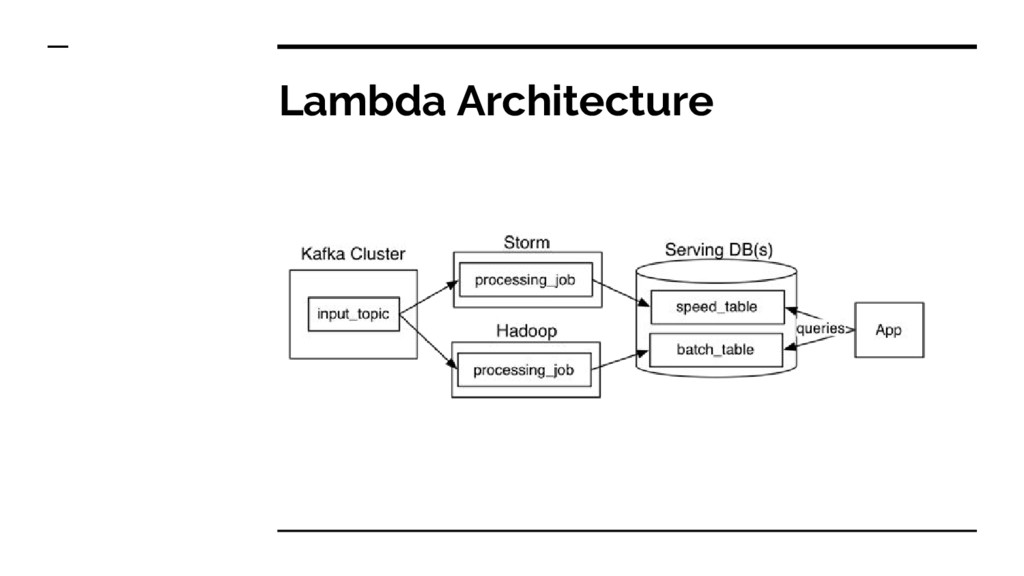
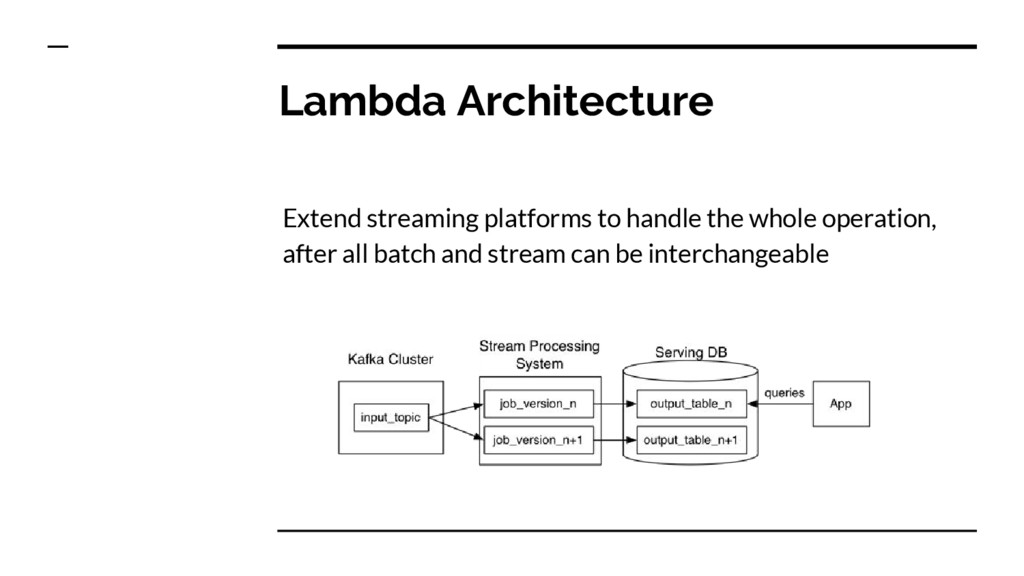
pain points - Pros : Keeps the source unchanged, emphasize the issue of reprocessing the data, force the operations on materialized views - Cons : Two separated code in two distributed systems, each with its own complexity, and painful to manage
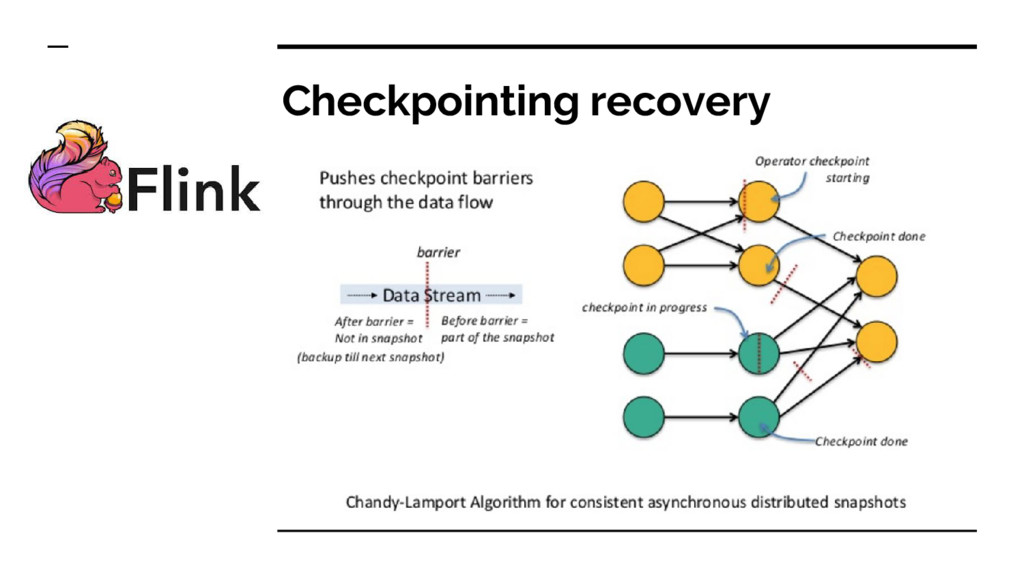
: ensure all operators see every data, and replay the stream in case of failure. Exactly once : ensure that operators do not process duplicate updates .
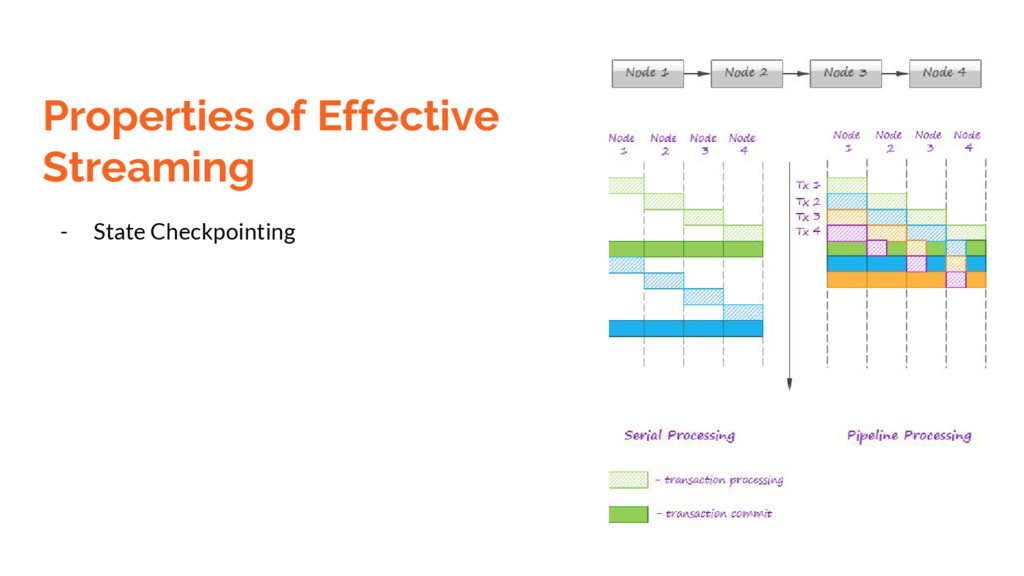
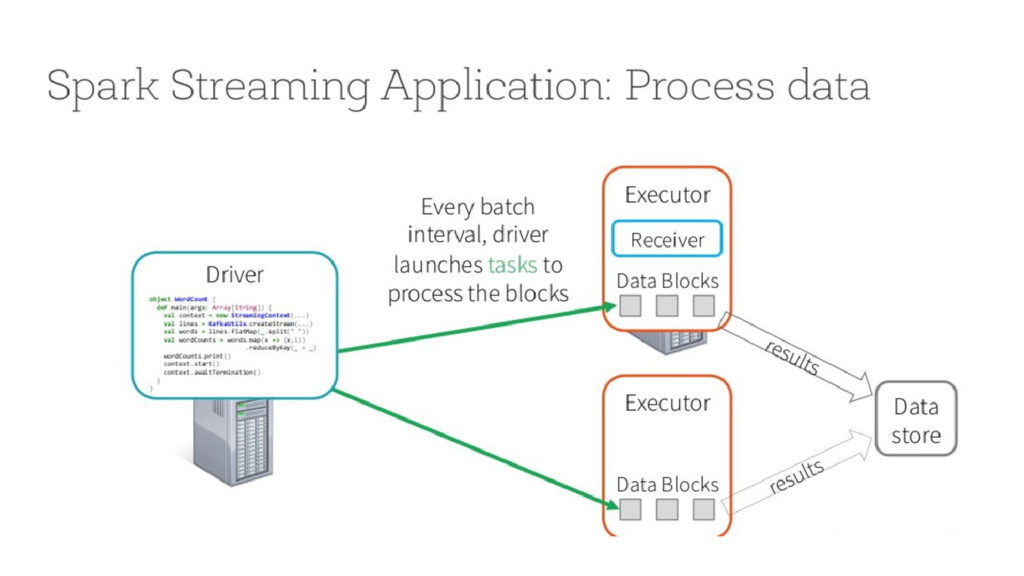
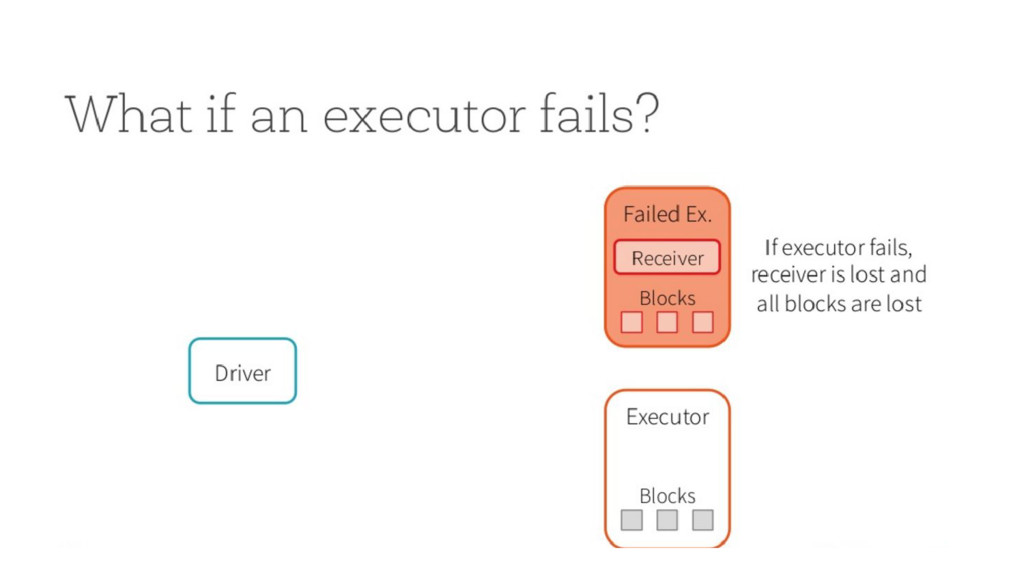
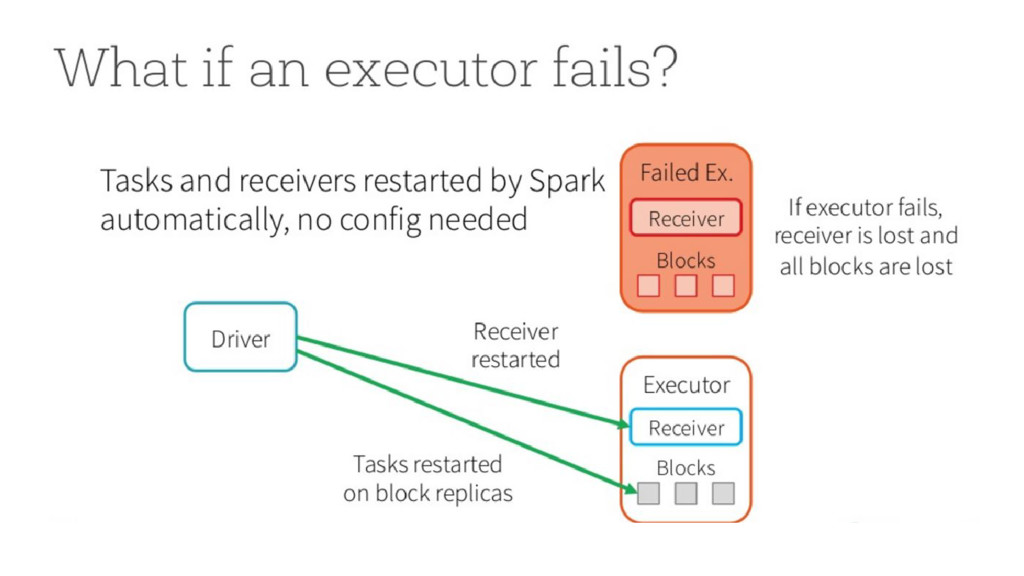
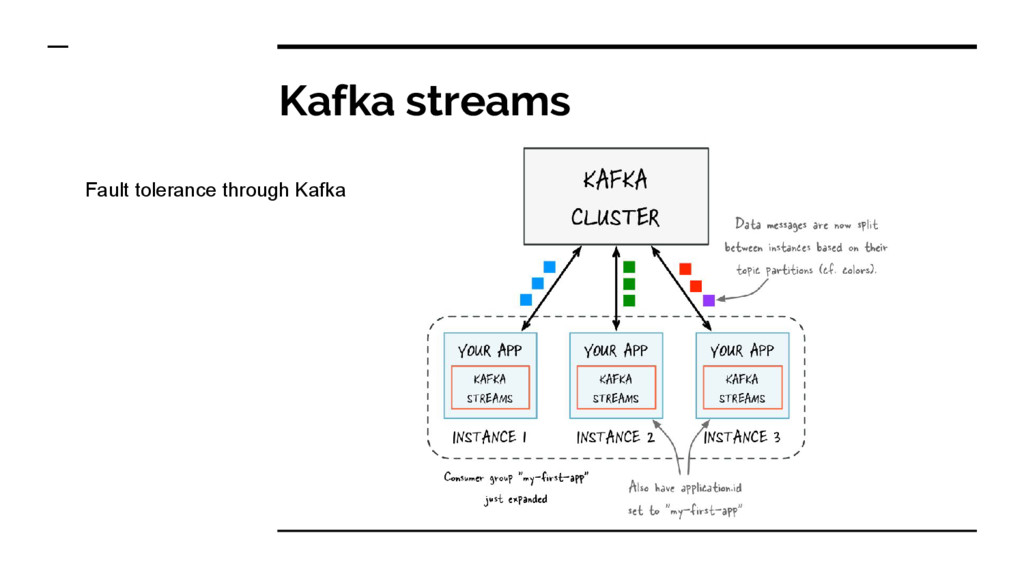
Local state : current state of a specific operator - Partitioned state : maintains state across partitions - Direct Stream API : mapWithState(), flatMapWithState(); etc - Checkpointing and savepoints - Exactly once semantics (at least they claim to be)
for protables data processing pipelines. Provides a Java SDK and other DSLs in other languages. And a handful of streaming engines as runners : Spark, Flink, Dataflow, etc.
Streaming 1 https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101 - The World Beyond Batch and Streaming 2 https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-102 - Dataflow Beam and Spark Conparison https://cloud.google.com/dataflow/blog/dataflow-beam-and-spark-compari son#logistics
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}