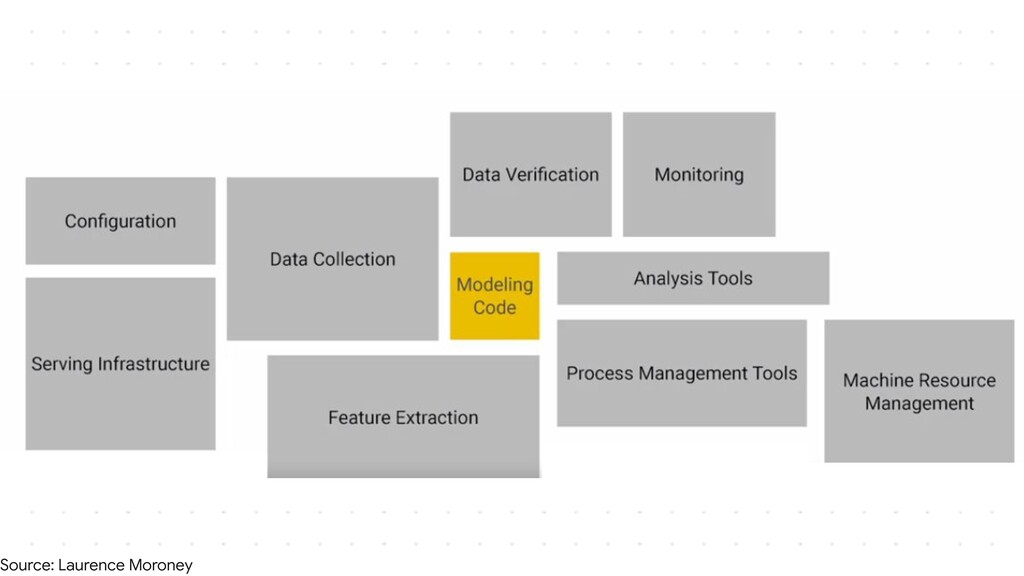
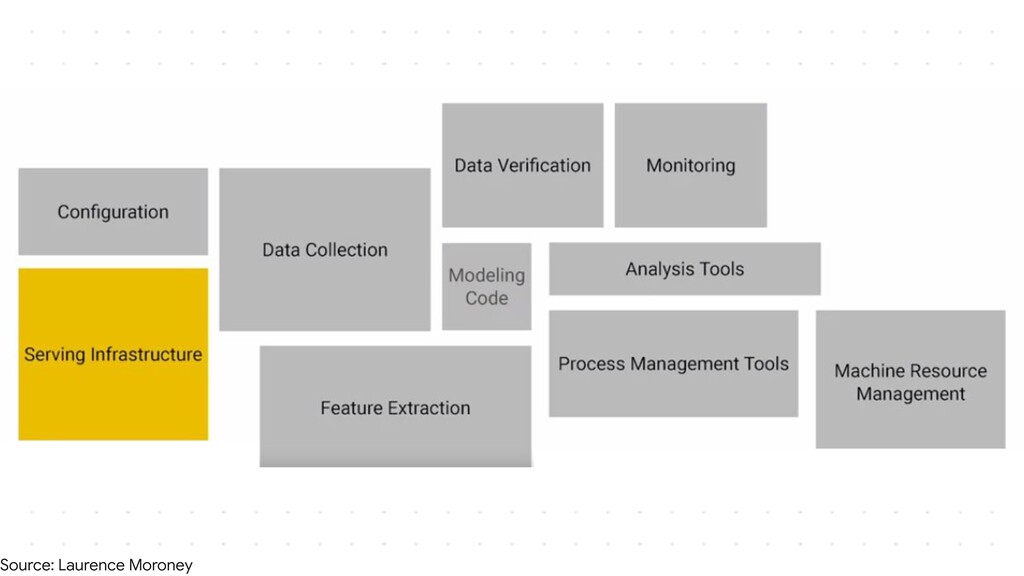
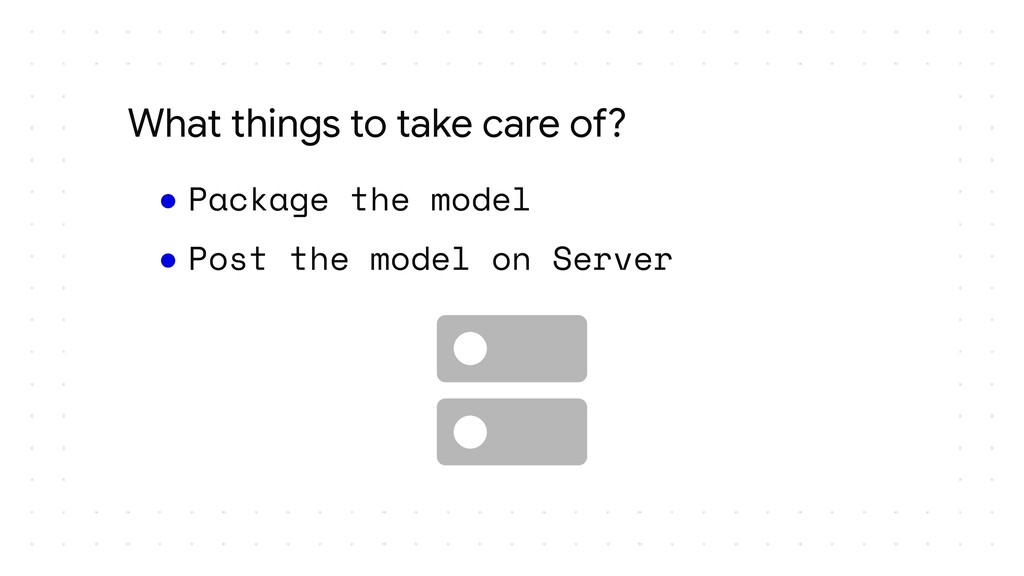
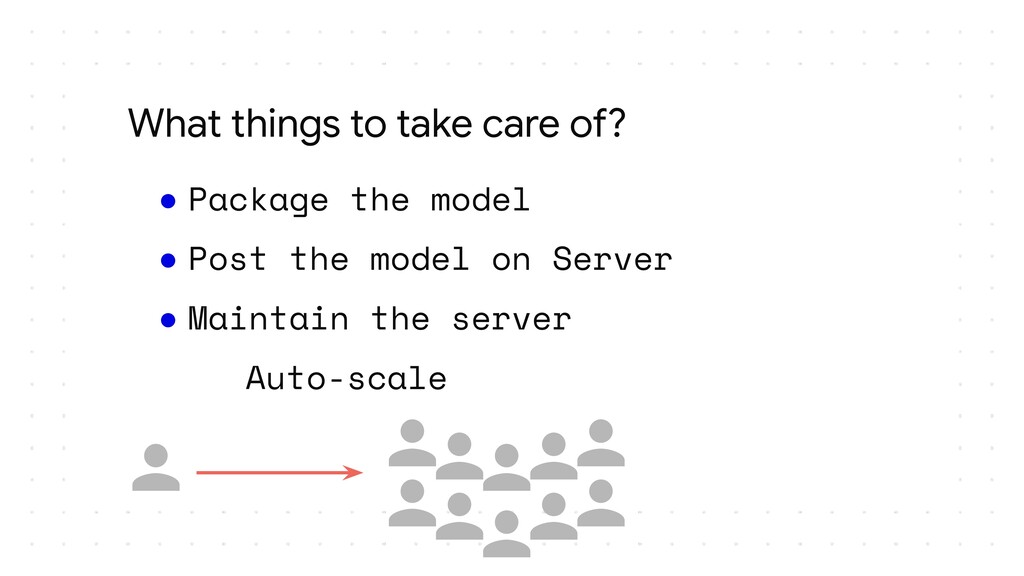
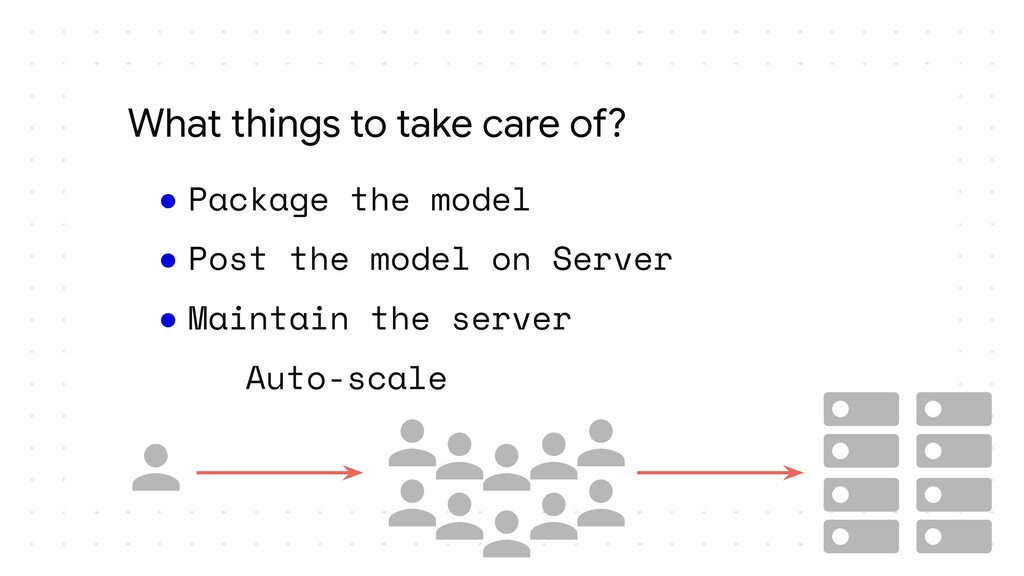
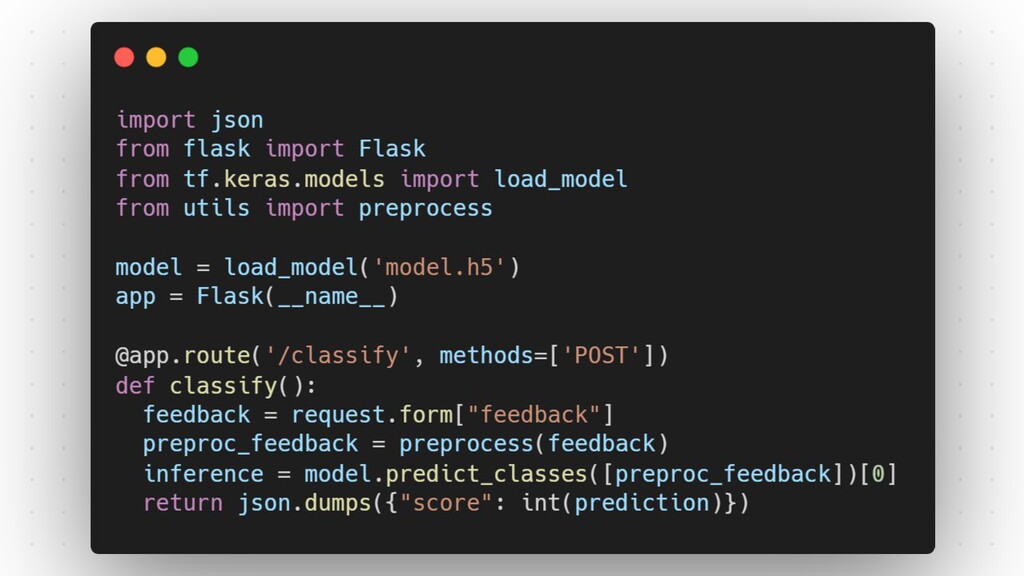
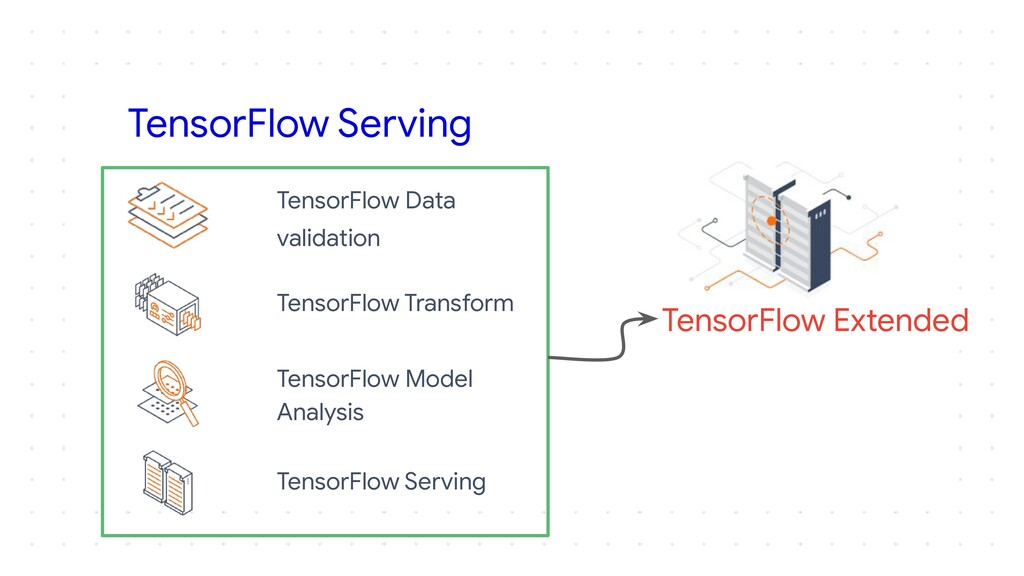
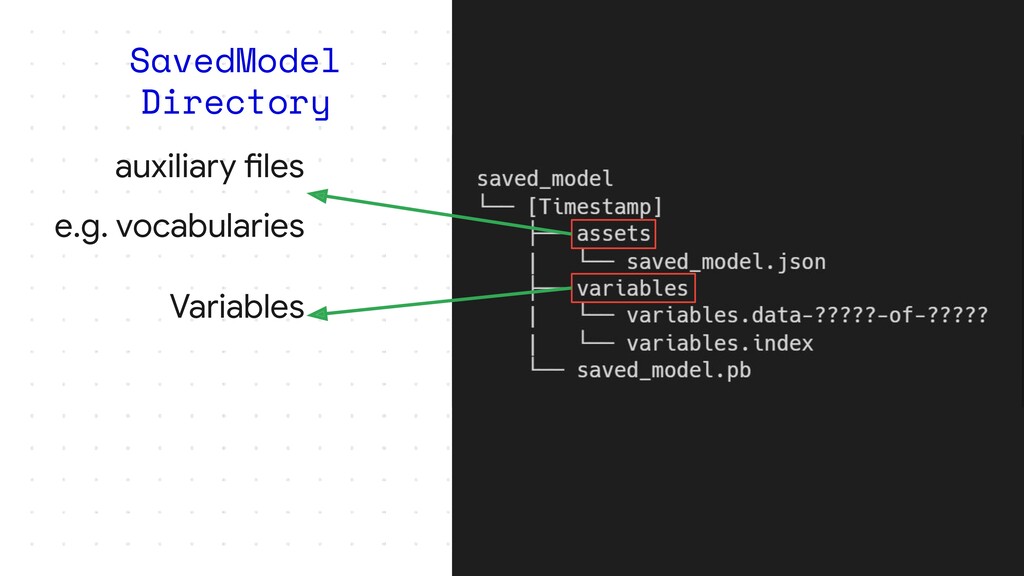
I plan to make it an intermediate level talk and would just expect the audience to know how they can make their own models with TensorFlow or Keras and take it forward from there and show how they can serve their models over HTTP and HTTPS. I would show how we can essentially follow the main steps of putting a model into production, package it and make it ready for deployment, upload it somewhere in the cloud, make an API and most importantly have no downtime while you are updating the model and doing version numbering efficiently. I plan to cover all these which are the steps required to deploy a model in the wild and how TensorFlow simplifies them for a developer. I would then also show how applications could access the model maybe through web or cloud calls. If time permits I could also show how one could make this deployment to auto scale using GCP Cloud functions and/or Kubernetes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}