Detection Unlike image classification, detection requires localizing objects within an image Deep CNNs have very large receptive fields, which makes precise localization very challenging Problem Two: Deep networks need large dataset to train
architecture Instead of 1000 ImageNet classes, want N object classes + background (N+1 classes) Need to reinitialize the soft-max layer Fine-tuning using Region Proposals Keep training model using positive / negative regions from detection images This time, use Detection Datasets (VOC, ILCVRC, COC, etc.)
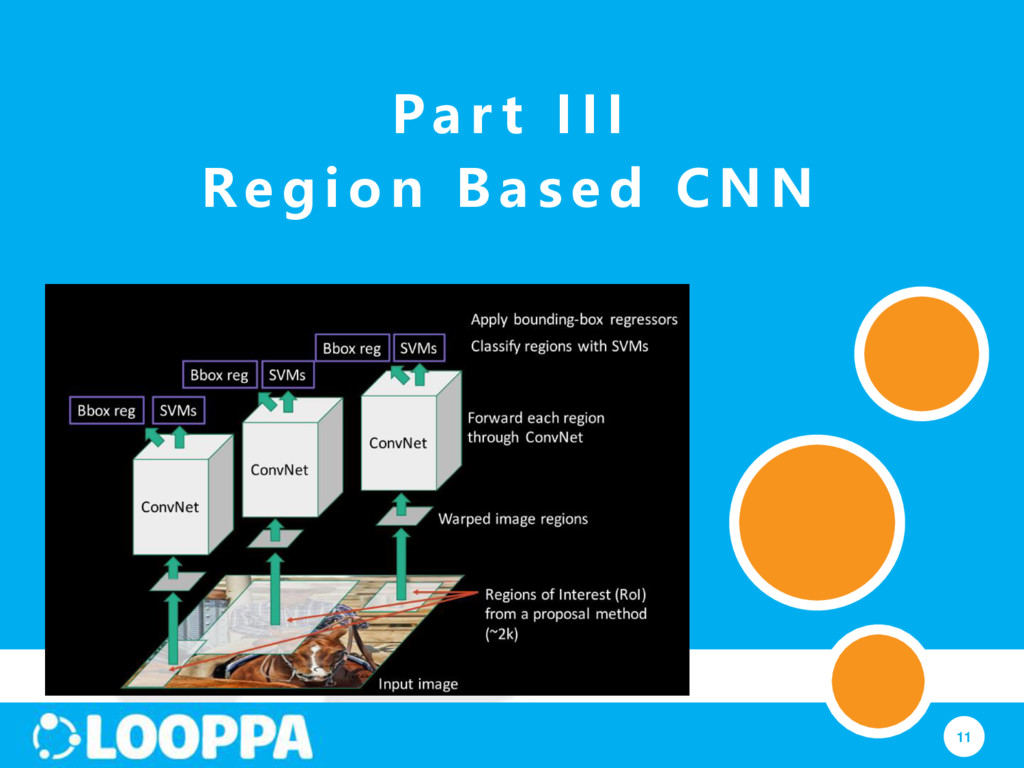
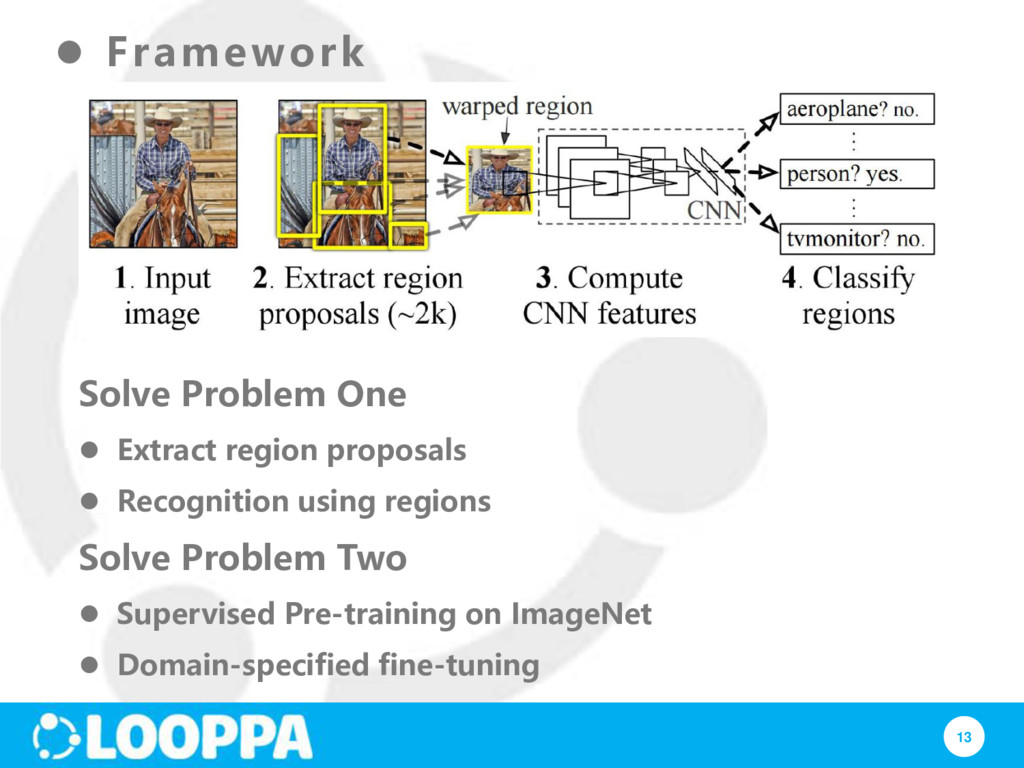
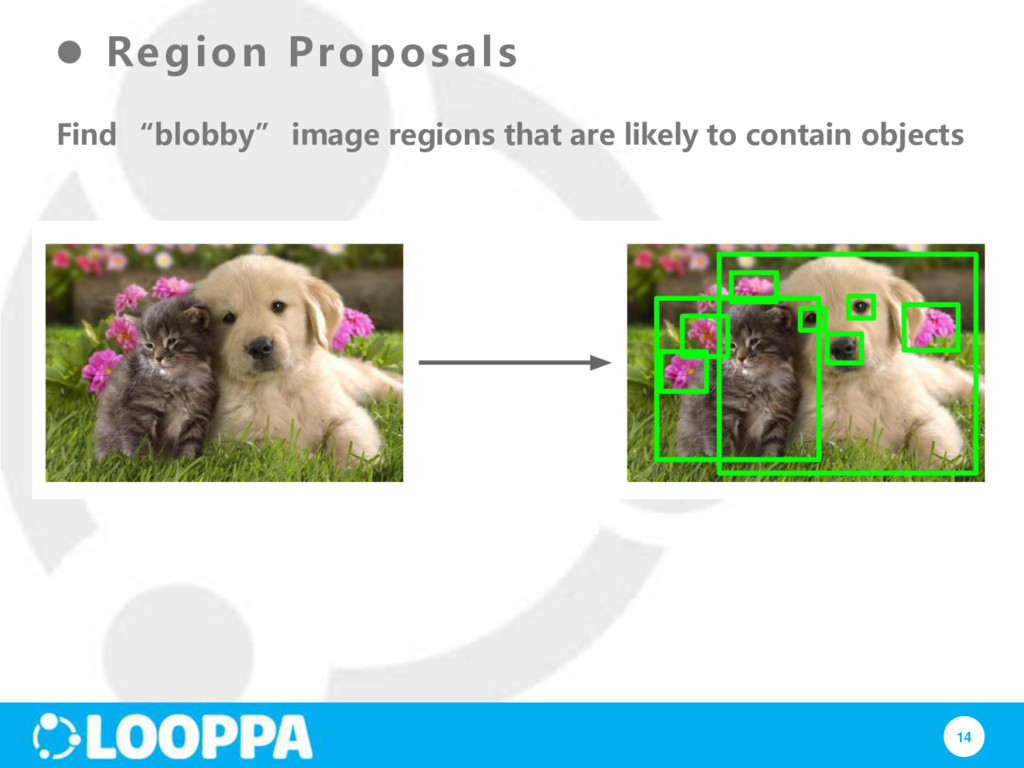
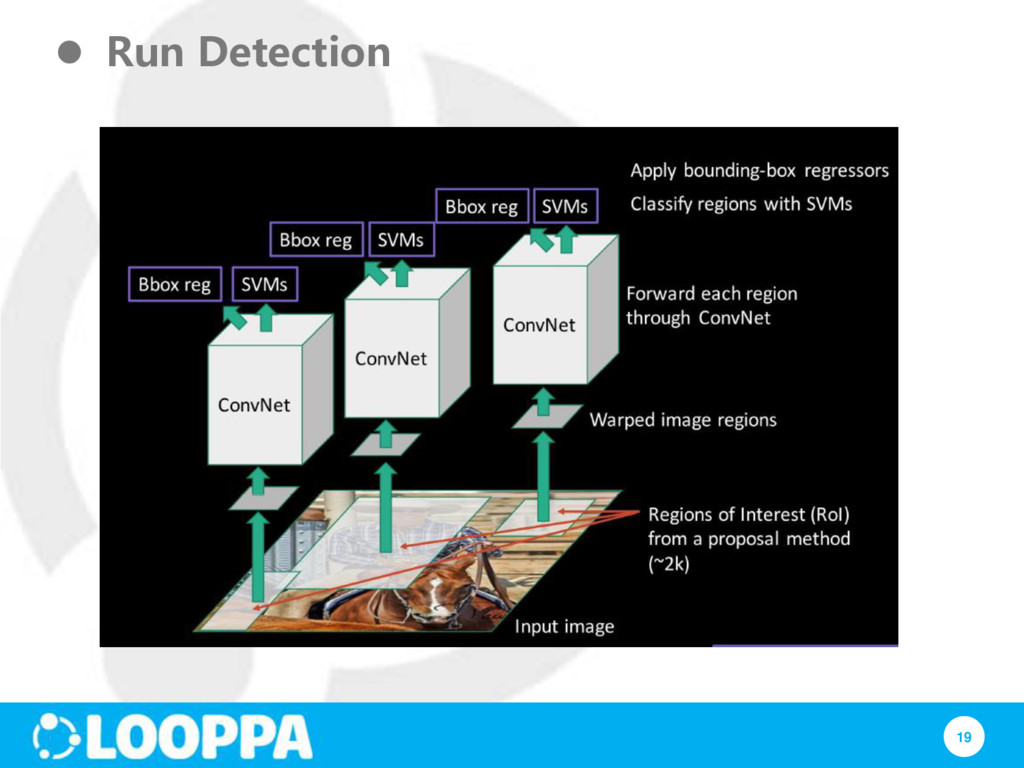
let us test it! Step 1: Extract region proposals for all images Step 2: (for each region) run through CNN, save pool5 features Step 3: use binary SVM to classify region features (WHY NOT just use soft-max) Step 5: bounding box regression: For each class, train a linear regression model to make up for “slightly wrong” proposals
multi-stage pipeline: RCNN⟶SVMs⟶bounding-box regression Training is expensive in space and time CNN features are stored for use of training SVMs and regression ~200GB disk place for PASCAL dataset! Object detection is slow: features are extracted from each object proposal 47s / image on a GPU!
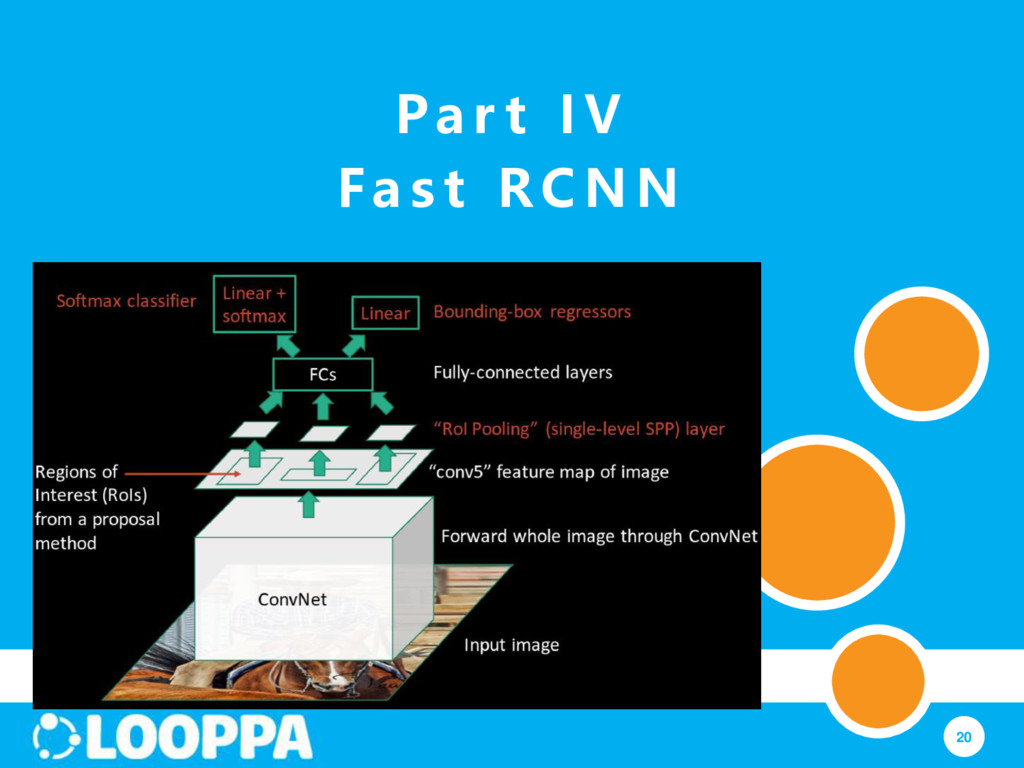
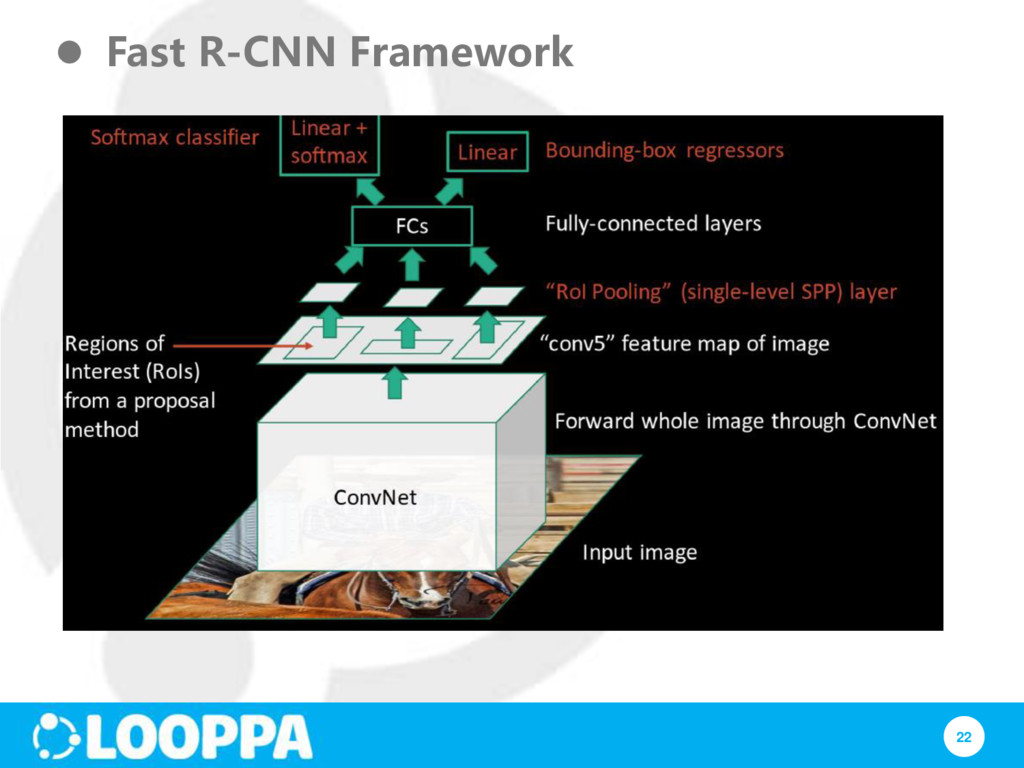
ROI 1. Soft-max probabilities for classification 2. Per-class bounding-box regression offsets 1st term: traditional cross-entropy loss for soft-max 2nd term: error between predicted and true bounding-box
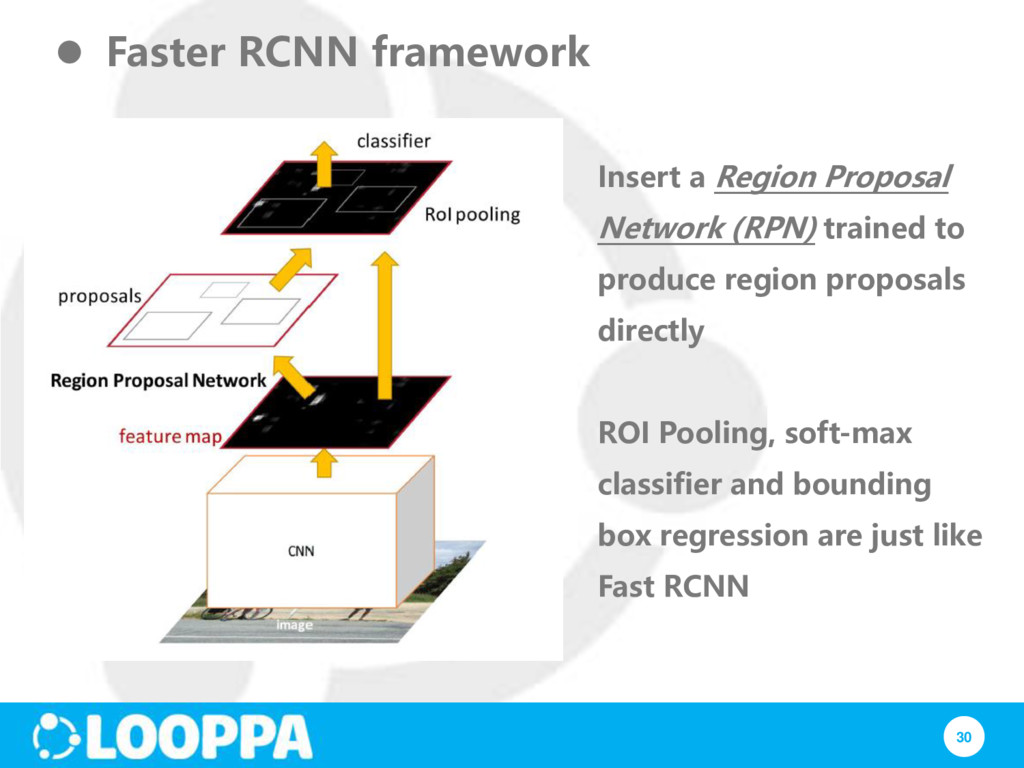
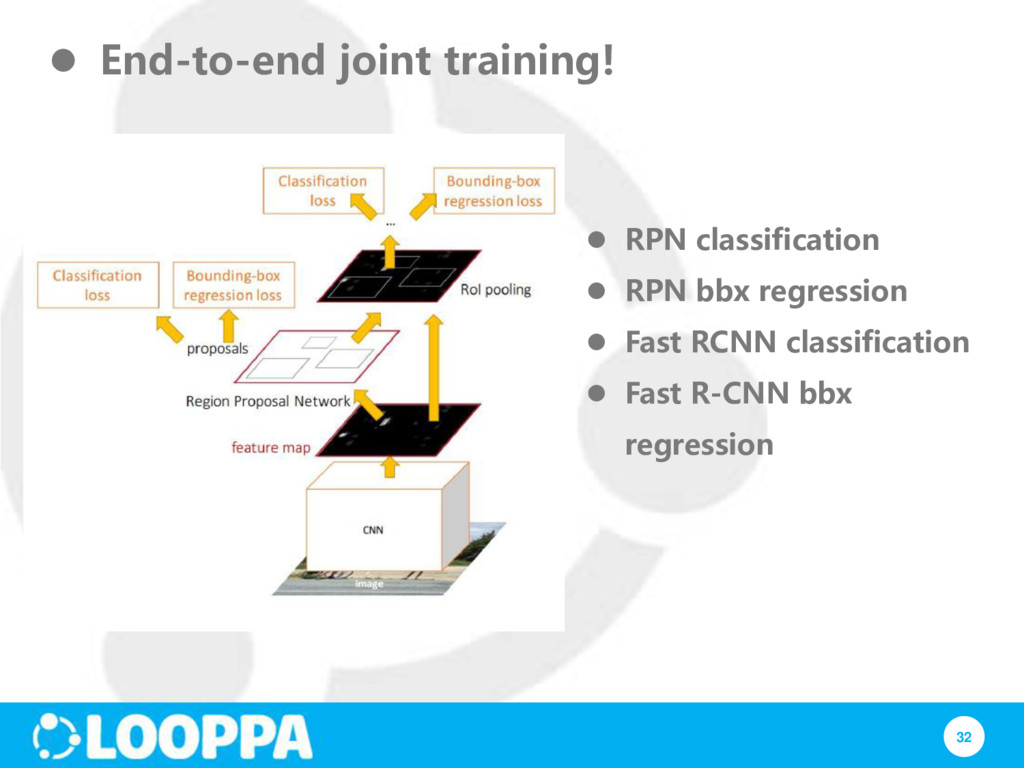
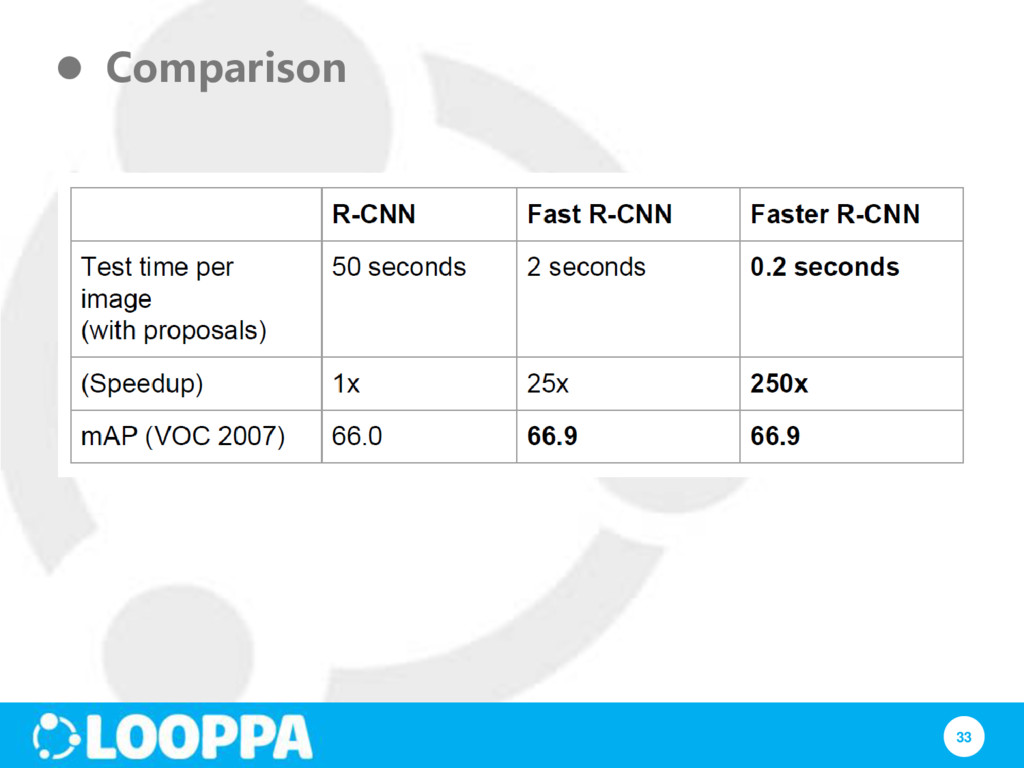
RCNN problem #1: Training is a multi-stage pipeline RCNN problem #2: Training is expensive in space and time Faster RCNN: end-to-end training; no need to store features
#3: Object detection is slow because features are extracted from each object proposal Fast RCNN: just run the whole image through CNN; regions are extracted from feature map
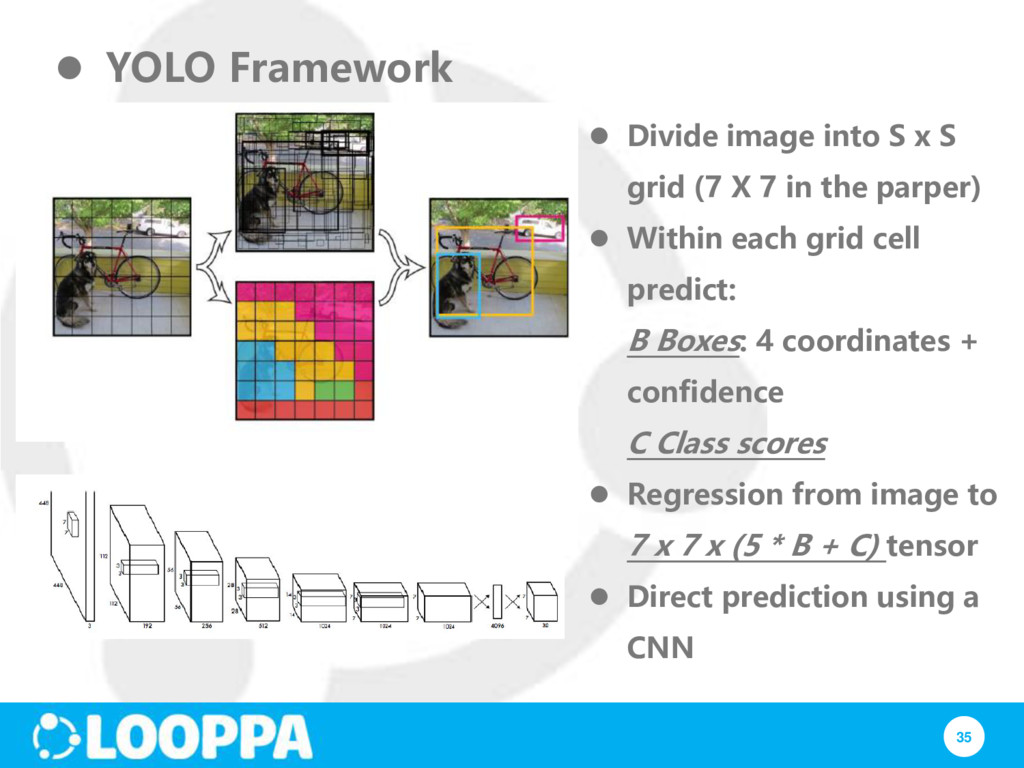
S grid (7 X 7 in the parper) Within each grid cell predict: B Boxes: 4 coordinates + confidence C Class scores Regression from image to 7 x 7 x (5 * B + C) tensor Direct prediction using a CNN
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}