educa0onal gaming • Founder of Data Science Athens Meetup www.meetup.com/Data-Science- Athens/ • Author, Mastering Predic2ve Analy2cs with R (I’m signing a few free copies tomorrow at lunch) • Instructor at MSc. Business Analy2cs at the Athens University of Economics and Business (AUEB) analy0cs.dmst.aueb.gr/
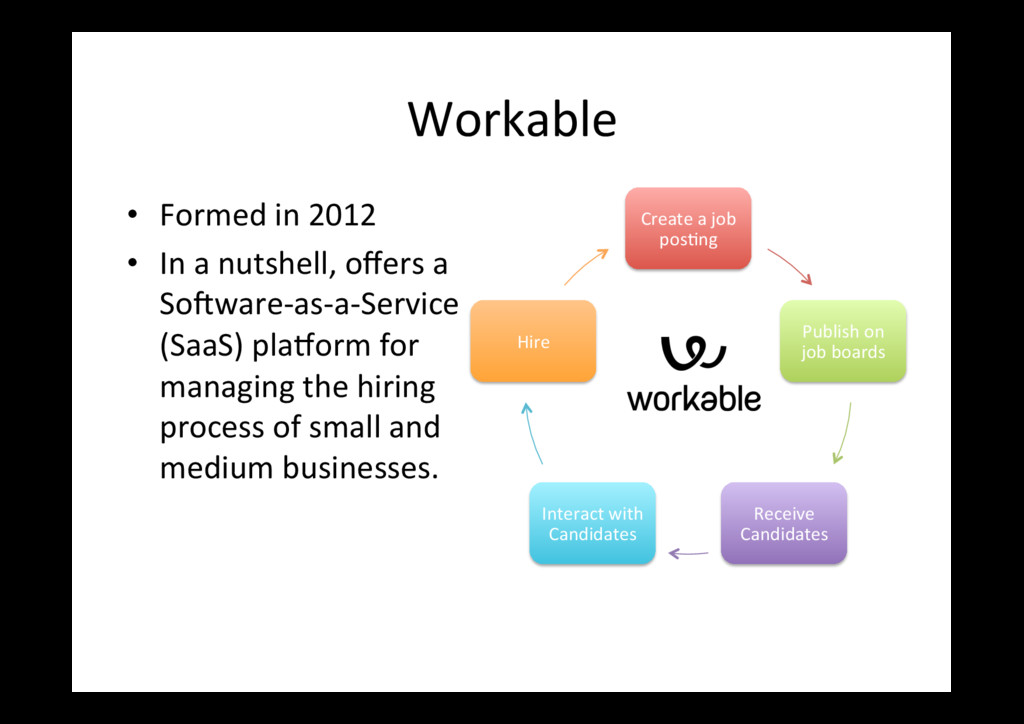
a SoWware-as-a-Service (SaaS) plaXorm for managing the hiring process of small and medium businesses. Create a job pos0ng Publish on job boards Receive Candidates Interact with Candidates Hire
of candidates who have applied to hundreds of thousands of jobs across a wide array of industries in many different countries • Massive opportuni0es for data science: – Iden0fying duplicate candidates applying for the same job – Matching candidate profiles to jobs – Matching job pos0ngs to relevant job boards – Detec0ng spam (job ads, candidates etc…) – Crea0ng structured candidate profiles from unstructured data such as CVs – Finding and merging data from sources such as social profiles – Classifying documents (CVs, cover le]ers etc…)
to power features from be]er search to recommenda0ons • Most users can fill in an online form or apply with their LinkedIn account, but the CV is not dead – Many recruiters operate with CVs with obfuscated candidate details – Clients oWen have a databank of CVs from candidates who applied in the past – Some people simply prefer to submit their CV
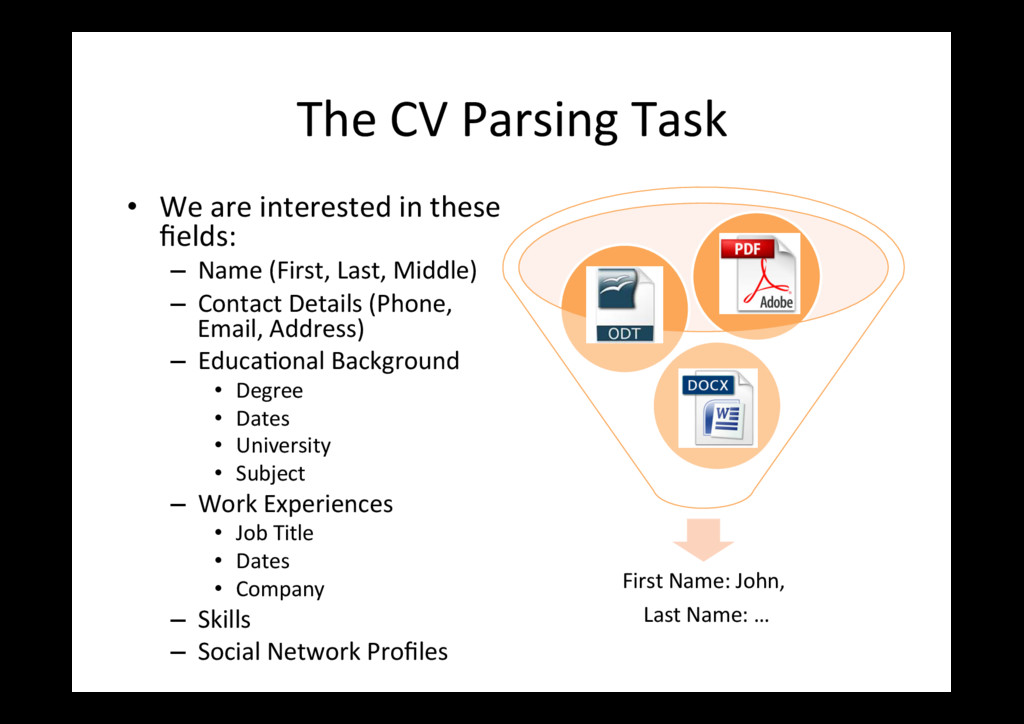
fields: – Name (First, Last, Middle) – Contact Details (Phone, Email, Address) – Educa0onal Background • Degree • Dates • University • Subject – Work Experiences • Job Title • Dates • Company – Skills – Social Network Profiles First Name: John, Last Name: …
– Tables oWen cause this, as does unusual layout, word art – This is especially bad if sentences change sec0on or if sentences get split up • Headers and footers may appear interspersed in the text • Layout/markup informa0on is lost • Characters may be altered (accents), repeated (strangely enough), spaced out (due to weird fonts or markup), lost (due to encoding issues), inserted (usually due to encoding issues)
of badly extracted text e.g. R u i M i g u e l F o r t e => Rui Miguel Forte • Currently inves0ga0ng ways to detect other problems such as badly extracted tables
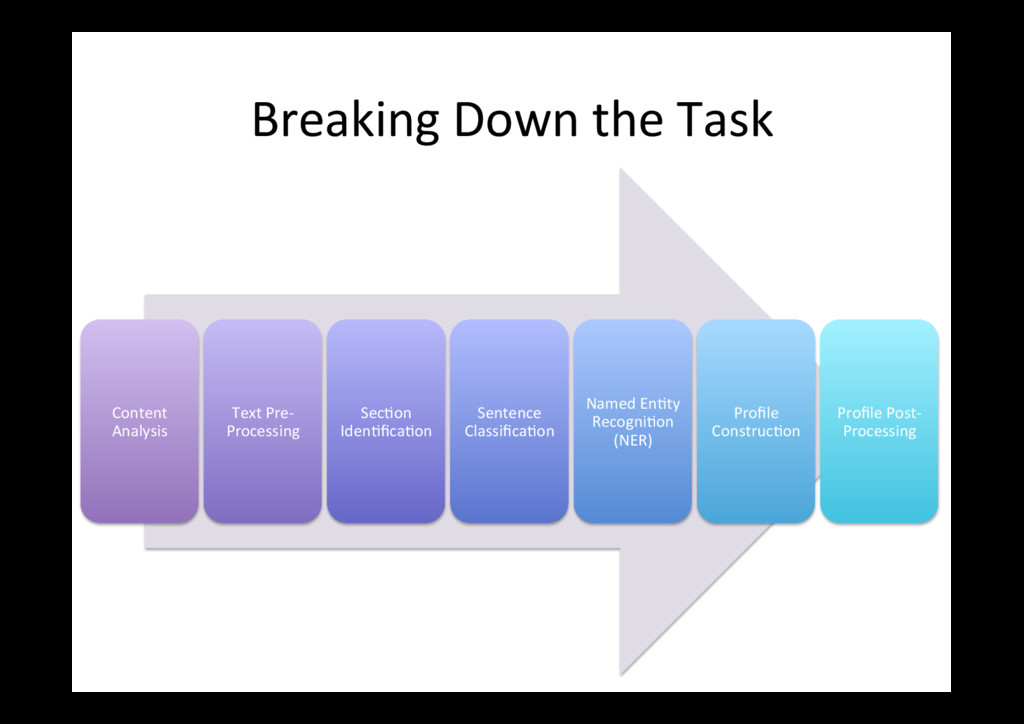
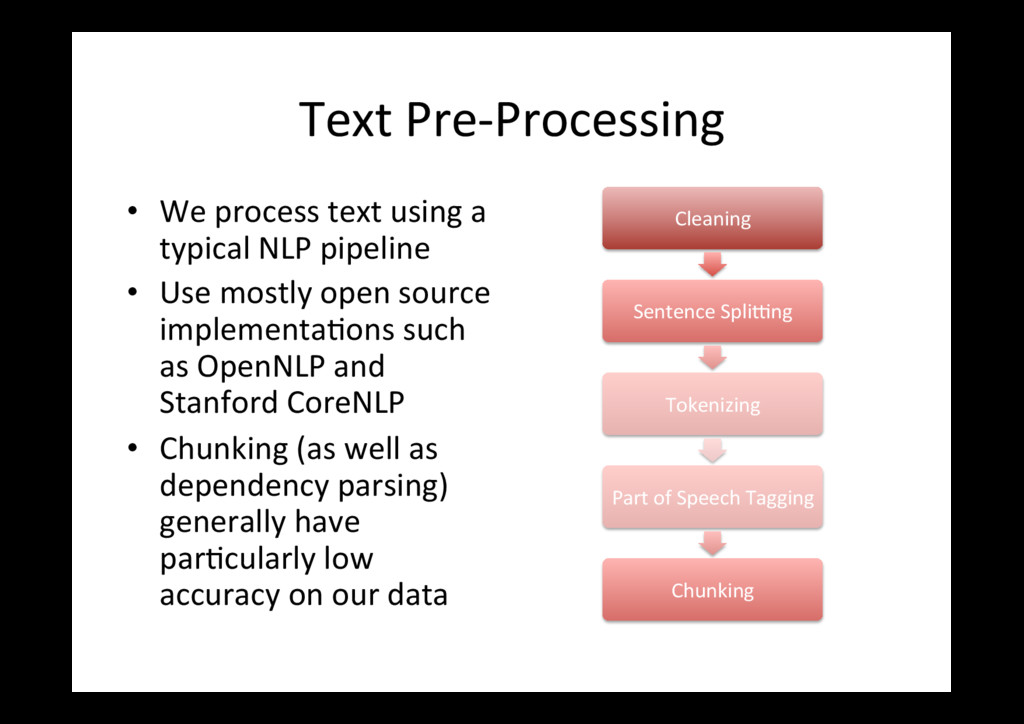
pipeline • Use mostly open source implementa0ons such as OpenNLP and Stanford CoreNLP • Chunking (as well as dependency parsing) generally have par0cularly low accuracy on our data Cleaning Sentence Splidng Tokenizing Part of Speech Tagging Chunking
usually trained on gramma0cal sentences from curated corpora. • CVs: – Are ungramma0cal and oWen have many typos – Have many headlines / fragments (incomplete sentences) – Have a large propor0on of proper nouns • Sentence splidng is tricky – we want to keep related en00es on same sentence but they may be separated by a lot of whitespace. • Training new models is difficult and expensive
extensive experience in managerial restructuring. Educa2on BA Human Rights, University of King’s Landing Experience Queen Regent, King’s Landing - Managed a large team of guards and knights for keeping the King’s peace - Taught leadership skills to King Geoffrey, First of his Name, King of the Andals, the Rhoynar and the First Men, Lord of the Seven Kingdoms and Protector of the Realm (contract expired)
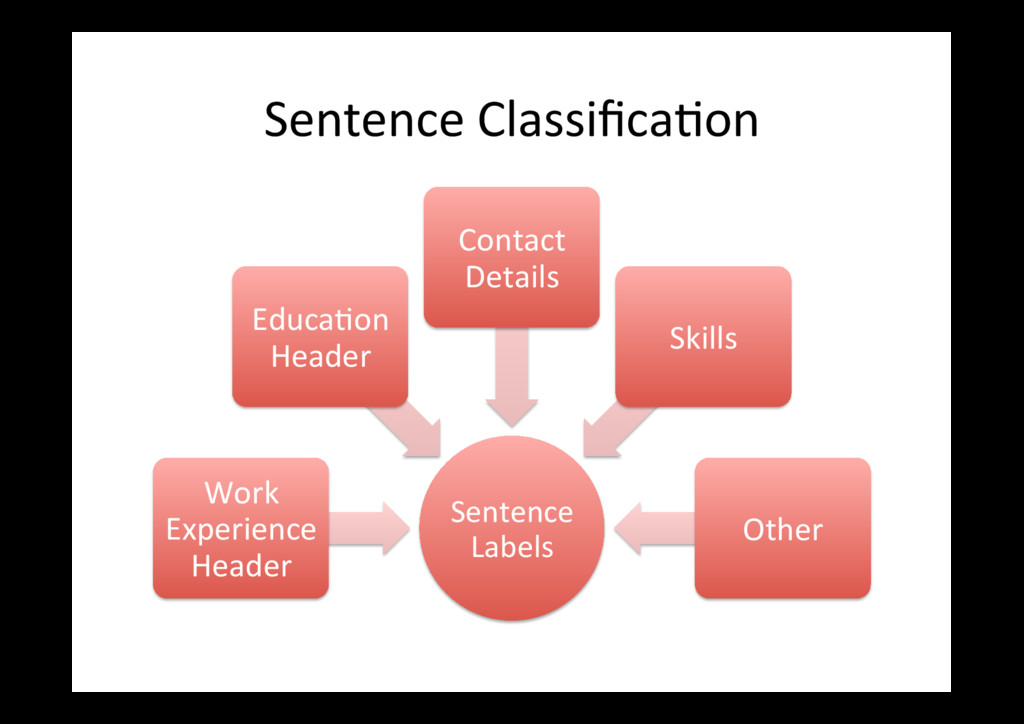
the few sec0ons we are interested in we need to know about many different sec0ons – A sec0on ends where another begins! • Second Key Idea: This could be a great feature on its own! – Computer-assisted data entry – Be]er search (weighing terms and phrases in relevant sec0ons) • We generally iden0fy headers using regular expressions e.g. ((Tertiary|Higher)\s+)?Education| (Academic|Educational)\s+Qualifications
want is concentrated on a small number of sentences • We build models (currently SVM based) using annotated CVs that classify each sentence in a CV into one of a set of labels – The features we use include things like capitaliza0on, spacing, POS features, presence of par0cular words (Bag of Words) features, as well as sec0on informa0on
task of finding par0cular en00es such as the names of people or organiza0ons in text Team Lead – Customer Relations Oct 2008 – Dec 2009 (Azdecca Co.) Key: Job Title Date Organiza4on
you need to get both en0ty boundaries and labels correctly. • We have had li]le success with exis0ng tools such as AlchemyAPI, OpenNLP etc… – They are trained on high quality text from a different domain – They some0mes don’t even have some of the labels we want
NER by hand using a mixture of regular expressions and lookup lists – These then become features of an ML based approach – Companies (Organiza0ons) turn out to be by far the hardest en00es to dis0nguish properly – Depending on how strict your rules are you can balance precision and recall • In our case, we can also use informa0on about what the label is for the current sentence – Of course the sentence classifica0on task could benefit if we knew what en00es it incorporated so this is a chicken and egg problem – We are considering a joint model for these two tasks
into details of Condi0onal Random Fields and other sequence predic0on models we compare when training on our data – What is more interes0ng is the data we are collec0ng • Feature design is more cri0cal and in our case it is especially tricky because NER is so far down the pipeline – Very noisy input features (badly extracted text, wrong tokeniza0on, wrong POS tagging, wrong parsing) – Rely on coarser features that are more reliable • Obtaining annotated data is resource intensive and very error prone but can be well worth the effort
given detailed guidelines with plenty of examples – We have a forty page manual … – … which we constantly revise and maintain • Split training data in batches – This allows changes to the annota0on methodology • Have a lot of redundancy – We use three-way annota0on for all our data • Start building models early! Do not wait 0ll you get what you feel will be enough data – This will guide decisions on the data that we need to get – We are considering ac0ve learning
skill is very tricky – Few domains (IT in par0cular) have well defined skills • Industries, products, processes, areas of knowledge, foreign languages, character a]ributes, even job 0tles appear as skills • A journalist might say “Newspapers”, a musician “Clarinet”, an HR professional “CVs”, a project manager “out-of-the-box thinking” • Building a taxonomy of skills is unfortunately mostly a manual process – e.g. we took the unique skills from all our candidates who applied from LinkedIn. On a random sample, < 1% were normalized and unambiguously iden0fiable as skills
and and discovered the relevant named en00es we construct the profile • We’ve trained models for picking out the best candidates for informa0on such as name and email for which there is only 1 correct answer • We use simple rules to iden0fy related en00es (e.g. job 0tles with companies ) in order to form complex elements – We can use a simple slot filling approach if our sentence classifica0on works well – En0ty rela0on models are a future op0on
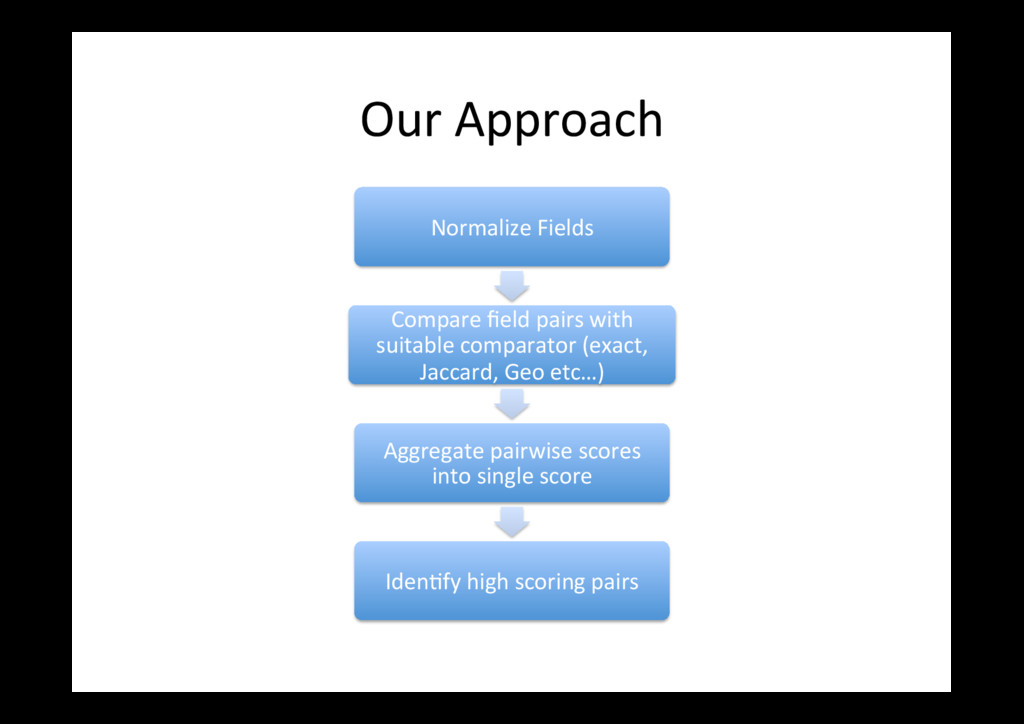
involves: – Fixing appearance e.g. mr. p k chang => P. K. Chang – Finding standard form of known en00es: Imperial => Imperial College London Python Programming => Python • Normaliza0on is very important – Improved visualiza0on – Improved searchability – Be]er profile comparison for de-duplica0on, recommenda0ons • Filtering prunes out components that seem too sparse – e.g. work experiences with just a job 0tle in them – Also acts as an error correc0on step
people • Fields can change (address, phone, name) or have many valid op0ons (email, phone) • Data can be presented in different ways: Rui Miguel Forte R. M. Forte Forte, Rui Miguel RUI M. FORTE Ρούι Μιγκέλ Φόρτε (my name in Greek)
for both performance and overfidng – e.g. we discovered certain company names as frequent when looking for fraudulent job descrip0ons • Watch memory footprint – e.g. In the sentence classifica0on problem we first had features computed for every sentence before classifying all of them • Do not go with ML if you can get high accuracy with hand craWed systems (rules, regexes etc…) – e.g. Often for a data fusion problem you know exactly the rules you want – e.g. Language detec0on in CVs can be done well with just a lookup of key terms we expect to find in CVs
Removing Accents from names makes it easy to look them up e.g. François => Francois – Look for field specific transforma0ons which could be rules, or lookups against a standard en0ty such as the name of a company – It is *far* be]er to have a simple ML model that compares normalized text than a more complex one on un-normalized text
design decisions. – We had marginally be]er performance with Random Forests when we did sentence classifica0on but they require a lot more memory so we went with SVMs instead. – We had a deduplica0on model that used name variants (Nikos / Nikolaos, Pavlos / Pavel, Jim / James) but ended up making too many comparisons for very li]le gain • When building models, reproducibility is essen0al but is oWen overlooked / not properly planned. – A copy of the data you used in the experiment – The source code you used to compute par0cular features – The actual results of the experiment for verifica0on and cross checking
benchmark data sets for all the tasks you use – We use several data sets with thousands of CVs – Benchmark suites can be used as part of con0nuous integra0on • Maintain a product perspec0ve at all 0mes – Build things that are useful to the business – Deliver features incrementally e.g. CV parsing has several useful intermediate steps such as contact details extrac0on, sec0on iden0fica0on
Python these are pre-compiled, make sure you manually do this in languages like Java – Take care to avoid issues such as catastrophic backtracking • Test. Extensively. Aggressively. And Profusely. – Feature computa0ons, accuracy metrics etc… – Can even write smoke tests for trained models using easily predicted examples
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}