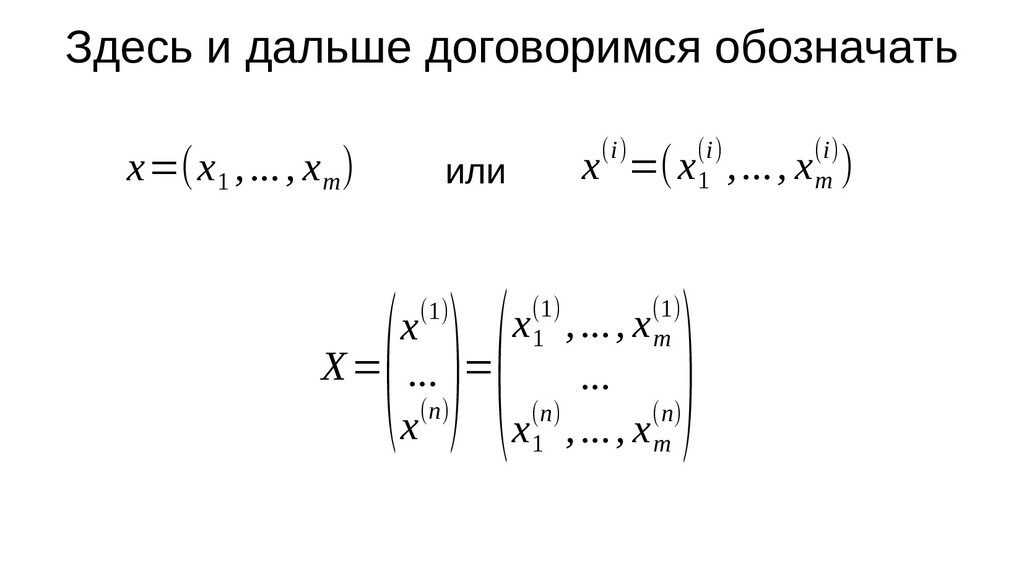
из n элементов (n строк), у каждого элемента m признаков (m столбцов) • x — произвольный элемент (<=> объект, строка) выборки, • x j — j-й признак элемента x • x(i) (верхний индекс в круглых скобках) — i-й элемент выборки x=(x 1 ,..., x m ) x(i)=(x 1 (i) ,..., x m (i))
(ячейка целиком) значения из словаря • Порядковые: можно сравнивать между собой: размер одежды (S, M, L, XL), диапазон возрастов (ребенок, юноша, взрослый, старик) и т.п. • Номинальные: нельзя сравнивать между собой: теги, города, цвета и т. п. • Можем по ним фильтровать и искать • Но обычно мы хотим иметь дело с числами • Задача: превратить текстовые категории в числа
признаков решение норм: назначить числовые значения так, чтобы сохранить порядок сравнения оригинальных категорий ([S → 0] < [M → 1] < [L → 2] < [XL → 3]) • Для номинальных признаков: номинальные категории сравнивать нельзя, а числа сравнивать можно • Просто пронумеровав номинальные категории, мы внесем в данные информацию, которой там не было
признак x j принимает значения из множества W={w 1 , ..., w l } — все категории: теги, города, цвета и т.п. • Создадим l [эль] (столько же, сколько всего категорий) новых бинарных фиктивных признаков-индикаторов u 1 , …, u l : • k-й индикатор u k показывает, равен ли категориальный признак x j на данном объекте значению k-й категории w k u k (i)= {1, x j (i)=w k 0, x j (i)≠w k ,k=1,...,l
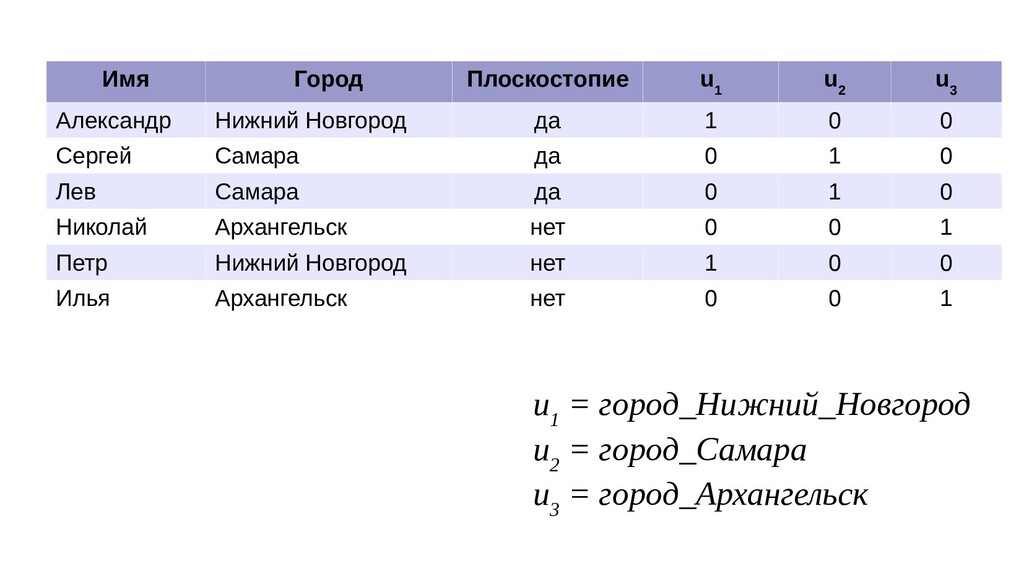
Новгород, Самара, Архангельск} • Кодируем тремя бинарными признаками (u 1 , u 2 , u 3 ): • Нижний Новгород →(1, 0, 0): (u 1 =1, u 2 =0, u 3 =0) • Самара → (0, 1, 0): (u 1 =0, u 2 =1, u 3 =0) • Архангельск → (0, 0, 1): (u 1 =0, u 2 =0, u 3 =1)
Нижний Новгород да 1 0 0 Сергей Самара да 0 1 0 Лев Самара да 0 1 0 Николай Архангельск нет 0 0 1 Петр Нижний Новгород нет 1 0 0 Илья Архангельск нет 0 0 1 u 1 = город_Нижний_Новгород u 2 = город_Самара u 3 = город_Архангельск
3 бинарных признака (3 колонки в таблице) • Из всех новых признаков только один может принимать ненулевое значение для одного объекта (одна единица на строку)
признака x j — последовательность слов (w 1 , w 2 , …, w m ) • В отличие от категорий, мы не рассматриваем признак как монолитное значение (значение ячейки целиком), а разбиваем его на составляющие и работаем с ними
слова перемешаны (частое употребление спец-терминов, эпоха, стиль, привычки автора и т.п.) • Все слова из всех текстов принадлежат словарю W = {w 1 , …, w l } • Создадим l [эль] новых фиктивных признаков-индикаторов u 1 , …, u l : • n(w k , x j ) — число вхождений слова w k в текст x j • k-й признак u k показывает, сколько раз k-е слово w k встречается в тексте x j • (похоже на дамми-кодирование, только вместо двоичных признаков числовые, ненулевых значений столько, сколько слов в тексте) u k (i)=n(w k , x j (i)),k=1,...,l
IDF — inverse document frequency (обратная частота документа) • Улучшение подхода: вычисляем не количество слов, а оценку важности слова для текста • Чем чаще встречается слово, тем оно более важно (этот текст про это слово) • Чем реже встречается слово в других текстах, тем оно еще важнее (это не общеупотребительная лексика)
числа вхождений слова в документ к количеству слов в документе (могут быть другие варианты определения, например, просто число вхождений) • IDF(w) — inverse document frequency (обратная частота документа): логарифм отношения общего количества документов к числу документов, содержащих слово
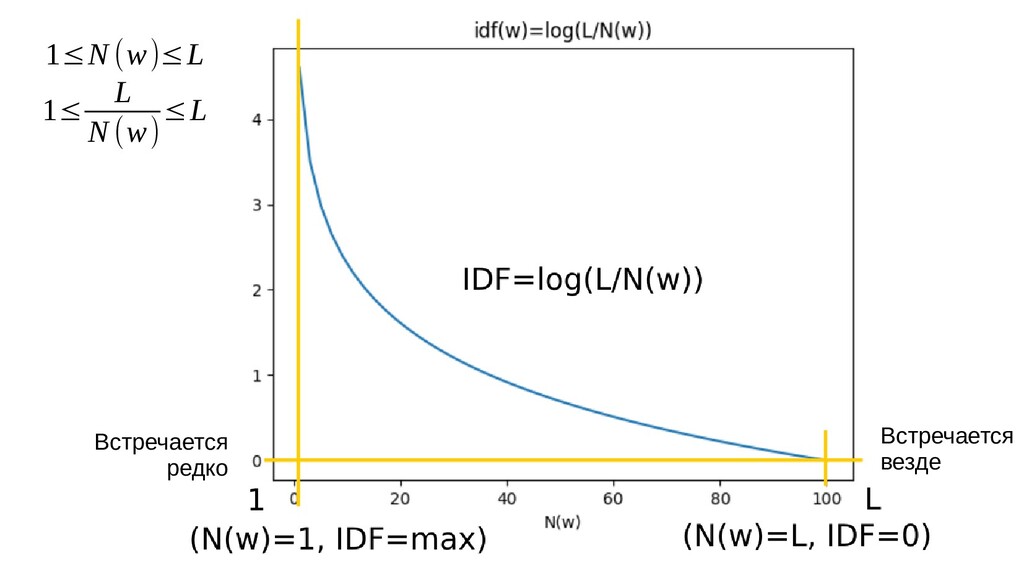
d • |d| - количество слов в документе d • N(w) — число документов, содержащих слово w • L — число документов • Мера важности слова w для документа d: TF−IDF(w ,d)= n(w ,d) |d| ⏟ TF(w ,d) ∗log( L N (w) ) ⏟ IDF(w)
L (слово встречается во всех текстах), то IDF = log(L/L) = log(1) = 0 = min (минимальный коэффициент) • Если N(w) = 1 (слово встречается только в одном тексте), то IDF = log(L) = max (максимальный коффициент) • Чем меньше N(w), тем больше IDF • На ноль здесь не делим, т.к. любое слово должно встретиться хотя бы в одном тексте, иначе оно не попадет в словарь
— большой штраф за каждый дополнительный текст • Чем чаще встречается слово, тем меньше штраф • Есть заметная разница, встречается слово в 1-м или уже в 2-х текстах • Нет примерно никакой разницы, встречается ли слово в 80-ти или в 110 текстах
при помощи sklearn.feature_extraction.text.CountVectorizer Выведите: • топ 5 слов для комментариев с позитивным отзывом, • топ 5 слов для комментариев с негативным отзывом
при помощи sklearn.feature_extraction.text.TfIdfTransformer Выведите: • топ 5 слов (максимальный tf-idf) для комментариев с позитивным отзывом, • топ 5 слов для комментариев с негативным отзывом
о положительности или отрицательности отзыва? • Будет ли IDF выводить характерные для всего класса слова в топ? • Можно ли улучшить алгоритм? например: считать IDF для каждого позитивного отзыва отдельно в группе только с негативными Задание-3
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}