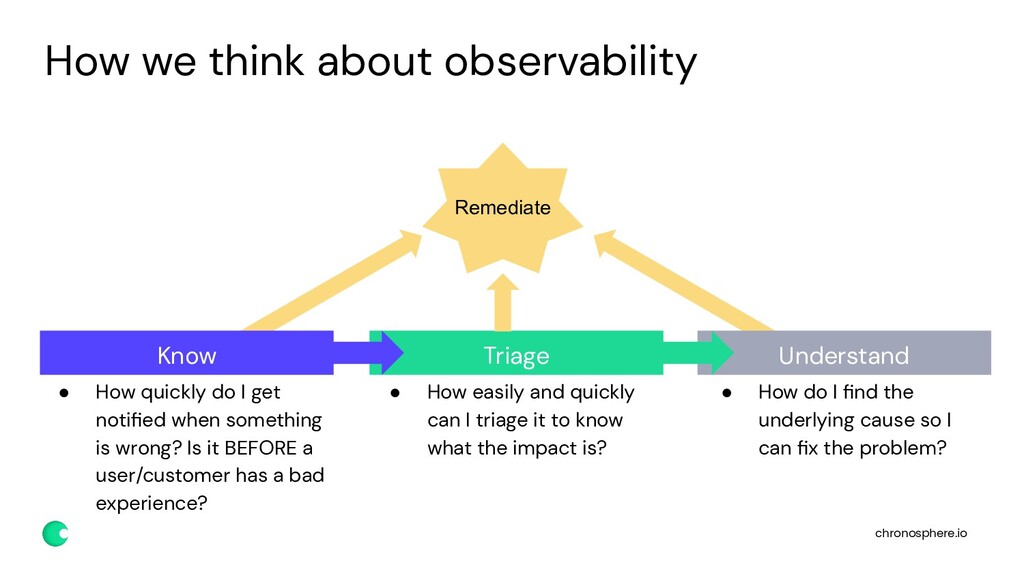
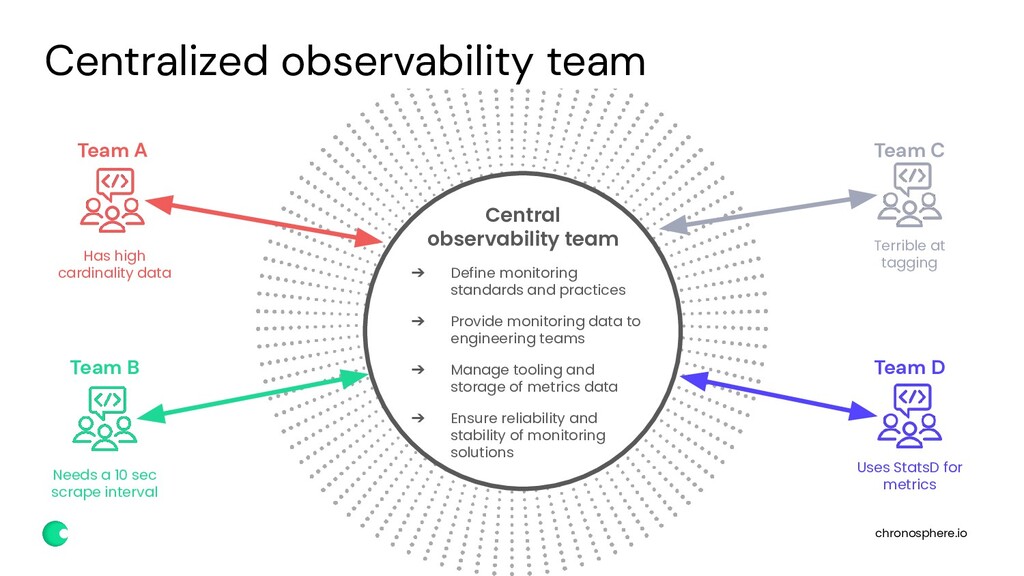
Observability teams as a centralized function within SRE or IT Operations are a relatively recent phenomenon. These teams are responsible for managing the monitoring and observability toolset and empowering developer and engineering teams to push the right data into the systems to get back the information they need. Central observability teams must walk a fine line between controlling cardinality and cost associated with data growth while also providing a complete dataset for quick troubleshooting and diagnostics.
This session will explore the people and process side of observability with lessons learned from the community, including:
Internal KPIs and metrics: how do you measure the success of your observability practice?
Tagging best practices: how to get tags and labels under control and working to your advantage?
Taming cardinality: What processes can help keep cardinality under control?
Roles and responsibilities: Who is responsible for running centralized observability functions? How do you know you need a dedicated team and how many people should be on it?
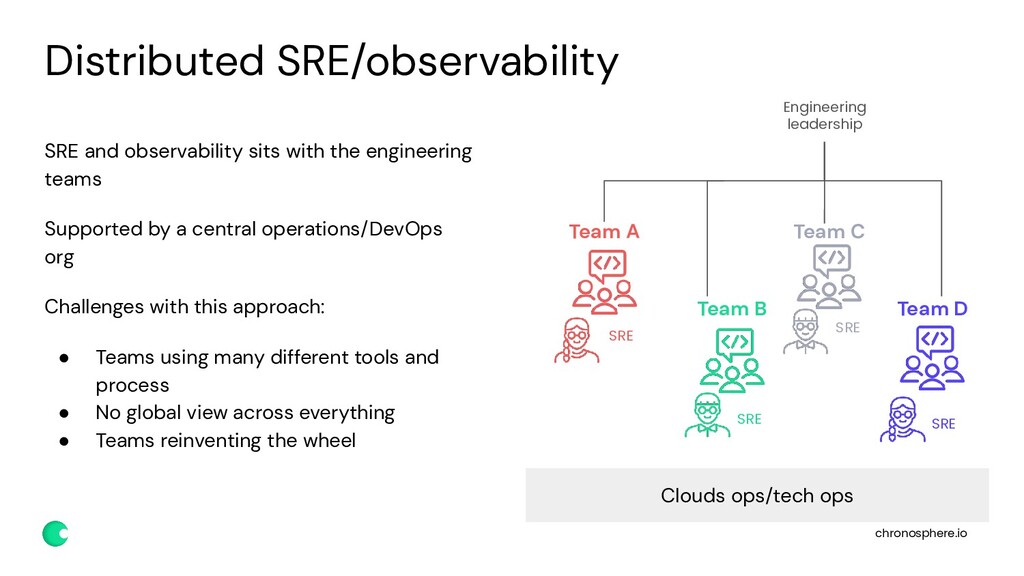
Centralized vs distributed teams: How to manage the balance between individual service teams unique requirements and the need for a centralized and consistent view for SREs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}