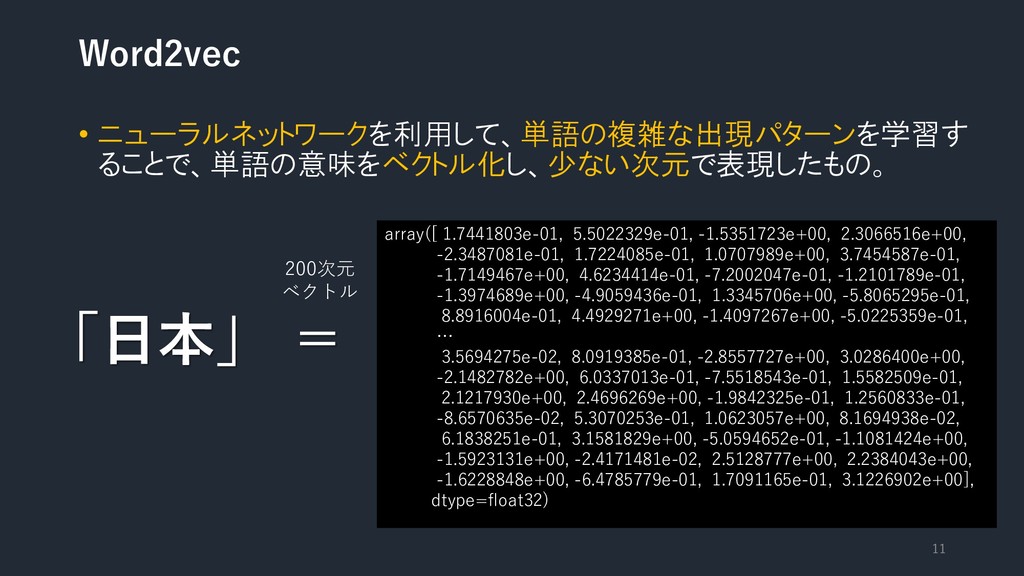
-2.3487081e-01, 1.7224085e-01, 1.0707989e+00, 3.7454587e-01, -1.7149467e+00, 4.6234414e-01, -7.2002047e-01, -1.2101789e-01, -1.3974689e+00, -4.9059436e-01, 1.3345706e+00, -5.8065295e-01, 8.8916004e-01, 4.4929271e+00, -1.4097267e+00, -5.0225359e-01, … 3.5694275e-02, 8.0919385e-01, -2.8557727e+00, 3.0286400e+00, -2.1482782e+00, 6.0337013e-01, -7.5518543e-01, 1.5582509e-01, 2.1217930e+00, 2.4696269e+00, -1.9842325e-01, 1.2560833e-01, -8.6570635e-02, 5.3070253e-01, 1.0623057e+00, 8.1694938e-02, 6.1838251e-01, 3.1581829e+00, -5.0594652e-01, -1.1081424e+00, -1.5923131e+00, -2.4171481e-02, 2.5128777e+00, 2.2384043e+00, -1.6228848e+00, -6.4785779e-01, 1.7091165e-01, 3.1226902e+00], dtype=float32) 「日本」 = 200次元 ベクトル
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![好きな単語のベクトルを表示する。 $ model[u'浦和レッズ'] # 「浦和レッズ」のベクトル出力 200次元ベクトル (= 1×200行列)](https://files.speakerdeck.com/presentations/5a1c45c8d8fd4d5fad0f9ac16c56485c/slide_26.jpg){kind=link}
![類似性が高い単語を表示する。 $ model.most_similar([u'人生']) # 「人生」の類似性が高い上位単語の出力 曖昧な単語についても、 ベクトル化されている。](https://files.speakerdeck.com/presentations/5a1c45c8d8fd4d5fad0f9ac16c56485c/slide_27.jpg){kind=link}
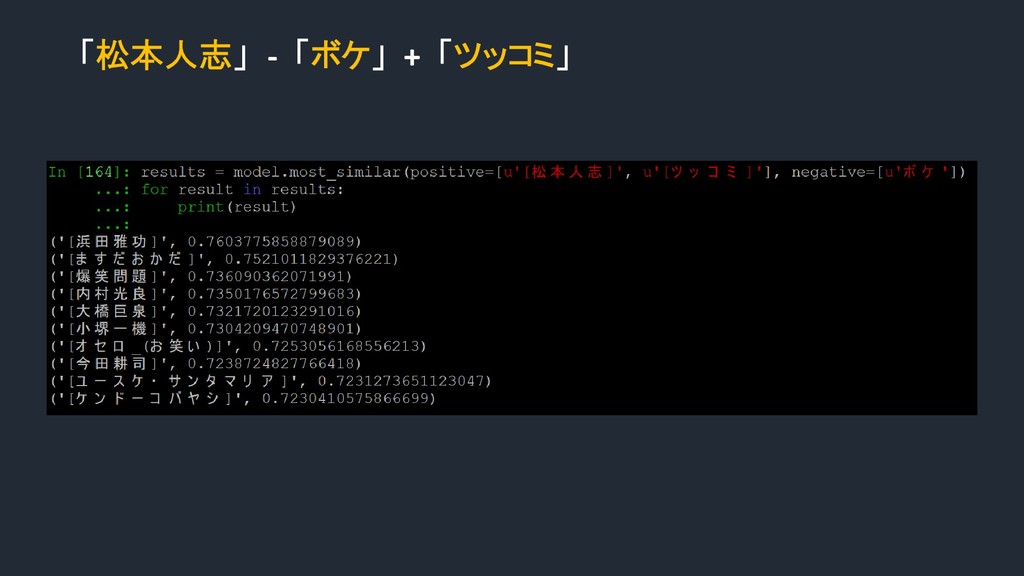{kind=link}
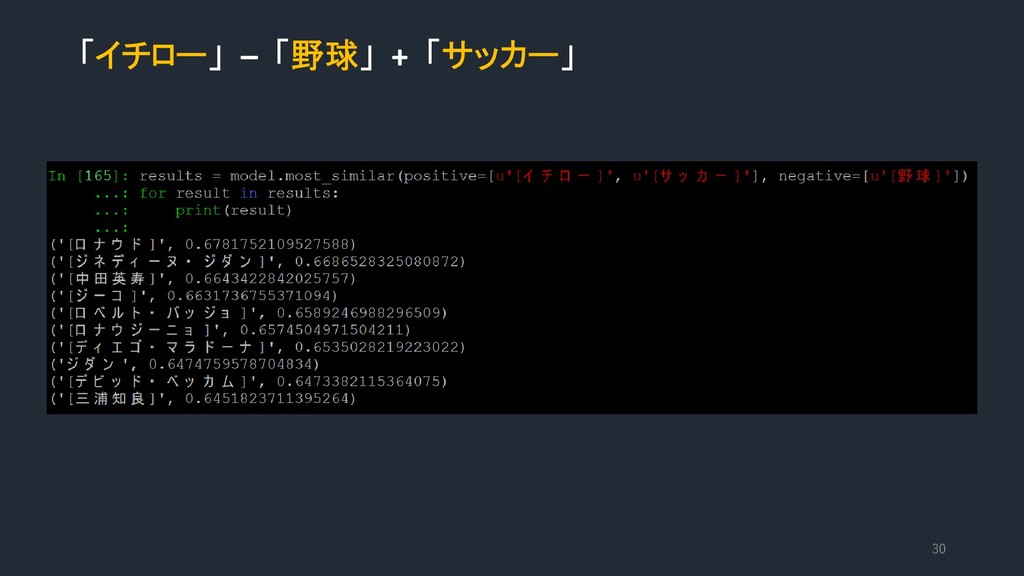{kind=link}
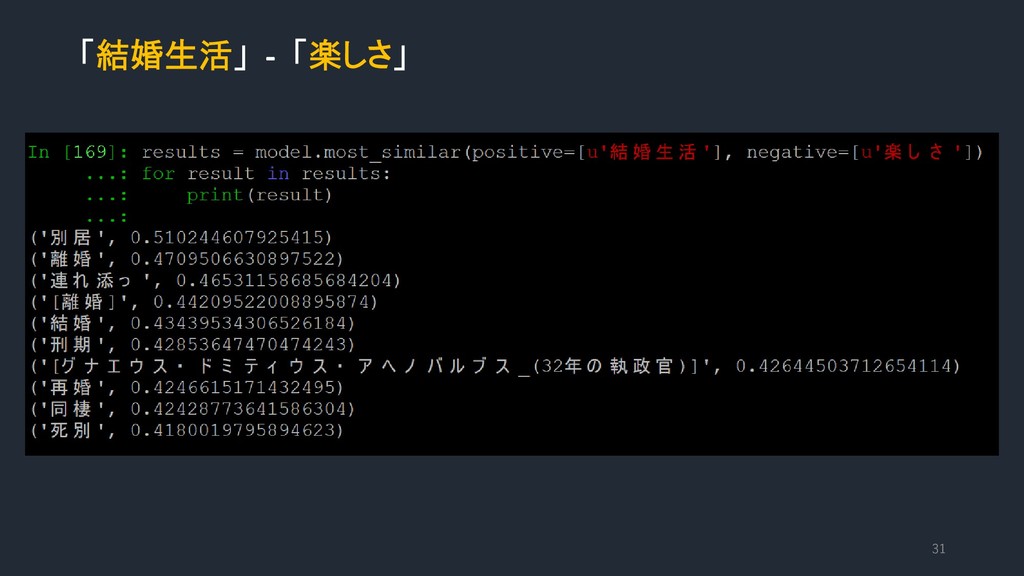{kind=link}
{kind=link}
{kind=link}
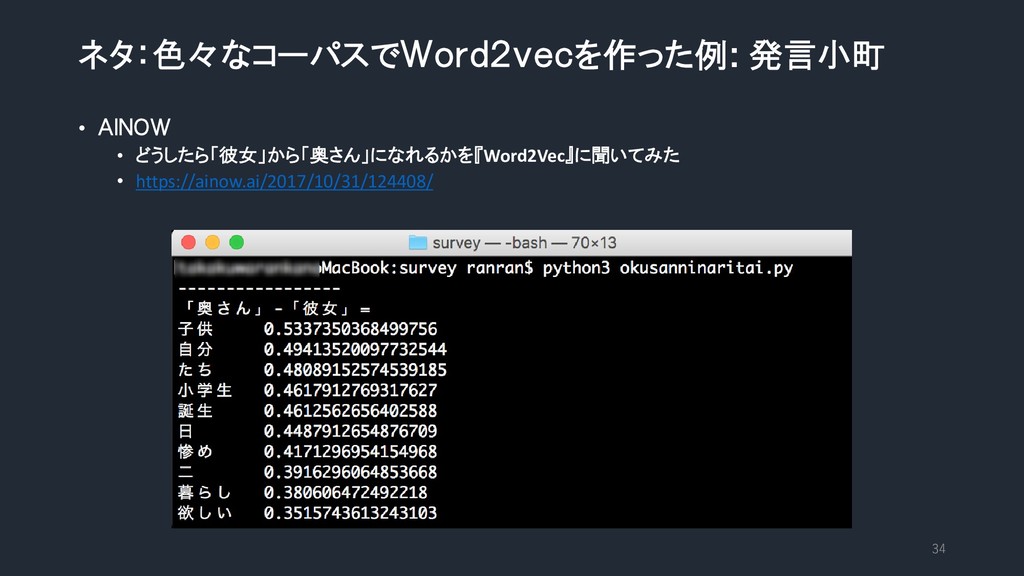{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}