■ イベント
渋谷 Biz × AI: ビジネスにおける AI 利活用 事例勉強会 第3回
https://cyberagent.connpass.com/event/367576/
■ 発表者
技術本部 研究開発部 Data Analysisグループ
齋藤 慎一朗
■ 研究開発部 採用情報
https://media.sansan-engineering.com/randd
■ Sansan Tech Blog
https://buildersbox.corp-sansan.com/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
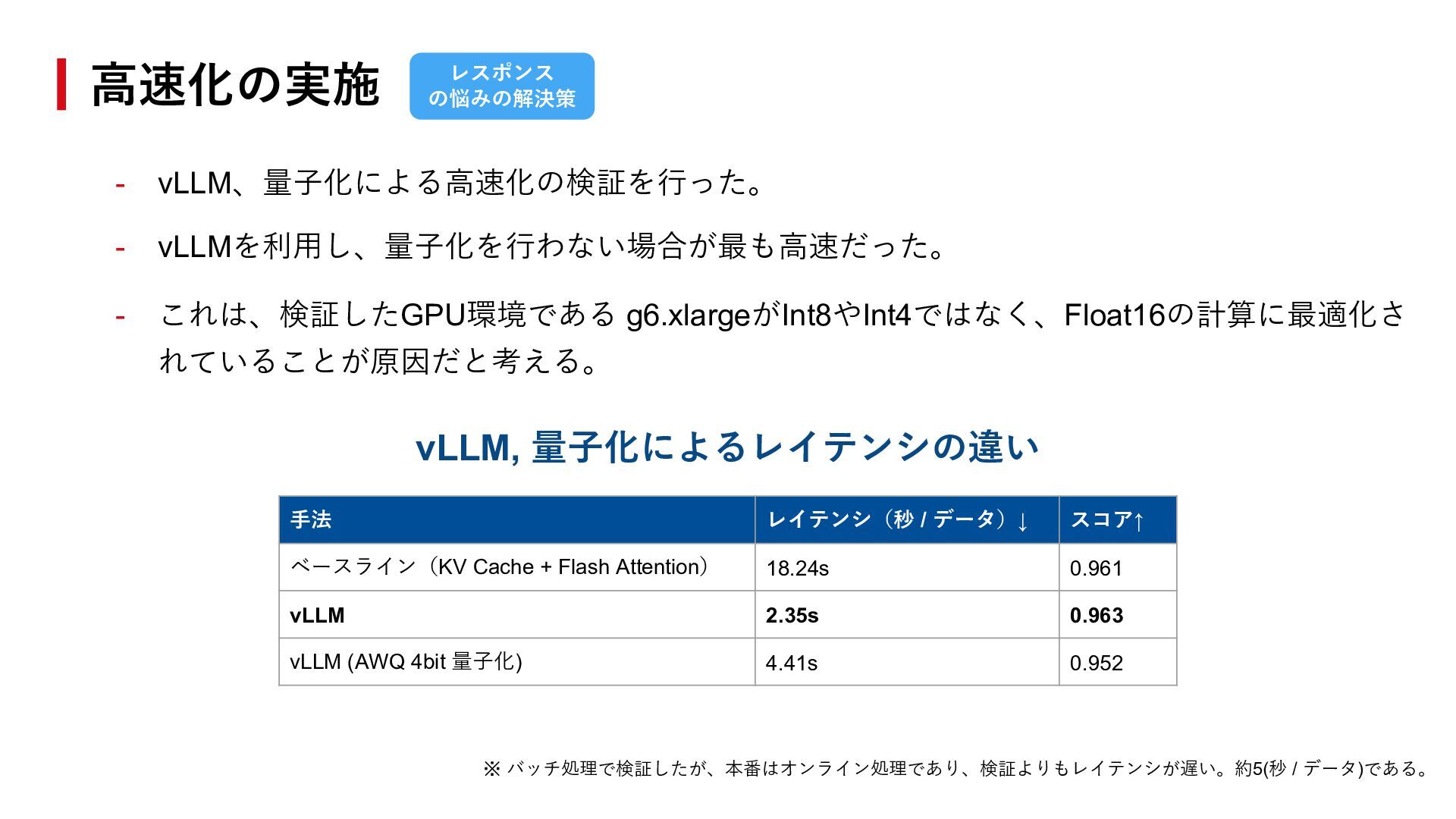{kind=link}
{kind=link}
{kind=link}
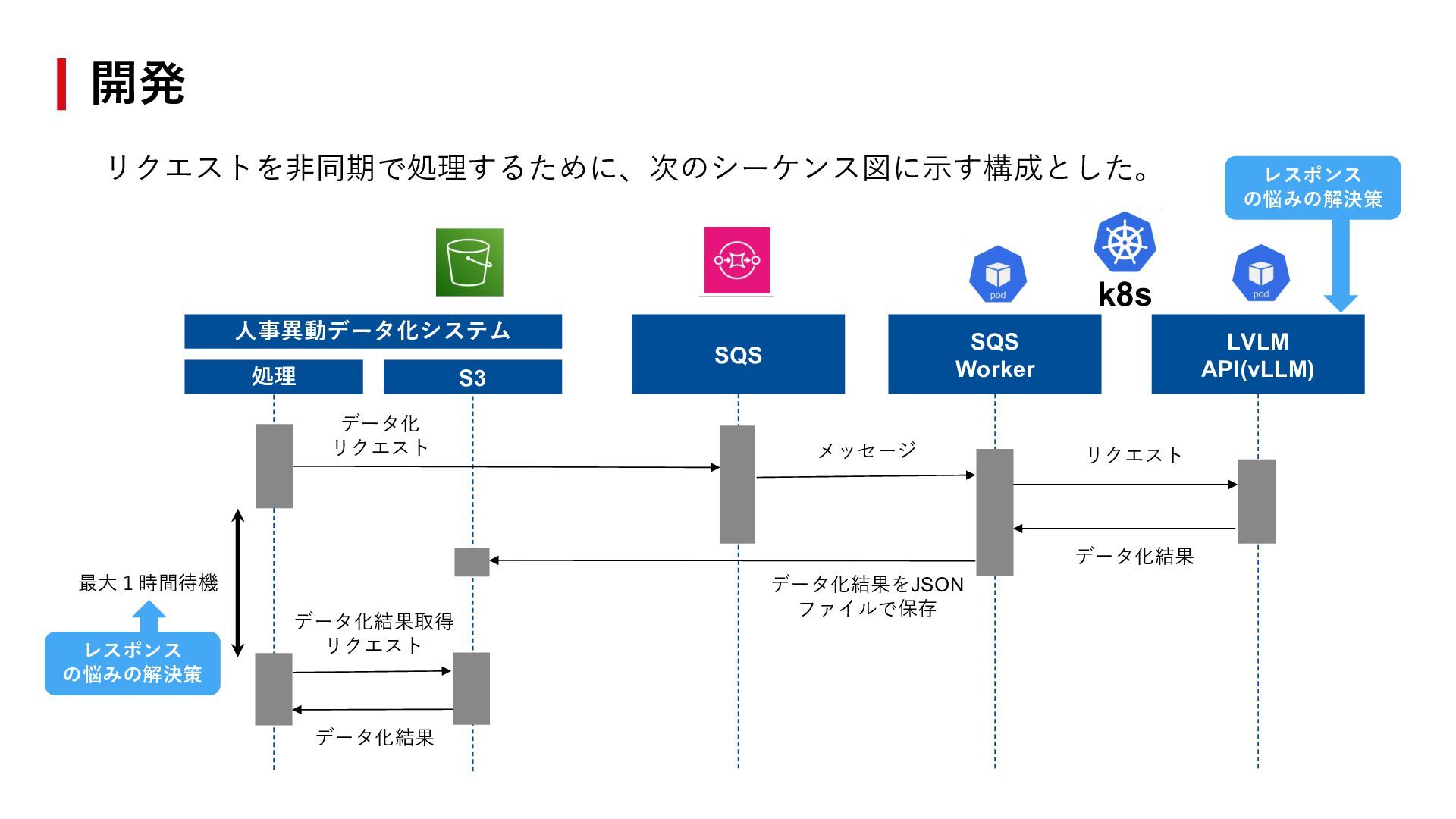{kind=link}
{kind=link}
{kind=link}
{kind=link}