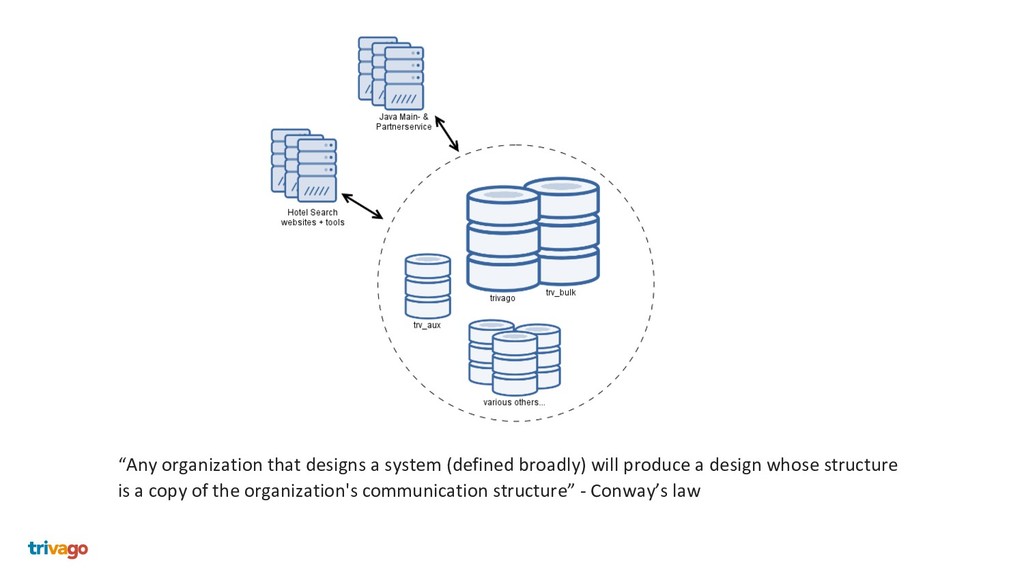
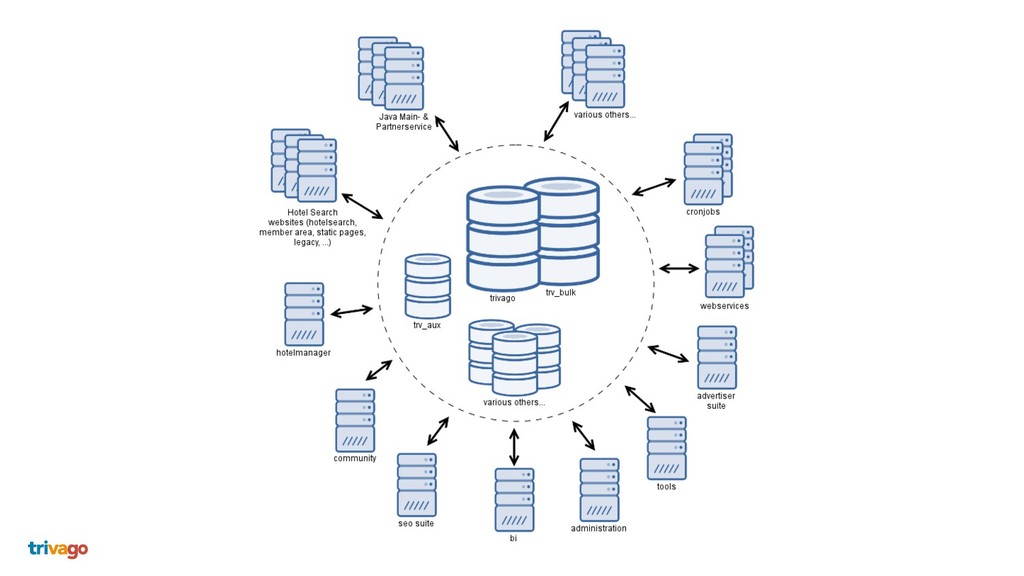
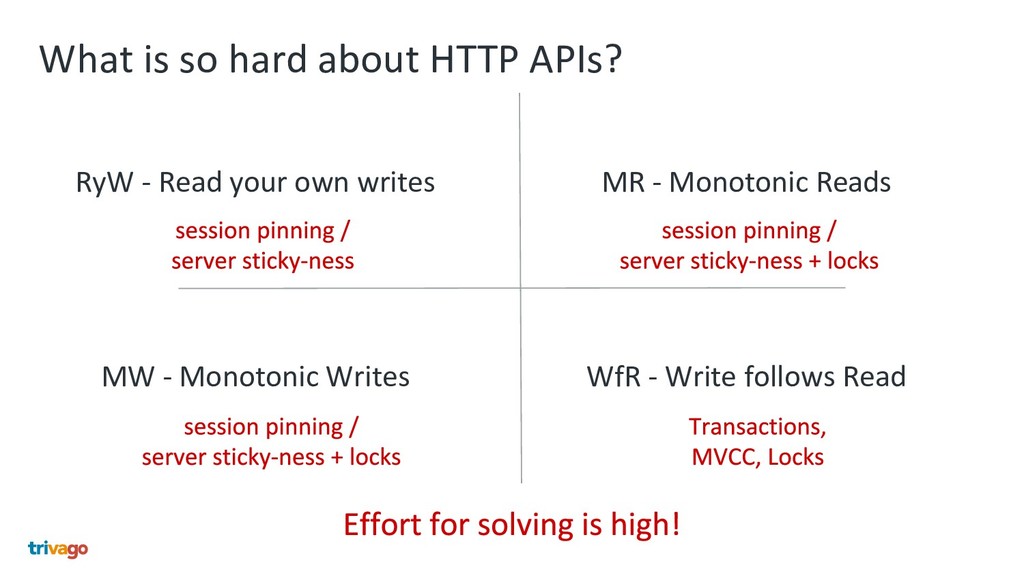
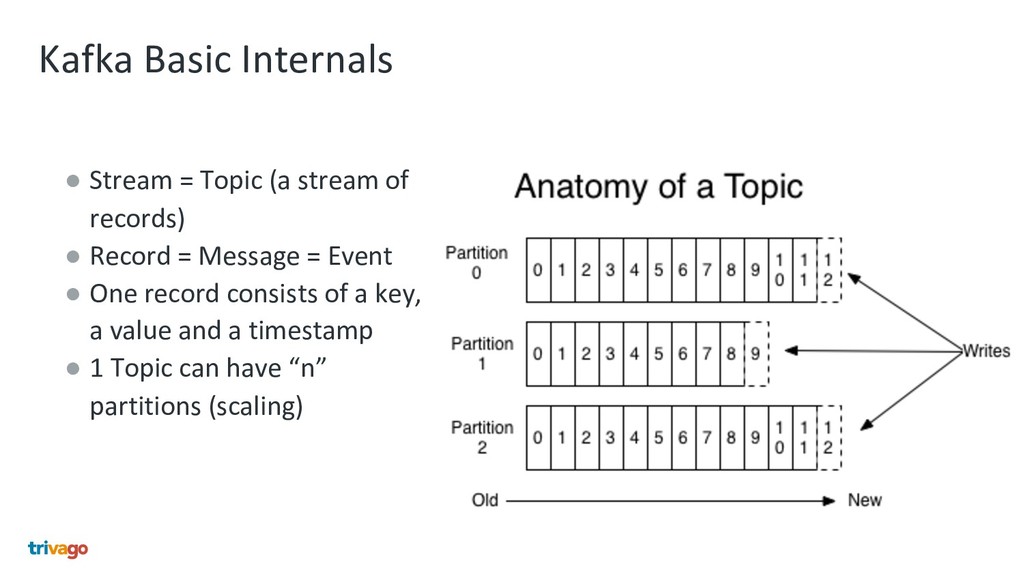
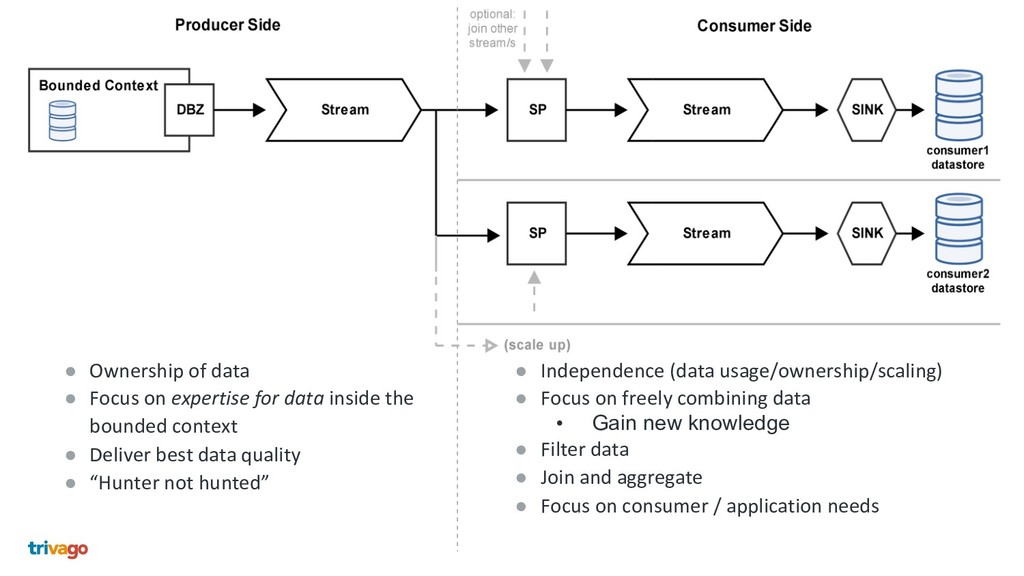
Nowadays everyone solves the separation and modularisation of big monolithic legacy applications and databases with HTTP microservices. We at trivago take another approach using Apache Kafka, Debezium and Stream processing. This talk shows how we do this and why we are convinced, that this is a better way to enhance your architecture, why this exceeds HTTP microservices and is more then 1 million times faster.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
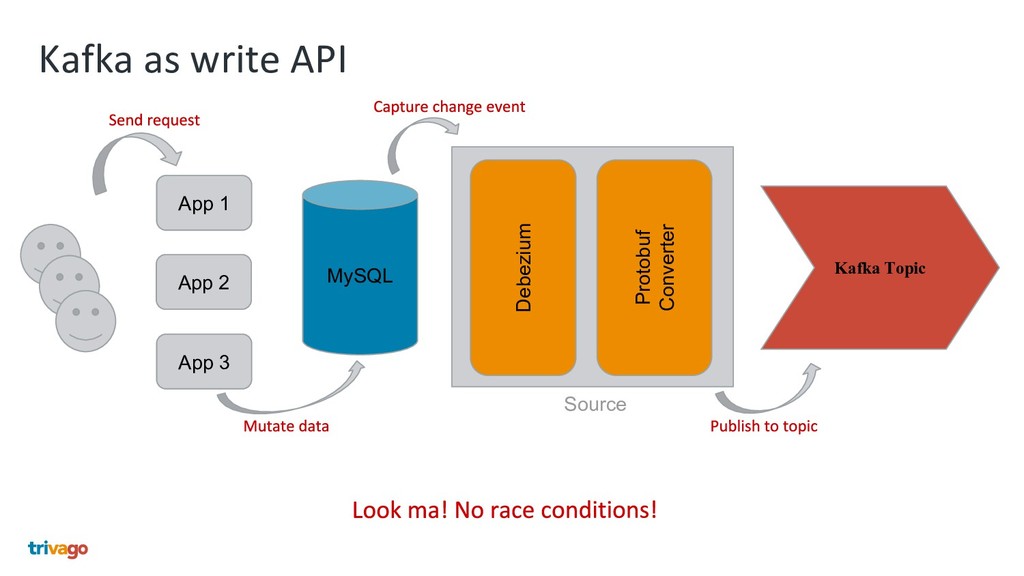{kind=link}
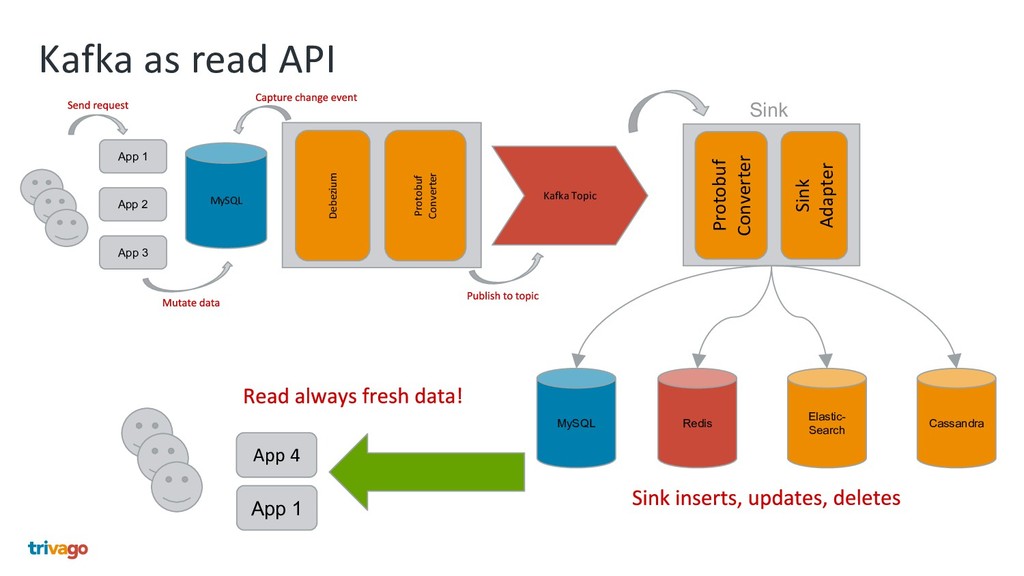{kind=link}
{kind=link}
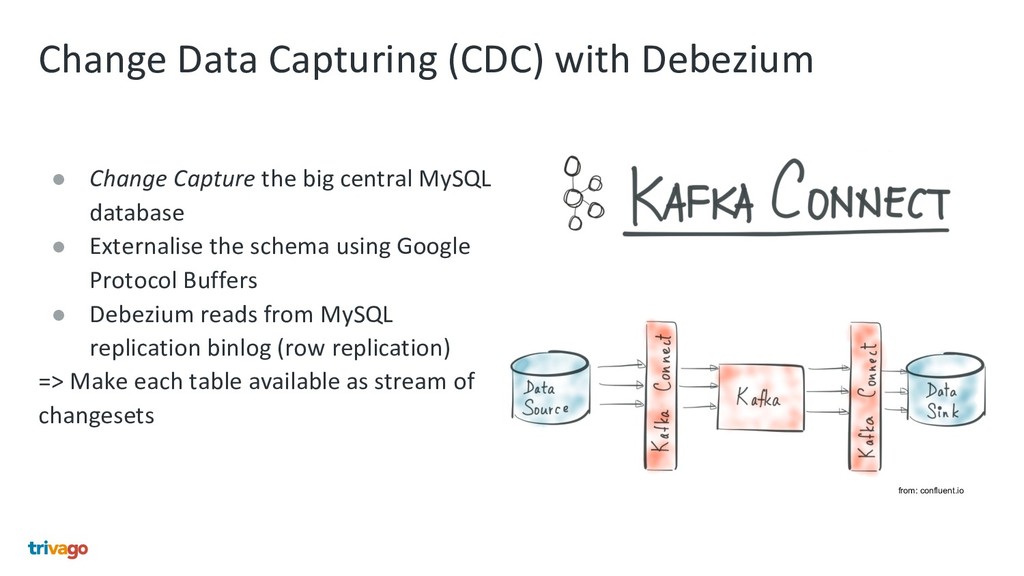{kind=link}
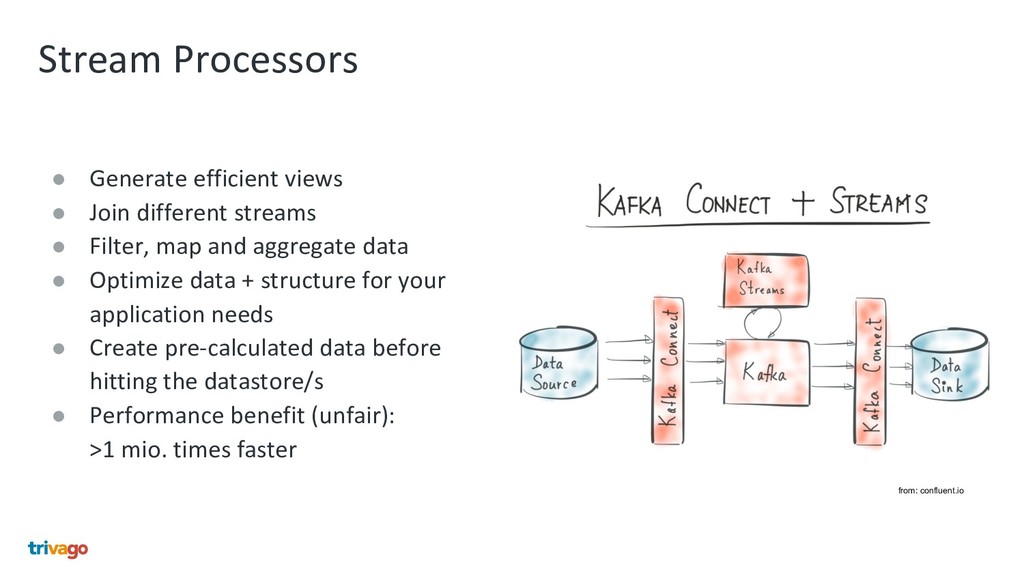{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}