Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Snorkel入門 大量の知識をプログラム化し、ラベル付けを高度化する
Search
Yoshiyuki Ishida
October 09, 2019
Technology
1.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Snorkel入門 大量の知識をプログラム化し、ラベル付けを高度化する
社内勉強会用の資料です。
Yoshiyuki Ishida
October 09, 2019
More Decks by Yoshiyuki Ishida
See All by Yoshiyuki Ishida
数式抜きでWord2vecを話す
ronasama
7
60k
Other Decks in Technology
See All in Technology
PHPで作って学ぶリアルタイム音声対話AIとWebSocket入門 by ムナカタ
munakata
0
110
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
160
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
250
AmplifyHostingConstructからSSRフレームワークのためのホスティング設計を考察する/amplify-hosting-construct
fossamagna
1
280
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.5k
生成 AI 時代にいま一度「問い合わせ」について考えてみる
kazzpapa3
1
110
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
2
980
人とエージェントが高め合う協業設計
kintotechdev
0
690
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
Kaggleで成長するために意識したこと
prgckwb
2
440
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
1
130
GoでCコンパイラを作った話
repunit
0
150
Featured
See All Featured
It's Worth the Effort
3n
188
29k
Google's AI Overviews - The New Search
badams
0
1.1k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
Balancing Empowerment & Direction
lara
6
1.2k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
AI: The stuff that nobody shows you
jnunemaker
PRO
9
840
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
RailsConf 2023
tenderlove
30
1.5k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
420
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
Transcript
入門 2019.10 Yoshiyuki Ishida 大量の知識をプログラム化し、ラベル付けを高度化する
今日、話すこと • Snorkelはトレーニングデータの作成やモデル化、管理するためのOSS。 • そのうちLabeling Functionの機能を紹介します。 • 様々な知識を組み合わせて、ラベル付けを行う話をします。 • 個人的な興味の話なので、業務に役立つかはわからない。
2
Snorkel 3 https://www.snorkel.org/
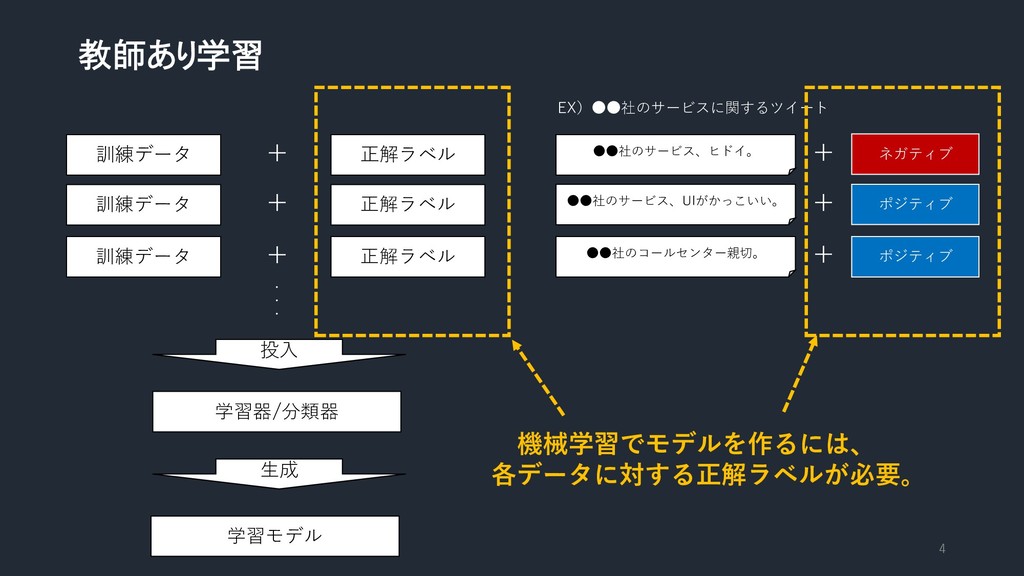
教師あり学習 4 訓練データ + 正解ラベル 訓練データ + 正解ラベル 訓練データ +
正解ラベル ・ ・ ・ 投入 学習器/分類器 生成 学習モデル EX)••社のサービスに関するツイート ••社のサービス、ヒドイ。 ••社のサービス、UIがかっこいい。 ••社のコールセンター親切。 + + + ネガティブ ポジティブ ポジティブ 機械学習でモデルを作るには、 各データに対する正解ラベルが必要。
Snorkelが解消したい「機械学習でのボトルネック」 5
Snorkelが解消したい「機械学習でのボトルネック」 手作業でのトレーニングデータの ラベル付け、管理 6
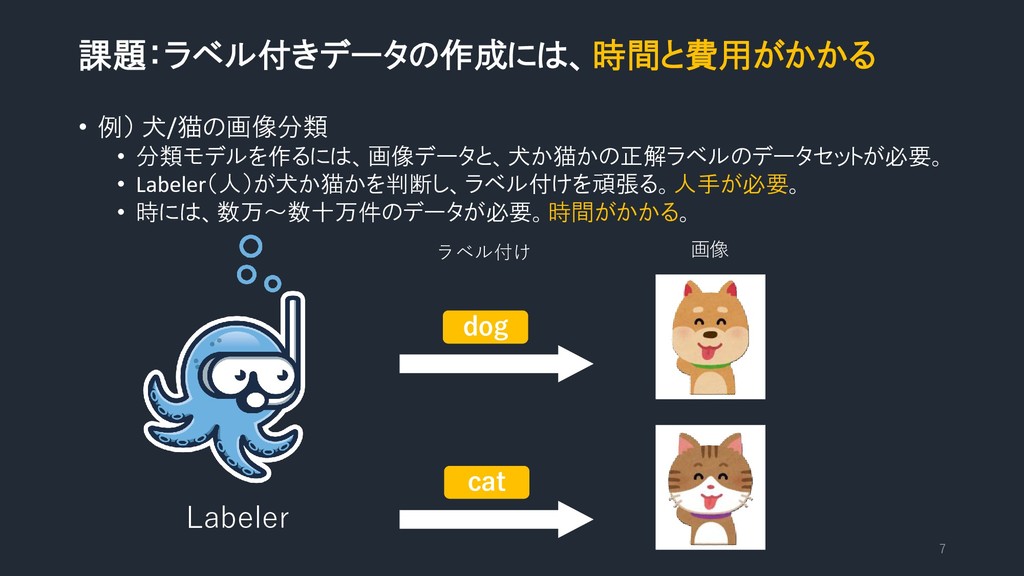
課題:ラベル付きデータの作成には、時間と費用がかかる • 例) 犬/猫の画像分類 • 分類モデルを作るには、画像データと、犬か猫かの正解ラベルのデータセットが必要。 • Labeler(人)が犬か猫かを判断し、ラベル付けを頑張る。人手が必要。 • 時には、数万~数十万件のデータが必要。時間がかかる。
7 Labeler dog cat 画像 ラベル付け
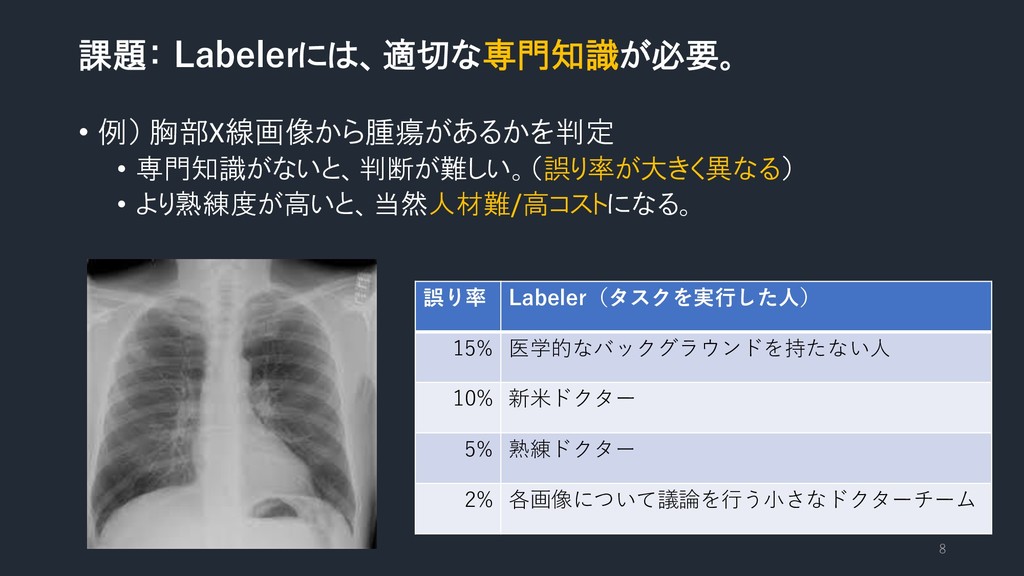
課題: Labelerには、適切な専門知識が必要。 • 例) 胸部X線画像から腫瘍があるかを判定 • 専門知識がないと、判断が難しい。(誤り率が大きく異なる) • より熟練度が高いと、当然人材難/高コストになる。 8
誤り率 Labeler(タスクを実行した人) 15% 医学的なバックグラウンドを持たない人 10% 新米ドクター 5% 熟練ドクター 2% 各画像について議論を行う小さなドクターチーム
課題: Labelerが人間であることによるノイズとバイアス 1. ノイズ • 環境や体調によって、判断がブレる可能性がある。 2. バイアス • 人によって、判断がブレる可能性がある。
9 わいは、 ポジティブな ツイートだと思う わいは、 ニュートラルな ツイートだと思う 恋人に 振られた メガネを 忘れた 今日は 熱がある 寝不足 梅雨で ジメジメ 久しぶりの 職場復帰
課題:アプリケーションの更新や方針変更への対応 • ラベル付けは、現実世界の影響を受け、状況は変化する。 • ラベリング方針の変更。 • どのくらい細かく分類するかの変更。 • 作業の進め方の変更。 •
結果、再ラベリングが必要になる。 • 新たに、「ニュートラル」という新しいカテゴリの追加、等 10
Snorkelは、手作業によって行っていた大規模なトレーニングデータ作成 作業を、数週間/数カ月→数時間/数日に短縮可能 “Snorkel is a system for build and manage
training data programmatically without manual labeling.” =「手作業ではなく、プログラマティックに ラベルを作成し管理する」 11
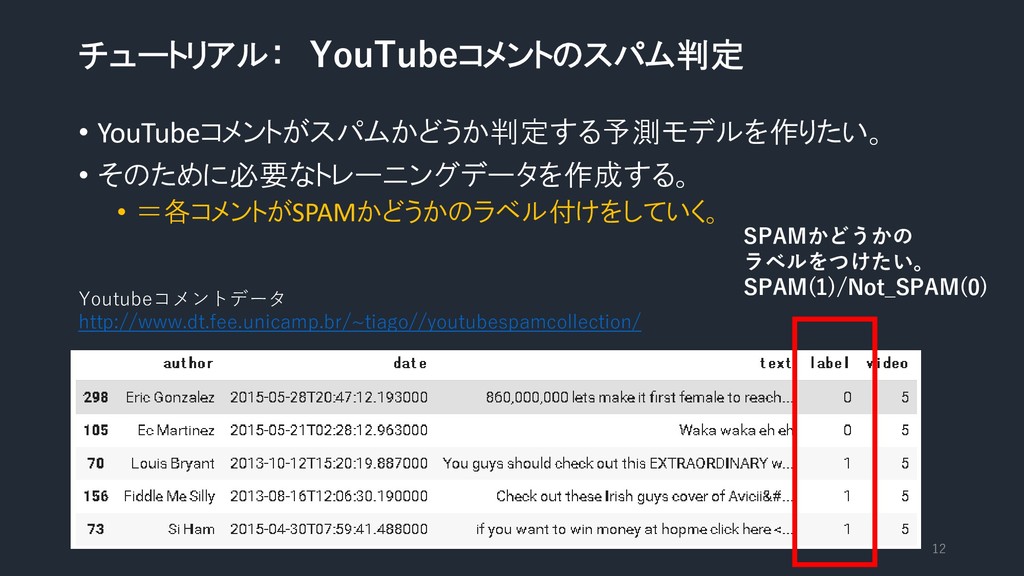
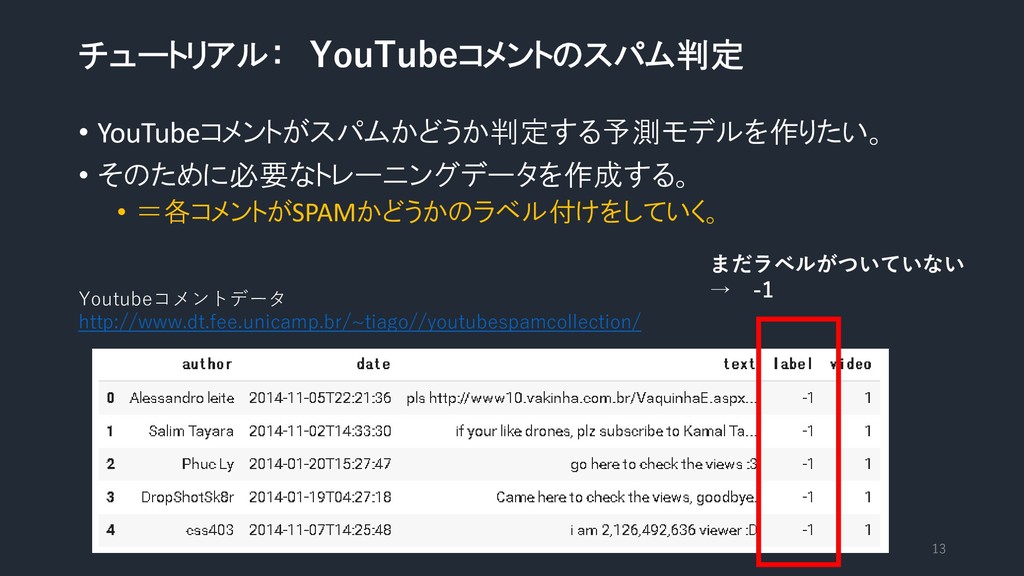
チュートリアル: YouTubeコメントのスパム判定 • YouTubeコメントがスパムかどうか判定する予測モデルを作りたい。 • そのために必要なトレーニングデータを作成する。 • =各コメントがSPAMかどうかのラベル付けをしていく。 12 Youtubeコメントデータ
http://www.dt.fee.unicamp.br/~tiago//youtubespamcollection/ SPAMかどうかの ラベルをつけたい。 SPAM(1)/Not_SPAM(0)
チュートリアル: YouTubeコメントのスパム判定 • YouTubeコメントがスパムかどうか判定する予測モデルを作りたい。 • そのために必要なトレーニングデータを作成する。 • =各コメントがSPAMかどうかのラベル付けをしていく。 13 Youtubeコメントデータ
http://www.dt.fee.unicamp.br/~tiago//youtubespamcollection/ まだラベルがついていない → -1
YouTubeコメントがSPAMか判定する様々な知識の例 • 多くのSPAMコメントは自分たちのWebサイトに誘導しようとする。 • SPAMコメントは、「check out my video」、「check it out」・・・等のコメントを残す。
• Non-SPAMコメントは、「cool video!」「Nice video」・・・など、しばしばコメントが短い。 • ポジティブな内容のコメントは、SPAMである可能性が低い。 14
YouTubeコメントがSPAMか判定する様々な知識の例 • 多くのSPAMコメントは自分たちのWebサイトに誘導しようとする。 → 「http」というキーワードが入っていると、SPAMの確率が高い。 • SPAMコメントは、「check out my video」、「check
it out」・・・等のコメントを残す。 → 「check * out」という正規表現だと、SPAMの確率が高い。 • Non-SPAMコメントは、「cool video!」「Nice video」・・・など、しばしばコメントが短い。 → 経験則的に、5単語以下だと、SPAMではない確率が高い。 • ポジティブな内容のコメントは、SPAMである可能性が低い。 →ポジネガ判定するサードパーティモデルがポジティブと判定した場合、SPAMでない確率が高い。 15
様々なドメイン知識の特徴 • 各知識は、形式や粒度が様々。また、各知識の精度もバラバラ。 • サードパーティモデル、正規表現、キーワードマッチ • 網羅性が低い知識も高い知識もある。 • YouTubeコメントの〇%がこの知識に当てはまる? •
各知識同士で、相関があるものもある。 • 知識Aと知識Bでは、違う判定をすることがある。 16
Snorkel が目指す考え方 1. Data Labeling • 各知識をプログラマティックに定義し、ラベル付けに活用する。 2. Weak Supervision
• 様々な形式の知識を、精度や相関、対立、網羅性を考慮しながら統合 し、精度が高い単一のラベル付けを行う。 17
Snorkelでのラベル付けステップ • STEP1 • 知識を定義していく。 • Labeling Function(LF)という機能を利用し、知識をプログラムで記述する。 • STEP2
• 知識を統合して、単一のラベル化にする。 • LabelModelを利用し、単一ラベルに統合するためのモデリングを行う。 18
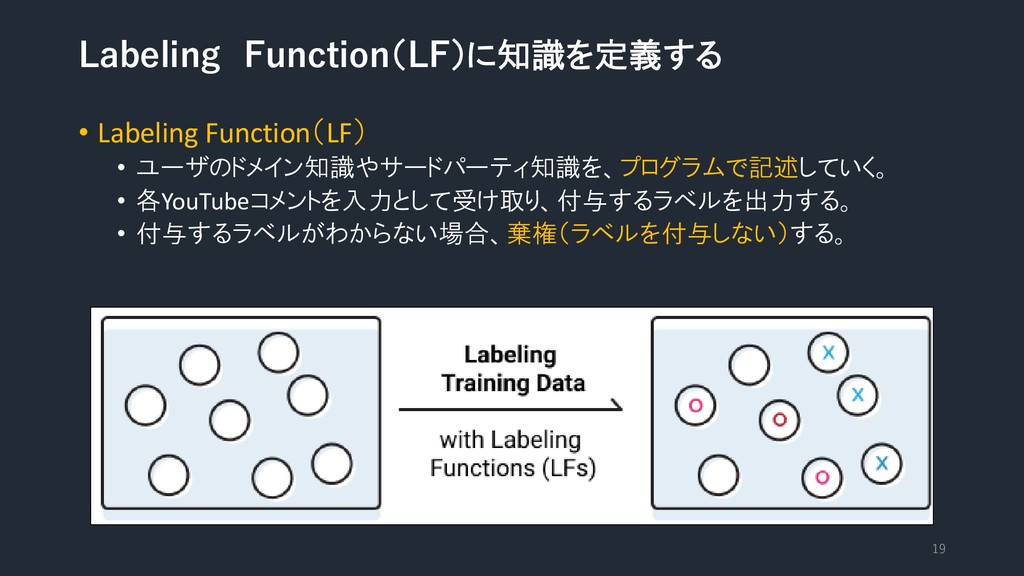
Labeling Function(LF)に知識を定義する • Labeling Function(LF) • ユーザのドメイン知識やサードパーティ知識を、プログラムで記述していく。 • 各YouTubeコメントを入力として受け取り、付与するラベルを出力する。 •
付与するラベルがわからない場合、棄権(ラベルを付与しない)する。 19
Snorkelのインストール 20
LFへの定義: キーワードマッチ • SPAM判定の知識 • 多くのSPAMコメントは自分たちのWebサイトに誘導しようとする。 • LFへの定義 • 「http」というキーワードにマッチすると、SPAMである。
• それ以外は、ABSTAIN(棄権) 21 デコレータ@labeling_functionを 付けて、関数を定義する。
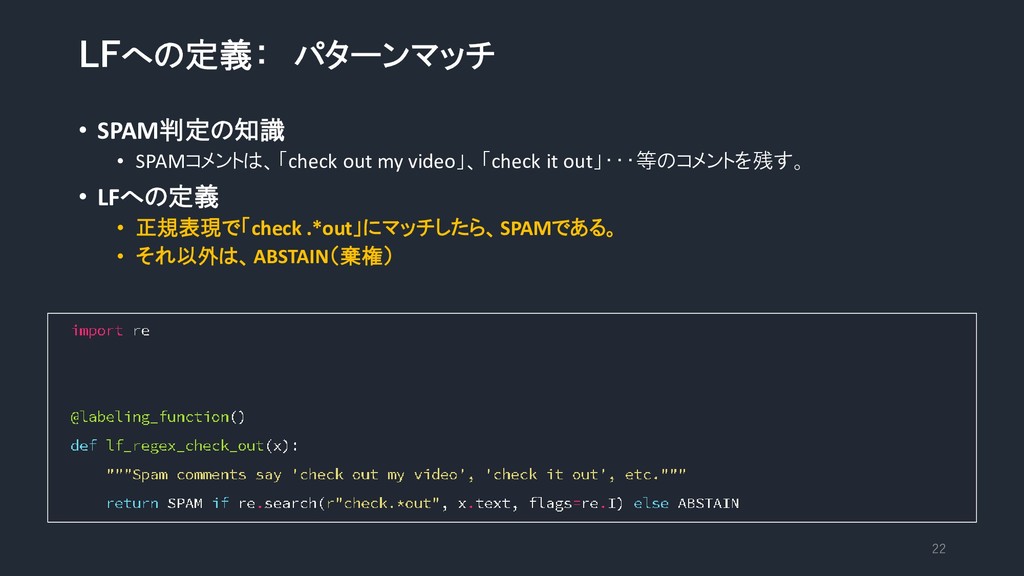
LFへの定義: パターンマッチ • SPAM判定の知識 • SPAMコメントは、「check out my video」、「check it
out」・・・等のコメントを残す。 • LFへの定義 • 正規表現で「check .*out」にマッチしたら、SPAMである。 • それ以外は、ABSTAIN(棄権) 22
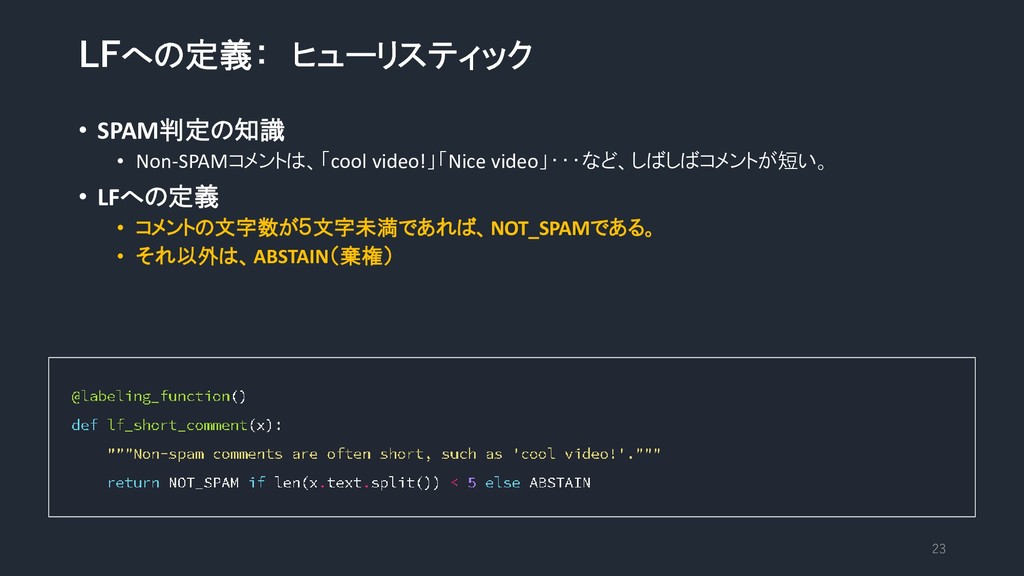
LFへの定義: ヒューリスティック • SPAM判定の知識 • Non-SPAMコメントは、「cool video!」「Nice video」・・・など、しばしばコメントが短い。 • LFへの定義
• コメントの文字数が5文字未満であれば、NOT_SPAMである。 • それ以外は、ABSTAIN(棄権) 23
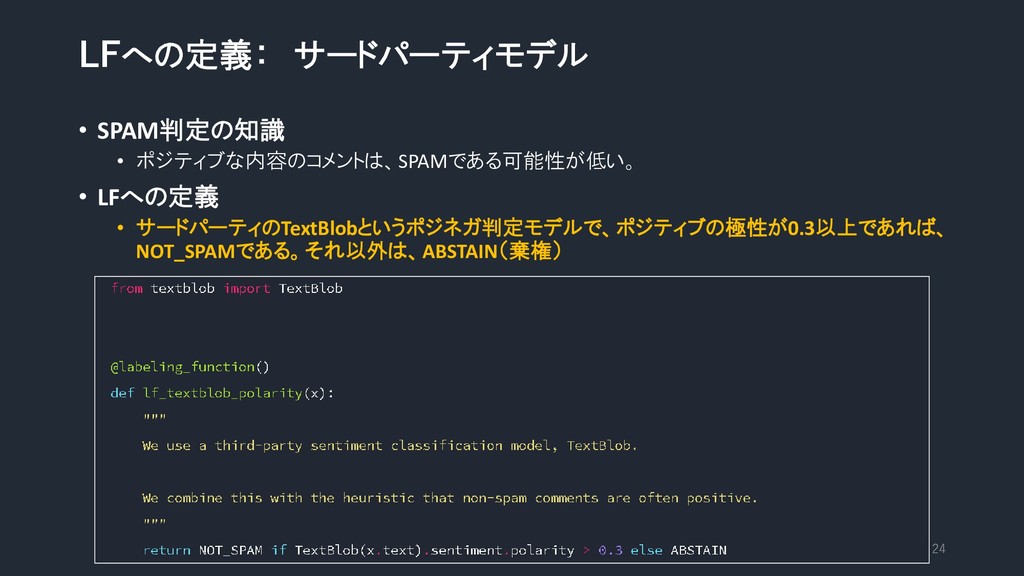
LFへの定義: サードパーティモデル • SPAM判定の知識 • ポジティブな内容のコメントは、SPAMである可能性が低い。 • LFへの定義 • サードパーティのTextBlobというポジネガ判定モデルで、ポジティブの極性が0.3以上であれば、
NOT_SPAMである。それ以外は、ABSTAIN(棄権) 24
LFで定義した知識を、データに適用する • 1つ以上のLFを適用するために、LFApplierを利用する。 • (今回はpandasが利用されているため、PandasLFApplierを利用。) • LFに渡される入力データの形式は、pandas seriesオブジェクト。 • 出力(L_train/L_dev)は、Labelのmatrix。
25
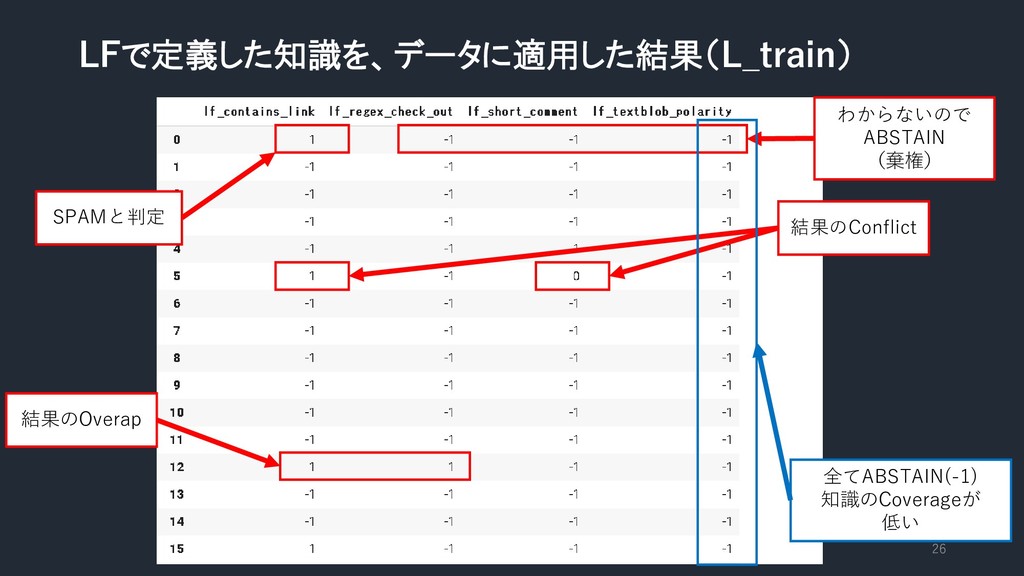
LFで定義した知識を、データに適用した結果(L_train) 26 SPAMと判定 わからないので ABSTAIN (棄権) 結果のConflict 結果のOverap 全てABSTAIN(-1) 知識のCoverageが
低い
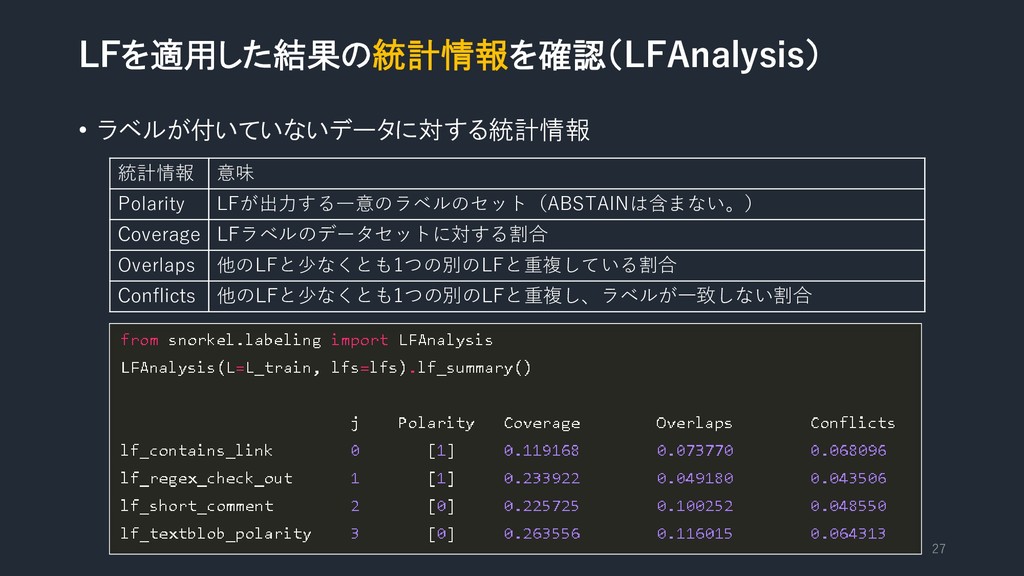
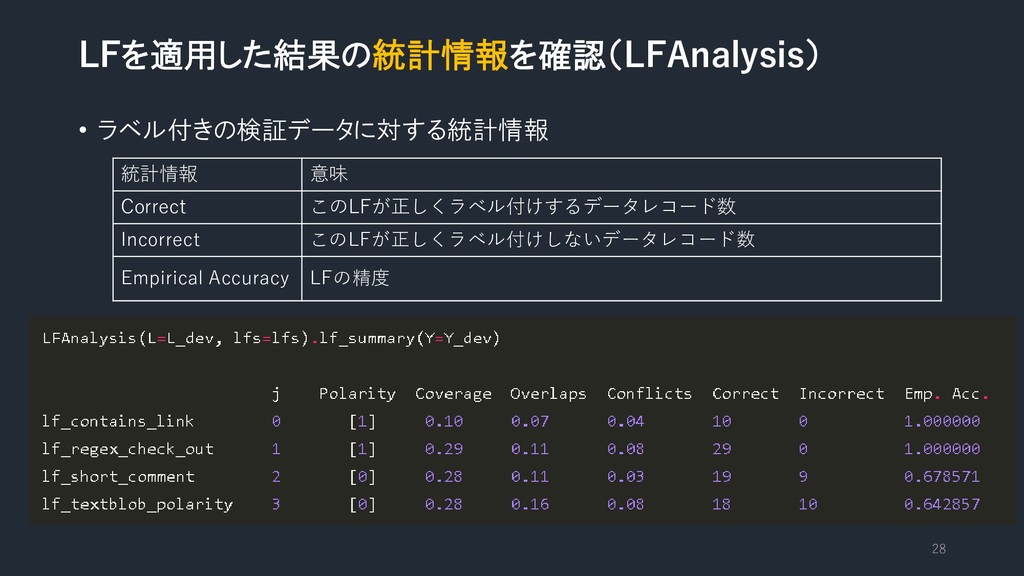
LFを適用した結果の統計情報を確認(LFAnalysis) • ラベルが付いていないデータに対する統計情報 27 統計情報 意味 Polarity LFが出力する一意のラベルのセット(ABSTAINは含まない。) Coverage LFラベルのデータセットに対する割合
Overlaps 他のLFと少なくとも1つの別のLFと重複している割合 Conflicts 他のLFと少なくとも1つの別のLFと重複し、ラベルが一致しない割合
LFを適用した結果の統計情報を確認(LFAnalysis) • ラベル付きの検証データに対する統計情報 28 統計情報 意味 Correct このLFが正しくラベル付けするデータレコード数 Incorrect このLFが正しくラベル付けしないデータレコード数
Empirical Accuracy LFの精度
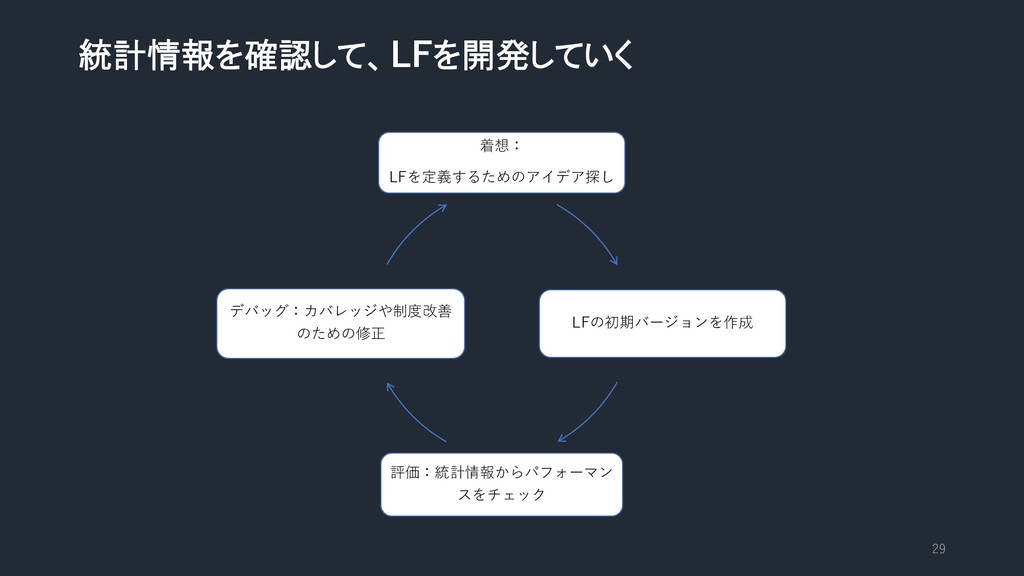
統計情報を確認して、LFを開発していく 着想: LFを定義するためのアイデア探し LFの初期バージョンを作成 評価:統計情報からパフォーマン スをチェック デバッグ:カバレッジや制度改善 のための修正 29
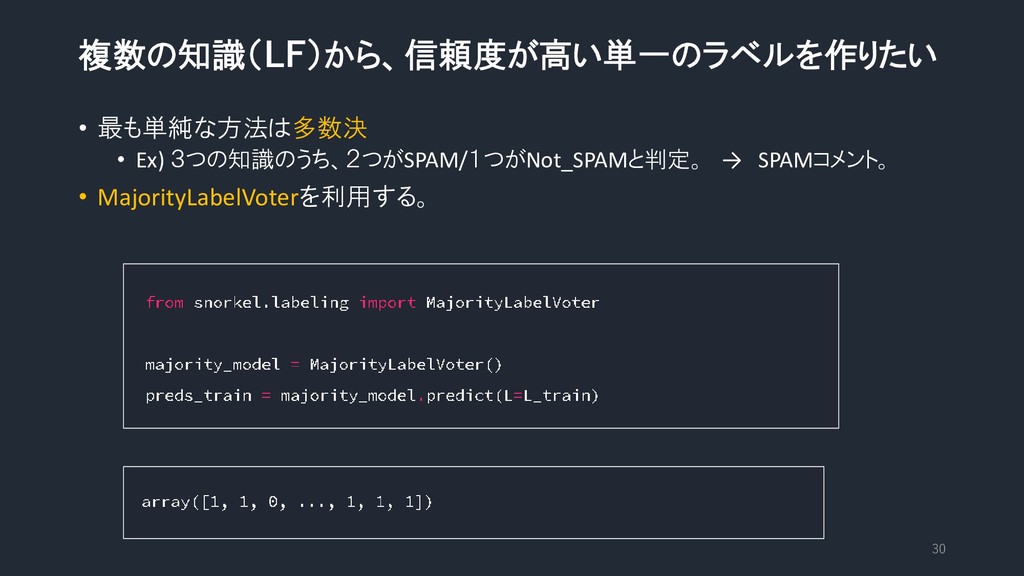
複数の知識(LF)から、信頼度が高い単一のラベルを作りたい • 最も単純な方法は多数決 • Ex) 3つの知識のうち、2つがSPAM/1つがNot_SPAMと判定。 → SPAMコメント。 • MajorityLabelVoterを利用する。
30
多数決の問題点 • 多数決は、全ての知識(LF)を同じように扱うがそうすべきではない。 特定のLFが過大/過少評価される可能性がある。 • 精度が違う。 • カバレッジが違う。 • 相関が高い似たLFがある。
31
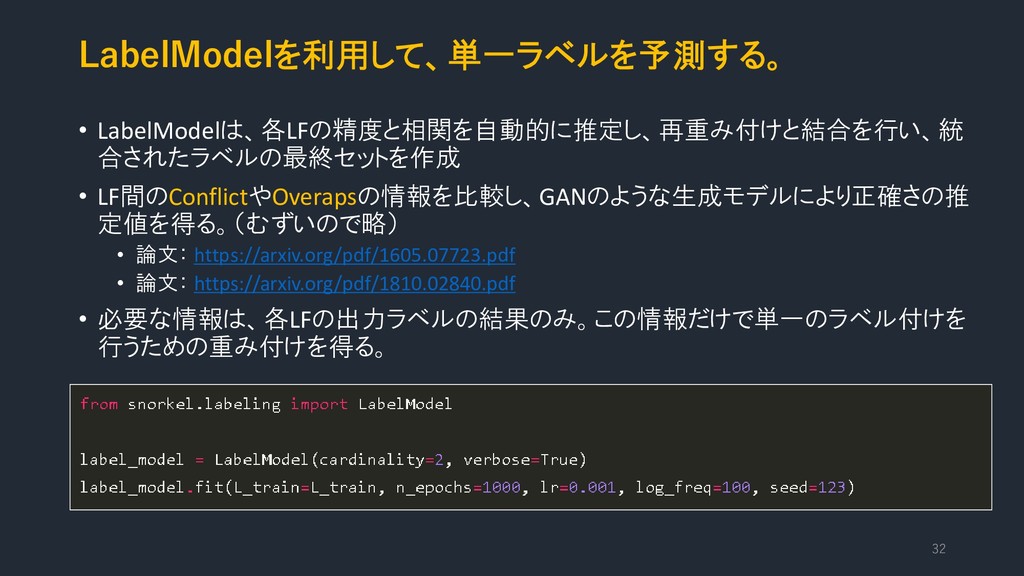
LabelModelを利用して、単一ラベルを予測する。 • LabelModelは、各LFの精度と相関を自動的に推定し、再重み付けと結合を行い、統 合されたラベルの最終セットを作成 • LF間のConflictやOverapsの情報を比較し、GANのような生成モデルにより正確さの推 定値を得る。(むずいので略) • 論文: https://arxiv.org/pdf/1605.07723.pdf
• 論文: https://arxiv.org/pdf/1810.02840.pdf • 必要な情報は、各LFの出力ラベルの結果のみ。この情報だけで単一のラベル付けを 行うための重み付けを得る。 32
LabelModelを利用して、単一ラベルを予測する。 33 Labeling Functionに 定義した各知識 モ デ リ ン グ
・ 統 合 MajorityModel の結果 LableModel の結果 検証データでの精度の結果 79.2% 81.7%
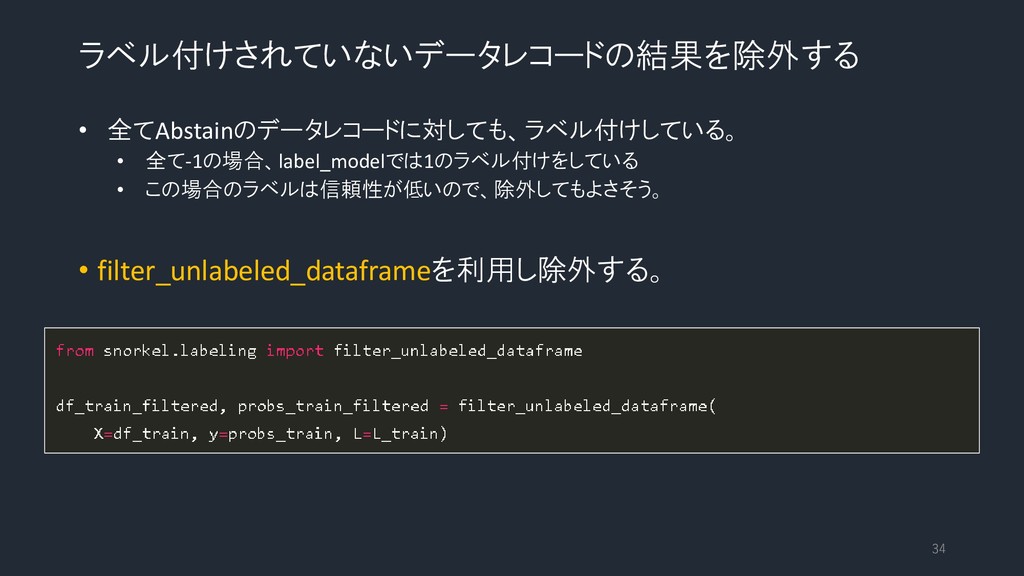
ラベル付けされていないデータレコードの結果を除外する • 全てAbstainのデータレコードに対しても、ラベル付けしている。 • 全て-1の場合、label_modelでは1のラベル付けをしている • この場合のラベルは信頼性が低いので、除外してもよさそう。 • filter_unlabeled_dataframeを利用し除外する。 34
Snorkelの目標 • ラベル付けがないデータセットに対して、高品質なラベルを付与すること。 • 全てのデータをラベル付けすることではない。 • 直接、SPAMを予測するモデルを作ることでもない。 • LabekModelにより作成したラベル付きデータを、別のモデルの学習データ として利用する。
35
まとめ • Snorkelを利用すると、機械学習のボトルネックの1つである、訓練デー タ作成のコストを下げる/精度をあげる可能性がある。 • LFは最も重要な機能だが、他にも色々な機能ある。 • Data Augmentation機能 •
Ex) ランダムな単語を同義語に置き換える。 • Ex) 画像の回転 • とか • たぶん、知識はたくさんあった方が精度高い結果が得られる。 36
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}