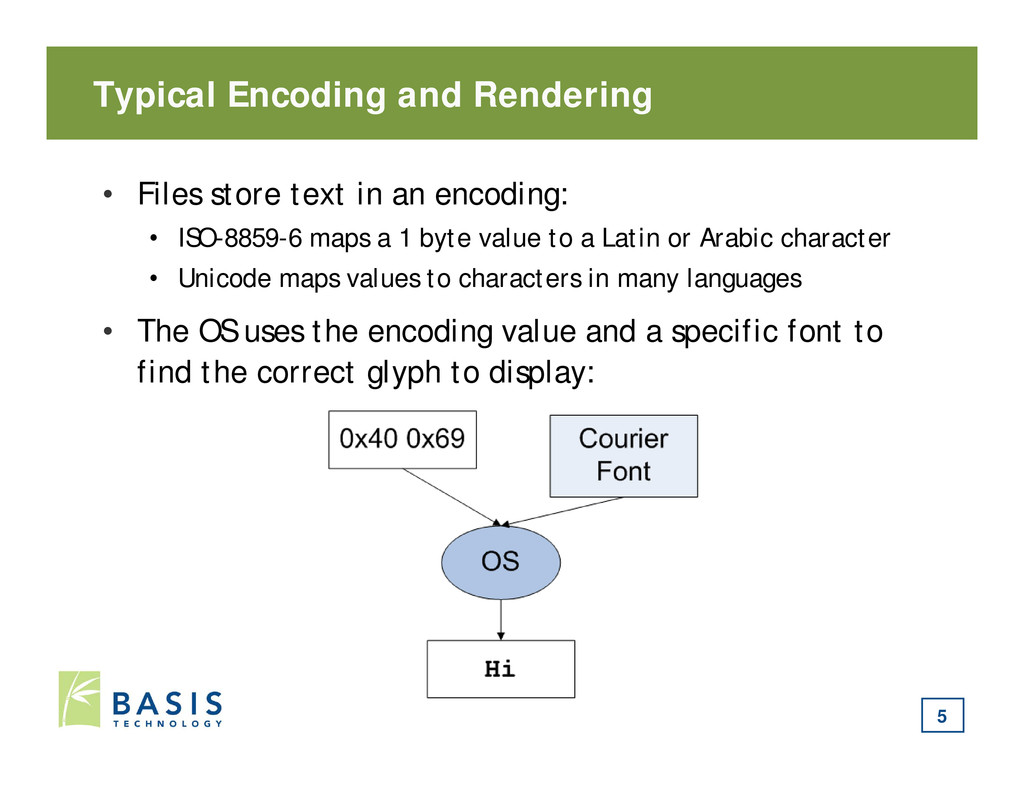
encoding: • ISO-8859-6 maps a 1 byte value to a Latin or Arabic character • Unicode maps values to characters in many languages • The OS uses the encoding value and a specific font to find the correct glyph to display: 5
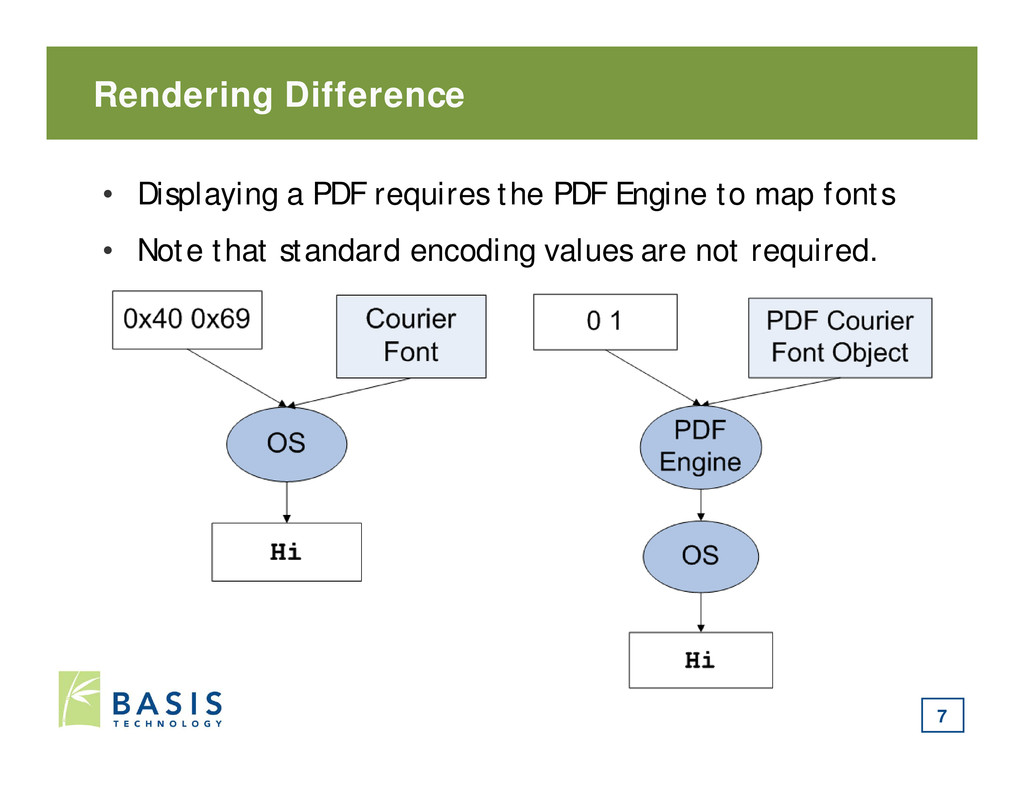
content objects 2. Parse page content stream into text chunks 3. Sort text chunks based on coordinates 4. Process chunks in order: 1. Get index for each character 2. Use font information to map index to Unicode (if defined) 3. Add Unicode value to end of string 8
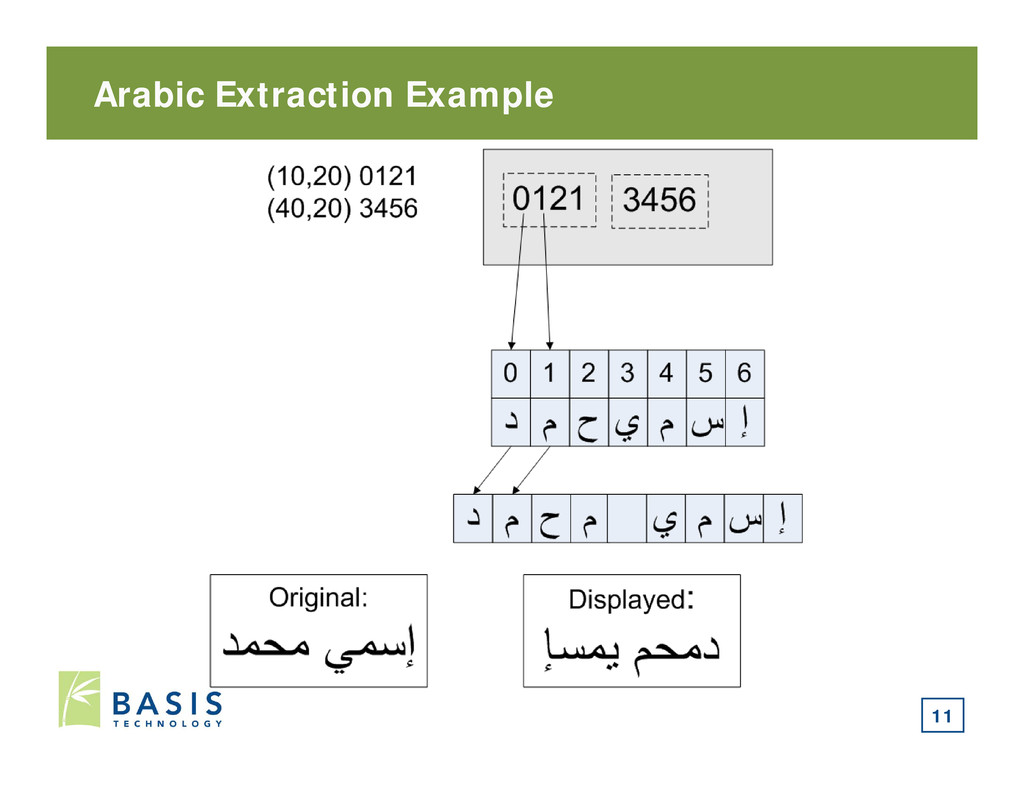
stored in logical order • First character stored is first character read or written • Presentation order is based on screen layout • Orders are same for Left to Right (LTR) Languages: • Opposite for Right to Left (RTL) Languages: 12
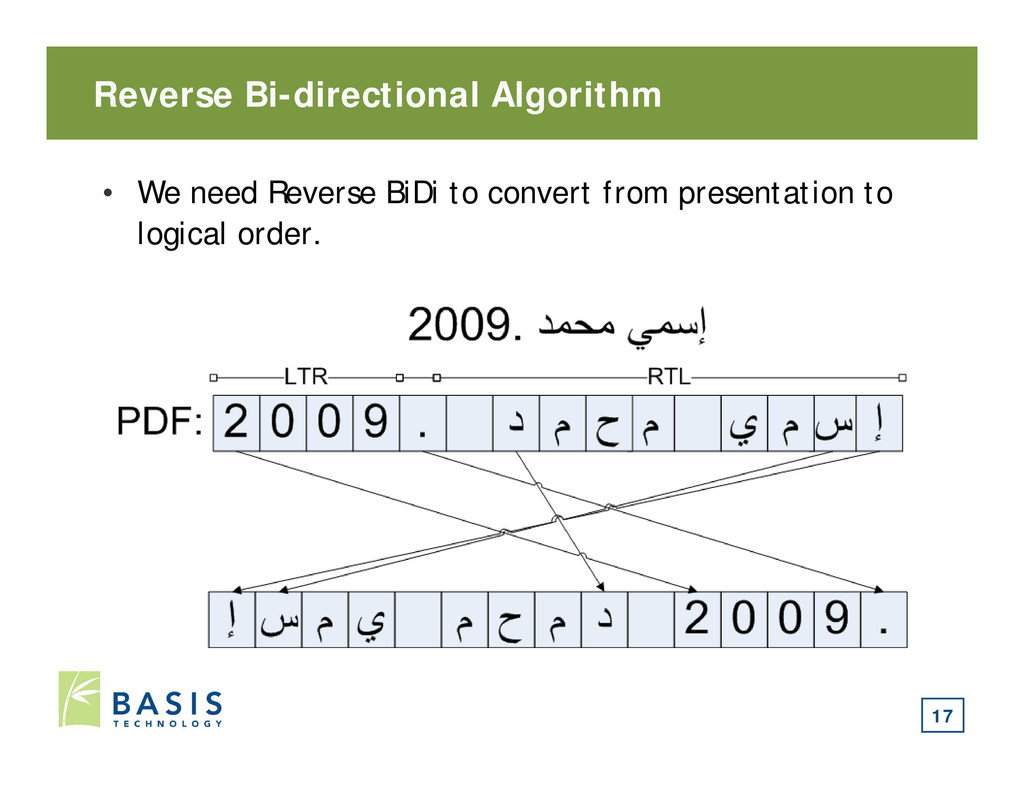
order. • Text editors need the text in logical order though. • Need to convert from presentation to logical order. • Obvious solution: • After decoding each line, reverse the order of the Arabic text: 13
characters and each should go in the correct direction • Unicode Bi-directional Text (BiDi) algorithm defines how to order characters in a paragraph based on: • Dominant direction of text in paragraph • Direction of each character in text • Punctuation and neighboring characters • Implicit direction markers • BiDi lets you convert from logical to presentation order. 16
content objects 2. Parse page content stream into text chunks 3. Sort text chunks based on coordinates 4. Determine dominant text direction 5. Process chunks in order and by line: 1. Get index for each character 2. Use font information to map index to Unicode 3. Add Unicode value to end of “presentation order” string 4. Apply reverse BiDi algorithm to “presentation order” string 18
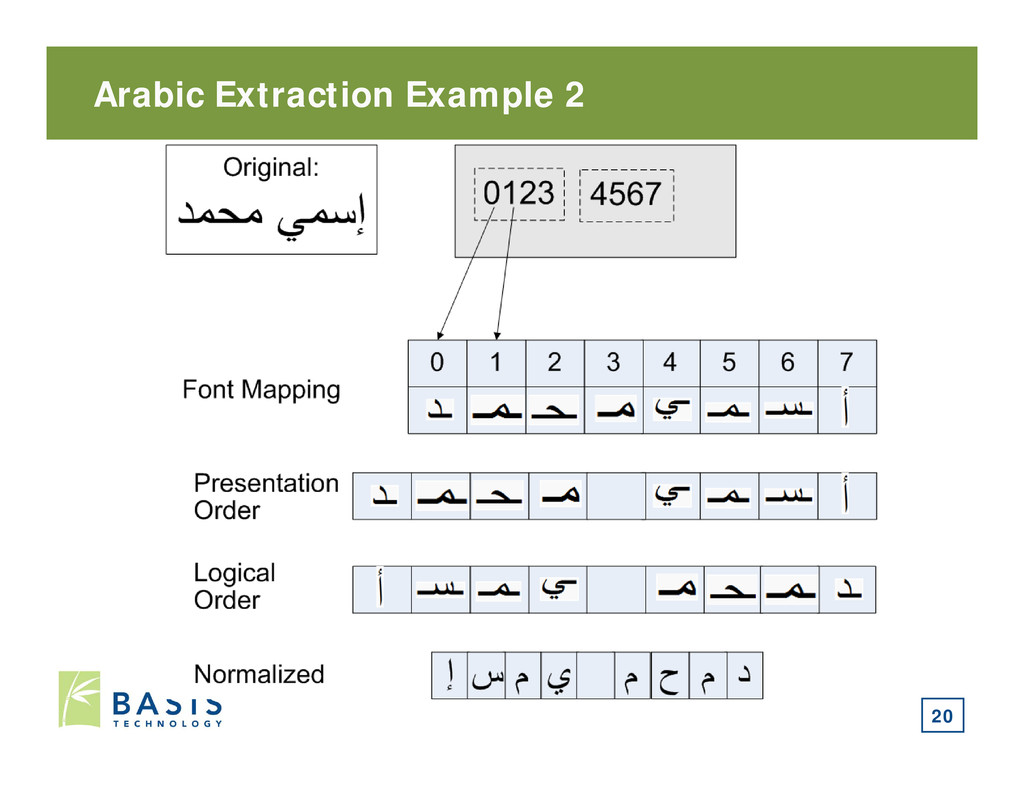
general form of Arabic characters. • Unicode is an exception. • The OS determines which glyph form to use (initial, medial, etc.) based on the context of the character. • PDF stores the specific form of each Arabic character. • Unicode presentation forms should not be used in a string and many tools cannot process them. • Need to normalize text from presentation to general forms 19
for Allah ( ﷲ). • The single ligature represents four characters: • “Alef, Lam, Lam, Heh”. • Some fonts implement the ligature differently: • “Lam, Lam, Heh” • They add a separate “Alef” before the ligature. • Alef (U+0627) Allah(U+FDF2) • When decomposing using Unicode specs: • “Alef Alef Lam Lam Heh” 21
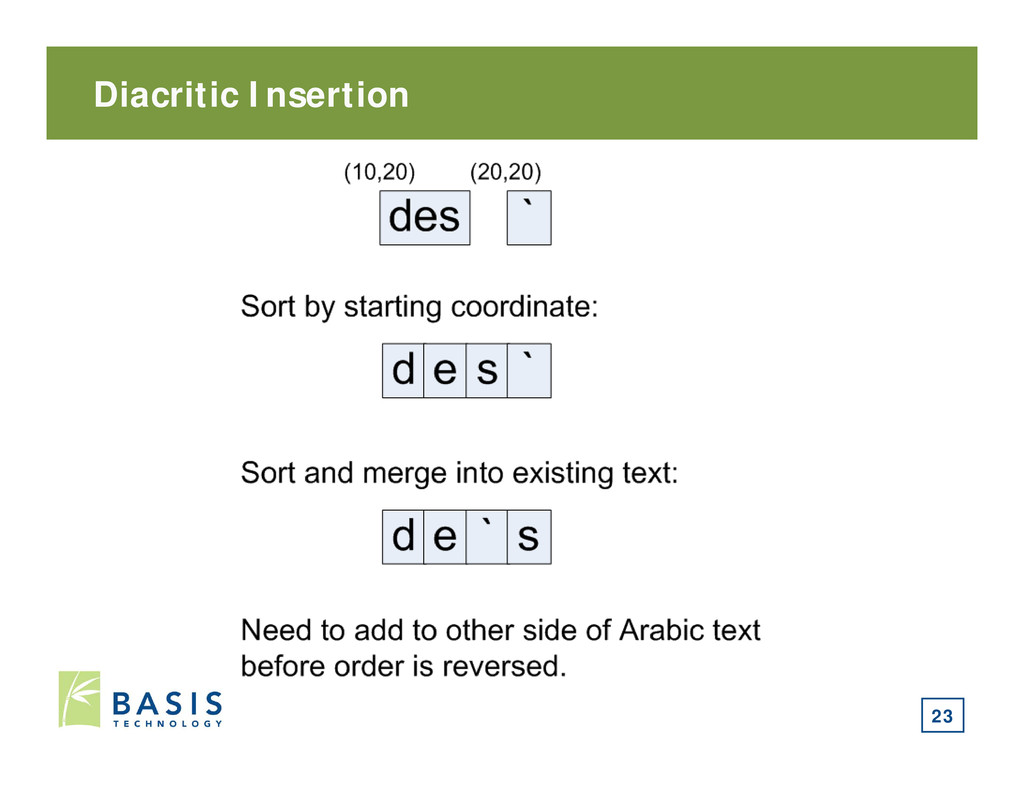
• With Unicode: • Diacritics are stored after the base character in logical order • Diacritics are placed over the base character when rendered on screen • With PDF: • Diacritics are stored in a separate text chunks • Coordinates cause them to overlap • Diacritic chunk can be before or after the chunk it modifies 22
• Spacing is achieved by direct placement of text. • Extraction requires guessing where spaces and newlines should exist. • Is this text chunk’s X-value further away then we expected? • Is this text chunk’s Y-value further away then we expected? • Spacing estimation can be done by keeping track of average character width thus far. • Newline estimation can be done by keeping track of character heights. 24
• It worked well for many documents in LTR languages • We enhanced it to: • Correct direction of RTL text • Normalize ligatures and presentation forms • Merge diacritics into text • Better estimate where to add spaces • Fix parsing issues • Deal with corrupt / non-compliant files • Can be freely downloaded (in next release): http://incubator.apache.org/pdfbox/ 25
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}