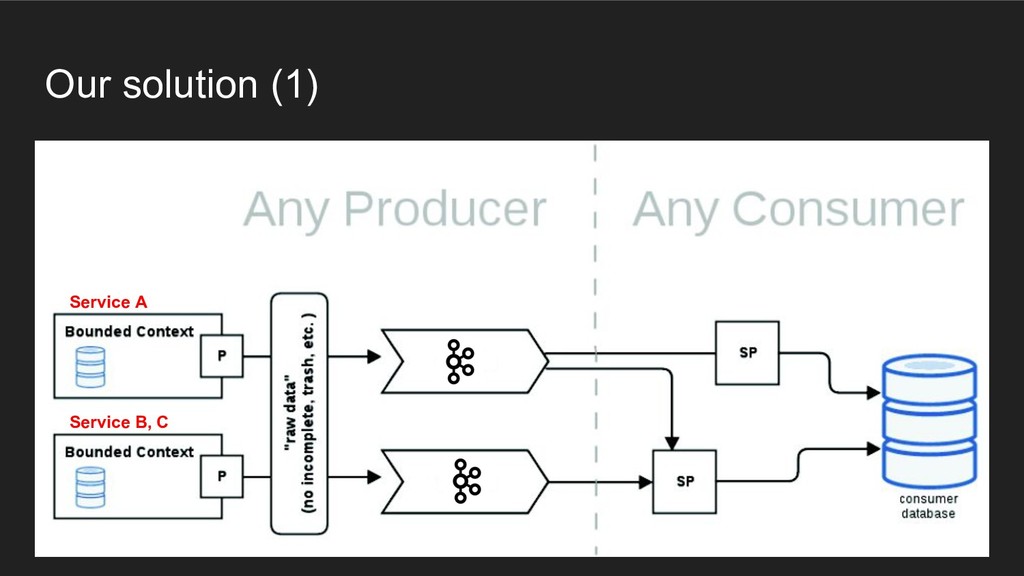
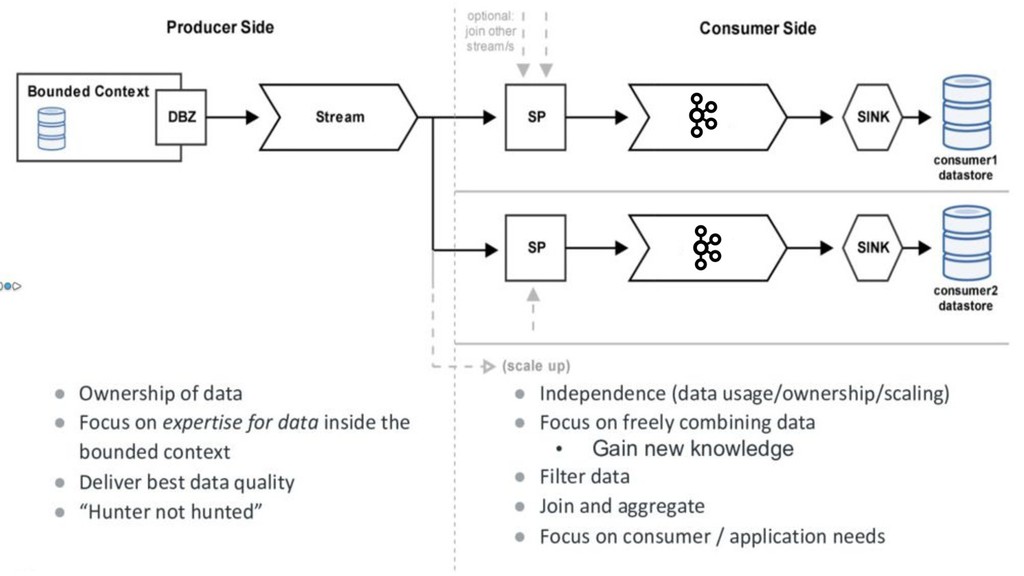
Heutzutage löst man die Aufteilung und Modularisation von großen monolithischen "Legacy"-Applikationen und Datenbanken mit HTTP Microservices. Trivago ist einen anderen Weg gegangen und nutzt Apache Kafka, Debezium und Stream Processing. Sie haben sich schon vor dem Release von Symfony 2.0.0, im Januar 2012, für die Nutzung von Symfony2 entschieden und ihre PHP-Applikationen basieren seitdem auf Symfony.
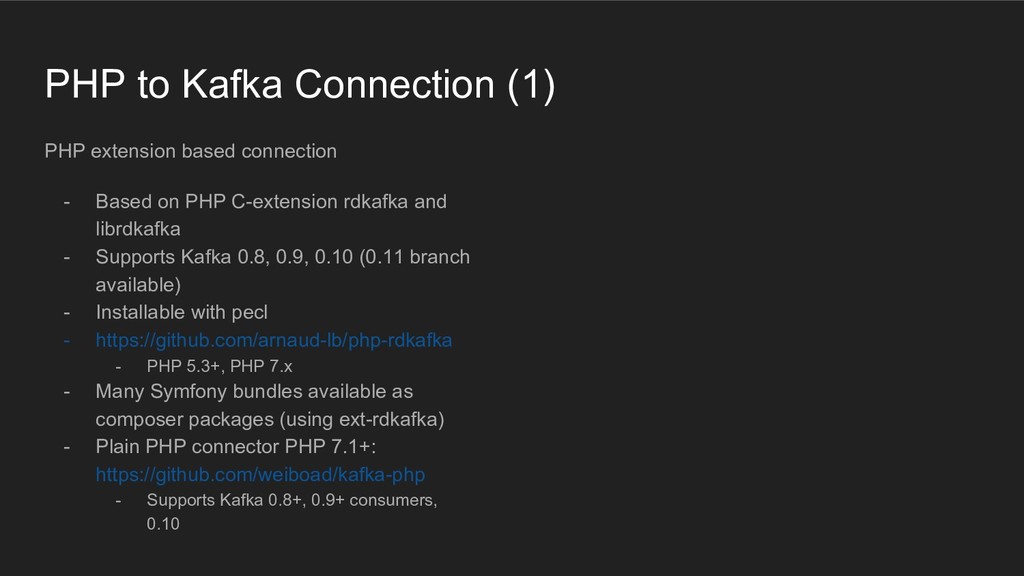
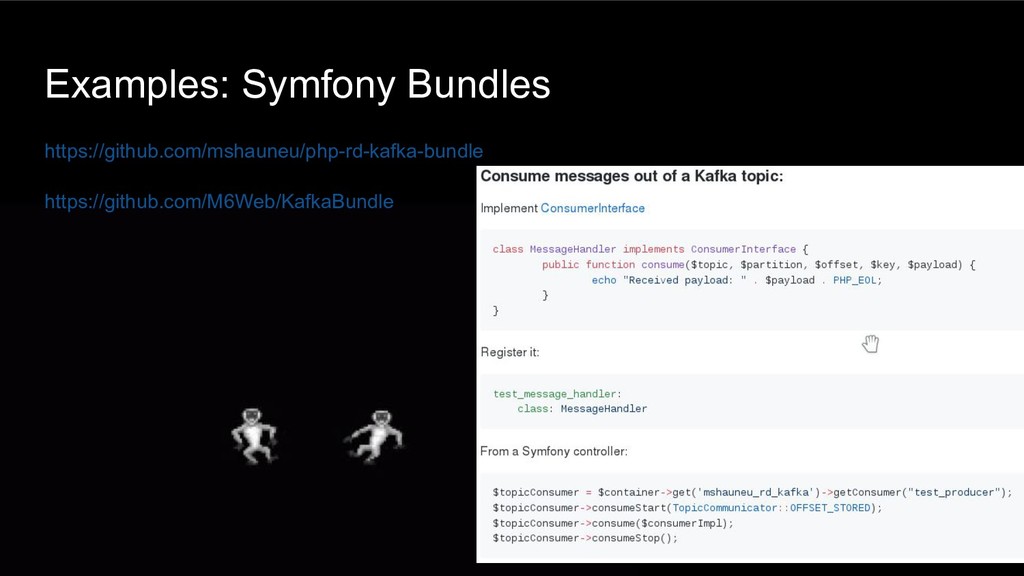
Der Talk zeigt, wie eine Stream-Architektur aufgebaut ist und wie man performant mit PHP und Symfony Google Protocol Buffer Nachrichten erzeugt und in einen Kafka Stream schreibt. Außerdem wird gezeigt, warum Trivago so von Streaming-Architekturen überzeugt ist und warum dieser Weg 1 Million mal schneller ist als HTTP Microservices.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
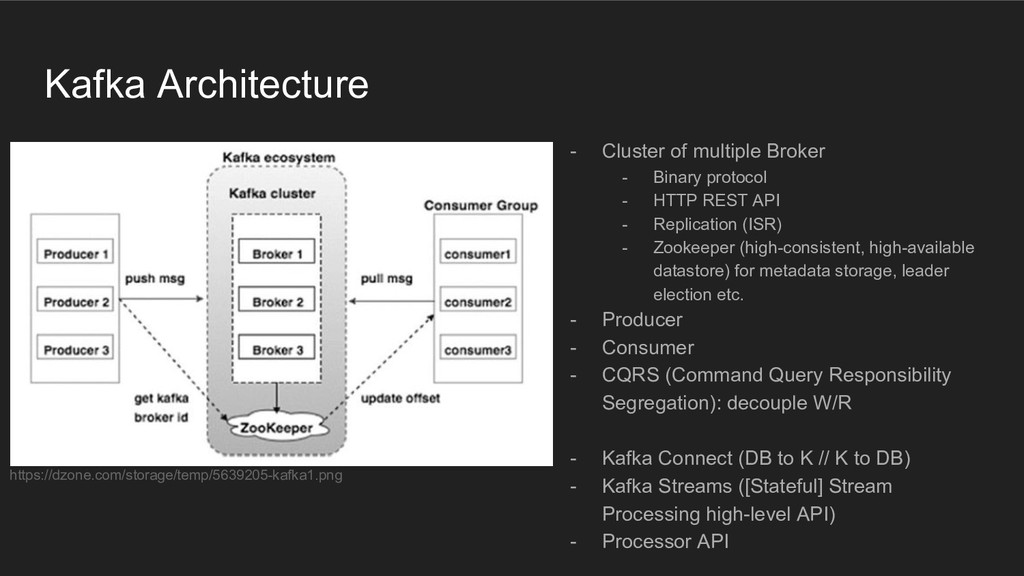{kind=link}
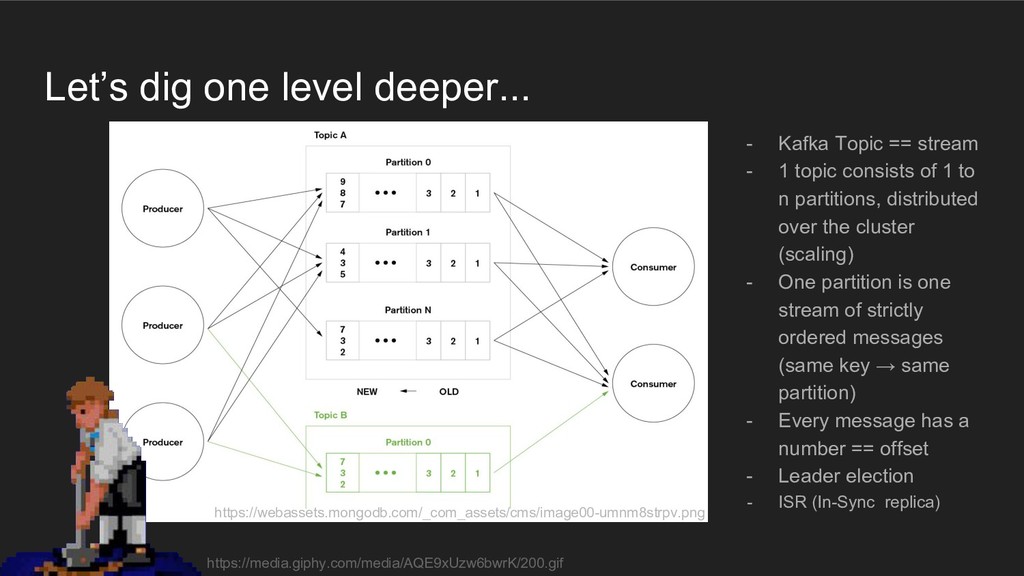{kind=link}
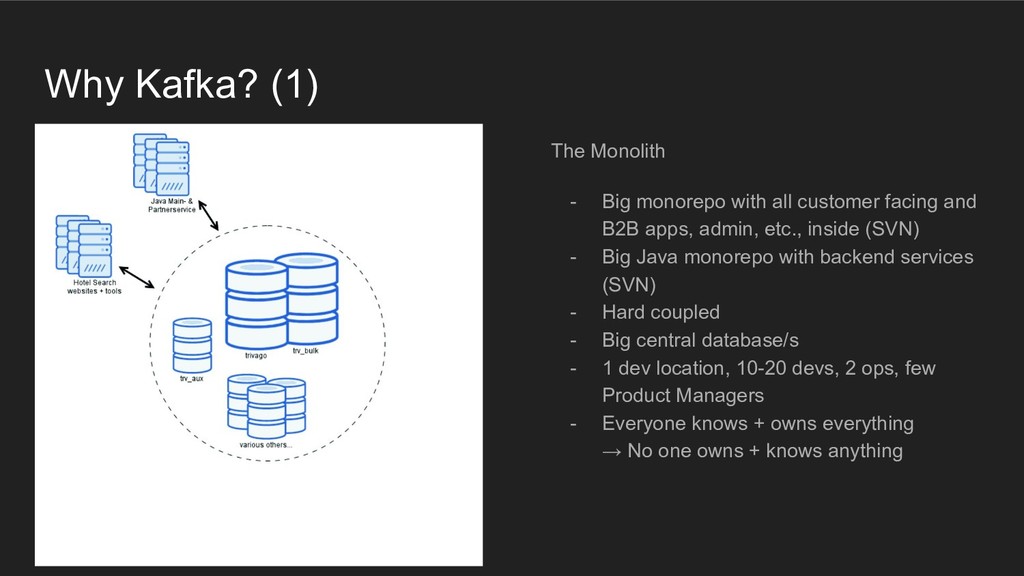{kind=link}
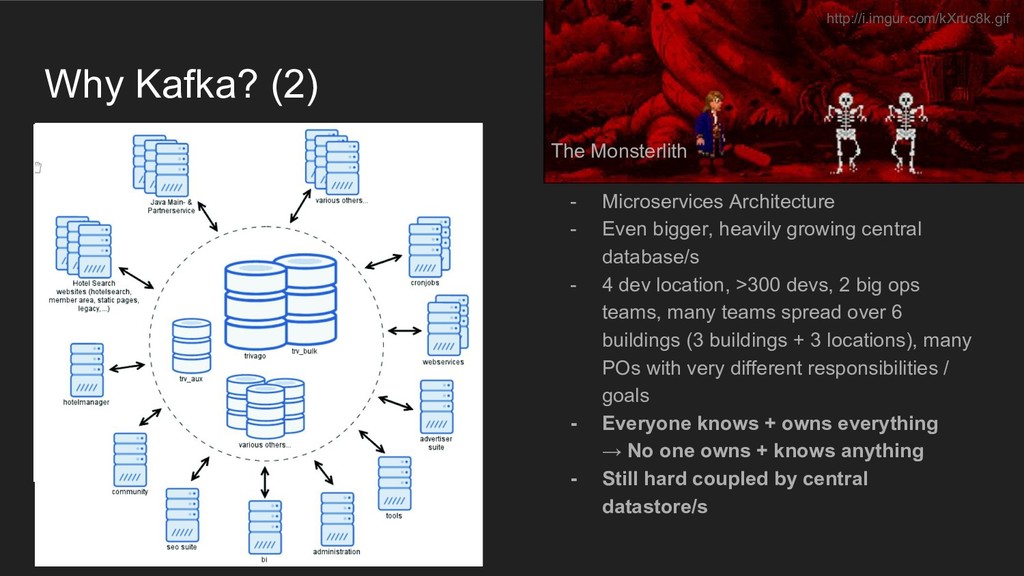{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}