Регрессия, регрессионная модель — модель предсказания целевой переменной в непрерывной шкале
Часть 2: построение модели предсказания: линейная модель, криволинейной модели, выбросы, подгонка, оценка качества
Обновлено: 09.04.2020
[видео - брак] https://vk.com/video53223390_456239427
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
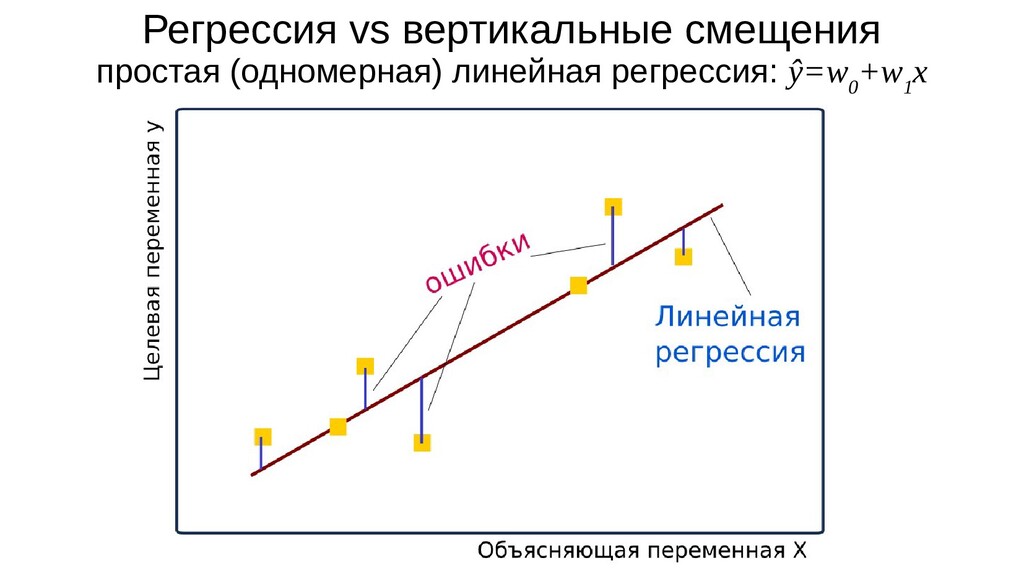{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
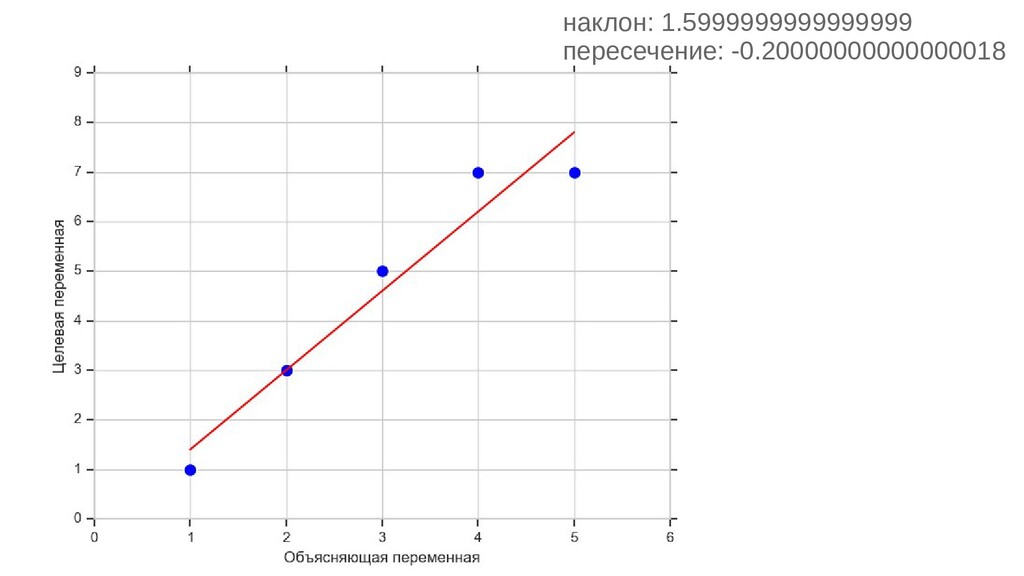{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Sklearn: LinearRegression X = df[['RM']].values y = df[['MEDV']].values from sklearn.linear_model](https://files.speakerdeck.com/presentations/dd36d0eee24245dabb4055dfc8994d2d/slide_24.jpg){kind=link}
![наклон: [9.10210898] пересечение: [-34.67062078]](https://files.speakerdeck.com/presentations/dd36d0eee24245dabb4055dfc8994d2d/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Sklearn: RANSACRegressor X = df[['RM']].values y = df[['MEDV']].values from sklearn.linear_model](https://files.speakerdeck.com/presentations/dd36d0eee24245dabb4055dfc8994d2d/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
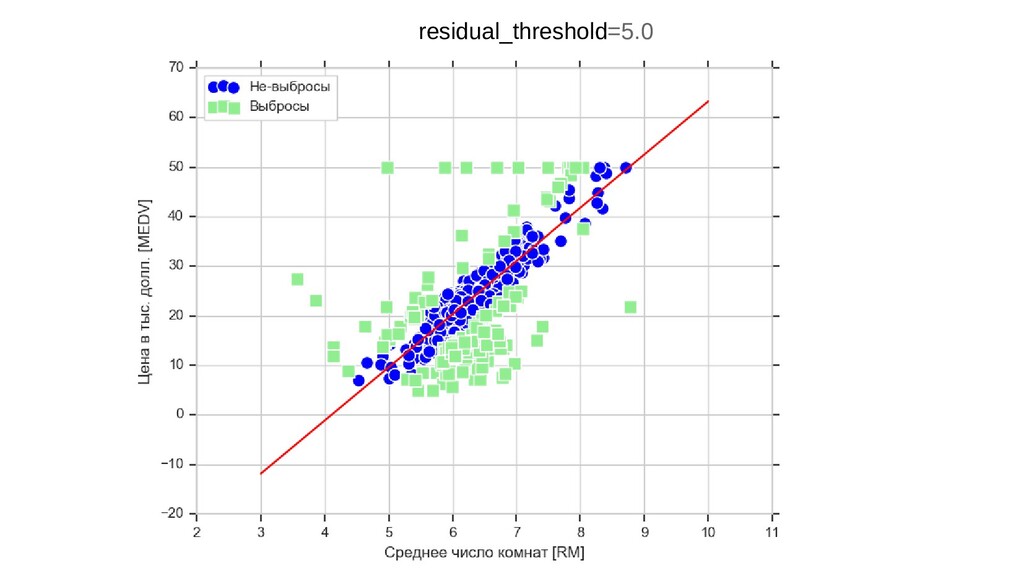{kind=link}
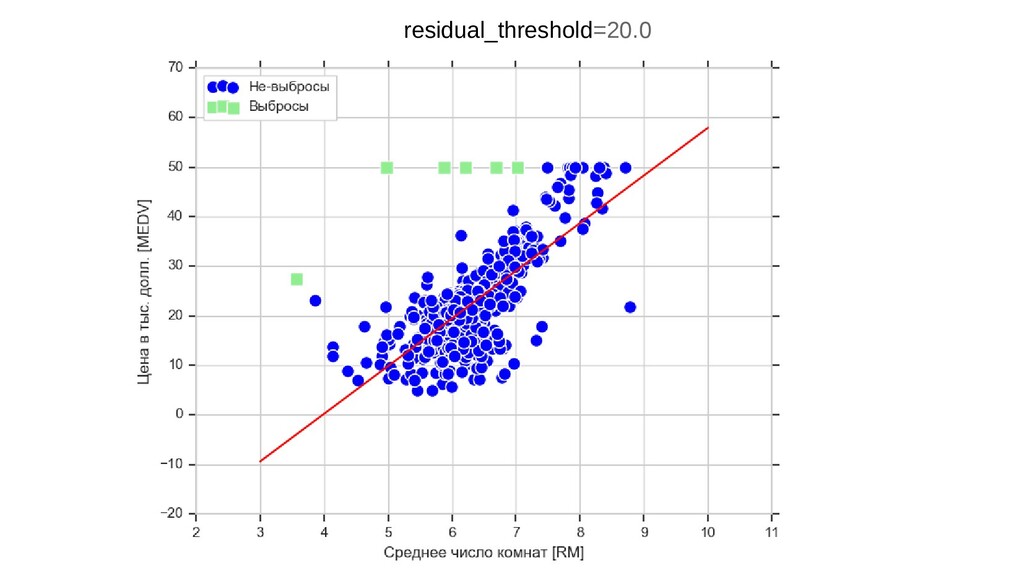{kind=link}
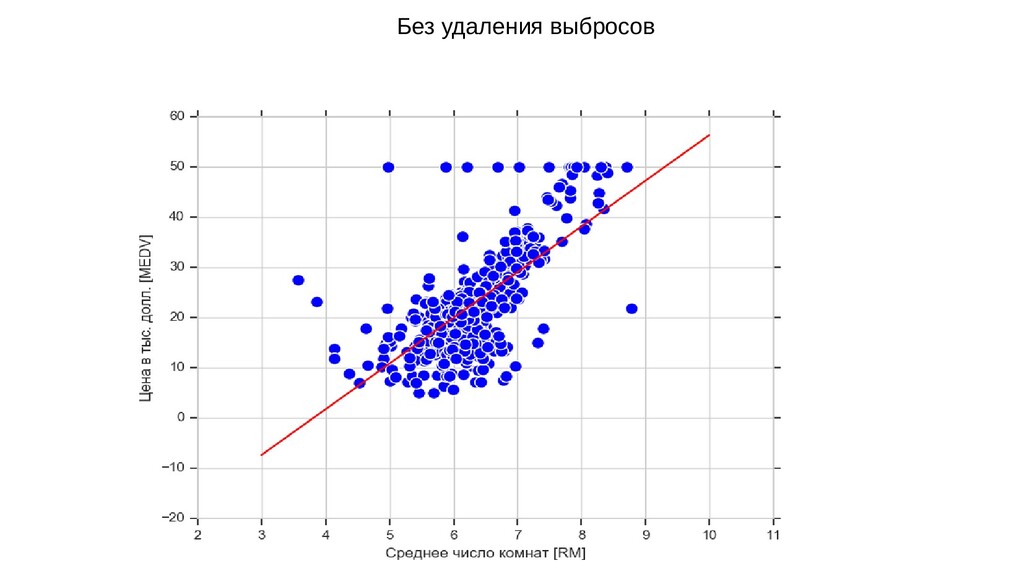{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
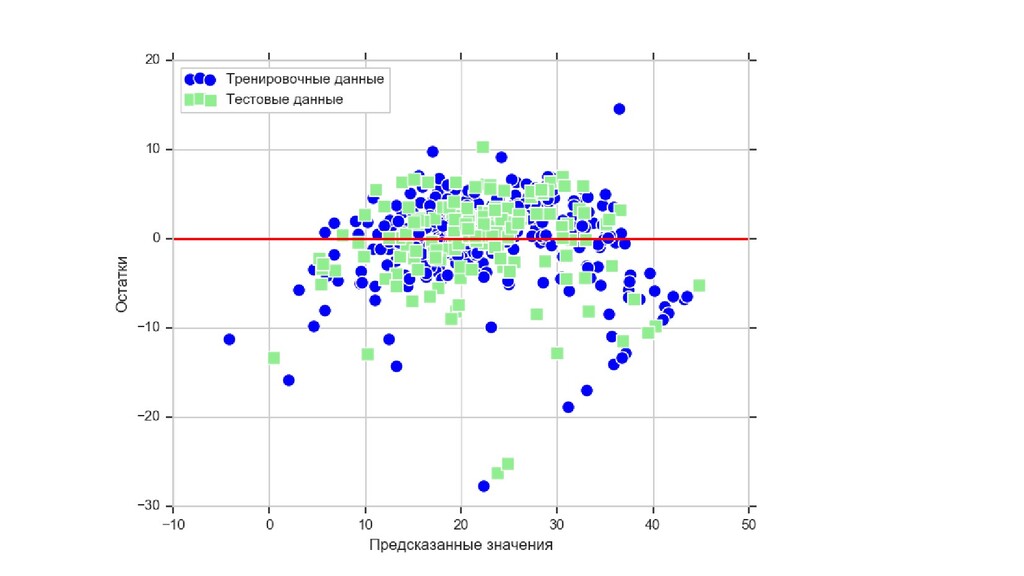{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
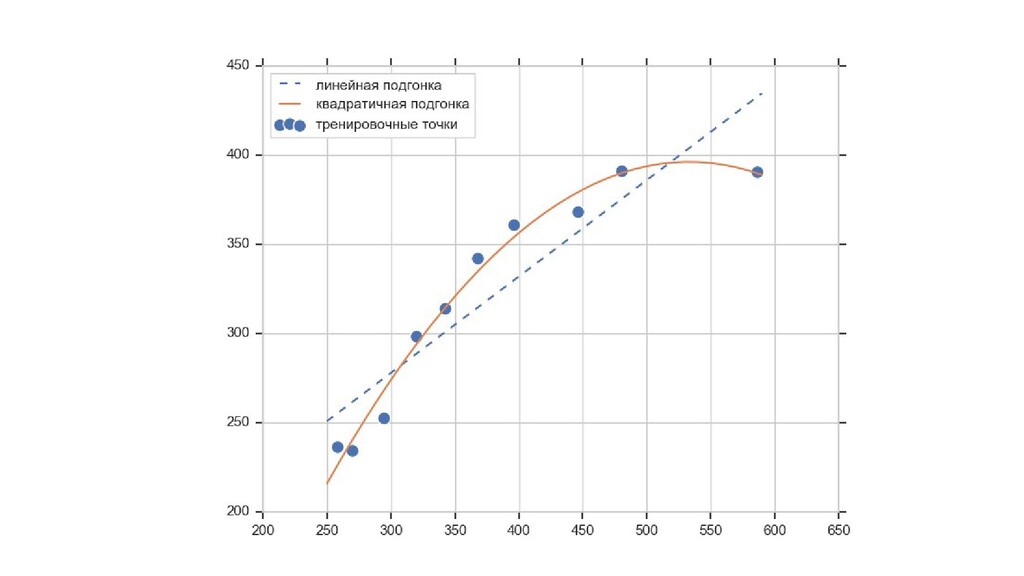{kind=link}
![boston-polynom.py X = df[['LSTAT']].values y = df[['MEDV']].values import numpy as](https://files.speakerdeck.com/presentations/dd36d0eee24245dabb4055dfc8994d2d/slide_50.jpg){kind=link}
![boston-polynom.py # линейная подгонка X_fit = np.arange(X.min(), X.max(), 1)[:, np.newaxis]](https://files.speakerdeck.com/presentations/dd36d0eee24245dabb4055dfc8994d2d/slide_51.jpg){kind=link}
{kind=link}
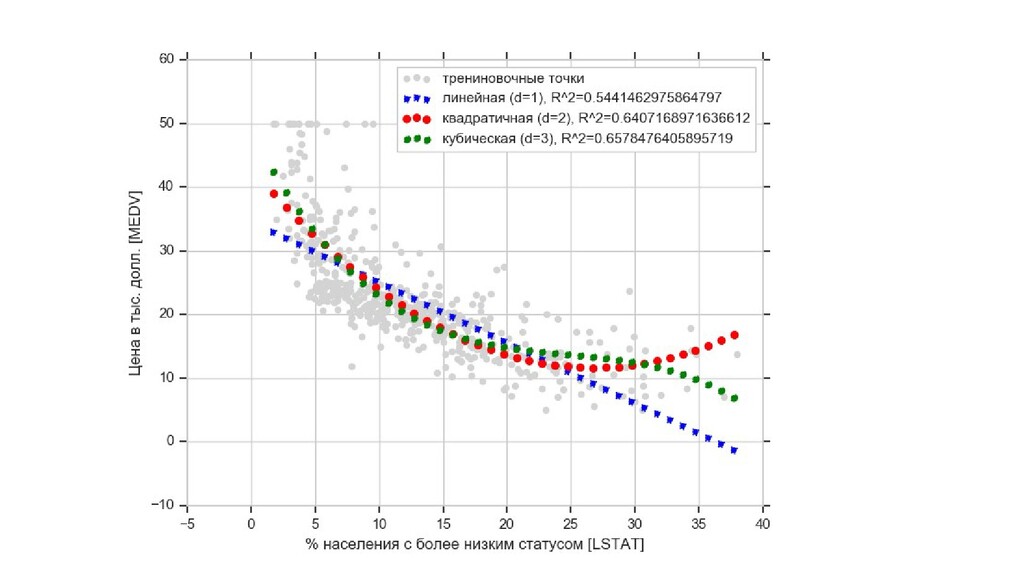{kind=link}
{kind=link}
{kind=link}
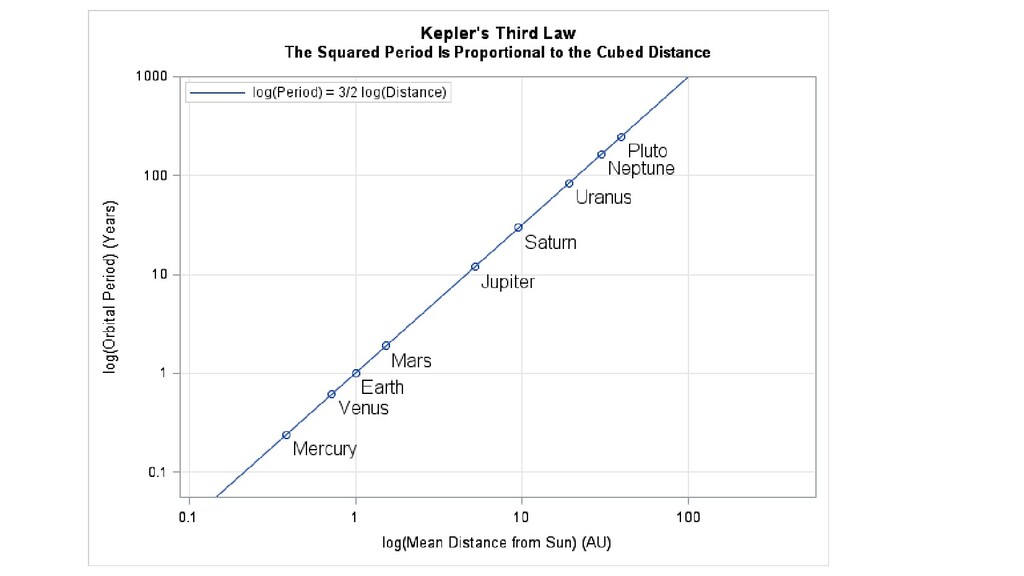{kind=link}
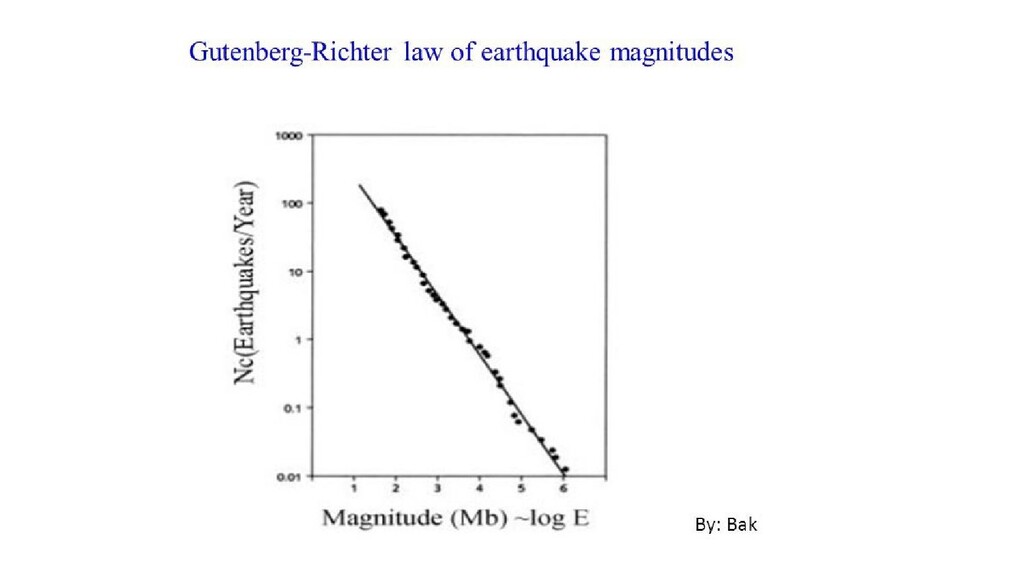{kind=link}
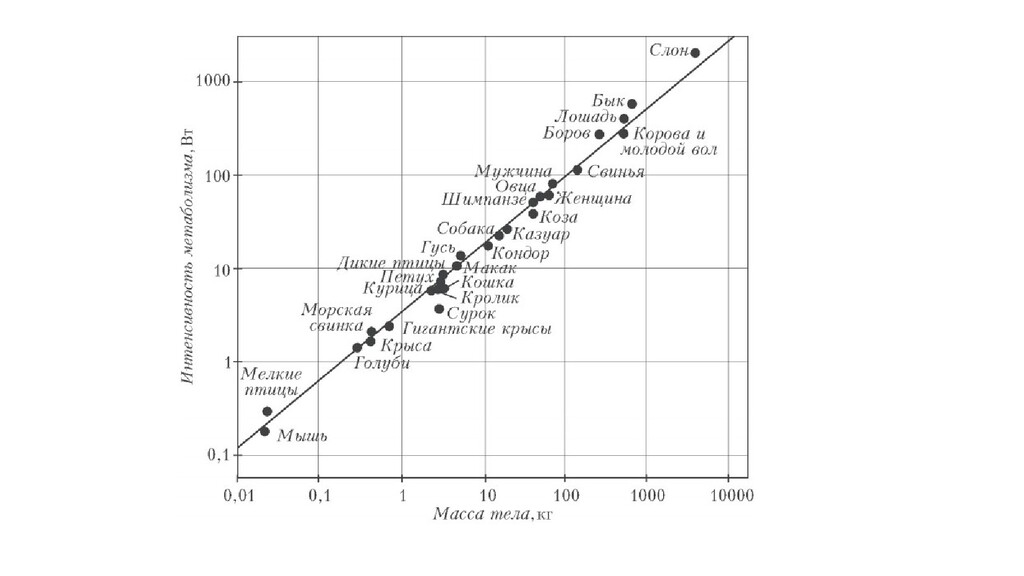{kind=link}
{kind=link}