API - Field API : project, map, discard , groupBy… - Typed API : TypedPipe[T], works like scala.collection.Iterator[T] - Matrix Library - ALGEBIRD : Abstract Algebra library … we’ll talk about it later
Four concepts - Streams : infinite sequence of tuples - Spouts : Source of streams - Bolts : Process and produces streams Can do : Filtering, aggregations, Joins, … - Topologies : define a flow or network of spouts and blots.
spout) .each(new Fields("sentence"), new Split(), new Fields("word")) .groupBy(new Fields("word")) .persistentAggregate(new Factory(), new Count(), new Fields("count")) .parallelismHint(6);
processing. - Scales to 100s of nodes and achieves second scale latencies -Efficient and fault-tolerant stateful stream processing - Simple batch-like API for implementing complex algorithms
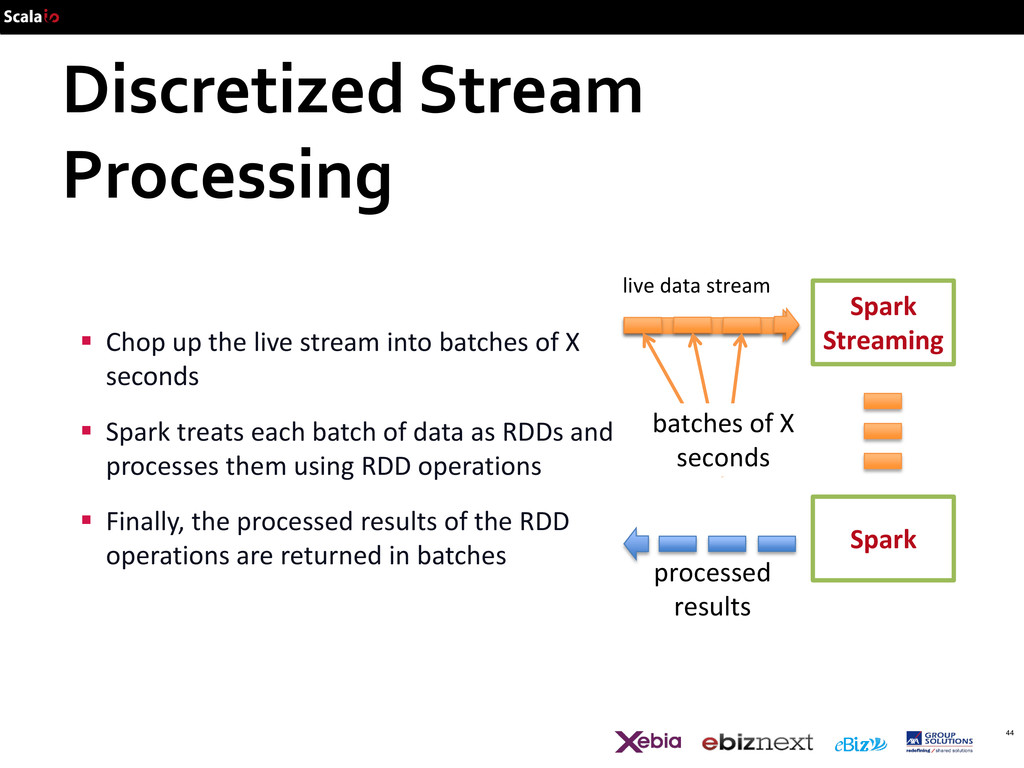
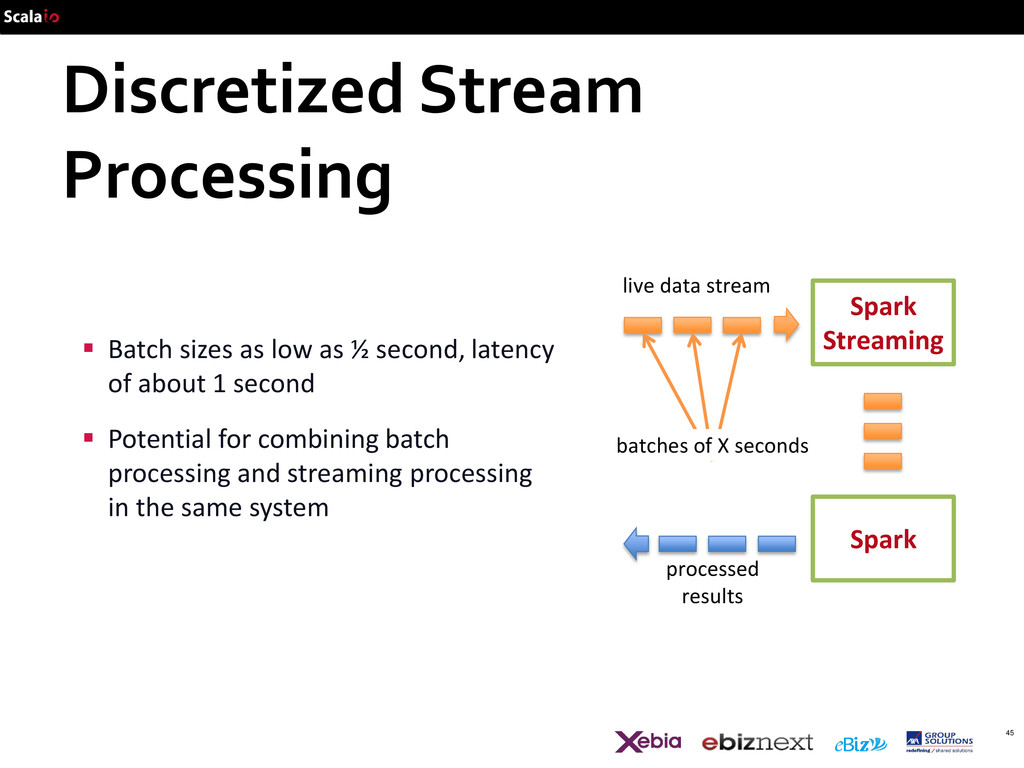
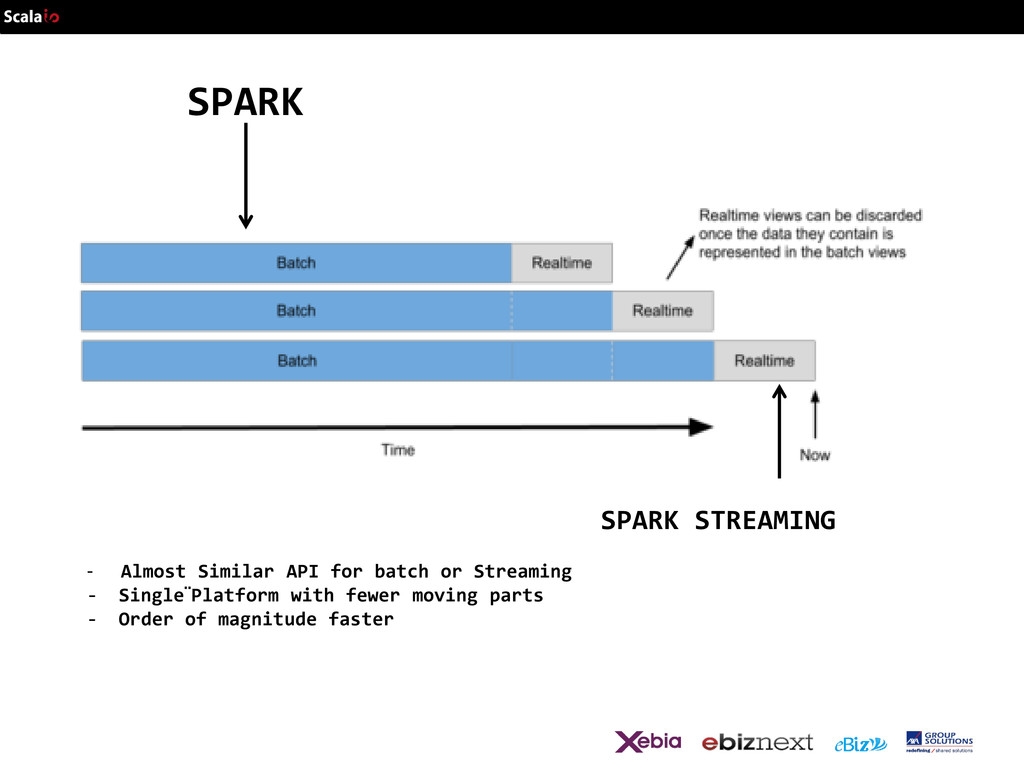
seconds live data stream processed results Chop up the live stream into batches of X seconds Spark treats each batch of data as RDDs and processes them using RDD operations Finally, the processed results of the RDD operations are returned in batches
½ second, latency of about 1 second Potential for combining batch processing and streaming processing in the same system Spark Spark Streaming batches of X seconds live data stream processed results
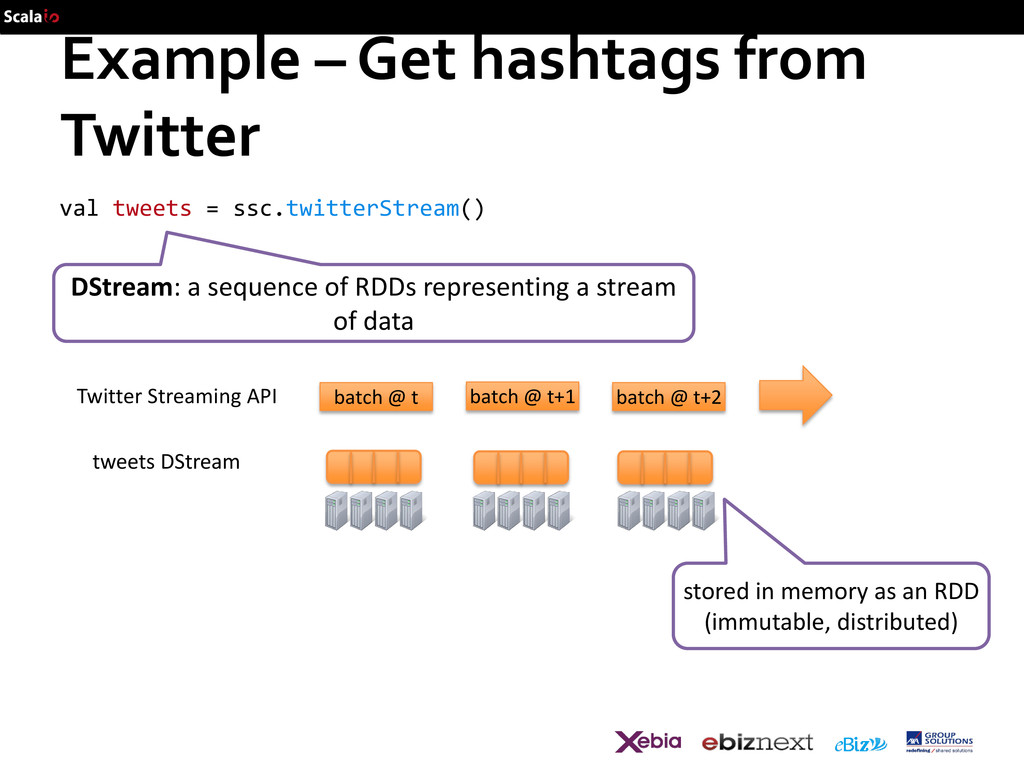
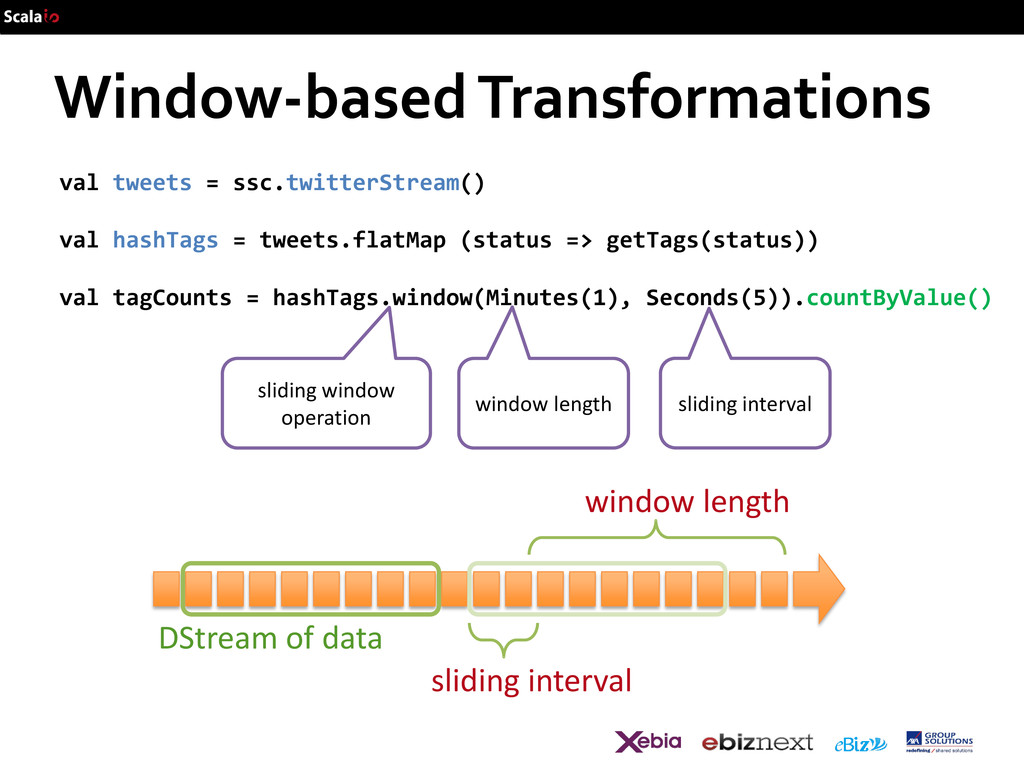
DStream: a sequence of RDDs representing a stream of data batch @ t+1 batch @ t batch @ t+2 tweets DStream stored in memory as an RDD (immutable, distributed) Twitter Streaming API
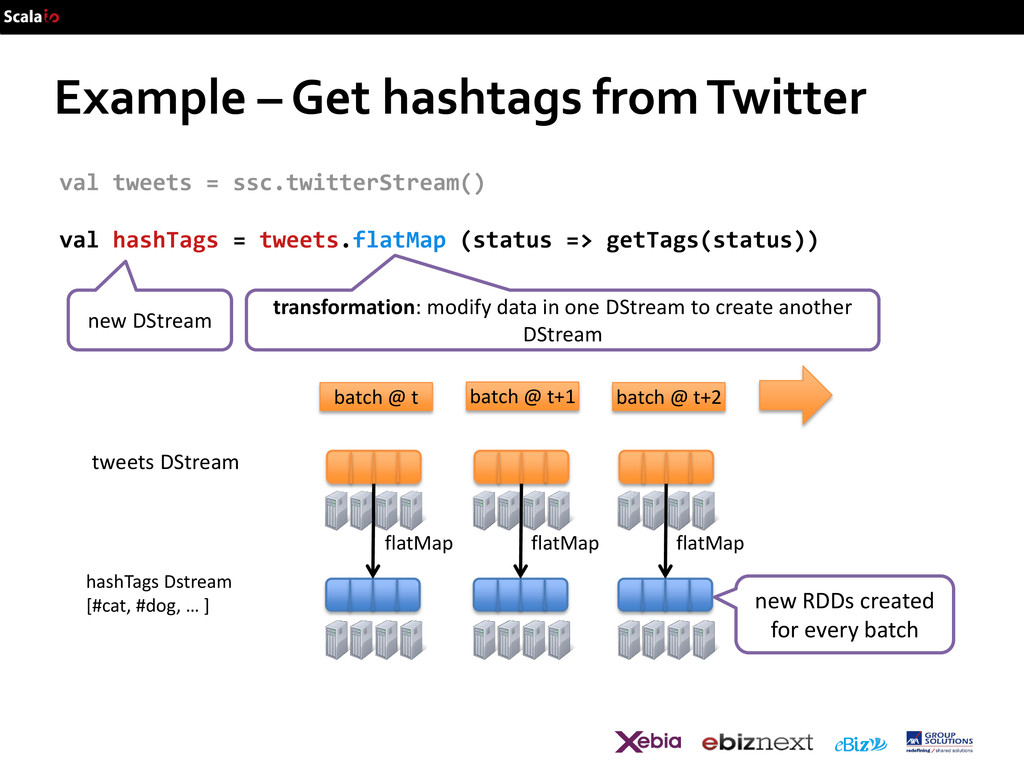
val hashTags = tweets.flatMap (status => getTags(status)) flatMap flatMap flatMap … transformation: modify data in one DStream to create another DStream new DStream new RDDs created for every batch batch @ t+1 batch @ t batch @ t+2 tweets DStream hashTags Dstream [#cat, #dog, … ]
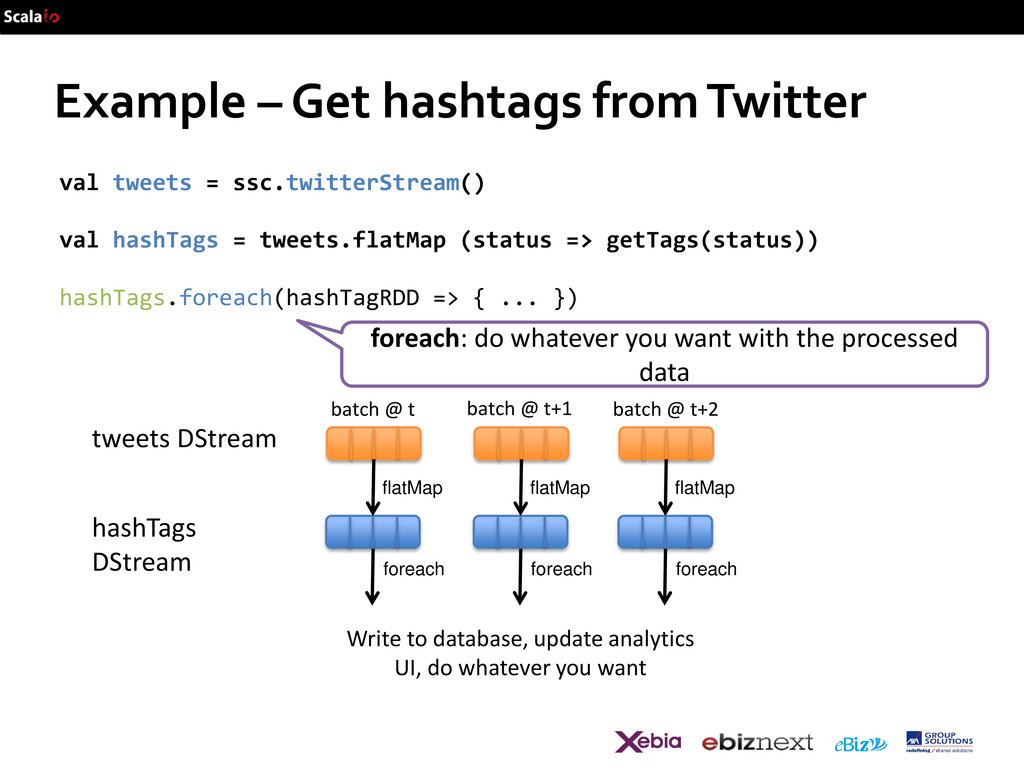
val hashTags = tweets.flatMap (status => getTags(status)) hashTags.foreach(hashTagRDD => { ... }) foreach: do whatever you want with the processed data flatMap flatMap flatMap foreach foreach foreach batch @ t+1 batch @ t batch @ t+2 tweets DStream hashTags DStream Write to database, update analytics UI, do whatever you want
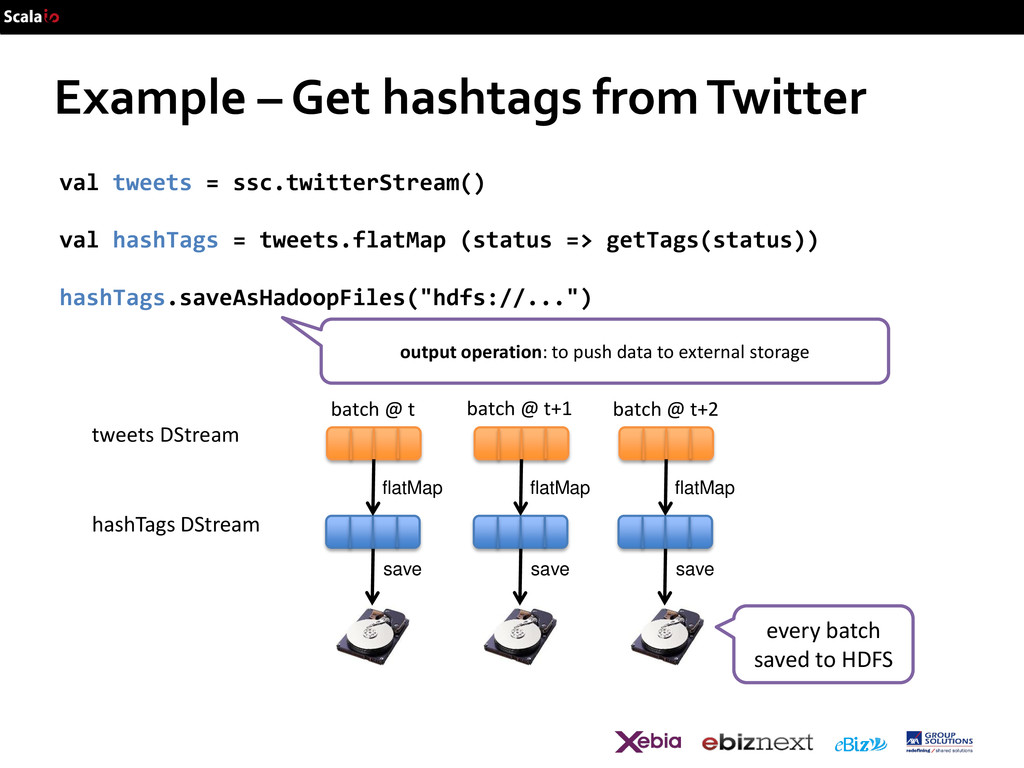
val hashTags = tweets.flatMap (status => getTags(status)) hashTags.saveAsHadoopFiles("hdfs://...") output operation: to push data to external storage flatMap flatMap flatMap save save save batch @ t+1 batch @ t batch @ t+2 tweets DStream hashTags DStream every batch saved to HDFS
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![def wordCount[P <: Platform[P]] (source: Producer[P, String], store: P#Store[String, Long])](https://files.speakerdeck.com/presentations/02c383b01f9901312c660a36078c81b4/slide_26.jpg){kind=link}
![SummingBird trait Platform[P <: Platform[P]] { type Source[+T] type Store[-K,](https://files.speakerdeck.com/presentations/02c383b01f9901312c660a36078c81b4/slide_27.jpg){kind=link}
![On Storm -Source[+T] : Spout[(Long, T)] -Store[-K, V] : StormStore](https://files.speakerdeck.com/presentations/02c383b01f9901312c660a36078c81b4/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Clustering with Mahout redux def StreamClustering(source : Platform[P.String], store :](https://files.speakerdeck.com/presentations/02c383b01f9901312c660a36078c81b4/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}