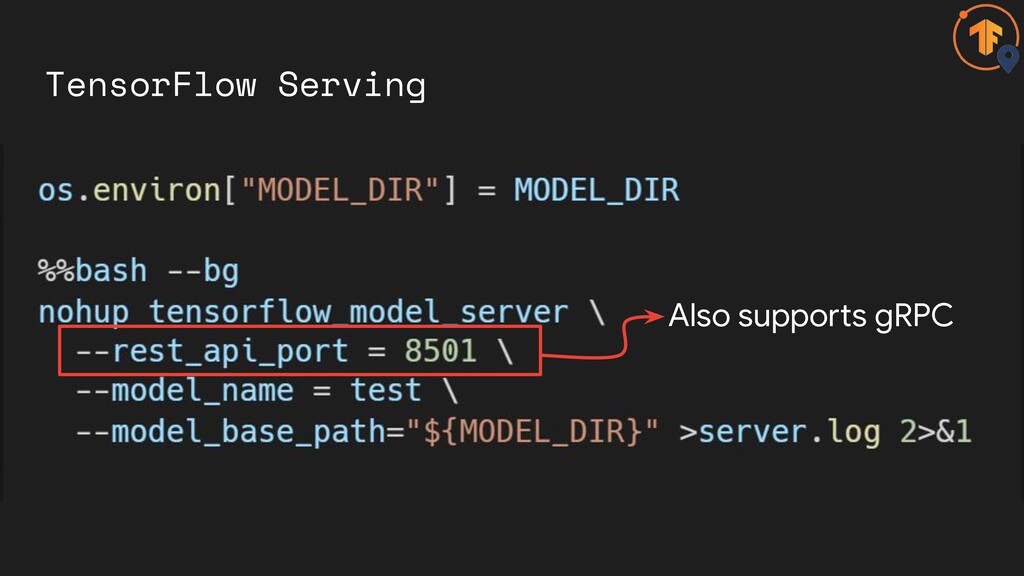
TensorFlow Serving Also supports gRPC
TensorFlow Serving
TensorFlow Serving
TensorFlow Serving
TensorFlow Serving
Inference
• Consistent APIs • Supports simultaneously gRPC: 8500 REST: 8501
• No lists but lists of lists Inference
• No lists but lists of lists Inference
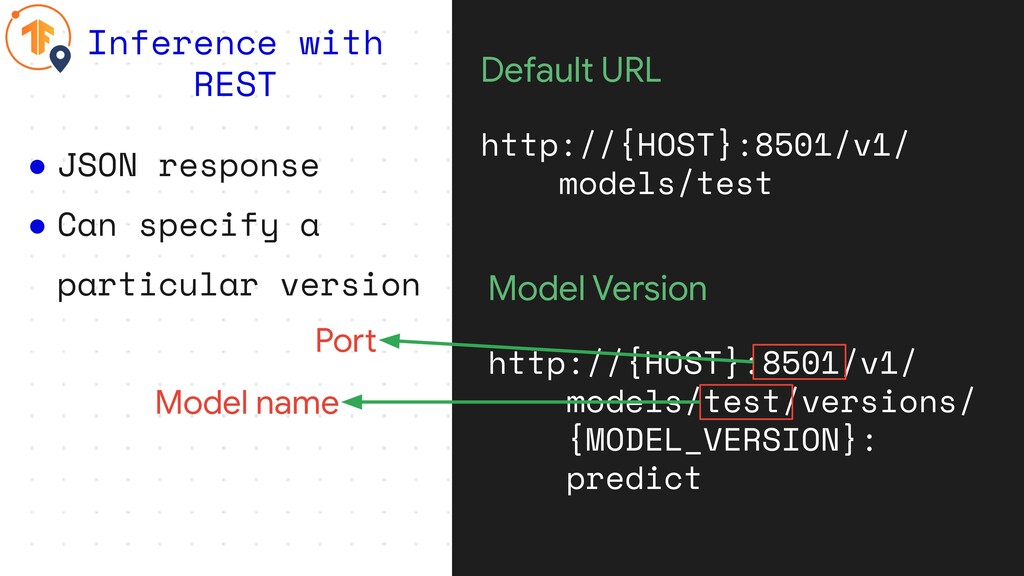
• JSON response • Can specify a particular version Inference
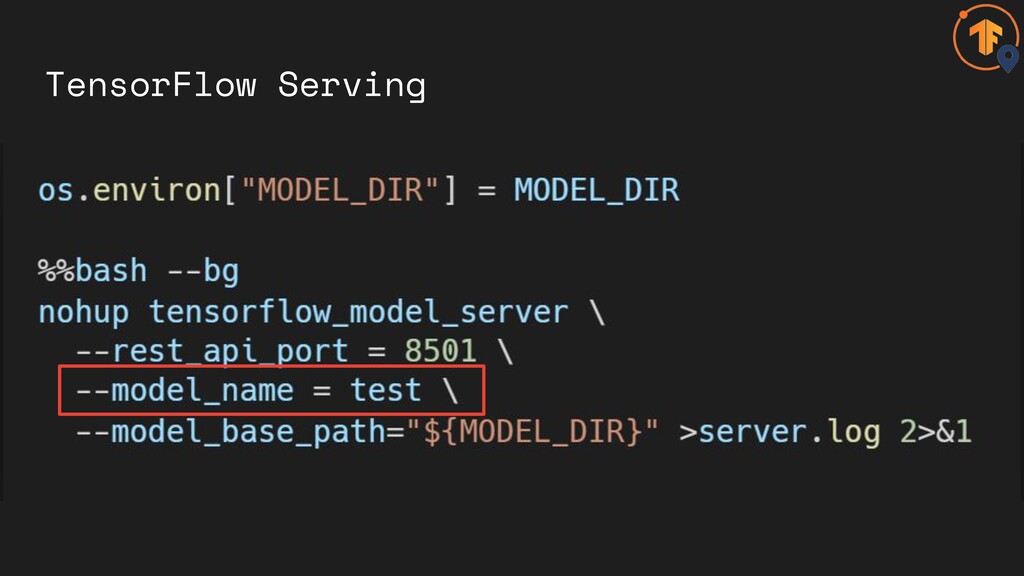
with REST Default URL http://{HOST}:8501/v1/ models/test Model Version http://{HOST}:8501/v1/ models/test/versions/ {MODEL_VERSION}: predict
• JSON response • Can specify a particular version Inference
with REST Default URL http://{HOST}:8501/v1/ models/test Model Version http://{HOST}:8501/v1/ models/test/versions/ {MODEL_VERSION}: predict Port Model name
Inference with REST
• Better connections • Data converted to protocol buffer •
Request types have designated type • Payload converted to base64 • Use gRPC stubs Inference with gRPC
Model Meta Information
• You have an API to get meta info •
Useful for model tracking in telementry systems • Provides model input/ outputs, signatures Model Meta Information
Model Meta Information http://{HOST}:8501/ v1/models/{MODEL_NAME} /versions/{MODEL_VERSION} /metadata
Batch Inferences
• Use hardware efficiently • Save costs and compute resources
• Take multiple requests process them together • Super cool😎 for large models Batch inferences
• max_batch_size • batch_timeout_micros • num_batch_threads • max_enqueued_batches • file_system_poll_wait
_seconds • tensorflow_session _paralellism • tensorflow_intra_op _parallelism Batch Inference Highly customizable
• Load configuration file on startup • Change parameters according
to use cases Batch Inference
Also take a look at...
• Kubeflow deployments • Data pre-processing on server🚅 • AI
Platform Predictions • Deployment on edge devices • Federated learning Also take a look at...
bit.ly/tf-everywhere-ind Demos!
bit.ly/serving-deck Slides
Thank You rishit_dagli Rishit-dagli
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}