◦ スケール依存の軽減:モデルサイズを用いずツール・手続き・環境で性能向上 Earth AIの例 AIエージェントがモデルAPIを活用 思考・計画・実行・修正をループ Aaron Bell et al. (2025), “Earth AI: Unlocking Geospatial Insights with Foundation Models and Cross-Modal Reasoning”, arXiv:2510.18318. より引用
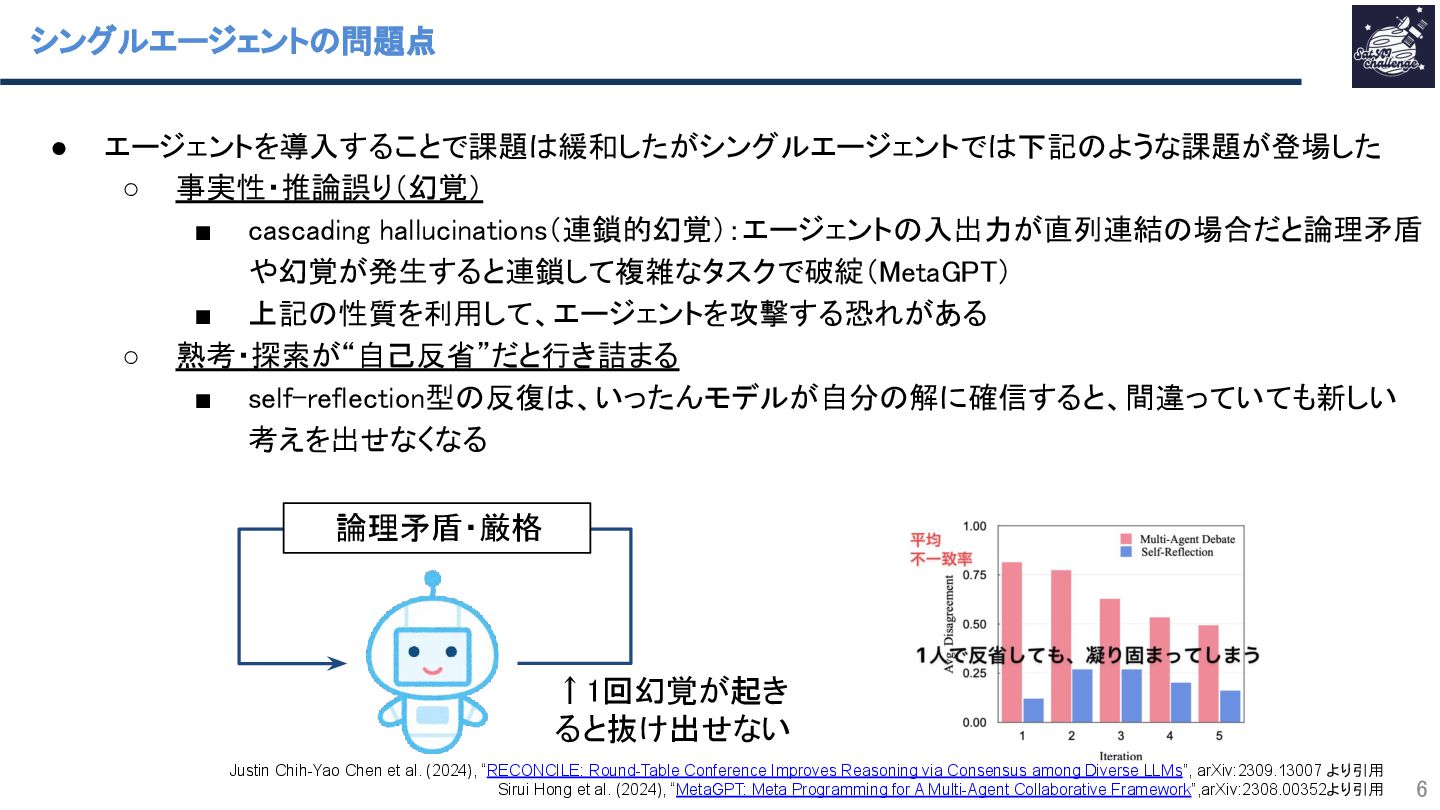
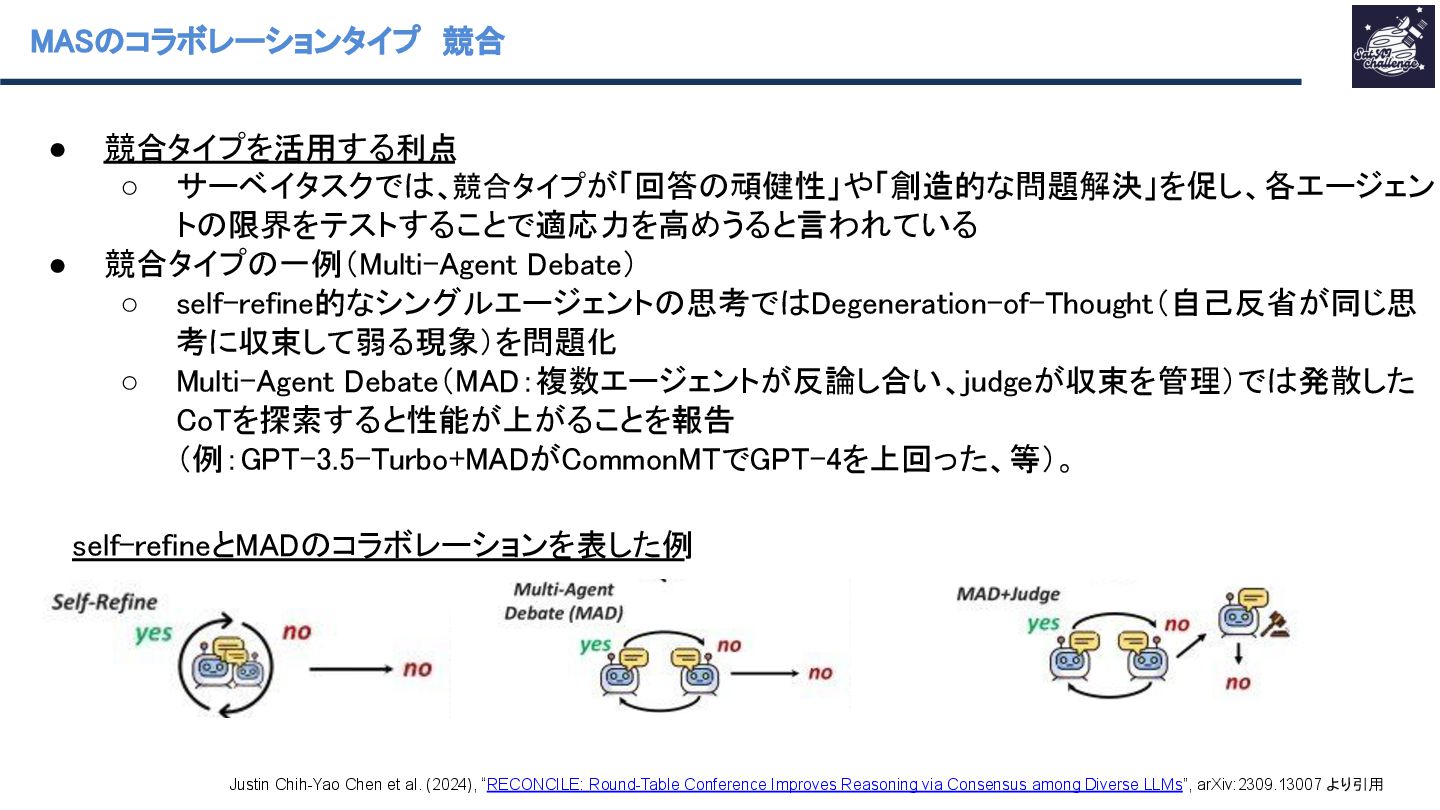
や幻覚が発生すると連鎖して複雑なタスクで破綻(MetaGPT) ▪ 上記の性質を利用して、エージェントを攻撃する恐れがある ◦ 熟考・探索が“自己反省”だと行き詰まる ▪ self-reflection型の反復は、いったんモデルが自分の解に確信すると、間違っていても新しい 考えを出せなくなる 論理矛盾・厳格 ↑1回幻覚が起き ると抜け出せない Justin Chih-Yao Chen et al. (2024), “RECONCILE: Round-Table Conference Improves Reasoning via Consensus among Diverse LLMs”, arXiv:2309.13007 より引用 Sirui Hong et al. (2024), “MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework”,arXiv:2308.00352より引用
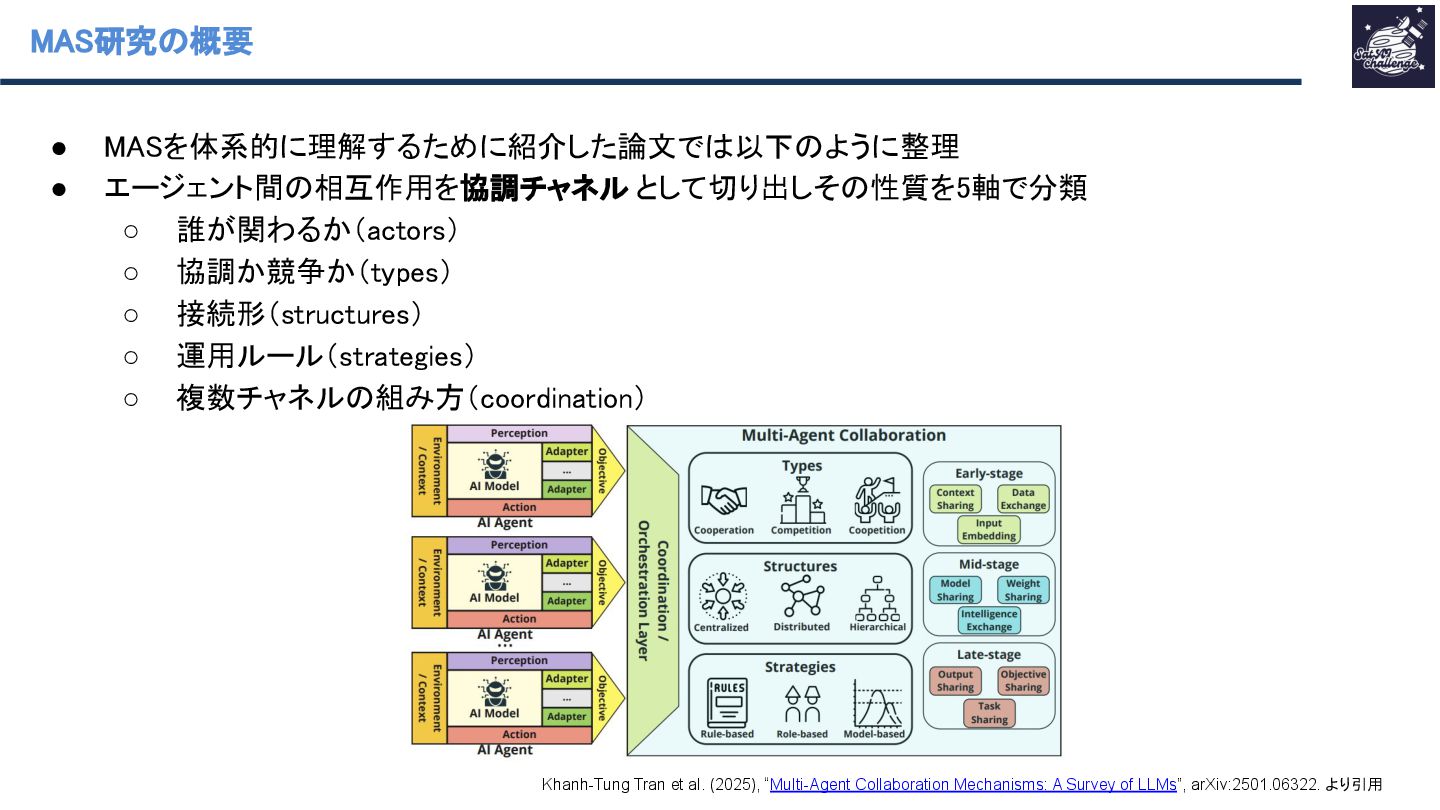
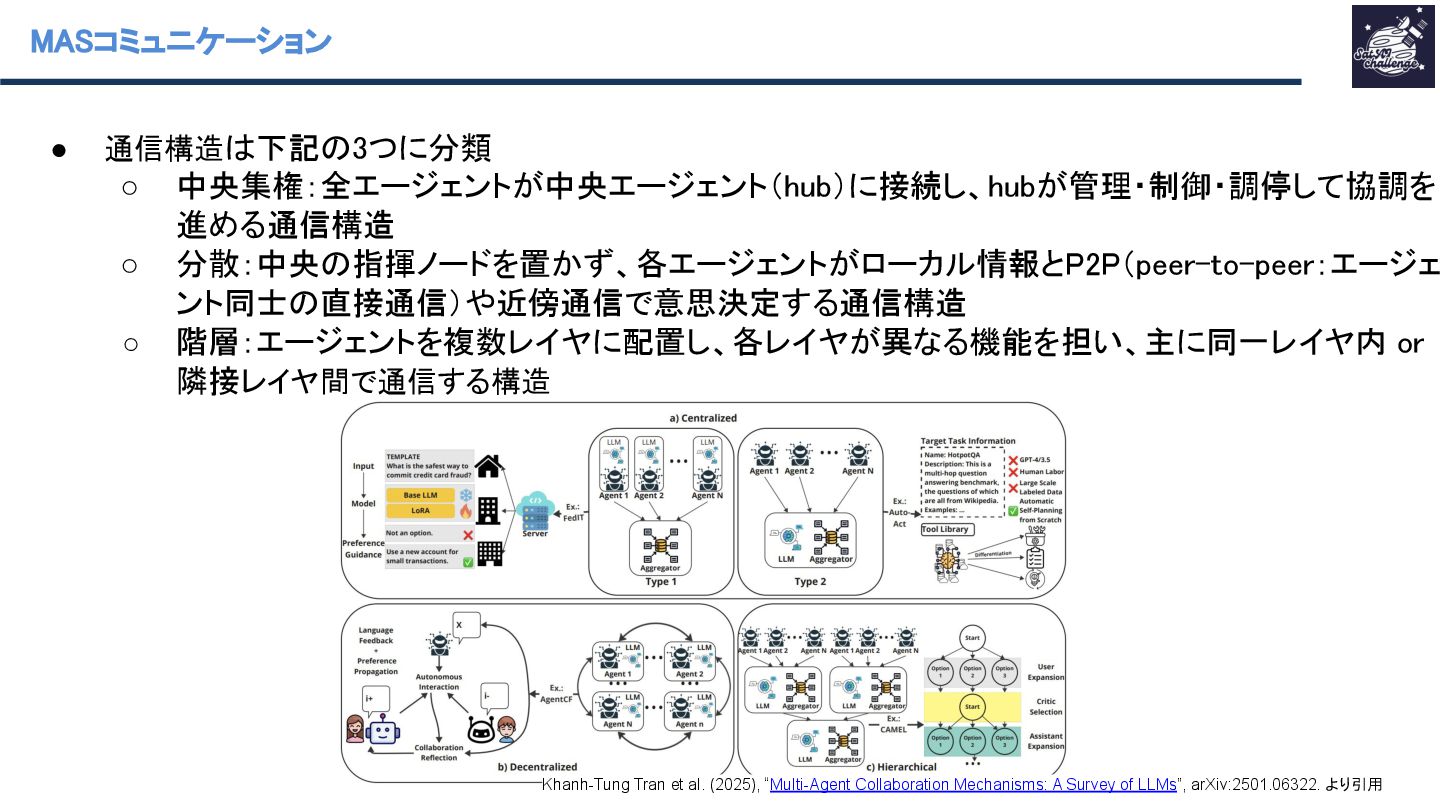
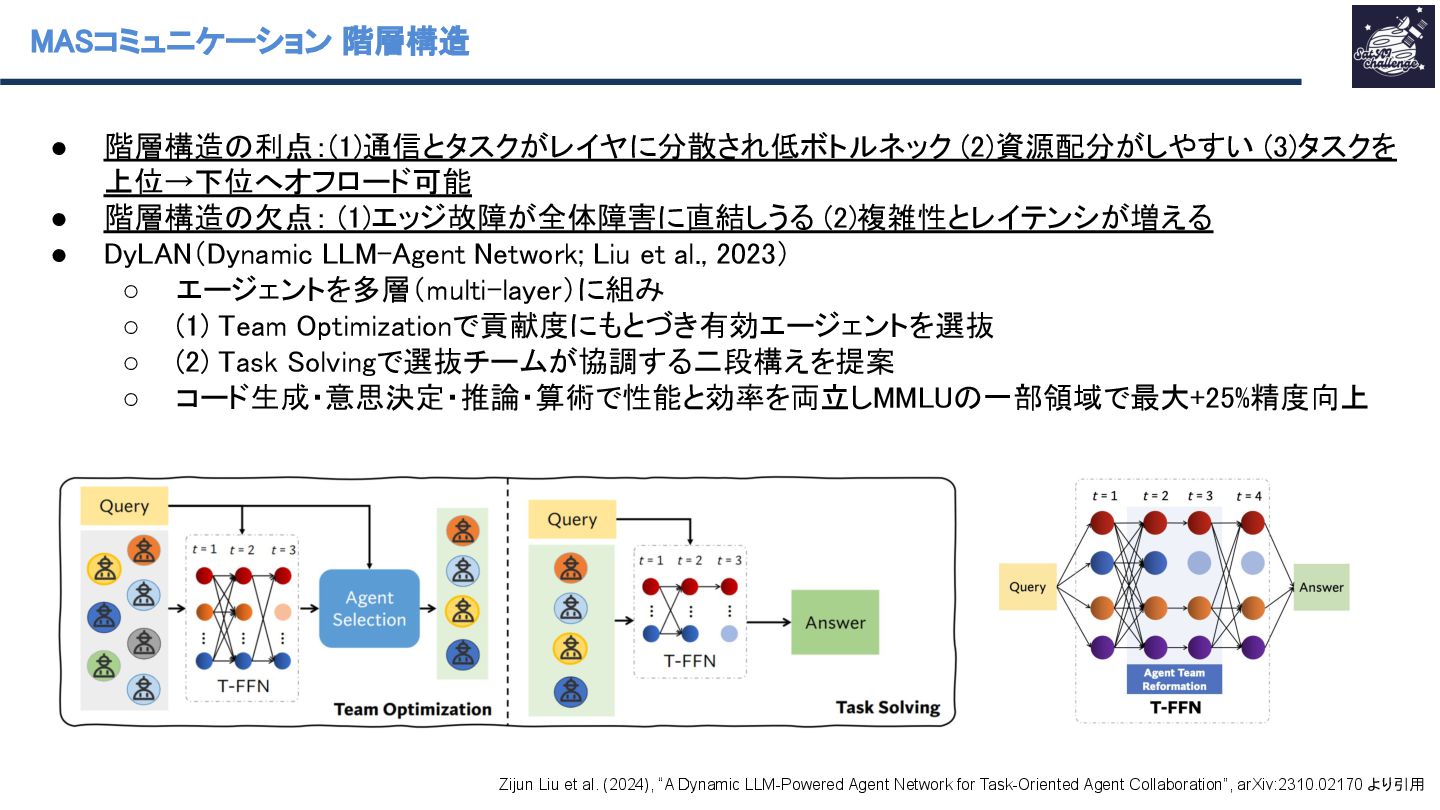
◦ 階層:エージェントを複数レイヤに配置し、各レイヤが異なる機能を担い、主に同一レイヤ内 or 隣接レイヤ間で通信する構造 Khanh-Tung Tran et al. (2025), “Multi-Agent Collaboration Mechanisms: A Survey of LLMs”, arXiv:2501.06322. より引用
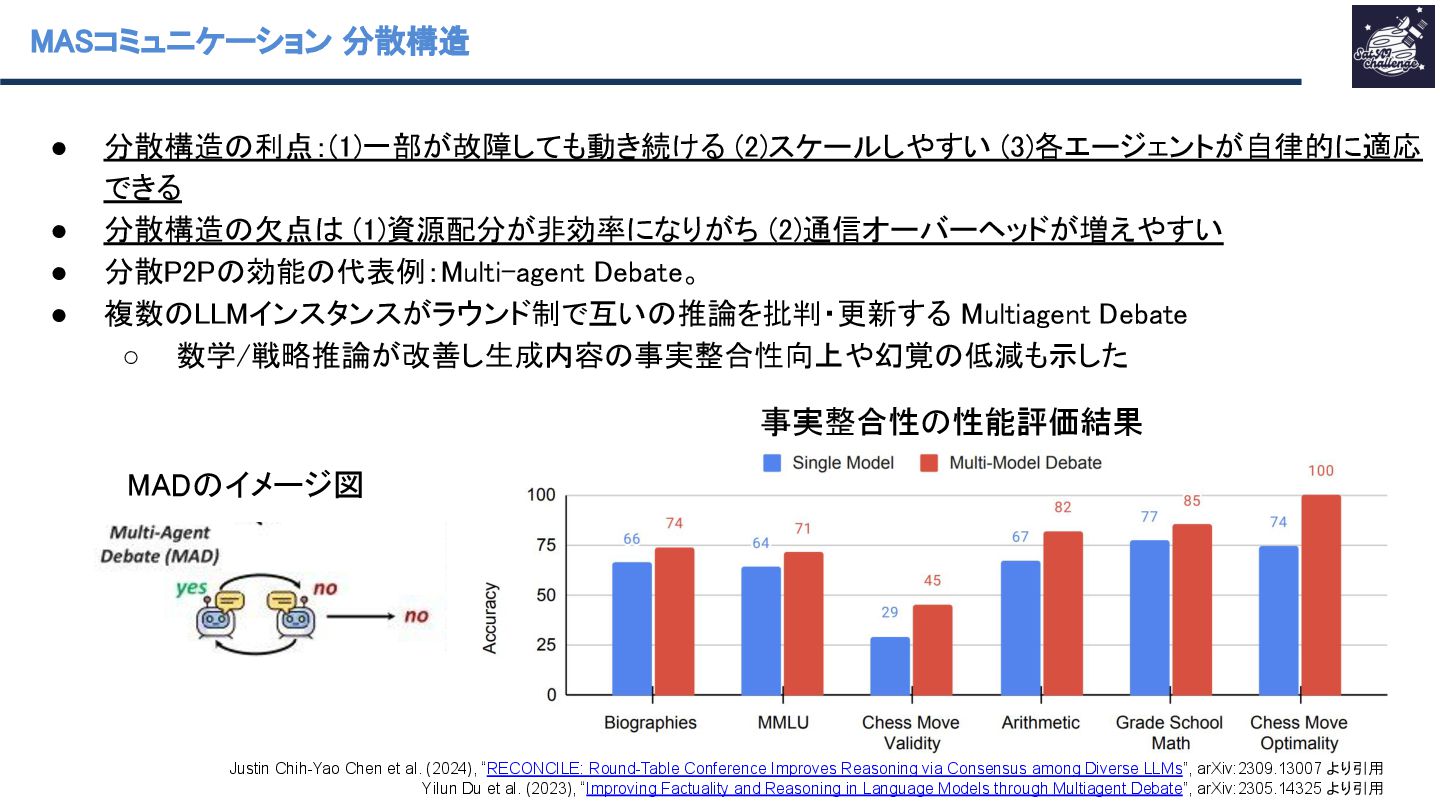
(1)資源配分が非効率になりがち (2)通信オーバーヘッドが増えやすい • 分散P2Pの効能の代表例:Multi-agent Debate。 • 複数のLLMインスタンスがラウンド制で互いの推論を批判・更新する Multiagent Debate ◦ 数学/戦略推論が改善し生成内容の事実整合性向上や幻覚の低減も示した Justin Chih-Yao Chen et al. (2024), “RECONCILE: Round-Table Conference Improves Reasoning via Consensus among Diverse LLMs”, arXiv:2309.13007 より引用 Yilun Du et al. (2023), “Improving Factuality and Reasoning in Language Models through Multiagent Debate”, arXiv:2305.14325 より引用 MADのイメージ図 事実整合性の性能評価結果
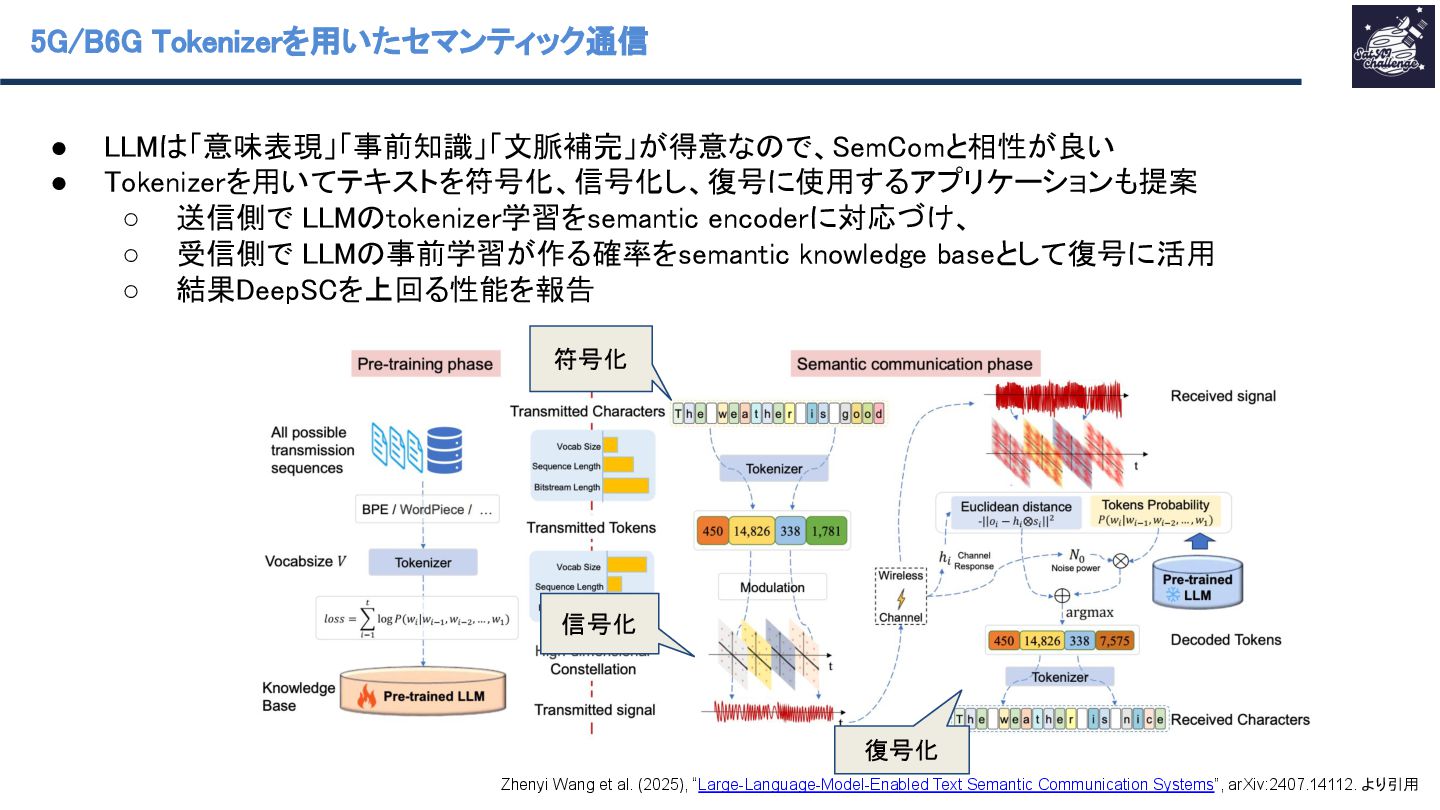
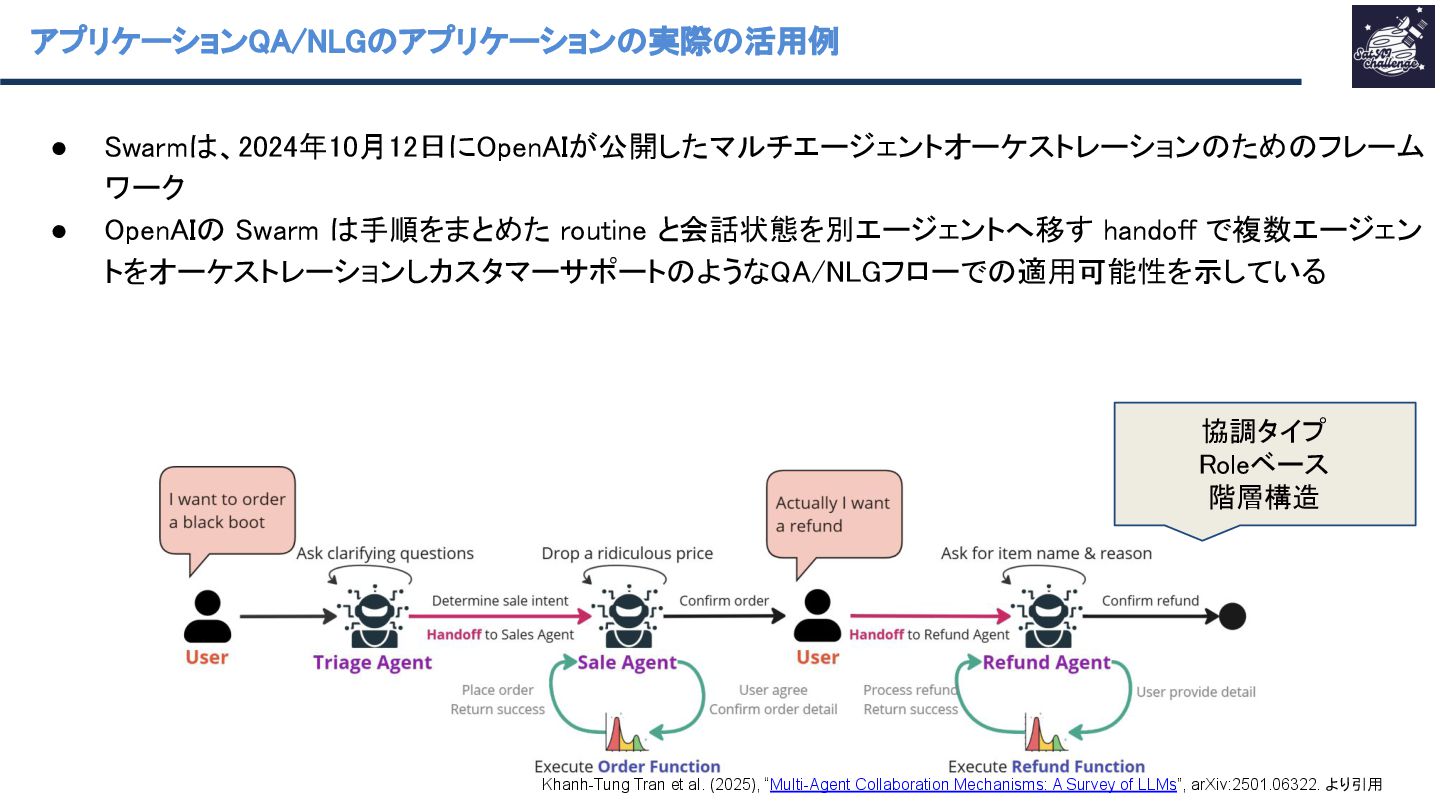
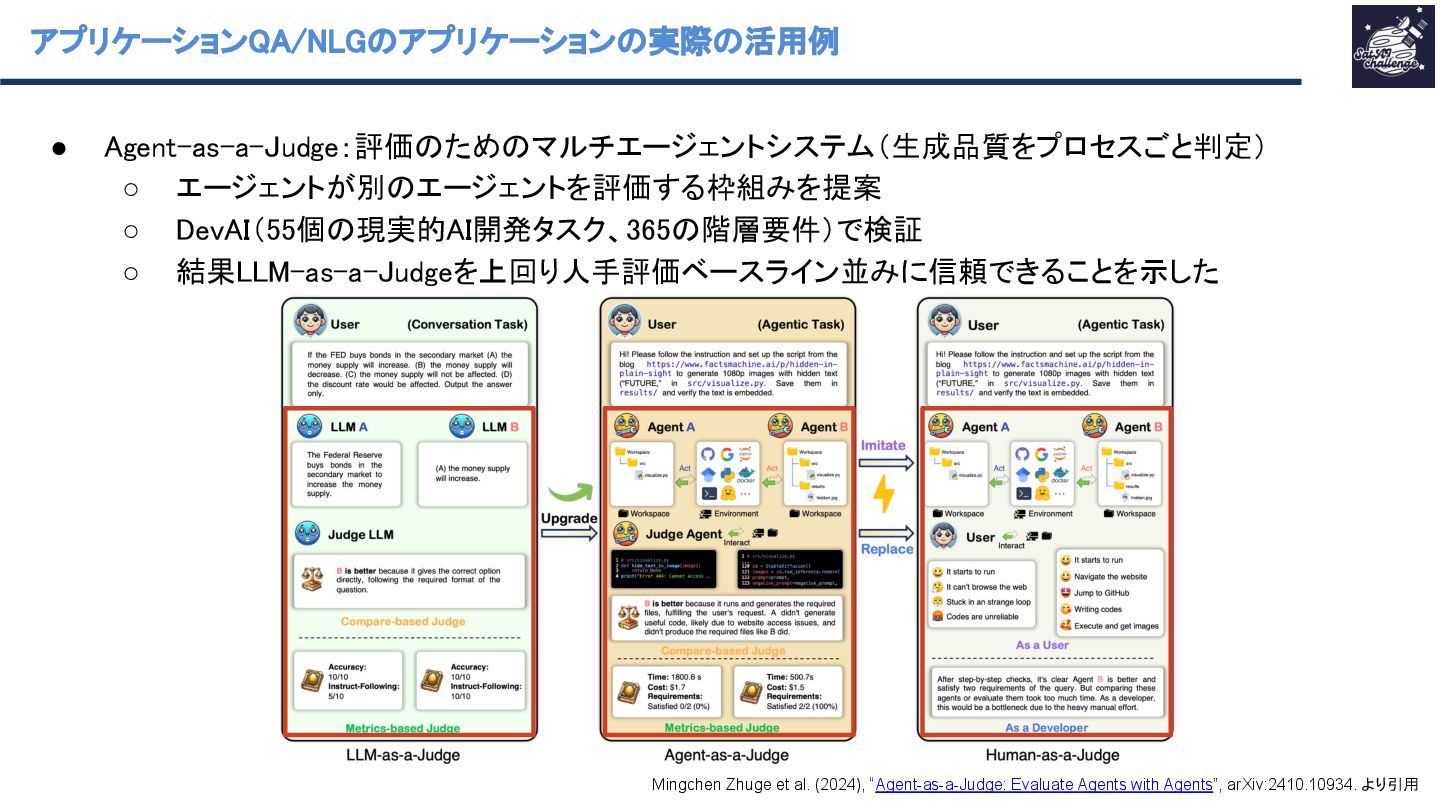
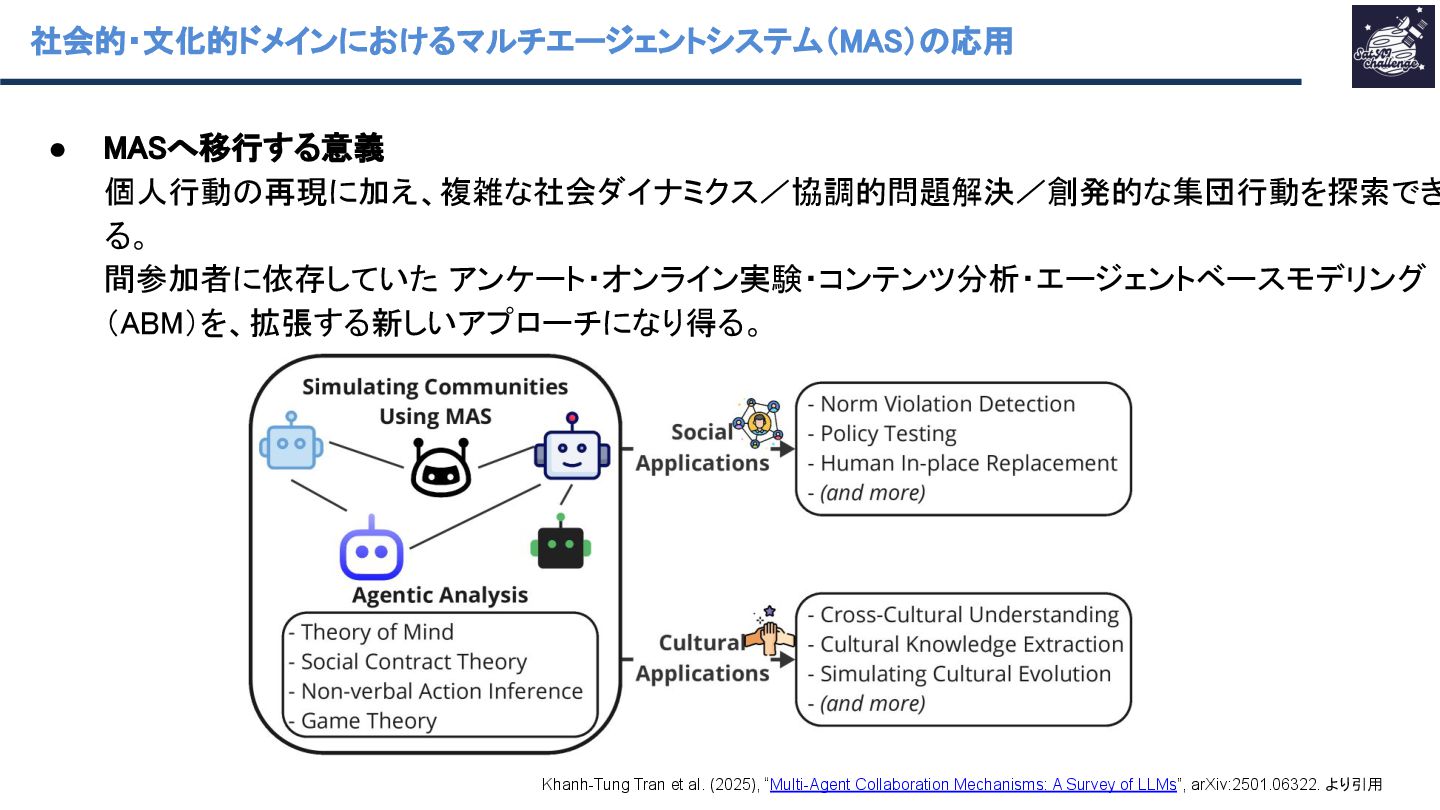
▪ 5G/B6G(B6G=Beyond 6G)と Industry 5.0 を「LLM がエッジネットワーク性能を高める」代 表的応用領域として同じ節で整理している(通信性能だけでなく、運用・自動化も含む)。 ◦ Question Answering / Natural Language Generation (QA/NLG) ◦ Social and Cultural Domains ▪ AIエージェントを題材に人間社会の社会・文化的振る舞いをシミュレーション Khanh-Tung Tran et al. (2025), “Multi-Agent Collaboration Mechanisms: A Survey of LLMs”, arXiv:2501.06322. より引用
al.(“Multi-Agent Consensus Seeking via Large Language Models”, 2023)は、数値状態を交渉で一致させる課題で、明示的に戦略を指示しな いと平均(average)戦略が主に選ばれること、さらに人数・性格・ネットワークトポロジが交渉過程に影響することを示した。 • 同研究は、このRB的な合意形成を**マルチロボット集合(aggregation)**に適用し、ゼロショットでの自律的な協調計画の可 能性をデモしている。 • ピアレビュー手順(解く→査読→修正)を固定すると推論精度が上がる:Xu et al.(“Towards Reasoning in LLMs via Multi-Agent Peer Review Collaboration”, 2023)は、各エージェントが独立解答→相互レビュー(confidence付き)→改稿する ルール化プロトコルを提案し、複数の推論タスクで既存法より高い精度を報告(単なる解答共有よりフィードバック交換が有 効、能力差と多様性も重要)。 • 設計上の含意:RBは「何をいつ誰が言うか」を固定できるので、検証線(レビュー役/多数決/停止条件)を組み込みやすい 一方、環境変化が大きいタスクではルール更新コストとルール爆発がボトルネックになる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
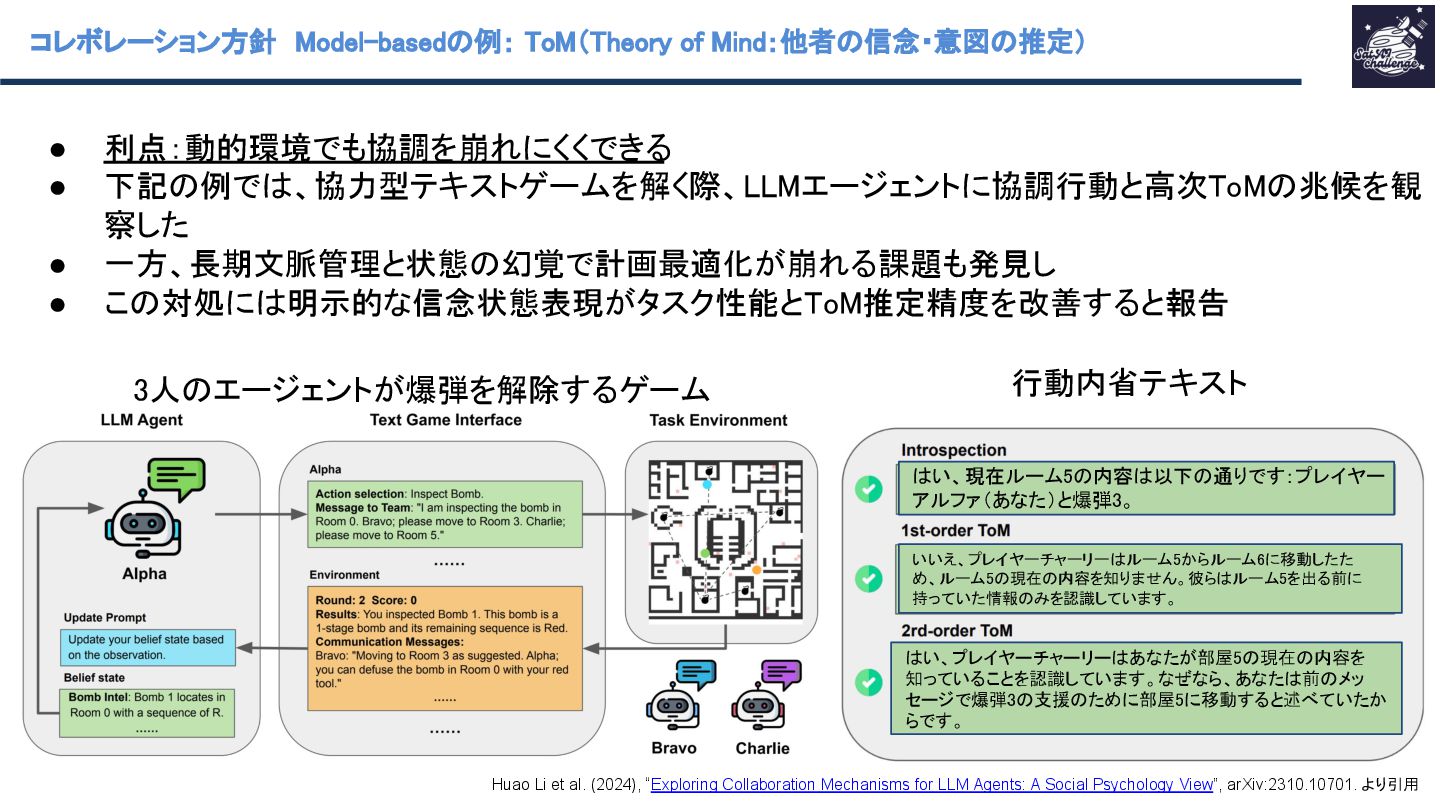{kind=link}
{kind=link}
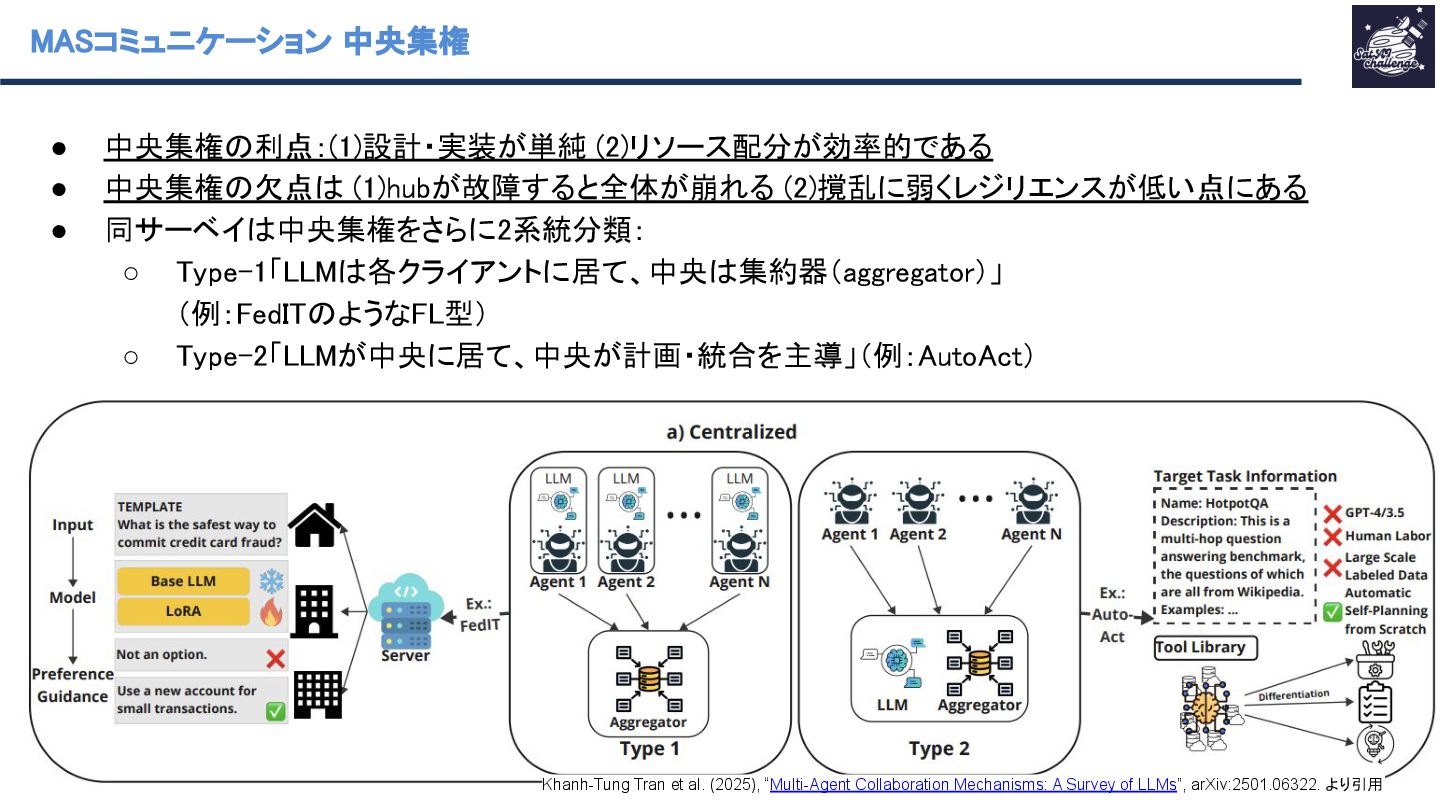{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}