revolution More data than ever before Most growth in 'big data' Or rather 'V data': • High Volume • High Velocity • Highly Variable • Often Un-Verified Continuing rush to access this data
-> 2001 o-d flow data (imperfect) Twitter API Historic tweets (pending Library of Congress action) (£) Mobile phone triangulation data (e.g. Telefonica) Strava data on Running/cycling (£) Migration flow data Anonymous, non-geo. Ind. Survey data Google Location Services data Primary survey data (e.g. Ian Kellar; LAs, Bogota) Size/recent/(potential) utility Direction of movement
tweets in the fixed 2006-10 archive was taking 24 hours just last year. Twitter acquired Gnip in April, prompting hopes that the archive may be operational in 2014-15, but even so, the archive will only be accessible on-site at the Library in Washington, D.C.” source: Poynter.org, 25th June http://www.poynter.org/latest-news/media-lab/social-media/256811/how-to-do-twitter-research-on-a-shoestring/ “Modeled after the U.S. Consumer Privacy Bill of Rights, Rivers and Lewis outline six guidelines for the ethical use of Twitter data:” http://phys.org/news/2014-06-scientists-tactics-ethical-twitter.html Increasing academic interest – data access issues The rise of “Big Analytics” corporations http://venturebeat.com/2014/07/02/datasift-works-with-the-united-nations-to-analyze-social-data-f or-humanitarian-missions/
-> paid data • Small -> big • Pre-processed by provider -> academics pre-process the data (e.g. Sandy Tweets) • Aggregate -> Individual-level • Space + time snapshots -> Space-time
powerful to deal with most [urban] models ... models based on individuals are now feasible both in terms of their computation and their representation using new programming languages” (Batty, 2007, p. 5).
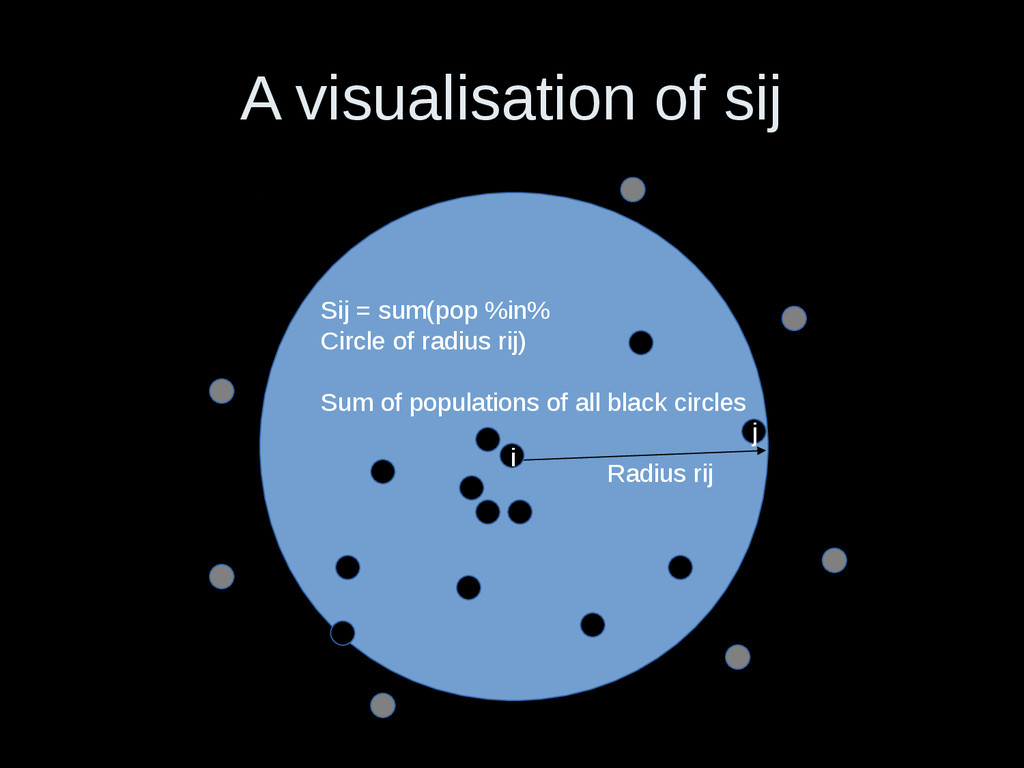
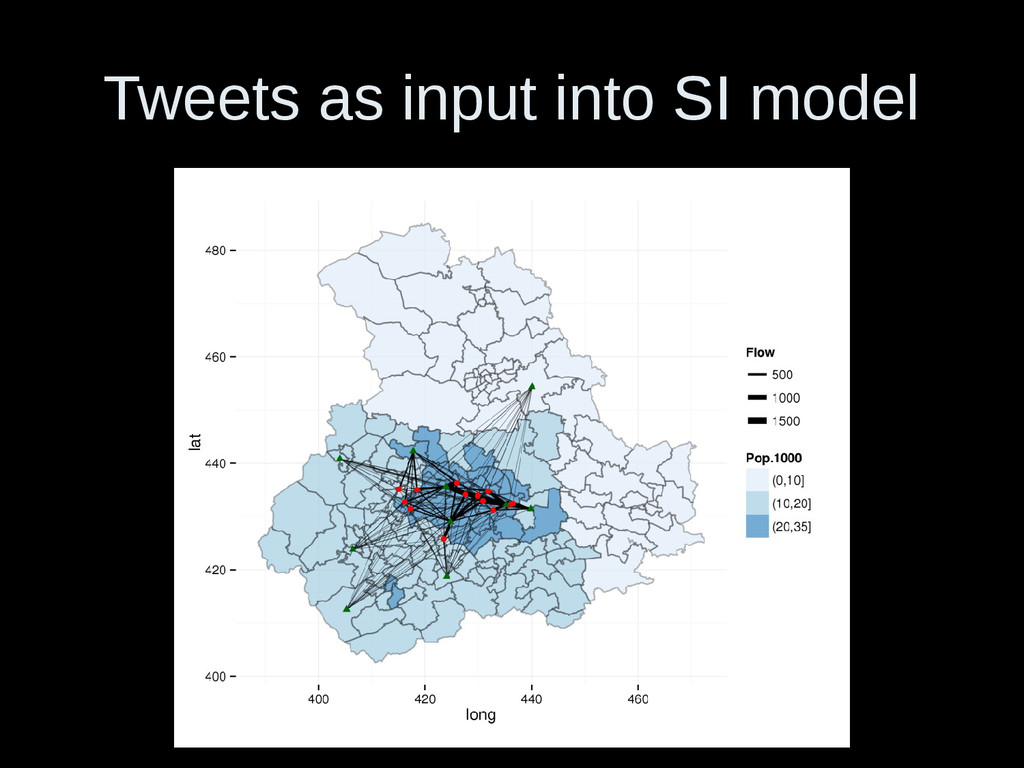
i to j • Ti: flow out of i – sum(Tj≄i) • mi: population of zone i (equiv: Pi) • nj: population of dest. Zone (eqiv: Wj) • sij: population in the circle surrounding i, with circumference touching j
the dominant 'NHST' or “frequentist” paradigm • You must state expectations – no more unrealistic 'null hypotheses' • Monte Carlo or numerical solutions move us from prior to posterior probability distributions for each model parameter • Can also tell us precisely how much more realistic model 1 is than model 2 • New software for handling space-time data (e.g. R packages INLA, spTimer)
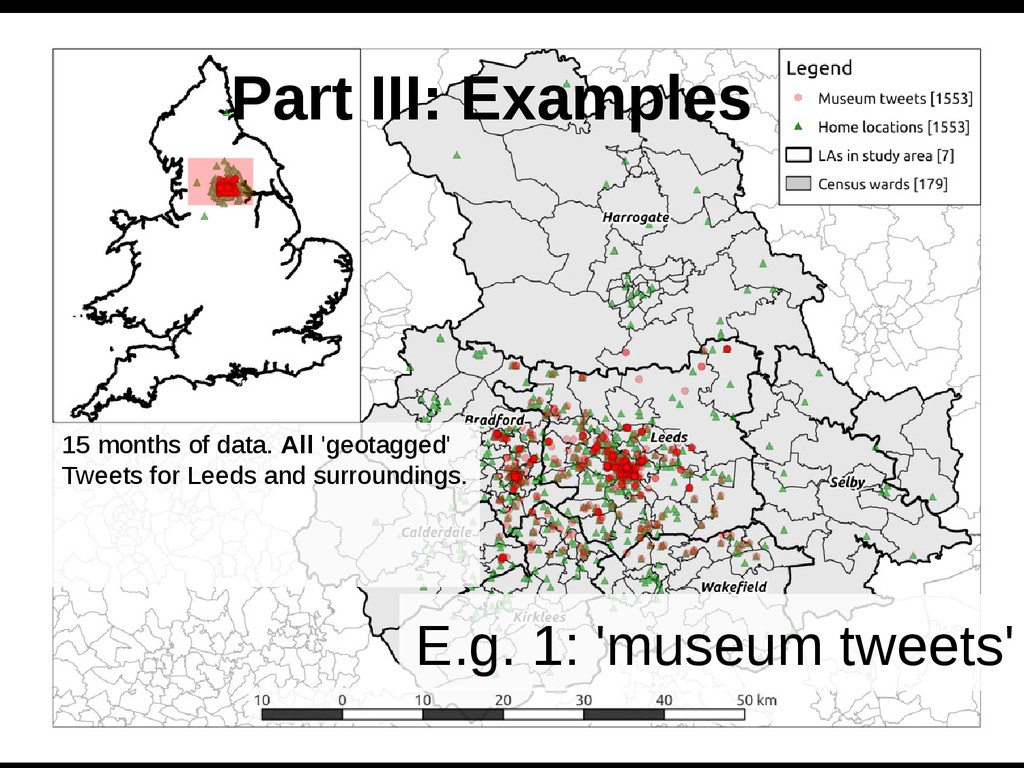
2.8 geo-referenced messages. Semantic filters Basically "regex" Search terms Overall just under 1,000 'museum Tweets' resulted from filters Spatial filters A buffer around each museum with osmar Preprocessing the Tweets
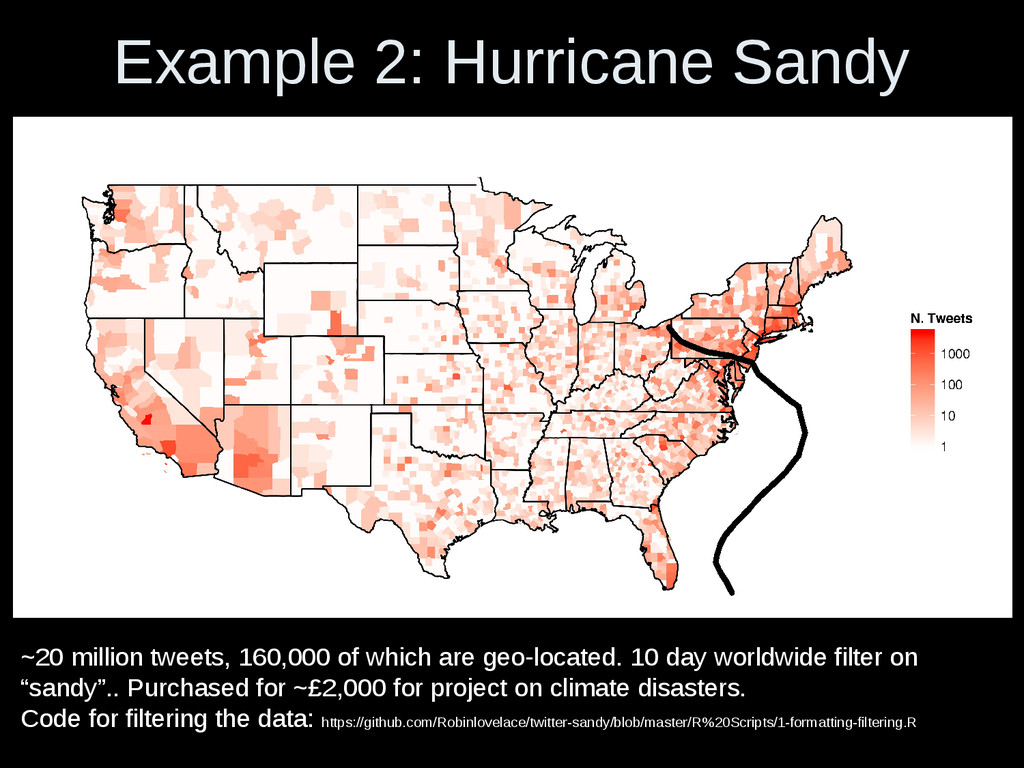
are geo-located. 10 day worldwide filter on “sandy”.. Purchased for ~£2,000 for project on climate disasters. Code for filtering the data: https://github.com/Robinlovelace/twitter-sandy/blob/master/R%20Scripts/1-formatting-filtering.R
into questions previously beyond the reach of survey • Diversity, low cost, comprehensive coverage • High spatial and temporal resolution • New opportunities for testing • Need to move away from 'big noise' to processed and verified datasets • Comparison with official datasets
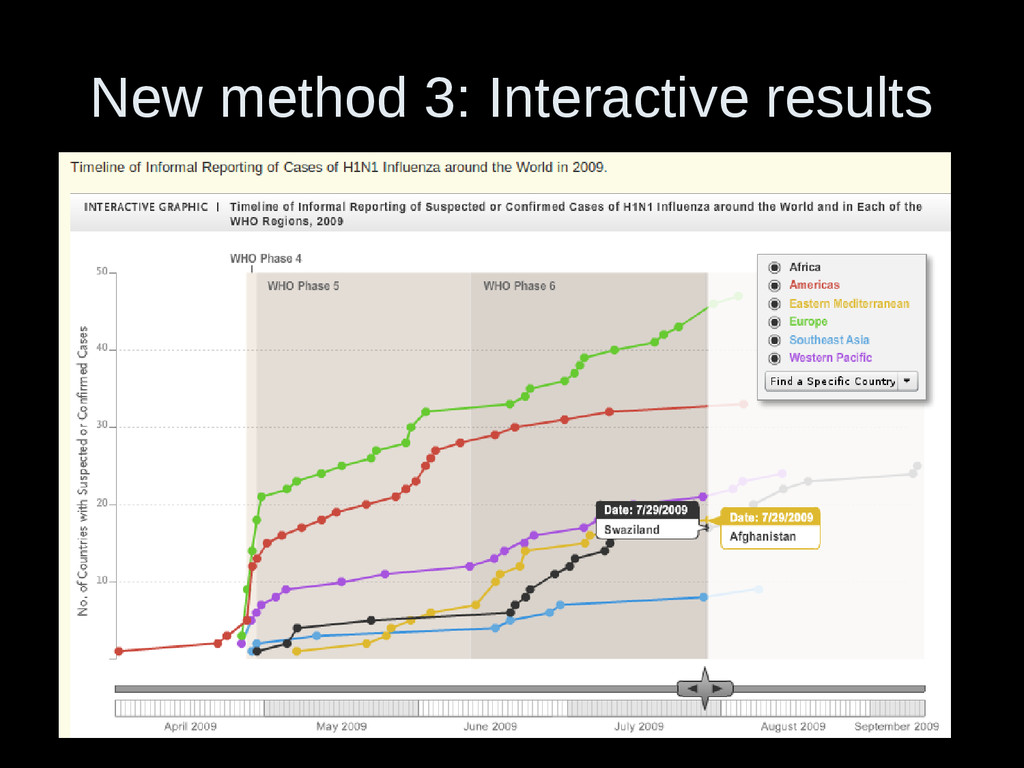
al. 2013) • Bayesian methods are well-suited to the analysis of large datasets • Interactive visualisation • New models and methods need to be tested on 'Big Data'
to deal with uncertainty • Ways to ingest continual data • Filtering • Aggregation New methods call for: • More code sharing (e.g. Dennett, 2012) • Comparative testing • Ways to input new data streams • Visualisation of key processes Convergence in research design?
models Little correspondence between advances in modelling and data sources New datasets call for new methodologies Bridging this model-data gap = research priority: thinking behind research at Leeds
Birkin, M. (2014). Geotagged tweets to inform a spatial interaction model: a case study of museums. arXiv preprint arXiv:1403.5118. • Masucci, a. P., Serras, J., Johansson, A., & Batty, M. (2013). Gravity versus radiation models: On the importance of scale and heterogeneity in commuting flows. Physical Review E, 88(2). • Simini, F., González, M. C., Maritan, A., & Barabási, A. L. (2012). A universal model for mobility and migration patterns. Nature, 484(7392), 96-100.
Policy relevance • Time pre-processing • Unrepresentative (Strava) • Less use of official data Of new models • New is not always better • Oversimplification (Masucci et al. 2013)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Risks of Big Data [Big data is] "a version of](https://files.speakerdeck.com/presentations/889debc0e9420131acc00e2a91d60c51/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}