Логистическая регрессия: градиентный спуск с сигмоидой
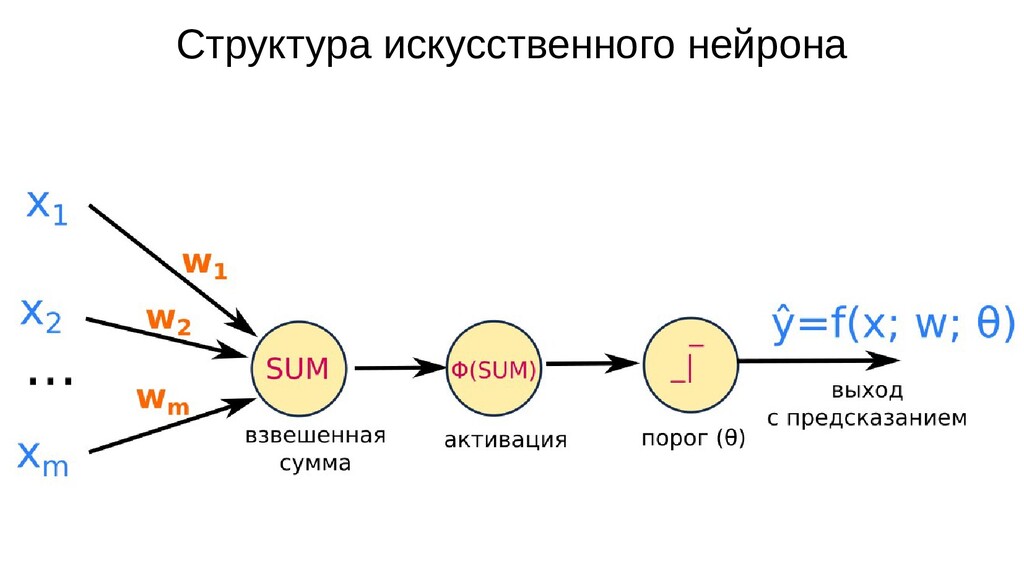
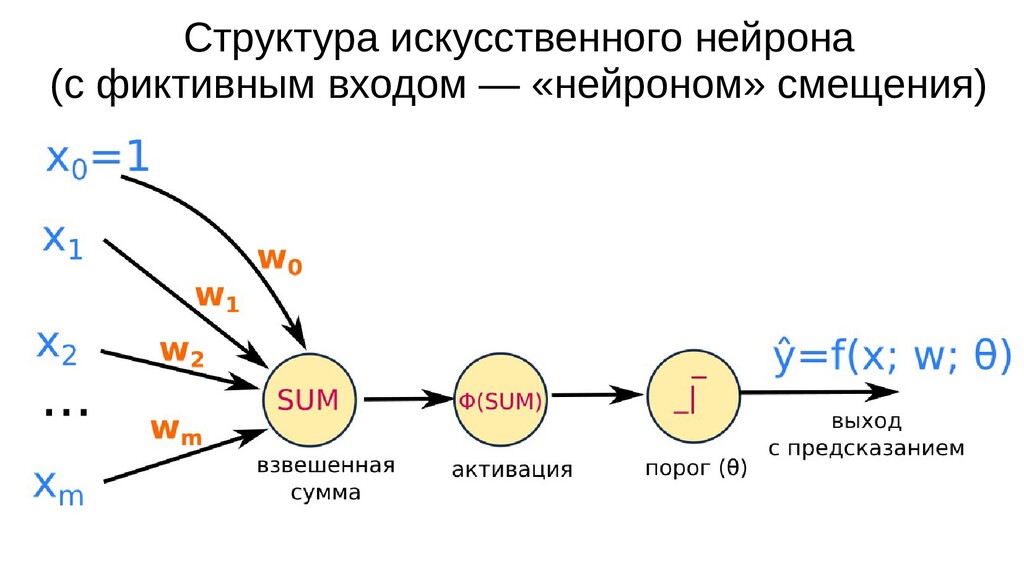
- Архитектура искусственного нейрона класса "Перцептрон": взвешенная сумма, активация, порог - двоичная классификация (разделение объектов на 2 класса)
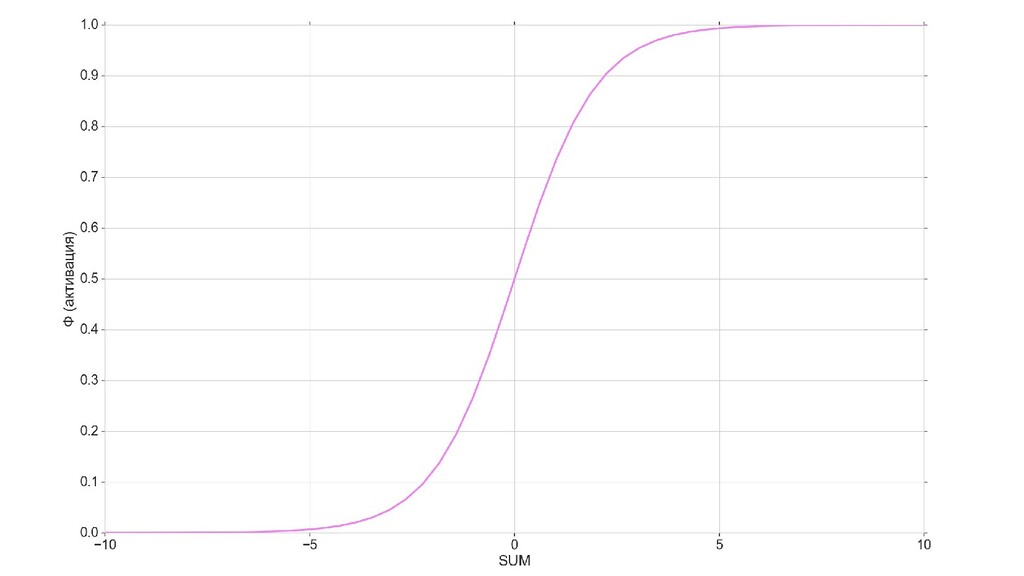
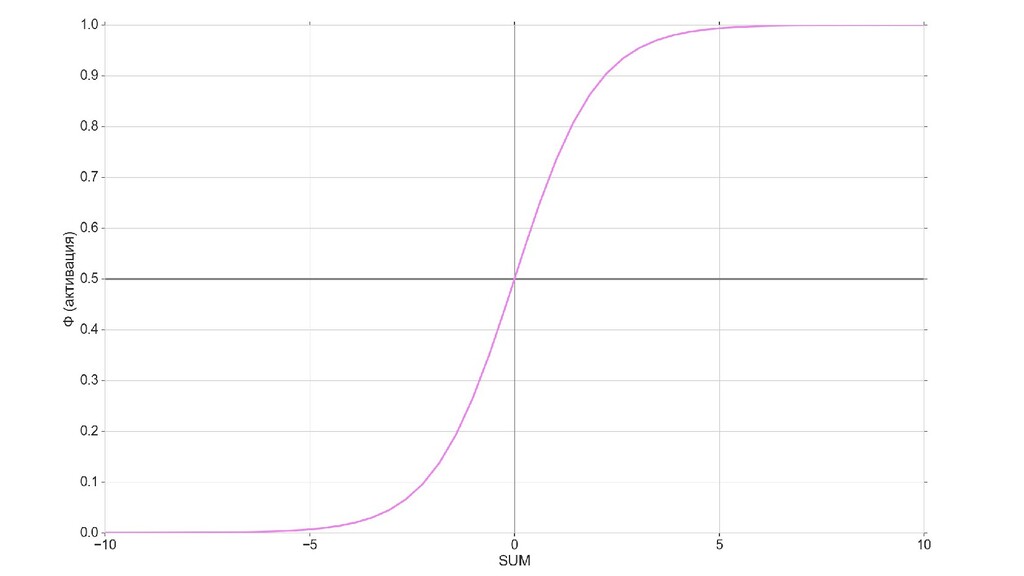
- Логистическая регрессия - сигмоида
- Использование сигмоиды в качестве активации искусственного нейрона
- Решение задачи в 1-мерном пространстве - классификация объектов с единственным признаком
- Геометрический смысл задачи с 1-мерными объектами: построение сигмоиды-активации на плоскости
- Интерпретация значения сигмоиды как вероятности попадания объекта в один из двух классов
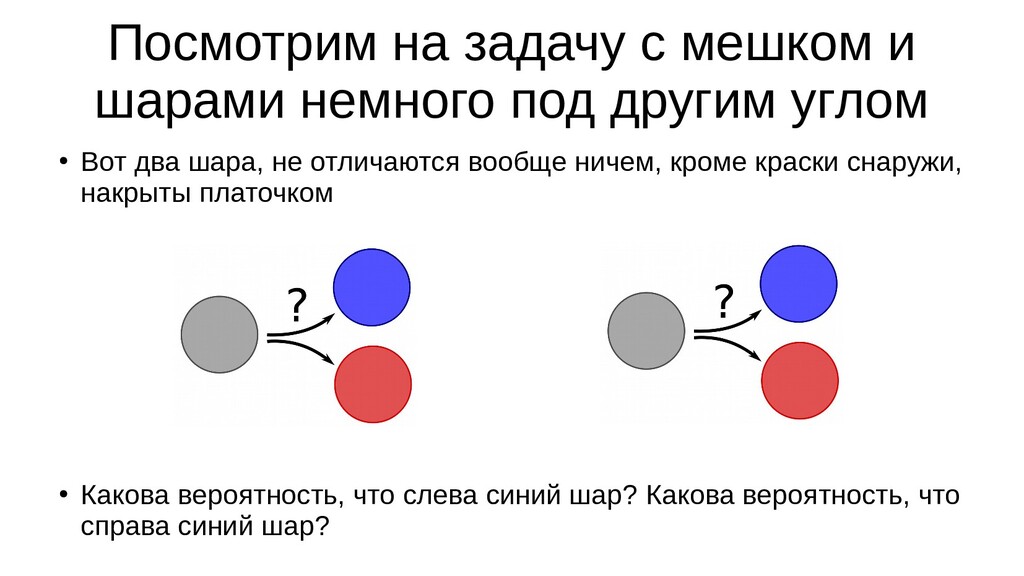
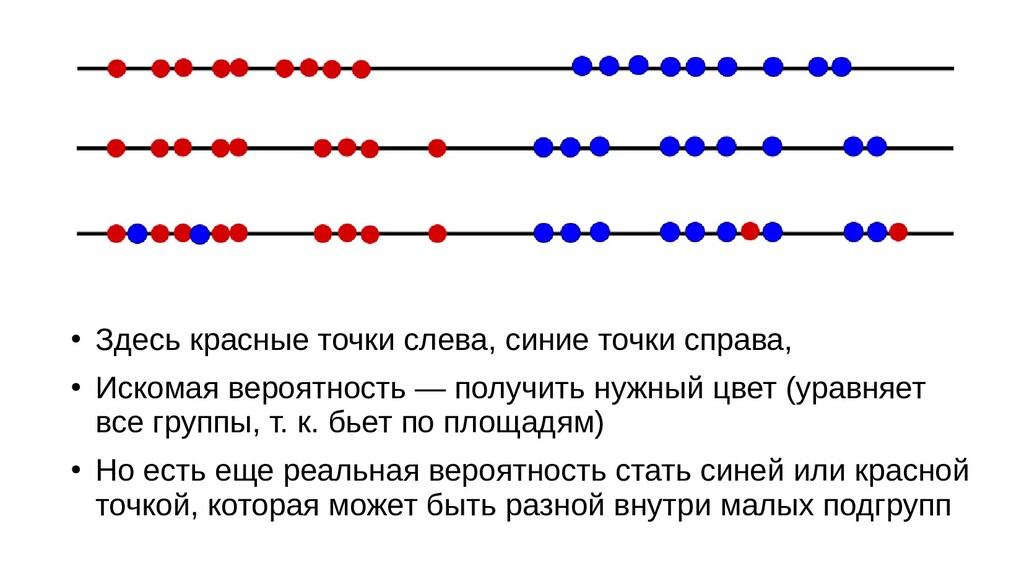
- Теория вероятностей: случайная величина, "природные" случайные величины, роль эксперимента в определении вероятности случайного события
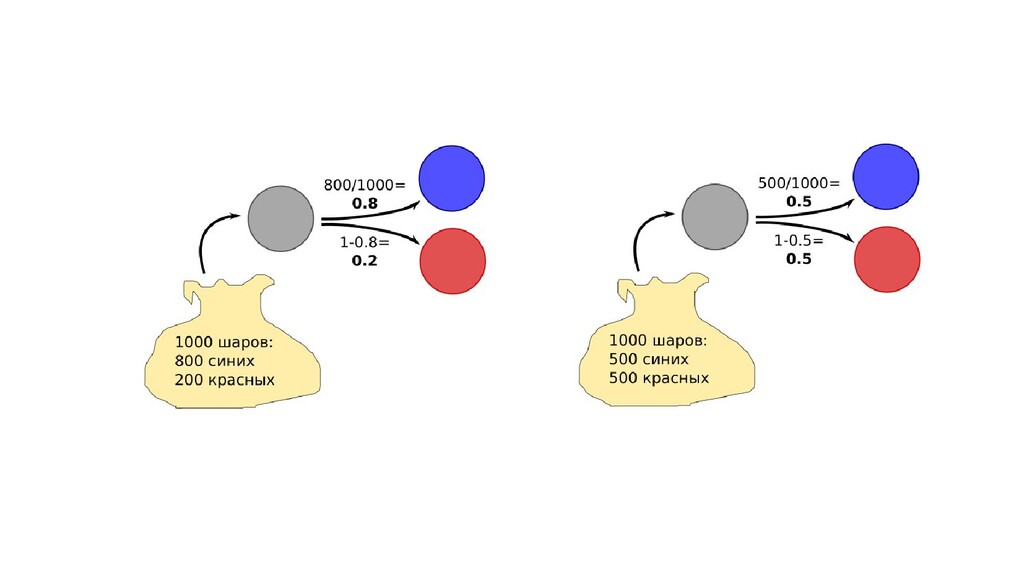
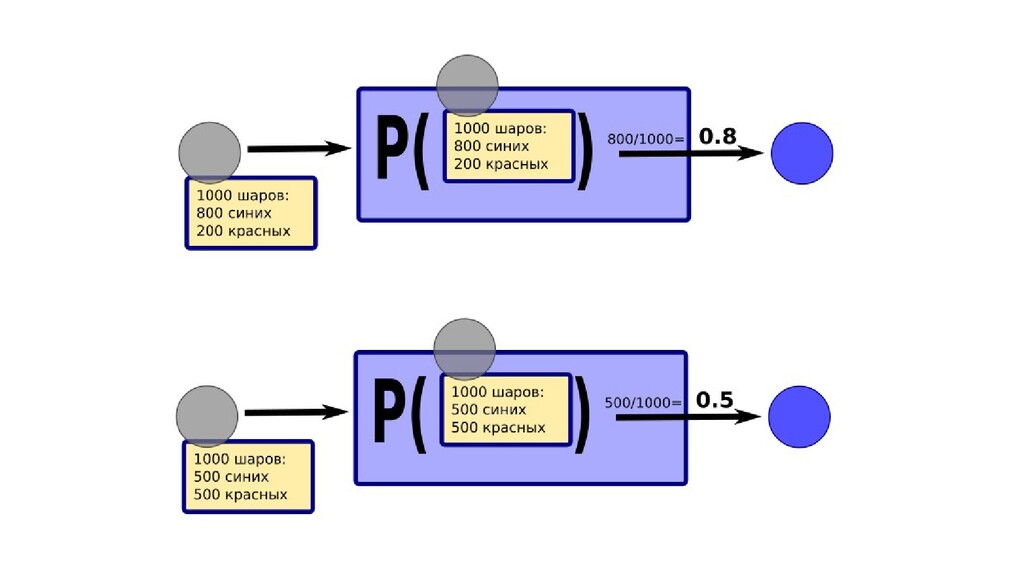
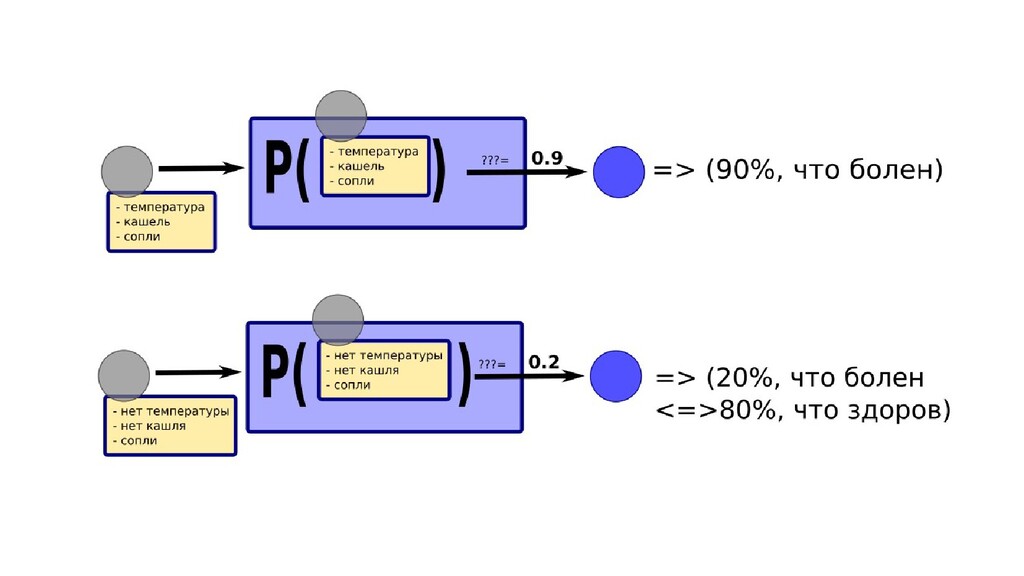
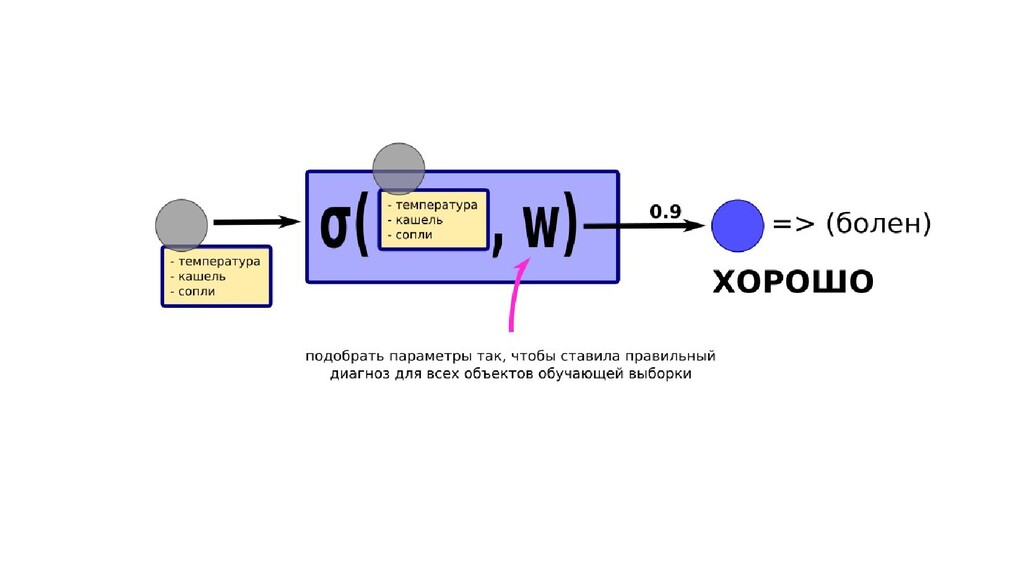
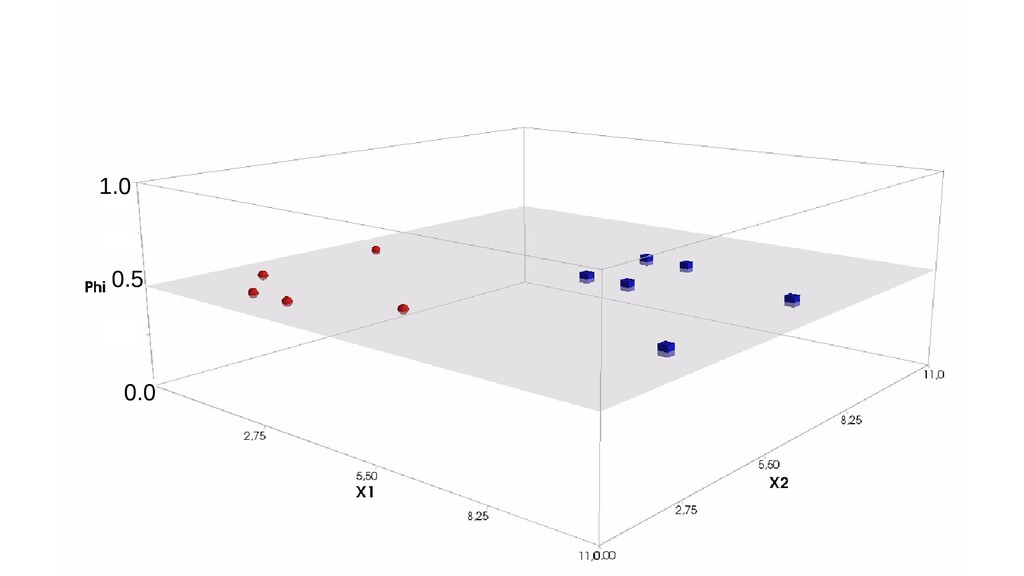
- Интерпретация задачи назначения класса объекту по признакам в терминах теории вероятностей: вероятность попадания объекта в класс как функция от признаков объекта
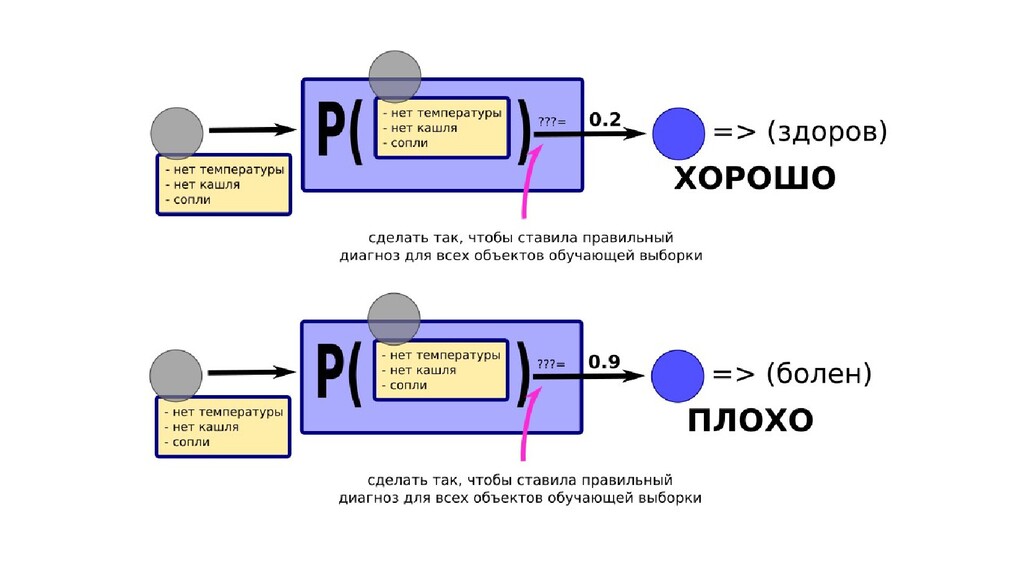
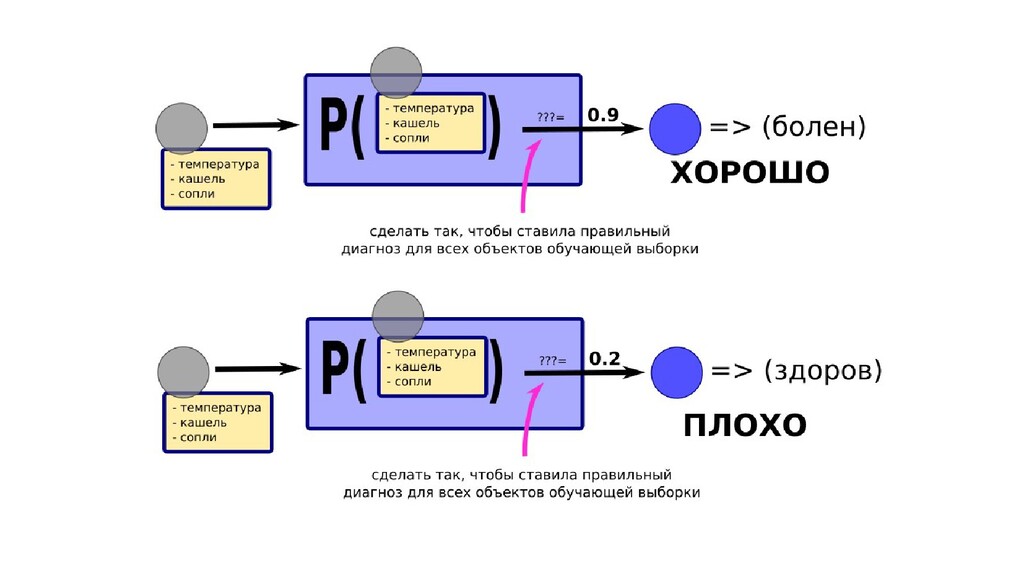
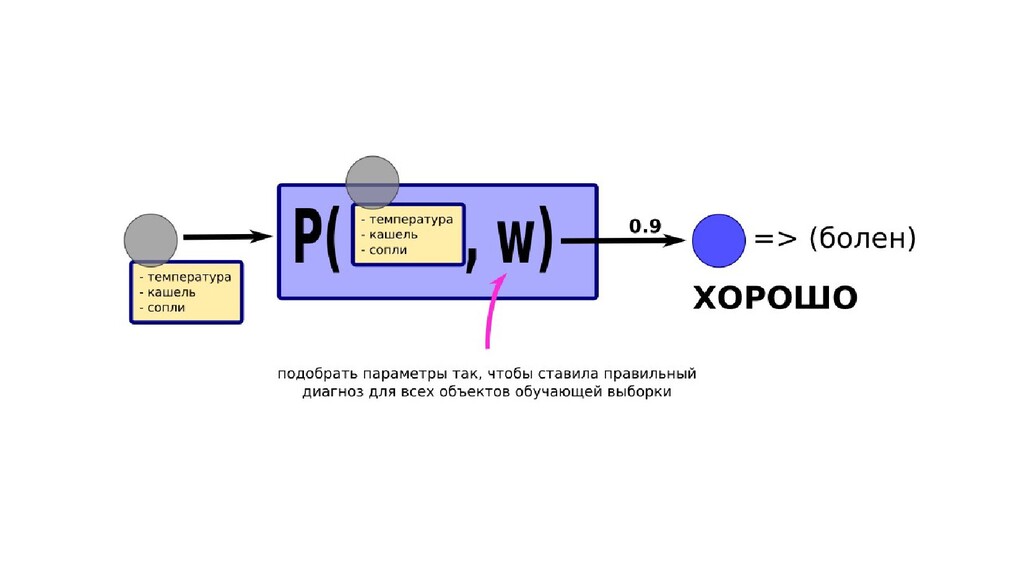
- Задача построения функции вероятности попадания объекта в класс как параметрической функции
- Общее (сильное) предположение о том, что класс объекта определяется известными параметрами
- Частное предположение-1 о форме неизвестного закона
- Частное предположение-2 об оптимальности выбранных параметров
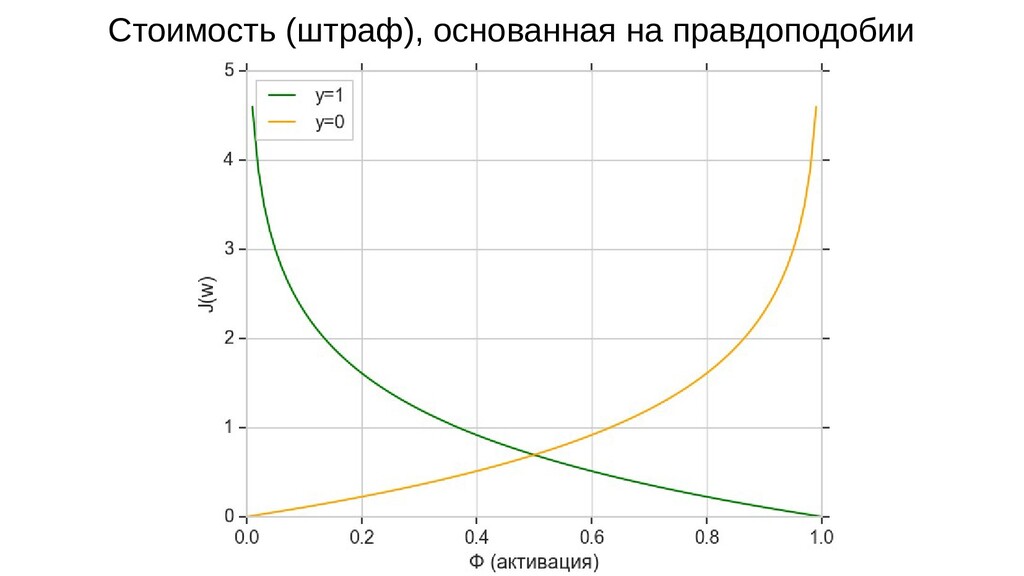
- Функция правдоподобия
- Функция стоимости (потерь) на основе функции правдоподобия
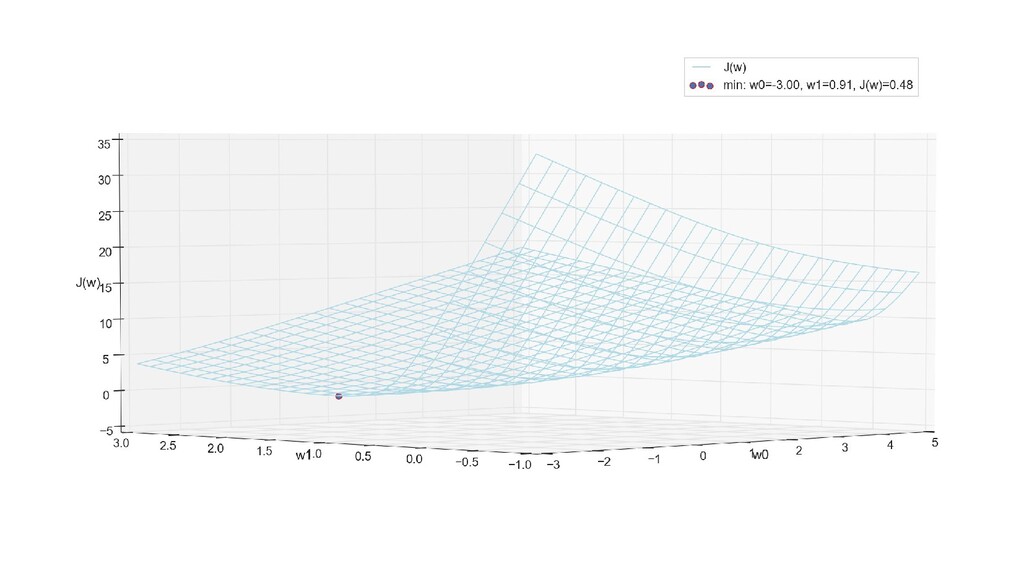
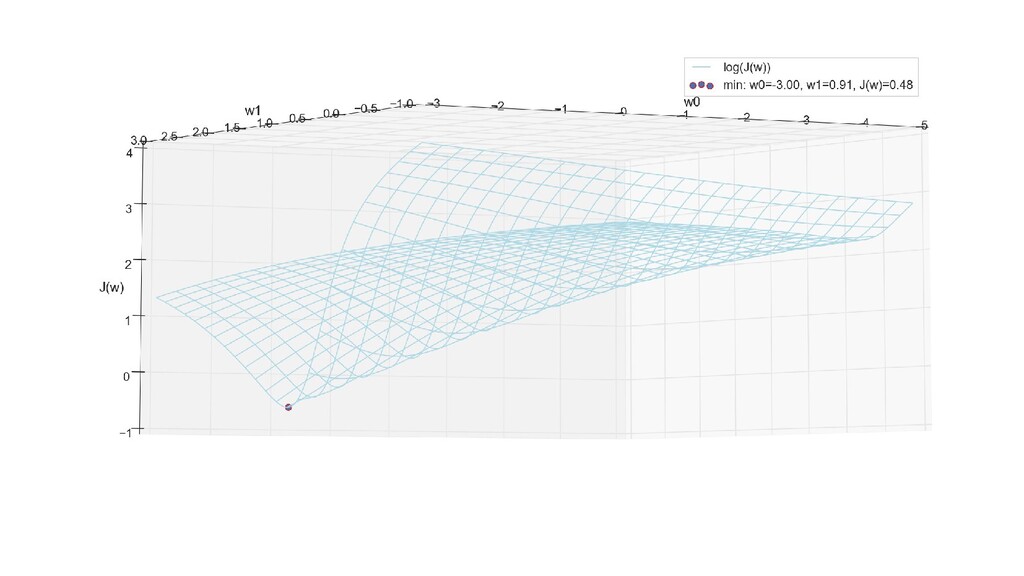
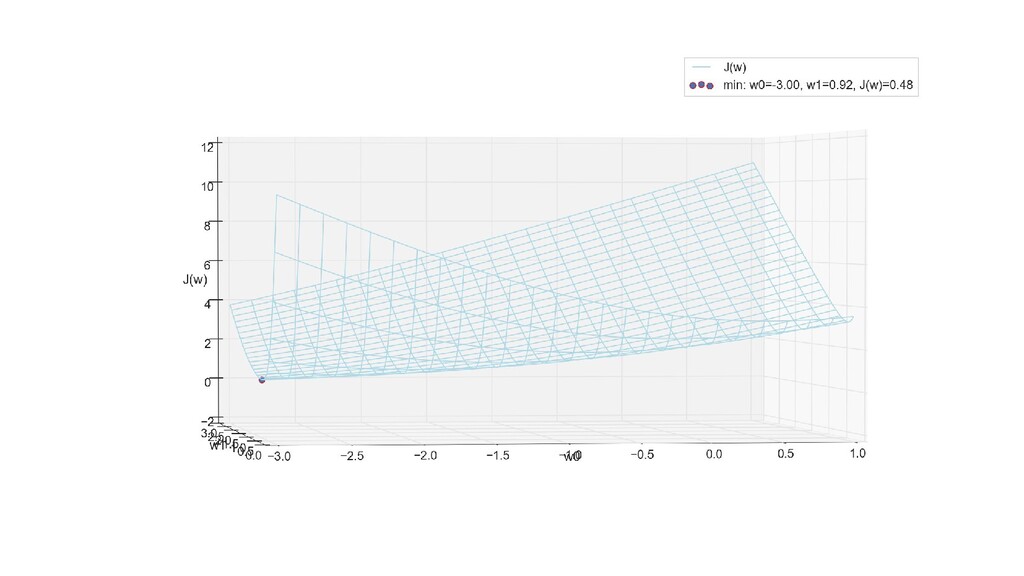
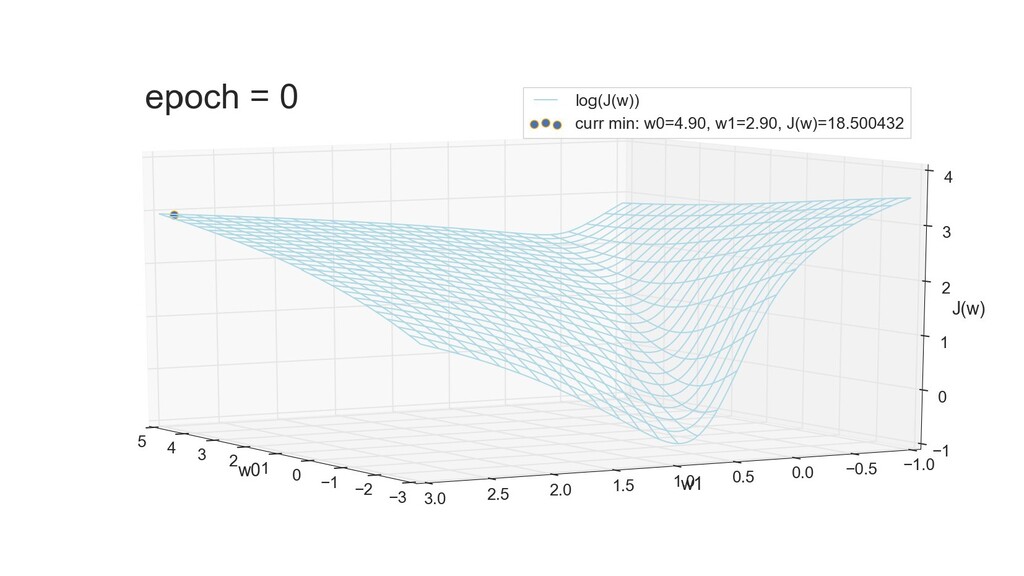
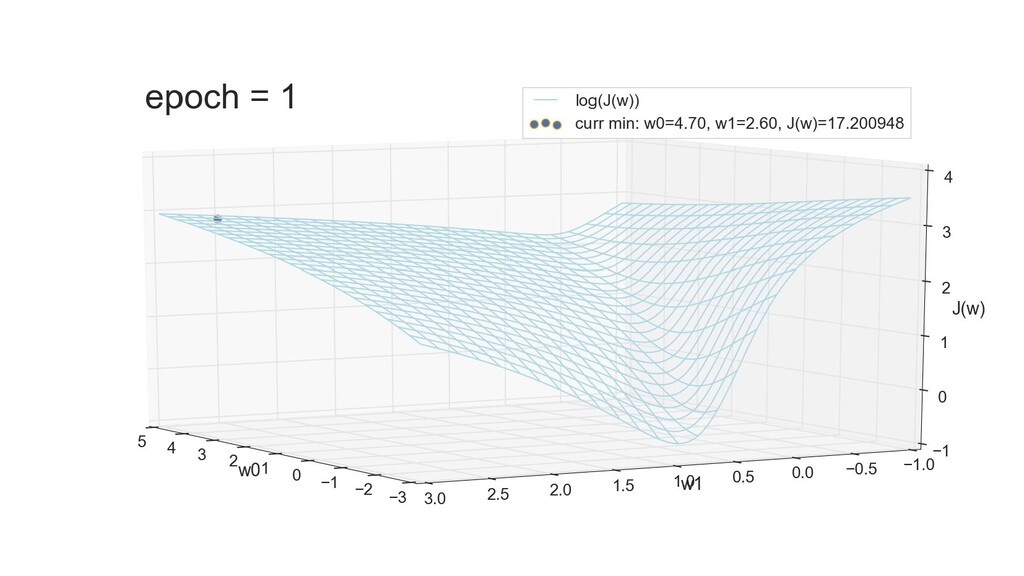
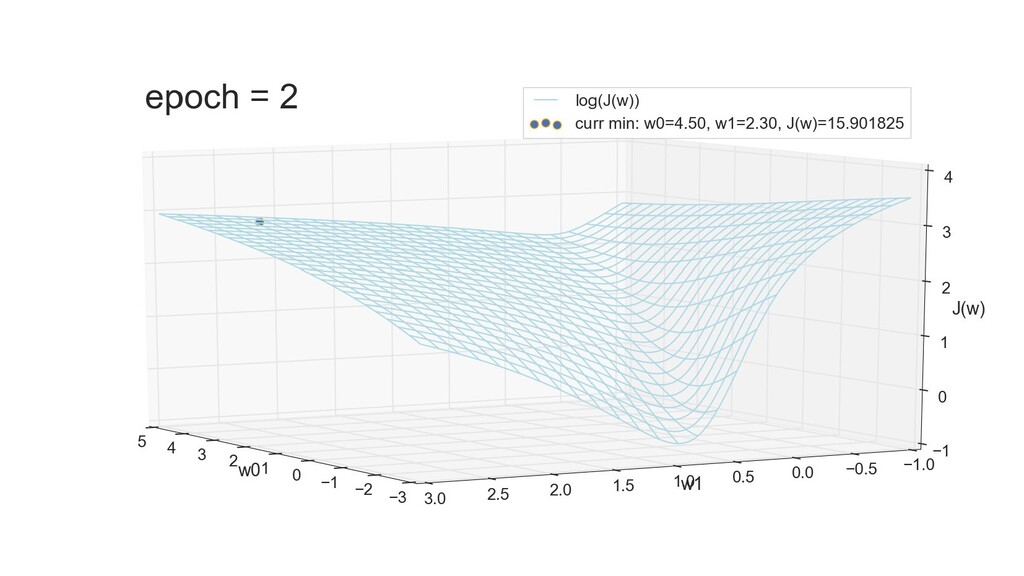
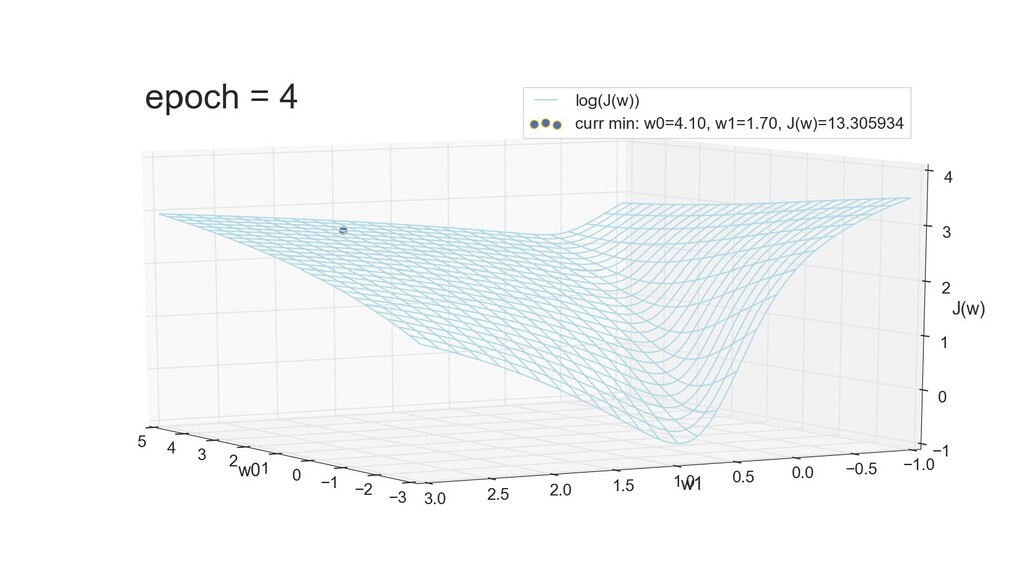
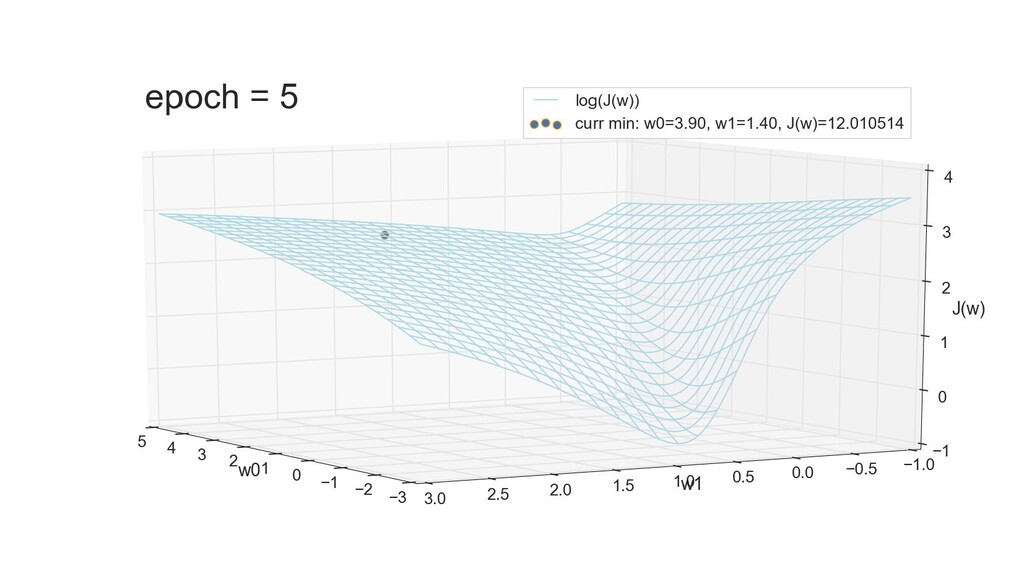
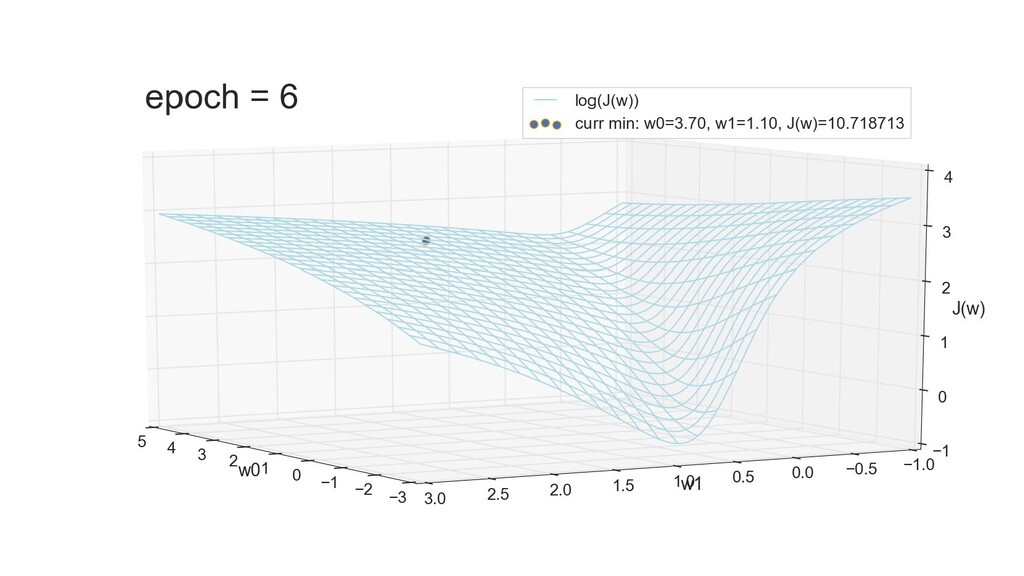
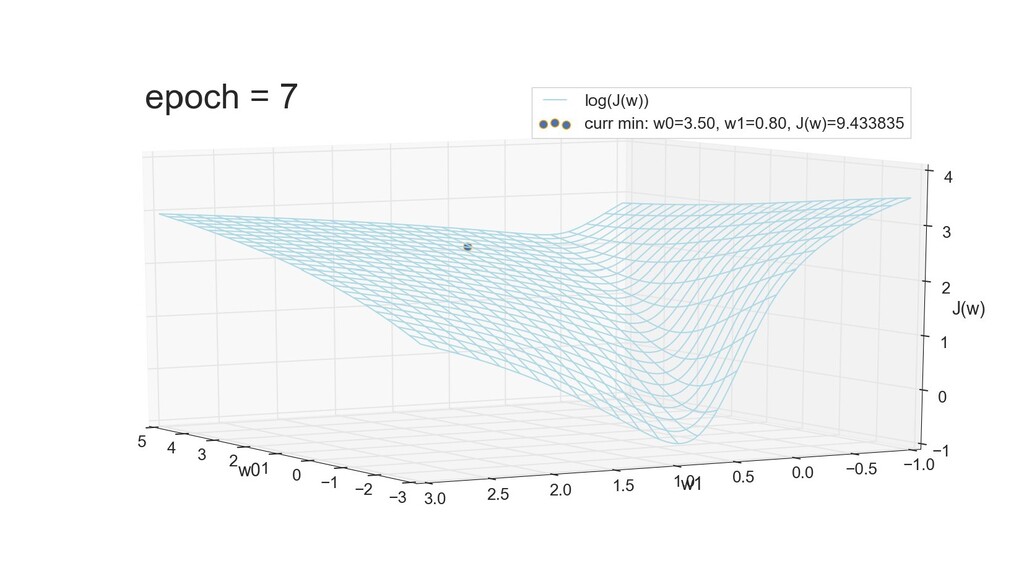
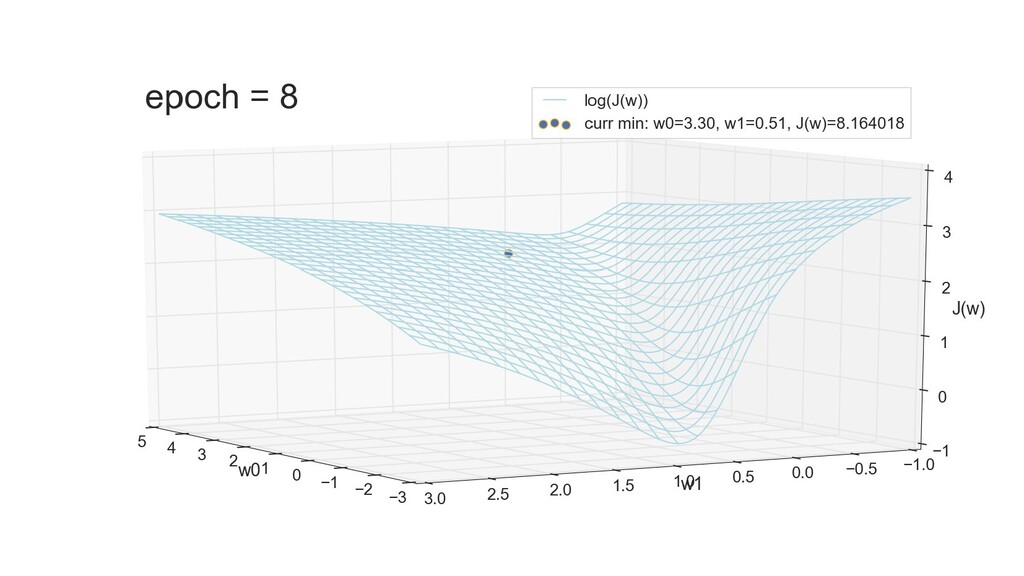
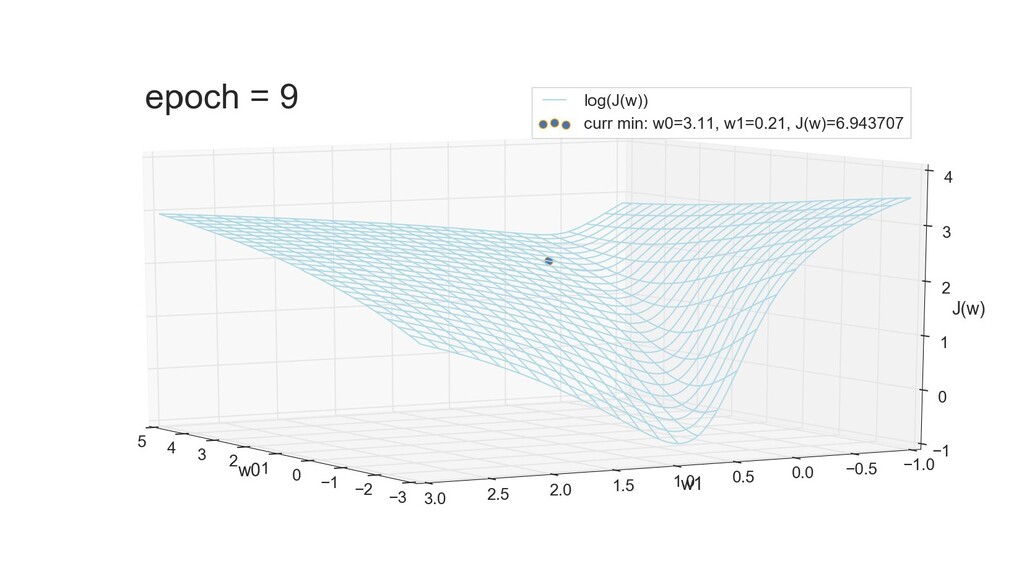
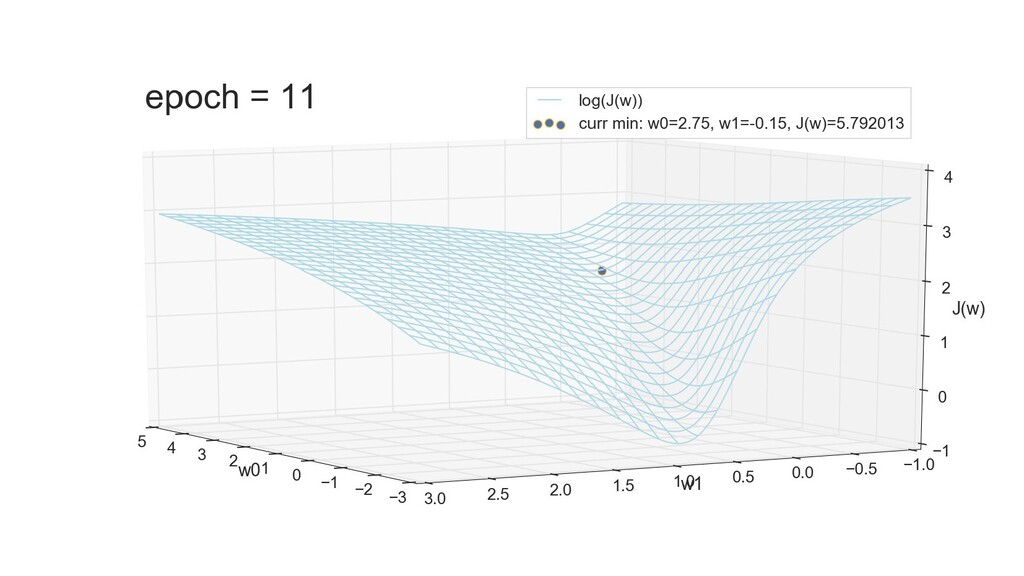
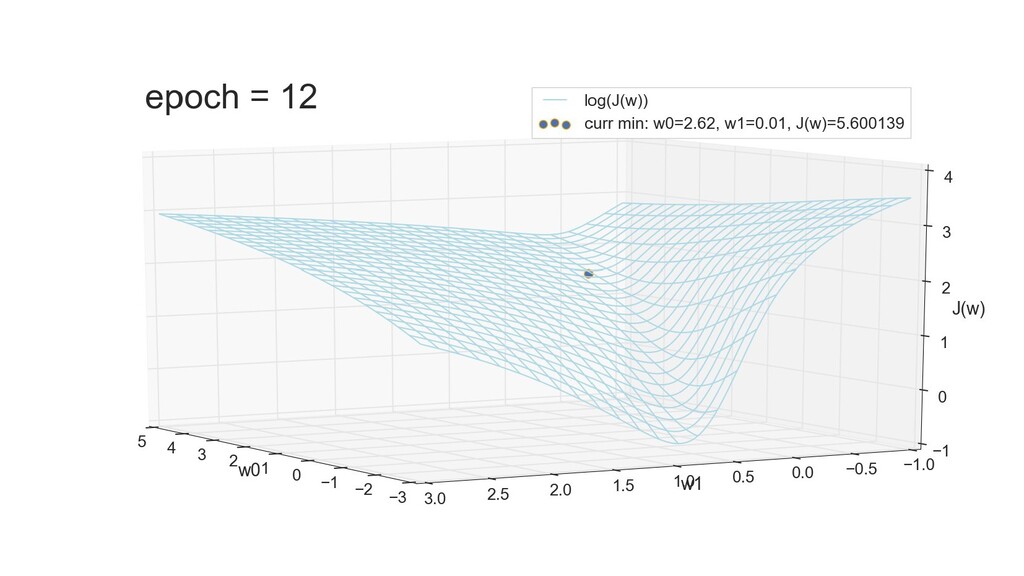
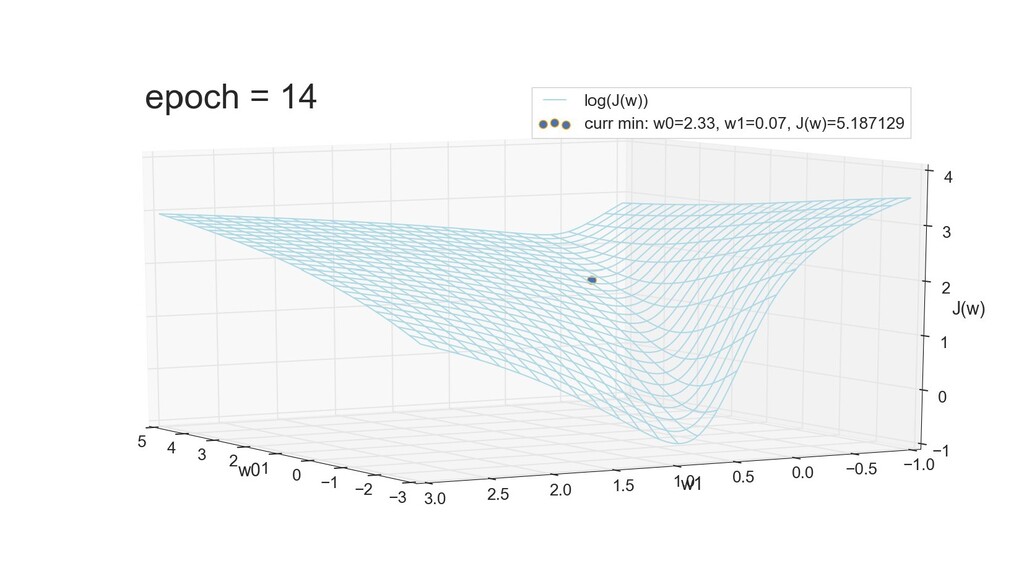
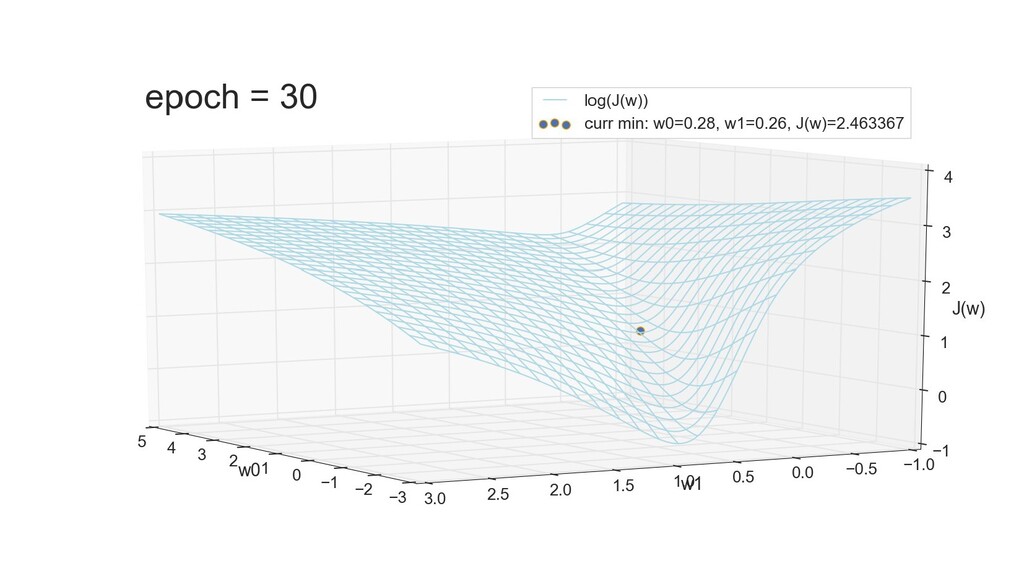
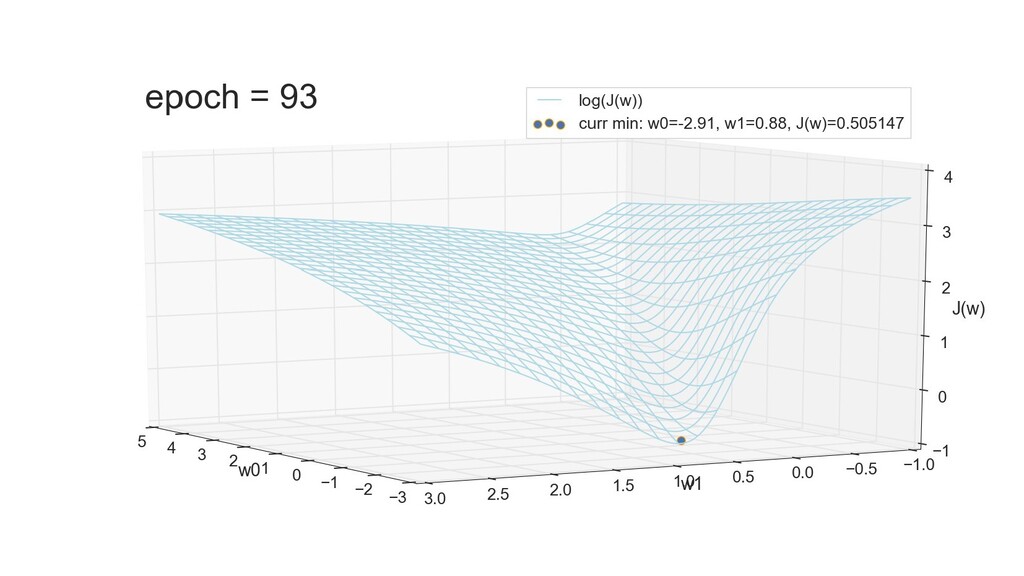
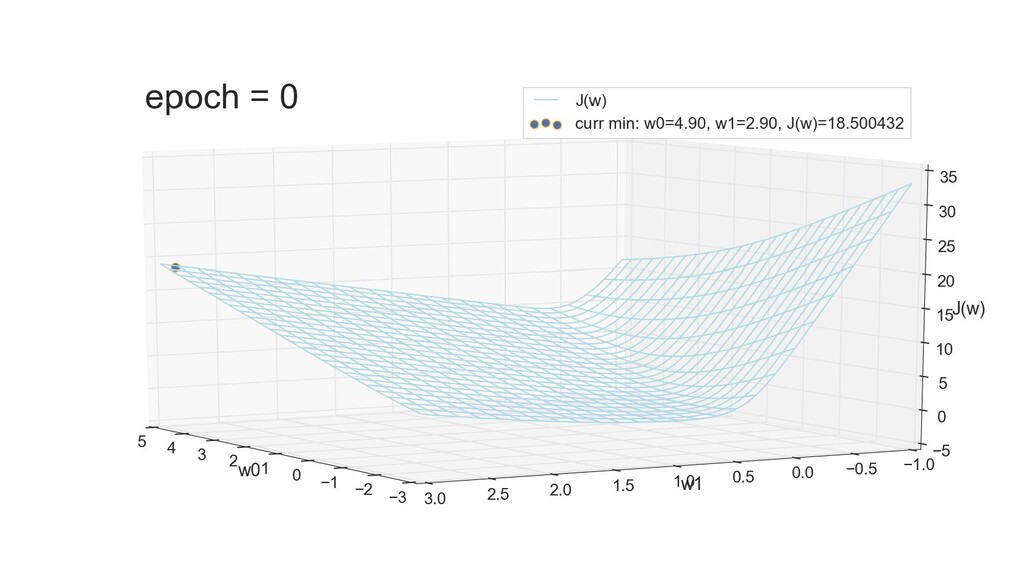
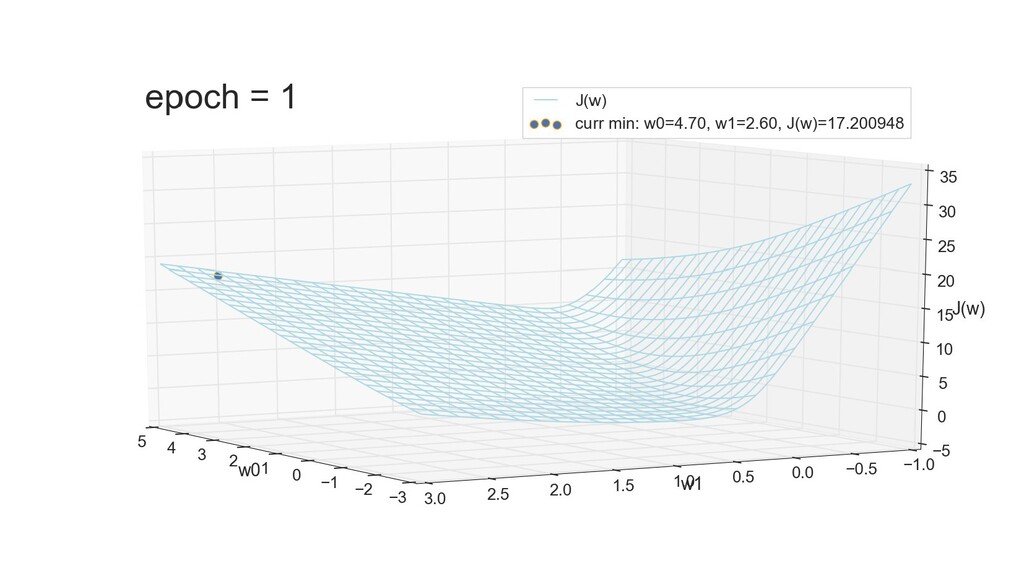
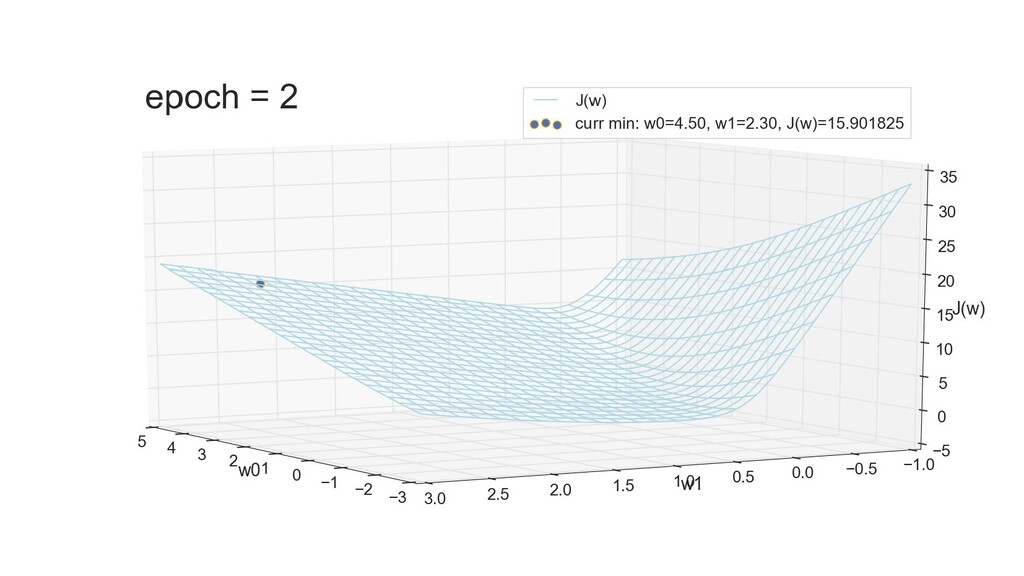
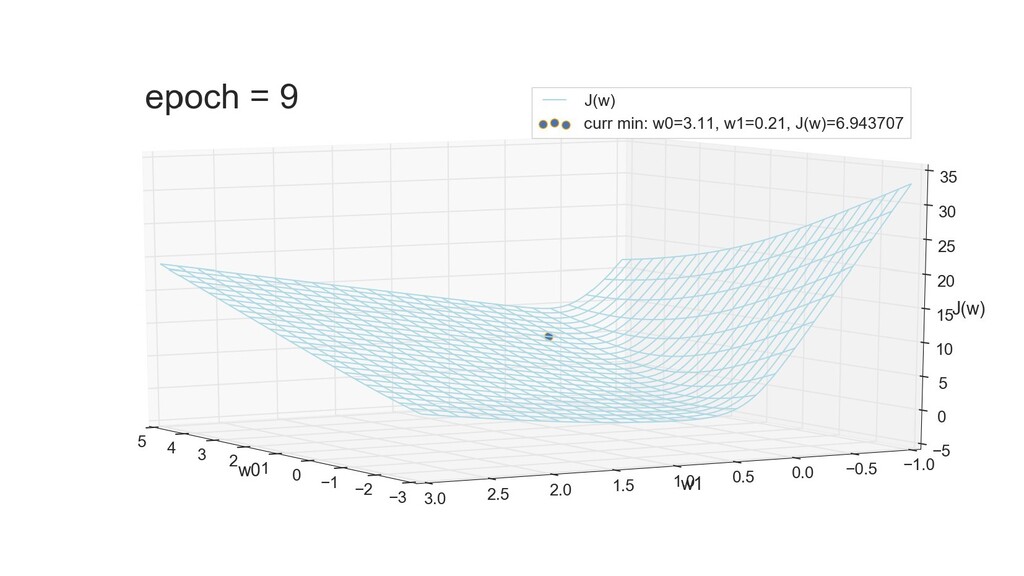
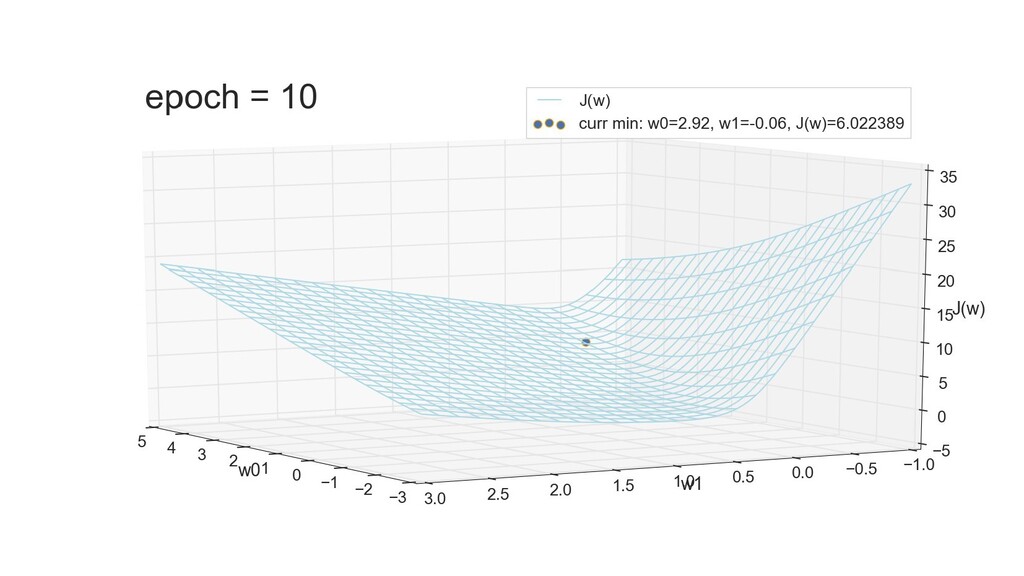
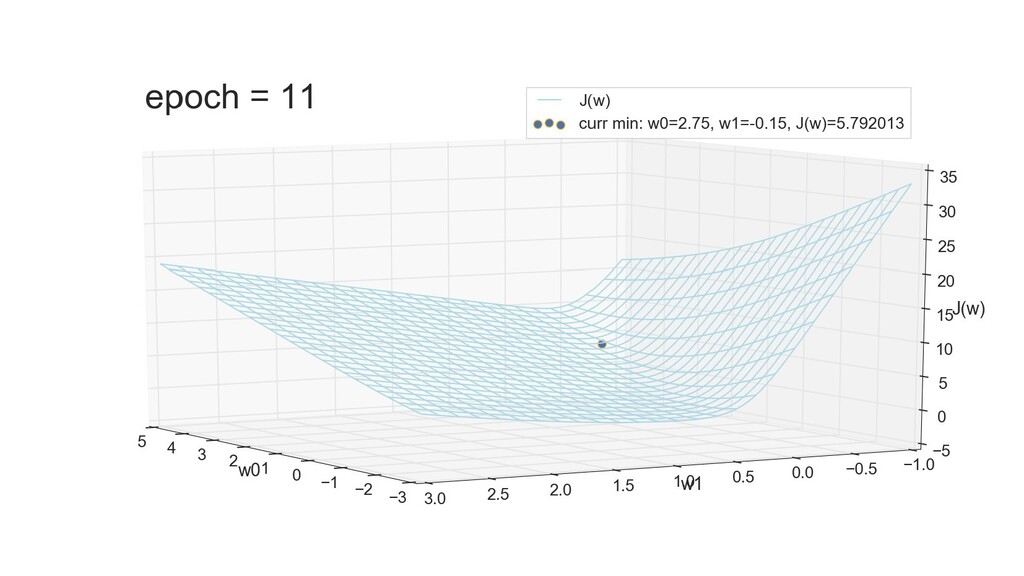
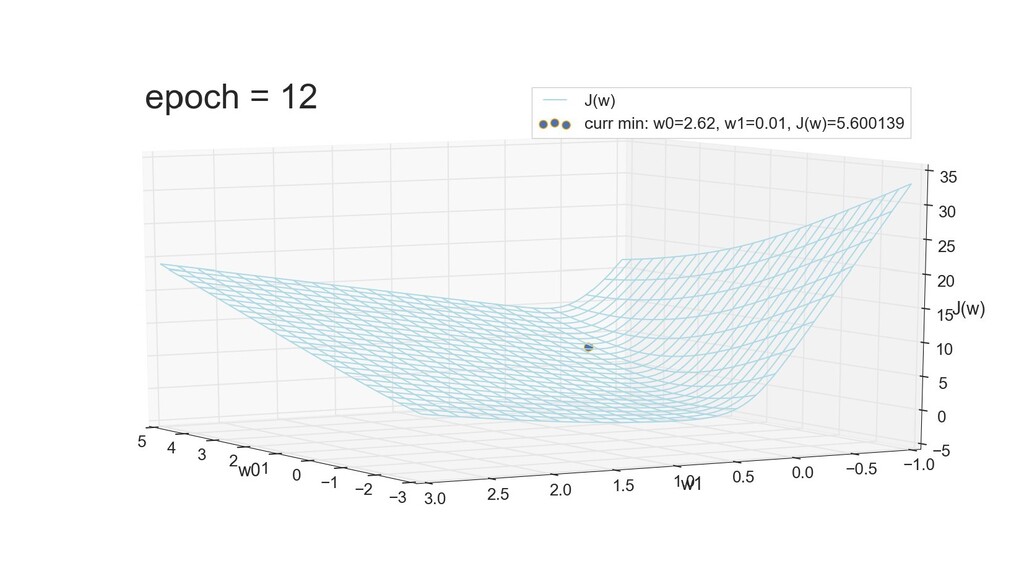
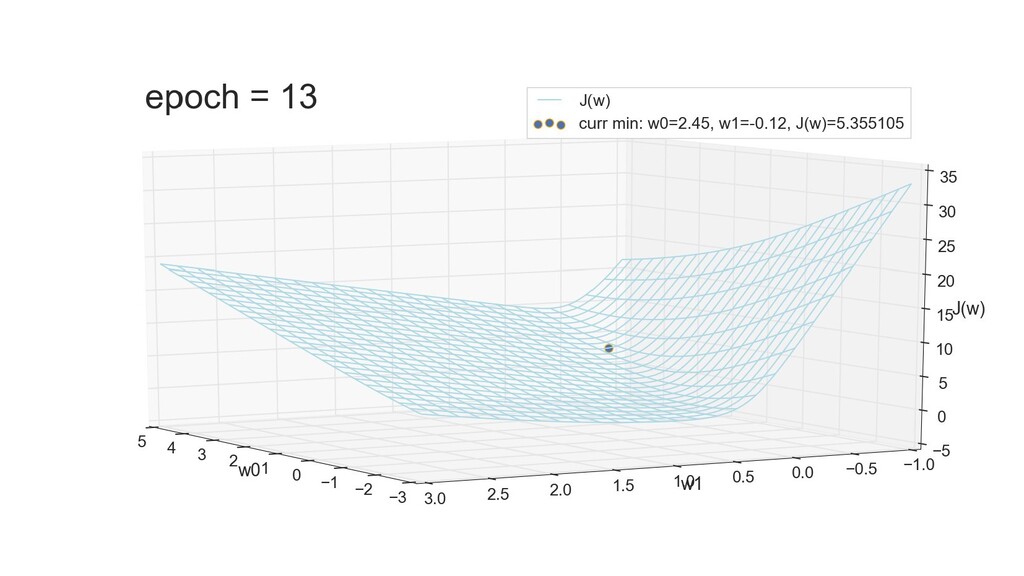
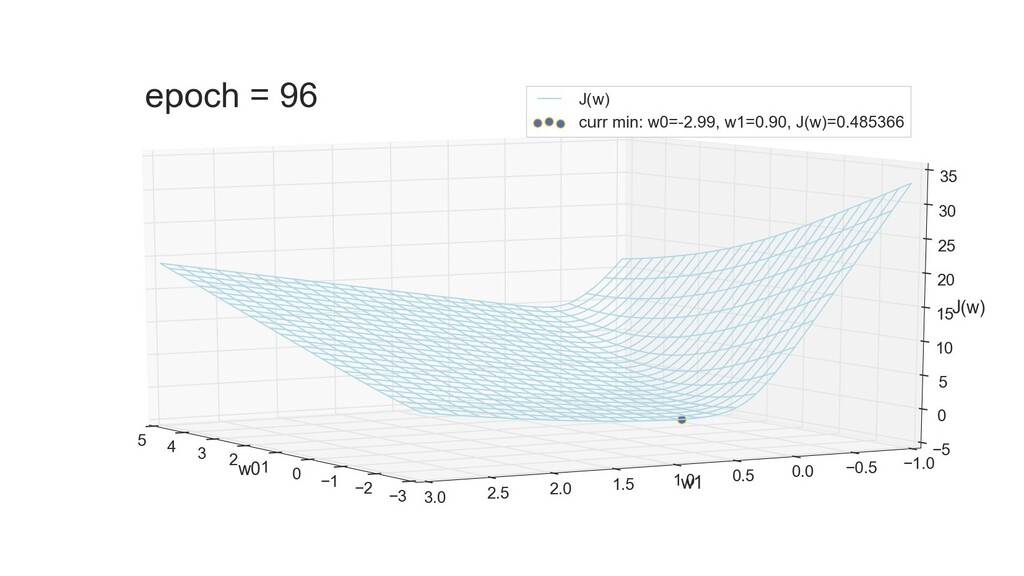
- 3д-график функции стоимости: шарик скатывается по желобу к краю одеяла
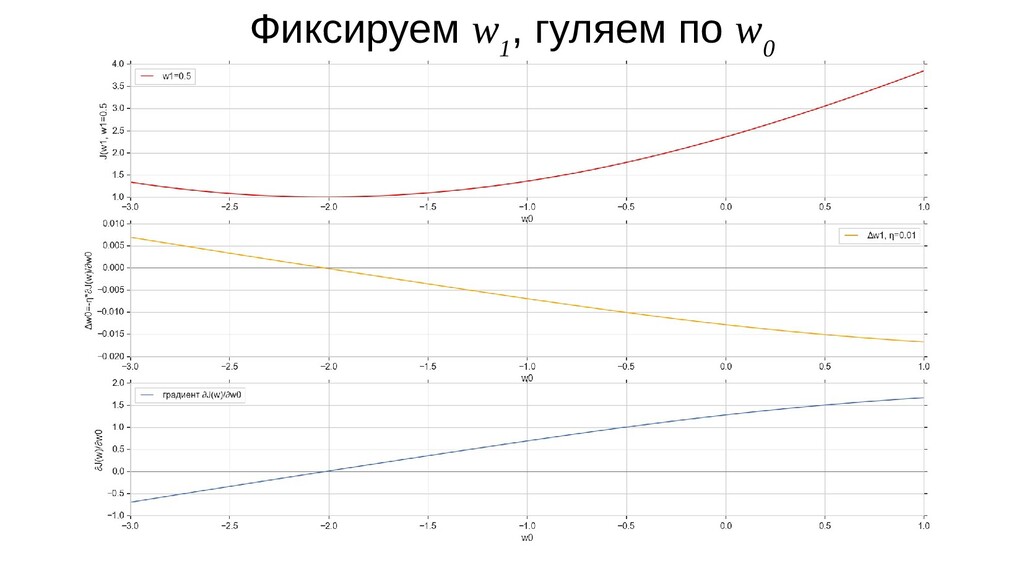
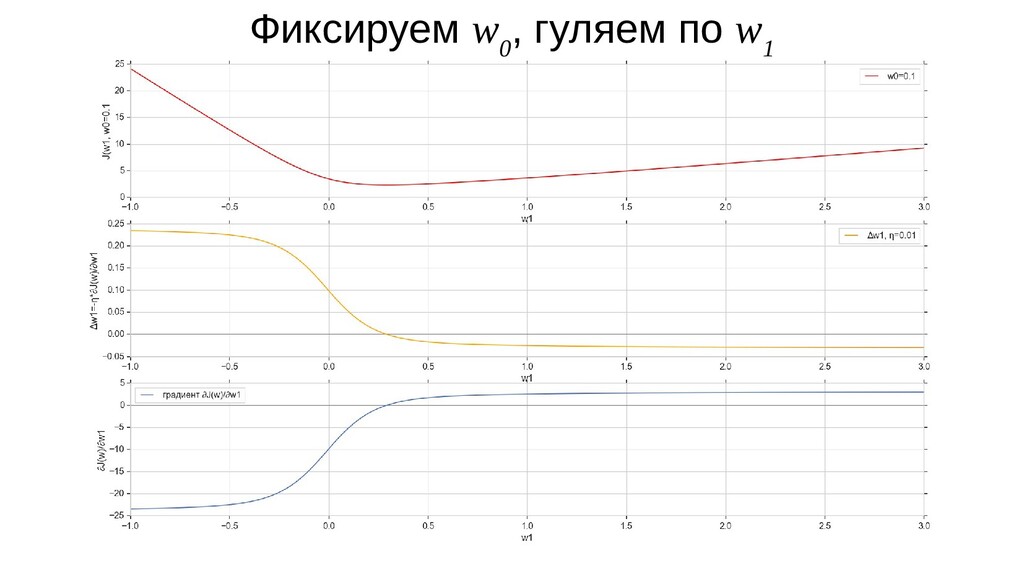
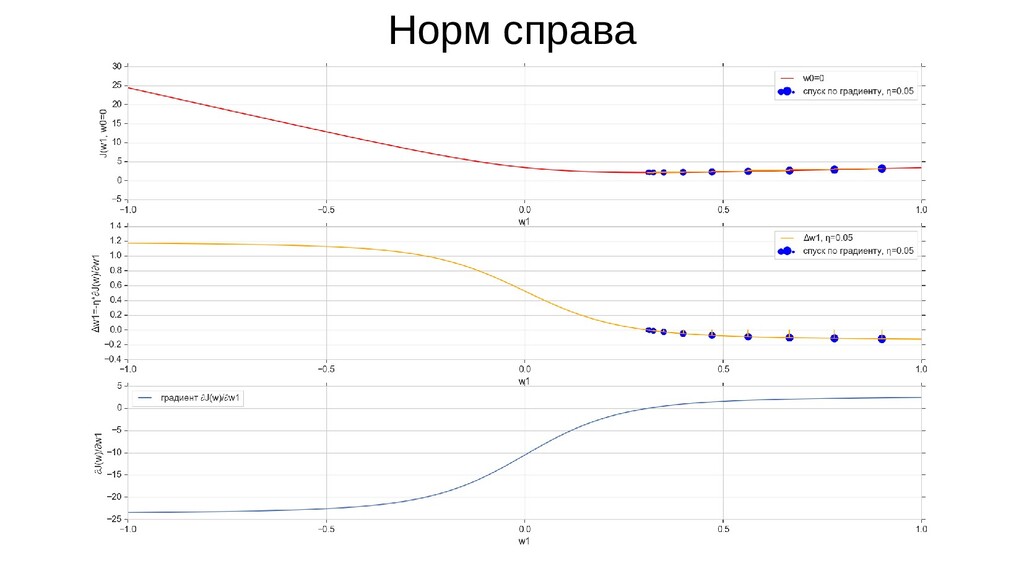
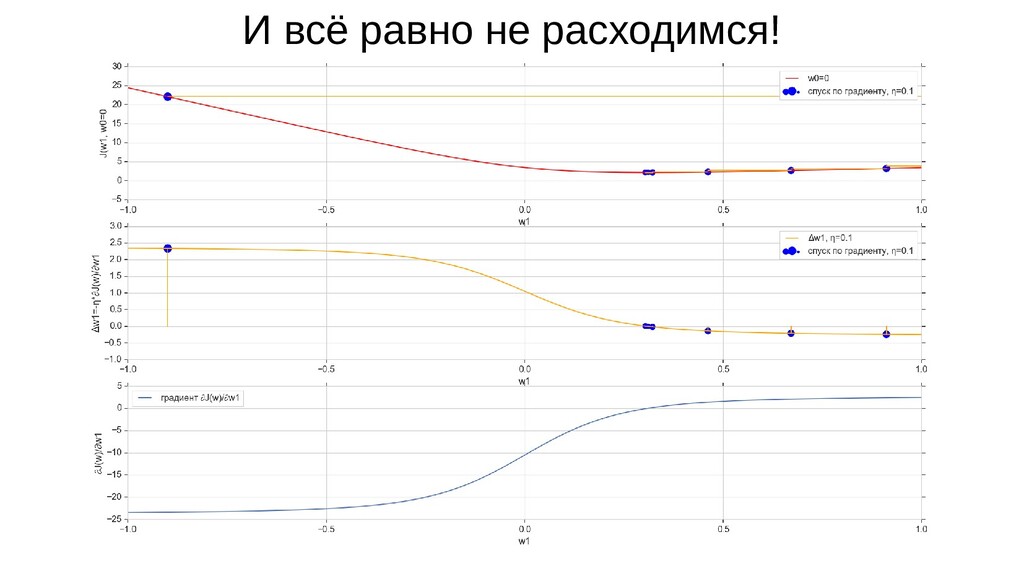
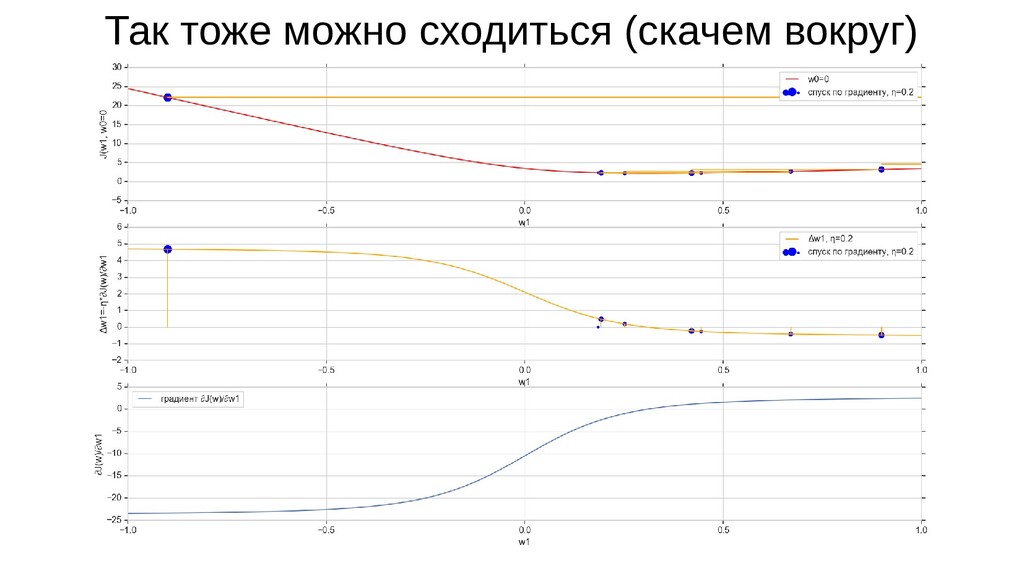
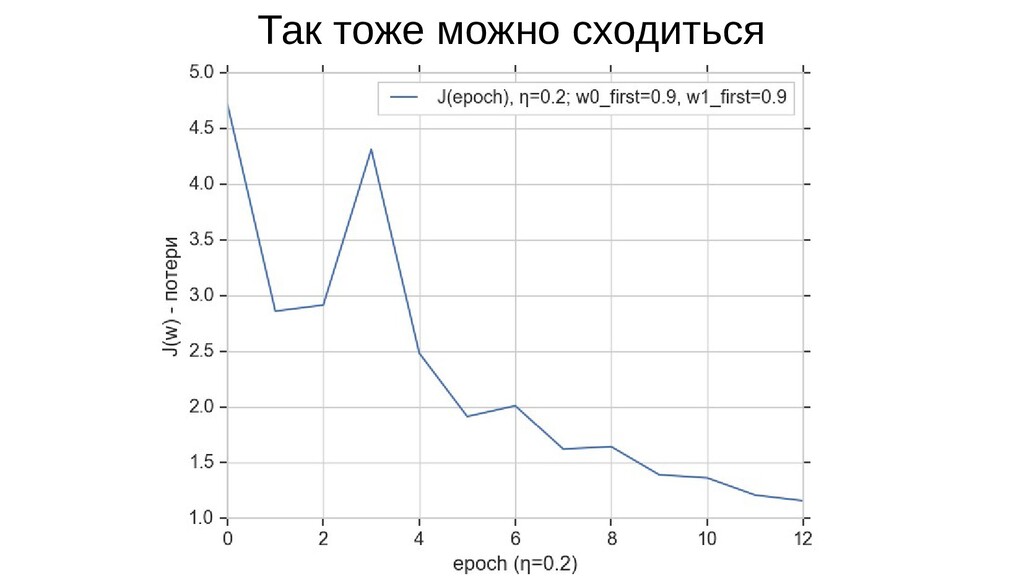
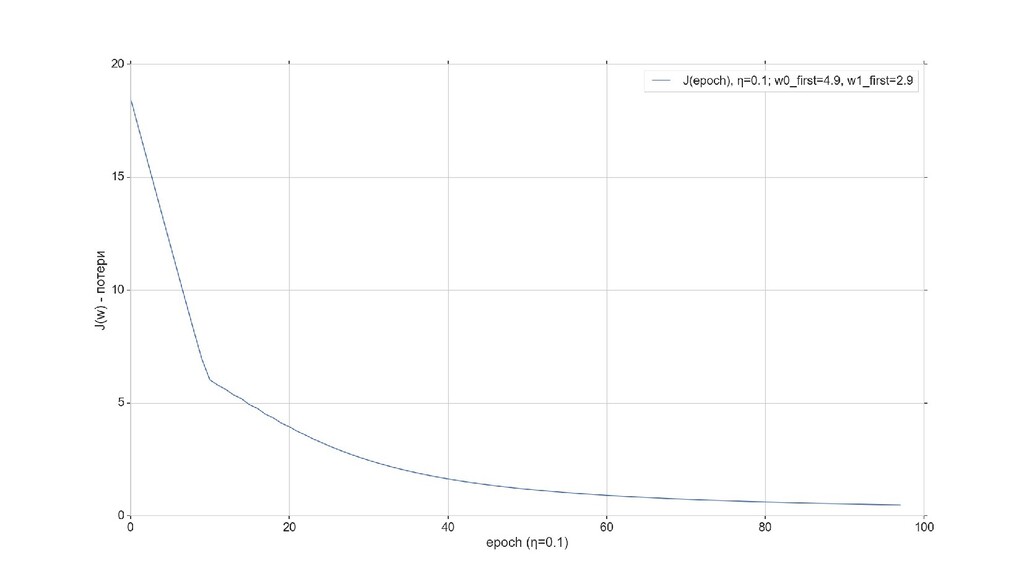
- Градиент функции стоимости, спуск по каждому из 2-х измерений
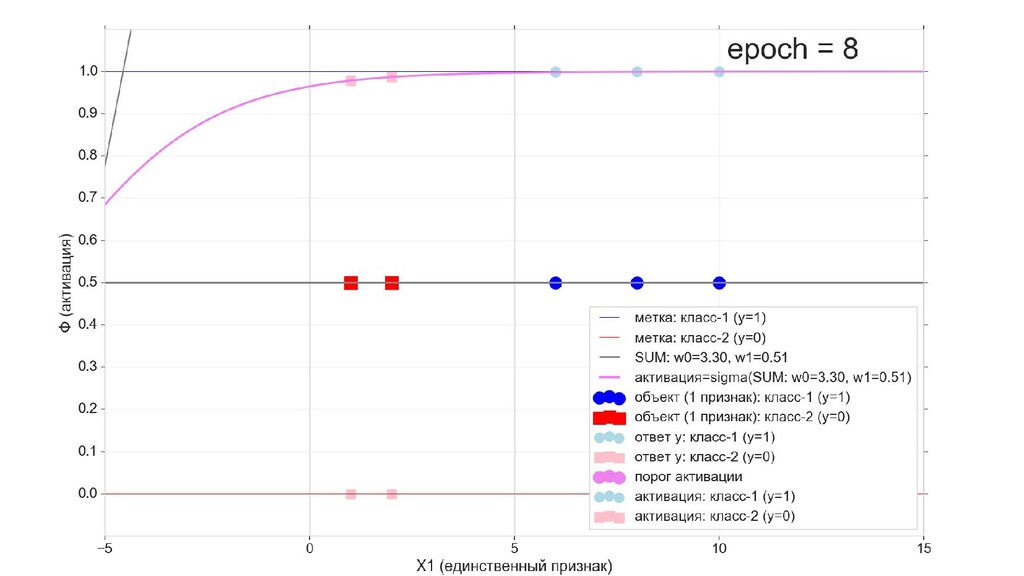
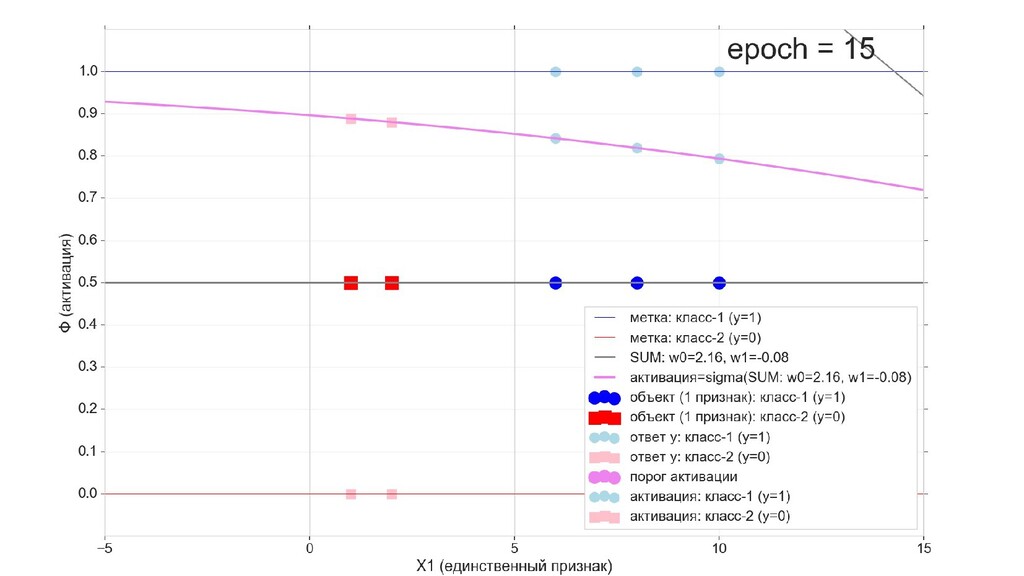
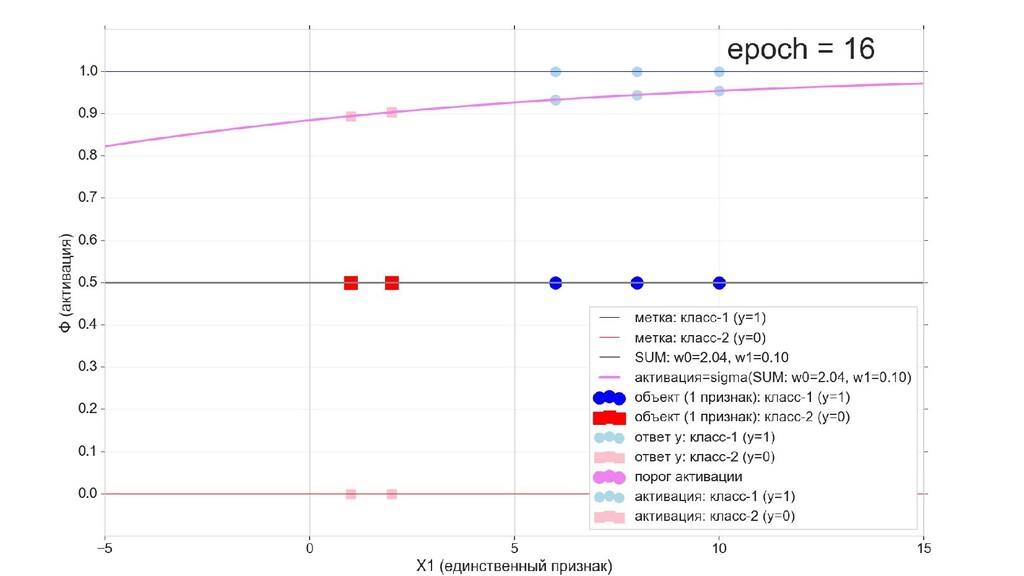
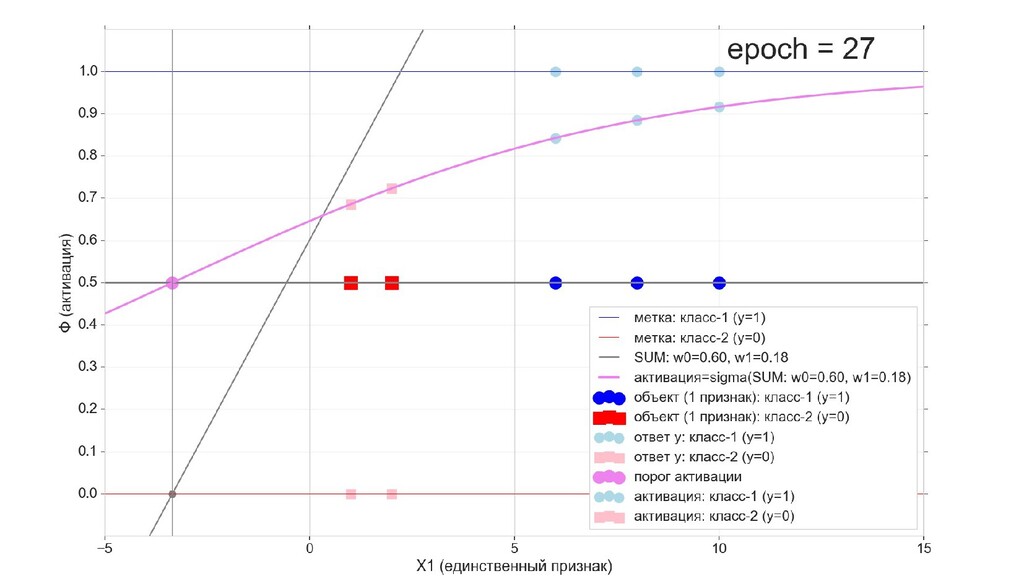
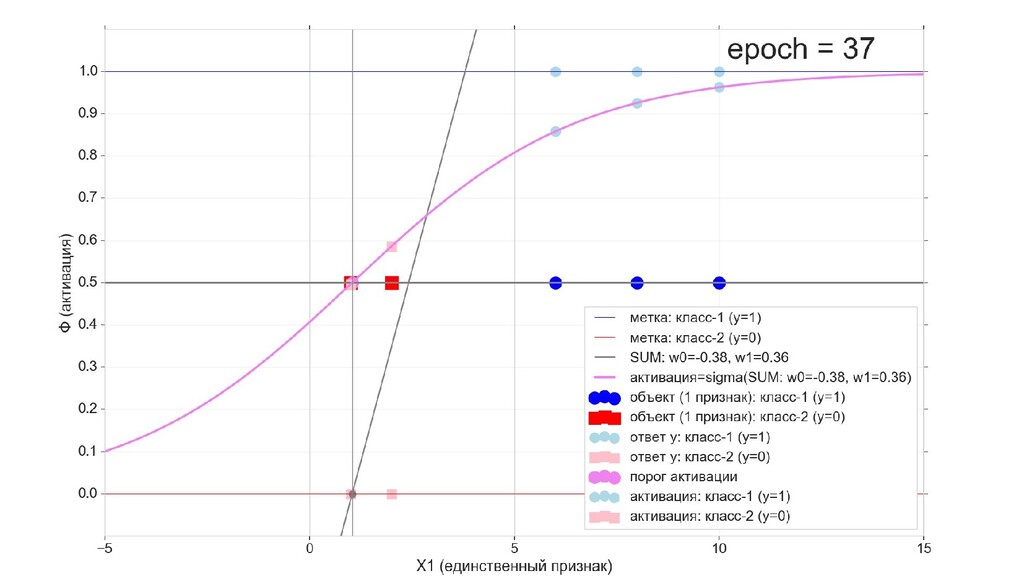
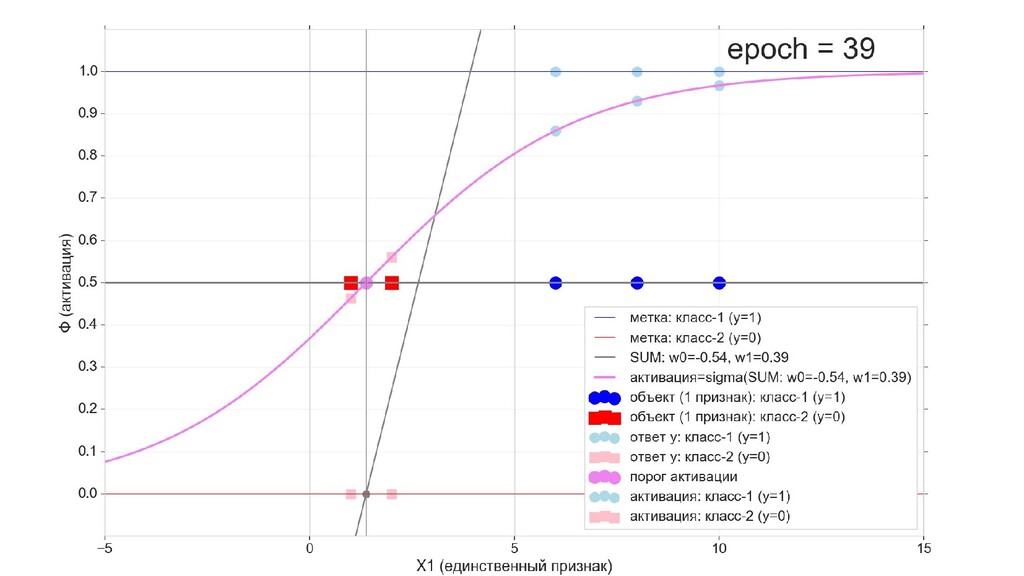
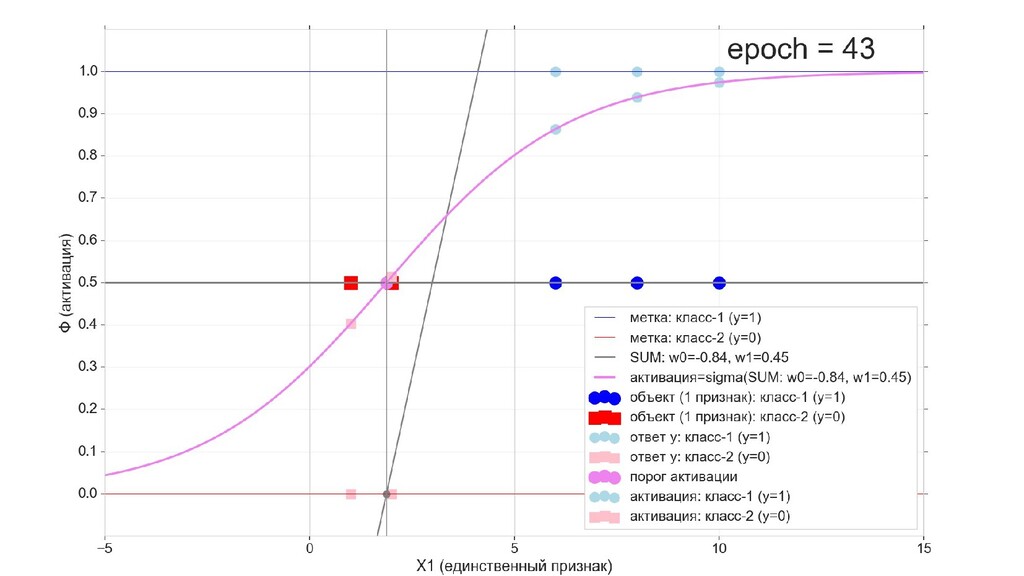
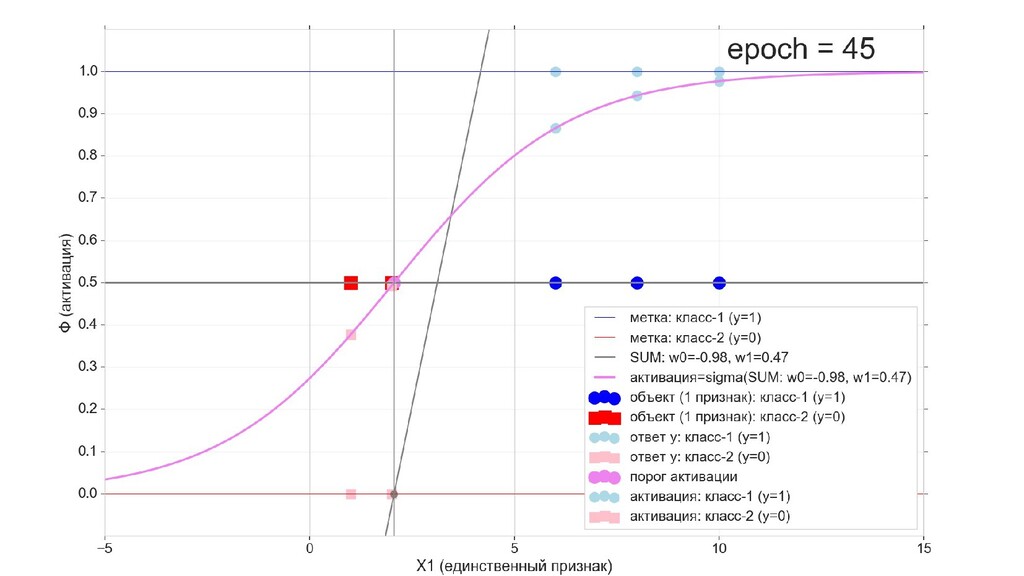
- Визуальное представление спуска: по 3д-графику функции стоимости
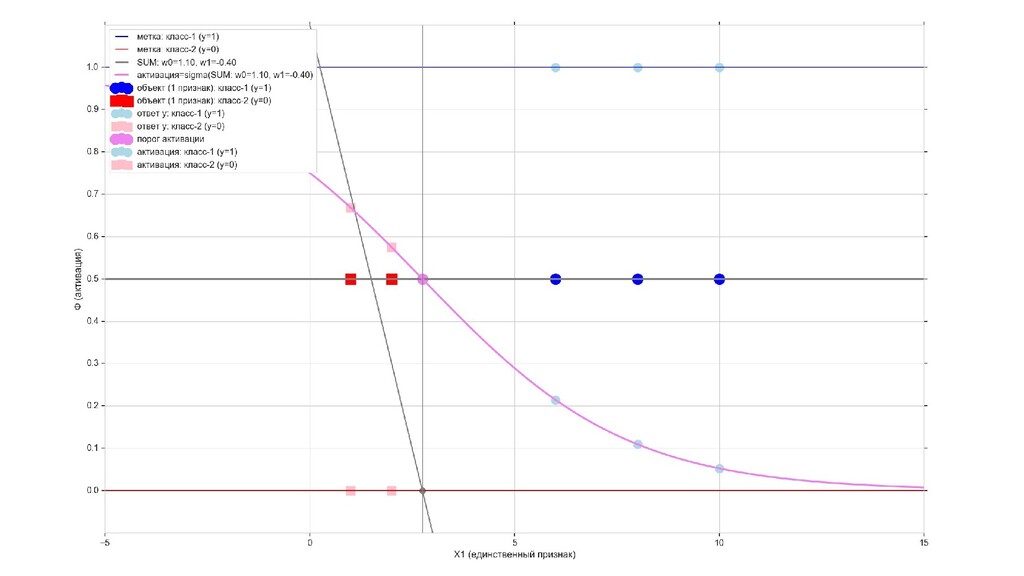
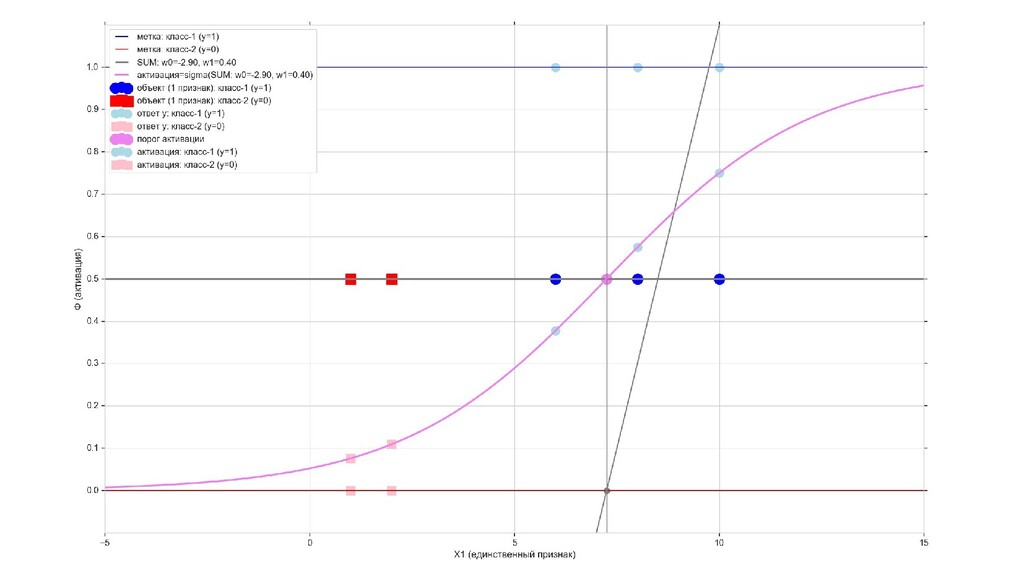
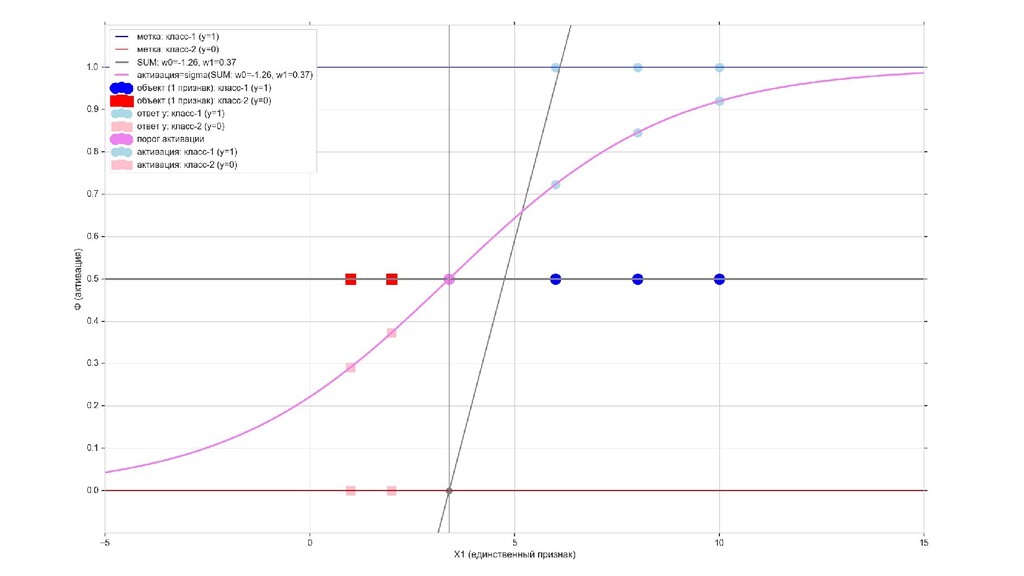
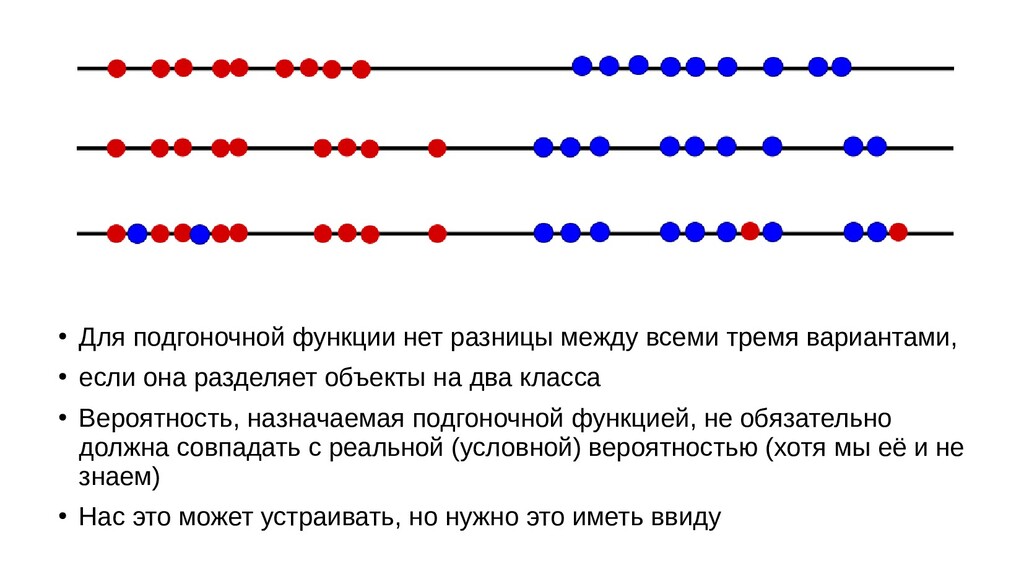
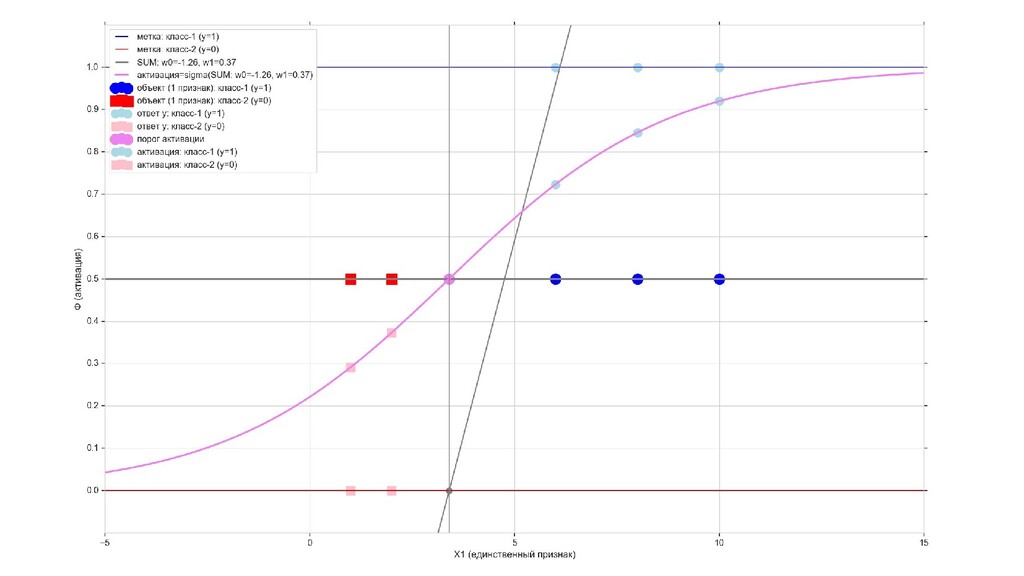
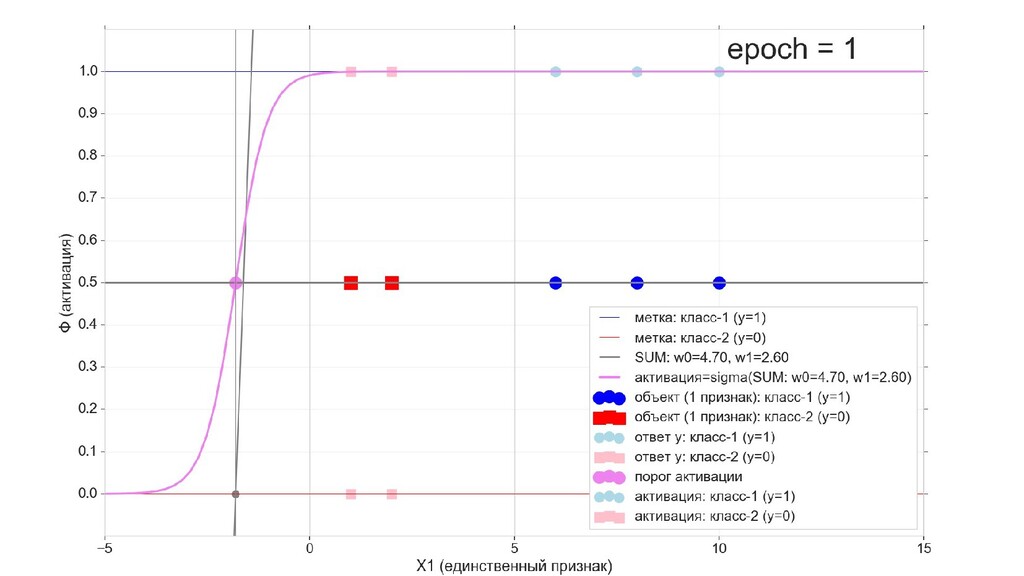
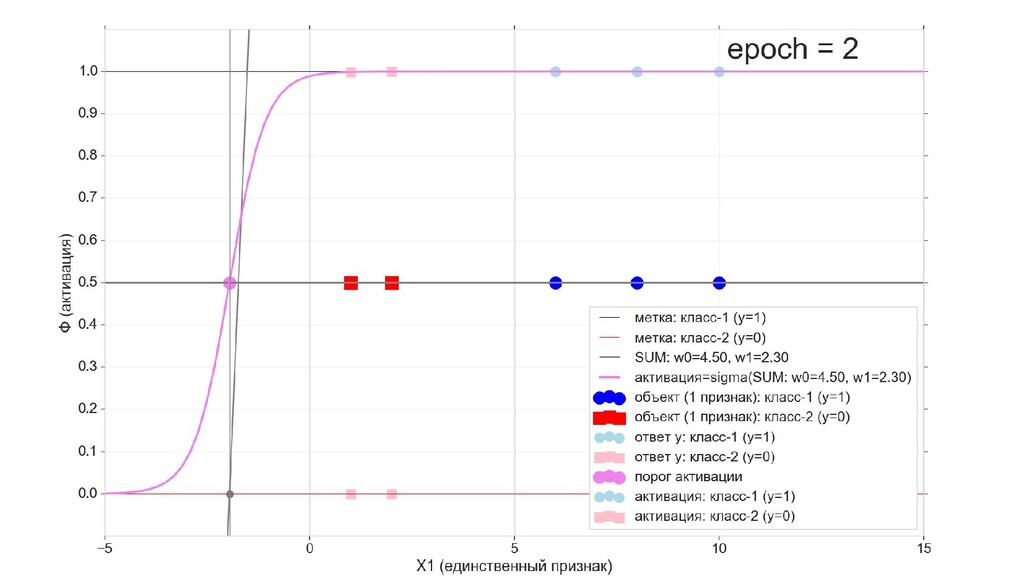
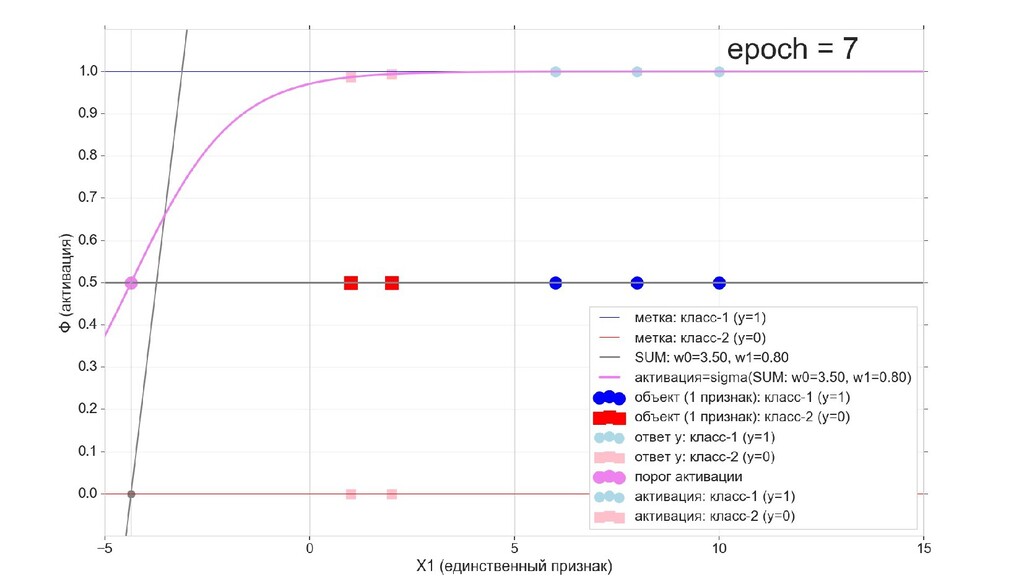
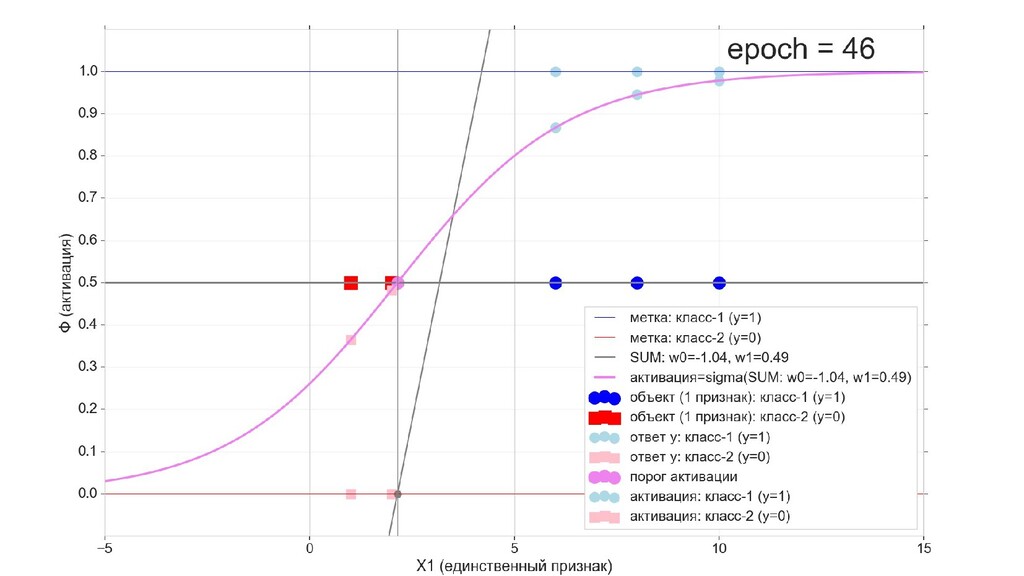
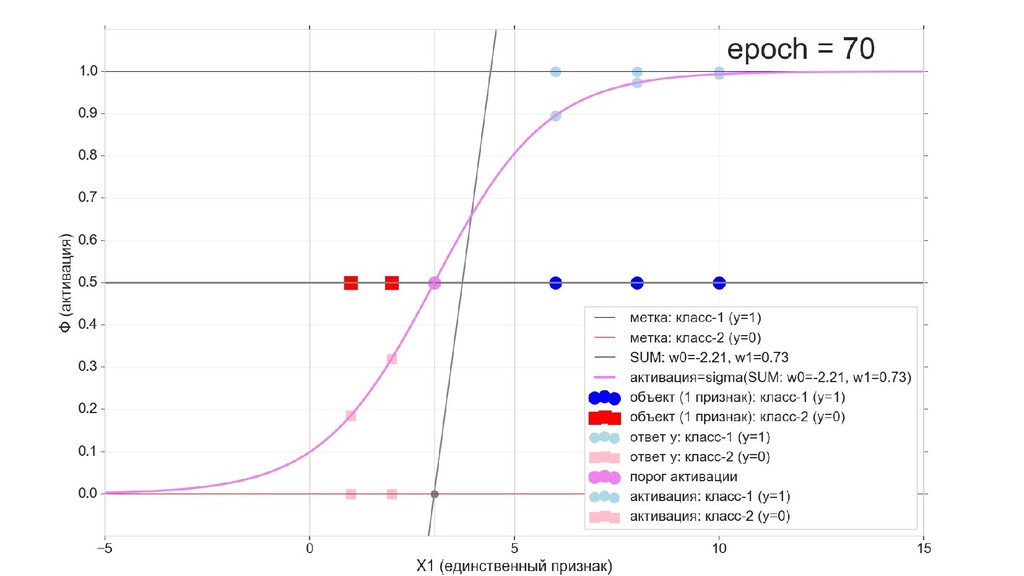
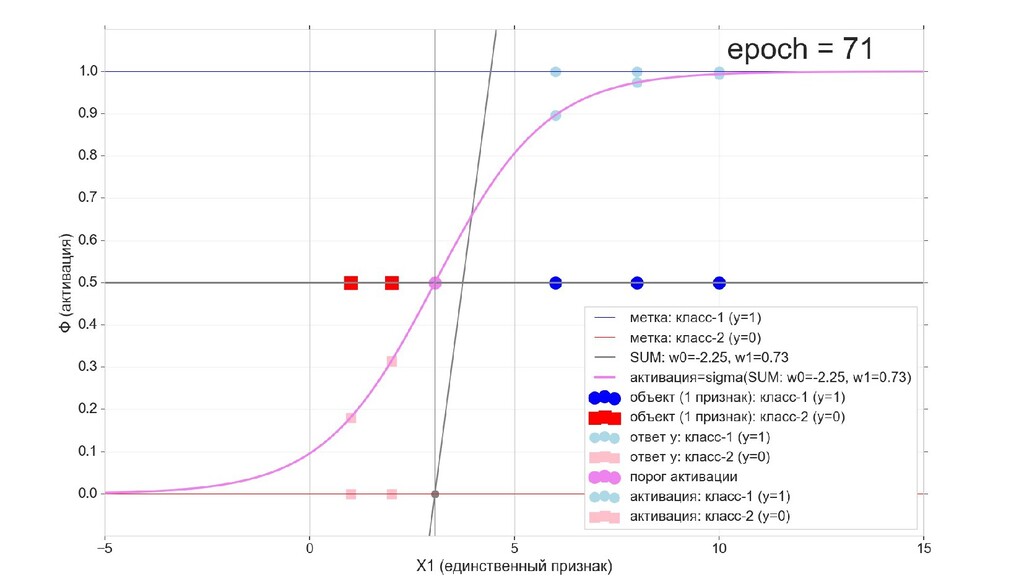
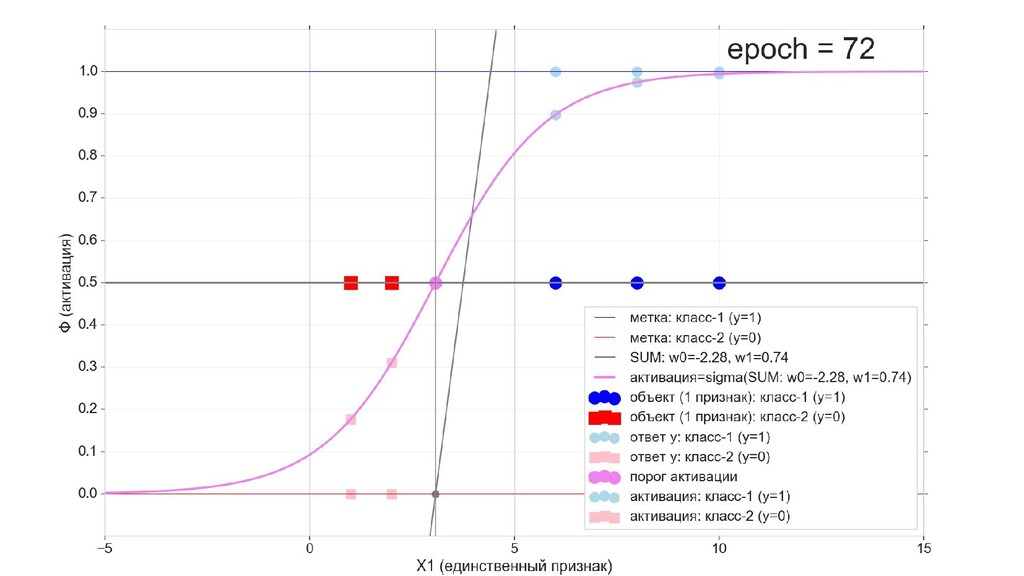
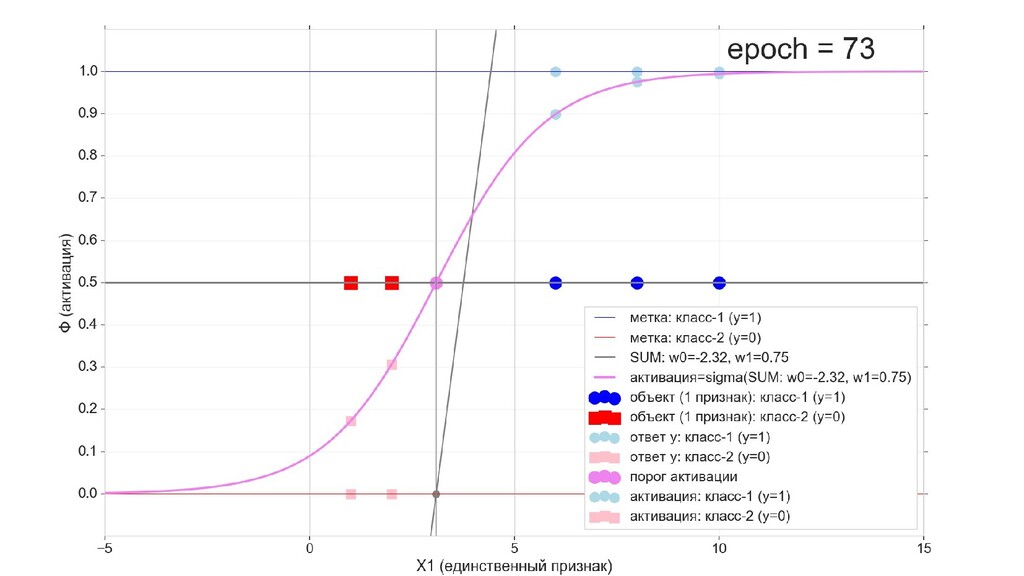
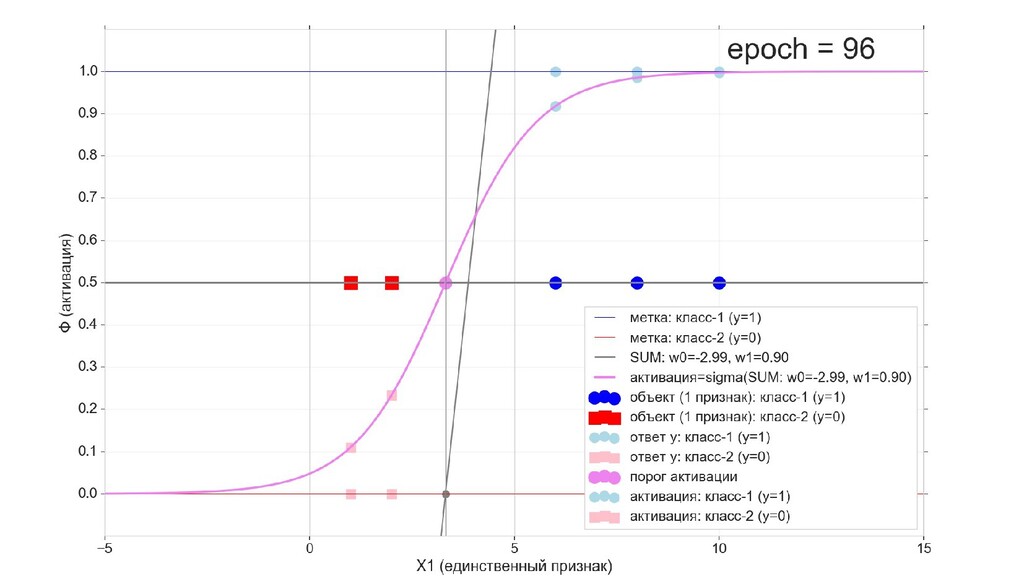
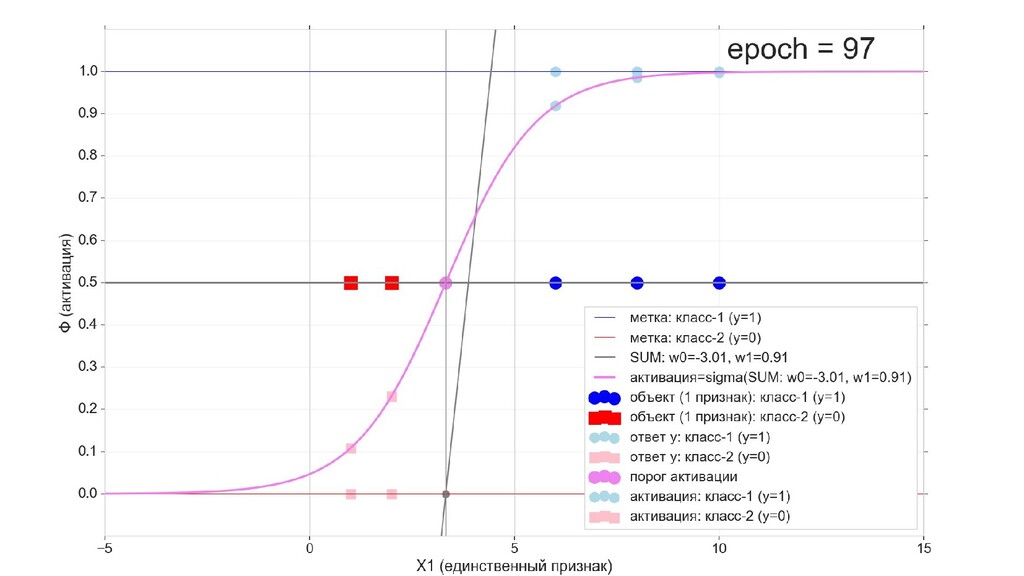
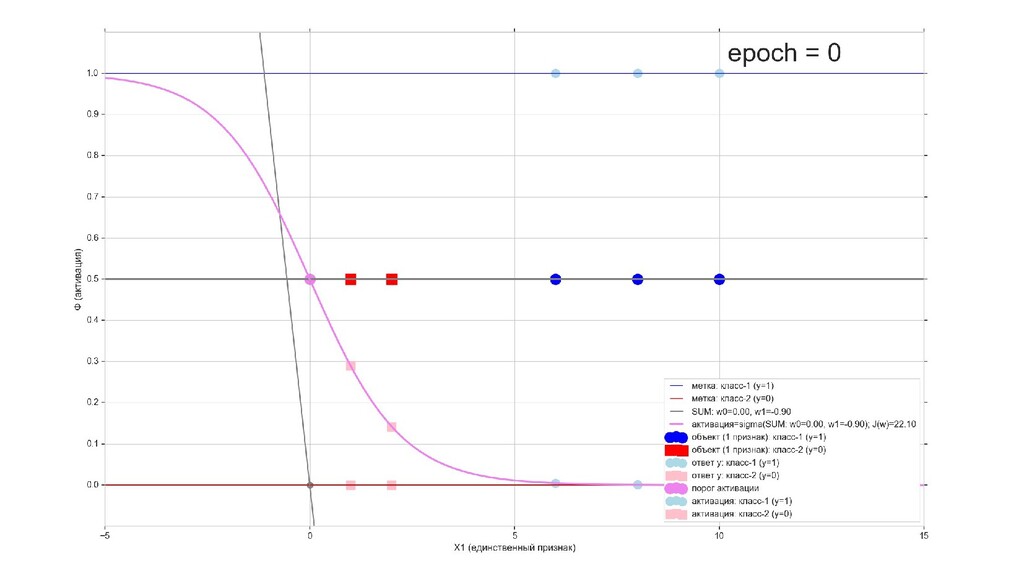
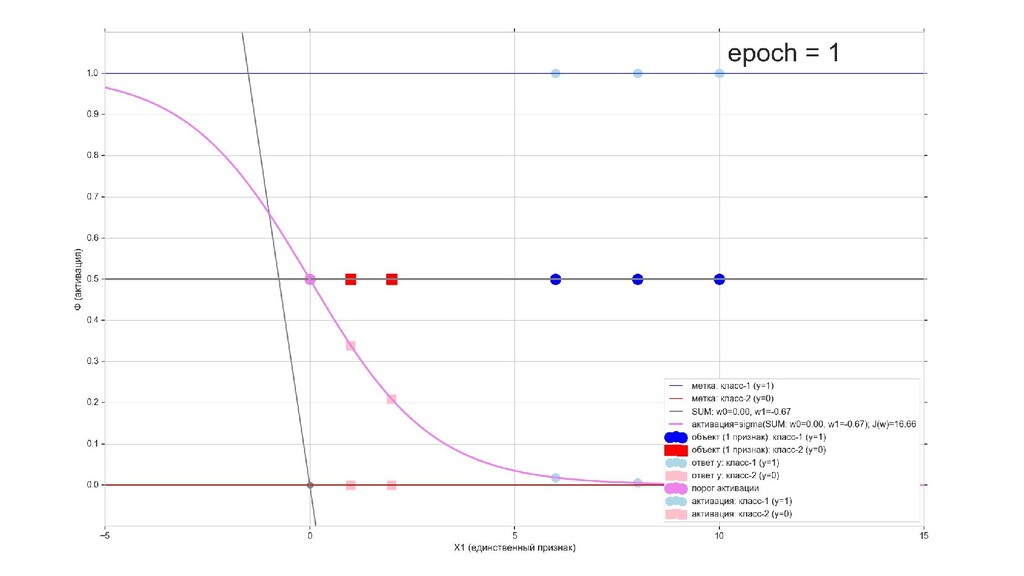
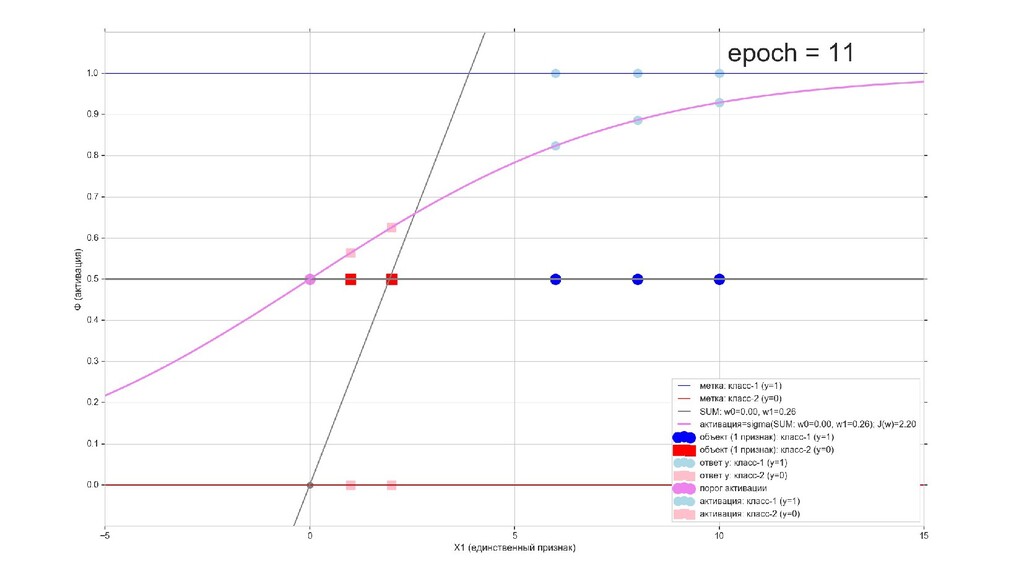
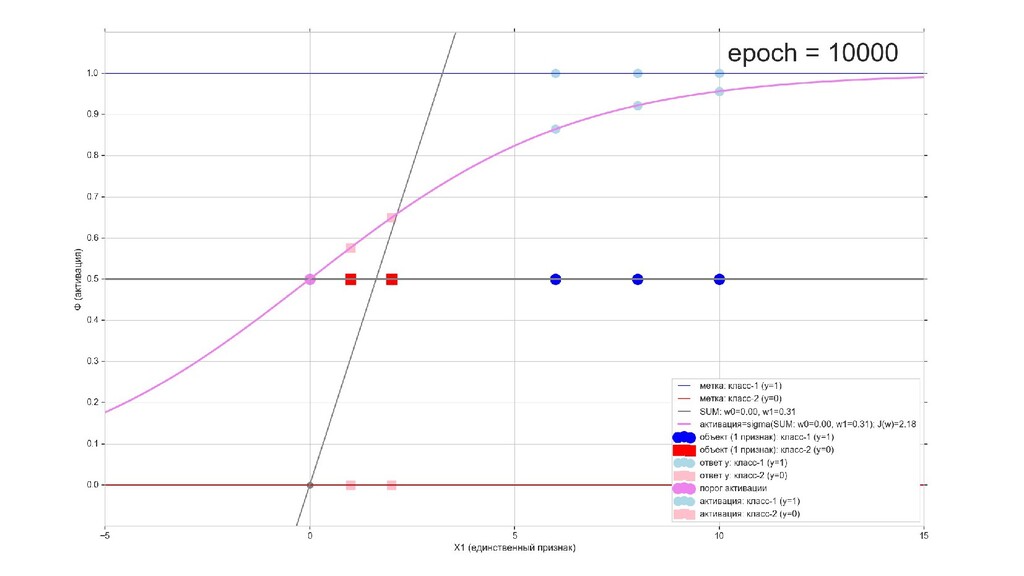
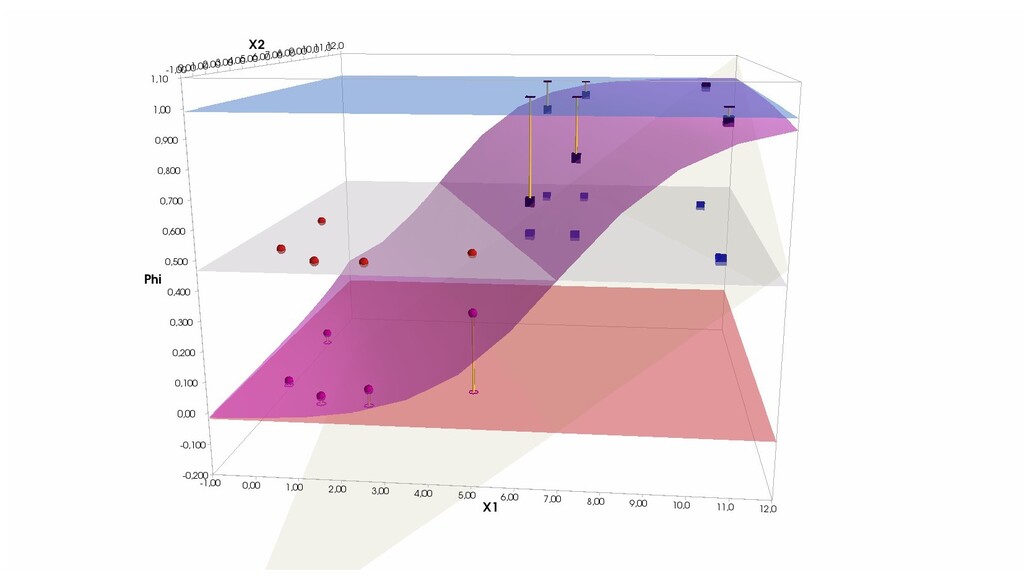
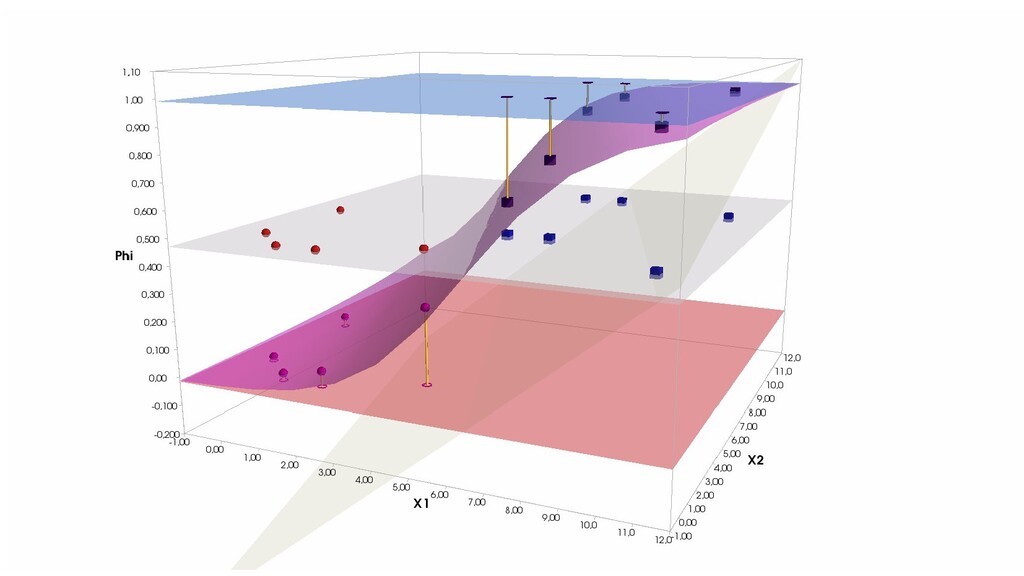
- Визуальное представление спуска: поиск оптимального положения сигмоиды активации в пространстве единственного признака объекта плюс измерение для значений активации: пересечение с порогом, разделяющее точки на классы, и направление наклона, назначающего точкам класс.
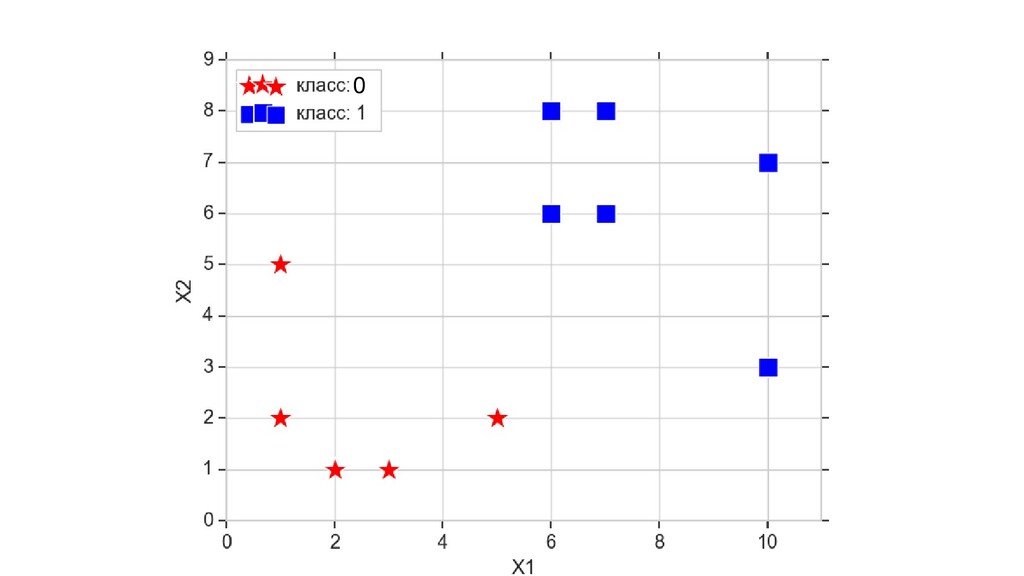
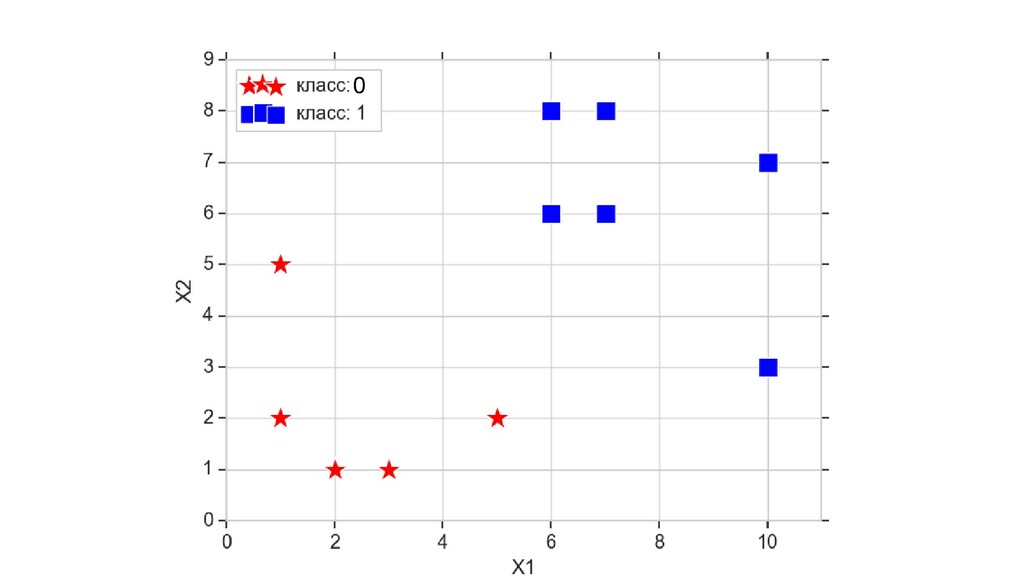
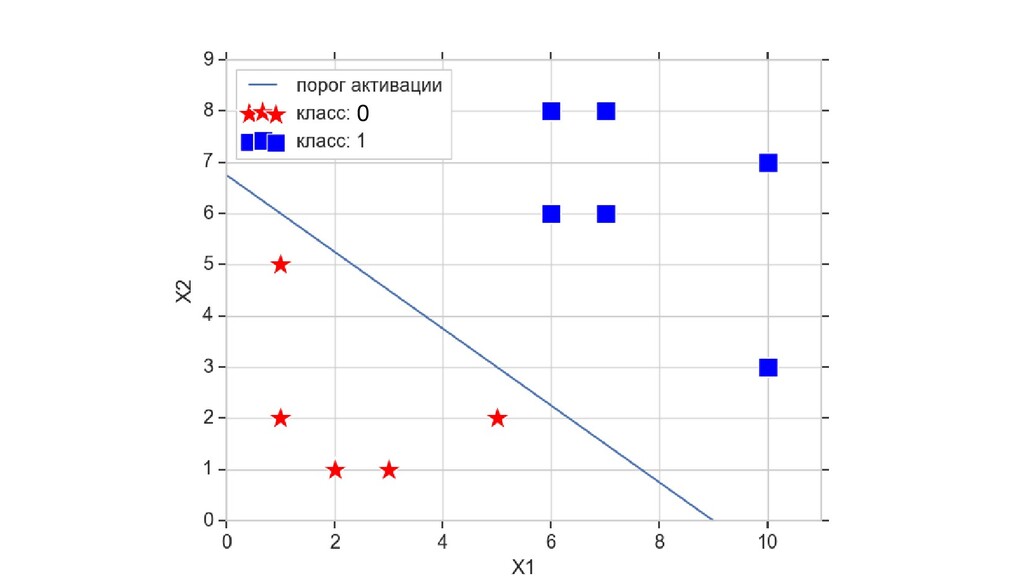
- Пространство 2-д: классификация объектов с 2-мя признаками
- Геометрическое представление задачи: активация теперь поверхность в пространстве 3д: два измерения - признаки объекта плюс значение активации. Порог активации - линия разделяющая объекты на плоскости на классы, наклон активации - назначение классов для каждой из групп.
- Сравнение сигмоиды-активации и линейной активации. В случае с единственным нейроном большой разницы нет, но нелинейность сигмоиды сыграет ключевую роль при объединении нейронов в сеть, как будет показано в следующей лекции.
Обновлено: 14.05.2020
https://vk.com/video53223390_456239473
https://www.youtube.com/watch?v=LgIQ0HcmJFg
https://www.youtube.com/playlist?list=PLSu-UfrQJjQky3LrVLb3hnJ7cnPxjZUQP
https://1i7.livejournal.com/154021.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Градиент — вектор частных производных • ∇ [набла] (перевернутая дельта)](https://files.speakerdeck.com/presentations/5830ce5877db4b17a248317e738ec420/slide_107.jpg){kind=link}
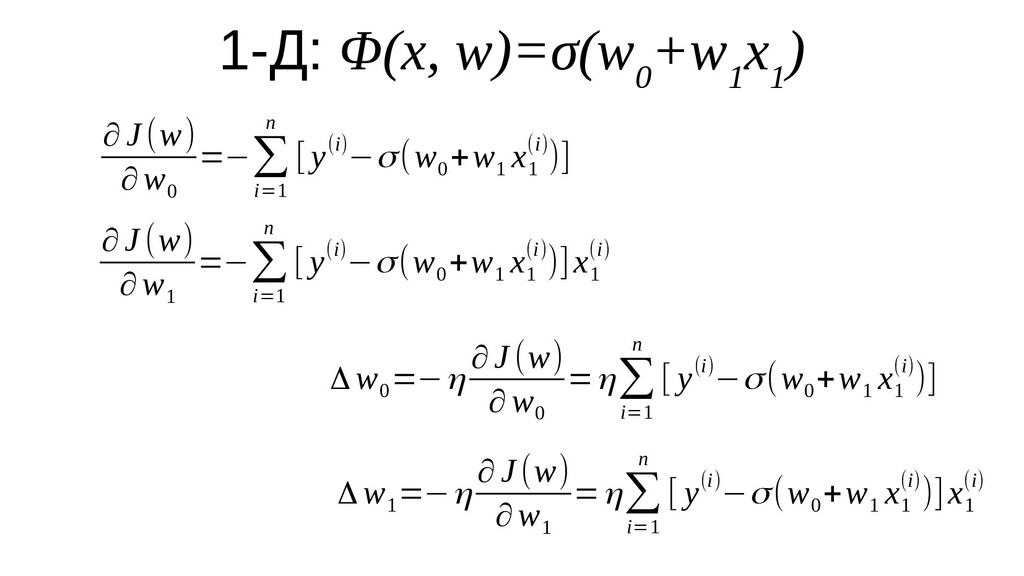{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![w 0 : [-3, 10]: «divide by zero»](https://files.speakerdeck.com/presentations/5830ce5877db4b17a248317e738ec420/slide_128.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}