6 Proactive Problem Avoidance Build an effective defensive perimeter – Standards & Best Practices – Automation – Patchset Updates (PSUs) – Testing (System Test Plan) – Capacity Planning – Security – Reasonable change control – Education & Training – In summary, operational excellence “The best offense is a good defence”.
7 Proactive Problem Avoidance Frequently Updated Tools and Resources – Master Note for Real Application Clusters (RAC) Oracle Clusterware and Oracle Grid Infrastructure [ID 1096952.1] – 11gR2 Clusterware and Grid Home - What You Need to Know (ID 1053147.1) – RAC and Oracle Clusterware Best Practices and Starter Kit (Platform Independent) (Doc ID 810394.1) With links to platform specific Best Practices and Starter Kits – RACcheck - RAC Configuration Audit Tool [ID 1268927.1] – TFA Collector- The Preferred Tool for Automatic or ADHOC Diagnostic Gathering Across All Cluster Nodes [ID 1513912.1] – Virtual Local Area Networks (VLANs) Deployment Considerations – Best Practices for Database Consolidation in Private Clouds “The best offense is a good defence”.
9 Grid Infrastructure Overview Oracle Clusterware is Required for 11gR2 RAC databases Oracle Clusterware can manage non RAC database resources using agents. Oracle Clusterware can manage HA for any Business Critical Application with agent infrastructure. Oracle publishes Agents for some non RAC DB resources – Bundled Agents for SAP, Golden Gate, Siebel, Apache.. What you need to know.
10 Grid Infrastructure Overview Grid Infrastructure is the name for the combination of :- – Oracle Cluster Ready Services (CRS) – Oracle Automatic Storage Management (ASM) The Grid Home contains the software for both products CRS can also be Standalone for ASM and/or Oracle Restart. CRS can run by itself or in combination with other vendor clusterware Grid Home and RDBMS home must be installed in different locations – The installer locks the Grid Home path by setting root permissions. What you need to know.
11 Grid Infrastructure Overview CRS requires shared Oracle Cluster Registry (OCR) and Voting files – Must be in ASM or CFS ( raw not supported for install ) – OCR backed up every 4 hours automatically GIHOME/cdata – Kept 4,8,12 hours, 1 day, 1 week – Restored with ocrconfig – Voting file backed up into OCR at each change. – Voting file restored with crsctl What you need to know.
12 Grid Infrastructure Overview For network CRS requires – One high speed, low latency, redundant private network for inter node communications – Should be a separate physical network. – VLANS are supported with restrictions. – Used for :- Clusterware messaging RDBMS messaging and block transfer ASM messaging. What you need to know.
13 Grid Infrastructure Overview For Network CRS requires – Standard set up Public Network One Public IP and VIP per node in DNS One Scan name set up in DNS. – Or Grid Naming Service (GNS) set up Public Network One Public IP per node ( recommended ) One GNS VIP per cluster DHCP allocation of hostnames. What you need to know.
14 Grid Infrastructure Overview Single Client Access Name (SCAN) – single name for clients to access Oracle Databases running in a cluster. – Cluster alias for databases in the cluster. – Provides load balancing and failover for client connections to the database. – Cluster topology changes do not require client configuration changes. – Allows clients to use the EZConnect client and the simple JDBC thin URL for transparent access to any database running in the cluster – Examples sqlplus system/manager@sales1-scan:1521/oltp jdbc:oracle:thin:@sales1-scan:1521/oltp What you need to know.
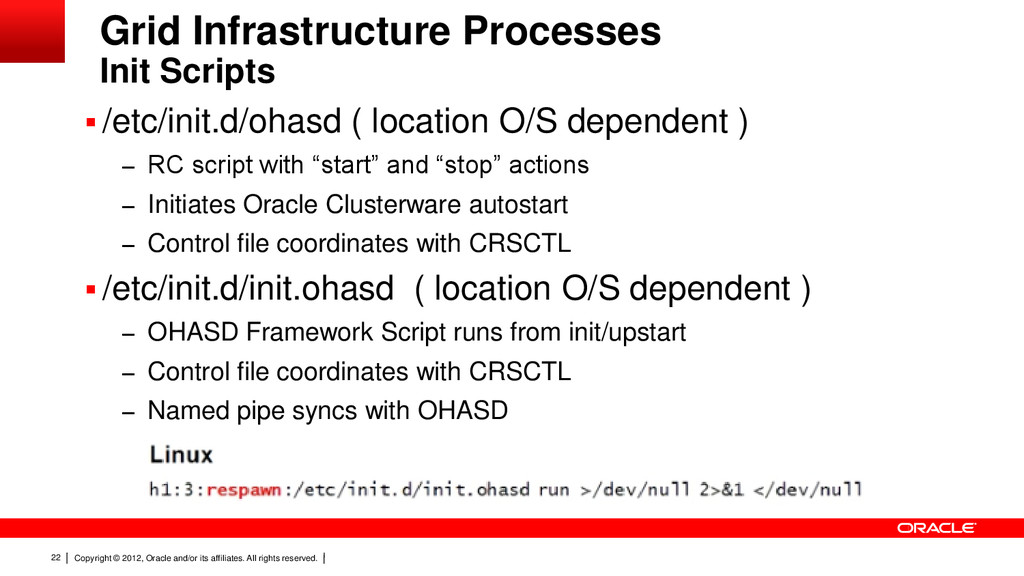
17 Grid Infrastructure Overview Only one set of Clusterware daemons can run on each node The CRS stack all spawns from Oracle HA Services Daemon (ohasd) On Unix ohasd runs out of inittab with respawn . A node can be evicted when deemed unhealthy – May require reboot but at least CRS stack restart (rebootless restart). CRS provides Cluster Time Synchronization services. – Always runs but in observer mode if ntpd configured What you need to know.
18 Grid Infrastructure Overview Nodes only lease a node number – Not guaranteed for stack to always start with same node number – Only way to influence numbering is at first install/upgrade, and then ensure nodes remain fairly active. (almost true) – Pre 11.2 databases cannot handle leased node numbers Pin node numbers – only allows pinning to current leased number CRS stack should be started/stopped on boot/shutdown by init or – crsctl start/stop crs for local clusterware stack – crsctl start/stop cluster for all nodes ( ohasd must be running ) What you need to know.
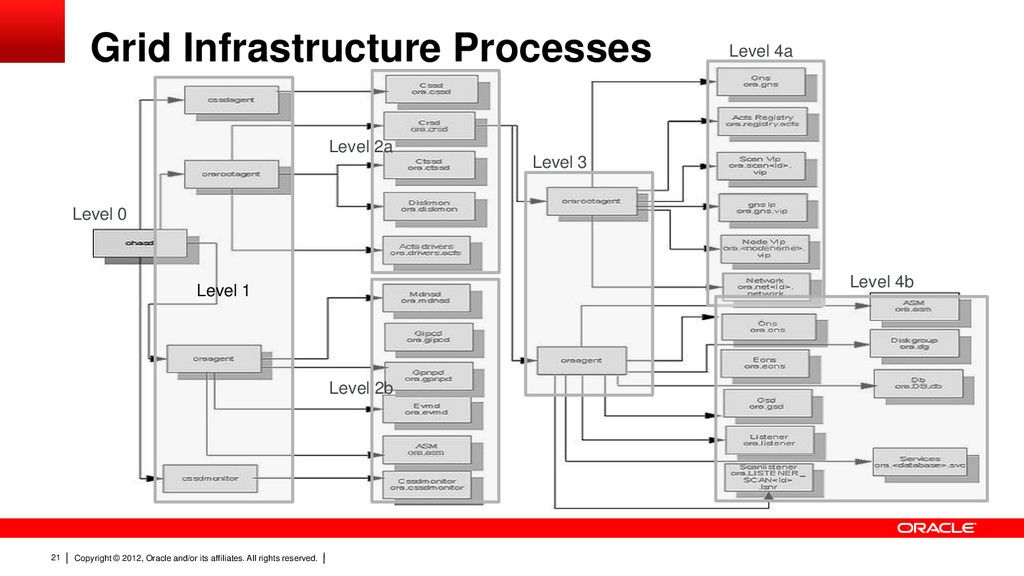
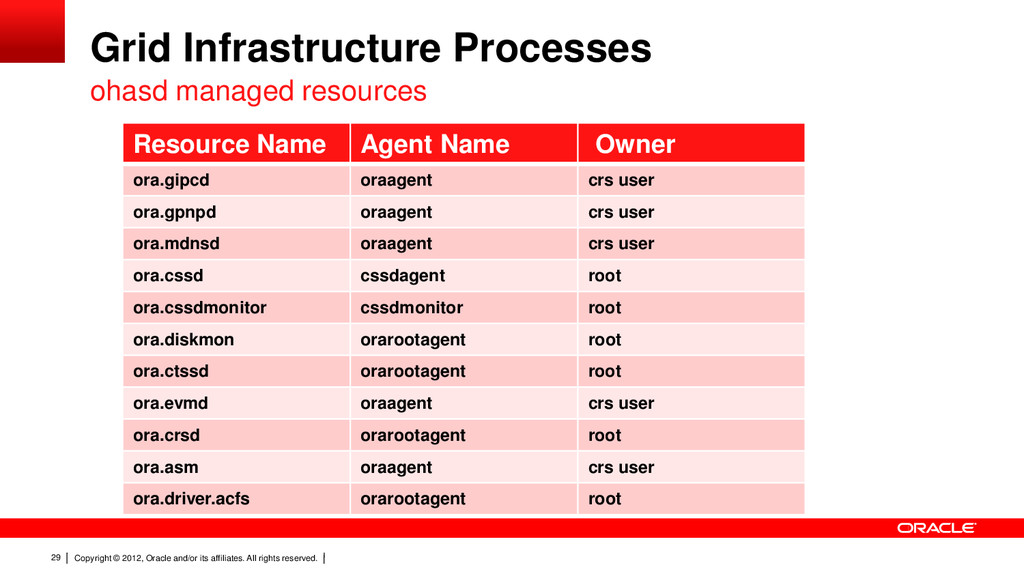
20 Grid Infrastructure Processes 11.2 Agents change everything. Multi-threaded Daemons Manage multiple resources and types Implements entry points for multiple resource types – Start,stop check,clean,fail New Highly Available agent process spawned for different users oraagent, orarootagent, application agent, script agent, cssdagent Single process started from init on Unix (ohasd). Diagram below shows all core resources.
27 Grid Infrastructure Processes Level 3: CRSD spawns: – orarootagent - Agent responsible for managing all root owned crsd resources. – oraagent - Agent responsible for managing all nonroot owned crsd resources. One is spawned for every user that has CRS ressources to manage. Startup Sequence 11gR2.
28 Grid Infrastructure Processes Level 4: CRSD oraagent spawns: – ASM Resouce - ASM Instance(s) resource (proxy resource) – Diskgroup - Used for managing/monitoring ASM diskgroups. – DB Resource - Used for monitoring and managing the DB and instances – SCAN Listener - Listener for single client access name, listening on SCAN VIP – Listener - Node listener listening on the Node VIP – Services - Used for monitoring and managing services – ONS - Oracle Notification Service – eONS - Enhanced Oracle Notification Service ( pre 11.2.0.2 ) – GSD - For 9i backward compatibility – GNS (optional) - Grid Naming Service - Performs name resolution Startup Sequence 11gR2.
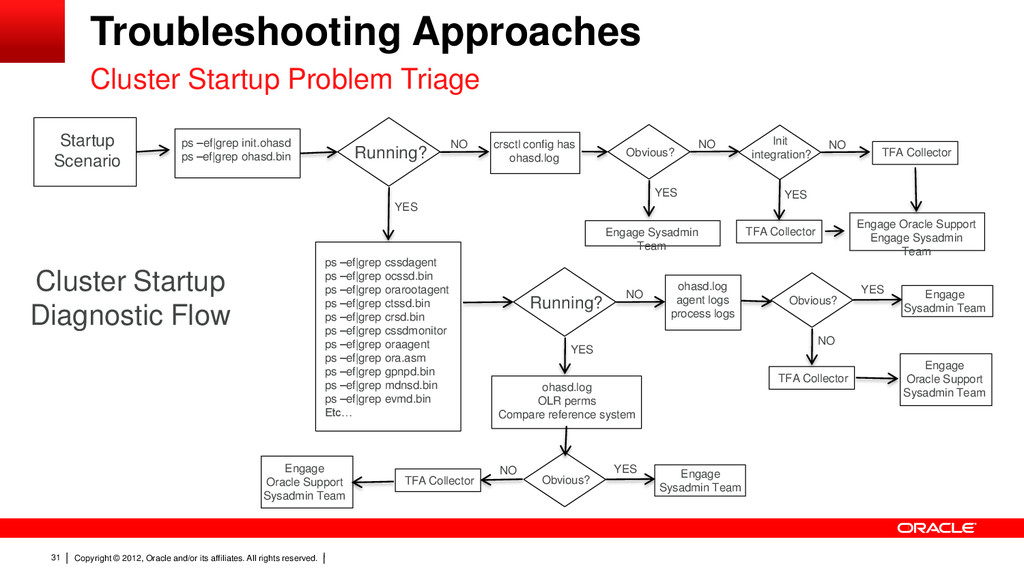
33 Grid Inter-process Communications Daemon (gipc(d)) – Support daemon that enables redundant interconnect usage. This is not HAIP but the daemon that ensures CRS processes know what valid interfaces and paths are available. The CRS processes still use the physical interfaces to connect but make calls to gipc to determine the route – CSSD has it’s own gipc code so does not depend on gipcd right now. – Log is GI_HOME/log/<node>/gipcd/gipcd.log Troubleshooting Approaches Cluster Startup Problem Triage
34 Multicast Domain Name Service Daemon (mDNS(d)) – Used by Grid Plug and Play to locate profiles in the cluster, as well as by GNS to perform name resolution. The mDNS process is a background process on Linux and UNIX and on Windows. – An open-sourced Apple implementation of multicast DNS (a.k.a. “Bonjour”), non-persistent distributed DNS-type cache. – Uses multicast for cache updates on service advertisement arrival/departure. – Advertises/serves on all found node interfaces. – Log is GI_HOME/log/<node>/mdnsd/mdnsd.log Troubleshooting Approaches Cluster Startup Problem Triage
35 Grid Plug ‘n’ play daemon (gpnp(d)) – Provides access to the Grid Plug and Play profile – Coordinates updates to the profile from clients among the nodes of the cluster – Ensures all nodes have the most recent profile – Registers with mdns to advertise profile availability – Log is GI_HOME/log/<node>/gpnpd/gpnpd.log Troubleshooting Approaches Cluster Startup Problem Triage
36 Grid Plug ‘n’ play Profile GPnP Profile is bootstrap info necessary to start forming a cluster (cname/guid, css/asm discovery strings, net connectivity). GPnP Config = xml profile + signing wallet Gpnpd maintains and serves gpnp profile for clients Mdnsd used to publish service information cluster-wide Troubleshooting Approaches Cluster Startup Problem Triage
37 • Grid Plug ‘n’ play Profile • GPnP profile is xml file, readable and editable, but must never be edited. • Protected from unsanctioned alterations by a digital signature (hence a need for signing/verifying wallet). • Contents-neutral, judged by a sequence number. • Profile has no node specifics. Just enough info to join the cluster • GPnP config (profile+wallet) is identical for every peer node (unless updating). Created by installer, managed by gpnpd (cached locally in FS, OLR, cluster-wide in OCR). Troubleshooting Approaches Cluster Startup Problem Triage
38 Grid Plug ‘n’ play CLI Tools – User tools performing indirect gpnp profile changes. crsctl replace discoverystring, oifcfg getif/setif ASM (srvctl or sqlplus changing spfile location, asm disco string) – Script/diag tools only. Unlocked, low-level gpnp manipulations: gpnptool – Not for general use, only with support, yes it’s on google but beware. Troubleshooting Approaches Cluster Startup Problem Triage
40 cssd agent and monitor – Same functionality in both agent and monitor – Functionality of several pre-11.2 daemons consolidated in both OPROCD – system hang OMON – oracle clusterware monitor VMON – vendor clusterware monitor – Run realtime with locked down memory, like CSSD – Provides enhanced stability and diagnosability – Logs are GI_HOME/log/<node>/agent/oracssdagent_root/oracssdagent_root.log GI_HOME/log/<node>/agent/oracssdmonitor_root/oracssdmonitor_root.log Troubleshooting Approaches Cluster Startup Problem Triage
41 cssd agent and monitor – oprocd Now a thread in CSSD agent and monitor processes Integrates functionality of OMON and OPROCD Receives state information from CSSD Decides whether reboot required based on both hang time and CSSD state Troubleshooting Approaches Cluster Startup Problem Triage
42 cssd agent and monitor – oprocd The basic objective of both OPROCD and OMON was to ensure that the perceptions of other nodes was correct – If CSSD failed, other nodes assumed that the node would fail within a certain amount of time and OMON ensured that it would – If the node hung for long enough, other nodes would assume that it was gone and OPROCD would ensure that it was gone The goal of the change is to do this more accurately and avoid false terminations Troubleshooting Approaches Cluster Startup Problem Triage
43 cssd agent and monitor – The local cssdmonitor and agent in 11.2 receive the same state information from their cssd process that remote cssd processes receive. Ensures that the state of the local node as perceived by remote nodes to be accurate. Utilize time before other nodes perceive the local node to be down for purposes such as filesystem sync (to get better diagnostic data) DHB – Disk Heart Beat written to VF periodically, usually 1 per second NHB - Network Heart Beat sent to other nodes periodically, usually 1 per second LHB – Local Heart Beat sent to agent/monitor periodically, usually 1 per second – NHB and LHB done by same thread. Troubleshooting Approaches Cluster Startup Problem Triage
44 Cluster Synchronisation Services – CSS (cssd,agent and monitor) is responsible for Node membership (NM). Important to know state of each node in the cluster. If nodes are not able to communicate correctly to synchronise disk writes corruption may occur. NM determines the health of the nodes in the cluster and determines appropriate action. Group Membership (GM). Clients of cssd that are I/O capable register with cssd to ensure if fencing is required, all I/O capable clients are killed before processing continues. Registration is done through GM. Examples are RDBMS instances registering so that one instance can request the kill of another. Log is GI_HOME/log/<node>/cssd/ocssd.log – Rotation policy 50MB – Retention policy 10 logs Troubleshooting Approaches Cluster Startup Problem Triage
45 Cluster Synchronisation Services – Node Membership Decision based on connectivity information – Disk Heartbeat to Voting File contains info of nodes it can communicate with – The Network Heartbeat contains bitmaps for members and for connected nodes. The Reconfiguration manager uses this info to calculate an optimal sub-cluster – Bitmaps for connectivity and for membership – Does bitwise AND of bitmaps to determine cohort sets Surviving cohort – Cohort with the most nodes – Cohort with lowest node number not in other cohort Troubleshooting Approaches Cluster Startup Problem Triage
46 Cluster Synchronisation Services – Voting File Each node must be able to access a common voting file to issue a disk heartbeat. There should always be an odd number to ensure an intersect if you want to be able to survive loss of voting files. – 1 allows no loss of voting file access. – 3 allows loss of 1 voting file. – 5 allows loss of 2 voting files. When on ASM, requires 3 or 5 failure groups in the disk group for normal or high redundancy respectively. Holds lease information for node numbers, and connection endpoints. Troubleshooting Approaches Cluster Startup Problem Triage
47 Cluster Synchronisation Services – Evictions/Reboots Node eviction due to the missing network heartbeats (NHB) Node eviction due to the missing disk heartbeats Node reboot due to losing access to the majority of voting disks Node reboots due to the node hang or the perceived node hang Node reboots due to the hanging cssd Node reboots due to LMHB group member kill escalated to the node kill Node reboots by IPMI Troubleshooting Approaches Cluster Startup Problem Triage
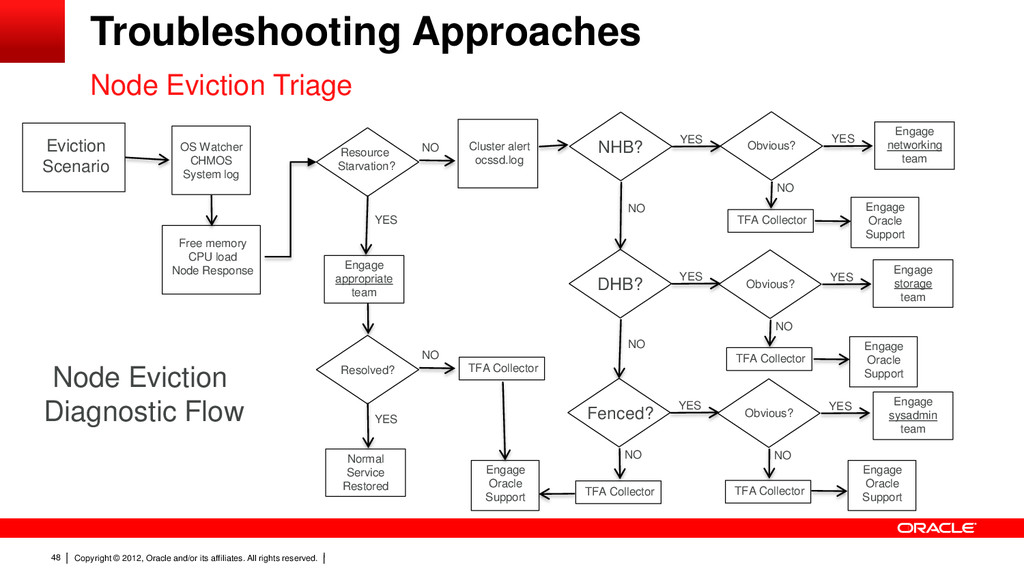
48 Node Eviction Triage Eviction Scenario Cluster alert ocssd.log NHB? Engage networking team YES NO DHB? YES NO Obvious? NO YES TFA Collector Engage Oracle Support Obvious? NO YES TFA Collector Fenced? YES NO Obvious? NO YES TFA Collector TFA Collector Node Eviction Diagnostic Flow Troubleshooting Approaches Resource Starvation? NO Engage Oracle Support Engage sysadmin team Engage Oracle Support Engage storage team OS Watcher CHMOS System log Engage Oracle Support YES Engage appropriate team Resolved? NO YES Normal Service Restored TFA Collector Free memory CPU load Node Response
49 Missing Network Heartbeat (1) ocssd.log from node 1 ===> sending network hearbeats other nodes. Normally, this message is output once every 5 messages (seconds) 2010-08-13 17:00:20.023: [ CSSD][4096109472]clssnmSendingThread: sending status msg to all nodes 2010-08-13 17:00:20.023: [ CSSD][4096109472]clssnmSendingThread: sent 5 status msgs to all nodes ===> The network hearbeat is not received from node 2 (drrac2) for 15 consecutive seconds. ===> This means that 15 network heartbeats are missing and is the first warning (50% threshold). 2010-08-13 17:00:22.818: [ CSSD][4106599328]clssnmPollingThread: node drrac2 (2) at 50% heartbeat fatal, removal in 14.520 seconds 2010-08-13 17:00:22.818: [ CSSD][4106599328]clssnmPollingThread: node drrac2 (2) is impending reconfig, flag 132108, misstime 15480 ===> continuing to send the network heartbeats and log messages once every 5 messages 2010-08-13 17:00:25.023: [ CSSD][4096109472]clssnmSendingThread: sending status msg to all nodes 2010-08-13 17:00:25.023: [ CSSD][4096109472]clssnmSendingThread: sent 5 status msgs to all nodes ===> 75% threhold of missing network heartbeat is reached. This is second warning. 2010-08-13 17:00:29.833: [ CSSD][4106599328]clssnmPollingThread: node drrac2 (2) at 75% heartbeat fatal, removal in 7.500 seconds
50 Missing Network Heartbeat (2) ===> continuing to send the network heartbeats and log messages once every 5 messages 2010-08-13 17:00:30.023: [ CSSD][4096109472]clssnmSendingThread: sending status msg to all nodes 2010-08-13 17:00:30.023: [ CSSD][4096109472]clssnmSendingThread: sent 5 status msgs to all nodes ===> continuing to send the network heartbeats, but the message is logged after 4 messages 2010-08-13 17:00:34.021: [ CSSD][4096109472]clssnmSendingThread: sending status msg to all nodes 2010-08-13 17:00:34.021: [ CSSD][4096109472]clssnmSendingThread: sent 4 status msgs to all nodes ===> Last warning shows that 90% threshold of the missing network heartbeat is reached. ===> The eviction will occur in 2.49 seconds. 2010-08-13 17:00:34.841: [ CSSD][4106599328]clssnmPollingThread: node drrac2 (2) at 90% heartbeat fatal, removal in 2.490 seconds, seedhbimpd 1 ===> Eviction of node 2 (drrac2) started 2010-08-13 17:00:37.337: [ CSSD][4106599328]clssnmPollingThread: Removal started for node drrac2 (2), flags 0x2040c, state 3, wt4c 0 ===> This shows that the node 2 is actively updatig the voting disks 2010-08-13 17:00:37.340: [ CSSD][4085619616]clssnmCheckSplit: Node 2, drrac2, is alive, DHB (1281744040, 1396854) more than disk timeout of 27000 after the last NHB (1281744011, 1367154)
52 Missing Network Heartbeat (4) ocssd.log from node 2: ===> Logging the message to indicate 5 network heartbeats are sent to other nodes 2010-08-13 17:00:26.009: [ CSSD][4062550944]clssnmSendingThread: sending status msg to all nodes 2010-08-13 17:00:26.009: [ CSSD][4062550944]clssnmSendingThread: sent 5 status msgs to all nodes ===> First warning of reaching 50% threshold of missing network heartbeats 2010-08-13 17:00:26.213: [ CSSD][4073040800]clssnmPollingThread: node drrac1 (1) at 50% heartbeat fatal, removal in 14.540 seconds 2010-08-13 17:00:26.213: [ CSSD][4073040800]clssnmPollingThread: node drrac1 (1) is impending reconfig, flag 394254, misstime 15460 ===> Logging the message to indicate 5 network heartbeats are sent to other nodes 2010-08-13 17:00:31.009: [ CSSD][4062550944]clssnmSendingThread: sending status msg to all nodes 2010-08-13 17:00:31.009: [ CSSD][4062550944]clssnmSendingThread: sent 5 status msgs to all nodes ===> Second warning of reaching 75% threshold of missing network heartbeats 2010-08-13 17:00:33.227: [ CSSD][4073040800]clssnmPollingThread: node drrac1 (1) at 75% heartbeat fatal, removal in 7.470 seconds
53 Missing Network Heartbeat (5) ===> Logging the message to indicate 4 network heartbeats are sent 2010-08-13 17:00:35.009: [ CSSD][4062550944]clssnmSendingThread: sending status msg to all nodes 2010-08-13 17:00:35.009: [ CSSD][4062550944]clssnmSendingThread: sent 4 status msgs to all nodes ===> Third warning of reaching 90% threshold of missing network heartbeats 2010-08-13 17:00:38.236: [ CSSD][4073040800]clssnmPollingThread: node drrac1 (1) at 90% heartbeat fatal, removal in 2.460 seconds, seedhbimpd 1 ===> Logging the message to indicate 5 network heartbeats are sent to other nodes 2010-08-13 17:00:40.008: [ CSSD][4062550944]clssnmSendingThread: sending status msg to all nodes 2010-08-13 17:00:40.009: [ CSSD][4062550944]clssnmSendingThread: sent 5 status msgs to all nodes ===> Eviction started for node 1 (drrac1) 2010-08-13 17:00:40.702: [ CSSD][4073040800]clssnmPollingThread: Removal started for node drrac1 (1), flags 0x6040e, state 3, wt4c 0 ===> Node 1 is actively updating the voting disk, so this is a split brain condition 2010-08-13 17:00:40.706: [ CSSD][4052061088]clssnmCheckSplit: Node 1, drrac1, is alive, DHB (1281744036, 1243744) more than disk timeout of 27000 after the last NHB (1281744007, 1214144) 2010-08-13 17:00:40.706: [ CSSD][4052061088]clssnmCheckDskInfo: My cohort: 2 2010-08-13 17:00:40.707: [ CSSD][4052061088]clssnmCheckDskInfo: Surviving cohort: 1
54 Missing Network Heartbeat (6) ===> Node 2 is aborting itself to resolve the split brain and ensure the cluster integrity 2010-08-13 17:00:40.707: [ CSSD][4052061088](:CSSNM00008:)clssnmCheckDskInfo: Aborting local node to avoid splitbrain. Cohort of 1 nodes with leader 2, drrac2, is smaller than cohort of 1 nodes led by node 1, drrac1, based on map type 2 2010-08-13 17:00:40.707: [ CSSD][4052061088]################################### 2010-08-13 17:00:40.707: [ CSSD][4052061088]clssscExit: CSSD aborting from thread clssnmRcfgMgrThread 2010-08-13 17:00:40.707: [ CSSD][4052061088]###################################
55 Missing Network Heartbeat (7) Observation 1. Both nodes reported missing heartbeats at the same time 2. Both nodes sent heartbeats to other nodes all the time 3. Node 2 aborted itself to resolve split brain Conclusion 1. This is likely a network problem 2. Check OSWatcher output (netstat and traceroute) 3. Check CHMOS 4. Check system log
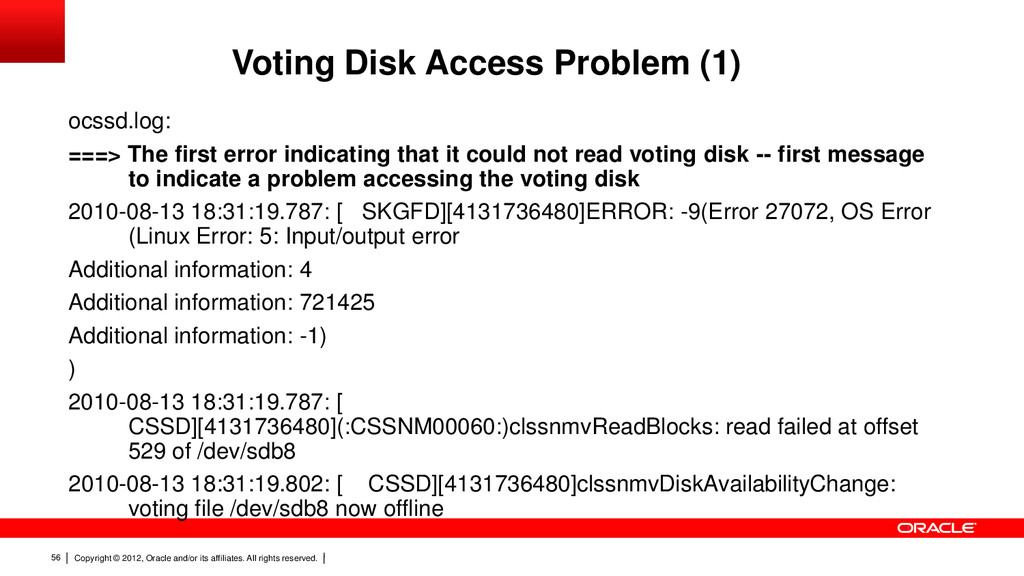
56 Voting Disk Access Problem (1) ocssd.log: ===> The first error indicating that it could not read voting disk -- first message to indicate a problem accessing the voting disk 2010-08-13 18:31:19.787: [ SKGFD][4131736480]ERROR: -9(Error 27072, OS Error (Linux Error: 5: Input/output error Additional information: 4 Additional information: 721425 Additional information: -1) ) 2010-08-13 18:31:19.787: [ CSSD][4131736480](:CSSNM00060:)clssnmvReadBlocks: read failed at offset 529 of /dev/sdb8 2010-08-13 18:31:19.802: [ CSSD][4131736480]clssnmvDiskAvailabilityChange: voting file /dev/sdb8 now offline
57 Voting Disk Access Problem (2) ====> The error message that shows a problem accessing the voting disk repeats once every 4 seconds 2010-08-13 18:31:23.782: [ CSSD][150477728]clssnmvDiskOpen: Opening /dev/sdb8 2010-08-13 18:31:23.782: [ SKGFD][150477728]Handle 0xf43fc6c8 from lib :UFS:: for disk :/dev/sdb8: 2010-08-13 18:31:23.782: [ CLSF][150477728]Opened hdl:0xf4365708 for dev:/dev/sdb8: 2010-08-13 18:31:23.787: [ SKGFD][150477728]ERROR: -9(Error 27072, OS Error (Linux Error: 5: Input/output error Additional information: 4 Additional information: 720913 Additional information: -1) ) 2010-08-13 18:31:23.787: [ CSSD][150477728](:CSSNM00060:)clssnmvReadBlocks: read failed at offset 17 of /dev/sdb8
58 Voting Disk Access Problem (3) ====> The last error that shows a problem accessing the voting disk. ====> Note that the last message is 200 seconds after the first message ====> because the long disktimeout is 200 seconds 2010-08-13 18:34:37.423: [ CSSD][150477728]clssnmvDiskOpen: Opening /dev/sdb8 2010-08-13 18:34:37.423: [ CLSF][150477728]Opened hdl:0xf4336530 for dev:/dev/sdb8: 2010-08-13 18:34:37.429: [ SKGFD][150477728]ERROR: -9(Error 27072, OS Error (Linux Error: 5: Input/output error Additional information: 4 Additional information: 720913 Additional information: -1) ) 2010-08-13 18:34:37.429: [ CSSD][150477728](:CSSNM00060:)clssnmvReadBlocks: read failed at offset 17 of /dev/sdb8
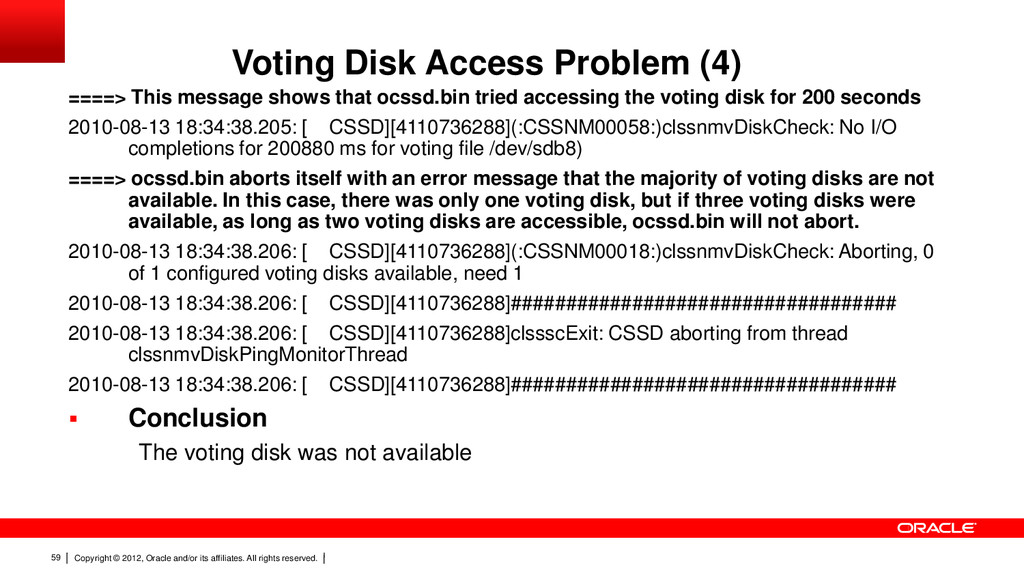
59 Voting Disk Access Problem (4) ====> This message shows that ocssd.bin tried accessing the voting disk for 200 seconds 2010-08-13 18:34:38.205: [ CSSD][4110736288](:CSSNM00058:)clssnmvDiskCheck: No I/O completions for 200880 ms for voting file /dev/sdb8) ====> ocssd.bin aborts itself with an error message that the majority of voting disks are not available. In this case, there was only one voting disk, but if three voting disks were available, as long as two voting disks are accessible, ocssd.bin will not abort. 2010-08-13 18:34:38.206: [ CSSD][4110736288](:CSSNM00018:)clssnmvDiskCheck: Aborting, 0 of 1 configured voting disks available, need 1 2010-08-13 18:34:38.206: [ CSSD][4110736288]################################### 2010-08-13 18:34:38.206: [ CSSD][4110736288]clssscExit: CSSD aborting from thread clssnmvDiskPingMonitorThread 2010-08-13 18:34:38.206: [ CSSD][4110736288]################################### Conclusion The voting disk was not available
60 Cluster Time Synchronisation Services daemon – Provides time management in a cluster for Oracle. Observer mode when Vendor time synchronisation s/w is found – Logs time difference to the CRS alert log Active mode when no Vendor time sync s/w is found Node Eviction Triage Troubleshooting Approaches
61 Cluster Ready Services Daemon – The CRSD daemon is primarily responsible for maintaining the availability of application resources, such as database instances. CRSD is responsible for starting and stopping these resources, relocating them when required to another node in the event of failure, and maintaining the resource profiles in the OCR (Oracle Cluster Registry). In addition, CRSD is responsible for overseeing the caching of the OCR for faster access, and also backing up the OCR. – Log file is GI_HOME/log/<node>/crsd/crsd.log Rotation policy 10MB Retention policy 10 logs Node Eviction Triage Troubleshooting Approaches
62 CRSD oraagent – CRSD’s oraagent manages all database, instance, service and diskgroup resources node listeners SCAN listeners, and ONS – If the Grid Infrastructure owner is different from the RDBMS home owner then you would have 2 oraagents each running as one of the installation owners. The database, and service resources would be managed by the RDBMS home owner and other resources by the Grid Infrastructure home owner. – Log file is GI_HOME/log/<node>/agent/crsd/oraagent_<user>/oraagent_<user>.log Node Eviction Triage Troubleshooting Approaches
64 Agents – CRS manages applications when they are registered as a resources – runs all resource-specific commands through an entity called an agent. – Agent contains Agent framework – library to plugin user code User code – actual resource management code Node Eviction Triage Troubleshooting Approaches
65 Agent entry points – START – STOP – CHECK: If it notices any state change during this action, then the agent framework notifies Oracle Clusterware about the change in the state of the specific resource. – CLEAN: The CLEAN entry point acts whenever there is a need to clean up a resource. It is a non-graceful operation that is invoked when users must forcefully terminate a resource. This command cleans up the resource-specific environment so that the resource can be restarted. – ABORT: If any of the other entry points hang, the agent framework calls the ABORT entry point to abort the ongoing action. If the agent developer does not supply an abort function, then the agent framework exits the agent program. Node Eviction Triage Troubleshooting Approaches
66 Agent return codes – Check entry must return one of the following return codes: ONLINE UNPLANNED_OFFLINE – Target=online, may be recovered failed over PLANNED_OFFLINE UNKNOWN – Cannot determine, if previously online, partial then monitor PARTIAL – Some of a resources services are available. Instance up but not open. FAILED – Requires clean action Node Eviction Triage Troubleshooting Approaches
67 CRSD Resources States – ONLINE – OFFLINE – UNKNOWN – INTERMEDIATE Could be we are not sure but previously it was online Maybe the resource failed over but is not where it needs to be, such as a node vip. May be a database is mounted but not open Node Eviction Triage Troubleshooting Approaches
70 Clusterware trace files – Clusterware daemon logs are all under <GRID_HOME>/log/<nodename> – alert<NODENAME>.log - look here first for most clusterware issues – The cfgtoollogs dir under <GRID_HOME> and $ORACLE_BASE contains other important logfiles. Specifically for rootcrs.pl and configuration assistants like ASMCA, etc... – ASM logs live under $ORACLE_BASE/diag/asm/+asm/<ASM Instance Name>/trace – Tracefile Analyzer Collector (TFA) should be considered for targeted tracefile collection from all nodes of a cluster. Node Eviction Triage Troubleshooting Approaches
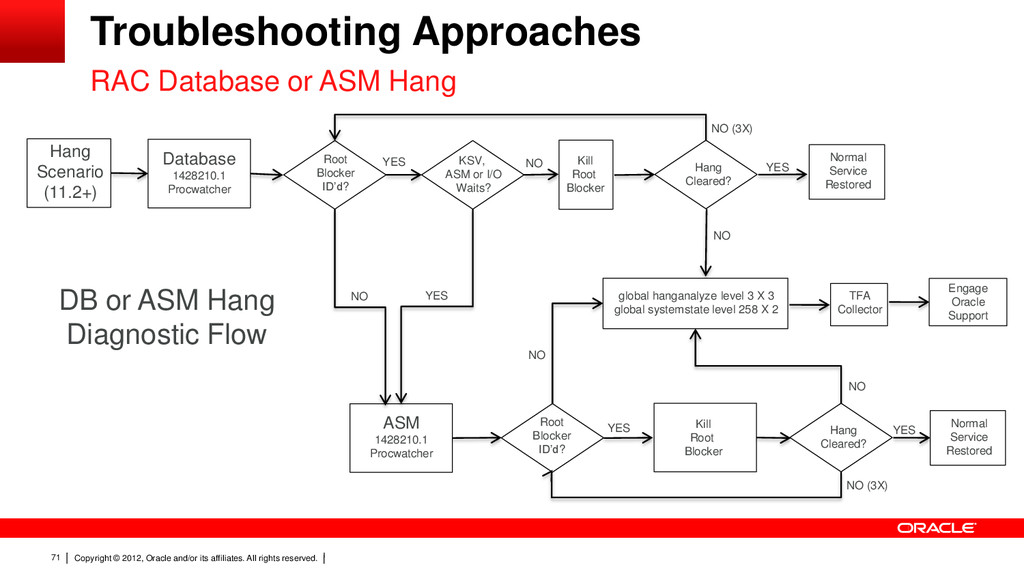
71 RAC Database or ASM Hang Hang Scenario (11.2+) Database 1428210.1 Procwatcher Root Blocker ID’d? Normal Service Restored YES NO Kill Root Blocker Hang Cleared? NO (3X) YES TFA Collector Engage Oracle Support DB or ASM Hang Diagnostic Flow Troubleshooting Approaches NO global hanganalyze level 3 X 3 global systemstate level 258 X 2 ASM 1428210.1 Procwatcher Root Blocker ID’d? YES NO Kill Root Blocker Hang Cleared? NO (3X) YES NO Normal Service Restored KSV, ASM or I/O Waits? YES NO
73 Tools To Help You Trace File Analyzer Collector Framework (TFA) • Goals • Improved comprehensive first failure diagnostics • Efficient collection, packaging and transfer of data for Customers • Reduce pings between Customers and Oracle • Reduce time to triage problems • Backend efficiencies for Support • Operate independent of clusterware • Support 10.2, 11.1, 11.2 and above • Approach • Collect for all relevant components (OS, Grid Infrastructure, RDBMS) • One command to collect all required information • Prune large files based on temporal criteria • Collect time relevant IPS (incident) packages on RAC nodes • Collect time relevant CHMOS, OSWatcher, ProcWatcher data on RAC nodes • Source • TFA Collector - The Preferred Tool for Automatic or ADHOC Diagnostic Gathering Across All Cluster Nodes [ID 1513912.1]
75 Tools To Help You ProcWatcher • Goals • Improved first failure diagnostics for • Database, ASM, Clusterware processes • Session level hangs or Severe database or ASM contention • Instance evictions, DRM timeouts • Database or Clusterware processes stuck or consuming high CPU • ORA-4031, ORA-4030 error diagnosis • Approach • Clusterwide deployment • Runs as daemon, activated by suspected hangs to collect diagnostic data • Simple interface • Very flexible configuration • Lightweight resource footprint • TFA Collector is Procwatcher-aware • Source • Procwatcher: Script to Monitor and Examine Oracle DB and Clusterware Processes [ID 459694.1] • Troubleshooting Database Contention With V$Wait_Chains [ID 1428210.1]
76 Tools To Help You Cluster Health Monitor – OS (CHMOS) • Goals • Improved first failure OS diagnostics for • Node evictions • Severe resource contention • Other scenarios where OS stats might be helpful to Support • Policy managed database heuristics • Approach • Installed by default in 11.2.0.3 and higher • Integrated into clusterware for high availability • Data for cluster nodes stored in a single master repository • Runs in real time scheduling class • Lightweight resource footprint • TFA Collector is CHMOS-aware • Source • Built into 11.2.0.3 and above • Prior to 11.2.0.3 see Cluster Health Monitor (CHM) FAQ [ID 1328466.1] for platform and version support
77 Tools To Help You OS Watcher Black Box (oswbb) • Goals • Improved first failure OS diagnostics for • Node evictions • Severe resource contention • Other scenarios where OS stats might be helpful to Support • Approach • Simple installation and configuration • Operates independent of clusterware • Data stored locally on each node • Flexible snapshot interval and retention policies • Lightweight resource footprint • Uses standard OS utilities • TFA Collector is oswbb-aware • Source • OS Watcher Black Box User's Guide [ID 1531223.1]
78 Tools To Help You oratop – near real-time monitoring of databases • Goals • Improved first failure OS diagnostics for database contention issues • Near real-time monitoring of database performance metrics • Familiar character-based interface similar to OS top utility • Approach • Simple installation and configuration • Operates on Linux only but supports other platforms via TNS connections • Supports RAC or single instance databases • One console monitors entire database • One console per database • Batch mode operation redirects metrics to file similar to OS Watcher • Compliments OS Watcher with database metrics • Lightweight resource footprint • TFA Collector is oratop-aware • Source • oratop - utility for near real-time monitoring of databases, RAC and Single Instance [ID 1500864.1]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}