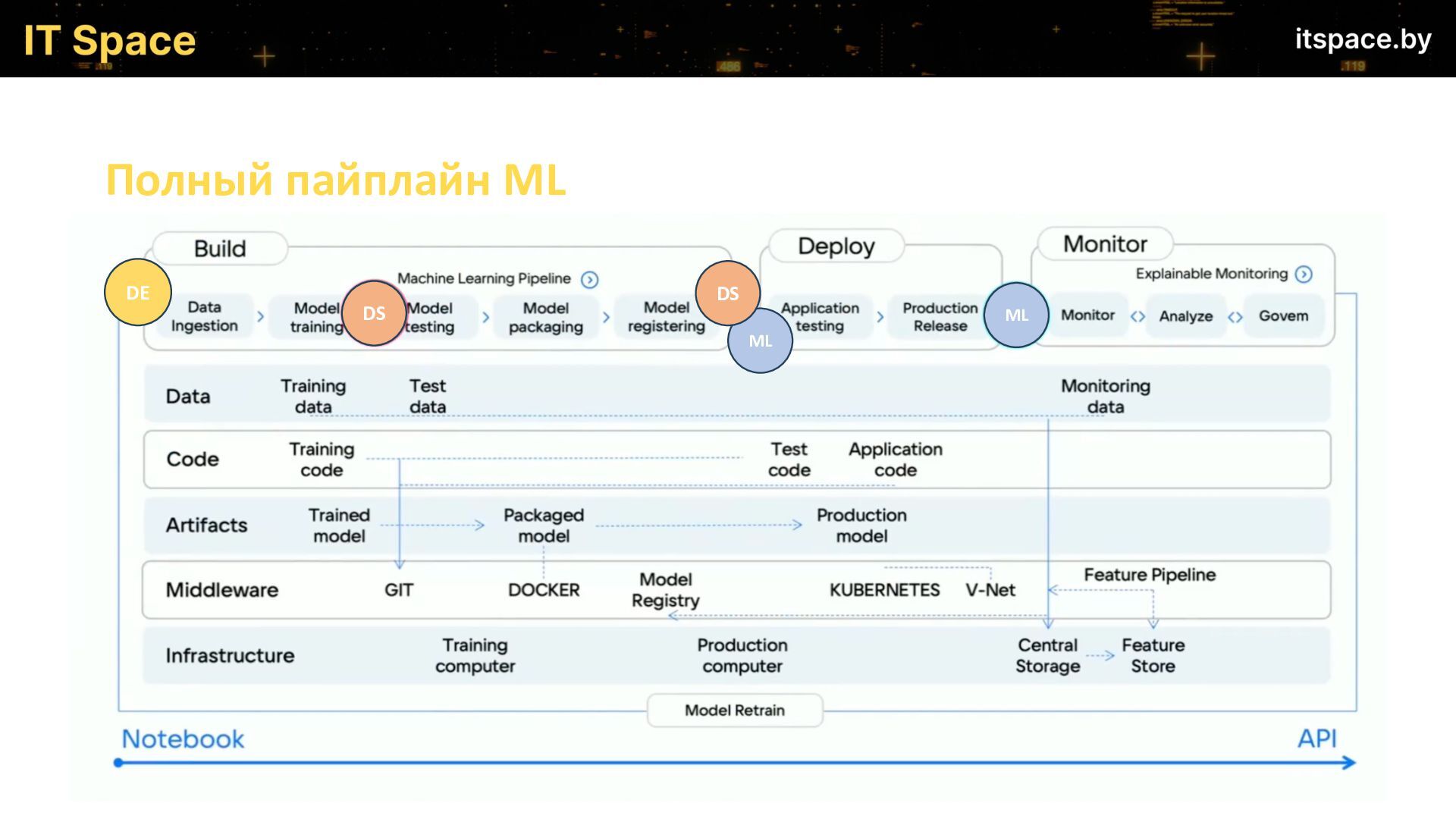
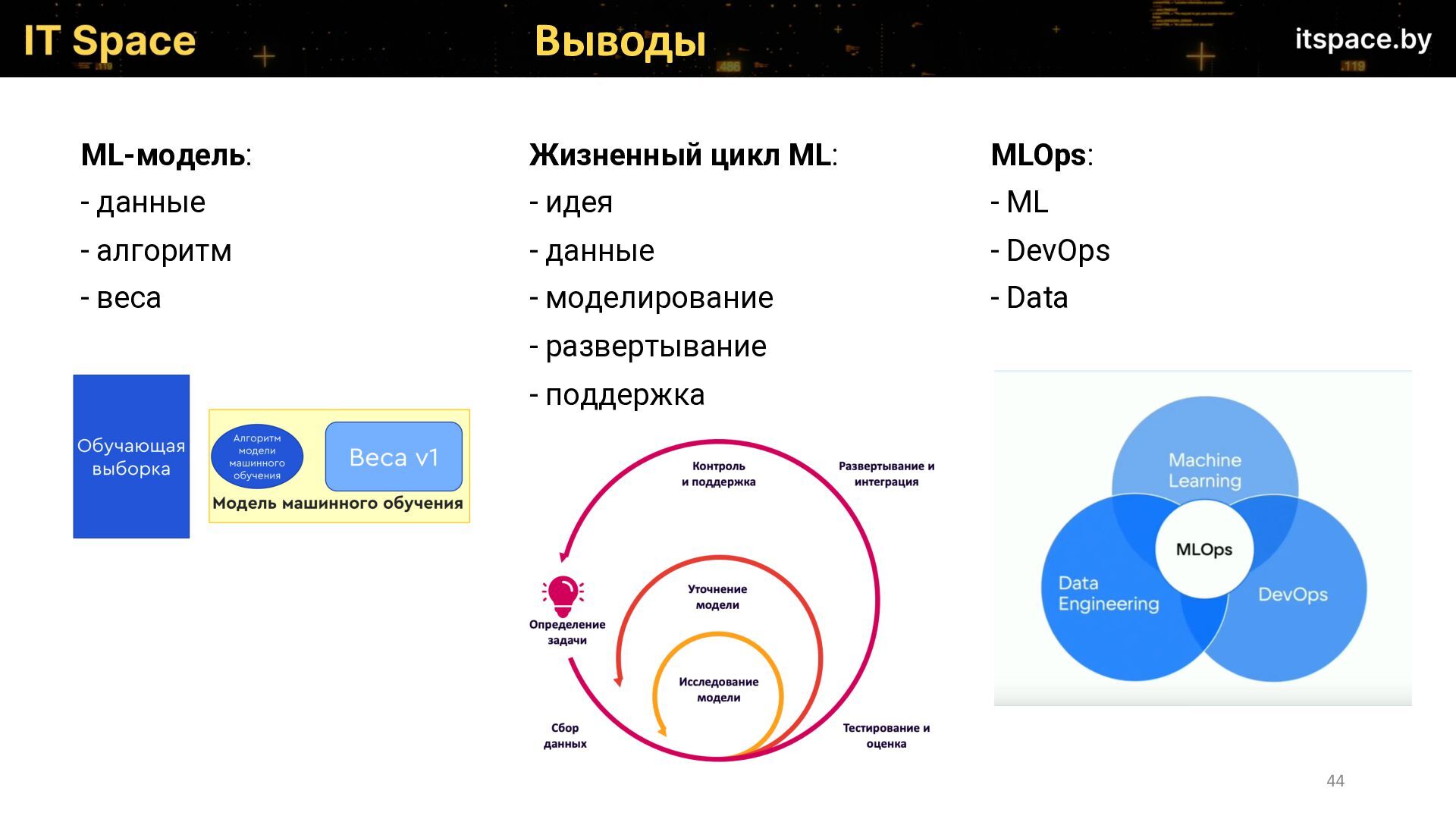
В 2010-х произошел значительный прорыв в области Data Science и машинного обучения. В то же время вопросам внедрения моделей в продакшен уделялось куда меньше внимания. Проекты могли тянуться годами из-за отсутствия стратегии внедрения. Некоторые проекты отменялись после нескольких лет разработки - становилось ясно, что модели плохо работают в реальных условиях или их функциональность неприменима на практике. Сейчас деплой моделей стал неотъемлемой частью процесса разработки и применения алгоритмов машинного обучения. Любая, даже самая точная и сложная модель бесполезна, если она не интегрируется и не работает надежно в Production-среде.
На всех этапах от разработки до внедрения моделей ML могут возникнуть сложности, и на докладе будут подробно рассмотрены основные из них, а именно моменты связанные с:
- Подготовка данных (DataEngineering).
- Обучение/дообучение модели.
- Версионирование обучающих выборок и весов (Трекинг эксперимента).
- Организация разработки
- Управление ресурсами
- Безопасность данных
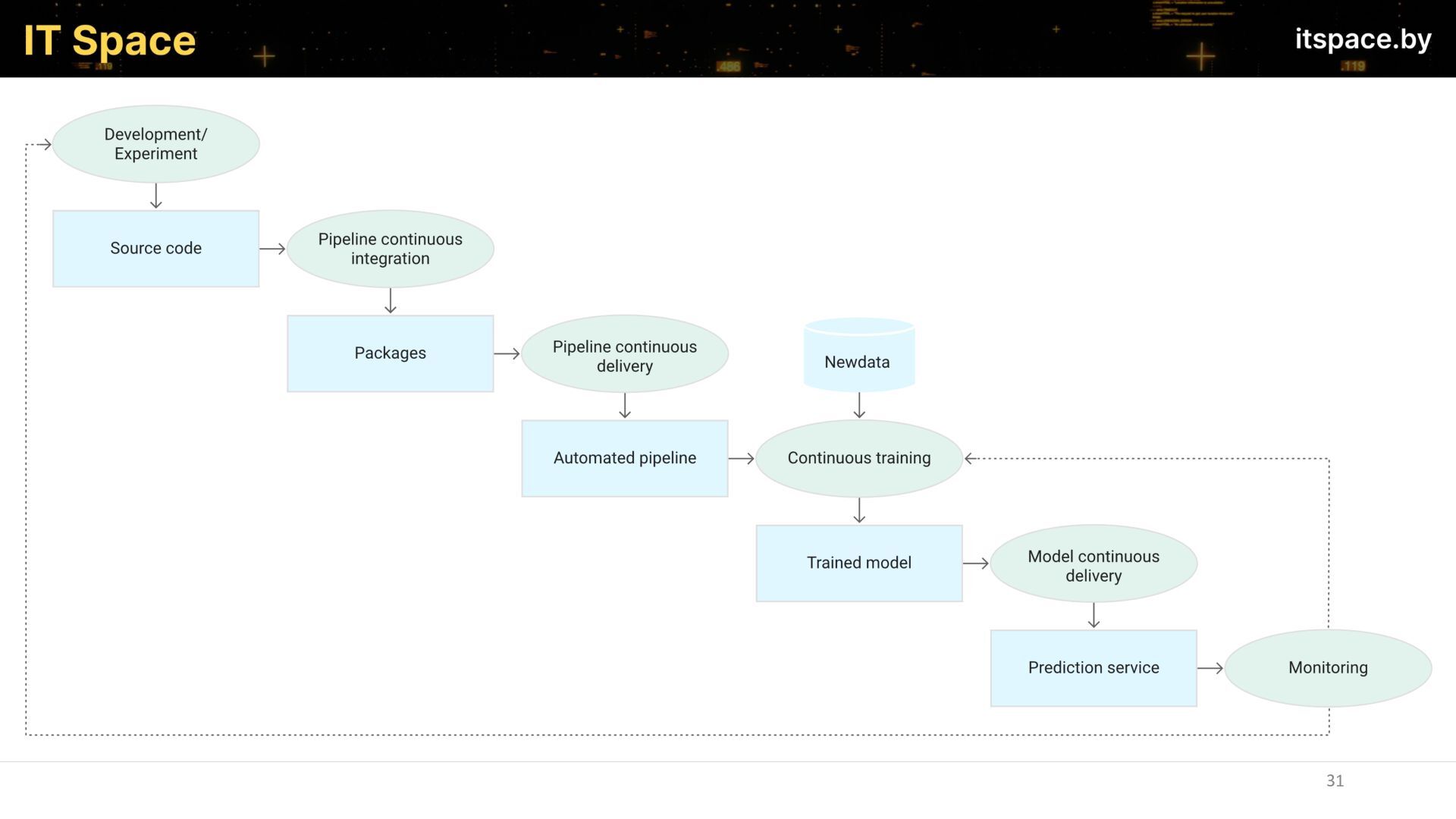
- Организация CI/CD
- Мониторинг запущенных моделей
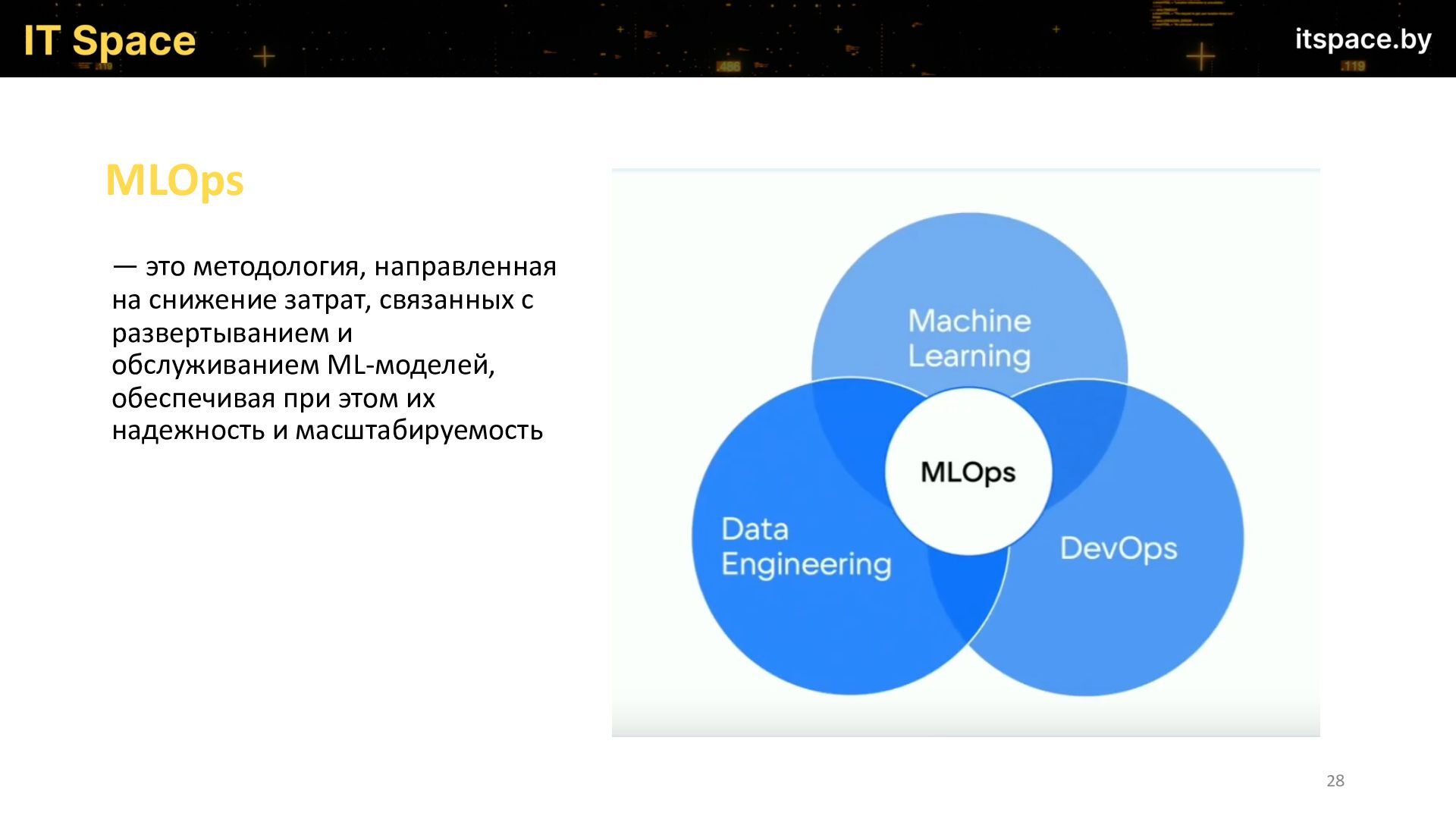
Спикер расскажет, к каким вызовам нужно быть готовым, если вы собираетесь начать или уже начали разработку и эксплуатацию ML-моделей. На многие из этих вызовов нет каноничных ответов, и многое приходится прокладывать путь самому, набивая шишки, так как область внедрения ML в Production находится в начале своего пути и открывает большие возможности тем кто разрабатывает такие сервисы.
Спикер: Руслан Гайнанов, тимлид DevOps-команды в ИТ-Холдинге Т1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
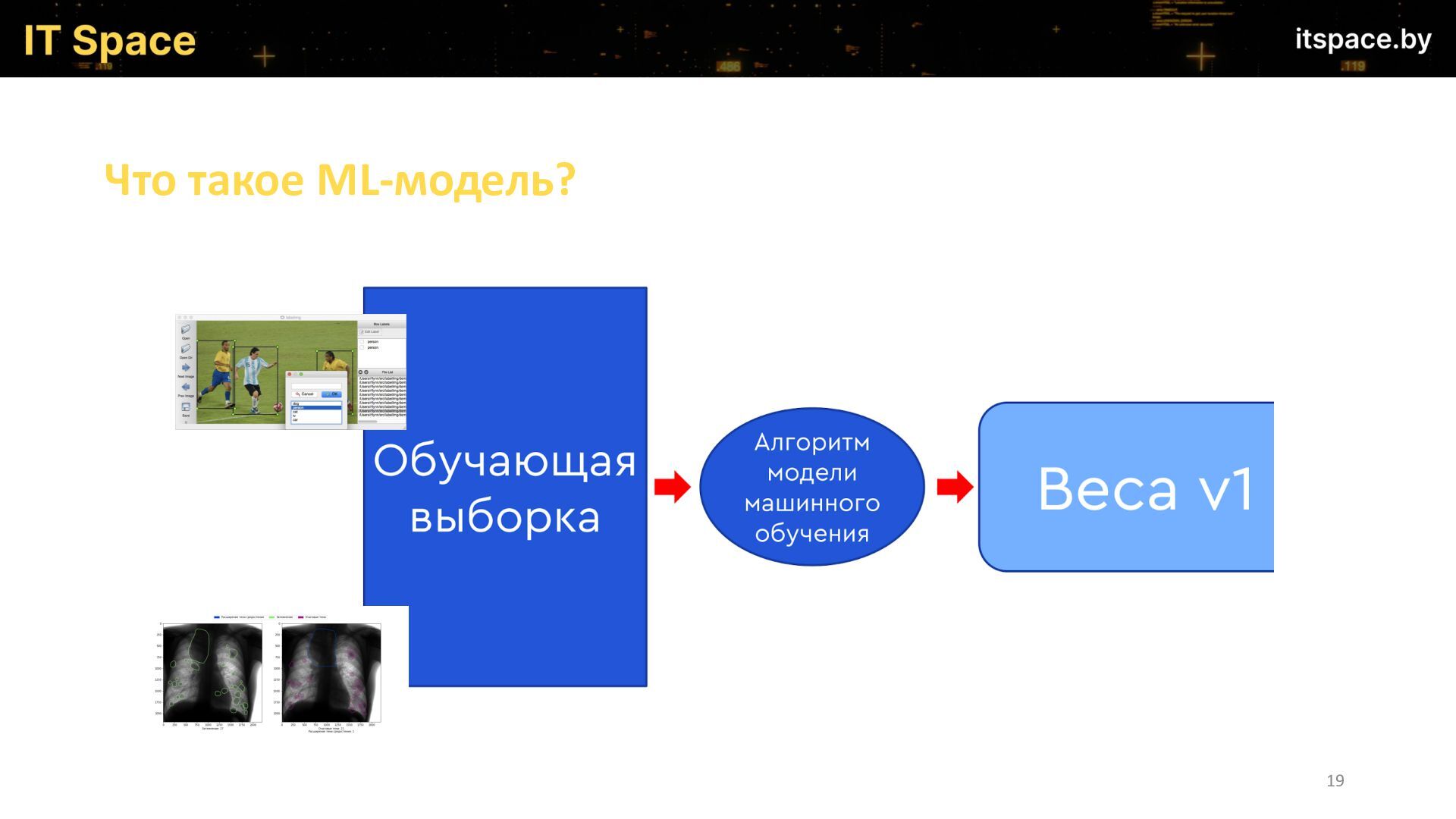{kind=link}
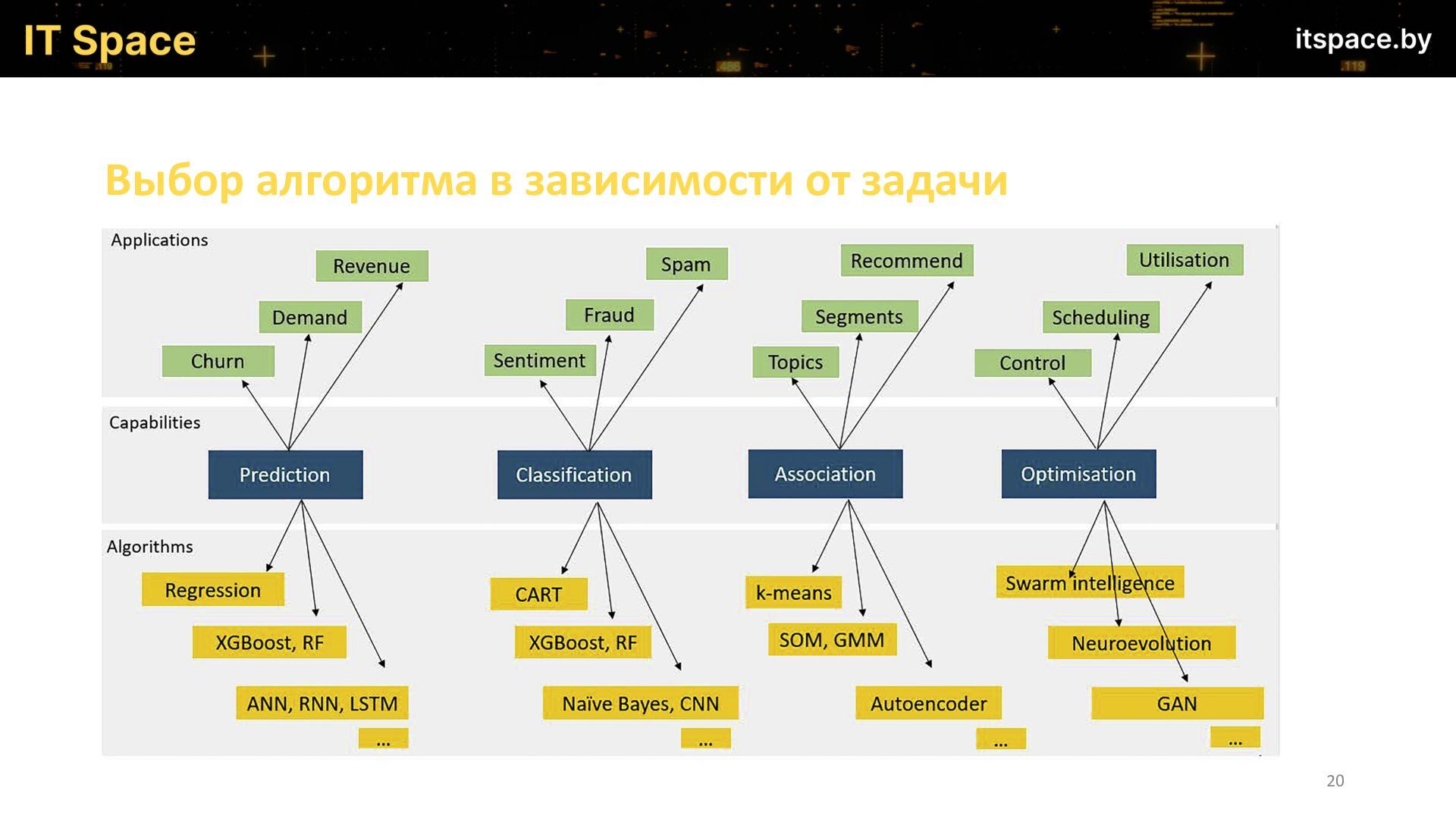{kind=link}
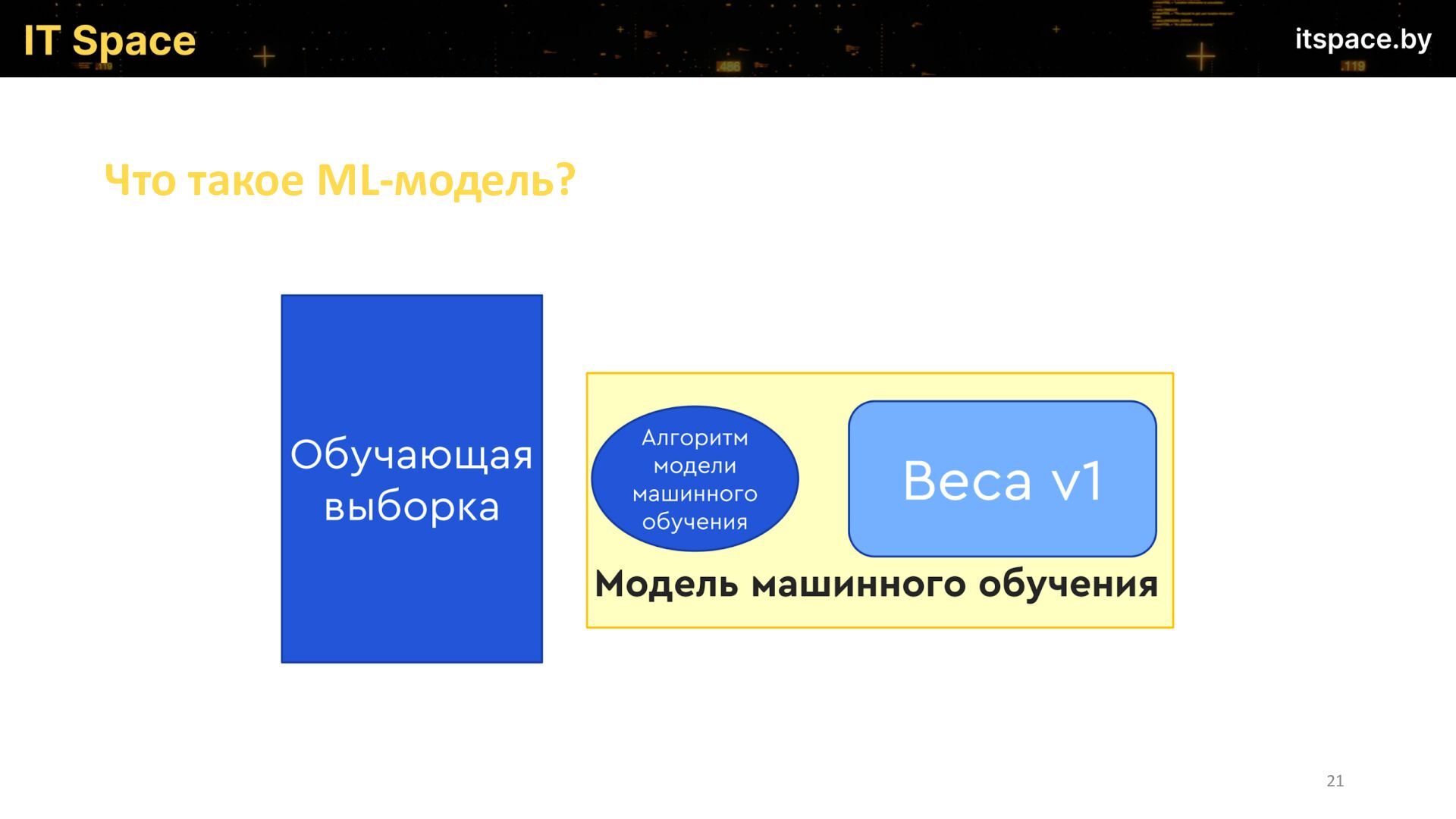{kind=link}
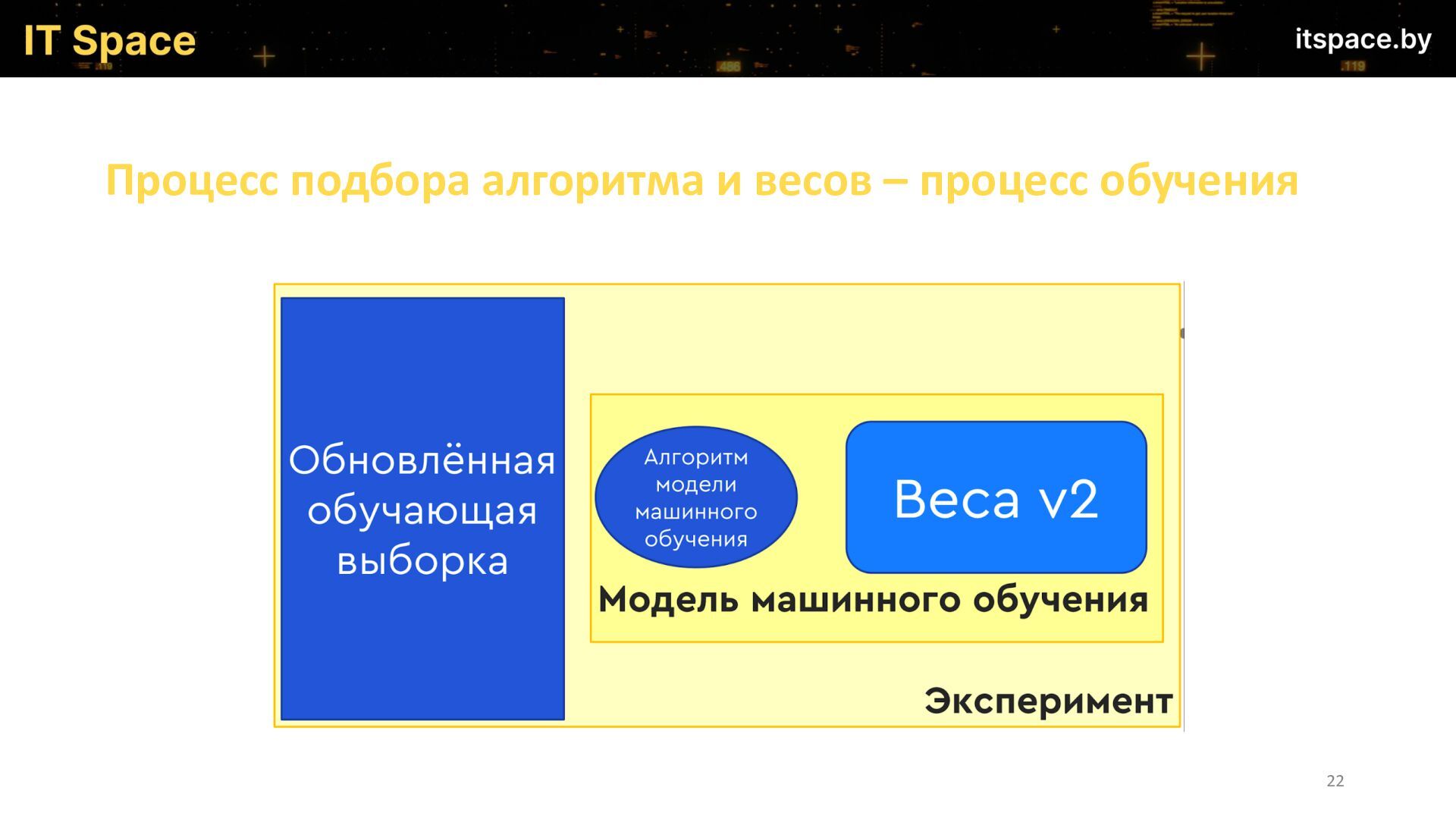{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}