Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[CNDT2020]リーガルテックの機械学習基盤を支えるクラウドネイティブ技術の実践
Search
rupy
September 09, 2020
Programming
800
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[CNDT2020]リーガルテックの機械学習基盤を支えるクラウドネイティブ技術の実践
rupy
September 09, 2020
Other Decks in Programming
See All in Programming
AI 輔助遺留系統現代化的經驗分享
jame2408
1
780
Javaの型とAI時代に型が大事な理由 / java types and type in AI era
kishida
2
140
LLMによるContent Moderationの本番運用の裏側と品質担保への挑戦
suikabar
3
710
気づいたらRubyで100作品 ー クリエイティブコーディングが生活の一部になるまで / 100 Ruby Sketches Later: How Creative Coding Became Part of My Life
chobishiba
3
590
TypeScript+Orvalで実現する型安全かつ堅牢でスケーラブルなマルチチャネル通知基盤 / TSKaigi Night talks ~after conference~
d0riven
0
350
DynamoDBには集計系のクエリがないけどなんとかしたい
musan
1
180
Developing with AI Agents — Codex, Claude Code & Cowork Practical Guide
x5gtrn
PRO
0
1.3k
ECSアプリログをFireLensでコスト削減しようとしたけど諦めた話 in Fargate×Node.js
akihisaikeda
2
4.2k
代数的データ型って何が嬉しいの? #frontend_phpcon_do
kajitack
8
3.7k
AIで効率化できた業務・日常
ochtum
0
140
フロントエンドとバックエンドで「1文字」を揃えよう
youkidearitai
PRO
0
710
PHPで使える日時の表現と、その知り方 #frontend_phpcon_do
o0h
PRO
0
260
Featured
See All Featured
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.6k
Making Projects Easy
brettharned
120
6.7k
Amusing Abliteration
ianozsvald
1
210
The SEO Collaboration Effect
kristinabergwall1
1
490
AI: The stuff that nobody shows you
jnunemaker
PRO
8
720
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
390
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
200
The Spectacular Lies of Maps
axbom
PRO
1
820
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
620
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Transcript
リーガルテックの 機械学習基盤を⽀える クラウドネイティブ技術の実践 株式会社LegalForce ⾈⽊ 類佳
⾈⽊ 類佳 株式会社LegalForce 執⾏役員 兼 最⾼研究開発責任者(CRO: Chief R&D Officer) 経歴:
元 東京大学情報理工学系研究科 中山英樹研究室(修士) 元 株式会社リクルート 出身:広島県→島根県 技術:Web開発、スマートフォン開発、ゲーム開発、 クラウドインフラ、自然言語処理、画像認識、機械学習等 趣味:ピアノ、ドラム、作曲 !SVLB@GVOBLJ
本⽇の流れ • 契約書レビュー⽀援サービス「LegalForce」 • LegalForceでの開発体制 • 機械学習における種々の課題 • 機械学習基盤(MLOps)構築による課題解決 •
LegalForceにおける機械学習基盤(MLOps)構築事例 • 機械学習基盤(MLOps)を通して
None
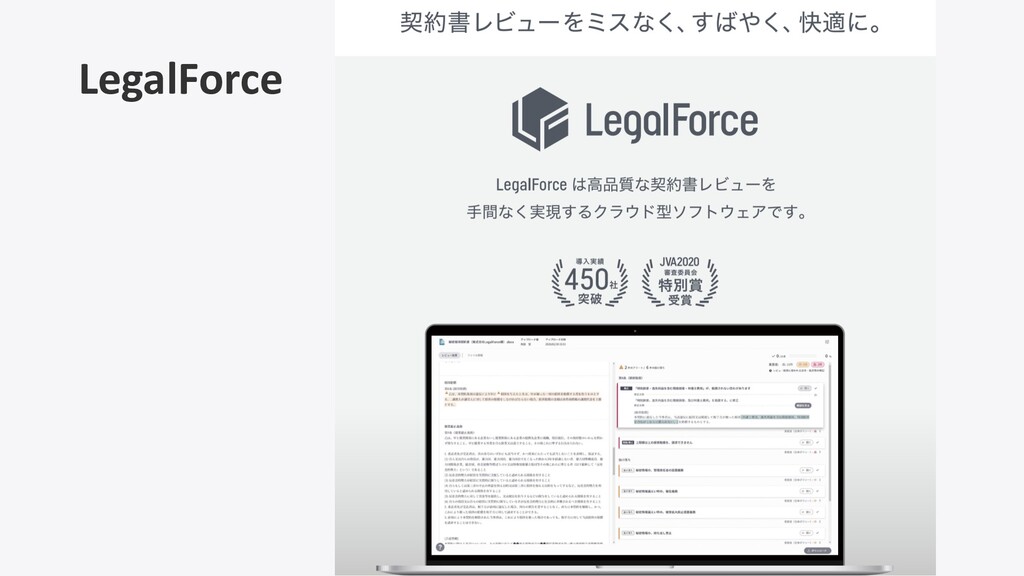
契約書レビュー⽀援システム 「LegalForce」
株式会社LegalForce
⽇⽐⾕の会社です 外観 フリースペース
リーガルテックの会社です 法律 テクノロジー
となりに法律事務所があります • 創業者2⼈がLegalForceと同時に⽴ち上げた法律事務所 • 弁護⼠軍団(実際のユーザー)がすぐそばに!
⾃然⾔語処理の会社です
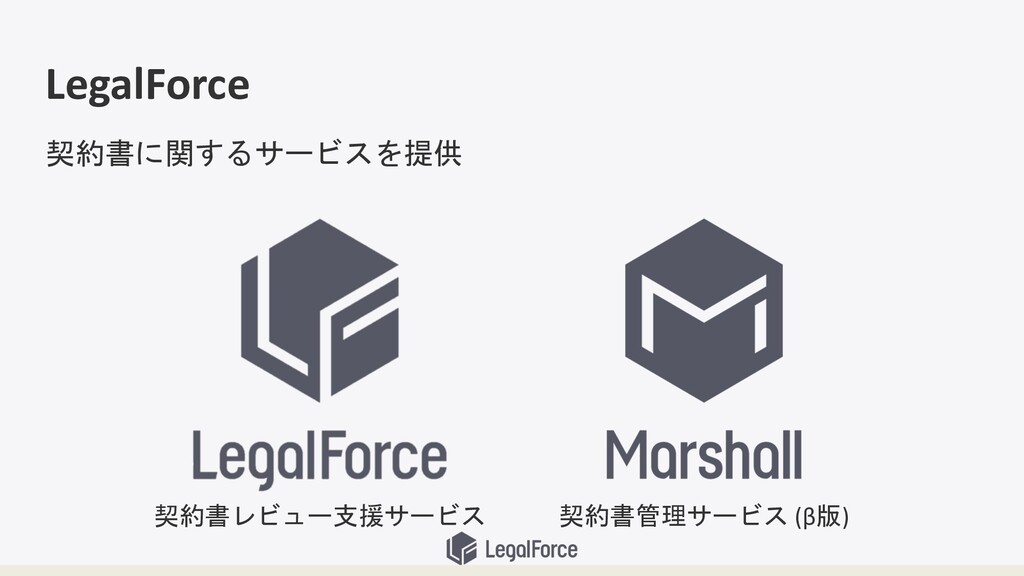
契約書を扱っています
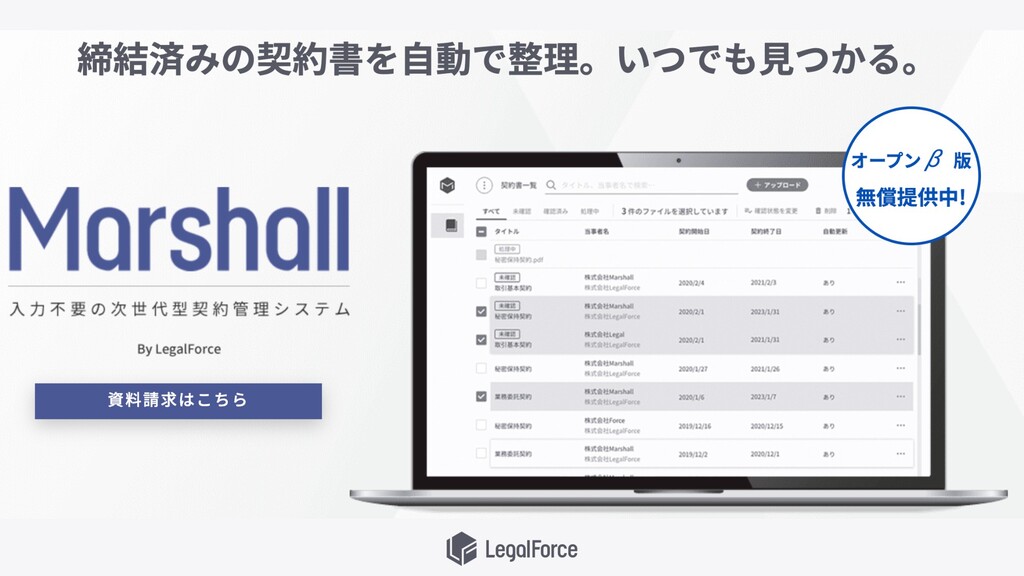
LegalForce 契約書管理サービス (β版) 契約書に関するサービスを提供 契約書レビュー支援サービス
LegalForce
None
契約書を印刷をしてレビュー
None
None
None
None
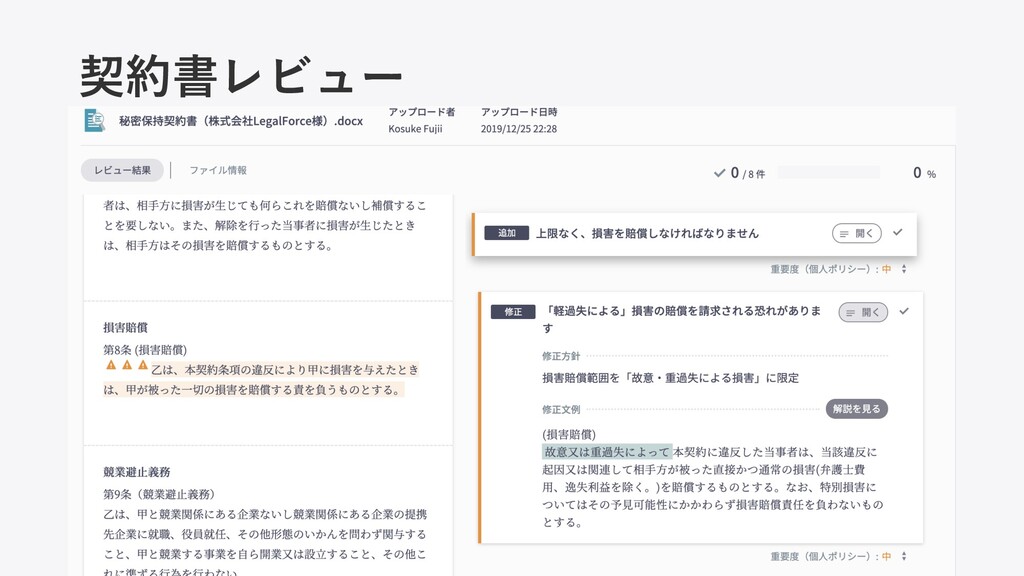
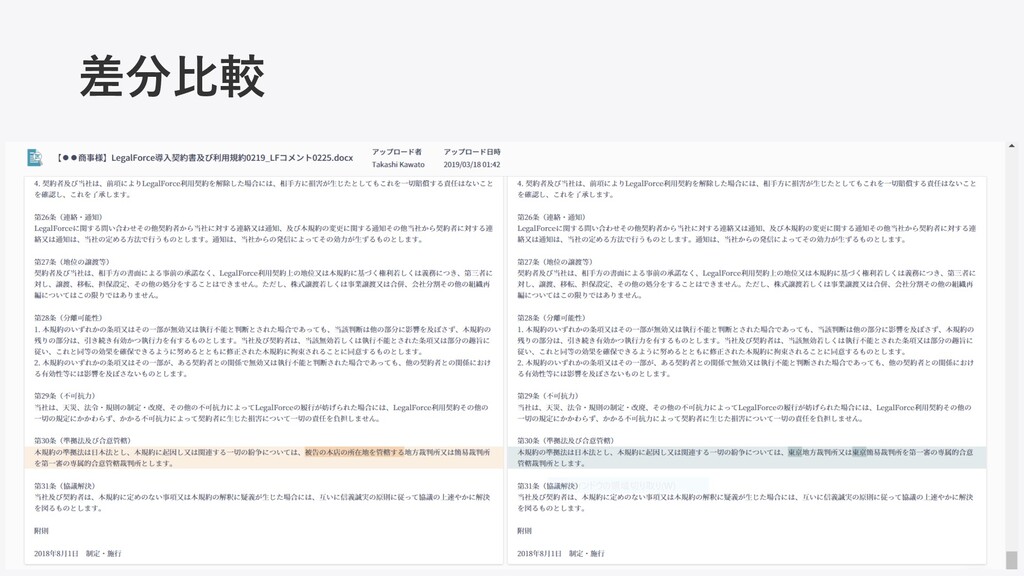
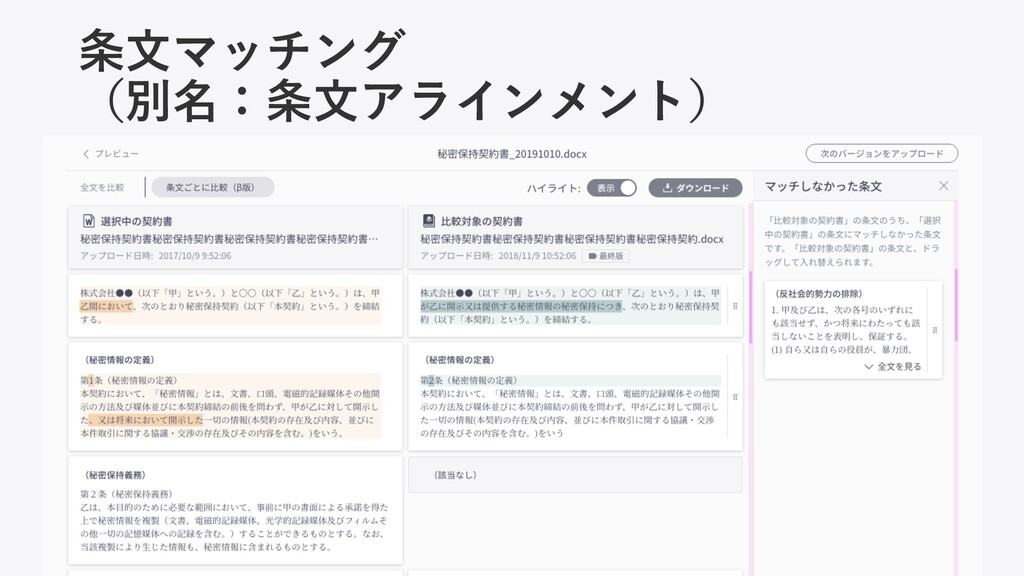
LegalForceの機能(⼀部)
契約書レビュー
契約書条⽂検索
差分⽐較
条⽂マッチング (別名:条⽂アラインメント)
LegalForceの開発体制
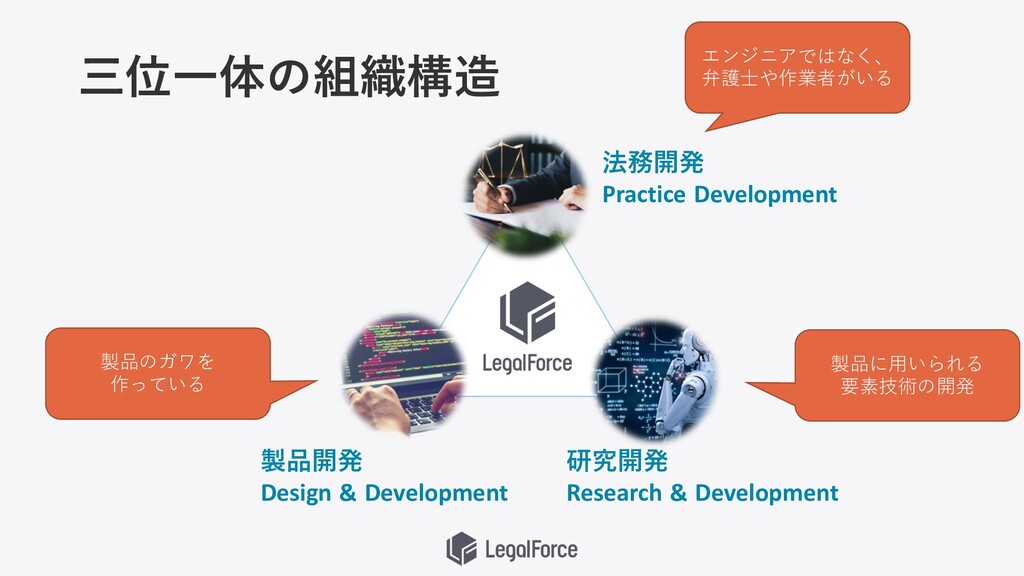
三位⼀体の組織構造 法務開発 Practice Development 製品開発 Design & Development 研究開発 Research
& Development エンジニアではなく、 弁護⼠や作業者がいる 製品のガワを 作っている 製品に⽤いられる 要素技術の開発
LegalForceの研究開発 • 契約書⾔語処理を中⼼とした データに関わる要素技術の研究、 及び開発を実施 研究開発 Research & Development
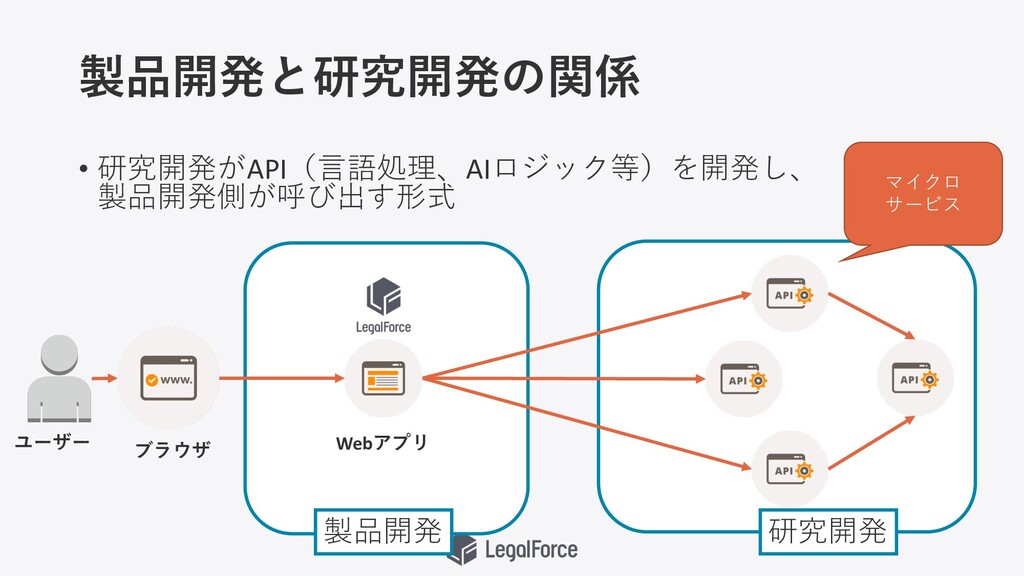
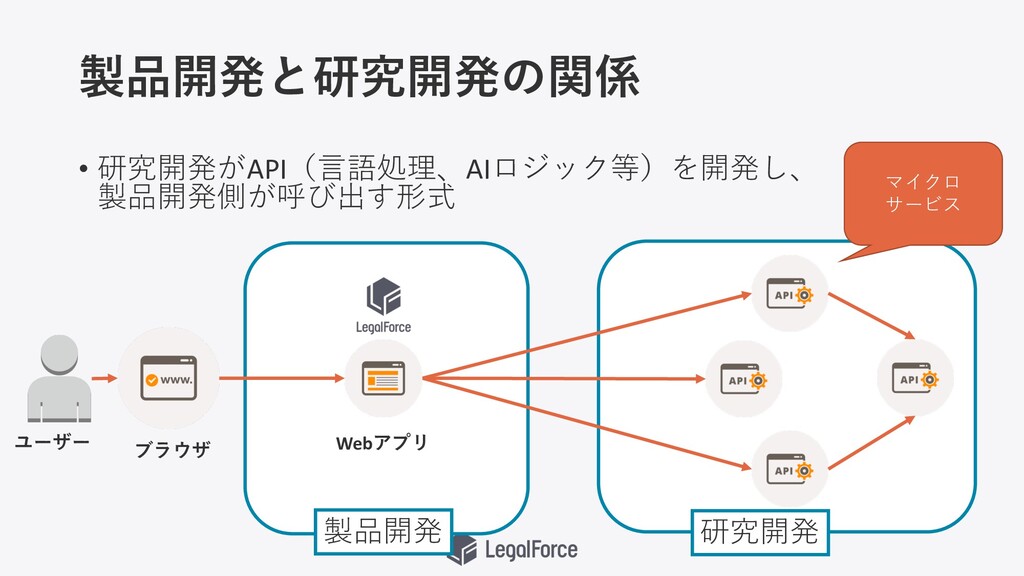
製品開発と研究開発の関係 • 研究開発がAPI(⾔語処理、AIロジック等)を開発し、 製品開発側が呼び出す形式 製品開発 研究開発 ユーザー マイクロ サービス ブラウザ
Webアプリ
LegalForce R&D Zoo AIや契約書⾔語処理などに代表される LegalForceの研究開発技術を、 動物と紐付けて紹介
検索 テキスト構造化 テキスト分類 レビュー データ変換 条⽂検索 ⽂書構造解析 ⽂書分類 検査 PDF変換
Word変換 条ラベリング ⽂分割 類似⽂書推薦 差分⽐較 OCR ⾔語認識 ⽂書検索 情報抽出 権利義務抽出 LegalForce R&D Zoo(1/2) 条アラインメント 情報抽出 表抽出 ⽐較 改⾏位置予測 クエリ⾃動補完 OCR後修正 データ変換後処理 編集⽀援 校閲 ライティング⽀援 ファイルクローラー クローラー
LegalForce R&D Zoo(2/2) データ基盤 契約書アノテーション基盤 評価基盤 データ基盤 データパイプライン アプリケーション基盤 ノートブック
機械学習基盤 アプリケーション基盤 検索基盤 アノテーション基盤 BI・可視化 汎⽤アノテーション基盤 検索基盤 契約書匿名化 契約書匿名化 マスターデータ管理 オントロジー データカタログ ID基盤 学習基盤 モデルサービング セキュリティ 機密データ保護 監視 システム監視
None
機械学習おける種々の課題
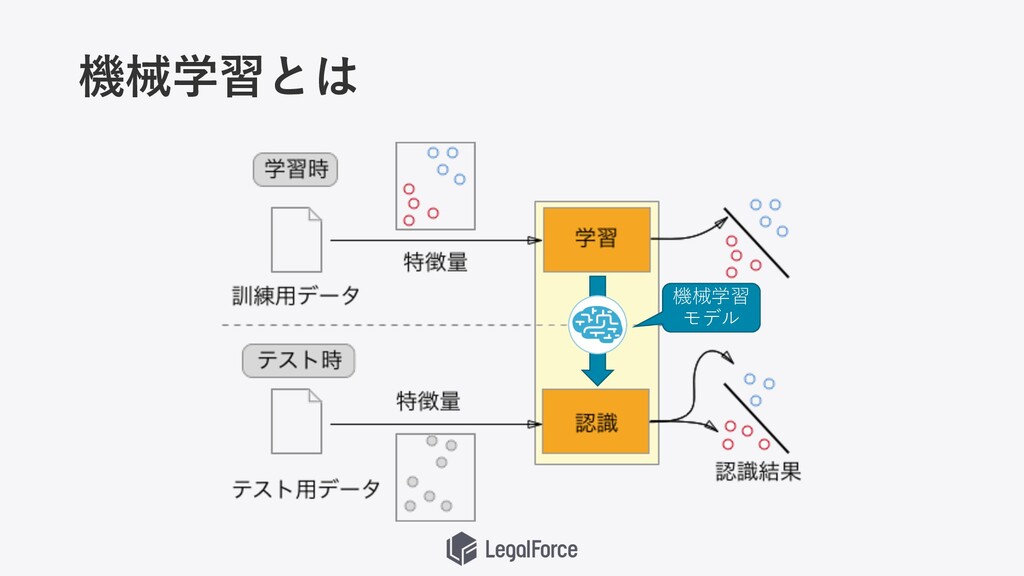
機械学習とは 機械学習 モデル
機械学習をビジネスに活⽤したい
フレームワーク・ライブラリ を利⽤して記述するだけ?
フレームワーク・ライブラリ を利⽤して記述するだけ?
機械学習サービスを開発するために 機械学習以外で考えることが多い
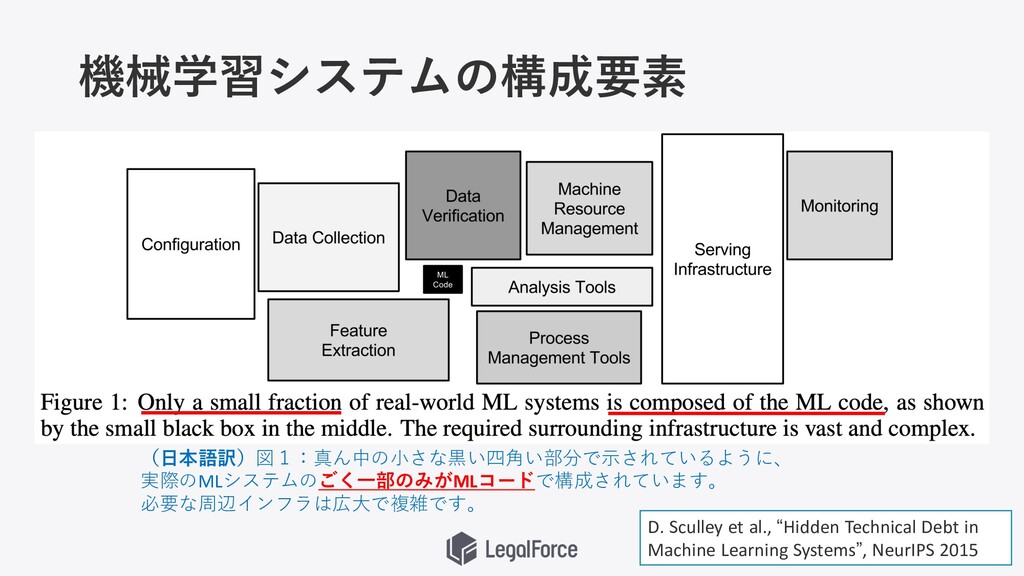
機械学習システムの構成要素 • 機械学習以外の部分の要素が⾮常に⼤きい D. Sculley et al., “Hidden Technical Debt
in Machine Learning Systems”, NeurIPS 2015 (⽇本語訳)図1:真ん中の⼩さな⿊い四⾓い部分で⽰されているように、 実際のMLシステムのごく⼀部のみがMLコードで構成されています。 必要な周辺インフラは広⼤で複雑です。
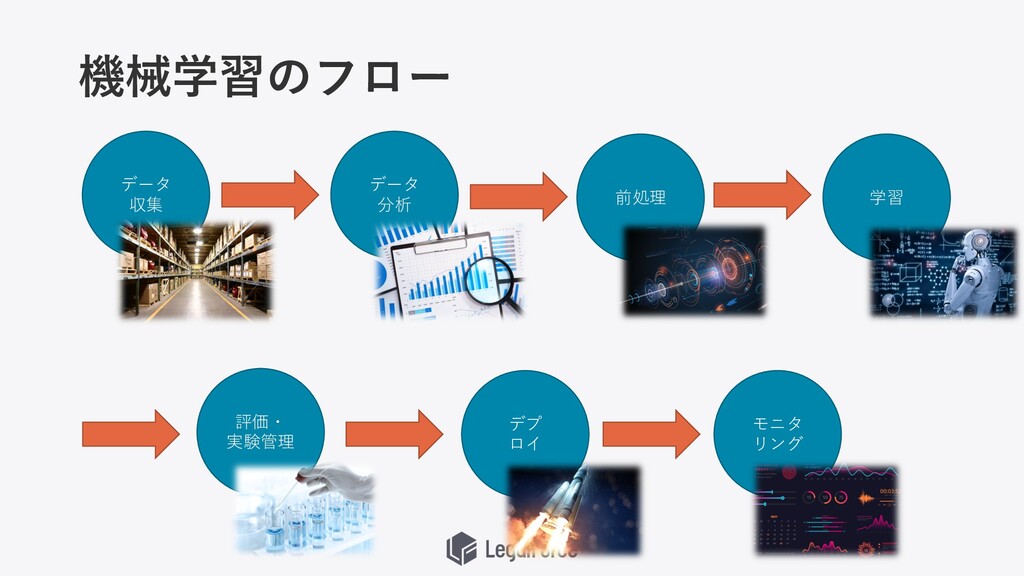
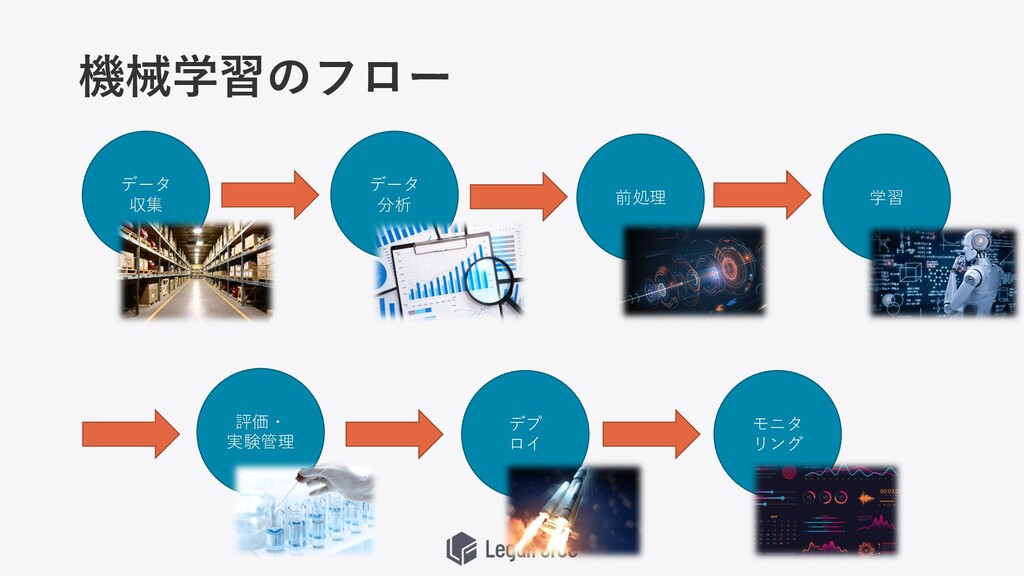
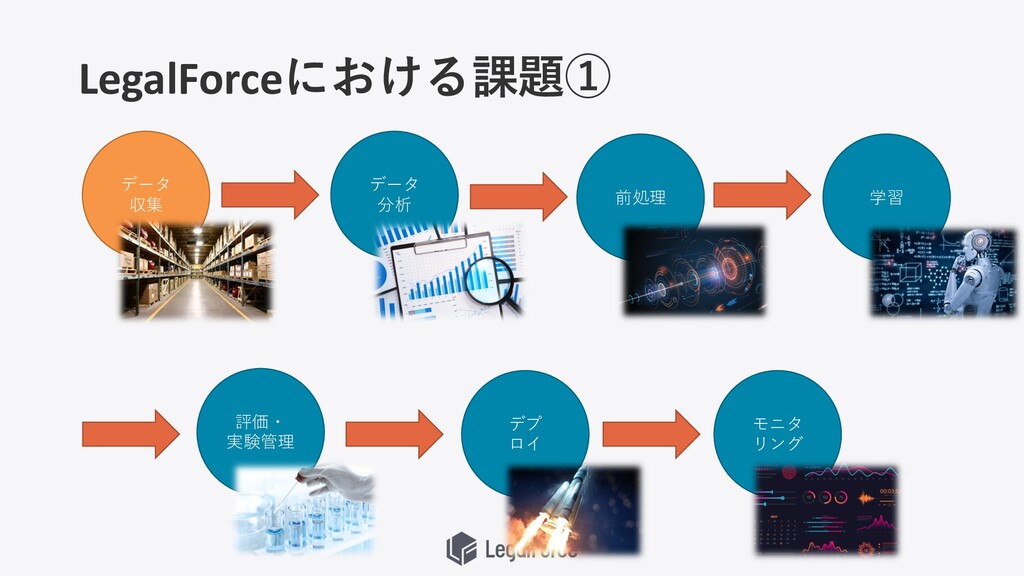
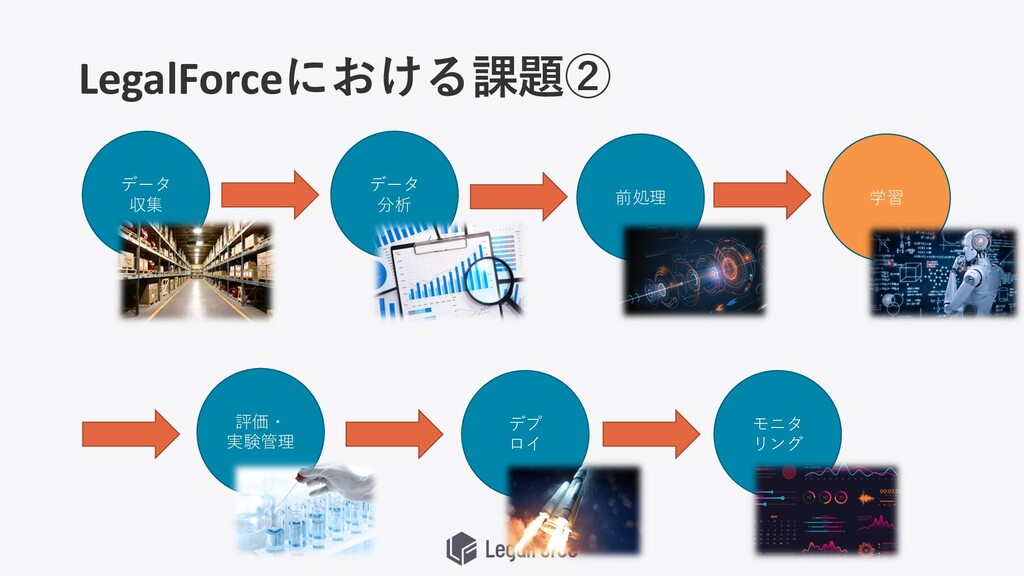
機械学習のフロー データ 収集 データ 分析 前処理 学習 評価・ 実験管理 デプ
ロイ モニタ リング
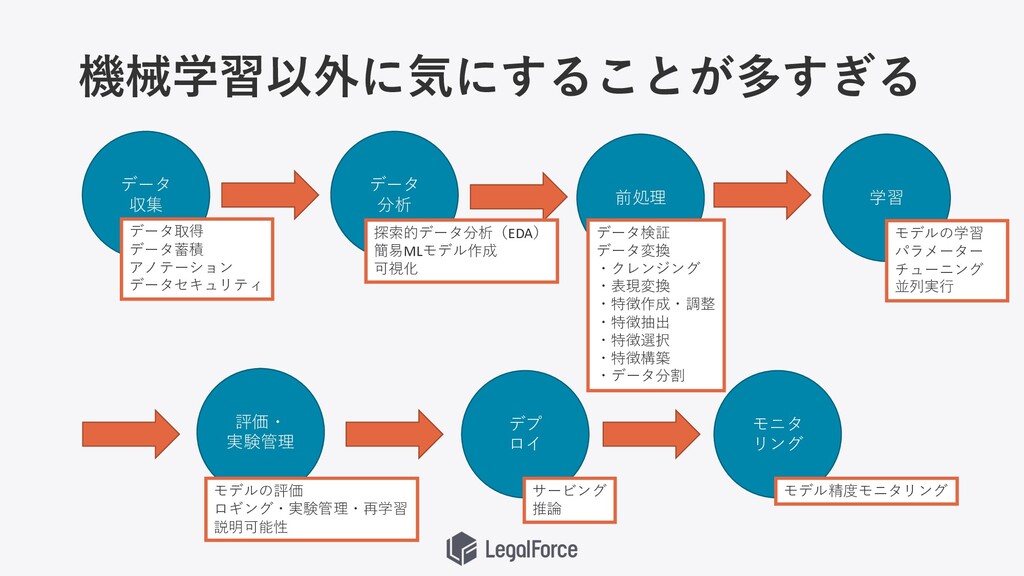
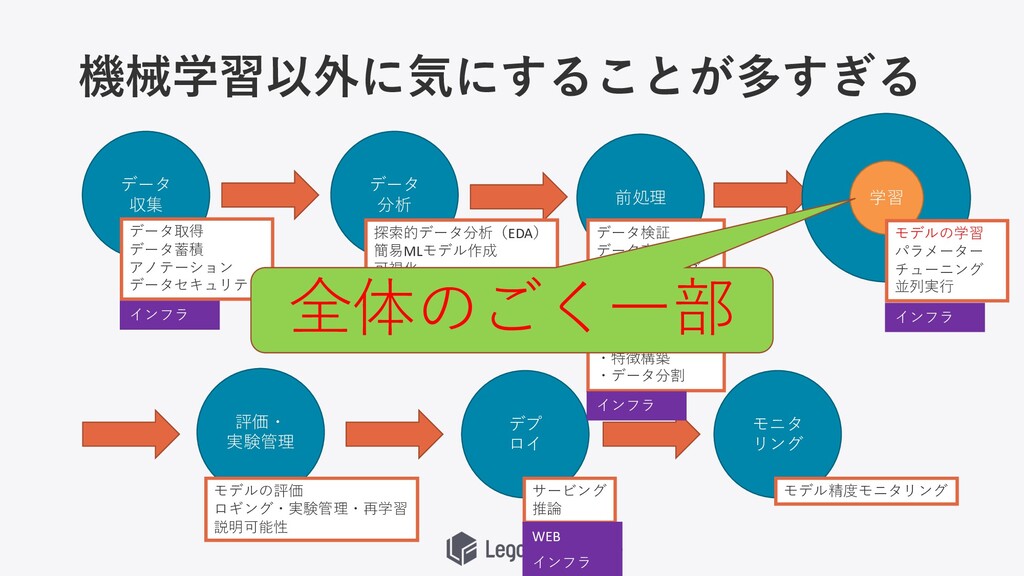
機械学習以外に気にすることが多すぎる データ 収集 データ 分析 前処理 学習 評価・ 実験管理 デプ
ロイ モニタ リング データ取得 データ蓄積 アノテーション データセキュリティ 探索的データ分析(EDA) 簡易MLモデル作成 可視化 データ検証 データ変換 ・クレンジング ・表現変換 ・特徴作成・調整 ・特徴抽出 ・特徴選択 ・特徴構築 ・データ分割 モデルの学習 パラメーター チューニング 並列実⾏ モデルの評価 ロギング・実験管理・再学習 説明可能性 サービング 推論 モデル精度モニタリング
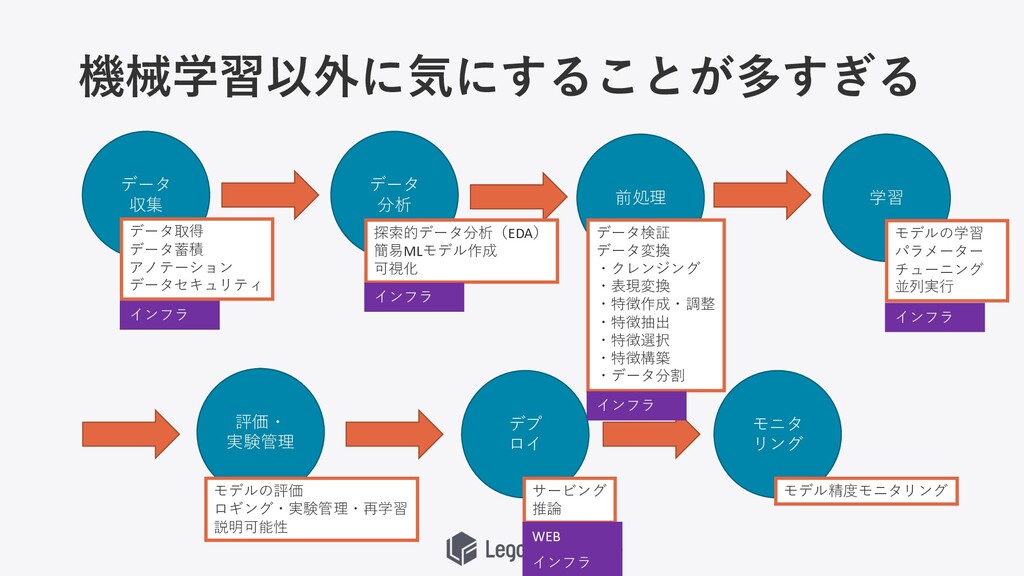
機械学習以外に気にすることが多すぎる データ 収集 データ 分析 前処理 学習 評価・ 実験管理 デプ
ロイ モニタ リング データ取得 データ蓄積 アノテーション データセキュリティ 探索的データ分析(EDA) 簡易MLモデル作成 可視化 データ検証 データ変換 ・クレンジング ・表現変換 ・特徴作成・調整 ・特徴抽出 ・特徴選択 ・特徴構築 ・データ分割 モデルの学習 パラメーター チューニング 並列実⾏ モデルの評価 ロギング・実験管理・再学習 説明可能性 サービング 推論 モデル精度モニタリング インフラ インフラ インフラ WEB インフラ インフラ
機械学習以外に気にすることが多すぎる データ 収集 データ 分析 前処理 評価・ 実験管理 デプ ロイ
モニタ リング データ取得 データ蓄積 アノテーション データセキュリティ 探索的データ分析(EDA) 簡易MLモデル作成 可視化 データ検証 データ変換 ・クレンジング ・表現変換 ・特徴作成・調整 ・特徴抽出 ・特徴選択 ・特徴構築 ・データ分割 モデルの評価 ロギング・実験管理・再学習 説明可能性 サービング 推論 モデル精度モニタリング インフラ インフラ WEB インフラ インフラ 学習 全体のごく⼀部 モデルの学習 パラメーター チューニング 並列実⾏ インフラ
機械学習基盤(MLOps)構築による 課題解決
MLOpsとは • DevOpsの考え⽅を 機械学習(ML)に適応させたもの。 • 機械学習システムの • 継続的インテグレーション(CI) • 継続的デリバリー(CD)
• 継続的トレーニング(CT) • 継続的評価(CE) 等を含む MLOps
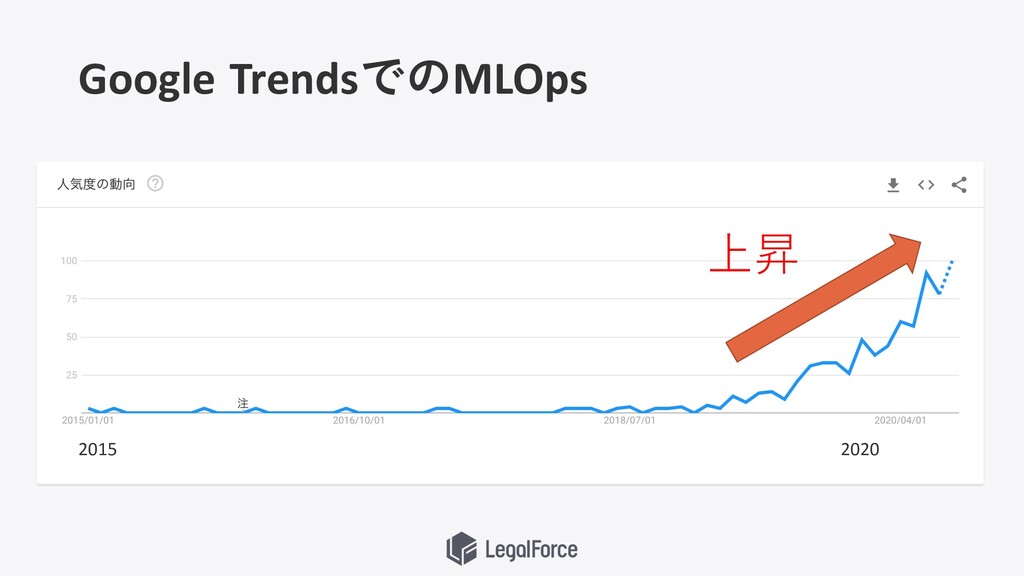
Google TrendsでのMLOps 上昇 2015 2020
何が機械学習固有の難しさなのか • コードだけでなくデータが振る舞いを決めてしまう • ⼤量の機械学習パラメータも結果に影響を与える • 通常のプログラムが確定的な振る舞いをするが 機械学習は確率的振る舞いをする • 前処理などのデータパイプラインが複雑化する
• それらの性質により⾃動テストがしにくい • 継続的トレーニング(Continuous Training) • 継続的評価(Continuous Evaluation)
Change Anything, Change Everything (CACE) • 2014年にGoogleが論⽂で提唱 • ある部分を変えるとあらゆる振る舞いが変わる •
機械学習のランダム性による D. Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, Michael Young SE4ML: Software Engineering for Machine Learning (NeurIPS 2014 Workshop) • 再度モデルを作ることができない • 問題が起きたときに前の状態に戻れない
⼈に関する問題 • 機械学習が得意なエンジニアがWeb開発などの ソフトウェアエンジニアリングが得意なケースが少ない • Webもできて、機械学習もできるエンジニアは いなくはないが、採⽤がとても難しい • 仮に機械学習エンジニアがWebをできたとしても 機械学習にフォーカスできる状態が好ましい
MLOpsの成熟レベル Googleの定義によると • MLOps レベル 0: ⼿動プロセス • なにも⼯夫を指定ない状態 •
⾃動化を含まず⼿動で⾏っている状態 • MLOps レベル 1: ML パイプラインの⾃動化 • 学習のパイプラインが⾃動化されており 継続的学習が⾏われている状態 • パイプラインのデプロイは⼿動 • MLOps レベル 2: CI / CD パイプラインの⾃動化 • 更にパイプラインのデプロイがCI/CDにより⾃動化されている状態 引⽤:https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation- pipelines-in-machine-learning?hl=ja
機械学習のフロー データ 収集 データ 分析 前処理 学習 評価・ 実験管理 デプ
ロイ モニタ リング
アノテーション エンドツーエンドMLOps (広範囲の領域をカバー) 実験管理 モデル・データ バージョン管理 Serving ワークフロー データ基盤 ノートブック
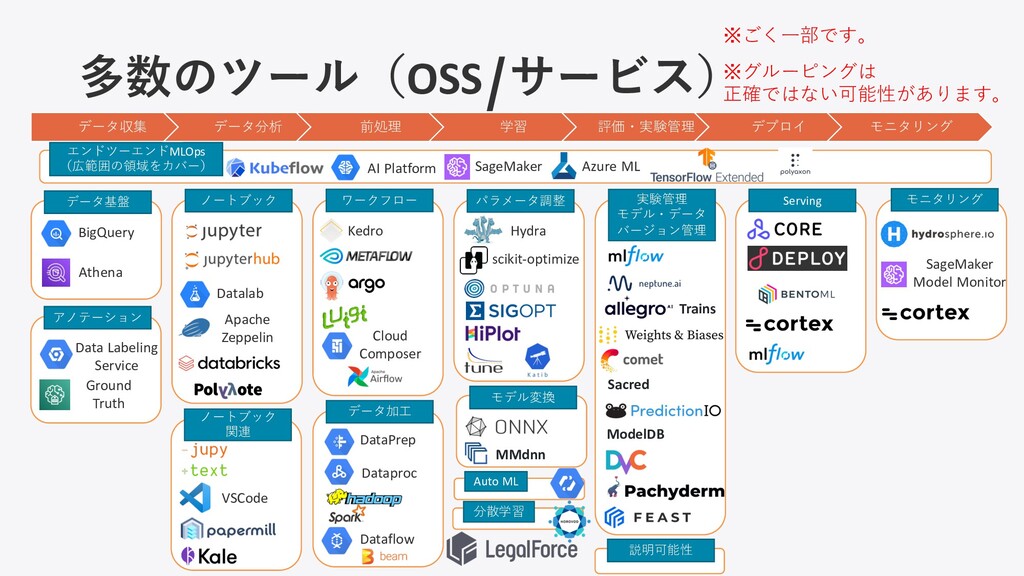
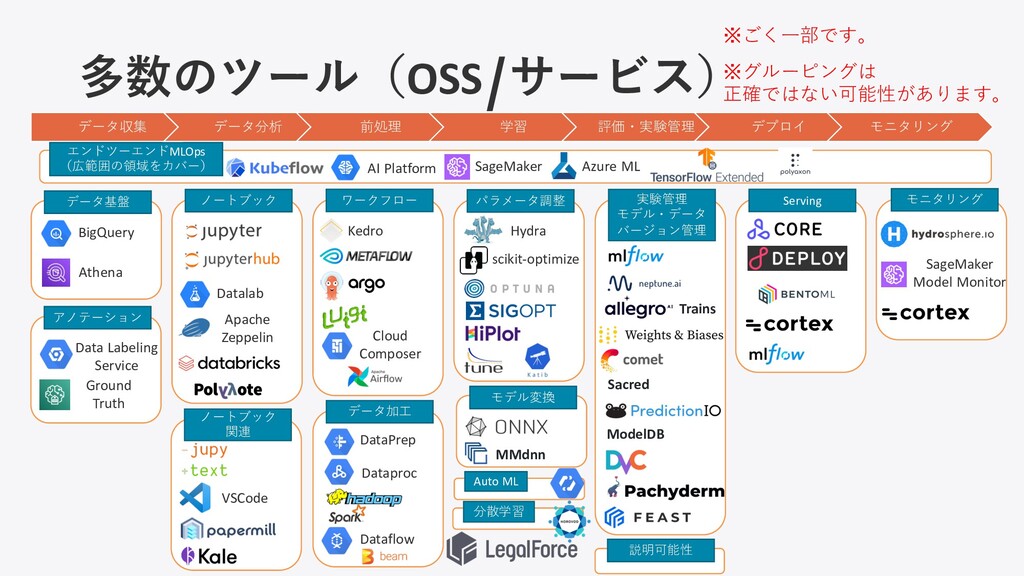
多数のツール(OSS/サービス) データ収集 データ分析 前処理 学習 評価・実験管理 デプロイ モニタリング SageMaker AI Platform Kedro BigQuery Athena Datalab パラメータ調整 Sacred Hydra scikit-optimize VSCode モデル変換 Data Labeling Service Ground Truth データ加⼯ DataPrep Dataproc Cloud Composer Dataflow モニタリング ModelDB Trains MMdnn SageMaker Model Monitor Azure ML Apache Zeppelin ※グルーピングは 正確ではない可能性があります。 ※ごく⼀部です。 Auto ML 説明可能性 分散学習 ノートブック 関連
LegalForceにおける実例
LegalForceのMLOps検討における モチベーション • LegalForceではDevOpsの推進を通して ⾼速な開発サイクルを実現することができた • DevOpsの知⾒を機械学習にも 応⽤することで 先に上げたような課題を解消し、 さらに機械学習の開発を⾼速化できるはず
MLOps
LegalForceにおける課題① データ 収集 データ 分析 前処理 学習 評価・ 実験管理 デプ
ロイ モニタ リング
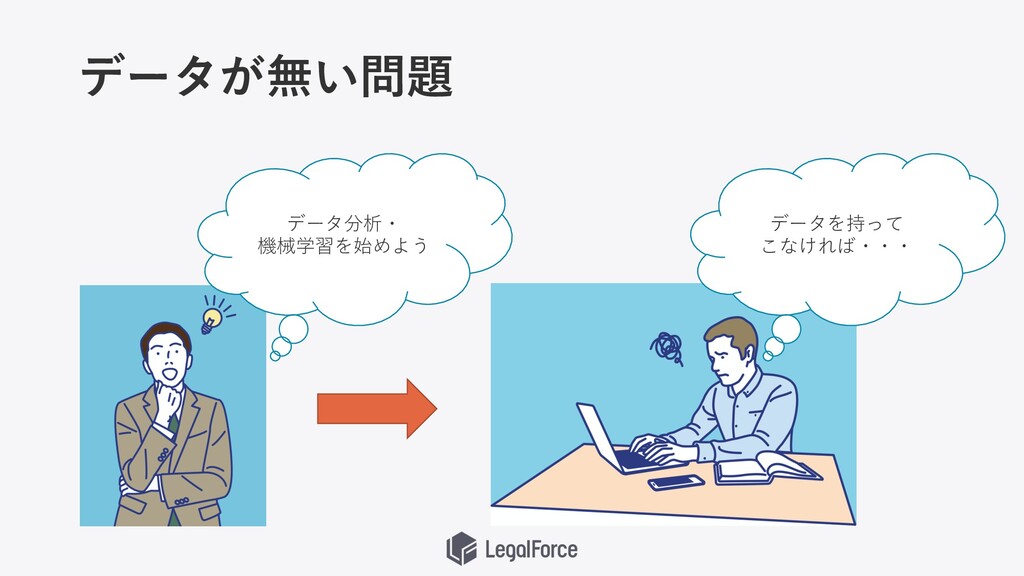
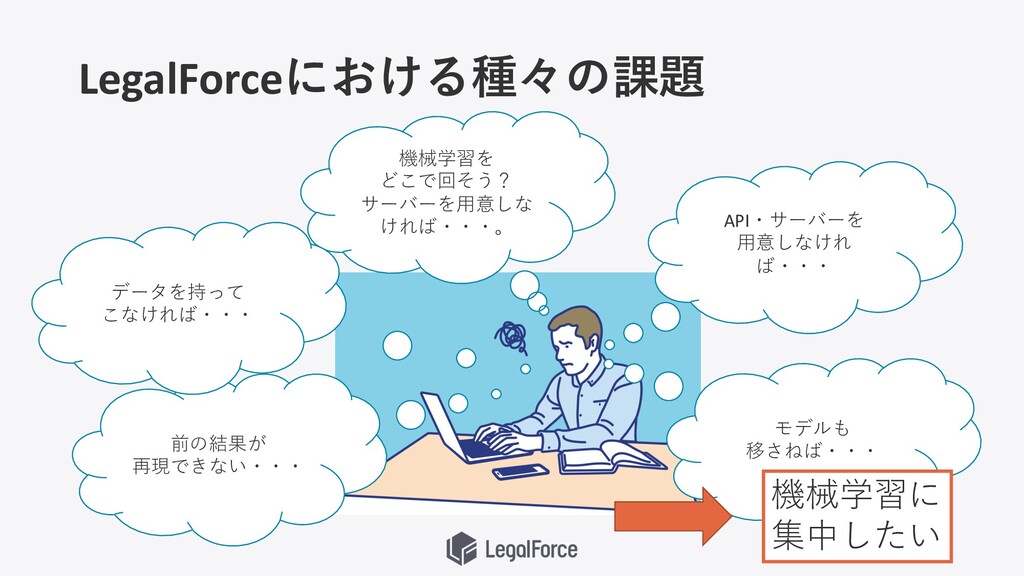
データが無い問題 データを持って こなければ・・・ データ分析・ 機械学習を始めよう
LegalForceにおける課題② データ 収集 データ 分析 前処理 学習 評価・ 実験管理 デプ
ロイ モニタ リング
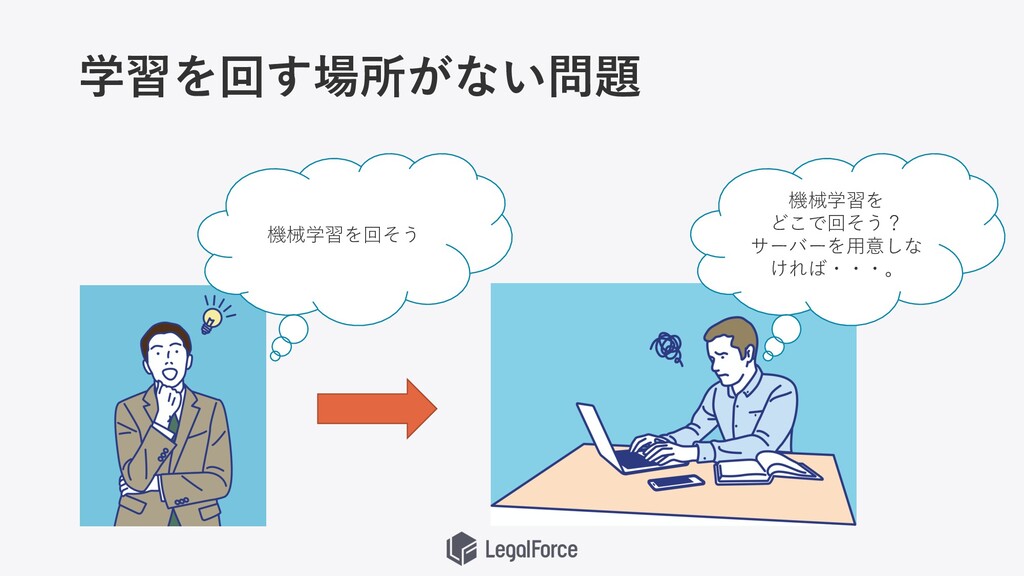
学習を回す場所がない問題 機械学習を どこで回そう? サーバーを⽤意しな ければ・・・。 機械学習を回そう
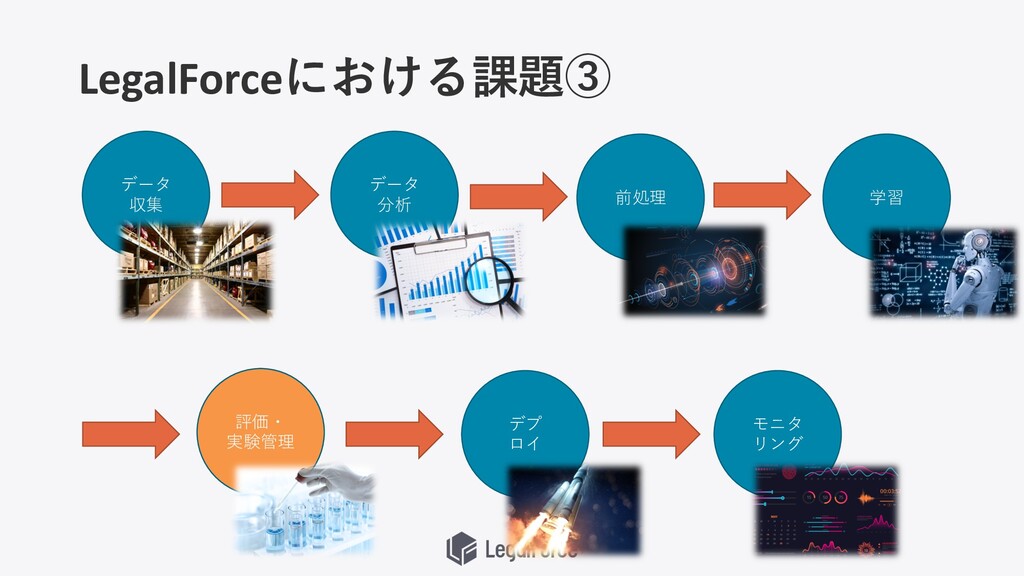
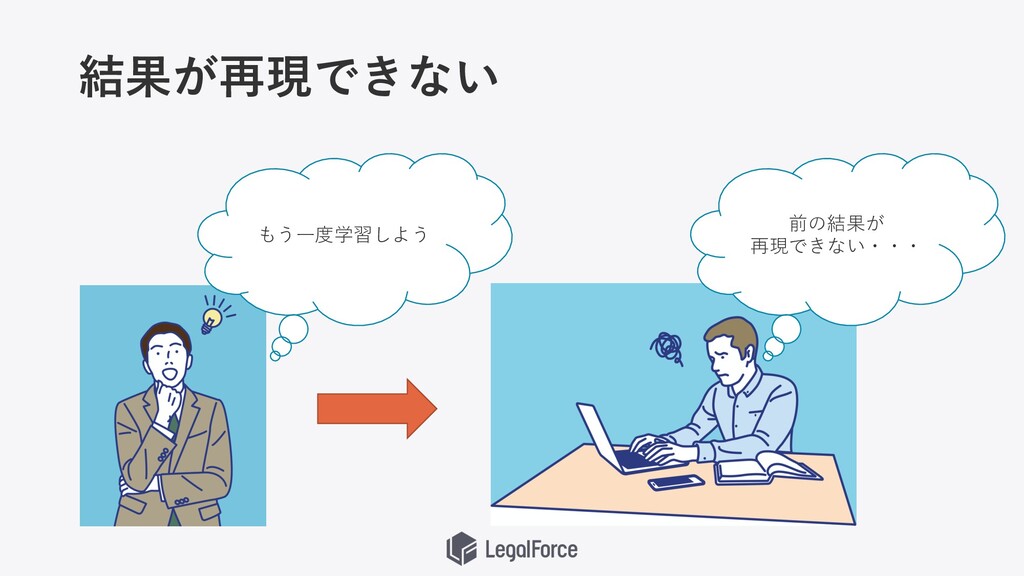
LegalForceにおける課題③ データ 収集 データ 分析 前処理 学習 評価・ 実験管理 デプ
ロイ モニタ リング
結果が再現できない 前の結果が 再現できない・・・ もう⼀度学習しよう
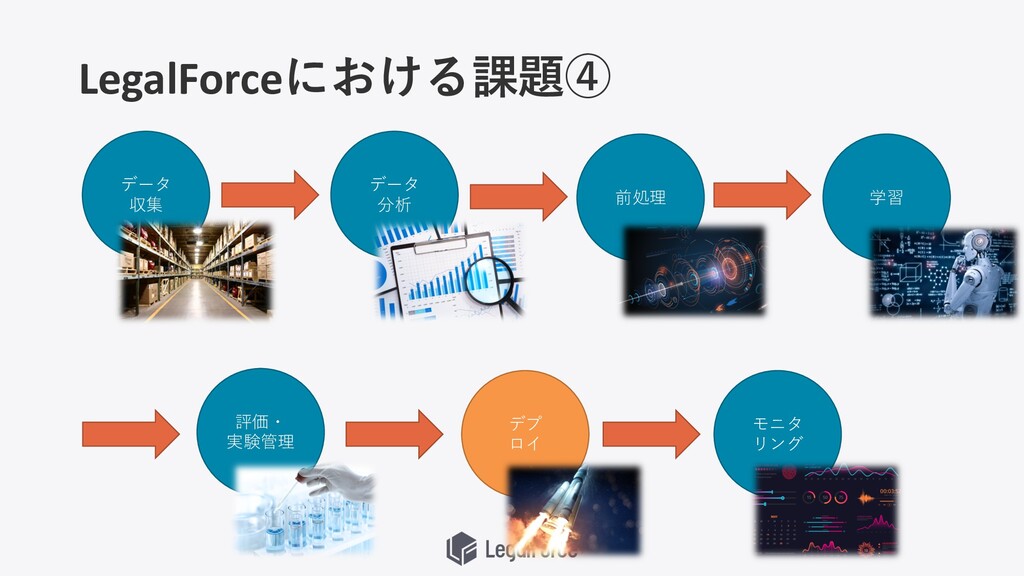
LegalForceにおける課題④ データ 収集 データ 分析 前処理 学習 評価・ 実験管理 デプ
ロイ モニタ リング
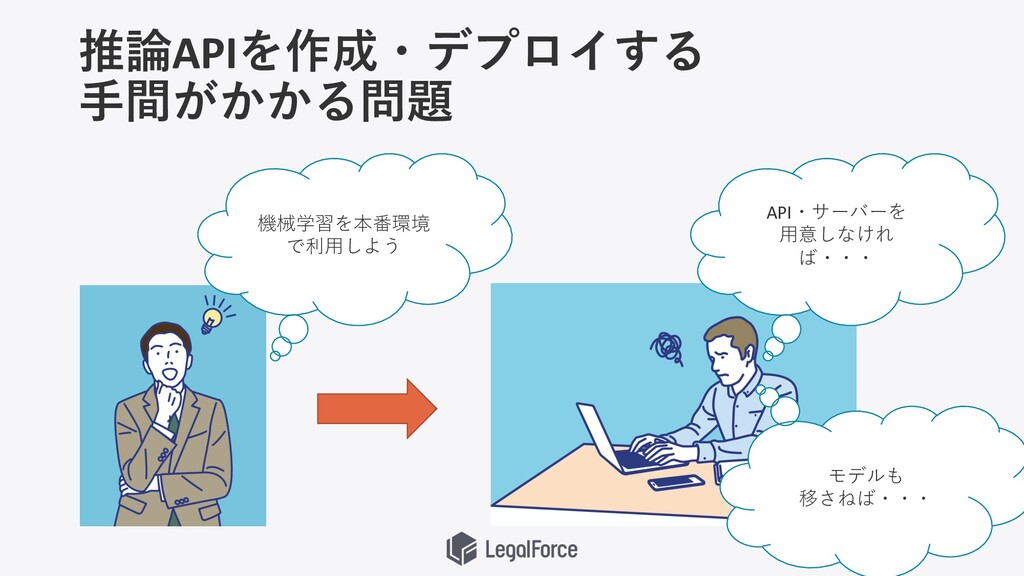
推論APIを作成・デプロイする ⼿間がかかる問題 API・サーバーを ⽤意しなけれ ば・・・ 機械学習を本番環境 で利⽤しよう モデルも 移さねば・・・
LegalForceにおける種々の課題 API・サーバーを ⽤意しなけれ ば・・・ モデルも 移さねば・・・ 機械学習を どこで回そう? サーバーを⽤意しな ければ・・・。
前の結果が 再現できない・・・ データを持って こなければ・・・ 機械学習に 集中したい
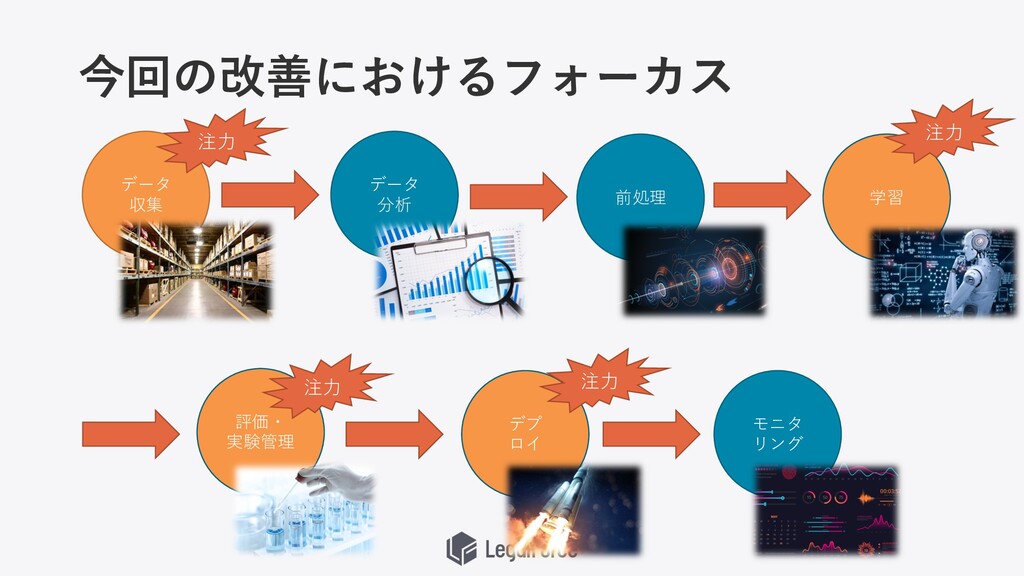
今回の改善におけるフォーカス データ 収集 データ 分析 前処理 学習 評価・ 実験管理 デプ
ロイ モニタ リング 注⼒ 注⼒ 注⼒ 注⼒
None
アノテーション エンドツーエンドMLOps (広範囲の領域をカバー) 実験管理 モデル・データ バージョン管理 Serving ワークフロー データ基盤 ノートブック
多数のツール(OSS/サービス) データ収集 データ分析 前処理 学習 評価・実験管理 デプロイ モニタリング SageMaker AI Platform Kedro BigQuery Athena Datalab パラメータ調整 Sacred Hydra scikit-optimize VSCode モデル変換 Data Labeling Service Ground Truth データ加⼯ DataPrep Dataproc Cloud Composer Dataflow モニタリング ModelDB Trains MMdnn SageMaker Model Monitor Azure ML Apache Zeppelin ※グルーピングは 正確ではない可能性があります。 ※ごく⼀部です。 Auto ML 説明可能性 分散学習 ノートブック 関連
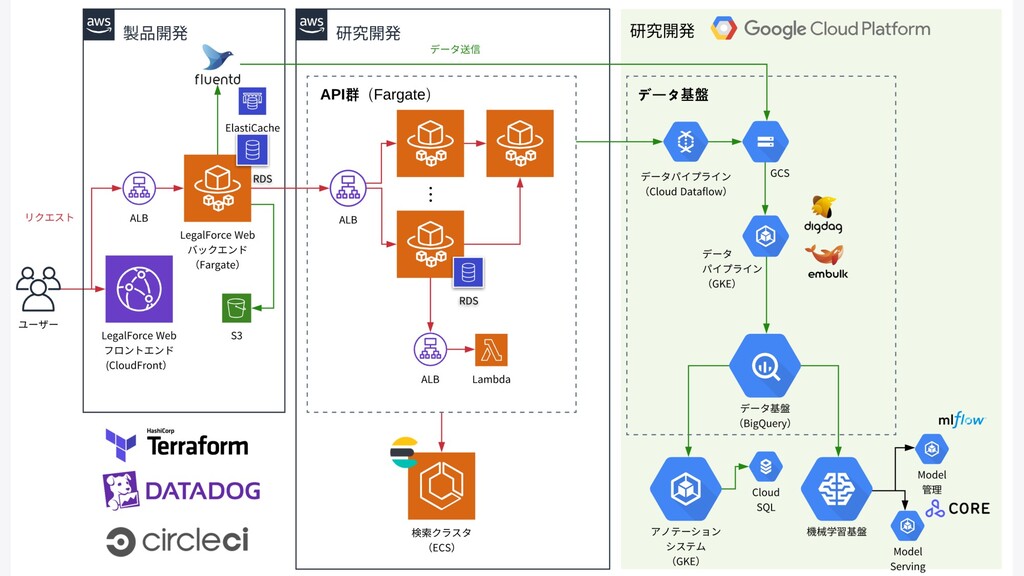
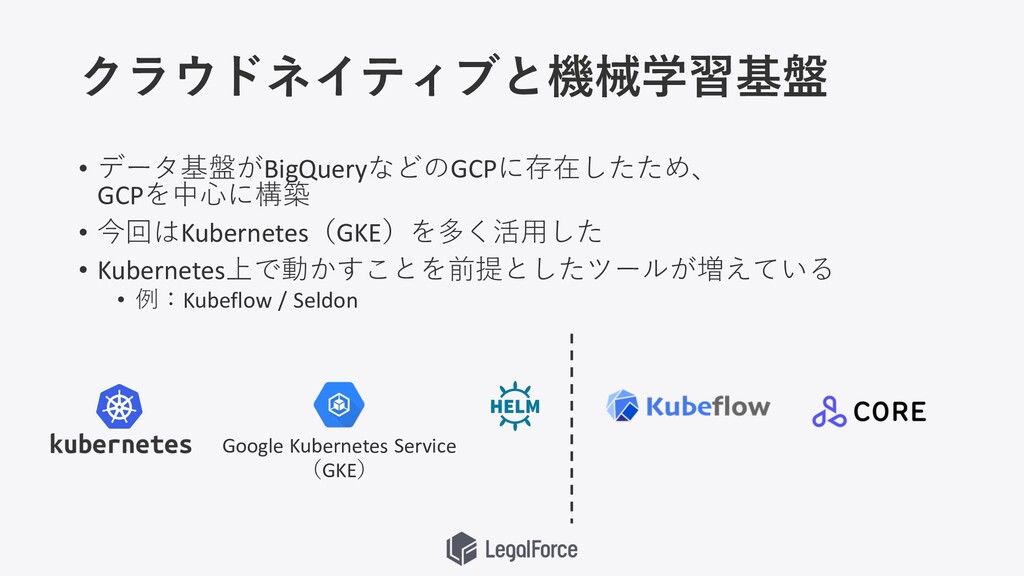
クラウドネイティブと機械学習基盤 • データ基盤がBigQueryなどのGCPに存在したため、 GCPを中⼼に構築 • 今回はKubernetes(GKE)を多く活⽤した • Kubernetes上で動かすことを前提としたツールが増えている • 例:Kubeflow
/ Seldon Google Kubernetes Service (GKE)
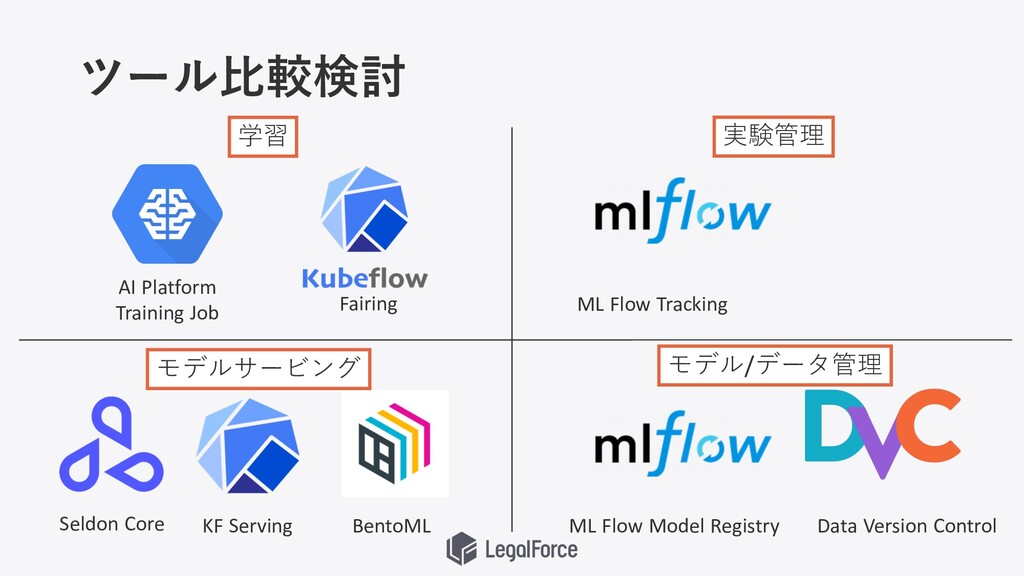
ツール⽐較検討 AI Platform Training Job Fairing Seldon Core KF Serving
BentoML ML Flow Tracking ML Flow Model Registry Data Version Control 学習 実験管理 モデル/データ管理 モデルサービング
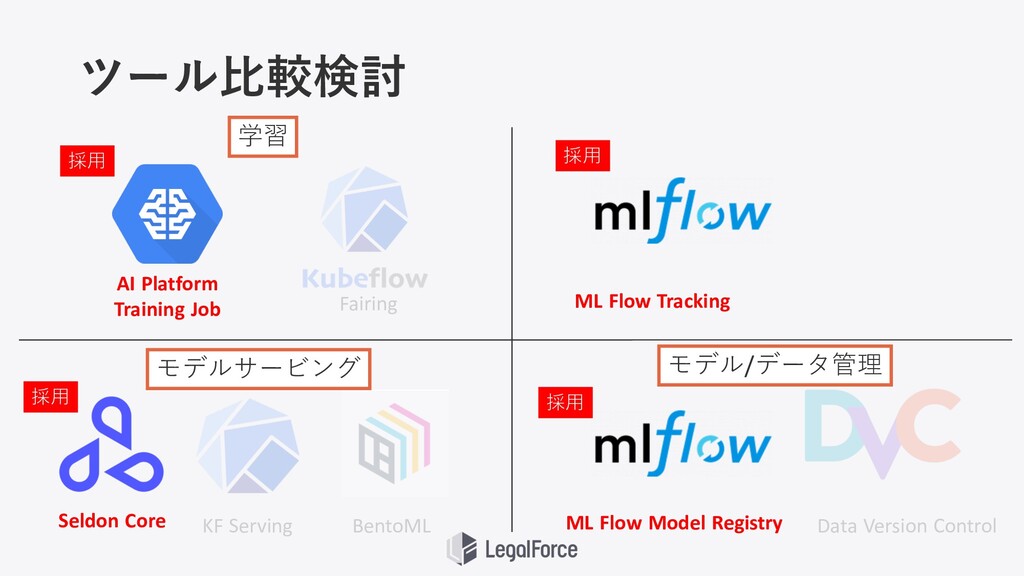
ツール⽐較検討 AI Platform Training Job Fairing Seldon Core KF Serving
BentoML ML Flow Tracking ML Flow Model Registry Data Version Control 学習 モデル/データ管理 モデルサービング 採⽤ 採⽤ 採⽤ 採⽤
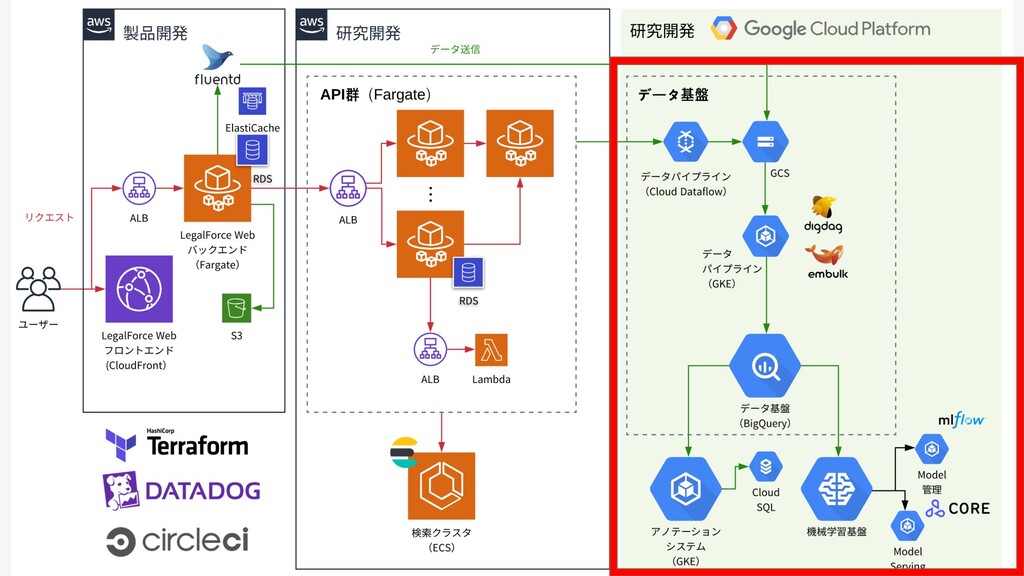
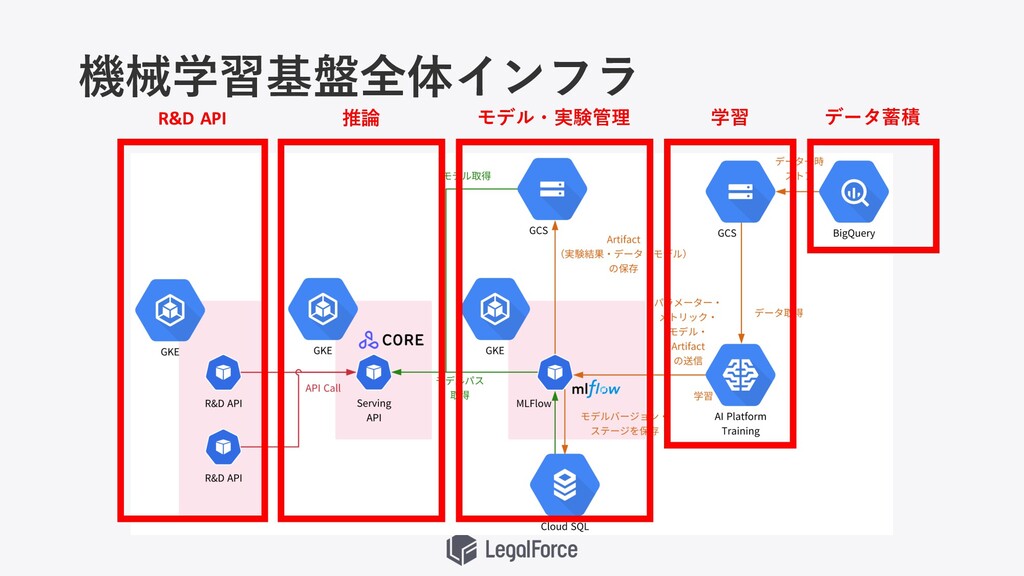
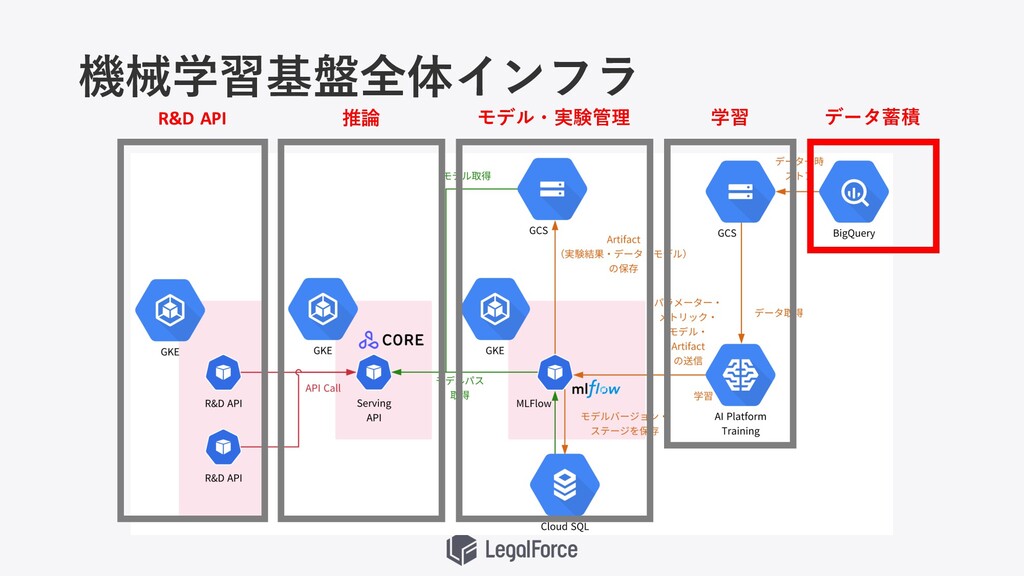
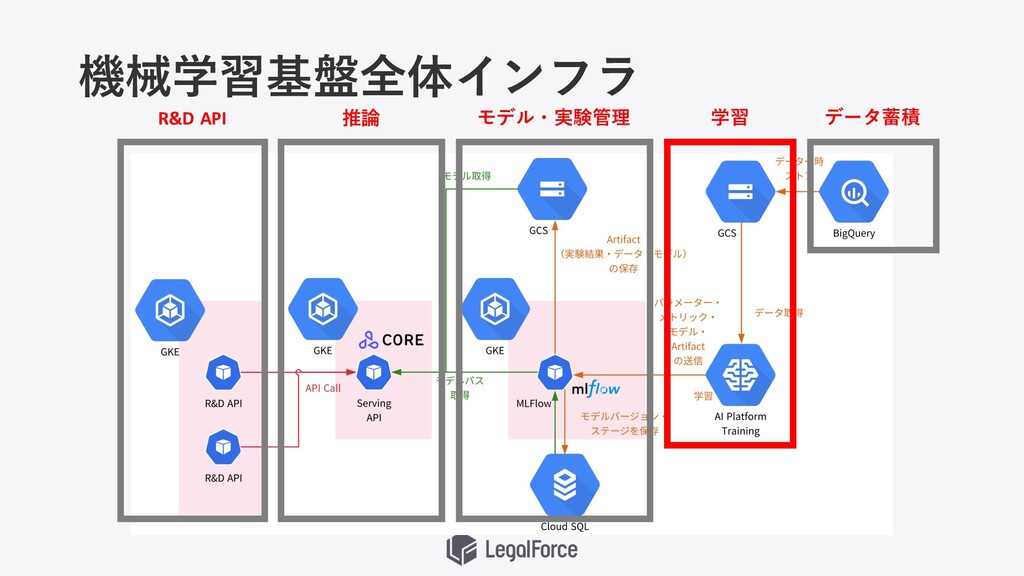
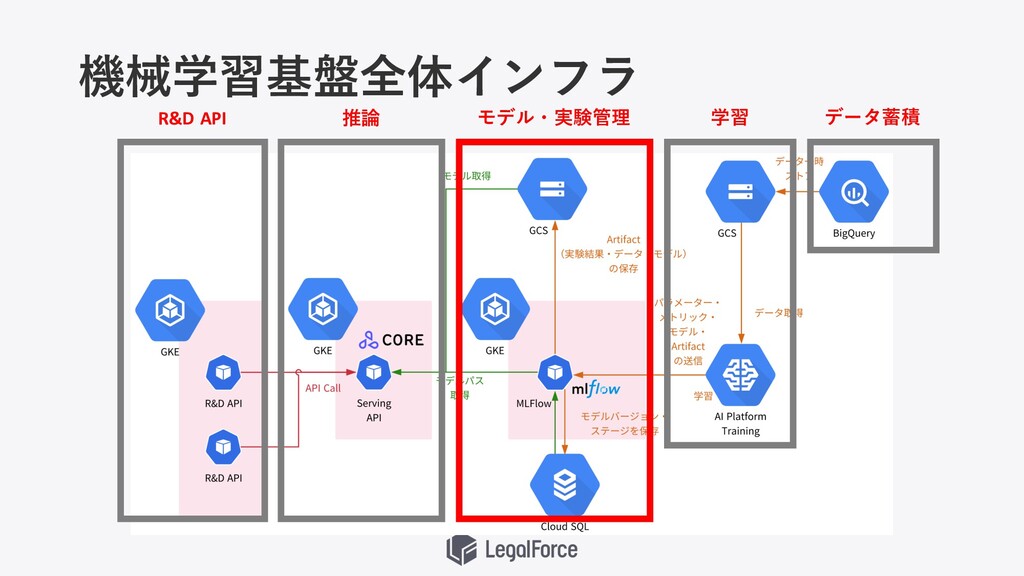
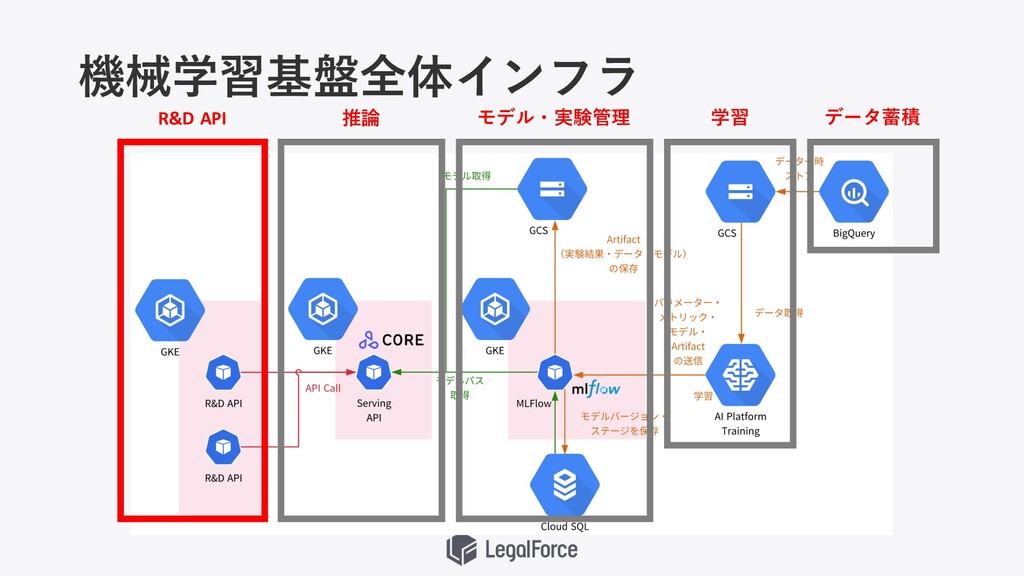
機械学習基盤全体インフラ
機械学習基盤全体インフラ データ蓄積 学習 モデル・実験管理 推論 R&D API
機械学習基盤全体インフラ データ蓄積 学習 モデル・実験管理 推論 R&D API
LegalForceにおけるデータ基盤の役割 • 社内全体のデータを集約・蓄積 • ETLツールによるデータパイプライン • データレイク、データウェアハウス、 データマート • BIツール
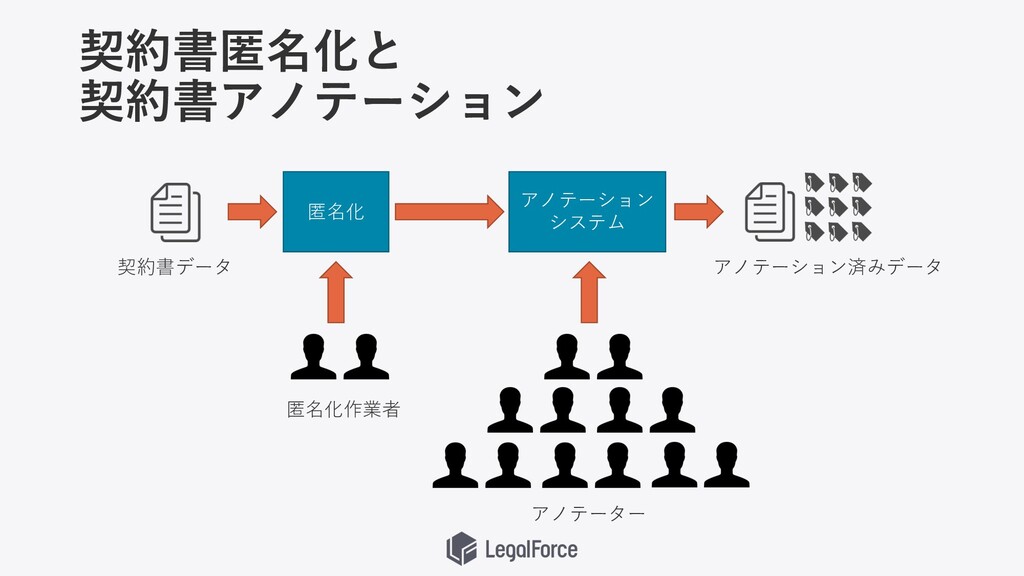
• 契約書データの アノテーションツールの運⽤ • 契約書の匿名化 • ⾃動契約書データの整理・分析 • ラベル付与等による機械学習⽤データの 蓄積
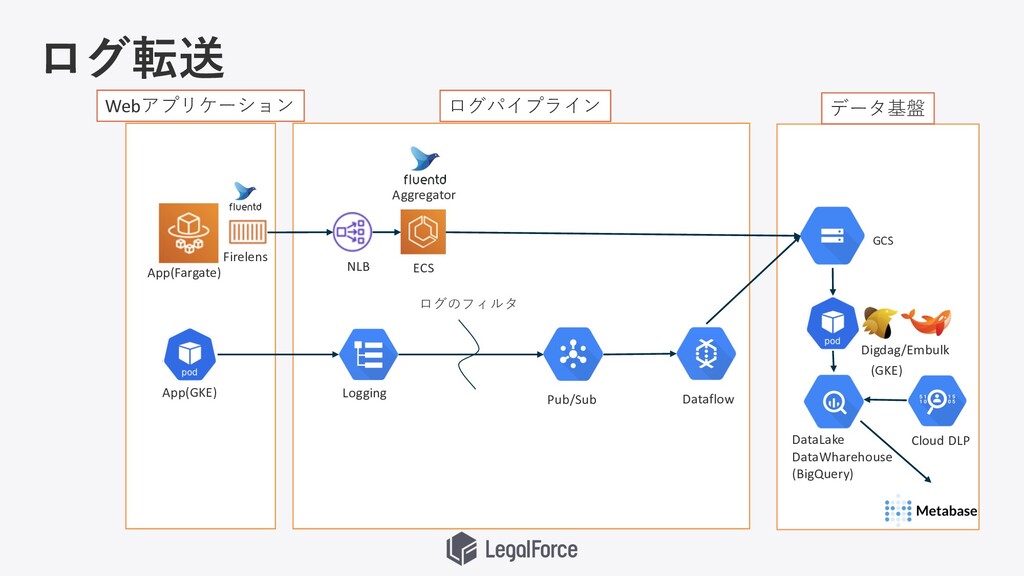
LegalForceで扱うデータ 契約書テキスト・スキャン画像データ Webアプリケーションログデータ
Firelens Aggregator NLB Digdag/Embulk Logging GCS Pub/Sub Dataflow DataLake DataWharehouse
(BigQuery) (GKE) App(Fargate) ログ転送 Webアプリケーション ログパイプライン データ基盤 ログのフィルタ ECS App(GKE) Cloud DLP
契約書匿名化と 契約書アノテーション 匿名化 アノテーション システム 契約書データ アノテーション済みデータ 匿名化作業者 アノテーター
機械学習基盤全体インフラ データ蓄積 学習 モデル・実験管理 推論 R&D API
学習 • 機械学習モデルを実際に学習する • PyTorch / Tenforflow / Scikit-learn /
XGBoost等の 複数のフレームワークに対応させたい • セキュアにデータにアクセスしつつ GPUをスケールさせながら 学習を⾏いたい
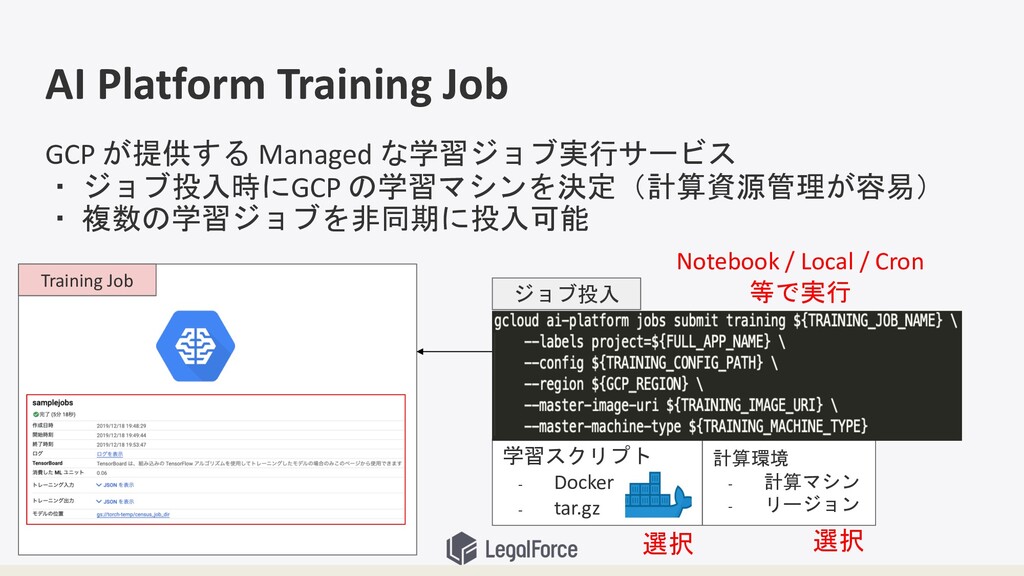
AI Platform Training Job GCP が提供する Managed な学習ジョブ実行サービス ・ ジョブ投入時にGCP
の学習マシンを決定(計算資源管理が容易) ・ 複数の学習ジョブを非同期に投入可能 Training Job 計算環境 - 計算マシン - リージョン 学習スクリプト - Docker - tar.gz 選択 選択 ジョブ投入 Notebook / Local / Cron 等で実行
Kubeflow Fairing Kubeflow が提供する学習ジョブ管理ツール ・ AI Platform Training Job と同様にジョブ投入が可能
・ ジョブ投入後に KF Serving でエンドポイント化するフローが容易 ・ Kubeflow on GKE の構築が前提 AI Hub: "Build, Train, and Deploy XGBoost model using Kubeflow Fairing” より Notebook / Local / Cron で学習実行 (Fairing) KF Serving でエンドポイント立ち上げ
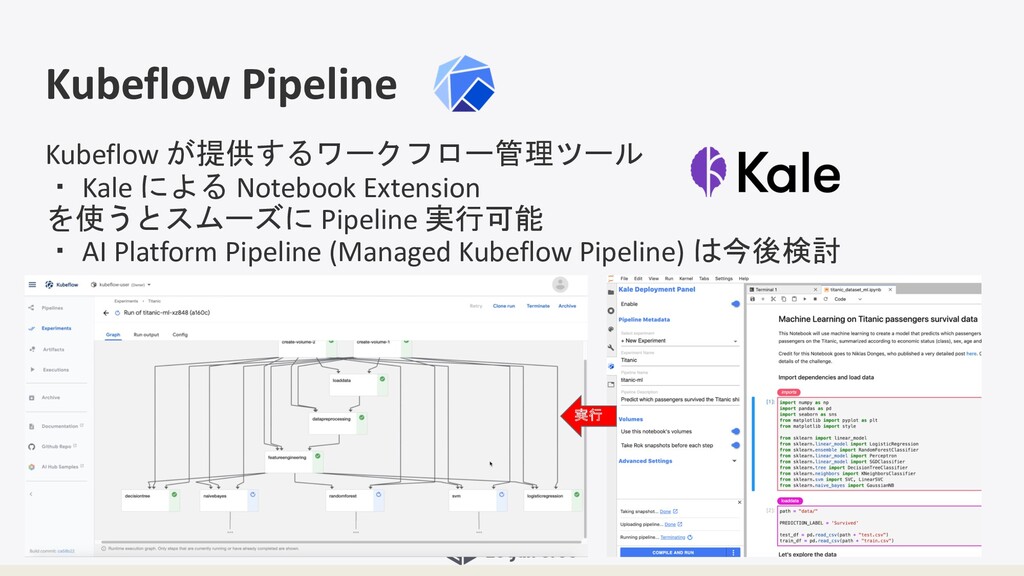
Kubeflow Pipeline Kubeflow が提供するワークフロー管理ツール ・ Kale による Notebook Extension を使うとスムーズに
Pipeline 実行可能 ・ AI Platform Pipeline (Managed Kubeflow Pipeline) は今後検討 実行
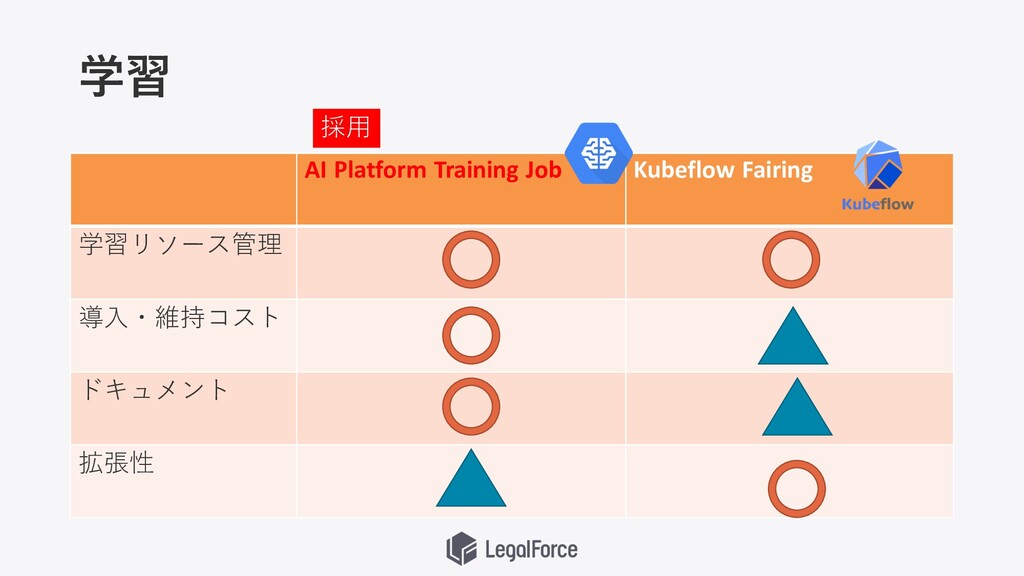
学習 AI Platform Training Job Kubeflow Fairing 学習リソース管理 導⼊・維持コスト ドキュメント
拡張性 採⽤
機械学習基盤全体インフラ データ蓄積 学習 モデル・実験管理 推論 R&D API
モデル・実験管理 • 複数のモデルのバージョンを管理するともに それぞれのモデルのデータやパラメーター、 特徴量、実験結果等を管理する • これにより実験における 再現性の確保を⽬指す
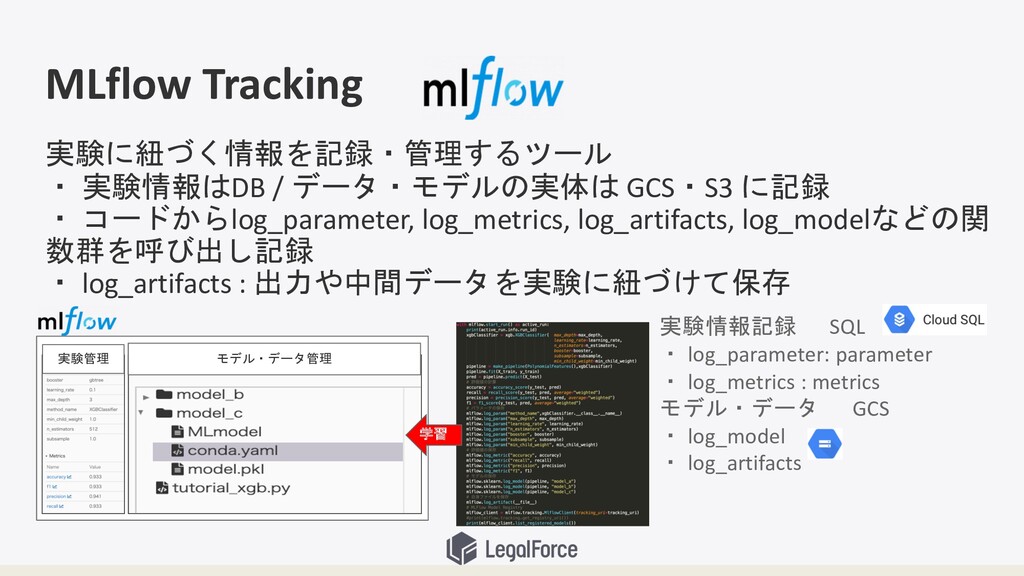
MLflow Tracking 実験に紐づく情報を記録・管理するツール ・ 実験情報はDB / データ・モデルの実体は GCS・S3 に記録 ・
コードからlog_parameter, log_metrics, log_artifacts, log_modelなどの関 数群を呼び出し記録 ・ log_artifacts : 出力や中間データを実験に紐づけて保存 モデル・データ管理 実験管理 学習 実験情報記録 SQL ・ log_parameter: parameter ・ log_metrics : metrics モデル・データ GCS ・ log_model ・ log_artifacts
MLflow Model Registry モデルを Version として管理し、 Version ごとの Parameter ・
Metrics を比較可能
MLflow Model Registry 性能比較結果をVisualizeすることも可能
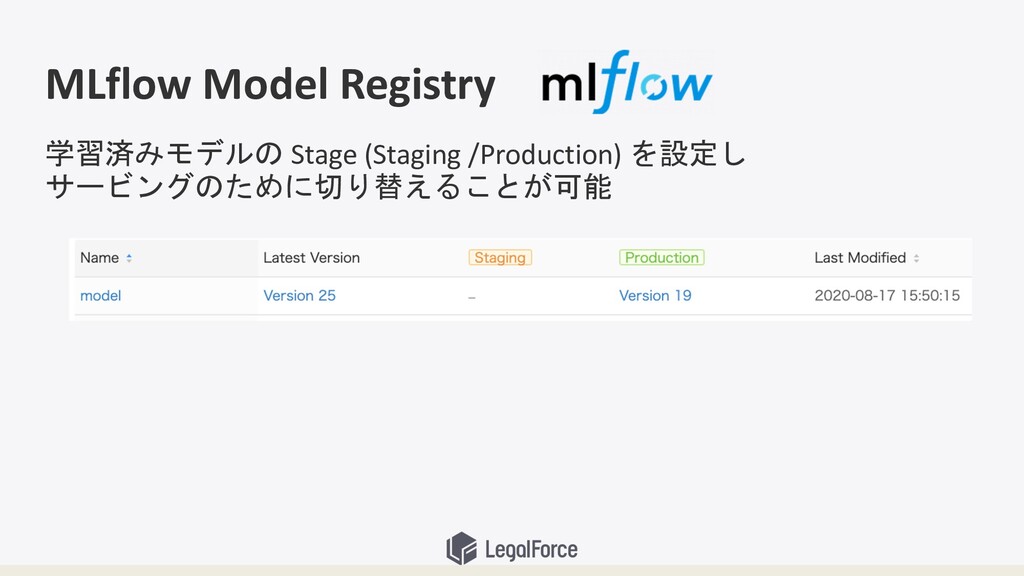
MLflow Model Registry 学習済みモデルの Stage (Staging /Production) を設定し サービングのために切り替えることが可能
機械学習基盤全体インフラ データ蓄積 学習 モデル・実験管理 推論 R&D API
推論APIのサービング • 学習済みのモデルをAPIとして提供する (サービング) • APIはデータを受け取り、推論結果を返却する • 機械学習エンジニアのスキルセットは 推論API開発に適しているしているとは ⾔い難い
• 機械学習エンジニアがAPI開発を⾏ったり、 API開発を依頼したりすることから開放されるこ とによる開発スピード・アジリティの改善が期待 される
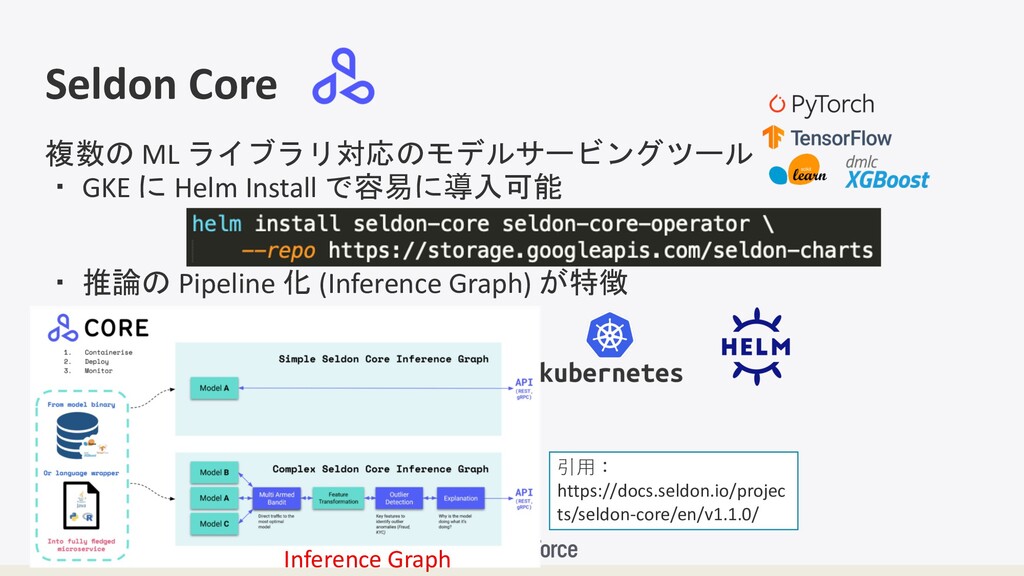
Seldon Core 複数の ML ライブラリ対応のモデルサービングツール ・ GKE に Helm Install
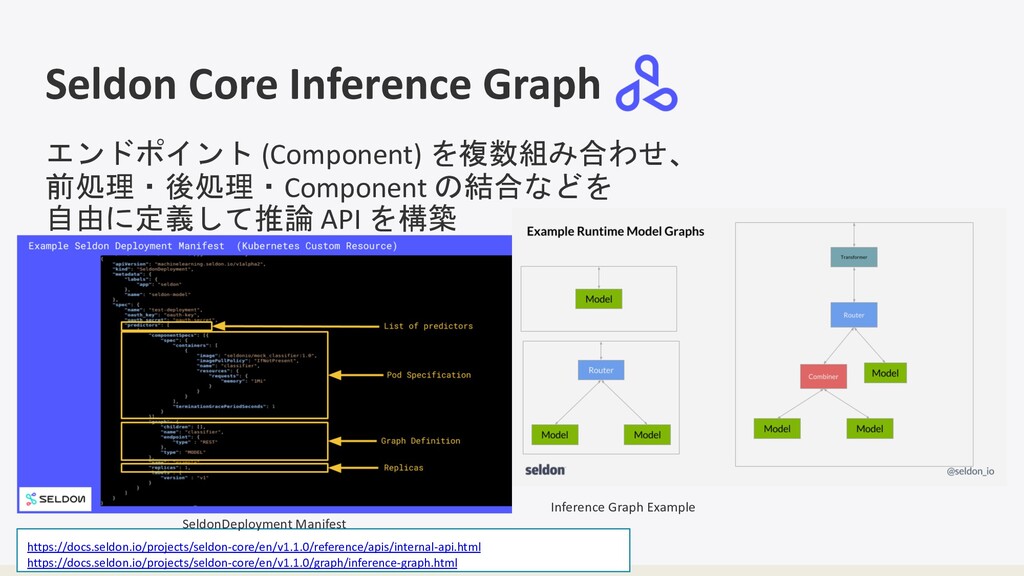
で容易に導入可能 ・ 推論の Pipeline 化 (Inference Graph) が特徴 Inference Graph 引⽤: https://docs.seldon.io/projec ts/seldon-core/en/v1.1.0/
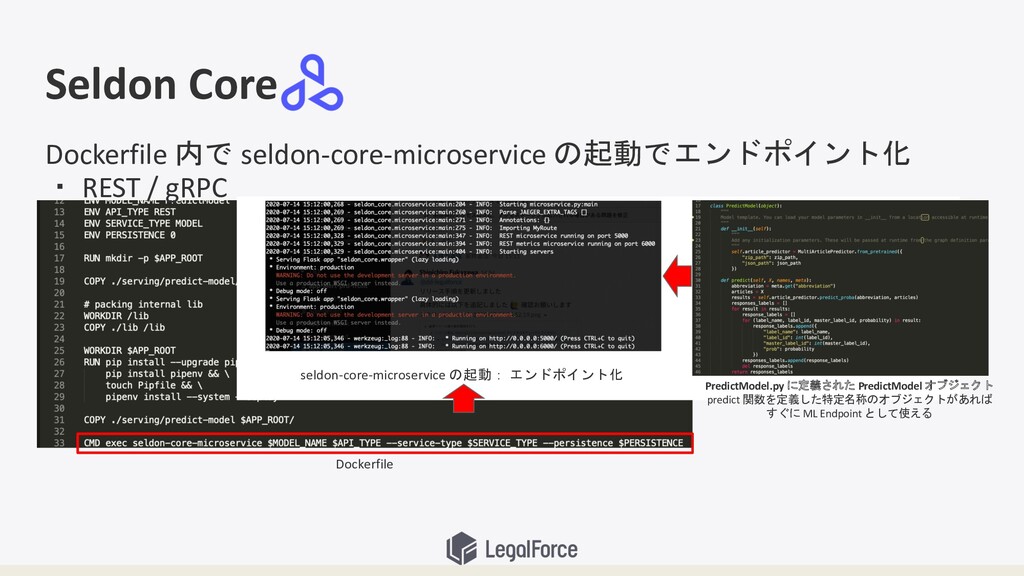
Seldon Core Dockerfile seldon-core-microservice の起動: エンドポイント化 PredictModel.py に定義された PredictModel オブジェクト
predict 関数を定義した特定名称のオブジェクトがあれば すぐに ML Endpoint として使える Dockerfile 内で seldon-core-microservice の起動でエンドポイント化 ・ REST / gRPC
Seldon Core Inference Graph https://docs.seldon.io/projects/seldon-core/en/v1.1.0/reference/apis/internal-api.html https://docs.seldon.io/projects/seldon-core/en/v1.1.0/graph/inference-graph.html エンドポイント (Component) を複数組み合わせ、 前処理・後処理・Component
の結合などを 自由に定義して推論 API を構築 SeldonDeployment Manifest Inference Graph Example
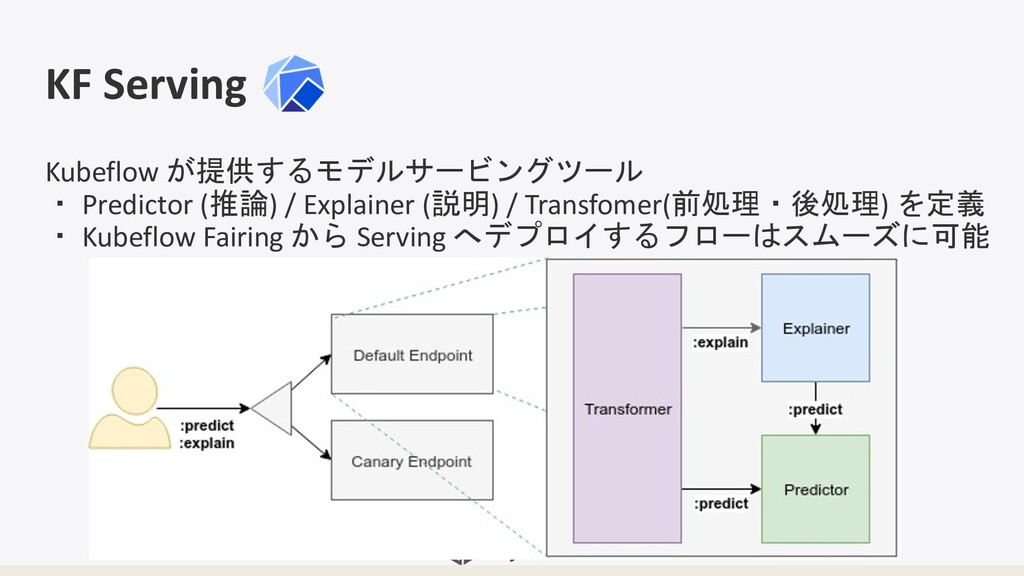
KF Serving Kubeflow が提供するモデルサービングツール ・ Predictor (推論) / Explainer (説明)
/ Transfomer(前処理・後処理) を定義 ・ Kubeflow Fairing から Serving へデプロイするフローはスムーズに可能
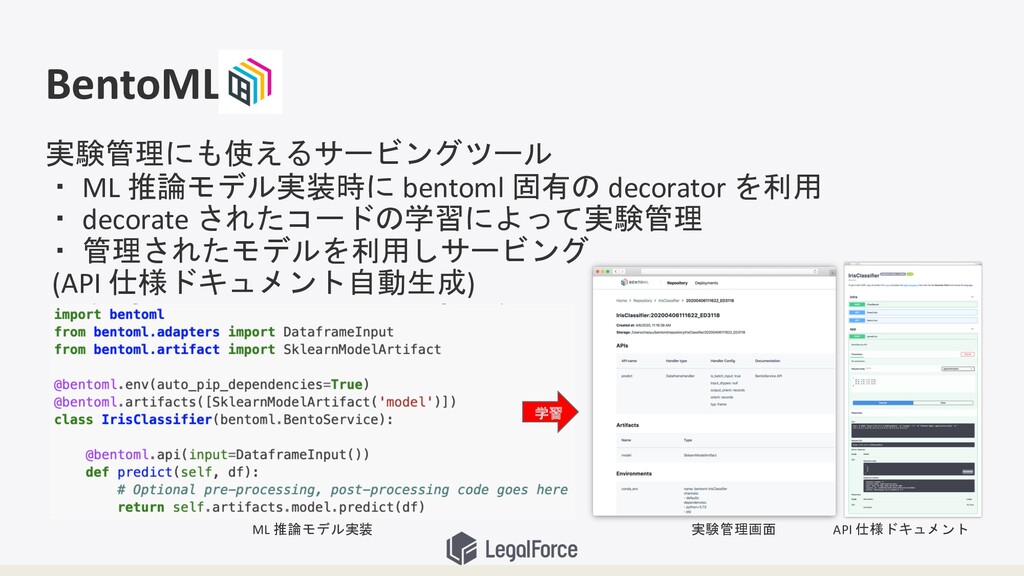
BentoML 実験管理にも使えるサービングツール ・ ML 推論モデル実装時に bentoml 固有の decorator を利用 ・
decorate されたコードの学習によって実験管理 ・ 管理されたモデルを利用しサービング (API 仕様ドキュメント自動生成) ML 推論モデル実装 実験管理画面 API 仕様ドキュメント 学習
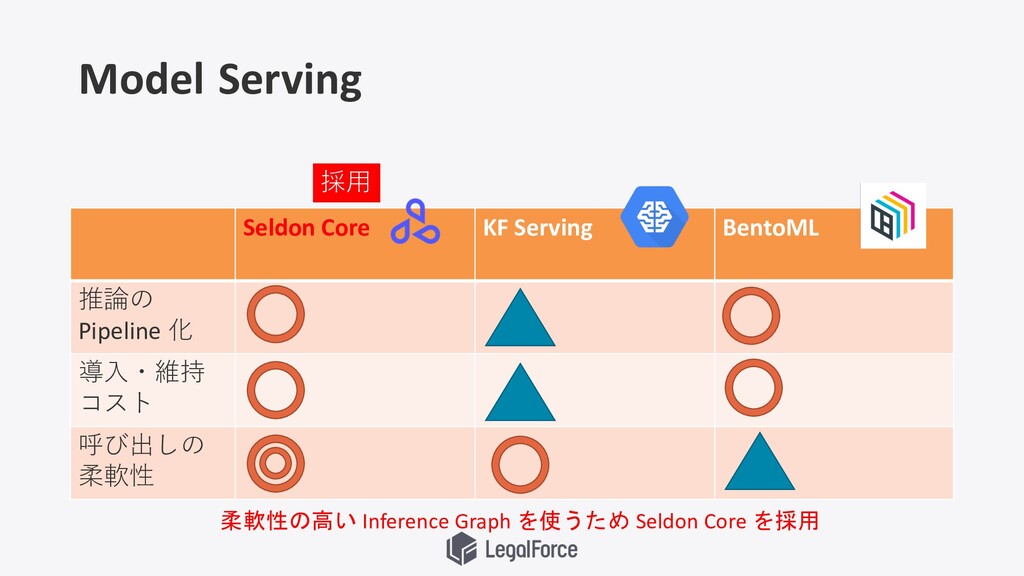
Model Serving Seldon Core KF Serving BentoML 推論の Pipeline 化
導⼊・維持 コスト 呼び出しの 柔軟性 採⽤ 柔軟性の高い Inference Graph を使うため Seldon Core を採用
機械学習基盤全体インフラ データ蓄積 学習 モデル・実験管理 推論 R&D API
製品開発と研究開発の関係 • 研究開発がAPI(⾔語処理、AIロジック等)を開発し、 製品開発側が呼び出す形式 製品開発 研究開発 ユーザー マイクロ サービス ブラウザ
Webアプリ
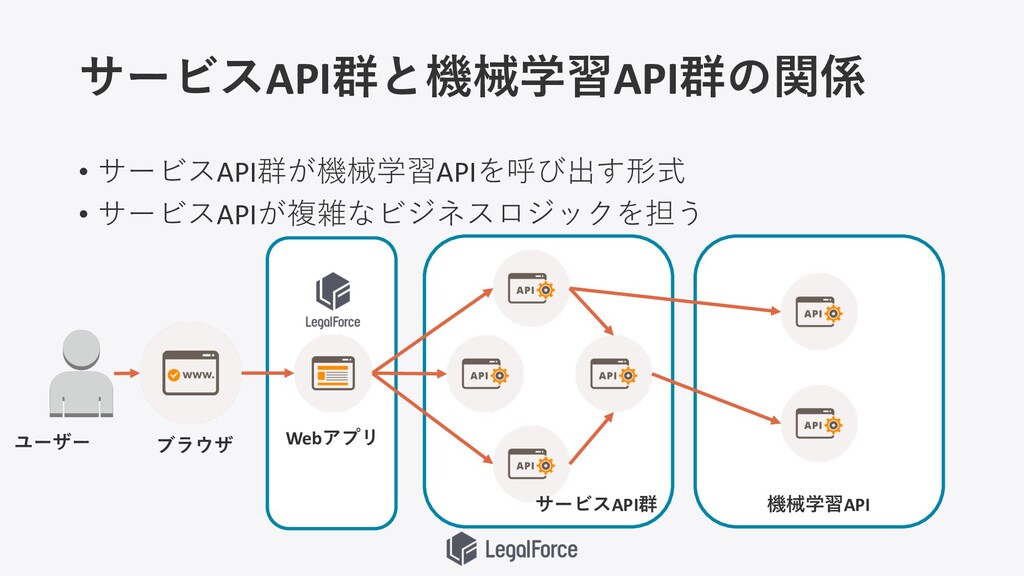
サービスAPI群と機械学習API群の関係 • サービスAPI群が機械学習APIを呼び出す形式 • サービスAPIが複雑なビジネスロジックを担う ユーザー ブラウザ Webアプリ サービスAPI群 機械学習API
機械学習基盤(MLOps)構築を通して
LegalForceにおける MLOpsによる効果 1. アジリティ: データアクセス、分析、学習、デプロイ、 さらに再学習も含めた リリースまでの速度の改善 2. 再現性: 学習結果が再現可能になり、
実験結果が⽐較しやすく 3. ⾃動化・⾮属⼈化: リリースまでのフローを整備し、 誰でも学習・デプロイができるように 4. セキュア化 データアクセスにおけるセキュリティの向上
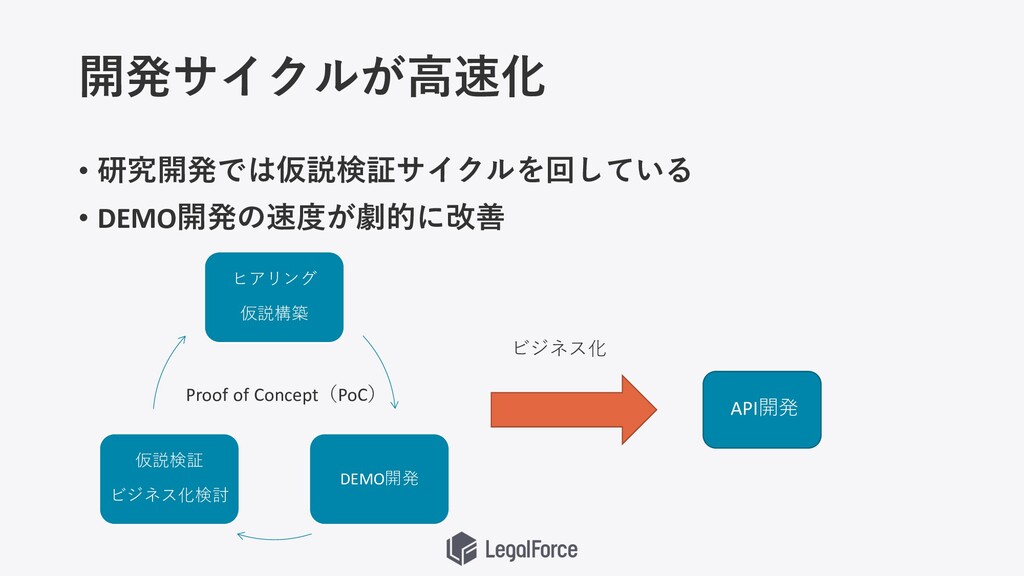
開発サイクルが⾼速化 • 研究開発では仮説検証サイクルを回している • DEMO開発の速度が劇的に改善 ヒアリング 仮説構築 DEMO開発 仮説検証 ビジネス化検討
API開発 ビジネス化 Proof of Concept(PoC)
試⾏錯誤した部分 • MLOpsのあるべき姿がわからず、 何度も⼤きな⽅針変更となった • MLOpsツール⾃体がまだまだ発展途上な部分もあり、 機能不⾜等で不便に感じるところがあった • MLOpsに関わるツールを利⽤する際に、 どのOSSが機械学習のどこの部分に位置づけられるのか整理で
きるまでに時間がかかった • 分類モデルを複数組み合わせて利⽤していたりと、 特殊な構成であったため、 ツール内でうまく動かすために⼯夫が必要だった
⼀緒にサービスを作ってくれる SRE募集中!!(DM待ってます!!) !SVLB@GVOBLJ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}