It consists of multiple files – o tracks.csv o echohonest.csv o genre.csv ◎ Original Data was scraped from Free Music Archive (FMA) and Echohonest (Now Spotify)
had multiple .csv files which contained information about songs, its features and genres 2. Cleaning the Data Since the data was huge in size, there was a lot of data cleaning to be done without losing anything 3. Preparing the Data The files had linking columns such as Track_ID and Genre_ID Tracks – Information about the track ID, track interest, track duration Genre – Information about the various genres Echohonest (now Spotify) – contains details about song’s features such as danceability, song hotness, valence etc.
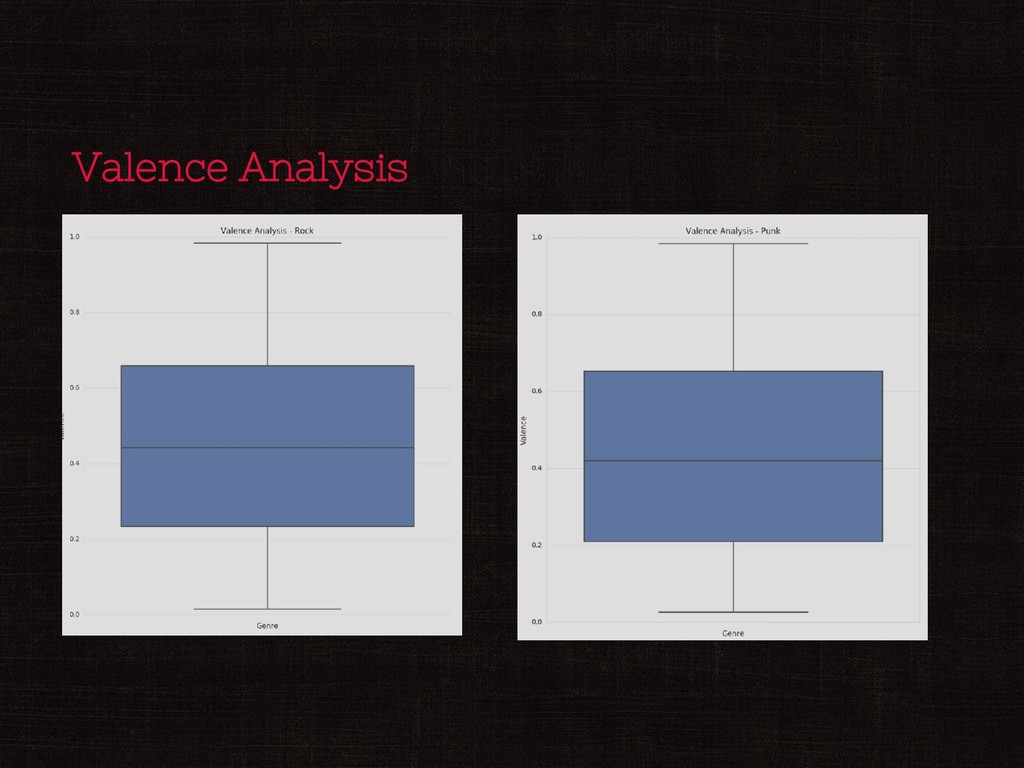
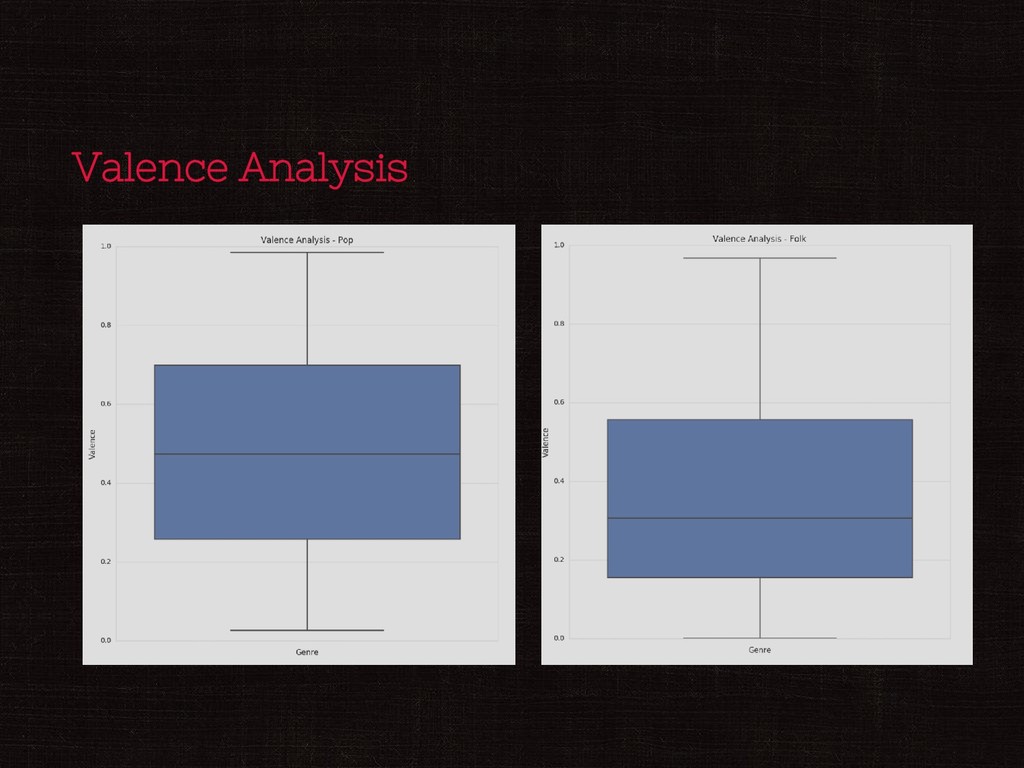
Acousticness and Instrumentalness are negatively correlated ◎ Speechiness and artist hotness are positively correlated II) Analyzing popularity of a song Track Listens ◎ Artist familiarity is highly positively correlated ◎ Danceability and Energy are negatively correlated ◎ Track favorites and speechiness are positively correlated
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}