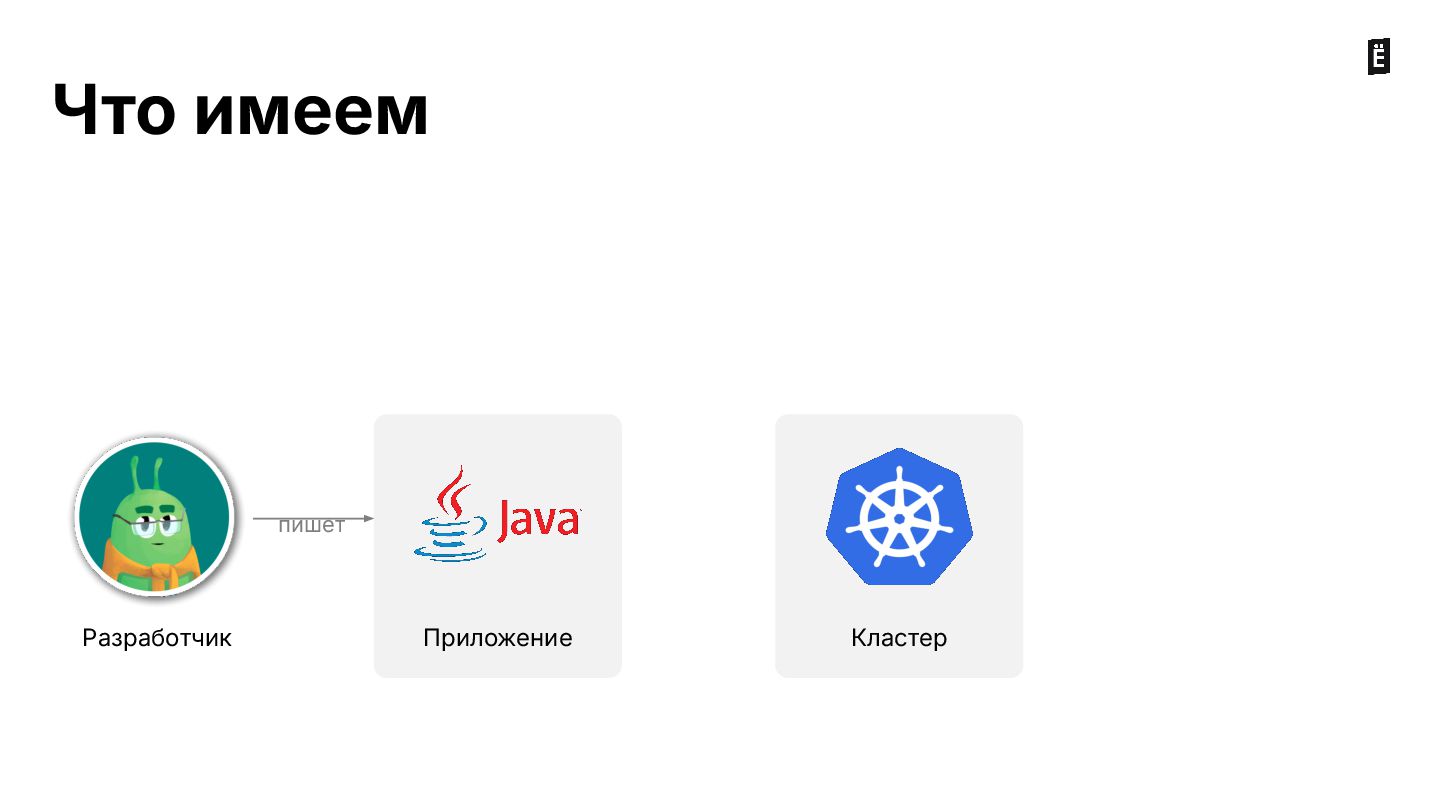
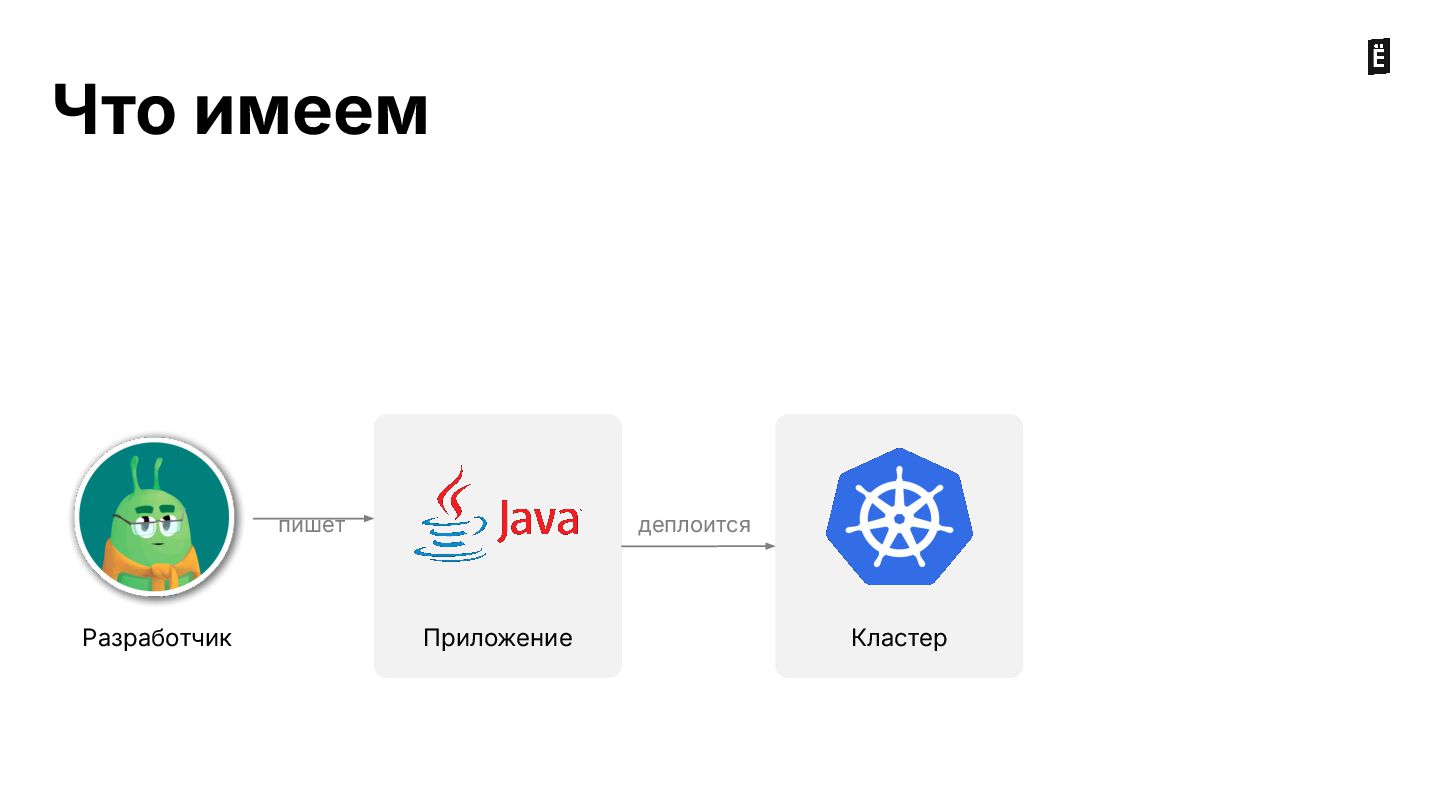
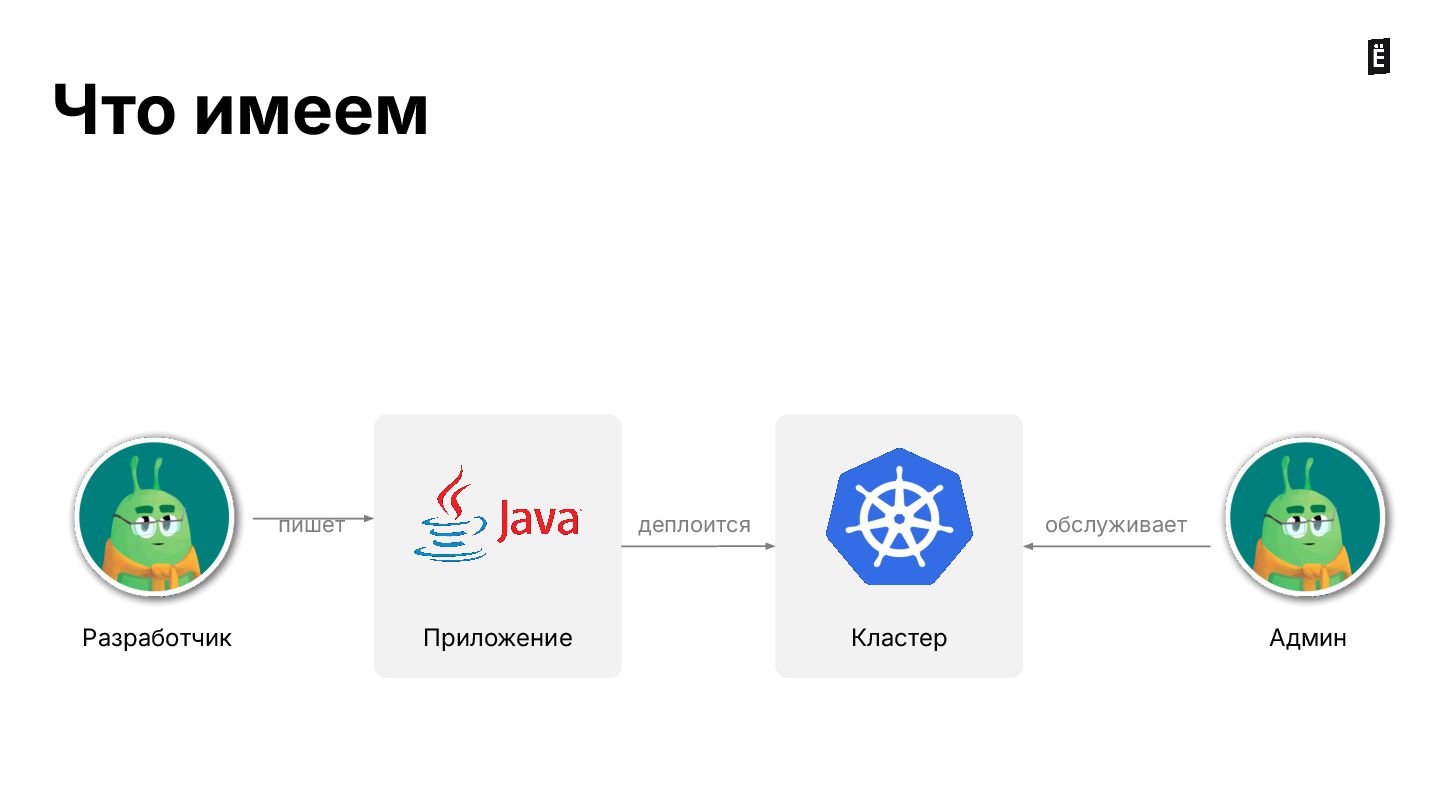
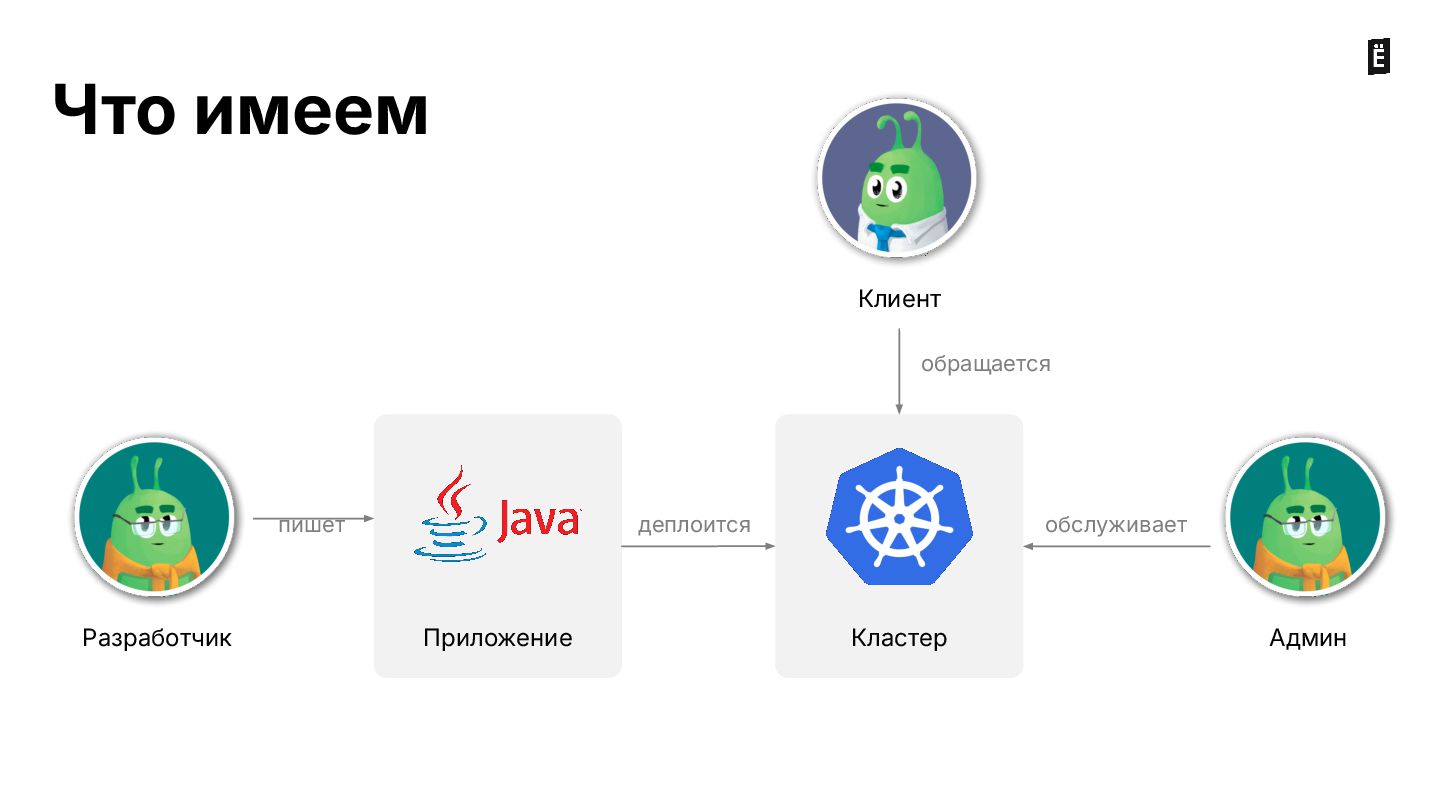
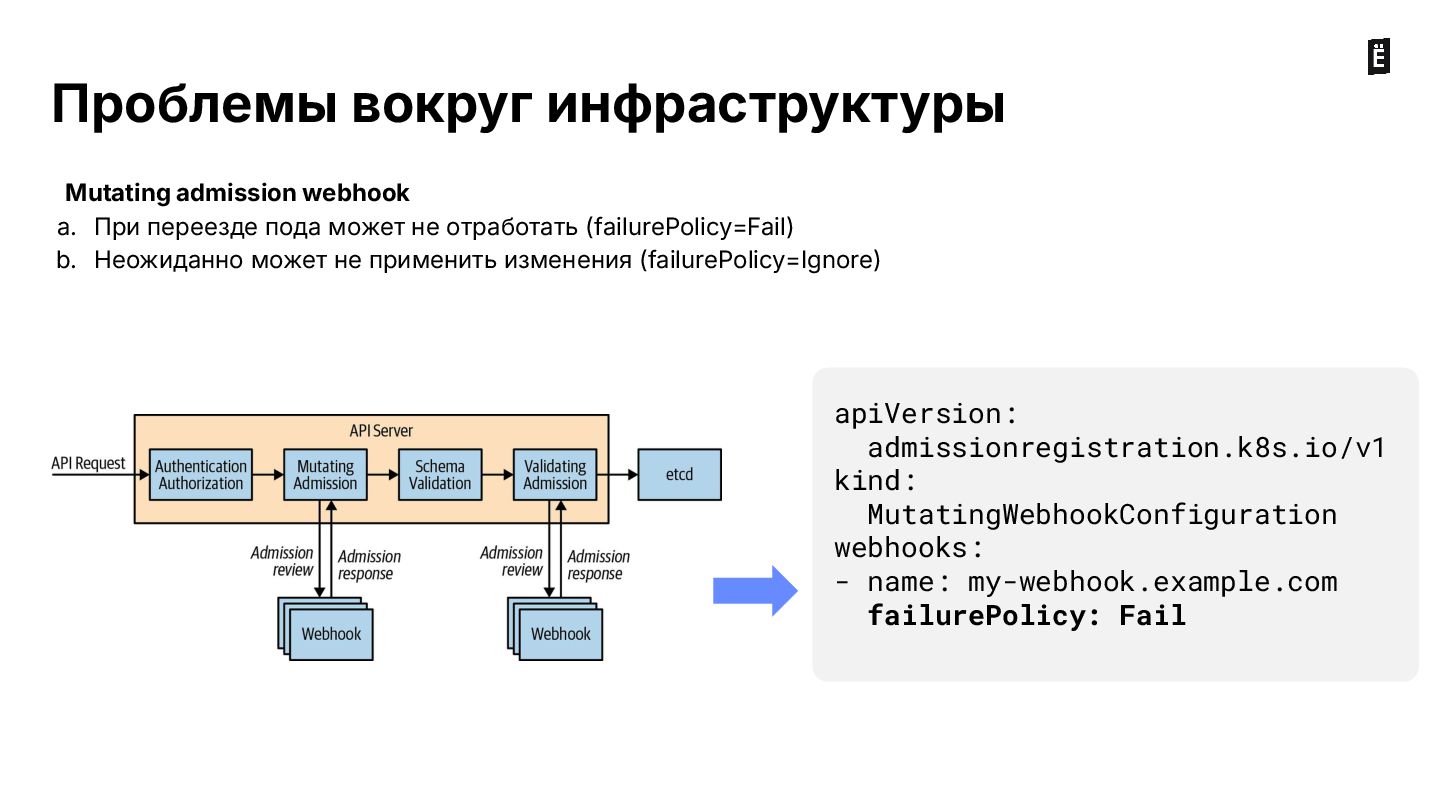
На вебинаре разбираем типовые ошибки, которые можно допустить при деплое сервисов в кластер: от некорректной настройки лимитов ресурсов до сложных кейсов с admission webhooks.
В конце вебинара будут даны рекомендации по настройке вашего кластера и приложений для безотказной работы.
Запись доклада:
https://vk.com/video-59405817_456239816
https://rutube.ru/video/9b354b74f4ec5c72d4b2e1a5d0ade6a5/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
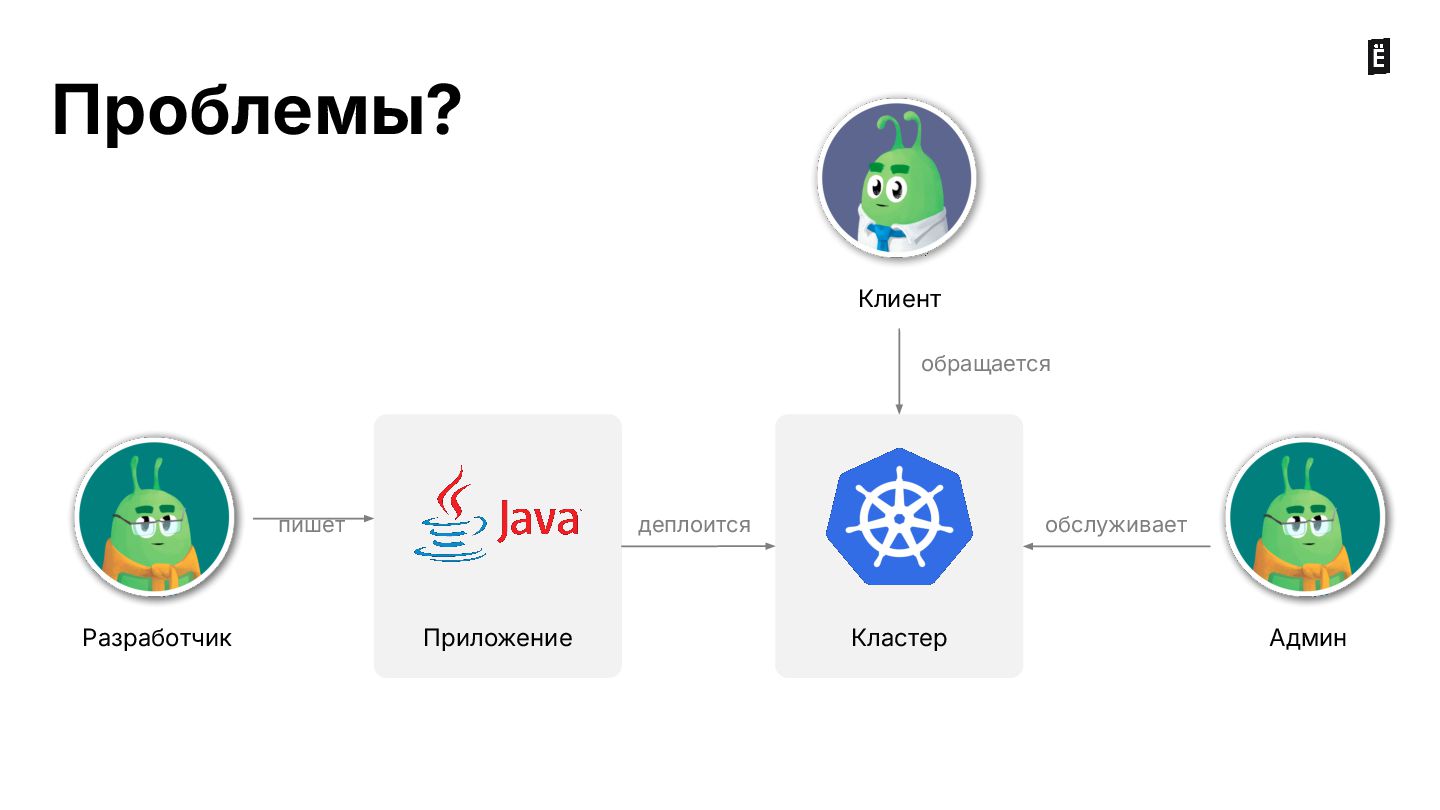{kind=link}
{kind=link}
{kind=link}
{kind=link}
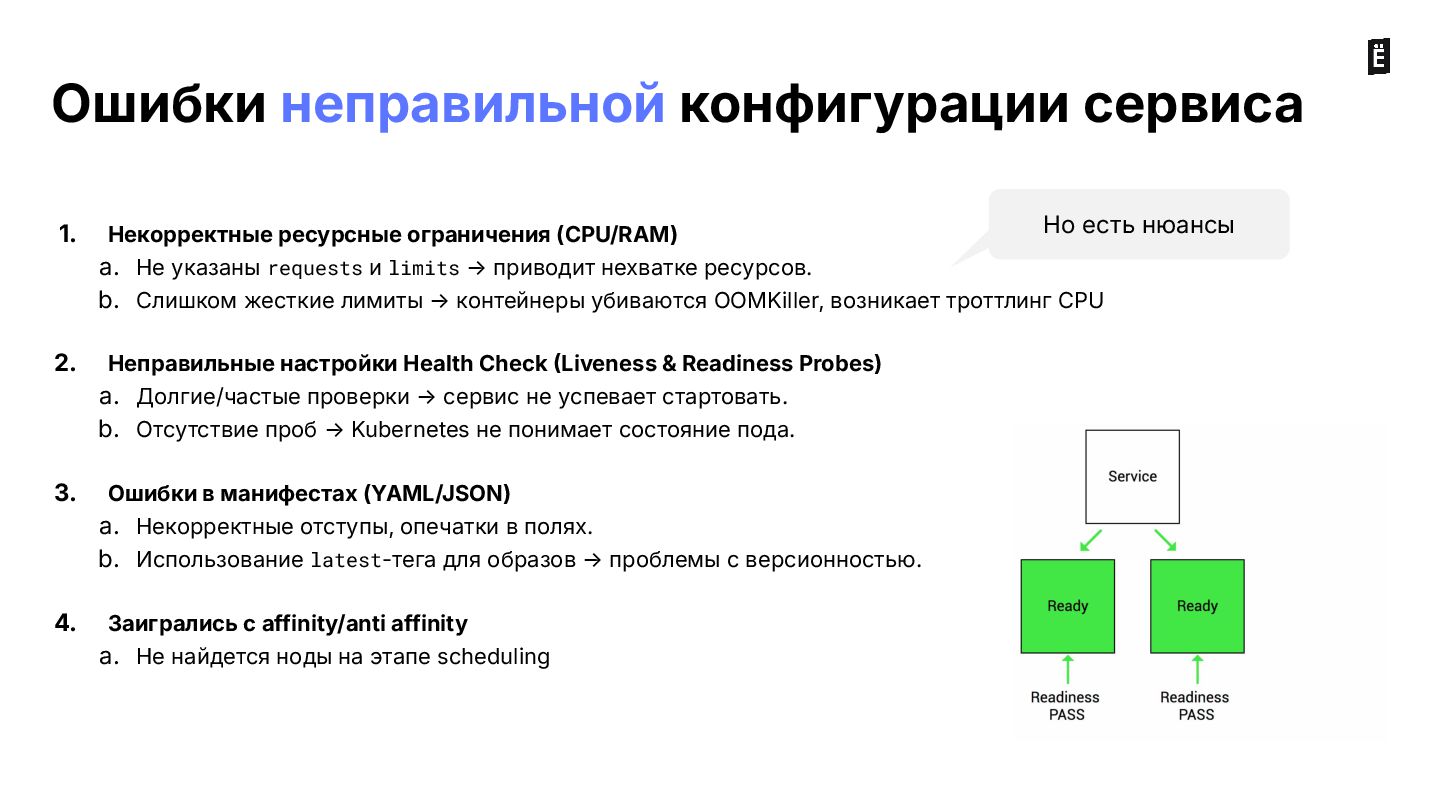{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
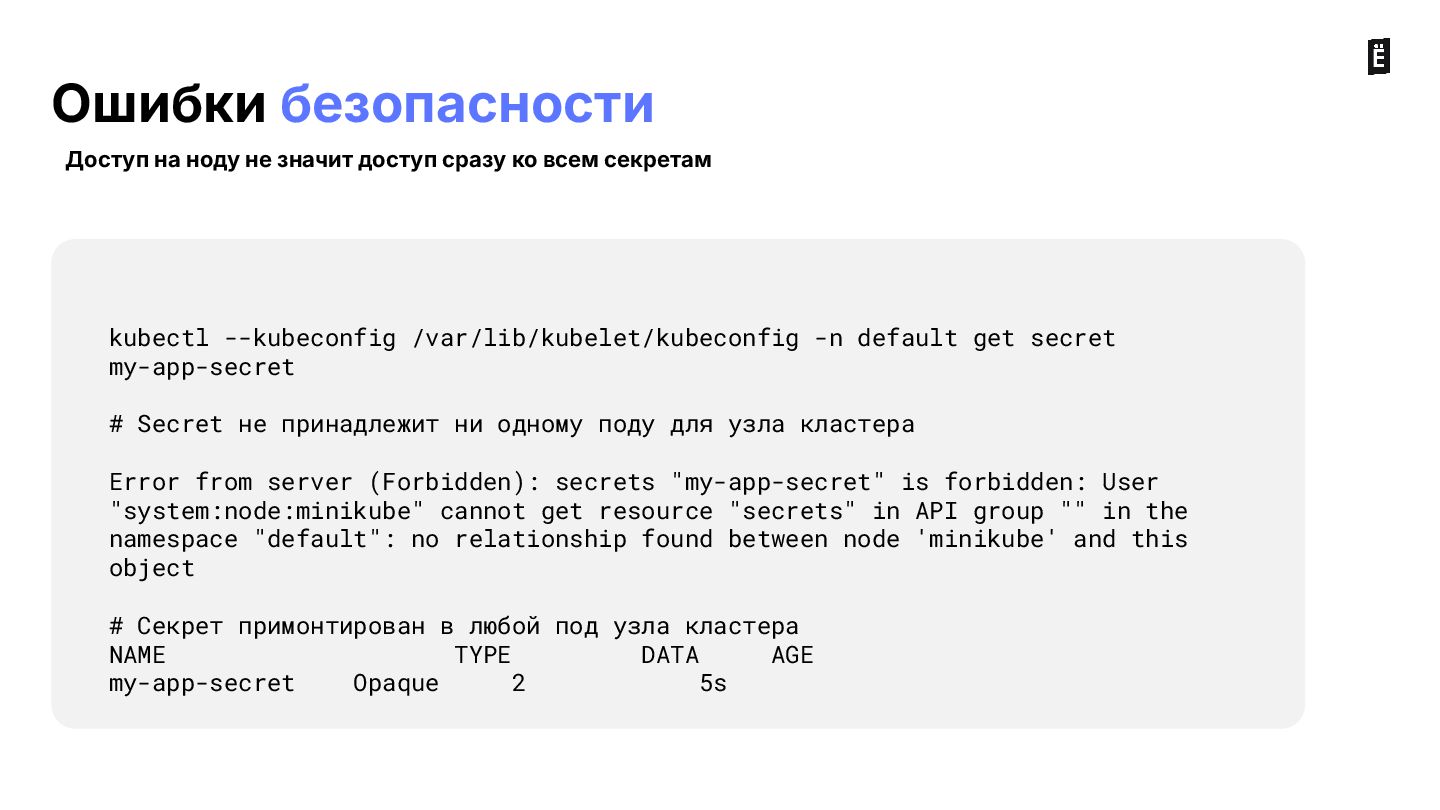{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}