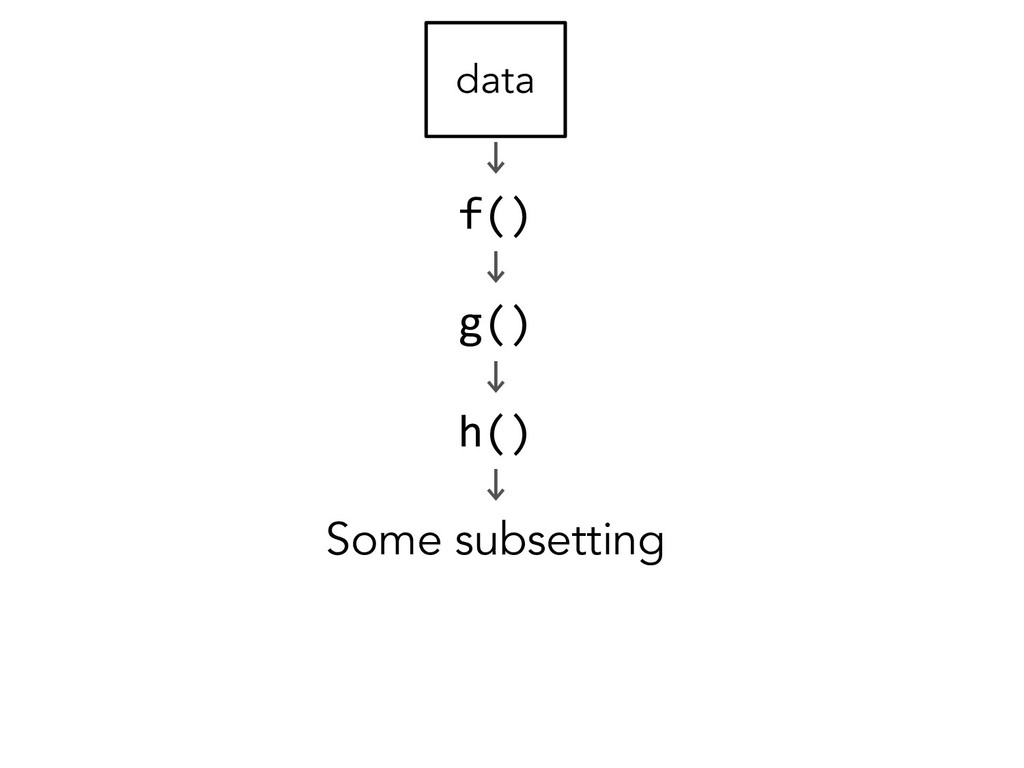
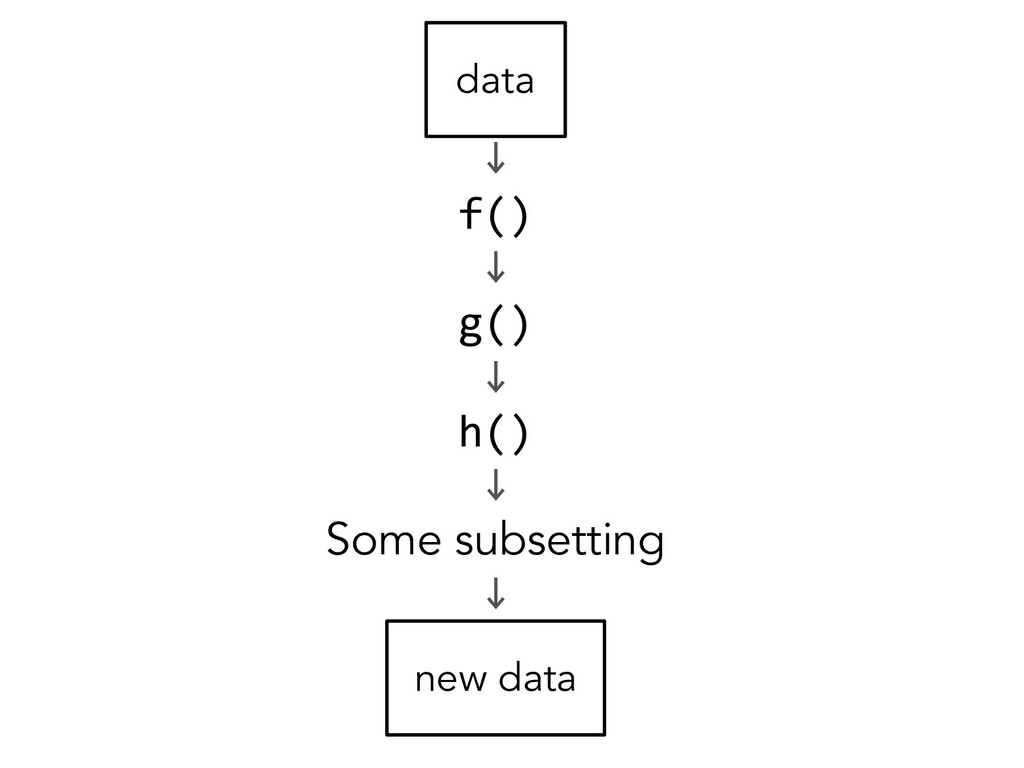
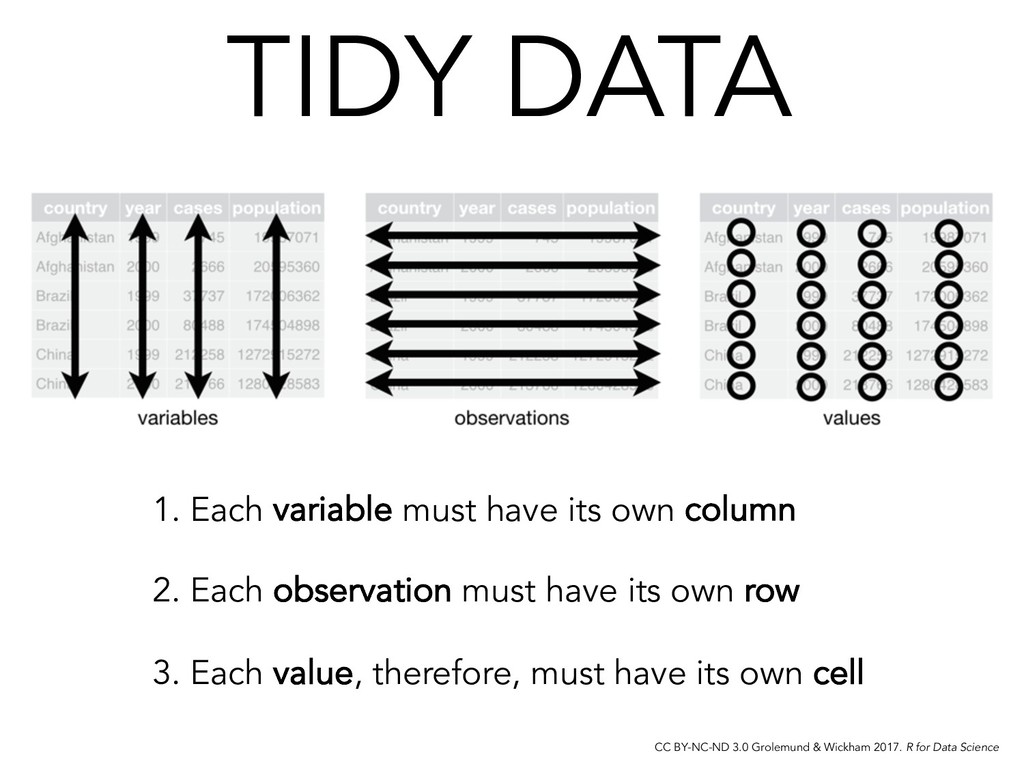
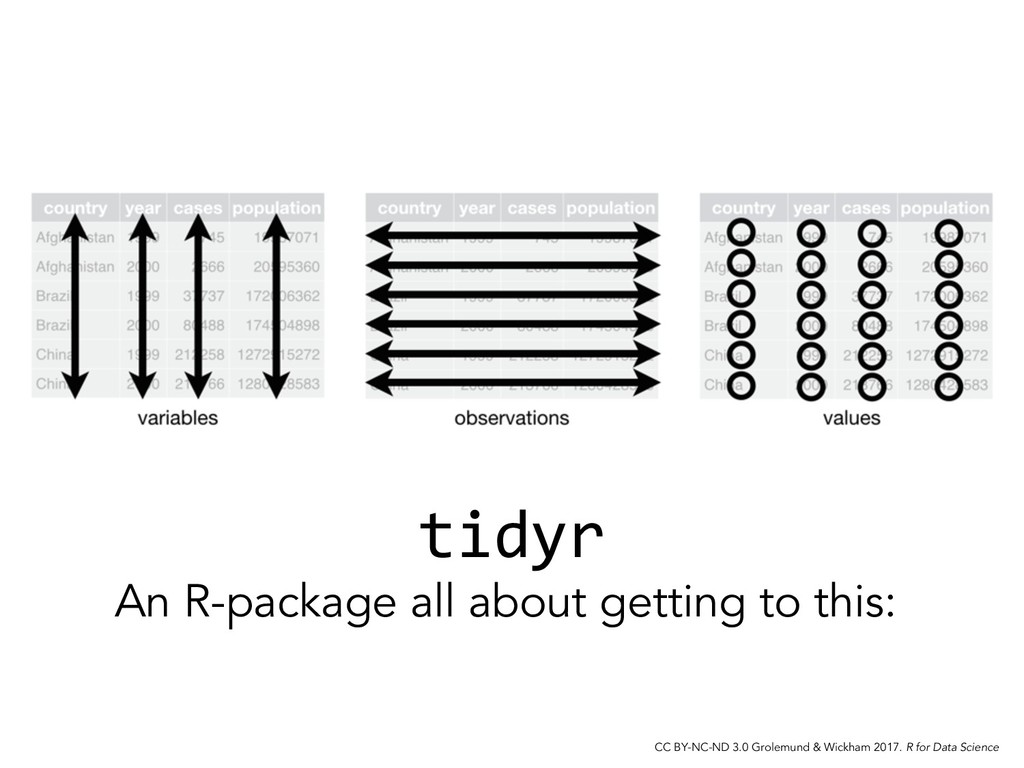
# if > 1 observation per row spread() # if observations live in > 1 row # Untidy variables? separate() # if > 1 variable per column unite() # if variables live in > 1 column
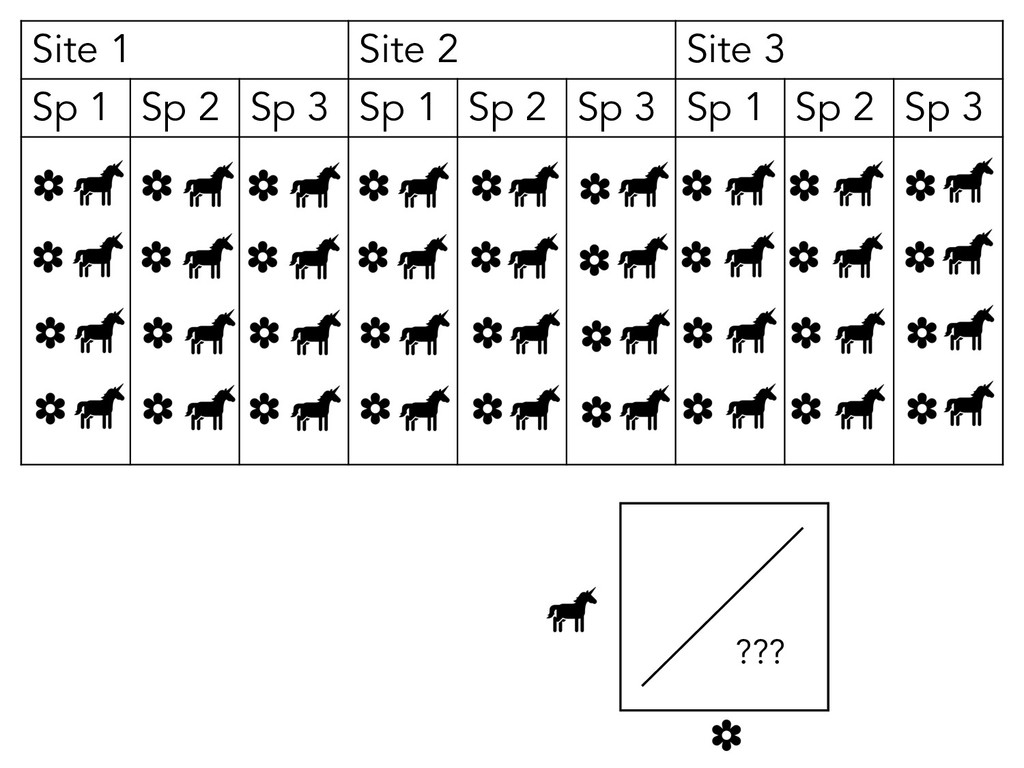
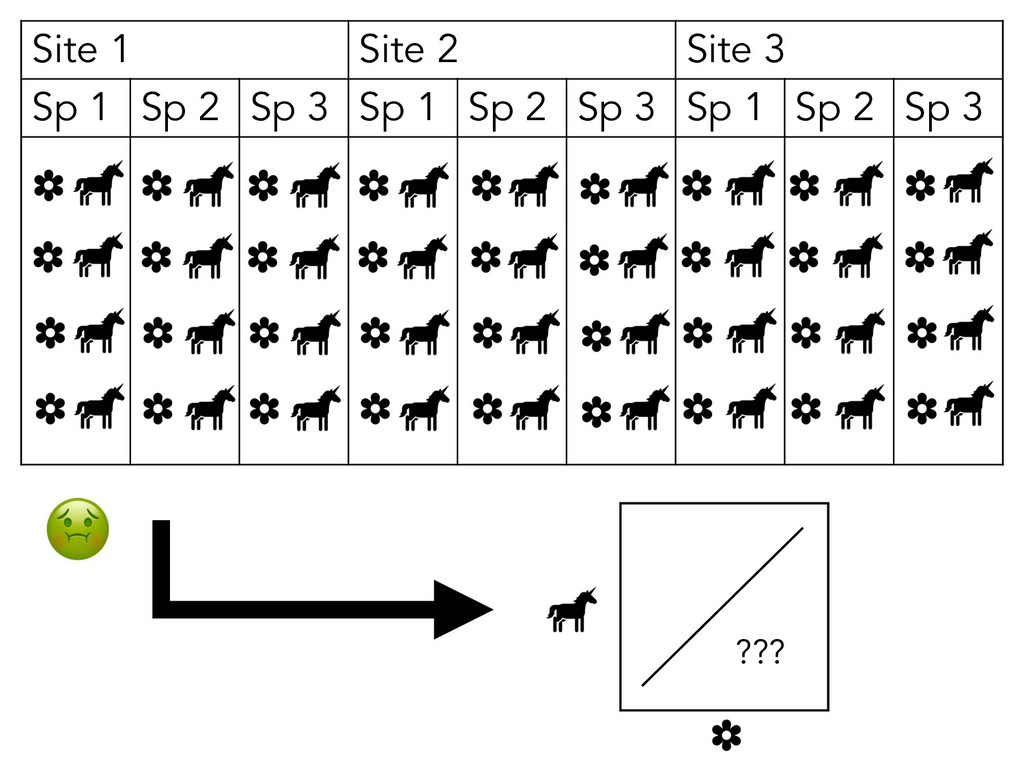
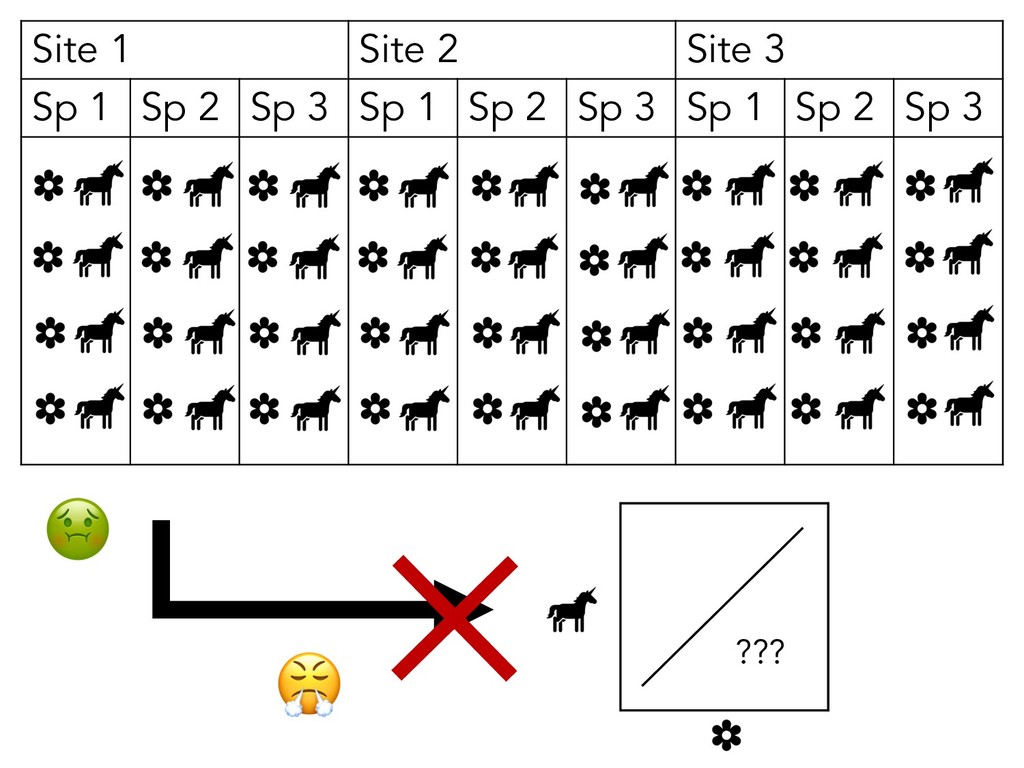
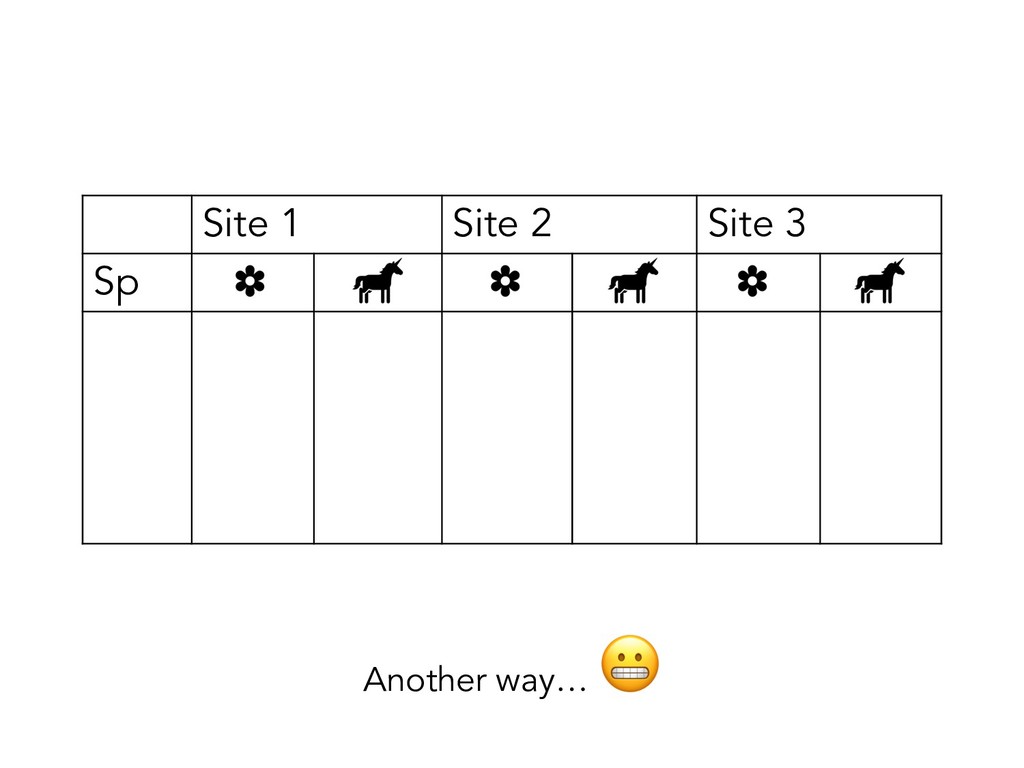
what your observations are: • Like, what unit of your study “counts” as an observation • E.g. Leaf traits: plant leaf vs plant individual • E.g. Reproductive success: egg size vs clutch size
what your observations are: • Like, what unit of your study “counts” as an observation • E.g. Leaf traits: plant leaf vs plant individual • E.g. Reproductive success: egg size vs clutch size • This will depend on your study &/or data!
what your observations are: • Like, what unit of your study “counts” as an observation • E.g. Leaf traits: plant leaf vs plant individual • E.g. Reproductive success: egg size vs clutch size • This will depend on your study &/or data! • Variables are discrete, separate ideas!
what your observations are: • Like, what unit of your study “counts” as an observation • E.g. Leaf traits: plant leaf vs plant individual • E.g. Reproductive success: egg size vs clutch size • This will depend on your study &/or data! • Variables are discrete, separate ideas! • But again, this will depend on your study &/or data!
# if > 1 observation per row spread() # if observations live in > 1 row # Untidy variables? separate() # if > 1 variable per column unite() # if variables live in > 1 column
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![> workshop$outline[1:3]](https://files.speakerdeck.com/presentations/53b8dfb5aee34766bbca429521ce3625/slide_12.jpg){kind=link}
![> workshop$outline[1:3] DAY 1 Tidy data principles & tidyr](https://files.speakerdeck.com/presentations/53b8dfb5aee34766bbca429521ce3625/slide_13.jpg){kind=link}
![> workshop$outline[1:3] DAY 1 Tidy data principles & tidyr DAY](https://files.speakerdeck.com/presentations/53b8dfb5aee34766bbca429521ce3625/slide_14.jpg){kind=link}
![> workshop$outline[-(1:3)]](https://files.speakerdeck.com/presentations/53b8dfb5aee34766bbca429521ce3625/slide_15.jpg){kind=link}
![> workshop$outline[-(1:3)] 2 dialects of R:](https://files.speakerdeck.com/presentations/53b8dfb5aee34766bbca429521ce3625/slide_16.jpg){kind=link}
![> workshop$outline[-(1:3)] 2 dialects of R: base $ [] [[]]](https://files.speakerdeck.com/presentations/53b8dfb5aee34766bbca429521ce3625/slide_17.jpg){kind=link}
![> workshop$outline[-(1:3)] 2 dialects of R: base $ [] [[]]](https://files.speakerdeck.com/presentations/53b8dfb5aee34766bbca429521ce3625/slide_18.jpg){kind=link}
{kind=link}
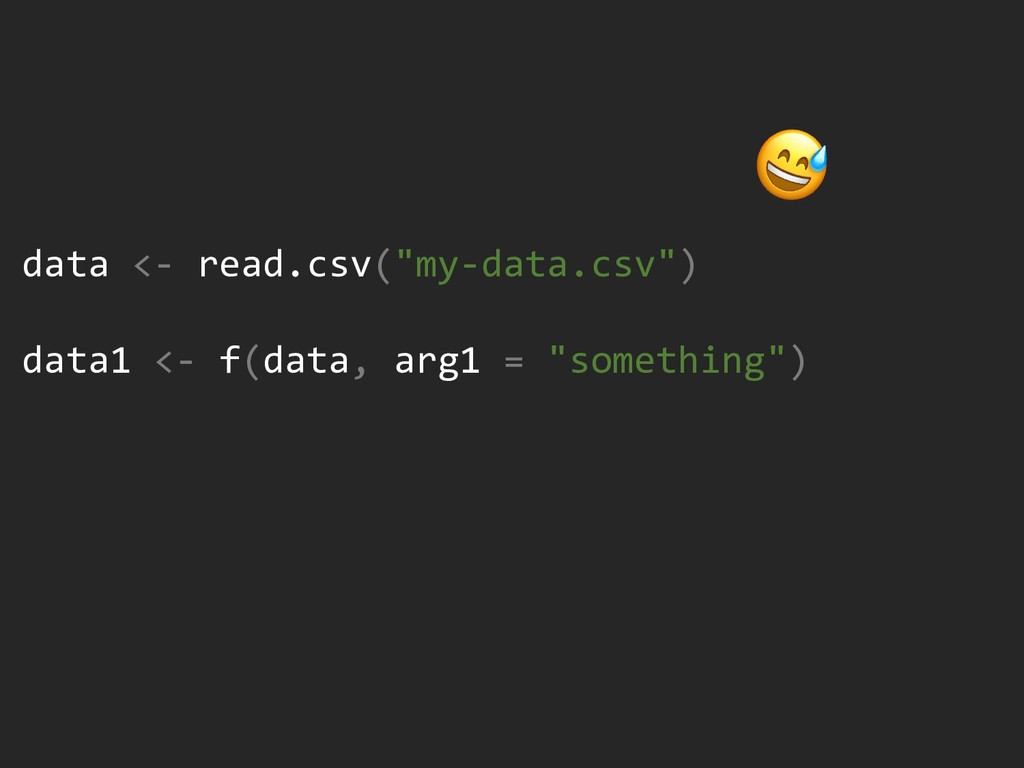{kind=link}
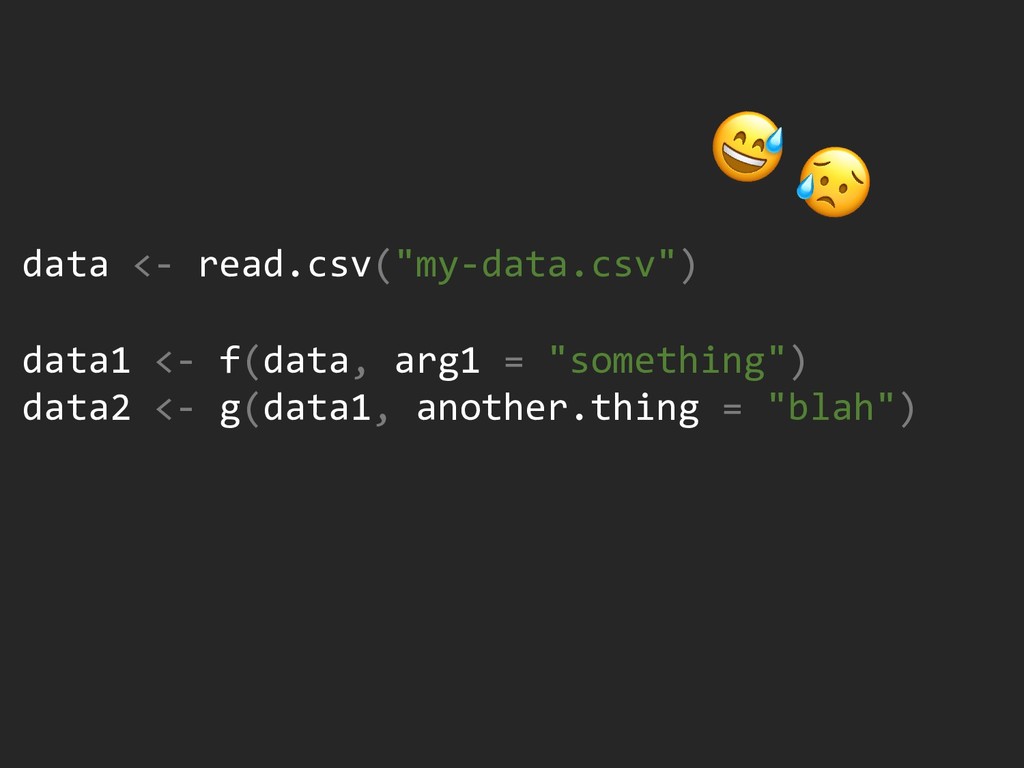{kind=link}
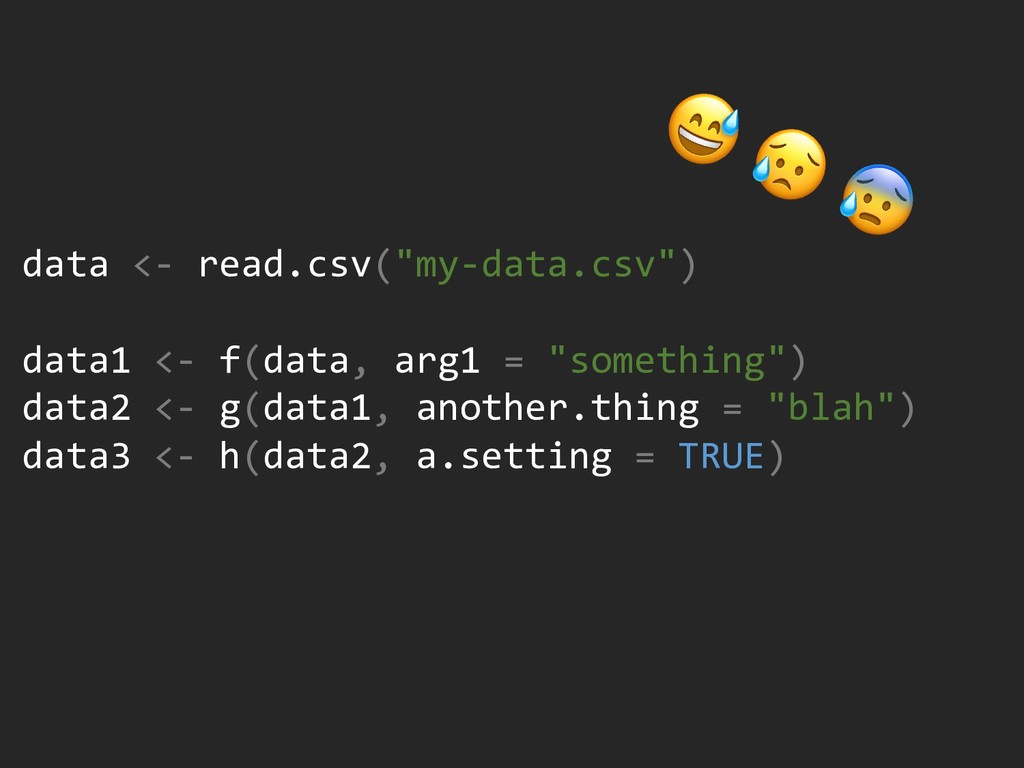{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![%>% Solution: the pipe! { } [ ] [[ ]]](https://files.speakerdeck.com/presentations/53b8dfb5aee34766bbca429521ce3625/slide_36.jpg){kind=link}
![%>% Solution: the pipe! { } [ ] [[ ]]](https://files.speakerdeck.com/presentations/53b8dfb5aee34766bbca429521ce3625/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
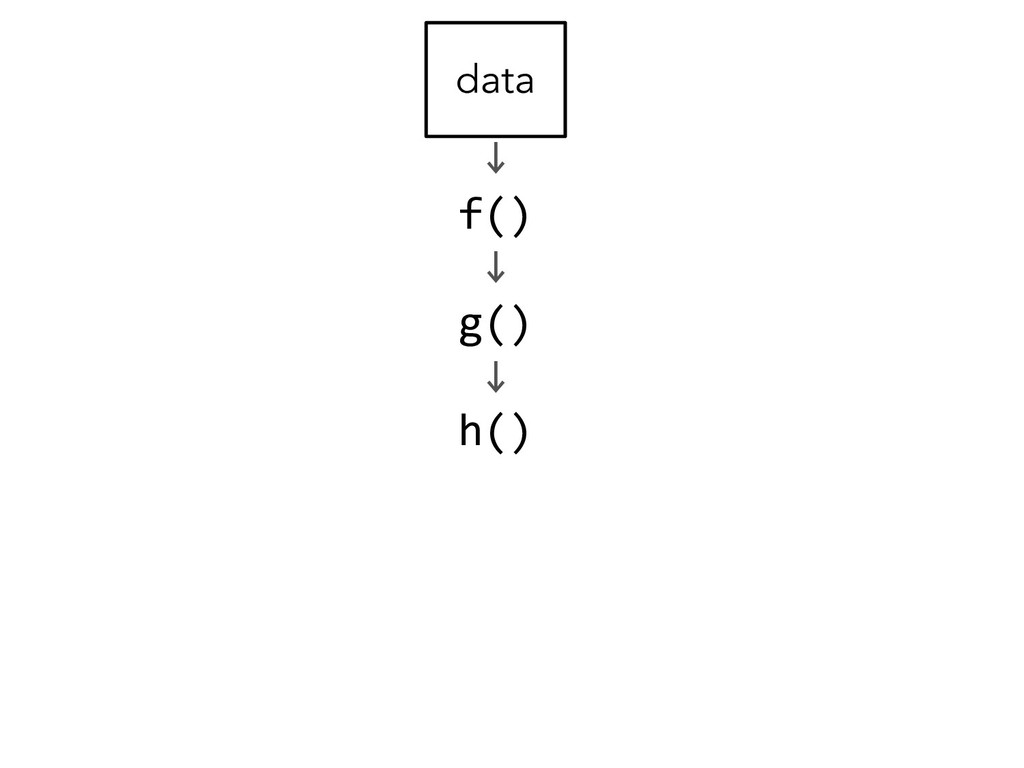{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
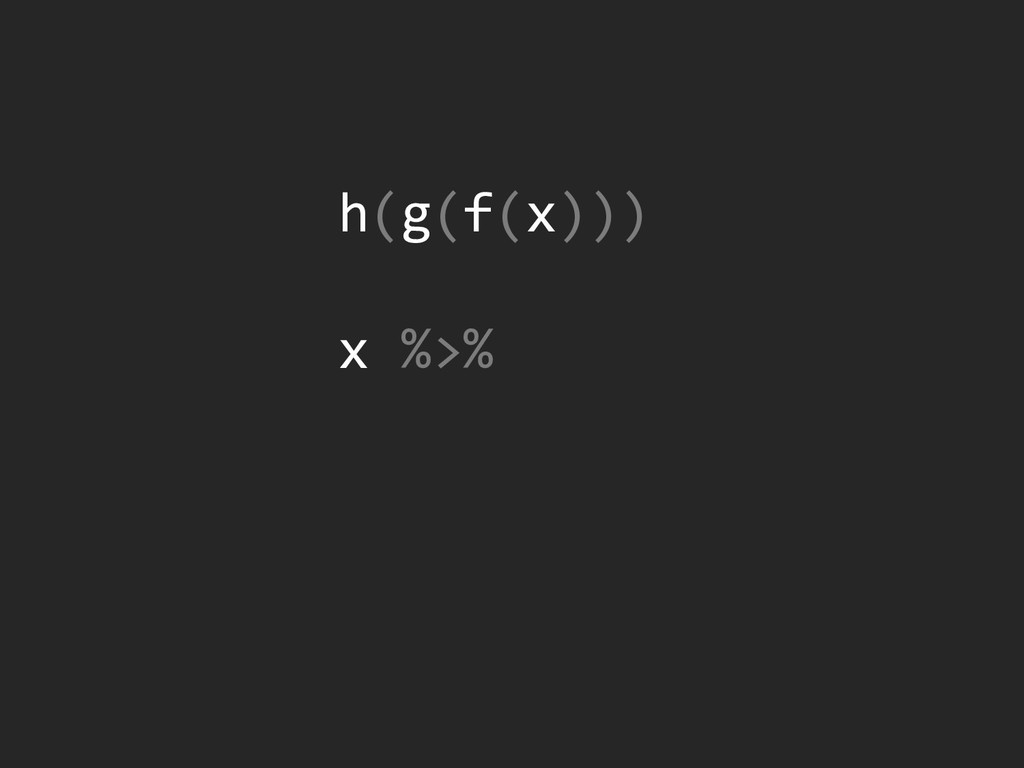{kind=link}
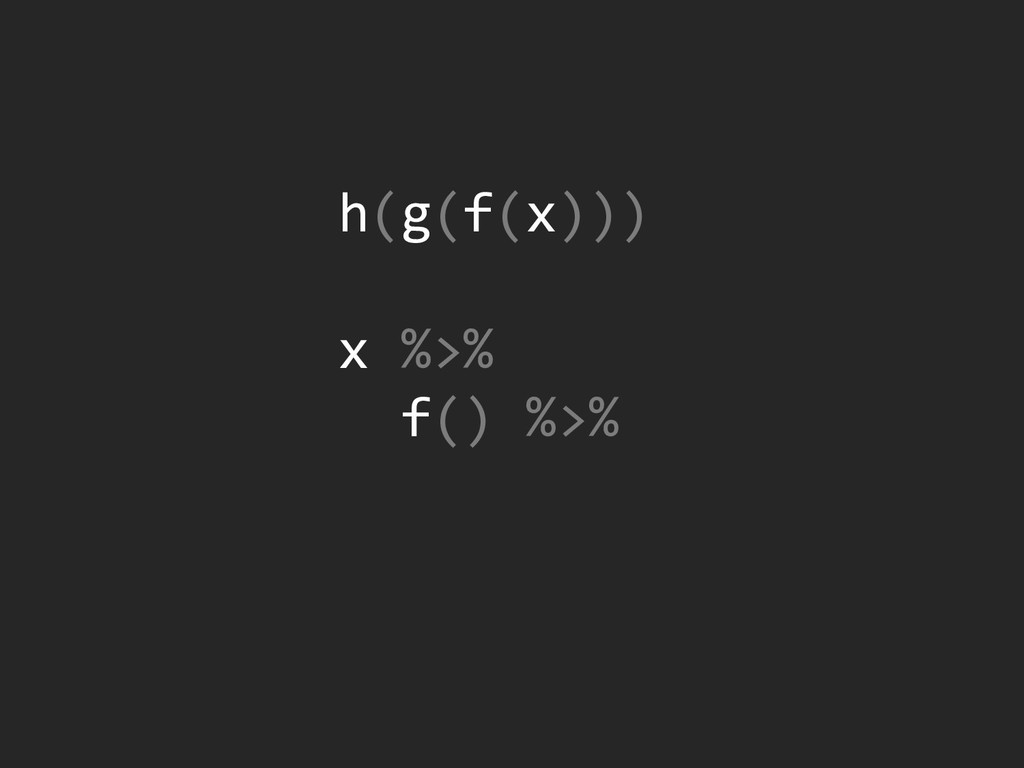{kind=link}
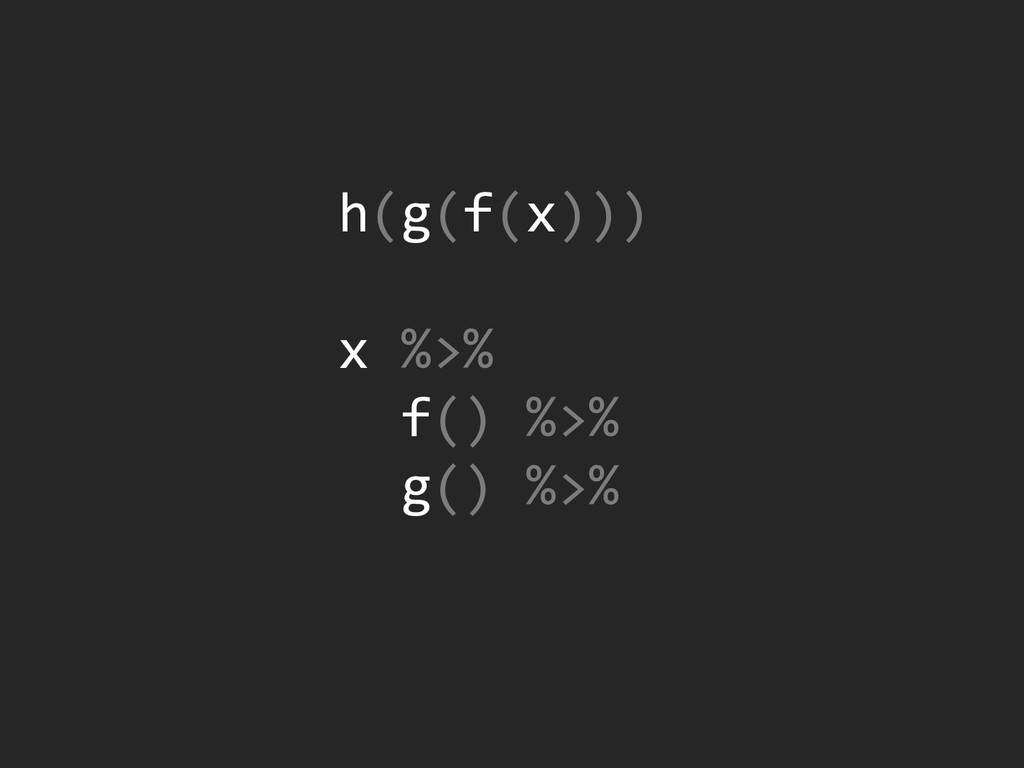{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
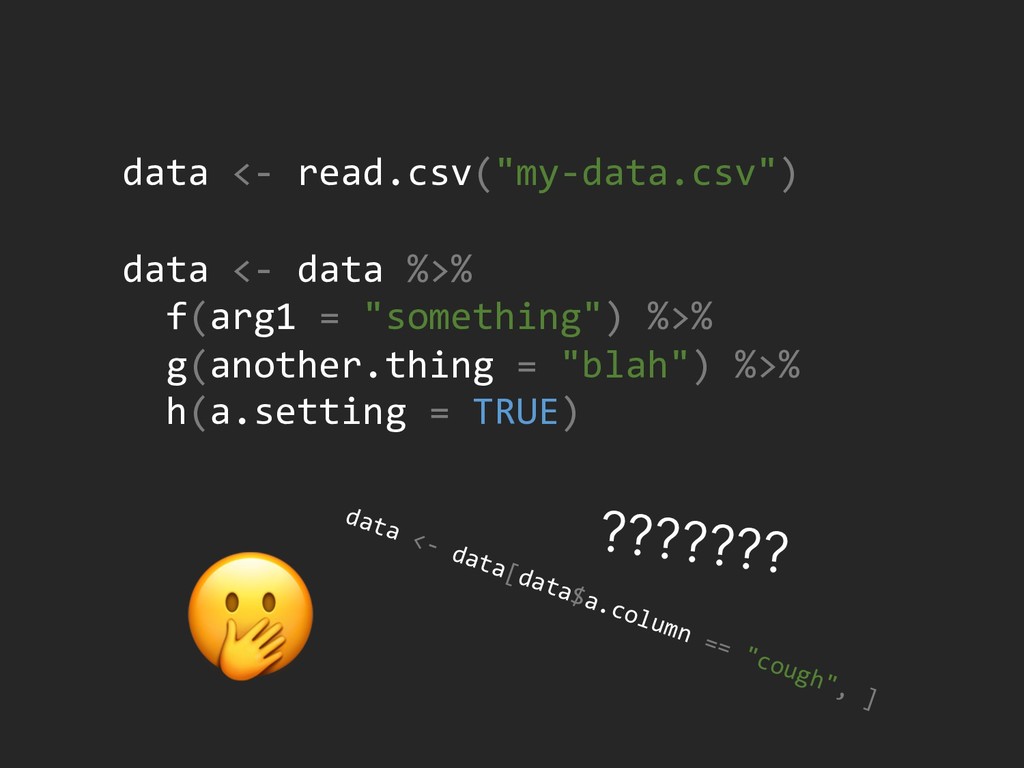{kind=link}
![> workshop$outline[1:3] DAY 1 Tidy data principles & tidyr DAY](https://files.speakerdeck.com/presentations/53b8dfb5aee34766bbca429521ce3625/slide_60.jpg){kind=link}
![> workshop$outline[[1]] DAY 1 Tidy data principles & tidyr](https://files.speakerdeck.com/presentations/53b8dfb5aee34766bbca429521ce3625/slide_61.jpg){kind=link}
![> workshop$outline[[1]] DAY 1 Tidy data principles & tidyr](https://files.speakerdeck.com/presentations/53b8dfb5aee34766bbca429521ce3625/slide_62.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
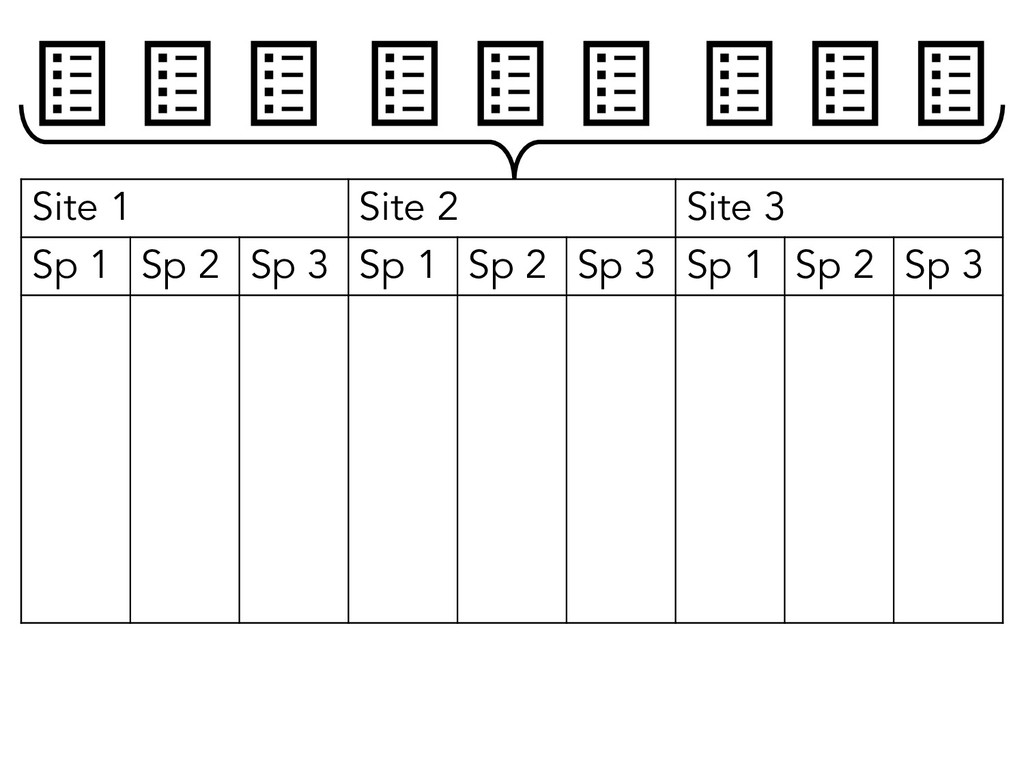{kind=link}
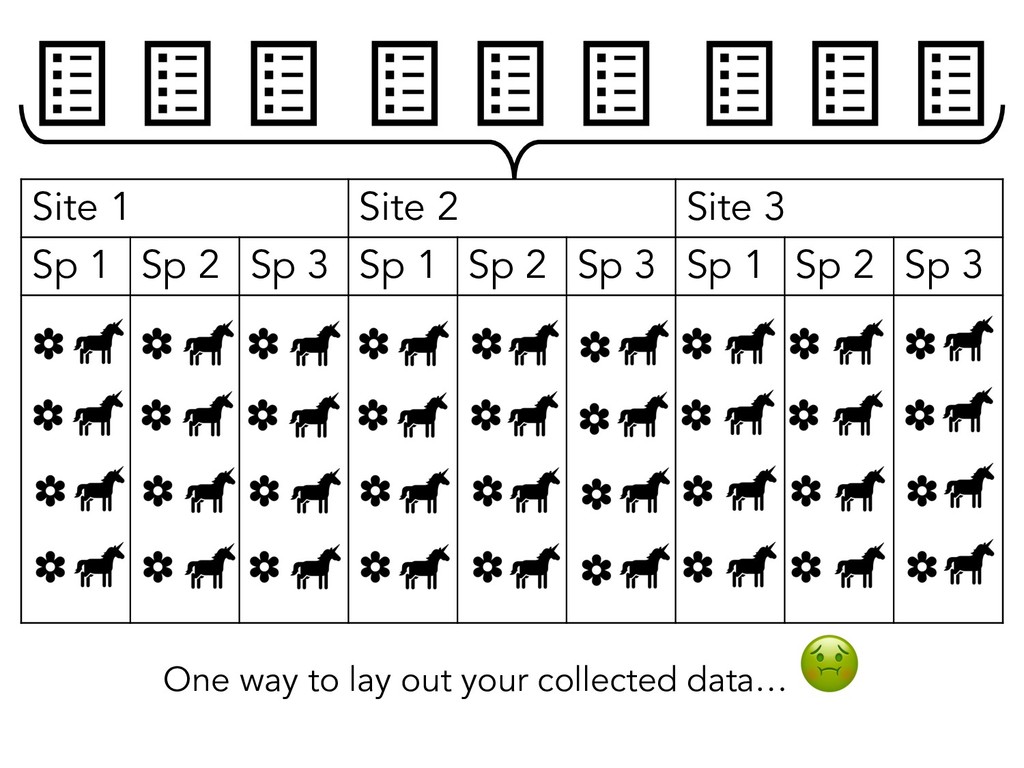{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}