relevancy: one-to-one personalization across email, web, mobile • Original idea: API-based transactional email • 3 engineers two years ago, now ~65 employees • Some Clients: Fab, Huffington Post, OpenSky, Patch, Thrillist, Refinery 29, Totsy, Business Insider, Savored, NY Observer, College Humor, Oscar De La Renta, Tippr, NY Post, American Media, Flavorpill, Codecademy, Ahalife, GroupCommerce, BustedTees, Lifebooker, BET, Newsweek/Daily Beast, turntable.fm
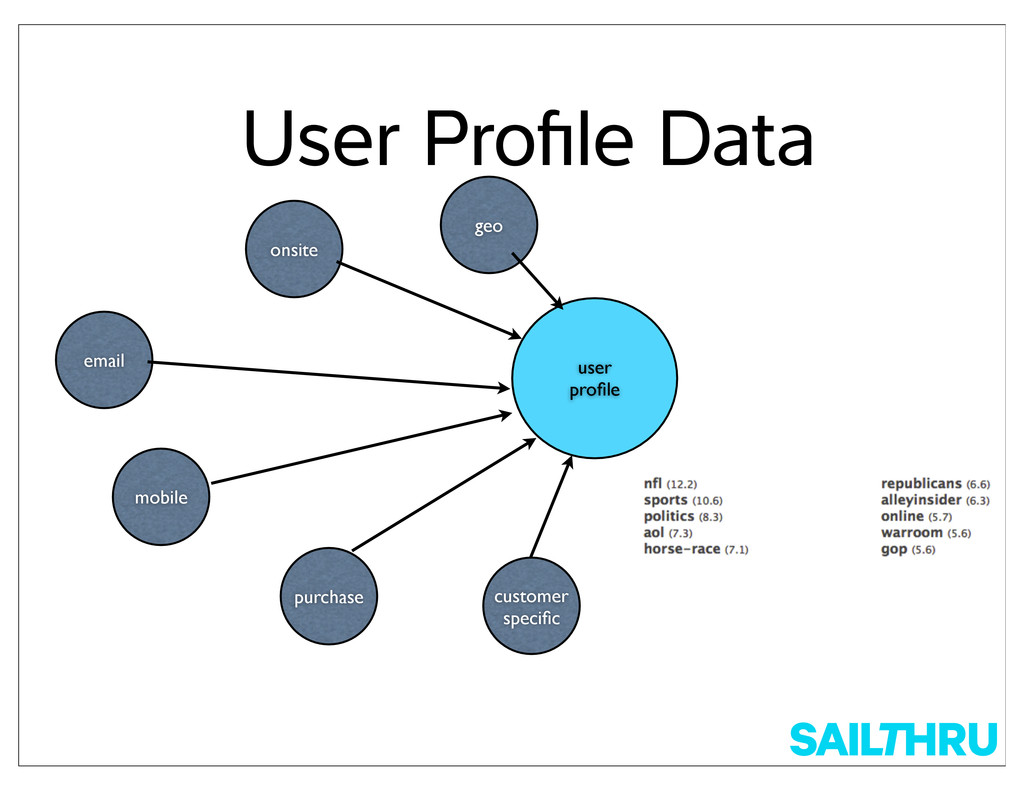
purposes (e.g. messages vs user profiles) • Largest logical collections are partitioned at e application level • Made sense for us as our data is naturally partitioned by customer
Makes it easy to store flexible JSON- based customer input (many now use Mongo emselves) • Good performance • Encourages scalable approach • We know it well
--fork --rest --replSet main1 • Don’t ever run wi out replication • Don’t ever kill -9 • Don’t run wi out writing to a log • Run behind a firewall • Use journaling • Default oplog size seems fine
Systems will surprise you • Production systems are complex • Graph every ing you can, so you can see when some ing you did changed e pattern • Alerts when some ing’s wrong
load average • faults/sec: if is starts to creep up, you may be nearing exceeding working set • number of connections: could be driver or network connectivity problem • replication lag: usually load on primary • dataSize and indexSize
• MMS is a great tool for diagnosing issues • But also Graphite / StatsD / Nagios • And don’t forget e log • explain() can shed light on pa ological queries
rough one in wrapper class which we wrote • If you use someone else’s lib or ORM, make sure (if you had to) you could do stuff like: • set timeouts or enable failfast retry add a $hint for all instances of a query queue writes elsewhere temporarily ensure all writes are “safe” for a collection
somewhere and tried later? (What if e queue fails?) • What if a queued write is failing indefinitely? • If a read fails, can you timeout quickly and try again on a different node? (failfast retry) • In some cases we might not care, in some cases lives might depend on it
cumbersome, we never use em • Referencing by MongoId can mean doing extra lookups • Build human-readable references to save you doing lookups and manual joins • Just be mindful of space tradeoffs for readability
design • If you can ask e question at all, you might want to err on e side of embedding • Don’t embed if e embedding could get huge • Don’t feel too bad about denormalizing by embedding AND storing in a top-level collection
• Does not size up infinitely, will hit 16MB limit • Hard to create references to embedded object • Limited ability to indexed-sort e embedded objects • Really huge objects are cumbersome and will have deserialization overhead
32423.00000341 • Need all messages in blast 32423: • db.message.blast.find( { _id: /^32423\./ } ); • (Yeah, I know e \. is ugly. Don’t use a dot if you do is.)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}