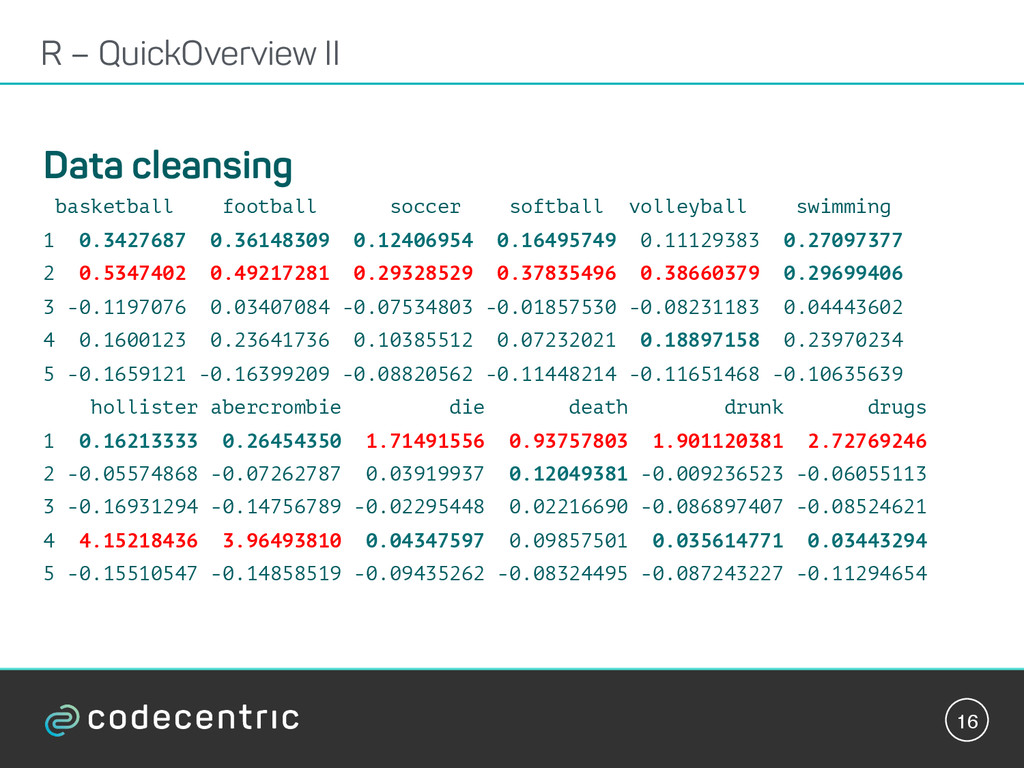
18.335,69,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,2,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0, 0 2006,F, 18.875,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 2006,NA, 18.995,10,0,0,0,0,0,0,0,0,0,0,0,1,0,0,5,1,1,0,3,0,1,0,0,0,1,0,0,0,2,0,0,0,0,0,1, 1 R - Our Dataset The 500 most common key-words of High-School students‘ profiles were mapped and counted to the mentioned categories.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![15 Data clustering > interests <- teens[5:40] > interests_z <-](https://files.speakerdeck.com/presentations/c2cf3b8d80b44bffa08e1b73ccff0c26/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
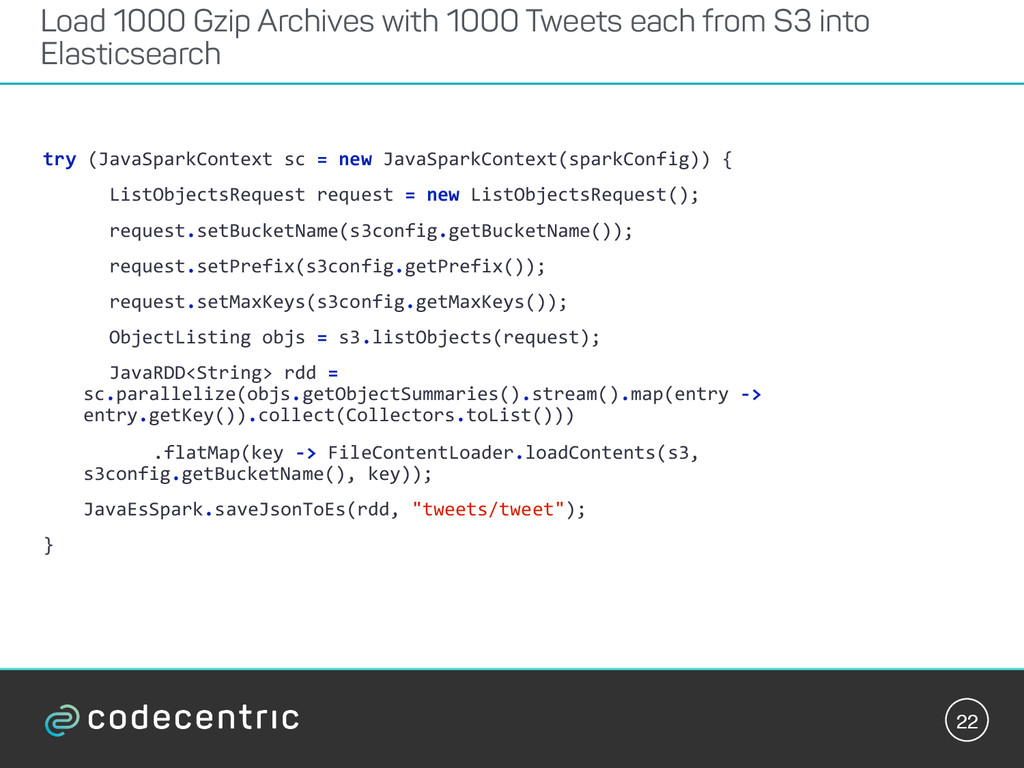
![21 SparkConf*sparkConfig*=*new*SparkConf();* sparkConfig.setMaster("local[3]").setAppName("ES*Loader");* sparkConfig.set("es.nodes",*“XXX.euEwestE1.aws.found.io:9200");* * * Spark configuration](https://files.speakerdeck.com/presentations/c2cf3b8d80b44bffa08e1b73ccff0c26/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![29 private*static*String[][]*clubs*=* ******new*String[][]*{{"FC*Bayern",*"Schweinsteiger",* "BastianSchweinsteiger",*"FCBayern",*"BayernMünchen",* "Vidal",*"Bayern",*"schweinsteiger",*"fcbayern"},* **********{"BVB",*"bvb",*"Aubameyang",*"badragaz15",* "Kagawa",*"Hummels",*"Tuchel",*"Reus",*"Immobile",* "Dortmund",*"EchteLiebe",*"BVBAsienTour15",* **************"Mkhitaryan",*"Gündogan",*"Weigl",*"Meyer"},* **********{"VfB",*"vfb",*"Stuttgart",*"VfBimZillertal",*](https://files.speakerdeck.com/presentations/c2cf3b8d80b44bffa08e1b73ccff0c26/slide_28.jpg){kind=link}
![30 *public*static*void*main(String...*args)*{* ****SparkConf*sparkConfig*=*new*SparkConf();* ****sparkConfig.setMaster("local[3]").setAppName(“Training* Set*Extracion");* ****sparkConfig.set("es.nodes",*"localhost:9200");* * ****try*(JavaSparkContext*sparkContext*=*new* JavaSparkContext(sparkConfig))*{* ******JavaRDD<Map<String,0Object>>*esRDD*=*](https://files.speakerdeck.com/presentations/c2cf3b8d80b44bffa08e1b73ccff0c26/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
![33 Training Run: Spark public*static*void*main(String...*args)*throws*ClassNotFoundException,*IOException*{* ****SparkConf*sparkConfig*=*new*SparkConf();* ****sparkConfig.setMaster("local[1]").setAppName(“Training*Run");* ****sparkConfig.set("es.nodes",*"localhost:9200");* ****try*(JavaSparkContext*sparkContext*=*new*JavaSparkContext(sparkConfig))*{* ******JavaEsSpark.esRDD(sparkContext,*"trainings/training").values().foreach(classificationTrainer);*](https://files.speakerdeck.com/presentations/c2cf3b8d80b44bffa08e1b73ccff0c26/slide_32.jpg){kind=link}
![34 Classification Run : Spark *public*static*void*main(String[]*args)*throws*ClassNotFoundException,*IOException*{* ****SparkConf*sparkConfig*=*new*SparkConf();* ****sparkConfig.setMaster("local[3]").setAppName(“Classification*Run");* ****sparkConfig.set("es.nodes",*"localhost:9200");* ****try*(JavaSparkContext*sparkContext*=*new*JavaSparkContext(sparkConfig))*{*](https://files.speakerdeck.com/presentations/c2cf3b8d80b44bffa08e1b73ccff0c26/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![39 *public*static*void*main(String...*args)*{* ****//0JavaStream* ****SparkConf*sparkConfig*=*new*SparkConf();* ****sparkConfig.setMaster("local[1]").setAppName("ES*Loader");* ****sparkConfig.set("es.nodes",*"localhost:9200");* ****//0Configre0Twitter* ****try*(JavaSparkContext*jsc*=*new*JavaSparkContext(sparkConfig))*{* ******JavaStreamingContext*jstrc*=*new*JavaStreamingContext(jsc,*new*Duration(1000));* 0TwitterUtils.createStream(jstrc).map(classifyTweets).foreachRDD(saveTweets);*](https://files.speakerdeck.com/presentations/c2cf3b8d80b44bffa08e1b73ccff0c26/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}